Simple Adjustments to Reduce Bias and Mean Squared Error
advertisement

Simple Adjustments to Reduce Bias and Mean Squared
Error Associated With Regression-Based Odds Ratio and
Relative Risk Estimators
by
Robert H. Lyles and Ying Guo
Technical Report 09-04
November 2009
Department of Biostatistics and Bioinformatics
Rollins School of Public Health
1518 Clifton Road, N.E.
Emory University
Atlanta, Georgia 30322
Telephone: (404) 727-1310 FAX: (404) 727-1370
e-mail: rlyles@emory.edu
Simple Adjustments to Reduce Bias and Mean Squared Error Associated
With Regression-Based Odds Ratio and Relative Risk Estimators
Robert H. Lyles and Ying Guo
Department of Biostatistics and Bioinformatics, The Rollins School of Public Health of Emory
University, 1518 Clifton Rd. N.E., Atlanta, GA 30322 (ph: 404-727-1310; fax: 404-727-1370; email: rlyles@sph.emory.edu)
Acknowledgements and Funding Support
R.H.L. was supported in part by NIEHS grant 2R01-ES012458-5. Y.G. was partially supported
under NIH grant R01-MH079448-01.
1
Abstract
In most practical situations, maximum likelihood estimators (MLEs) of regression coefficients
stemming from standard logistic, Poisson, and Cox proportional hazards models are reasonably
reliable in terms of their effective bias and approximate normal sampling distributions. While
this generally leads to satisfactory coverage properties for the usual normal theory-based
confidence intervals, a straightforward argument demonstrates that standard estimators of odds
ratios and relative risks obtained by direct exponentiation are biased upward in an explicitly
predictable way. This bias produces a propensity toward misleadingly large effect estimates in
practice. We propose correction factors that apply in the same manner to each of these regression
settings, such that the resulting estimators remain consistent and yield demonstrably reduced
bias, variability, and mean squared error. Our initial proposed estimator targets mean
unbiasedness in the traditional sense, while the usual exponential transformation-based MLE is
geared toward approximate median unbiasedness. We also propose a class of estimators that
provide reduced mean bias and squared error, while allowing the investigator to control the risk
of underestimating the true measure of effect. We discuss pros and cons of the usual estimator,
and use simulation studies and real-data examples to compare its properties to those of the
proposed alternatives.
Key Words: Bias; Odds ratio; Regression; Relative risk
2
Logistic, Poisson, and Cox proportional hazards regression are among the most
traditional and widely-used analytic techniques in many areas of research. Although useful for
prediction and other purposes, these models are most often applied with the primary aim of
estimating and making inferences about odds ratios or relative risks. Standard application of
these techniques takes advantage of unconditional, conditional, or partial likelihood methods,
yielding consistent estimators that support convenient inference based on asymptotically normal
sampling distributions. (1-3)
As is well known, traditional estimators of regression coefficients and resulting measures
of effect are not typically unbiased outside the linear model setting. Most prior research devoted
toward bias reduction tends to target bias on the regression coefficient scale that arises due to
small samples. For example, McCullagh(4) characterized the approximate bias in maximum
likelihood estimators of generalized linear model regression coefficients. Firth(5) proposed
penalized maximum likelihood to reduce such bias in logistic regression. King and Zeng(6)
describe bias-reduced estimators for probabilities based on logistic regression with rare events
data, and recommend using ratios of these to improve estimates of relative risk.
We present an approach aimed at bias reduction when estimating measures of effect in
logistic, Poisson, or Cox regression settings, among others. Almost any frequent user of these
statistical models has at times encountered suspiciously large odds or risk ratio estimates. We
argue that a tendency toward large point estimates results directly from the source of bias
addressed here, due to exponentiating estimated regression coefficients to transform to the
measure-of-effect scale. In fact, statisticians are well aware that upward bias can be induced by
exponentiation, since this follows as a direct consequence of Jensen’s inequality.(7) Our goal is to
demonstrate the nature and form of this bias, and to develop a class of reduced-bias estimators.
3
Our initial proposal targets mean unbiasedness, which inevitably requires a sacrifice of
the approximate median unbiasedness that is a property of standard exponential transformationbased estimators. As a result, more than 50% of the proposed bias-corrected estimates would be
expected to fall below the true odds or risk ratio upon repeated sampling from a study
population. As a compromise, we also introduce bias-reduced estimators that provide mean bias,
precision, and mean squared error (MSE) benefits while directly controlling the probability of
underestimating a true measure of effect.
The focus of this article differs from that of previous work, in the following respects.
First, we directly target bias in estimated odds ratios and relative risks, as opposed to bias in
estimated regression coefficients, because it is on the former scale that researchers generally
report and interpret estimates. Thus, a strong case can be made in favor of the view that classical
estimation criteria (mean bias, variability, MSE) remain particularly relevant on that scale.
Second, we assume the investigator is working in a scenario in which sampling anomalies [e.g.,
the separation problem in logistic regression(9)] are rare, there is relatively little bias in the usual
regression coefficient estimators, and in which the typical normal approximations for their
sampling distributions are reasonably adequate. This assumption is defensible in many realworld applications assuming appropriate models and well-designed studies.
Our proposal encourages thought about the merits of seeking mean versus median
unbiasedness on the measure-of-effect scale, while offering alternatives when the former is
deemed desirable and/or a compromise between these two performance measures is sought. We
believe that the specific relevance of this distinction to standard regression settings is not widely
recognized, and that most analysts naturally tend to associate the criterion of bias with the
traditional view. Practicing statisticians and investigators who commonly apply these standard
4
regression models may be surprised at the potential extent to which the usual odds and risk ratio
estimators sacrifice unbiasedness, precision, and MSE.
METHODS
Bias-Corrected Point Estimation
We focus on the wide variety of problems in which an estimate of effect [e.g., an odds
ratio (OR) or relative risk (RR)] is typically obtained by exponentiating an estimator whose
sampling distribution is asymptotically normal. This includes fundamental problems based on
2×2 tables(10) and potentially extends to modeling exercises for longitudinal or otherwise
correlated data.(11-13) However, we restrict attention here to traditional models for data obtained
under independence of experimental units, e.g., logistic, Poisson, or Cox models,(1-3) where the
estimators to be exponentiated correspond to regression coefficients. Thus, we consider the
models
k
g[E(Y | X x)] β 0 β j x j
j 1
,
(1)
where the logit or log link functions g(.) are standard for logistic or Poisson regression,
respectively, or
k
ln[h(t | X x)] ln[h 0 (t)] β j x j
j 1
,
(2)
where h(.) and h0(.) represent the hazard and baseline hazard functions in Cox regression.
When making inference about an OR or RR [say, ψj = exp(βj)] based on model (1) or (2),
we typically make use of the following standard asymptotic result pertaining to the sampling
distribution of a maximum likelihood (ML) or partial ML estimator:
β̂ j ~ N(β j , σ 2j )
5
,
(3)
where σ 2j represents the variance of β̂ j across repeated samples. The estimator routinely
employed is the MLE for the desired measure of effect, i.e.,
ψ̂ j e
β̂ j
(j=1,…, k)
(4)
Aside from the implications of Jensen’s inequality and the potential for ψ̂ j in equation
(4) to fail to exist (or “blow up”) due to rare sampling outcomes,(9) it is easy to show that this
standard estimator has a fundamental built-in tendency toward positive bias. In particular, the
distributional result in equation (3) dictates that the sampling distribution of ψ̂ j is approximately
lognormal such that
E(ψ̂ j ) e
β j σ 2j / 2
(5)
We note that expression (5) may also be derived via Taylor series arguments given that
E(β̂ j ) β j , without the assumption of normality for β̂ j . Although in large samples the
sampling variability ( σ 2j ) tends to zero so that ψ̂ j is consistent, this standard estimator is clearly
biased upward in practice. In particular, ψ̂ j is geared toward median unbiasedness(14) rather than
mean unbiasedness, as the median of the approximate lognormal sampling distribution is e
βj
but
the mean is larger. This fact is also clear from the symmetry of the approximate normal
distribution for β̂ j , which is (approximately) both mean and median unbiased. The implication is
that the traditional estimator ψ̂ j is essentially equally likely to over- or underestimate the true
measure of effect across repeated samples, but can be subject to overestimation errors of very
large magnitude. These errors might be viewed as especially detrimental given the emphasis
6
(e.g, in epidemiology) often placed on interpreting measure-of-effect point estimates.
Figure 1 is a plot of the bias factor (e
σ 2j / 2
) against j, the standard deviation of the
normal sampling distribution associated with β̂ j . Note that the bias is minimal for small values
of j, but quickly increases. The expectation of ψ̂ j will be approximately 150%, 200%, and
300% of the true ψj if j = 0.9, 1.2, and 1.5, respectively.
To approximately eliminate the positive bias of ψ̂ j , we propose the following
straightforward “corrected” estimator based on expression (5):
ψ̂ j, corr = e
σ̂ 2j / 2
ψ̂ j ,
(6)
where σ̂ 2j is the square of the estimated standard error associated with β̂ j when fitting model (1)
or (2). The estimator in (6) remains consistent, and should be preferred to the standard estimator
if one values the ideal of traditional as opposed to median unbiasedness. Because the bias
indicated in expression (5) is always positive, the proposed correction reduces the point estimate
regardless of whether the standard estimate ψ̂ j is greater than or less than one.
One criticism of (6) might be that it incorporates exponentiation of the term σ̂ 2j / 2 , thus
arguably introducing some bias of a similar nature to that originally targeted. While
corresponding adjustments to (6) could be contemplated, we maintain that this source of bias is
generally ignorable because the sampling variability of σ̂ 2j tends to be very small (much smaller
than that of β̂ j itself). Our empirical studies have been uniformly consistent with this view,
leading us to favor the simple adjustment in (6).
The result in (5) has some connection with what has been termed the “retransformation”
7
problem. For example, if one fits a linear regression model to a log-transformed dependent
variable (Y) assuming i.i.d. normal errors, the expectation of Y will clearly involve a
2
multiplicative factor of the form e σ / 2 . There has been extensive discussion in the literature
about the problem of correctly estimating E(Y) in such situations, with and without direct
specification of the transformation or the distributional form of the errors.(15-16) Major
distinctions in the current application are that the result in (5) applies to the sampling distribution
of β̂ j rather than to the distribution of Y, it is inherently robust due to well-established large
sample theory, and it is used here toward the estimation of measures of effect (i.e., ORs, RRs)
rather than E(Y).
Bias-Reduced Estimators Controlling the Risk of Underestimation
The estimator in (6) is designed to produce minimal traditional (mean) bias, given that
the normal approximation (3) is reasonable. It is asymptotically equivalent to the usual ML
estimator, but is virtually guaranteed to yield lower sampling variability in practice because it
multiplies by a correction factor constrained between 0 and 1. Naturally, these reductions in bias
and variability also imply reduced MSE. The benefits in these three well-emphasized estimation
criteria are made at the expense of sacrificing the approximate median unbiasedness that
characterizes the usual point estimator ψ̂ j . Thus, while it is appealing to achieve potentially
substantial reductions in mean bias, variance, and squared error, one may be reluctant to admit a
drastic departure from median unbiasedness.
The approximate lognormal distribution characterizing ψ̂ j readily allows us to
contemplate a class of estimators permitting access to some of the benefits inherent in the biascorrected estimator (6), while exerting targeted control over the extent to which median
8
unbiasedness is forfeited. In this direction, note that (3) implies that
Pr(ψ̂ j, corr e
βj
) Φ(σ j / 2) ,
(7)
where Φ(.) represents the standard normal cumulative distribution function. Thus, in practice
Φ(σ̂ j / 2) , which always exceeds 0.5, provides a reasonable estimate of the probability that the
use of ψ̂ j, corr would underestimate the true measure of effect. Larger values of σ̂ j imply more
upward bias in ψ̂ j and a consequently larger downward adjustment via ψ̂ j, corr . This in turn
suggests that ψ̂ j, corr will deviate more markedly from median unbiasedness; i.e., the probability
in (7) may be substantially greater than 0.5.
To control this risk of underestimation, consider an estimator of the form ψ̂ j, p e c ψ̂ j
for some constant c and specified probability p ( 0.5) and suppose we wish to ensure that
Pr(ψ̂ j, p ψ j ) p . Here, (3) implies that c = jzp, where zp is the 100p-th percentile of the
standard normal distribution. This leads to a class of estimators, i.e.,
ψ̂ j, p e
σ̂ j z p
ψ̂ j ,
where consistency is maintained regardless of the value chosen for p. To maximize potential
improvements in mean bias and squared error while controlling the risk of underestimating j,
we propose the following bias-reduced estimator:
ψ̂ *j,corr max(ψ̂ j,corr , ψ̂ j,p ) ,
(8)
with p judiciously selected by the investigator.
For example, one who is unwilling to make any concession of median unbiasedness takes
p=0.5, so that ψ̂*j, corr ψ̂ j,.50 ψ̂ j , the usual estimator. On the other hand, suppose one is
9
willing to tolerate approximately a 60% chance of underestimating the true effect in return for
gains in bias, efficiency, and MSE. Then p=0.6 yields ψ̂ *j, corr max(e
σ̂ 2j / 2
ψ̂ j , e
σ̂ j z .60
ψ̂ j ) ,
where z.60=0.253. It is readily seen that (8) is equivalent to
ψ̂*j, corr
ψ̂
j, corr if σ̂ j 2 z p
otherwise
ψ̂ j, p
Thus, the bias-reduced estimator targets a full bias correction as in (6) as long as σ̂ j 2 z p ;
otherwise, it tempers the bias correction factor to a degree commensurate with the probability (p)
of underestimation that is deemed acceptable. The latter approach still promises mean bias,
precision, and squared error improvements over ψ̂ j , albeit not to the full extent available via (6).
Notes Regarding Interval Estimation and Invariance
It is important to note that our proposals are geared toward point estimation on the OR or
RR scale, and imply no adjustments to the usual regression coefficient estimate ( β̂ j ) or its
standard error. That is, we would follow standard practice if reporting an estimate on the log
scale, but use the correction factors in (6) or (8) to address the bias introduced due to
exponentiating β̂ j before reporting or interpreting the estimate on the natural scale. As the
proposed estimators are predicated on the normal approximation (3), they also imply no direct
argument against the confidence interval that typically accompanies ψ̂ j in (4), obtained by
exponentiating the following bounds:
β̂ j z1 α/ 2 σ̂ j
,
(9)
where σ̂ j is the usual standard error estimate. We focus on typical settings in which this interval
10
should provide acceptable performance, and where alternative intervals such as those based on
likelihood ratios17 would be expected to perform similarly. Point estimates based on (6) or (8)
will simply be shifted further to the left within these intervals.
We note in passing that an argument almost identical to that underlying (5) accurately
predicts that the usual upper and lower limits obtained by exponentiating the bounds in (9) will
be biased upward for the true population percentiles (e
β j z1 α/ 2 σ j
) that they purport to estimate.
This tendency, most pronounced for the upper limit, can contribute to exceedingly wide intervals
in the same way that such bias can produce excessively large point estimates. An adjustment
similar to that in (6) can be made to nearly eliminate this bias as well. However, we find that
attempts to take advantage of the resulting bias-corrected upper and lower limit estimators to
yield narrower average interval widths require sacrifices in confidence interval coverage balance,
as the adjusted interval is necessarily shifted to the left. In our opinion, the forfeiture of coverage
balance is much harder to justify than, for example, some sacrifice of median unbiasedness with
respect to point estimation.
If a covariate Xj is binary, then it is well known that the MLE ( ψ̂ j ) for the OR or RR
possesses a certain invariance to coding changes. For example, if the coding of Xj is switched
from (0,1) to (1,0), then the MLE for βj changes sign and ψ̂ j is correspondingly inverted. In the
case of logistic regression, such inversion occurs regardless of the nature of the covariate Xj if
the coding of the outcome Y changes, e.g., from (0,1) to (1,0). Importantly, this type of
invariance is not a property of the bias-corrected estimator (6), or of the bias-reduced estimator
(8). In other words, neither ψ̂ j, corr nor ψ̂*j, corr should be inverted to obtain an estimate of j
upon recoding of a covariate or outcome. Doing so would produce an estimator that is no longer
11
bias-corrected on the inverted scale (and in fact more biased on that scale than the usual MLE),
thus negating the purpose of the estimation method. The proper approach when using (6) or (8) is
to compute the corresponding point estimates directly after first selecting the scale for reporting.
SIMULATION STUDIES
Tables 1-3 summarize simulation experiments examining the proposed point estimators,
with 5,000 independent replications generated in each scenario. In the case of logistic regression,
we simulated three covariates as follows: X1 ~ N(0, 0.22), X2 ~ Bernoulli(p), and X3 ~
Uniform(0, 0.5). X3 was generated independently of X1 and X2, but we introduced correlation
between X1 and X2 by taking p=0.15 in the event that X1 > 0 and p=0.85 in the event that X1 < 0.
For simulations under Poisson regression, data were generated under model (1) with a log link
and the covariate distributions remained the same except with X1 ~ N(0, 0.12) and X3 ~
Uniform(0, 0.25). For Cox regression, we generated survival times with constant baseline
hazard, 33% random censoring, and the same covariate distributions used for the Poisson
regression simulations. The parameters 1, 2, and 3 were set as 2, 1, and 0.5, corresponding to
ORs or RRs of 1=7.39, 2=2.72, and 3=0.61. Assumed sample sizes varied somewhat
depending on the model considered (n=200, 100, and 250 for logistic, Poisson, and Cox
regression, respectively). These sampling conditions produced similar average standard errors for
the MLEs of the regression coefficients under each type of model, with those corresponding to
X1 and X3 large enough to illustrate the potential for marked differences between the standard
and proposed bias-corrected and bias-reduced estimators.
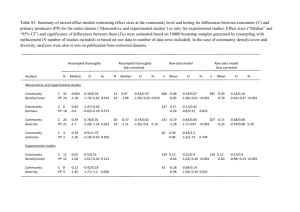
The second column of Table 1 illustrates minimal empirical bias in the MLEs of the
logistic regression coefficients ( β̂ ). However, the positive mean bias of the standard OR
estimators obtained via exponentiation is quite marked, especially for those corresponding to
12
larger sampling variances (i.e., for ψ̂1 and ψ̂ 3 ). In particular, the mean of ψ̂1 (7.39+6.04=13.43)
across the 5,000 simulations is nearly double the true value of 7.39, while the mean for ψ̂ 3
(0.61+0.45=1.06) is actually on the wrong side of the null despite a sample size of 200. In
contrast, we see dramatically reduced bias associated with the corrected estimator ( ψ̂ corr )
proposed in equation (6). In fact, most of the remaining positive bias in ψ̂1,corr is attributable to
the slight positive small-sample bias associated with β̂1 .
As expected, the standard OR estimator comes close to achieving median unbiasedness,
while the proposed bias-corrected estimator approaches mean unbiasedness. In the case of 1,
the proportion of estimates falling below the true OR of 7.39 was 48% for the usual MLE, as
compared with 66% for ψ̂1,corr . The right-most column summarizes the performance of the
alternative estimator ψ̂1*, corr in eqn. (8), where we take p=0.6. This estimator provides a clear
compromise between ψ̂1 and ψ̂1,corr in terms of mean and median bias. Note that the method is
quite effective at controlling the percentage of estimates falling below the true value of 1 at a
level less than or approximately equal to the desired threshold of 60%.
Conclusions in the case of 3 are very similar to what we see with 1, despite the
negative value of β3; that is, mean bias and MSE are dramatically reduced for ψ̂ 3, corr relative to
ψ̂ 3 , while a compromise that controls the resulting median bias via p=0.60 meets the desired
objective and provides an effective intermediate. In the case of 2, the average standard error of
approximately 0.38 is small enough that there is relatively little difference between ψ̂ 2 and
ψ̂ 2, corr , and the slight median bias incurred with ψ̂ 2, corr produces no distinction between
13
ψ̂ 2, corr and ψ̂*2, corr in any of the 5,000 replications (i.e., in this case one can directly target
mean unbiasedness without inducing median unbiasedness beyond the tolerated level).
We note that the simulation results agree remarkably well with the approximate result in
(7). For example, in Table 1 we find the following empirical estimates: σ̂1 0.98, σ̂ 2 0.38,
and σ̂ 3 1.07 . Inserting these into the calculation Φ(σ̂ j / 2) suggests that 69%, 58%, and 70%
of the estimates based on ψ̂1, corr , ψ̂ 2, corr , and ψ̂ 3, corr , respectively, should fall below the true
ORs. These closely match the observed percentages of 66%, 56%, and 70% in Table 1, also
suggesting that Φ(σ̂ j / 2) provides a reasonable estimate of the probability of underestimation
when using the bias-corrected estimator (6) in practice.
The results in Table 2 (Poisson regression) and Table 3 (Cox regression) are qualitatively
very similar to those in Table 1, as were simulation results under a variety of other conditions
(not shown). As in Tables 1-3, these experiments continued to confirm what is clear from
equation (5), i.e., that the magnitude of positive bias associated with the standard estimator of j
and the extent of the adjustments implemented via (6) or (8) depend upon the average standard
error associated with β̂ j .
Figure 2 compares histograms representing 4,000 standard and bias-corrected OR
estimates ( ψ̂ 3 and ψ̂ 3, corr ) based on a replication of the simulation study summarized in Table
1, where vertical lines mark the true OR of 0.61. Note the longer and heavier tail associated with
the histogram of standard estimates, yielding an empirical mean of 1.06. In contrast, the mean of
the 4,000 corrected estimates was 0.61, identical to the true OR. A plot comparing histograms for
ψ̂1 and ψ̂1, corr was almost identical visually.
14
The proposed bias-corrected and bias-reduced estimators offer remarkable improvements
in mean squared error (MSE), due to the dual benefits of reduced bias and reduced variation in
the point estimate. For example, Table 1 reflects simulation-based MSE estimates of 413.81 and
2.55 for ψ̂1 and ψ̂ 3 , respectively. Contrasting these with the values of 101.42 and 0.76 for
ψ̂1, corr and ψ̂ 3, corr produces MSE efficiency estimates of only 25% and 30% when comparing
*
the traditional to the bias-corrected OR estimator [eqn. (6)]. The estimated MSEs for ψ̂1,
corr and
ψ̂*3, corr are 219.24 and 1.42, respectively, suggesting that the MLEs are only 53% and 56% MSE
efficient relative to an estimator [eqn. (8)] that maintains a controlled and tolerable level of
median bias. Tables 1-3 provide corresponding estimates for all simulation scenarios, further
confirming substantial mean bias, precision, and MSE advantages of the proposed estimators.
EXAMPLE
Birth Weight Data
As a practical example, we analyze publicly available data from a well-known study of
low birth weight. Data on 189 births recorded at Baystate Medical Center in Massachusetts were
altered by the authors of the source text(8) to protect confidentiality. For this example, we restrict
attention to 100 births for which the mother required no first-trimester physician visits. The
binary outcome characterizes birth weight (1 if 2500 g, 0 if < 2500 g), and we consider two
covariates: the natural log of the mother’s weight at her last menstrual period (logLWT), and the
mother’s history (HX) of premature labor (1 if any, 0 if none).
Table 4 displays estimates of the adjusted ORs for logLWT and HX. Note particularly in
the case of logLWT that the large positive regression parameter and its sizable standard error
yield a remarkably high estimated OR of 6.02 based on standard methods. The bias-corrected OR
15
estimate [eqn. (6)] of 3.29 is reduced substantially (by 45%) relative to the usual MLE. Based on
the estimated standard error of 1.10, however, the approximation in (7) suggests that
approximately 71% of repeated samples from this population would yield a bias-corrected
estimate for logLWT that falls below the true OR. The right-most column of Table 4 provides
the bias-reduced estimate [eqn. (8)], upon limiting this percentage to the more moderate value of
approximately 60%. The resulting estimate of 4.56 is also based on a method that reduces mean
bias and MSE, but reflects a tempered adjustment to limit the extent to which median
unbiasedness is sacrificed. In the case of the second covariate (HX), the bias-corrected and biasreduced estimates ( ψ̂ corr and ψ̂*corr , respectively) agree with each other to two decimal places
based on eqn. (8), and are not dramatically different from the standard OR estimate.
Additional Simulations to Mimic Example
While the previous simulation studies demonstrate the properties of the bias-corrected
and bias-reduced estimators in three different settings (logistic, Poisson, and Cox regression),
those settings were selected for illustration as opposed to being based on real motivating data. It
is thus informative to repeat the exercise under conditions similar to those in the low birth weight
example. For the simulation studies summarized in Table 5, covariate data on “log(LWT)” and
“HX of pre-term labor” were generated so as to closely mimic their observed joint distribution in
the example data set consisting of 100 subjects. The outcome was generated based on a logistic
regression of “high birth weight” on log(LWT) and HX, with adjusted ORs matching the biascorrected estimates (3.29 and 0.14, respectively) from the example (see Table 4).
Results given in the top half of Table 5 are based on 5,000 simulated data sets, each of
sample size 100 as in the example. The performances of the three adjusted OR estimators
corresponding to log(LWT) continue to follow the general patterns seen in Tables 1-3.
16
Specifically, substantial positive bias is seen to be associated with ψ̂ , corresponding to an
average estimate of (3.29+6.95)= 10.24. This standard OR estimator also displays extreme
variability and empirical MSE, but minimal median bias as expected. The bias-corrected
estimator ( ψ̂ corr ) nearly eliminates the mean bias and provides drastically reduced variability
and MSE, at the expense of downward median bias. The bias-reduced estimate ( ψ̂*corr ) fits
nicely between the other two, while maintaining the risk of underestimating the true OR at or
near the specified level of 60%. These general features are maintained upon increasing the
sample size to 200 (lower half of Table 5), despite the expected overall reductions in bias,
variability, and MSE. The three estimators perform much more similarly in the case of the “HX”
variable, though overall impressions remain the same.
DISCUSSION
We have presented a straightforward and readily justified approach to reducing bias when
estimating common measures of effect (i.e., odds ratios, relative risks) based on regression
analysis. In contrast to most prior research on bias reduction due to small or aberrant samples,(2;
4-6)
our approach is geared toward the common scenario in which the usual normal asymptotics
associated with regression coefficient estimators are deemed to provide a reasonable
approximation. We believe our proposal is unique relative to prior work in terms of the
simplicity and ease of use characterizing the suggested estimators, as well as the magnitude of
their impact upon bias, variability and MSE on the measure-of-effect scale.
Our conclusions regarding the standard estimator ( ψ̂ j e
β̂ j
) may be summarized in
terms of a list of pros and cons relative to the alternatives in (6) and (8). On the plus side, ψ̂ j is
familiar and convenient, and achieves approximate median unbiasedness. It is also an ML
17
estimator, thus possessing familiar desirable asymptotic properties as well as transformation
invariance characteristics (e.g., 1 /ψ̂ j is the MLE for 1 /ψ j ). The proposed alternative estimators
are comparable in terms of ease of computation, and they share the same asymptotic properties
as the MLE but lack the invariance property under typical sample sizes. On the other hand, ψ̂ j is
subject to guaranteed and potentially extreme positive (mean) bias in practice. Its sampling
variability is certain to be higher than that of the proposed alternative estimators. It follows that
ψ̂ j will also carry a higher MSE, often markedly, given its relative deficiencies in terms of both
bias and variability (see Tables 1-3 for illustration).
The key result in equation (5) clarifies the explicit form of the positive bias characterizing
ψ̂ j , and the manner in which it sacrifices traditional mean unbiasedness in favor of median
unbiasedness. In our view, the median unbiasedness criterion has the disadvantage of ignoring
the magnitude of extreme estimates in the sampling distribution, thus producing an incomplete
and perhaps misleading performance measure for an estimator.
We also note that the question of invariance holds further relevance for grasping the
relative merits of the standard estimator as opposed to the proposed alternatives. Because of the
invariance of the MLE and because ORs and RRs are ratio measures, for example, one may be
prone to view a hypothetical point estimate that doubles the true value and one that halves it as
equally erroneous. However, one can argue that the statistical criteria upon which we focus (bias,
variability, MSE) do not lose their relevance simply because we are dealing with a ratio measure.
These objective criteria do not view such proportionality errors as equivalent, but rather tend to
give equal weight to equivalent additive deviations from the true value on the measure-of-effect
scale. Doing so provides protection against the large errors in estimation that come into play due
to the right-skewed sampling distribution on that scale.
18
When standard errors are large, eqn. (7) suggests that the bias-corrected estimator (6)
may require a substantial deviation from median unbiasedness in order to achieve approximate
mean unbiasedness. The plug-in estimator Φ(σ̂ j / 2) provides a convenient way to assess the
extent of such sacrifice. Concern over this may make the class of estimators in (8) particularly
appealing, because they permit the investigator to exert explicit control over the approximate risk
of underestimating true measures of effect in practice. Our example and simulation studies
demonstrate that marked gains in mean bias, variability, and MSE efficiency can still be
obtainable when tolerating only a moderate forfeiture of median unbiasedness. The fact that clear
improvements in these important estimation criteria are so readily available is eye-opening, and
could be quite valuable. We believe that the OR (or RR) scale is an appropriate one upon which
to seek them, given that it is so commonly the scale of reporting and interpretation in research
that relies on these types of regression analysis.
19
REFERENCES
1. Cox DR, Oakes D. Analysis of survival data. London: Chapman & Hall, 1984.
2. McCullagh P, Nelder JA. Generalized linear models, 2nd edition. New York:
Chapman & Hall, 1989.
3. Agresti A. Categorical data analysis, 2nd edition. New York: John Wiley & Sons, 2002.
4. McCullagh P. Tensor methods in statistics. London: Chapman & Hall, 1987.
5. Firth D. Bias reduction of maximum likelihood estimates. Biometrika 1993;80:27-38.
6. King G, Zeng L. Logistic regression in rare events data. Political Analysis 2001;9:137163.
7. Jensen JLWV. Sur les fonctions convexes et les inégalités entre les valeurs moyennes. Acta
Mathematica 1906;30:175-193.
8. Hosmer DW, Lemeshow S. Applied logistic regression, second edition. New
York: John Wiley & Sons, 2000.
9. Allison PD. Convergence problems in logistic regression. In Numerical Issues in
Statistical Computing for the Social Scientist (Altman, M., Gill, J., and McDonald, M.P.,
eds.). Hoboken, NJ: John Wiley & Sons, 2004 (pp. 238-252).
10. Rosner B. Fundamentals of biostatistics, 5th edition. Pacific Grove, CA: Duxbury, 2000.
11. Molenberghs G, Verbeke G. Models for discrete longitudinal data. New York:
Springer-Verlag, 2005.
12. Davidian M, Giltinan DM. Nonlinear models for repeated measurement data.
New York: Chapman & Hall, 1995.
13. Liang K-Y, Zeger SL. Longitudinal data analysis using generalized linear models.
Biometrika 1986;73:13-22.
14. Read CB. Median unbiased estimators. In Encyclopedia of Statistical Sciences, Volume 5
(Kotz, S. and Johnson, N.L., eds.). New York: John Wiley & Sons, 1985 (pp. 424-426).
15. Duan N. Smearing estimate: A nonparametric retransformation method. Journal of the
American Statistical Association 1983;79:605-610.
16. Manning WG. The logged dependent variable, heteroscedasticity, and the retransformation
problem. Journal of Health Economics 1998;17:283-295.
20
17. Venzon DJ, Moolgavkar SH. A method for computing profile-likelihood based confidence
intervals. Applied Statistics 1988;37:87-94.
*
†
‡
¶
Table 1. Simulation Results: Logistic Regression*
Performance of Estimators:
Mean Bias [Median Bias]
(SD)
{Empirical MSE}
Percentage of estimates < true value
β̂
ψ̂ corr ‡
ψ̂ †
Variable
ψ̂*corr ¶
Mean (SD)
6.04 [0.51]
0.60 [2.36] 2.99 [1.17]
X1
(19.42)
(10.05)
(14.50)
2.09 (0.98)
{413.81}
{101.42}
{219.24}
(1=2, 1=7.39)
48%
66%
58%
0.31 [0.06]
0.09 [0.14] 0.09 [0.14]
X2
(1.26)
(1.15)
(1.15)
1.03 (0.38)
{1.69}
{1.33}
{1.33}
(2=1, 2=2.72)
48%
56%
56%
0.45 [0.01]
0.00 [0.26] 0.20 [0.15]
X3
(1.53)
(0.87)
(1.17)
0.51 (1.07)
{2.55}
{0.76}
{1.42}
(3=.5, 3=0.61)
51%
70%
60%
Based on 5,000 replications with n=200 in each case; Covariate distributions described in text
Usual MLE for adjusted OR
Bias-corrected estimate [eqn. (6)]
Bias-reduced estimate [eqn. (8)]; Using p=0.60 to limit proportion of estimates falling
below true RR to approximately 60% or less
21
*
†
‡
¶
Table 2. Simulation Results: Poisson Regression*
Performance of Estimators:
Mean Bias [Median Bias]
(SD)
{Empirical MSE}
Percentage of estimates < true value
β̂
ψ̂ corr ‡
ψ̂ †
Variable
ψ̂*corr ¶
Mean (SD)
0.19 [2.73] 1.56 [1.67]
4.01 [0.08]
X1
1.99
(14.00)
(8.32)
(10.78)
(0.94)
{212.18}
{69.24}
{118.60}
(1=2, 1=7.39)
51%
68%
61%
0.07 [0.00]
0.02 [0.05]
0.02 [0.05]
X2
1.01
(0.57)
(0.56)
(0.56)
{0.34}
(0.20)
{0.31}
{0.31}
(2=1, 2=2.72)
50%
53%
53%
0.51 [0.00]
0.24 [0.15]
0.00 [0.27]
X3
(1.94)
(1.02)
(1.46)
0.49
{4.02}
(1.09)
{1.05}
{2.18}
(3=.5, 3=0.61)
50%
71%
60%
Based on 5,000 replications with n=100 in each case; Covariate distributions described in text
Usual MLE for adjusted OR
Bias-corrected estimate [eqn. (6)]
Bias-reduced estimate [eqn. (8)]; Using p=0.60 to limit proportion of estimates falling
below true RR to approximately 60% or less
22
*
†
‡
¶
Table 3. Simulation Results: Cox Regression*
Performance of Estimators:
Mean Bias [Median Bias]
(SD)
{Empirical MSE}
Percentage of estimates < true value
β̂
ψ̂ corr ‡
ψ̂ †
Variable
ψ̂*corr ¶
Mean (SD)
4.21 [0.08]
1.78 [1.44]
0.14 [2.44]
X1
2.01
(14.68)
(9.17)
(11.47)
(0.93)
{233.09}
{84.02}
{134.75}
(1=2, 1=7.39)
49%
67%
59%
0.08 [0.02]
0.03 [0.03]
0.03 [0.03]
X2
1.01
(0.54)
(0.53)
(0.53)
{0.30}
(0.19)
{0.28}
{0.28}
(2=1, 2=2.72)
48%
52%
52%
0.47 [0.00]
0.22 [0.14]
0.02 [0.25]
X3
(1.53)
(0.88)
(1.18)
0.48
{2.57}
(1.04)
{0.78}
{1.43}
(3=.5, 3=0.61)
50%
69%
59%
Based on 5,000 replications with n=250 in each case; Covariate distributions described in text
Usual MLE for adjusted OR
Bias-corrected estimate [eqn. (6)]
Bias-reduced estimate [eqn. (8)]; Using p=0.60 to limit proportion of estimates falling
below true RR to approximately 60% or less
23
*
†
‡
¶
Table 4. Logistic Regression: Analysis of Birth Weight Data*
Point Estimates
β̂
ψ̂ corr ‡
ψ̂ †
Variable
ψ̂*corr ¶
(SE)
1.80
logLWT
6.02
3.29
4.56
(1.10)
HX premature
1.77
0.17
0.14
0.14
labor
(0.64)
Data from Hosmer and Lemeshow,8 restricting to mothers with no first trimester
physician visits (N=100); OR for one-unit increase in logLWT
Usual MLE for adjusted OR
Bias-corrected estimate [eqn. (6)]
Bias-reduced estimate [eqn. (8)]; Using p=0.60 to limit proportion of estimates falling
below true RR to approximately 60% or less
24
Table 5. Simulation Results Mimicking Low Birth Weight Example *
Performance of Estimators:
Mean Bias [Median Bias]
(SD)
{Empirical MSE}
Percentage of estimates < true value
Sample
β̂
ψ̂ corr ‡
ψ̂ †
Variable
ψ̂*corr ¶
size (n)
Mean (SD)
6.95 [0.14]
0.18 [1.76] 3.73 [0.77]
logLWT
1.26
(34.66)
(7.58)
(21.99)
(1.36)
{1249.80}
{57.48}
{497.23}
(1=1.19, 1=3.29)
49%
72%
58%
100
0.02 [0.02]
0.01 [0.03] 0.00 [0.03]
HX premature labor
(0.12)
(0.09)
(0.10)
2.07
{0.02}
(0.82)
{0.01}
{0.01}
(2=1.97, 2=0.14)
54%
65%
63%
Sample
β̂
ψ̂ corr ‡
ψ̂ †
Variable
ψ̂*corr ¶
size (n)
Mean (SD)
1.94 [0.08]
0.14 [0.91] 0.86 [0.59]
logLWT
1.22
(6.62)
(3.90)
(5.09)
(0.91)
{47.59}
{15.21}
{26.66}
(1=1.19, 1=3.29)
49%
66%
58%
200
0.01 [0.00]
0.00 [0.02] 0.00 [0.02]
HX premature labor
(0.07)
(0.07)
(0.07)
2.00
{0.006}
(0.46)
{0.004}
{0.004}
(2=1.97, 2=0.14)
53%
61%
61%
* Based on 5,000 replications in each case; Covariate distributions described in text
† Usual MLE for adjusted OR
‡ Bias-corrected estimate [eqn. (6)]
¶ Bias-reduced estimate [eqn. (8)]; Using p=0.60 to limit proportion of estimates falling
below true RR to approximately 60% or less
25
Figure Legends:
Figure 1. Plot of the bias factor (e
σ 2j / 2
) characterizing the usual estimator e
β̂ j
, versus the
standard deviation (j) of the approximate sampling distribution of β̂ j .
Figure 2. Histograms of 4,000 standard and bias-corrected estimates ( ψ̂ 3 and ψ̂ 3, corr ), based on
repeating the simulation study summarized in Table 1. Normal kernel density estimates
accompany each histogram. The mean of the standard estimates is 1.06, markedly exceeding the
true OR of 0.61. The mean of the corrected estimates is 0.61.
26
Fig. 1: Plot of Bias Factor vs. j
Bias Factor
3.0
2.5
2.0
1.5
1.0
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Sigma
27
1.0
1.1
1.2
1.3
1.4
1.5
Fig. 2: Histograms of Standard and Bias-Corrected Estimates
28