A Pipeline Fast Fourier Transform
advertisement

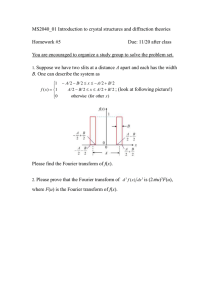
1015 IEEE TRANSACTIONS ON COMPUTERS, VOL. C-19, NO. 11, NOVEMBER 1970 [7] [81 [9] [10] [11] [12] [13] experiments with recorded text as a cornmunication media," 1964 Fall Joint Computer Conf., AFIPS Proc., vol. 27, pt. 1. Washington, D. C.: Spartan, 1965, pp. 399-411. D. C. Engelbart and W. K. English, "A research center for augmenting human intellect," 1968 Fall Joint Computer Conf., AFIPS Proc., vol. 33, pt. 1. Washington, D. C.: Thompson, 1968, pp. 395-410. T. H. Kehl and C. Moss, "Systems programming on-line," Computers and Biomed. Res., vol. 1, pp. 550-555, June 1968. H. Bratman, H. G. Martin, and E. C. Perstein, "Program composition and editing with an on-line display," 1968 Fall Joint Computer Conf., AFIPS Proc., vol. 33, pt. 2. Washington, D. C.: Thompson, 1968, pp. 1349-1360. B. Tolliver, "TVEDIT," Stanford University, Palo Alto, Calif., Stanford Time-Sharing Memo. 32, March 1965. J. McCarthy, D. Brian, G. Feldman, and J. Allen, "THOR-A display based time sharing system," 1967 Spring Joint Computer Conf., AFIPS Proc., vol. 30. Washington, D. C.: Thompson, 1967, pp. 623-633. M. A. Wilkes, LAP3 Users' Manual, Massachusetts Institute of Technology, Cambridge, Mass., Center Development Office Rept., August 1963. , "LAP5: LINC assembly program," Proc. DECUS Spring A [14] [15] [16] [17] [18] [19] [20] Symp. Maynard, Mass.: Digital Equipment Corp., 1966, pp. 43-50. W. A. Clark and C. E. Molnar, "A description of the LINC," in Computers in Biomedical Research, vol. 2, R. W. Stacy and B. Waxman, Eds. New York: Academic Press, 1965, pp. 35-66. R. L. Best and T. C. Stockebrand, "A computer-integrated rapidaccess magnetic tape system with fixed address," 1958 Proc. Western Joint Computer Conf. New York: American Institute of Electrical Engineers, 1959, pp. 42-46. T. Kilburn, R. B. Payne, and D. J. Howarth, "The Atlas supervisor," in Computers: A Key to Total Systems Control, 1961 Eastern Joint Computer Conf., AFIPS Proc., vol. 20. New York: Macmillan, 1961, pp. 279-294. M. A. Wilkes, "Conversational access to a 2048-word machine," Comm. ACM, vol. 13, pp. 407-414, July 1970. , LAP6 Handbook, Computer Research Laboratory, Washington University, St. Louis, Mo., Tech. Rept. 2, May 1967. , LAP6 Use of the Stucki-Ornstein Text Editing Algorithm, Computer Systems Laboratory, Washington University, St. Louis, Mo., Tech. Rept. 18, February 1970. , LAP6 Manuscript Listings, Computer Systems Laboratory, Washington University, St. Louis, Mo., May 1967. Pipeline Fast Fourier Transform HERBERT L. GROGINSKY, SENIOR MEMBER, IEEE, AND Abstract-This paper describes a novel structure for a hardwired fast Fourier transform (FFT) signal processor that promises to permit digital spectrum analysis to achieve throughput rates consistent with extremely wide-band radars. The technique is based on the use of serial storage for data and intermediate results and multiple arithmetic units each of which carries out a sparse Fourier transform. Details of the system are described for data sample sizes that are binary multiples, but the technique is applicable to any composite number. Index Terms-Cascade Fourier transform, digital signal processor, Doppler radar, fast Fourier transform, radar-sonar signal processor, radix-two fast Fourier transform, real-time signal processor. INTRODUCTION HIS paper describes a novel structure for a hardwired FFT signal processor that promises to permit digital spectrum analysis to achieve throughput rates consistent with extremely wide-band radars. The processor consists of a number ofmodular units connected in cascade through switches that direct the flow of information from memory to arithmetic units. The switching required to carry out the process is simple and is controlled by a binary counter. The processor is similar to the binary analyzer described by Bergland and Hale [1], but r Manuscript received November 7, 1969; revised April 27, 1970. This work was supported by Raytheon research and development funding. A patent has been filed on the basic structure of this signal processor. This paper was presented at EASCON'69 (Electronics and Aerospace Systems Convention), Washington, D. C., October 27-29, 1969. The authors are with the Raytheon Company, Sudbury, Mass. GEORGE A. WORKS employs only N complex words of storage to compute the FFT of N complex data samples.' Bergland [2] has listed many alternative organizations of FFT processors. Recently O'Leary [10] has also proposed a similar structure. We show that the Cooley-Tukey algorithm does a natural interleaving of data gathered by the time multiplexing of a number of independent channels, typical of radars and sonars. In this concept, the successive stages or iterations of the fundamental algorithm are each carried out in the separate cascaded modules. Using shift registers as digital delay lines permits new data to be entered into the processor while the processing of earlier data blocks is carried out. In effect the overall delay required is equal to the time required to gather the analysis sample block N in each of the separate channels. As the Nth complex data sample is loaded into the digital delay line, the first analysis frequency appears at the output. The output appears in precisely the same channel sequence as the data when they were loaded into the delay line. The output frequencies, however, appear in the scrambled sequence associated with the algorithm. The control device, namely the binary counter, yields a digital number identifying both the channel number and the frequency currently being outputted. In addition, it specifies the instants at which the separate modules are to be Although the processor described here is cascade in structure, we prefer the pipeline designation used by computer designers [11 ] because this structure permits direct application of pipeline arithmetic techniques. 1016 IEEE TRANSACTIONS ON COMPUTERS, NOVEMBER 1970 switched and a digital number identifying the sine/cosine and th ,e ranges values needed by each of the stages. This structure, although < v < Cm 1 < m < Ml 0 <I <Rm, hardwired, does permit the flexible interchange of channels processed for data sample length per channel. Thus a sys- wh tem capable of processing N complex samples in a single m channel is also capable of processing N/L samples in each of = H1 rk Rm L channels provided L is a factor of N. The modular design k= 1 of the device permits the duplicate arithmetic units to = Cm NIRm weight the input prior to the FFT operation and to present a%o= A,m0 = Xn the output in magnitude. Furthermore, it allows computation of Fourier transforms at the rate at which new data and can be inserted into the digital delay line. Fundamentally, the signal processing rate is independent of the data sample pl mod r-,up- greatest integer in ,u/r. length. A pipeline FFT configured to process radar data from a when this is done, the number of calculations pulse Doppler tracking radar has been designed and tested. dropsI act, N2 complex operations (MULTIPLY and ADD) to from The system uses MOSFET shift registers as the digital delay Nr, + ... + rM) such operations. This iterative pro-r2+ lines, TTL in the arithmetic units and MOS LSI READ ONLY N(r1 + the amount of hardware required to realreduces th memory to store sine/cosine tables and filter shaping weight icess be and provides the basic pipeline structure operation, functions. izeith new calculations to proceed before the results of tting The system processes eight range channels taking 512 permit calculations are completed. This form of the al* complex samples per channel. It is designed to obtain sub- earlthim is known as the Cooley-Tukey version. Wh clutter visibility of 60 dB and achieves this using 12-bit en rk =2 for all k, the algorithm is conveniently sumfixed-point internal operations in the arithmetic unit. The the flow diagram shown in Fig. 1. In this figure, throughput rate achieved by the system is 128K samples marize-d bydata enter the left-hand column and each succesthe inpput per second. corresponds to a later stage of the iterative pro)lumn sive co cess. T he coefficients indicated at the input then correspond THEORY OF OPERATION to the index of the input data xn and give its order in the In this section, the method of operation of the pipeline data sttream. The figures shown at each later stage indicate FFT is explained in terms of the fundamental mathematical the coeefficients of the rotation vector W2. that must be apoperations that must be carried out. An extensive literature plied t';o the lower branch entering each node. A niumber of important features of the algorithm may be now exists [3] explaining the basic principles of the FFT. The discussion here emphasizes certain features of the seen b'y examining Fig. 1. First, we observe that each stage analysis, permitting a hardwired realization ofthe algorithm needs only the data generated from the preceding stage. Secon'd, if each stage is processed in order of arrival, the to achieve the goals set forth in the introduction. first st ;age examines data points displaced by half the data The discrete Fourier transform (DFT) is defined by length (N/2), the second by one quarter of the data length N-1 (1) (N/4), etc. Third, if the data were available in a continuous Xm = Z xnW7N streaml, the first stage could be processing one block of data n=O while tthe second stage processed the next earlier block and where so on 1through all M stages. Fourth, the rotation vector reWN = e- j(2nlz1N) quired[, W2m, has the same periodicity as the data displacement i] nterval. Finally, we note that the output appears in the xn is a complex data sample, and Xm is the complex image of usual scrambled order of frequency associated with this the data at frequency m/N. n of the algorithm. versioi Theory shows that when N is a composite number The significance of these remarks is that each of the stages M N= Hl rk (2) may b e realized with a basic component whose general form is sho'wn in Fig. 2. Any m module alternately transfers k= 1 blocks of 2' data samples into the delay line and into the where the rk are a set of integers (possibly with repeats), and arithmletic unit. When the data block just fills the delay line, (1) may be calculated iteratively in M stages as follows. the ariithmetic unit obtains a rotation vector (from a READ ONLY lmemory) and begins its operation. The next block of a = (3) 2' inp out data samples are sent to the arithmetic unit that WR uam now p.roduces two complex outputs in response to the two compl4ex inputs it receives. One of the outputs is immediwith ately tiransferred to the next stage while the other output is p = , mod R,,1 sent tc the delay line. Thus in the interim period when the v + IC. q delay 1line is filled with fresh input data, the contents of the Fm-1 1=0 = GROGINSKY AND WORKS: PIPELINE FAST FOURIER TRANSFORM 1017 3 Stage 0 0 Spectrum Output Data Input OUTPUT FREQUENCY AND ROTATION VECTOR ADDRESS CHANNE NUMBEF Fig. 3. Pipeline FFT processor. W2 Rotation Vector Base 0D 0 W8 W4 Fig. 1. Flow diagram of a Cooley-Tukey FFT. SWITCH - CNRL 7- / / - - - - - /' / DATA INPUT / DELAY LINE = 2 SAMPLES | ? / ? / I 1 01 DATA OUTPUT 2341 6 1 j 1 10 1 13 17 8 11 1IZ1214 15 Complex Data Samples tI T ON Fig. 4. FFT interleaving mechanism. stage of the process has a simple interpretation. Theory shows that xOUT YIN I Rm-1 ROTATION VECTOR W Fig. 2. Pipeline FFT m module. A= line containing the results of processing the earlier blocks are transferred to the next stage. The arithmetic unit, of course, computes the complex two-point transforms, shown below. xout Yout = Xin + Yin W Xin YinWz (4) This module design may be assembled into a system for computing DFTs in blocks of N = 2M samples as shown in Fig. 3. The rotation vector storage shown in the figure is a table of roots of unity, or sines and cosines, which is shared by all m modules. Fig. 1 shows that N/2 different rotation vectors are read to process one block of N samples. Indeed if they are produced in the order required for the last stage, the rotation vectors required for the earlier stages may be obtained by strobing this list at the proper instant in advance of its need. Thus the sines and cosines required for each stage may be obtained by providing a register for each arithmetic unit, all driven from a common bus. Note that exactly M arithmetic units and exactly N-1 complex data points of storage are needed in this system and that the first transform output is obtained immediately after the last data sample in the block of N is received. The theory cited above leads to still another important observation, namely that the output at any intermediate k=O XV+kCmWyynRX (5) which is precisely the discrete Fourier transform of all groups of data points separated by an interval Cm. This may be better understood in reference to Fig. 4, which shows the natural FFT interleaving mechanism that results from the Cooley-Tukey algorithm. In terms of a sequential process, the output of the first stages results in N/2 independent twopoint transforms; the output of the second stage yields N/4 independent four-point transforms, etc. Thus, if two independent streams of complex data were entered into the input interleaved with one another, the module 1 stage of the cascade processor would produce two independent DFTs of each data stream. The spectral component of each channel of data is outputted before the spectral frequency is changed. In particular for pulsed radar or sonar application, where the data for many range samples are received before a new sample may be taken, this system permits the data to be processed in order of arrival with no modification of the control circuits and without requiring the data to be reassembled first into consecutive (noninterleaved) data streams. Equation (5) shows that the index u, which is the rotation vector coefficient in (3), can also be regarded as the current frequency being outputted, namely- PIRm. When these normalized frequencies (chosen to make Rm a unit period) are modified to account for the expanded sampling interval Cm, the current frequency being outputted may be regarded on 1018 IEEE TRANSACTIONS ON COMPUTERS, NOVEMBER 1970 absolute scales as the frequency U/RmCm= 1u/N. Thus, in Fig. 1, the coefficient given at every stage in the process indicates not only the coefficient of the rotation vector applied to the lower branch but the current frequency (in absolute terms) as well. The control mechanism for this system is perhaps its most elegant feature. Fig. 1 shows clearly that a binary counter driven in synchronism with the data stream generates a signal designating the processing interval (i.e., the switch position) for each stage. However, if any output is taken at any intermediate stage, say at the k + 1st stage, then the lower k bits of the counter, in normal order, give the channel number of the data currently being outputted, while the upper M - k bits taken in bit-reversed order, give the frequency that is currently being outputted and, in addition, describes the address (0) of the sine and cosines needed in the current computation of the k +1st stage. Thus, the control mechanism contains all the information needed to carry out the spectral analysis as well as to descramble the output data. In many applications, it is unnecessary to descramble the output data provided one can identify the frequency of any component. Indeed the structure shown in Fig. 3 may be readily modified to calculate transforms when the data samples are given in scrambled order. This structure also permits the trade-off of channels processed for data length per channel by taking outputs at an intermediate stage. The modified structure produces the output sequence in natural order in both the channels and in time. COMPUTATIONAL ERRORS AND QUANTIZATION If the input signal to an FFT machine is obtained from an analog-to-digital converter, it must be sufficiently finely quantized so that quantization noise is uncorrelated to avoid distortion of the Fourier transform. Widrow [4] has shown that for signals in the presence of Gaussian noise, choosing the quantization grain or value of the least significant bit of the quantizer equal to three times the noise standard derivation provides a good approximation to this condition. The value of the most significant bit of the quantizer must be greater than or equal to one half the peak value of the input signal (without noise) to avoid peak limiting. The minimum number of bits Q required to represent a signal of peak value + Vp with additive Gaussian noise of standard deviation an is therefore given by Q log2 (VPI/3n) + 1. = (6) One or more bits may be added to further reduce quantization noise. The number of bits per data word required in an FFT processor is usually greater than the number of bits Q in the input word to reduce computational noise. The twopoint transform (4), which is the building block of larger Fourier transforms, may be accomplished by four real multiplications and six real additions. Following each twopoint transform, words may be truncated or rounded to maintain constant word size or allowed to grow. Welch [5] has shown that rounding after each two-point transform leads to a relative rms output error E, which is bounded above by B = (0.3)2 -B+(M+ 3)'2/rms (input) (7) for -a transform of 2M samples using B-bit arithmetic. The error may be reduced by allowing words to lengthen from stage to stage. This can be particularly attractive in a cascade machine because most of the storage in such a machine may be associated with the first few stages of the transform. ALTERNATE CONFIGURATIONS The computing module circuitry may be configured in a number of different ways to meet different requirements. The arithmetic unit that computes two-point transforms may employ either four real multiplications and six real additions or three real multiplications and nine real additions. The multiplications may be performed either before data are stored in the shift register or after data emerge from the shift register. Goldstone [6] has shown that multipliers may be time-shared between adjacent modules by performing half of the required multiplications as data enter the shift register and the other half as data leave. Some of the total shift register delay may be incorporated in a pipeline multiplier for high-speed operation. In order to make use of the speed possible in a pipeline processor, one word delays must be inserted between the computing modules. These delays permit each module to begin computation at the start of a word time rather than to wait for the preceding modules to compute the input it requires. These intermodule delays do not appreciably complicate the control circuitry of the processor, since they may be compensated by delaying the control and rotation vector inputs to the module by a delay equal to the total data delay. A cascade processor requires no multipliers in the first two modules. The rotation vectors (W° and Wj) used in these modules may be implemented by, at most, a switching circuit to interchange the real and imaginary part of the data word and invert the sign of the resulting real part when rotation by W4 is required. The multipliers may be implemented if desired and used for data windowing. Data windowing, or multiplying input data samples by a data window function, is a technique used to change the frequency response of the equivalent N filters whose output is computed by the FFT. If an FFT of N samples taken at equal intervals T is computed, a data window that is exactly zero everywhere except over sampling interval of duration NT must be used. If no data windowing is intentionally performed, input data samples are weighted by a data window function that is unity over the sampling interval and zero elsewhere. The frequency response of the equivalent FFT filters is given by the discrete Fourier transform of the data window function. The frequency response of an FFT filter when no data windowing is performed is therefore the DFT of a unitamplitude pulse of duration NT, which (normalized) is GROGINSKY AND WORKS: PIPELINE FAST FOURIER TRANSFORM sin rNTf (f) NJ Nsin 7tTf = 1019 (8) The relatively slow decrease in amplitude with increasing frequency of this function makes it undesirable for Fourier analyzer applications, in which data windowing is commonly used. Frequently used data window functions include the Hamming [7], Hanning [7], Dolph-Tchebyscheff [8], and Taylor [9] functions. The properties of these functions have been extensively described. IMPLEMENTATION The pipeline structure was used to implement a real-time FFT machine to provide spectral analysis for a tracking pulse-Doppler radar. This machine simultaneously processes eight channels of Doppler data at a sample rate of 16 000 complex samples per second per channel with a transform length of 512 complex samples and a quantization of 24 bits per complex sample. The FFT throughput rate is slightly over three million bits per second. A Taylor data window is employed to permit 60-dB subclutter visibility of high-speed targets. The machine is composed of nine processing modules, a synchronizer, A-D converter, and display. The processing modules employ a total of 2600 TTL integrated circuits for switching and arithmetic functions and a total of 500 200bit MOSFET shift registers for delay. Words are stored in bit-serial form in the shift registers, but arithmetic operations are performed in bit-parallel. Interstage delay is incorporated in the arithmetic units. Data windowing is performed by the "spare" multiplier in the first processing module. An eight complex sample input buffer following the A-D converter allows the FFT machine to operate at a constant word rate equal to eight times the 8-16 kHz radar PRF, independent of the ranges at which samples are collected. Fig. 5 shows a photograph of the complete breadboard FFT cascade processor. CONCLUSIONS The pipeline FFT processor has proven to be an effective tool to meet the real-time spectral analysis requirements of many radar and sonar systems. Its structure permits sufficient paralleling of operations, such that the processing time is limited solely by the time it takes to collect the data. It is efficient in storage requirement since it requires only as much storage as the number of samples to be processed. It is simple to control because basically all of the control information can be generated by a binary counter. Furthermore the use of this counter guarantees proper synchronization of the control function with the data stream passing through the device. Perhaps its greatest disadvantage is the scrambled order in which the output appears. In the radar/sonar applications, for which the device was designed, this fault was transparent. It does, however, make certain operations in the frequency domain, such as smoothing over frequency, somewhat more difficult. Descrambling is possible in a Fig. 5. Pipeline processor machine. pipeline processor at the cost of additional memory less than the number of words in the processed data block. The remarkable flexibility with which the structure may be reconfigured to trade channels for data sample length and to carry out the inverse transform functions is one of its most satisfying properties. Properly utilized, the device is able to carry out auto- and cross-correlation, block convolutions, and cross-spectral density calculations. REFERENCES [1] G. D. Bergland and H. W. Hale, "Digital real-time spectral analysis," IEEE Trans. Electronic Computers, vol. EC-16, pp. 180-185, April 1967. [2] G. D. Bergland, "Fast Fourier transform hardware implementations-An overview," IEEE Trans. Audio Electroacoust., vol. AU-17, pp. 104-108, June 1969. [3] "A guided tour of the fast Fourier transform," IEEE Spectrum, vol. 6, pp. 41-52, July 1969. [4] B. Widrow, "Statistical analysis of amplitude-quantized sampleddata systems," AIEE Trans., vol. 79, pt. 2, pp. 555-567, January 1961. [5] P. D. Welch, "A fixed-point fast Fourier transform error analysis," IEEE Trans. Audio Electroacoust., vol. AU-17, pp. 151-157, June 1969. [6] B. J. Goldstone, "Serial FFT-More efficient utilization of the multiplier," Raytheon Co. internal memo BFX-R-29, October 1968. [7] R. B. Blackman and J. W. Tukey, The Measurement of Power Spectra. New York: Dover, 1958. [81 C. L. Dolph, "A current distribution for broadside arrays which optimizes the relationship between beam width and side-lobe level," Proc. IRE, vol. 34, pp. 335-348, June 1946. [9] T. T. Taylor, "Design of line-source antennas for narrow beamwidth and low sidelobes," IRE Trans. Antennas Propag., vol. AP-3, pp. 16-28, January 1955. [10] G. O'Leary, "A high-speed cascade fast Fourier transformer," presented at IEEE Arden House Workshop on Digital Filtering, January 1970. [11] W. R. Graham, "The parallel, pipeline and conventional computer," Datamation, vol. 16, pp. 68-71, April 1970. ,