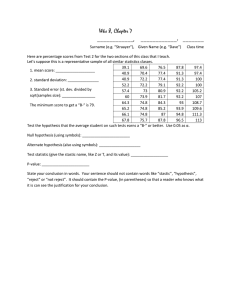
Testing of hypothesis with EXCEL Statistical inference: The process of drawing inference about a population on the basis of information contained in the sample taken from the population is called statistical inference. Statistical inference is divided into two branches 1. Estimation of parameters: 2. Testing of hypothesis: Testing of hypothesis: It is procedure which enables us to decide on the basis of information obtained by sampling whether to accept or reject any specified statement or hypothesis regarding the value of the parameter in a statistical problem.we use these test in MS excel to test of hypothesis Name One-sample z-test testing of mean Two-sample z-test testing of mean Formula for Assumptions or notes (Normal population or and σ known. for Normal population and independent observations and σ1 and σ2 are known Two-sample pooled t-test, equal variances* for testing about difference between two population mean (Normal populations and independent observations and σ1 = σ2 and σ1 and σ2 unknown Two-sample unpooled ttest, unequal variances* for testing about difference between two population mean. (Normal populations or and independent observations and σ1 ≠ σ2 and σ1 and σ2 unknown *Two-sample F test for equality of variances Arrange so > One sample z-test: 1. We state our null and alternative hypothesis as follow a. Ho: μ = μ0 and H1: μ ≠ μ0 (Two sided) b. Ho: μ ≥μ0 and H1: μ < μ0 (One sided) c. Ho: μ ≤ μ0 and H1: μ >μ0 (one sided) 2. Level of significance: α will be given 3. Test statistic 4. Calculation: This step will be done in excel if we have values of𝑥̅ , n and σ is given then we will use enter our formula in excel 5. Critical region: a. Our CR will depend on the value of z-cal if it 1. Z-cal is +vie then we will use =normsinv(1-α/2) 2. Z-cal is negative then we will use =normsinv(α/2) 3. We will also calculate p-value by 2*(1-normsdist (abs (z-cal)) b. For b our CR will be i. For z-tab we will use =normsinv (α) ii. For p-value we will use =normsdist (z-cal) c. For c our CR will be i. For z-tab we will use =normsinv(1-α) ii. For p-value we will use =1-normsdist(z-cal) 6. Decision: We will take decision on two bases 1. Z-tab a. For z-cal is + then we will use =if(z-cal > z-tab, “reject ho”,”do not reject ho”) b. For z-cal is – then we will use = if(z-cal < z-tab, “reject ho”,”do not reject ho”) 2. P-value a. =if(p-value< α,”reject ho”,”do not reject ho”) 3. For B hypothesis we will use a. we will use = if(z-cal < z-tab, “reject ho”,”do not reject ho”) b. =if(p-value< α,”reject ho”,”do not reject ho”) 4. For c a. =if(p-value< α,”reject ho”,”do not reject ho”) b. =if(z-cal > z-tab, “reject ho”,”do not reject ho”) 7. Conclusion: they will be made from p and z-tabulated decisions. Two sample z-test: 1. We state our null and alternative hypothesis as follow a. Ho: μ - μ0 = 0 and H1: μ - μ0≠ 0 (Two sided) b. Ho: μ -μ0 ≥ 0 and H1: μ - μ0 < 0 (one sided) c. Ho: μ -μ0 ≤ 0 and H1: μ -μ0> 0 (one sided) Where 0 will be any specified value from 0, 1, 2, 3… 2. Level of significance: α will be given 3. Test statistic z X 1 X 2 0 2 1 n1 12 n1 4. Calculation: This step will be done in excel if we have values of𝑥̅ , n and σ is given then we will use enter our formula in excel 5. Critical region: a. Our CR will depend on the value of z-cal if it 4. Z-cal is +vie then we will use =normsinv(1-α/2) 5. Z-cal is negative then we will use =normsinv(α/2) 6. We will also calculate p-value by 2*(1-normsdist (abs (z-cal)) b. For b our CR will be i. For z-tab we will use =normsinv (α) ii. For p-value we will use =normsdist (z-cal) c. For c our CR will be i. For z-tab we will use =normsinv(1-α) ii. For p-value we will use =normsdist(z-cal) 6. Decision: We will take decision on two bases 1. Z-tab c. For z-cal is + then we will use =if(z-cal > z-tab, “reject ho”,”do not reject ho”) d. For z-cal is – then we will use = if(z-cal < z-tab, “reject ho”,”do not reject ho”) 2. P-value a. =if(p-value< α,”reject ho”,”do not reject ho”) 3. For B hypothesis we will use a. we will use = if(z-cal < z-tab, “reject ho”,”do not reject ho”) b. =if(p-value< α,”reject ho”,”do not reject ho”) 4. For c a. =if(p-value< α,”reject ho”,”do not reject ho”) b. =if(z-cal > z-tab, “reject ho”,”do not reject ho”) 7. Conclusion: they will be made from p and z-tabulated decisions. Unpaired and paired two-sample t-tests Unpaired: The unpaired, or "independent samples" t-test is used when two separate sets of independent and identically distributed samples are obtained, one from each of the two populations being compared Paired: Dependent samples (or "paired") t-tests typically consist of a sample of matched pairs of similar units, or one group of units that has been tested twice (a "repeated measures" t-test). A typical example of the repeated measures t-test would be where subjects are tested prior to a treatment, say for high blood pressure, and the same subjects are tested again after treatment with a bloodpressure lowering medication. Paired sample test: In statistics, a paired difference test is a type of location (mean) test that is used when comparing two sets of measurements to assess whether their population means differ. A paired difference test uses additional information about the sample that is not present in an ordinary unpaired testing situation, either to increase the statistical power. Dependent t-test for paired samples: 8. We state our null and alternative hypothesis as follow a. Ho: μd = 0 and H1: μd ≠ 0 (Two sided) b. Ho: μd≥0 and H1: μd < 0(Two sided) c. Ho: μd ≤ 0 and H1: μd >0 (one sided) 9. Level of significance: α will be given 10. Test statistic: t d sd n where d d n i and s d (d i d) n 1 . It follows t-dist with n-1 df. 11. Calculation: This step will be done in excel if we have values of𝑥̅ , n and σ is given then we will use enter our formula in excel 12. Critical region: a. Our CR will depend on the value of t-cal if it 7. t-cal is +vie then we will use =tinv(α, df) 8. t-cal is negative then we will use = -tinv(α, df) 9. We will also calculate p-value by = tdist(abs(t-cal), df, tail) b. For b our CR will be i. For t-tab we will use = -tinv (2α, df) ii. For p-value we will use =tdist (abs(t-cal), df, tail) c. For c our CR will be i. For t-tab we will use = tinv(2α, df) ii. For p-value we will use =tdist(t-cal, df, tail) 13. Decision: We will take decision on two bases 5. t-tab a. For t-cal is + then we will use =if(t-cal > t-tab, “reject ho”,”do not reject ho”) b. For t-cal is – then we will use = if(t-cal < t-tab, “reject ho”,”do not reject ho”) 6. P-value 7. For B hypothesis we will use a. we will use = if(t-cal < -t-tab, “reject ho”,”do not reject ho”) b. CR for p-value will be completed in following steps 1. First from p-value we will calculate 1-p-value. 2. Decision for critical region a. we will use =if(t-cal<0, p-value”,”1-pvalue) 3. Then from above we will take decision. 8. For c CR for p-value will be completed in following steps 1. First from p-value we will calculate 1-p-value. 2. Decision for critical region a. we will use =if(t-cal<0, 1-p-value”,”pvalue”) 3. Then from above we will take decision. b. =if(t-cal > t-tab, “reject ho”,”do not reject ho”) Conclusion: they will be made from p and t-tabulated decisions. T-test assuming unequal variances: In statistics, Welch's t test is an adaptation of Student's t-test intended for use with two samples having possibly unequal variances. As such, it is an approximate solution to the Behrens–Fisher problem. Procedure: 14.We state our null and alternative hypothesis as follow a. Ho: μ - μ0 = 0 and H1: μ - μ0≠ 0 (Two sided) b. Ho: μ -μ0 ≥ 0 and H1: μ - μ0 < 0 (one sided) c. Ho: μ -μ0 ≤ 0 and H1: μ -μ0> 0 (one sided) 15. Level of significance: α will be given s12 s12 n1 n1 ( x1 x 2 ) 0 16. Test statistic: t where v 2 2 2 2 s1 s2 s12 s12 n n 1 1 n1 n2 n1 1 n2 1 17. Calculation: This step will be done in excel if we have values of𝑥̅ , n and σ is given then we will use enter our formula in excel 18. Critical region: a. Our CR will depend on the value of t-cal if it 10. t-cal is +vie then we will use =tinv(α, df) 11. t-cal is negative then we will use = -tinv(α, df) 12. We will also calculate p-value by = tdist(abs(t-cal), df, tail) b. For b our CR will be i. For t-tab we will use = -tinv (2α, df) ii. For p-value we will use =tdist (abs(t-cal), df, tail) c. For c our CR will be i. For t-tab we will use = tinv(2α, df) ii. For p-value we will use =tdist(t-cal, df, tail) 19. Decision: We will take decision on two bases 9. t-tab a. For t-cal is + then we will use =if(t-cal > t-tab, “reject ho”,”do not reject ho”) b. For t-cal is – then we will use = if(t-cal < t-tab, “reject ho”,”do not reject ho”) 10. P-value 11. For B hypothesis we will use a. we will use = if(t-cal < -t-tab, “reject ho”,”do not reject ho”) b. CR for p-value will be completed in following steps 1. First from p-value we will calculate 1-p-value. 2. Decision for critical region a. we will use =if(t-cal<0, p-value”,”1-pvalue) 3. Then from above we will take decision. 12. For c CR for p-value will be completed in following steps 1. First from p-value we will calculate 1-p-value. 2. Decision for critical region a. we will use =if(t-cal<0, 1-p-value”,”pvalue”) 3. Then from above we will take decision. b. =if(t-cal > t-tab, “reject ho”,”do not reject ho”) 20.Conclusion: they will be made from p and t-tabulated decisions. Testing of normality assumption: We JB test for this purpose. In statistics, the Jarque–Bera test is a goodness-of-fit test of whether sample data have the skewness and kurtosis matching a normal distribution. The test is named after Carlos Jarque and Anil K. Bera. The test statistic JB is defined as Where n is the number of observations (or degrees of freedom in general); S is the sample skewness, and K is the sample kurtosis: where and are the estimates of third and fourth central moments, respectively, sample mean, and is the estimate of the second central moment, the variance. is the If the data come from a normal distribution, the JB statistic asymptotically has a chi-squared distribution with two degrees of freedom, so the statistic can be used to test the hypothesis that the data are from a normal distribution. The null hypothesis is a joint hypothesis of the skewness being zero and the excess kurtosis being zero. Samples from a normal distribution have an expected skewness of 0 and an expected excess kurtosis of 0 (which is the same as a kurtosis of 3). As the definition of JB shows, any deviation from this increases the JB statistic. History: Considering normal sampling, and √β1 and β2 contours, Bowman & Shenton (1975) noticed that the statistic JB will be asymptotically χ2(2)-distributed; however they also noted that “large sample sizes would doubtless be required for the χ2 approximation to hold”. Bowman and Shelton did not study the properties any further, preferring D’Agostino’s K-squared test. Around 1979, Anil Bera and Carlos Jarque while working on their dissertations on regression analysis, have applied the Lagrange multiplier principle to the Pearson family of distributions to test the normality of unobserved regression residuals and found that the JB test was asymptotically optimal (although the sample size needed to “reach” the asymptotic level was quite large). In 1980 the authors published a paper (Jarque & Bera 1980), which treated a more advanced case of simultaneously testing the normality, homoscedasticity and absence of autocorrelation in the residuals from the linear regression model. The JB test was mentioned there as a simpler case. A complete paper about the JB Test was published in the International Statistical Review in 1987 dealing with both testing the normality of observations and the normality of unobserved regression residuals, and giving finite sample significance points Procedure: 1. We state our null and alternative hypothesis Ho: the data is normal. And H1: the data is not normal 2. Level of significance: 3. Test statistics: S 2 (k 3)2 2 JB n ~ with 2 df 6 24 4. Calculation decision and conclusion will be on excel