DSL - A .NET Implementation Rajeswar Majumdar ADP India
advertisement

DSL - A .NET Implementation
Rajeswar Majumdar
Architect- R&D- Global Product & Technology
ADP India
|2
Introduction
Domain specific languages (DSL) are around for quite some time and widely in use for software
development. In this article we will discuss what DSLs are and their characteristics,some basic concepts of
computer science language theory relevant to DSL and finally an example of DSL implementation using
.NET.
What is a Domain Specific Language (DSL)
A domain specific language (DSL) is a computer programming language of limited expressiveness that is
focused on a particular domain. A DSL is worthwhile and conveys meaning only in the context of the
particular domain.
The characteristic which makes DSL distinct from general purpose languages is ‘limited expressiveness’.
With a general purpose language like Java or C#, we can build almost any kind of system- small or big, PC or
mobile or web enabled, with rich user interface or no user interface at all and in any functional domain like
banking, HR etc. This requires supporting different data structures, control flow, abstraction and many
more features. This also makes these languages too vast and difficult to understand or master for nonprogrammers.
On the other hand, a DSL being focused on a particular problem domain can be defined using bare
minimum of syntactical rules which are sufficient for the domain in question. This makes it possible to
define a DSL which closely resembles a natural language like English (with a very small subset of words and
strict syntactical rules). So it becomes easier for non-programmers like domain experts and business
analysts to understand if not write programs in DSL.
Kinds of DSL- Internal and External
Some examples of DSLs which we use in everyday programming are HTML (domain- Web user interface),
Sql (domain- RDBMS) or CSS (domain- HTML styling). These are examples of ‘external’ DSLs which are
completely different from general purpose languages and do not use any feature of a general purpose
language.
However it is possible to create a so-called ‘internal’ DSL within a general purpose language itself that uses
only limited features of that language. One such example is ‘Fluent Interface’ pattern in C# which uses a
special chaining syntax for method call and is suitable where C# code needs to be mixed with other
languages like HTML (e.g. ASP.NET MVC View pages).
Rule engines are closely related to DSL but they are different from DSL because of the fact that rule engines
are also general purpose rather than focused on a specific domain. However rule engines often uses some
form of DSL for defining the rules. For example, IBM JRULE rule engine uses an Xml based DSL for defining
rules and Microsoft .NET Workflow Foundation rule engine uses a C# internal DSL for rule definition.
DSL Basic Concepts
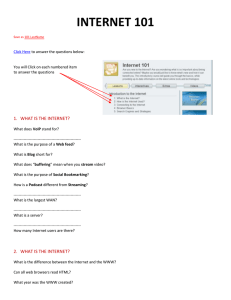
Optional
DSL
Script
Parse
Domain Model
Architecture
Code Generator
Target Code
DSL
|3
The implementation of an external DSL requires a DSL script, a parser and optionally a code generator. The
DSL script adheres to the limited grammatical or syntactical rules defined for the DSL. The parser parses the
DSL to generate an instance of the domain model specific to the domain in consideration. This domain
model is the crux of the design and should be conceptualized prior to designingthe DSL. The domain model
drives the design of the DSL and parser. The generated instance of the domain model is manipulated by the
application code to produce the DSL program output. Optionally the domain model can be further
processed to generate code in some general purpose language like Java or C# which is then compiled and
executed just like hand written code.
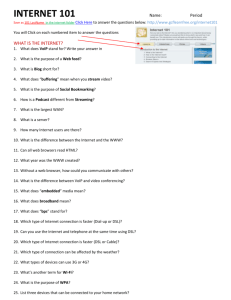
Before we go into the details of DSL implementation, we need to understand a few important concepts
related to general computer science language theory. Any so called ‘program’ written in any computer
language, is nothing but a series of characters. The process of converting the stream of characters to a
sequence of tokens is called lexical analysisor tokenization. A token is a string of one or more characters
that is significant or meaningful as a group according to the grammar of that particular language.The
component which does this tokenization is called a lexer or tokenizer. These tokens are then parsed or
syntactically analyzed by a parserto generate a hierarchical tree structure of tokens which is called a parse
tree. Often the parser itself will combine the functions of lexer and parser. The parse tree is also called a
syntax tree or Abstract Syntax Tree (AST). The AST represents the syntactical structure of the program i.e.
which code blocks or statements are contained within what. The syntax is "abstract" in not representing
every detail appearing in the real syntax.
This parse tree is then used by an interpreter to perform semantic analysis (and generate code in some
lower level language in case of compiler). Then the interpreter takes appropriateactions using the validated
expressions in the parse tree and contextual data supplied by the hosting run time system.
Sequence of
Characters
Lexer
(Lexical Analysis)
Grammar
Tokens
Parser
(Syntactical Analysis)
Grammar
Parse Tree
Contextual Data
Interpreter
(Semantic Analysis)
Output
Language process flow
Grammar
|4
The grammar or rules of the language can be expressed or defined in various ways. One of the standard
ways of specifying this is Backus-Naur Form (BNF). In this notation, the grammatical rules are specified as
follows:
<symbol>::= __<expression>__
For example
<postal-address>::=<name-part><street-address><zip-part>
In this article, we will use the BNF notation for specifying the DSL rules.
External DSL Implementation - EmployeeLeave EligibilityDetermination
As discussed previously, DSL are especially useful for implementing application code which is subjected to
change often. This makes DSL suitable for Human Capital Management (HCM) domain where the employee
benefits, entitlements, taxation etc. often change based on company policies or regulatory requirements.
In this example, we will consider a simple use case from HCM domain which is validating the leave
eligibility of an employee.
External DSLs require a hosting environment which would create the run time and execute the DSL script in
the context of a domain model. We would be using Microsoft .NET to provide this hosting environment.
Irony (http://irony.codeplex.com/) is an open source language implementation kit developed in and for
.NET framework. This provides in- built components for defining language grammar and comes with an
inbuilt parser and interpreter to parse and execute the source code script based on a particular language
grammar.
In this example, we would be using Irony to define grammar, creating the AST from source code script and
execute the source code script in the context of our domain model.
Below is the domain model we would be working with:
Domain Model
The Employee entity represents an employee in the organization who can apply for a leave. The leave
applied by an employee is represented by the LeaveApplication entity. One Employee instance can be
associated with zero or more LeaveApplication instances. Each leave application can of any of the following
leave types: Casual, Earned or Optional Holiday. This is represented by the LeaveType enumeration.
For our purpose the following are the significant attributes of our domain entities:
Employee:
LeaveBalances (Dictionary<LeaveType,int>): A dictionary object which contains the leave balance
days (integer) keyed by the corresponding leave type enum value. Obviously whether an
employee is eligible for leave depends on his leave balance for that type of leave.
|5
DaysWorked (int): The number of days worked by the employee in the current organization since
his joining. She can avail certain types of leaves only if she has spent a minimum tenure with the
organization.
LeaveApplication:
Duration (int): The number of days for which the leave is applied. For simplicity we assume that
only full day leaves are allowed i.e. duration is always integer.
LeaveType (LeaveType enum): The type of the leave being applied. Obviously eligibility varies
depending on the leave type.
With the domain entities defined, let’s now come to the business logic to be implementedthat will decide
whether a leave application is valid or invalid based on employee’s eligibility.
Our business rules require that:
1. If the employee’s leave balance is not sufficient for the duration of the leave applied, then the
leave application is invalid
2. Employee cannot apply for Casual leave if the leave duration is more than a couple of days
3. Employee has to spend at least 30 days in the organization before she becomes eligible for Earned
or Option Holiday leaves
Since the above rules are often subjected to change, so we decided to implement the above logic as
external DSL so that it can be understood and modified by the Human Resource department without the
help of developers of HCM software. Also any change in the business logicwould not require recompilation of the HCM system’s source code.
First step of implementing any external DSL is to define the language grammar. As mentioned before, we
would use BNF to represent the grammar.
<program>:=<statementList>
<statementList>:= <statement>+
<statement>:= (<expression> ";") | <incaseStatement>
<incaseStatement>:= "in case" <booleanExpression> "then" "{" <statementList> "}"
[otherwiseStatement]
<otherwiseStatement>:= "otherwise" "{" <statementList> "}"
<expression>:= <Number>| <String> | <boolean> | <balance> | <daysWorked> | <duration>|
<booleanExpression> | <arithmeticExpression> | <parenExpression> | <resultAssignmentExpression>
<parenExpression>:= "(" <expression> ")"
<booleanExpression>:= <expression><booleanOperator><expression> | <leaveTypeOptions>
<arithmeticExpression>:= <expression><arithmeticOperator><expression>
<resultAssignmentExpression>:= "application" <validInvalid>
<booleanOperator>:= "="|"<"|">"|">="|"<="|"and"|"or"
<arithmeticOperator>:= "+"|"-"|"*"|"/"
<validInvalid>:= "valid"|"invalid"
<balance>:= "balance"
<daysWorked>:"daysWorked"
<leaveTypeOptions>:= "OH"| "casual"| "earned"
<duration>:= "duration"
Leave Validation Grammar- BNF
The grammar defines the rules for various elements (i.e. tokens) in a hierarchical structure. Note that at
the lowest level, we have defined a number of keywords like “duration”, “balance” etc. which has specific
meanings for only our DSL and in a particular context which is our domain model. The higher level
elements consist of combinations of lower level elements. For example, an “arithmeticExpression” will
consist of an “expression” followed by an “arithmeticOperator” followed by another “expression” (e.g.
|6
balance – duration). Similarly an expression can be either a “number” or a “string” or “booleanExpression”
or “arithmeticExpression” etc.
The “resultAssignmentExpression” rule might be of particular interest. This would be used to set whether
the leave application is valid or invalid and can be written in either of the following way:
application valid;
or
application invalid;
The conditional statements can be written using
in case <condition> then
{
//statements
}
otherwise
{
//statements
}
This is equivalent to “if” statement in C#. Similar to C# where “else” statement is optional, “otherwise” if
also optional and hence appear enclosed in square brackets in the “incaseStatement” rule definition.
Note that element rules can be recursive for example the rule for “expression” element contains
“expression” on the right hand side of the rule definition indirectly via “booleanExpression”,
“arithmeticExpression” etc.
The topmost element of the grammar is the “program” element which consists of “statementList” element
which in turn consists of one or more “statement” elements. Hence the “+” sign appears following the
“statement” element in the “statementList” rule definition. Similarly “*” denotes that zero or more
elements and “|” denotes that either of the adjacent elements are allowed.
With the grammar defined in BNF notation, we will proceed with defining the grammar using Irony and
subsequently writing “code” in our DSL which would be parsed and interpreted in the context of our
domain model.
The sample code accompanying this article consists of the following solution structure:
|7
It is written on .NET framework 4.5 and would require Visual Studio 2012 or later to open. It consists of
the following projects:
DSL.Sample.DomainEntities: Contains the domain entity classes as described before.
DSL.Sample.Language: Contains the implementation of the language grammar. Also contains
implementation of custom grammar elements to evaluate each element in the context of our domain.
DSL.Sample.Tests: This is a visual studio unit test project to unit test the grammar and custom grammar
elements against a given “source code” program of our DSL.
Apart from these, the “Scripts” solution folder contains the grammar defined in BNF
(LeaveValidationGrammar_BNF.txt) and the sample script written in this DSL (LeaveValidationScript.txt)
which implements the business logic described before.
The DSL.Sample.Language project contains reference to the following two Irony dlls:
Irony.dll: It contains the support for defining the grammar. Also contains the parser among other
framework elements.
Irony.Interpretor.dll: Contains the support for execution of source code script written in a DSL based on
a pre-defined grammar.
The LeaveApplicationValidationGrammarclass in the DSL.Sample.Language defines the grammar
(described before in BNF) as C# statements. This class has to derive from the Irony supplied
Irony.Parsing.Grammar class which provides the base methods for defining the grammar. The grammar
rules must be defined inside the constructor inside this class.
We want our language to be case insensitive, so while calling the base constructor we pass the
“caseSensitive” parameter as “false”. Also the whitespaces, new lines etc. are ignored automatically
during lexical analysis.
By default, Irony does not create Abstract Syntax Tree (AST) node while generating parse tree from source
code script. Since we want to generate the AST node for each of our grammar elements (unless otherwise
specified), we have to set the LanguageFlag accordingly.It is the custom implementation of AST Nodes
where we would define our own node evaluation logic.
The parse tree consists of “NonTerminals” (non-leaf nodes) and “Terminals” (leaf nodes). The “number”
and “text” nodes use Irony provided “NumberLiteral” and “StringLiteral” terminal nodes for rule
definition. It is important to set the TermFlags asNoAstNodefor these terms as we are not providing any
AstNode implementation for these terms.
All the other nodes are defined as “NonTerminal” so that we can implement our custom execution logic
via the “nodeType” parameter of its constructor.More on this is explained later.
Each non terminal definition corresponds to each rule in the BNF grammar definition. For example:
The C# statement
booleanOperator.Rule = ToTerm("<") | "=" | ">" | ">=" | "<=" |"and" | "or" | leaveTypeKeyword;
is equivalent to corresponding BNF form
<booleanOperator>:= "="|"<"|">"|">="|"<="|"and"|"or" | <leaveTypeKeyword>
Note the ToTerm() call at the start of the C# rule which converts the string “<” to an object of Irony
defined KeyTerm class (a subclass of Terminal class) and subsequently the overloaded “|” operator is used
to build the rule. Irony has also overloaded “+” operator to indicate concatenation of BNF terms.
|8
Similarly it provided methods like MakeStarRule(), MakePlusRule() etc. to define rules like <statement>*,
<statement>+ etc.
Each grammar requires a root to be defined for the parse tree and in our case “program” node is the root.
Based on this grammar, the following is the source code script in our own DSL that implements the
business logic we have described before:
in case (duration > balance)
then
{
application invalid;
}
otherwise
{
in case(casual and (duration > 2))
then
{
application invalid;
}
otherwise
{
in case((OH or earned) and (daysWorked < 30))
then
{
application invalid;
}
otherwise
{
application valid;
}
}
}
With the grammar defined and script written, we can generate the parse tree based on this grammar and
script. The LeaveApplicationValidationProcessor class in the same project defines the method
ProcessLeaveApplicationValidation() to generate the parse tree (and later to evaluate the parse tree based
on domain model data). The parse tree generation code is very simple:
LeaveApplicationValidationGrammarleaveValidationGrammar =
newLeaveApplicationValidationGrammar();
var parser = newParser(leaveValidationGrammar);
varparseTree = parser.Parse(script);
In case there is any error ((according to the grammar) in the source script, the code does not throw any
exception but it populates the ParserMessages property of the ParseTree with the error message. In case
there is no error during parsing, the ParseTree.Root will contain the root element which will in turn
contain subsequent tree elements in hierarchical structure. The ParseTree.Tokens property will contain all
the parsed tokens in a flat list.
Irony also provides a utility application to visualize the parse tree as a tree structure.
|9
Once the parse tree is generated from the source code script, we need to evaluate or execute the parse
tree based on a supplied domain model instance. This will in turn require evaluation of each node or term
in the parse tree. Since how each node would be evaluated depends on our language and domain, we
need to implement the evaluation logic for each non terminal node.
This custom evaluation logic is defined in the classes under the “Nodes“ folder of DSL.Sample.Language
project. Each of these custom nodes need to derive from Irony provided Irony.Interpreter.Ast.AstNode
class. In our case we have provided an intermediate class named BaseLeaveAstNode which derives from
AstNode and all the custom node classes are the subclass of this. This defines some application specific
common methods to be used by all custom node classes.
The AstNode class provides two virtual methods which are of importance to us:
Init: This gets invoked during the creation of parse tree as opposed to the evaluation of parse tree. The
parse tree node is one of the parameters to this which or whose attribute values can be stored
internally for usage during evaluation.
DoEvaluate: This gets invoked during the evaluation of the parse tree and accepts a parameter of type
ScriptThread through which any runtime data can be supplied. We can use the tree node attributes
cached in Init call to recursively call Evaluate of child nodes from this method.
Let’s now look an example of such custom node implementation. We can recall that we have defined a
non-terminal named “balance” which is intended to return the leave balance of an employee for a
particular leave type depending on the leave application being validated.
Following is the grammar definition of this element:
var balance = newNonTerminal("balance", typeof(BalanceNode)); //leave balance
balance.Rule = ToTerm("balance");
And following is the implementation of the “BalanceNode” class:
protectedoverrideobject DoEvaluate(ScriptThread thread)
{
base.DoEvaluate(thread);
varleaveBalances = GetDataContext(thread).Employee.LeaveBalances;
varleaveType = GetDataContext(thread).LeaveApplication.LeaveType;
returnleaveBalances != null&&leaveBalances.ContainsKey(leaveType) ? leaveBalances[leaveType] : 0;
}
The GetDataContext() method is defined in BaseLeaveAstNode class which returns an object of
LeaveValidationDataContext class that contains the Employee and LeaveApplication objects in question
and also exposes IsValidApplication property to be set by the parse tree evaluation.
As we can see, the BalanceNode’s DoEvaluate method returns the number of leave balances (or zero in
case not available) for the particular leave type from the Employee object’s LeaveBalances dictionary
property.
This balance value would in turn be used by higher level nodes in their own implementation of DoEvaluate
method.
| 10
Another example is of the BooelanExpressionNode which caches the child nodes in Init methods and then
uses those in DoEvaluate.
publicclassBoolExpressionNode : BaseLeaveAstNode
{
privateExpressionNodeleftNode;
privateExpressionNoderightNode;
privateBooleanOperatorNodeoperatorNode;
privateLeaveTypeKeywordNodeleaveTypeKeywordNode;
protectedoverrideobject DoEvaluate(ScriptThread thread)
{
base.DoEvaluate(thread);
if (leaveTypeKeywordNode != null)
{
returnleaveTypeKeywordNode.Evaluate(thread);
}
objectleftValue = leftNode.Evaluate(thread);
objectrightValue = rightNode.Evaluate(thread);
returnoperatorNode.Function(leftValue, rightValue);
}
publicoverridevoid Init(AstContext context, ParseTreeNodetreeNode)
{
base.Init(context, treeNode);
if (treeNode.ChildNodes.Exists(n =>n.Term.Name == "leavetypekeyword"))
{
leaveTypeKeywordNode = treeNode.ChildNodes.First(n =>n.Term.Name ==
"leavetypekeyword").AstNode asLeaveTypeKeywordNode;
}
else
{
leftNode = treeNode.ChildNodes[0].AstNode asExpressionNode;
rightNode = treeNode.ChildNodes[2].AstNode asExpressionNode;
operatorNode = treeNode.ChildNodes[1].AstNode asBooleanOperatorNode;
}
}
}
For evaluating a parse tree, we have to pass the domain objects. This can be passed via the ScriptThread
parameterin the AstNode.Evaluate() method. Following is the code for invoking parse tree evaluation:
LanguageDatalanguageData = newLanguageData(leaveValidationGrammar);
LanguageRuntime runtime = newLanguageRuntime(languageData);
ScriptApp app = newScriptApp(runtime);
ScriptThread thread = newScriptThread(app);
thread.App.Globals.Add("CONTEXT", context);
varastNode = parseTree.Root.AstNodeasAstNode;
| 11
if (astNode != null) astNode.Evaluate(thread);
The ScriptThread.App.Globals is a dictionary data structure where any arbitrary data can be stored and
this can be retrieved in the individual node’s DoEvaluate() method to access context sensitive data.
With all the code and infrastructure set, we can now proceed to test our DSL implementation using Visual
Studio unit tests. The LeaveValidationTests class of the unit tests project defines the unit test method to
test the DSL implementation. Consider the below unit tests method:
[TestMethod]
publicvoidTestLeaveApplicationInValidCasual()
{
Employeeemployee = CreateEmployeeData();
LeaveApplication application = newLeaveApplication();
application.Duration = 4;
application.LeaveType = LeaveType.Casual;
var context = newLeaveValidationDataContext(employee, application);
LeaveApplicationValidationProcessor.ProcessLeaveApplicationValidation(context, GetValidationScript());
Assert.IsFalse(context.IsValidApplication);
}
As per our business rule, casual leave duration cannot exceed 2 days. So in this case, the leave application
is invalid. That is why we are checking whether context.IsValidApplication is “false” in the assert
statement. If we run this unit test, it should pass.
Conclusion
In this article, we have discussed what are DSL and its basic concepts. Then we touched upon some
important computer science language theory concepts relevant to DSL. And finally we implemented an
external DSL for leave eligibility determination using .NET and Irony language implementation kit.
Although we have not implemented in our example, some of the essential features of any external DSL
should include:
Support for code comments
Support exception handling
Support for versioning the DSL
Logging and tracing in the parser
We hope this gives the reader a head start for considering external DSL implementation in their specific
domain using any .NET framework language.
Bibliography:
1. Domain Specific Language- Martin Fowler & Rebecca Parson
2. Software Architecture in Practice- Bass, Clements & Kazman
About the Author
Rajeswar Majumdar is an Architect in Time & Labor Management (TLM) product line at ADP India. He is
responsible for overall architecture and design of TLM products. He has over 11 years of experience in
architecture and design. He is a Certified Project Management Professional (PMP) and member of Project
Management Institute (PMI). He also worked with Cognizant Technology Solutions, India as ArchitectTechnology in Insurance and Vertical PriceWaterhouseCoopers as Principal Consultant in Technology
Consulting.
| 12
About ADP India
ADP India is a fully-owned subsidiary of Automatic Data Processing, Inc. (ADP) and is engaged in providing
Information Technology and Information Technology Enabled Services to ADP’s business divisions
worldwide. ADP Private Limited currently operates in world-class facilities located in Hyderabad and Pune,
providing over 8500 associates the opportunity to work on multiple processes, domains and technologies.
ADP India provides a complete range of product development services, technical support services and
solution center services that involve back office operations covering both voice and non-voice processes.