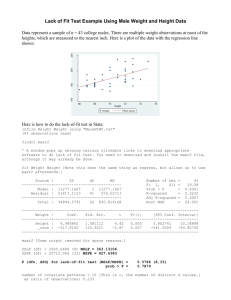
Apr. 19th Mon. Chapter 3.4 NONLINEAR RELATIONSHIPS Scatterplots of (bivariate) data frequently shows curvature rather than a linear pattern. (An example of such curvature was shown in Exercise 27 Data set #2 (see p.16 of Apr. 18 Sun.pdf). In Chapter 3.4, we discuss different ways to fit a curve (rather than a straight line) to such scatterplots of (bivariate) data. Power Transformations (For review, a list of algebraic power transformations is on the left-hand side of p.133 of your text.) In this section, you are expected to know WHEN a power transformation is to be employed (we are not going to get you into the business of memorizing which power transformation may be more likely to work in one set of circumstances or is otherwise recommended – but not guaranteed; but, rather, we want to be most comfortable and confident with the case of WHEN to use a power transformation). The case of WHEN to use a power transformation is WHEN the general pattern in the scatterplot (or data) is monotonic, but when a linear fit (i.e., a straight line) won’t do to the original data as is. Recall the definition of monotonic from calculus or otherwise: a monotonic graph is a graph in which there is either strictly increasing or decreasing in the plotted points. In this course, we will say that WHEN a scatterplot is generally (i.e., the, vast majority of points) monotonic then we should attempt a power transformation to model our data. Example 3.12 Power Transformation p. 134-5 Consider the following dataset with respect to x = frying time (sec) and y = moisture content % x: 5 10 15 20 25 30 45 60 y: 16.3 9.7 8.1 4.2 3.4 2.9 1.9 1.3 Cal Poly Learn By Doing Note that the general pattern of this scatterplot is monotonic (note definition given above); this prompts us to attempt a power transformation to model our data. Before doing so, however, I want you to note the R Studio output below with respect to attempting to fit a linear model (i.e., straight line) and its accompanied r-squared value: Example 3.12: Untransformed Call: lm(formula = moisture ~ fry, data = fm) Residuals: Min 1Q Median -3.1762 -2.3895 -0.1576 3Q 0.8192 Max 5.5610 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 11.85995 2.07897 5.705 0.00125 ** fry -0.22419 0.06616 -3.389 0.01470 * --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 3.233 on 6 degrees of freedom Multiple R-squared: 0.6568, Adjusted R-squared: 0.5996 F-statistic: 11.48 on 1 and 6 DF, p-value: 0.0147 With respect to several transformations that we could attempt (and there are also several statistical tests that can be employed beyond using Figure 3.16 in your text as a guide) we will provide the (or provide several possible) transformations for you. Then, based on the computer output we will leave for you to determine which model is best. In this introductory to statistics course, what transformation is best will be judged by which model (among those we attempt, or do attempt based on our established procedures) has the highest r2 value, and this general rule also holds up well in more advanced modeling found beyond the scope of your textbook. We display the power transformation of taking a natural log to both variable x and y below: Note how now a visual inspection now reveals a linear pattern to the scatterplot above. The accompanied computer output is: Example 3.12: Power Transformation (Ln x, Ln y) Call: lm(formula = lnmoisture ~ lnfry, data = lnfm) Residuals: Min 1Q Median -0.15863 -0.06523 -0.02129 3Q 0.01043 Max 0.29473 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 4.6384 0.21105 21.98 5.80e-07 *** lnfry -1.0492 0.06786 -15.46 4.63e-06 *** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.1449 on 6 degrees of freedom Multiple R-squared: 0.9755, Adjusted R-squared: 0.9714 F-statistic: 239.1 on 1 and 6 DF, p-value: 4.629e-06 Our regression equation now is: ln 𝑦̂ = 4.6384 − 1.0492(ln 𝑥) Note that the r2 value has improved to 0.9755 from 0.6568 in the previous (original) plot. All else equal, we again judge that the prediction model does a BETTER job of predicting if the given prediction model has a higher r2 value then any other examined models. This transformed model notes that when frying time, x, is 20 seconds, then the predicted moisture content, %, y, is 4.46%. This is found by: ln 𝑦̂ = 4.6384 − 1.0492(ln 𝑥) ln 𝑦̂ = 4.6384 − 1.0492(ln 20) ln 𝑦̂ = 4.6384 − 1.0492( 2.995732274) ln 𝑦̂ = 4.6384 − 3.143122301 ln 𝑦̂ = 1.495277699 𝑒 ln 𝑦̂ = 𝑒 1.495277699 𝑦̂ = 4.4606 Can you verify that when frying time is x = 27.5 seconds, that the model predicts moisture content percentage y to be 3.1936%? Cal Poly Learn By Doing --- End Example 3.12 --- Fitting a Polynomial Function If viewing the scatterplot of your original dataset, if there is both a LACK of linear fit (i.e., a straight line would not do), and a LACK of monotonicity, then it is reasonable to transform your data by fitting a quadratic function (i.e., polynomial) with the general form: 𝑦̂ = a + b1x + b2x2 The signs of the coefficients (a, b1, and b2) are given to us by our computer output (either R Studio or Minitab, whichever is presented), in the same fashion that non-polynomial functions were. Example 3.13 p.136 Lack of Monotonicity Consider the following dataset with respect to x = fermentation (days) and y = glucose (g/L) x: 1 2 3 4 5 6 7 8 y: 74 54 52 51 52 53 58 71 We note from our scatterplot that the data is NOT linear and is also NOT monotonic; therefore, we are well served to attempt to fit a polynomial. Before doing so, however, I want you to note the R Studio output below with respect to attempting to fit a linear (i.e., straight line) model and this original data’s r-squared value: Example 3.13: Untransformed Call: lm(formula = gc ~ ft, data = ftgc) Residuals: Min 1Q Median -7.107 -6.089 -4.607 3Q Max 3.027 16.000 Coefficients: Estimate Std. Error t value (Intercept) 57.96429 7.70589 7.522 ft 0.03571 1.52599 0.023 --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 Pr(>|t|) 0.000286 *** 0.982087 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.89 on 6 degrees of freedom Multiple R-squared: 9.128e-05, Adjusted R-squared: F-statistic: 0.0005477 on 1 and 6 DF, p-value: 0.9821 -0.1666 (We note the r2 value is extremely low r2= 0.00009128, or < 0.001, another indication that a linear model is not a good fit. (Again, all else equal, we want r2 to be as close to 1.0 as possible.) OK – let’s fit a polynomial, for glucose concentration, gc, and fermenting time, time: We note the fit appears to be pretty good (i.e., most points appear to fall on the quadratic line, shown in green. Let’s check our output to see if the value of r2 has improved. Example 3.13 Transformation to Polynomial Call: lm(formula = gc ~ time + timesqd, data = TS) Residuals: 1 2 3 3.6250 -5.8036 -0.7679 4 1.7321 5 2.6964 6 7 0.1250 -1.9821 8 0.3750 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 84.4821 4.9036 17.229 1.21e-05 *** time -15.8750 2.5001 -6.350 0.00143 ** timesqd 1.7679 0.2712 6.519 0.00127 ** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 3.515 on 5 degrees of freedom Multiple R-squared: 0.8948, Adjusted R-squared: 0.8527 F-statistic: 21.25 on 2 and 5 DF, p-value: 0.003594 Our general form for quadratic is: 𝑦̂ = a + b1x + b2x2 𝑦̂ = 84.482 − 15.875𝑥 + 1.7679𝑥 2 Note that the r2 value has improved to 0.8948 from < 0.001 in the original (untransformed) plot. Again, all else equal, we can judge whether the prediction model does a BETTER job of predicting if the given prediction model has a higher r2 value than any other examined plots. The model notes that when time, x, is 4 days*, then the glucose concentration, y, is 49.27; can you verify this? Cal Poly Learn By Doing *textbook has a slight typo; this should again read as ‘days’ as it correctly does on p. 113 --- End Example 3.13 --Please be comfortable with, or otherwise PRACTICE Section 3.4 Exercises: 29a 29b, 31b 31c, 33a 33b Cal Poly Learn By Doing Note also that the below pages have scatterplots and computer output provided for you necessary to answer these exercises. Such output will, of course, be continued to be provided for you. On scientific notation: 9.96e-03 is equivalent to: 0.00996 (i.e., you move the decimal to the left 3 places if you have e-03) On scientific notation: 1.452e+01 is equivalent to 14.52 (i.e., you move the decimal to the right 1 place if you have e+01) (For a greater sense of variety, I have changed the colors and plotting character of these scatterplots; we do want to be comfortable with the idea that bivariate data can be, and is, plotted using multiple colors and multiple plotting symbols to represent datapoints, respectively. Furthermore, we want to be comfortable with dealing with scientific notation, when it presents itself.) Exercise 29 y versus x Call: lm(formula = yield ~ flow, data = fy) Residuals: Min 1Q -154.77 -128.99 Median -33.52 3Q 8.68 Max 586.23 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -397.9 389.6 -1.021 0.334 flow 136496.6 90168.2 1.514 0.164 Residual standard error: 224.6 on 9 degrees of freedom Multiple R-squared: 0.2029, Adjusted R-squared: 0.1144 F-statistic: 2.292 on 1 and 9 DF, p-value: 0.1644 Exercise 29 1/y versus x Call: lm(formula = yield1 ~ flow, data = fy1) Residuals: Min 1Q -0.013273 -0.002082 Median 0.001456 3Q 0.003474 Max 0.010298 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 0.10454 0.01182 8.844 9.85e-06 *** flow -21.02141 2.73617 -7.683 3.05e-05 *** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.006817 on 9 degrees of freedom Multiple R-squared: 0.8677, Adjusted R-squared: 0.853 F-statistic: 59.03 on 1 and 9 DF, p-value: 3.054e-05 Exercise 31: y versus x Call: lm(formula = stramp ~ cycfail, data = CS) Residuals: Min 1Q Median -0.0038061 -0.0020579 -0.0009746 3Q 0.0019876 Max 0.0082848 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 9.906e-03 9.132e-04 10.848 4.64e-09 *** cycfail -4.934e-08 3.101e-08 -1.591 0.13 --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.003509 on 17 degrees of freedom Multiple R-squared: 0.1297, Adjusted R-squared: 0.07846 F-statistic: 2.532 on 1 and 17 DF, p-value: 0.13 Exercise 31: y versus ln(x) Call: lm(formula = stramp ~ cycfaillnx, data = CS) Residuals: Min 1Q Median -0.0032929 -0.0024824 -0.0003629 3Q 0.0021192 Max 0.0044476 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 0.0197092 0.0026331 7.485 8.92e-07 *** cycfaillnx -0.0012805 0.0003126 -4.096 0.000753 *** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.002668 on 17 degrees of freedom Multiple R-squared: 0.4967, Adjusted R-squared: 0.4671 F-statistic: 16.78 on 1 and 17 DF, p-value: 0.0007534 Exercise 31: ln(y) versus ln(x) Call: lm(formula = stramplnx ~ cycfaillnx, data = CS) Residuals: Min 1Q Median -0.37052 -0.23765 -0.01776 3Q 0.20089 Max 0.43123 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -3.73722 0.26946 -13.869 1.07e-10 *** cycfaillnx -0.12395 0.03199 -3.874 0.00122 ** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.2731 on 17 degrees of freedom Multiple R-squared: 0.4689, Adjusted R-squared: 0.4376 F-statistic: 15.01 on 1 and 17 DF, p-value: 0.001218 Exercise 31: 1/y versus 1/x Call: lm(formula = istrampl ~ icycfail, data = CS) Residuals: Min 1Q -60.745 -17.602 Median -2.295 3Q 37.733 Max 44.957 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 129.259 8.803 14.684 4.34e-11 *** icycfail -2154.336 946.543 -2.276 0.0361 * --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 36.35 on 17 degrees of freedom Multiple R-squared: 0.2336, Adjusted R-squared: 0.1885 F-statistic: 5.18 on 1 and 17 DF, p-value: 0.03607 Exercise 33 Call: lm(formula = strength ~ thickness, data = TS) Residuals: Min 1Q -8.8620 -2.2765 Median 0.5266 3Q 2.4411 Max 5.7708 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 29.294856 2.260001 12.962 1.44e-10 *** thickness -0.022422 0.004019 -5.579 2.70e-05 *** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 4.098 on 18 degrees of freedom Multiple R-squared: 0.6336, Adjusted R-squared: 0.6132 F-statistic: 31.12 on 1 and 18 DF, p-value: 2.701e-05 Exercise 33 Polynomial Function Call: lm(formula = strength ~ thickness + thicknesssqd, data = TS) Residuals: Min 1Q -5.6278 -2.2024 Median 0.2857 3Q 2.4414 Max 4.8790 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.452e+01 4.754e+00 3.055 0.00717 ** thickness 4.323e-02 1.981e-02 2.183 0.04337 * thicknesssqd -6.001e-05 1.786e-05 -3.359 0.00372 ** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 3.269 on 17 degrees of freedom Multiple R-squared: 0.7797, Adjusted R-squared: 0.7538 F-statistic: 30.09 on 2 and 17 DF, p-value: 2.599e-06 Our quadratic equation used to predict strength is: 𝑦̂ = 14.52 + .0432x - .00006x2 (As per Section 3.4 where Residual Plots were cited as optional, we are skipping this portion)