CACTI: An Enhanced Cache Access and Cycle Time Model
advertisement

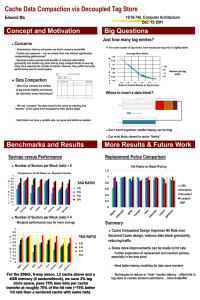
To appear in IEEE Journal of Solid State Circuits 1996
CACTI: An Enhanced Cache Access and Cycle Time Model
Steven J.E. Wilton
Department of Electrical and Computer Engineering
University of Toronto
Toronto, Ontario, Canada M5S 1A4
(416) 978-1652
wilton@eecg.toronto.edu
Norman P. Jouppi
Digital Equipment Corporation Western Research Lab
250 University Avenue
Palo Alto, CA 94301
(415) 617-3305
jouppi@pa.dec.com
May 14, 1996
Abstract
This paper describes an analytical model for the access and cycle times of on-chip directmapped and set-associative caches. The inputs to the model are the cache size, block size,
and associativity, as well as array organization and process parameters. The model gives
estimates that are within 6% of Hspice results for the circuits we have chosen.
This model extends previous models and xes many of their major shortcomings. New
features include models for the tag array, comparator, and multiplexor drivers, non-step
stage input slopes, rectangular stacking of memory subarrays, a transistor-level decoder
model, column-multiplexed bitlines controlled by an additional array organizational parameter, load-dependent size transistors for wordline drivers, and output of cycle times as well
as access times.
Software implementing the model is available via ftp.
1
To appear in IEEE Journal of Solid State Circuits 1996
1 Introduction
Most computer architecture research involves investigating trade-os between various alternatives. This can not be done adequately without a rm grasp of the costs of each
alternative. For example, it is impossible to compare two dierent cache organizations
without considering the dierence in access or cycle times. Similarly, the chip area and
power requirements of each alternative must be taken into account. Only when all the costs
are considered can an informed decision be made.
Unfortunately, it is often dicult to determine costs. One solution is to employ analytical models that predict costs based on various architectural parameters. In the cache
domain, both chip area models [1] and access time models [2] have been published.
In [2], Wada et al. present an equation for the access time of an on-chip cache as
a function of various cache parameters (cache size, associativity, block size) as well as
organizational and process parameters. Unfortunately, Wada's access time model has a
number of signicant shortcomings. For example, the cache tag and comparator in setassociative memories are not modeled, and in practice, these often constitute the critical
path. Each stage in their model (e.g., bitline, wordline) assumes that the inputs to the
stage are step waveforms; actual waveforms in memories are far from steps and this can
greatly impact the delay of a stage. In the Wada model, all memory subarrays are stacked
linearly in a single le; this can result in aspect ratios of greater than 10:1 and overly
pessimistic access times. Wada's decoder model is a gate-level model which contains no
wiring parasitics. In addition, transistor sizes in Wada's model are xed independent of the
load. For example, the wordline driver is always the same size independent of the number
of cells that it drives. Finally, Wada's model predicts only the cache access time, whereas
both the access and cycle time are important for design comparisons.
This paper describes a signicant improvement and extension of Wada's access time
model. The enhanced model is called CACTI. Some of the new features are:
a tag array model with comparator and multiplexor drivers
non-step stage input slopes
rectangular stacking of memory subarrays
a transistor-level decoder model
column-multiplexed bitlines and an additional array organizational parameter
2
To appear in IEEE Journal of Solid State Circuits 1996
load-dependent transistor sizes for wordline drivers
cycle times as well as access times
The enhancements to Wada's model can be classied into two categories. First, the
assumed cache structure has been modied to more closely represent real caches. Some
examples of these enhancements are the column multiplexed bitlines and the inclusion of
the tag array. The second class of enhancements involve the modeling techniques used to
estimate the delay of the assumed cache structure (e.g. taking into account non-step input
rise times). This paper describes both classes of enhancements. After discussing the overall
cache structure and model input parameters, the structural enhancements are described
in Section 4. The modeling techniques used are then described in Section 5. A complete
derivation of all the equations in the model is far beyond the scope of a journal paper but
is available in a technical report [3].
Any model needs to be validated before the results generated using the model can be
trusted. In [2], a Hspice model of the cache was used to validate the authors' analytical
model. The same approach was used here; Section 6 compares the model predictions to
Hspice measurements. Of course, this only shows that the analytical model matches the
Hspice model; it does not address the issue of how well the assumed cache structure (and
hence the Hspice model) reects a real cache design. When designing a real cache, many
dierent circuit implementations are possible. In architecture studies, however, the relative
dierences in access/cycle times between dierent cache sizes or congurations are usually
more important than absolute access times. Thus, even though our model predicts absolute
access times for a specic cache implementation, it can be used in a wide variety of situations
when an estimate of the cost of varying an architectural parameter is required. Section 7
gives some examples of how the model can be used in architectural studies.
The model described in this paper has been implemented, and the software is available
via ftp. Appendix A explains how to obtain and use the CACTI software.
2 Cache Structure
Figure 1 shows the organization of the SRAM cache being considered. The decoder rst
decodes the address and selects the appropriate row by driving one wordline in the data
array and one wordline in the tag array. Each array contains as many wordlines as there
3
To appear in IEEE Journal of Solid State Circuits 1996
ADDRESS
INPUT
BIT LINES
BIT LINES
WORD
LINES
WORD
LINES
TAG
ARRAY
DATA
ARRAY
COLUMN
MUXES
COLUMN
MUXES
DECODER
SENSE
AMPS
SENSE
AMPS
COMPARATORS
OUTPUT
DRIVERS
MUX
DRIVERS
DATA OUTPUT
OUTPUT
DRIVER
VALID OUTPUT
Figure 1: Cache structure
are rows in the array, but only one wordline in each array can go high at a time. Each
memory cell along the selected row is associated with a pair of bitlines; each bitline is
initially precharged high. When a wordline goes high, each memory cell in that row pulls
down one of its two bitlines; the value stored in the memory cell determines which bitline
goes low.
Each sense amplier monitors a pair of bitlines and detects when one changes. By
detecting which line goes low, the sense amplier can determine the contents of the selected
memory cell. It is possible for one sense amplier to be shared among several pairs of
bitlines. In this case, a multiplexor is inserted before the sense amps; the select lines of the
multiplexor are driven by the decoder. The number of bitlines that share a sense amplier
depends on the layout parameters described in the next section.
The information read from the tag array is compared to the tag bits of the address. In an
A-way set-associative cache, A comparators are required. The results of the A comparisons
are used to drive a valid (hit/miss) output as well as to drive the output multiplexors.
These output multiplexors select the proper data from the data array (in a set-associative
cache or a cache in which the data array width is larger than the output width), and drive
4
To appear in IEEE Journal of Solid State Circuits 1996
the selected data out of the cache.
3 Cache and Array Organization Parameters
Table 1 shows the ve model input parameters.
Parameter Meaning
C
Cache size in bytes
B
Block size in bytes
A
Associativity
bo
Output width in bits
baddr
Address width in bits
Table 1: CACTI input parameters
In addition, there are six array organization parameters that are used to estimate the
cache access and cycle time. In the basic organization discussed by Wada [2], a single
set shares a common wordline. Figure 2-a shows this organization, where B is the block
size (in bytes), A is the associativity, and S is the number of sets (S = BCA ). Clearly,
such an organization could result in an array that is much larger in one direction than the
other, causing either the bitlines or wordlines to be very slow. To alleviate this problem,
Wada describes how the array can be broken horizontally and vertically and denes two
parameters, Ndwl and Ndbl , which indicates to what extent the array has been divided.
Figure 2-b introduces another organization parameter, Nspd. This parameter indicates how
many sets are mapped to a single wordline, and allows the overall access time of the array
to be changed without breaking it into smaller subarrays. The optimum values of Ndwl ,
Ndbl, and Nspd depend on the cache and block sizes, as well as the associativity.
We assume that the tag array can be congured independently of the data array. Thus,
there are also three tag array parameters: Ntwl, Ntbl, and Ntspd.
4 Model Components
This section gives an overview of key portions of the cache read access and cycle time
model. The access and cycle times were derived by estimating delays due to the following
components:
5
To appear in IEEE Journal of Solid State Circuits 1996
8xBxA
16xBxA
S
S/2
a) Original Array
b) Nspd = 2
Figure 2: Cache organization parameter Nspd
decoder
wordlines (in both the data and tag arrays)
bitlines (in both the data and tag arrays)
sense ampliers (in both the data and tag arrays)
comparators
multiplexor drivers
output drivers (data output and valid signal output)
The delay of each these components is estimated separately and the results combined
to estimate the access and cycle time of the entire cache. A complete description of each
component can be found in [3]. In this paper, we focus on those parts that dier signicantly
from Wada's model.
4.1 Decoder
Wada's model contains a gate-level decoder model without any parasitic capacitances or
resistances. It also assumes all memory sub-arrays are stacked single le in a linear array.
We have used a detailed transistor-level decoder that includes both parasitic capacitances
and resistances. We have also assumed that sub-arrays are placed in a two-dimensional
array to minimize critical wiring parasitics.
Figure 3 shows the logical structure of the decoder architecture used in this model. The
decoder in Figure 3 contains three stages. Each block in the rst stage takes three address
bits (in true and complement), and generates a 1-of-8 code, driving a precharged decoder
bus. These 1-of-8 codes are combined using NOR gates in the second stage. The nal
6
To appear in IEEE Journal of Solid State Circuits 1996
WORDLINE
DRIVER
Word
Lines
Address
3
to
8
3
to
8
Figure 3: Single decoder structure
stage is an inverter that drives each wordline driver. We also model separate decoder driver
buers for driving the 3-to-8 decoders of the data arrays and the tag arrays.
Estimating the wire lengths in the decoder requires knowledge of the memory tile layout.
As mentioned in Section 3, the memory is divided into Ndwl Ndbl subarrays; each of these
spd
arrays is 8BAN
Ndwl cells wide. If these arrays were placed side-by-side, the total memory
width would be 8 B A Ndbl Nspd cells. Instead, we assume they are grouped in twoby-two blocks, with the 3-to-8 predecode NAND gates at the center of each block; Figure 4
shows one of these blocks. This reduces the length of the connection between the decoder
driver and the predecode block to approximately one quarter of the total memory width,
or 2 B A Ndbl Nspd. The length of the connection between the predecode block and
C
the NOR gate is then (on average) half of the subarray height, which is BANdbl
Nspd cells.
In large memories with many groups the bits in the memory are arranged so that all bits
driving the same data output bus are in the same group, shortening the data bus.
4.2 Variable Size Wordline Driver
The size of the wordline driver in Wada's model is independent of the number of cells
attached to the wordline; this severely overestimates the wordline delay of large arrays.
Our model assumes a variable-sized wordline driver. Normally, a cache designer would
choose a target wordline rise time, and adjust the driver size appropriately. Rather than
7
To appear in IEEE Journal of Solid State Circuits 1996
Predecoded
address
Address in
from driver
Predecode
Channel for data output bus
Figure 4: Memory block tiling assumptions
assuming a constant rise time for caches of all sizes, however, we assume the desired rise
time (to a 50% word line swing) is:
desired rise time = krise ln(cols) 0:5
where
spd
cols = 8BAN
N
dwl
and krise is a constant that depends on the implementation technology. To obtain the
transistor size that would give this rise time, it is necessary to work backwards, using an
equivalent RC circuit to nd the required driver resistance, and then nding the transistor
width that would give this resistance. This is described in Section 5.5.
4.3 Bitlines and Sense Ampliers
Wada's model does not apply to memories with column multiplexing. Our model allows
column multiplexing using NMOS pass transistors between several pairs of bitlines and a
shared sense amp. In our model, the degree of column multiplexing (number of pairs of
bitlines per sense amp) is Nspd Ndbl .
Although we use the same sense amp as Wada's model, we precharge the bitlines to
two NMOS diodes less than Vdd since the sense amp performs poorly with a common-mode
8
To appear in IEEE Journal of Solid State Circuits 1996
Vdd
PRECHARGE
OUT
a0
a0
a1
a
1
a
n
an
b
0
b
0
b
b1
bn
bn
1
EVAL
From
dummy
row
sense
amp
in tag
array
small p
large n
Figure 5: Comparator
voltage of Vdd .
4.4 Comparator
Although Wada's model gives access times for set-associative caches, it only models the data
portion of a set-associative memory. However, the tag portion of a set-associative memory
is often the critical path. Our model assumes the tag memory array circuits are similar to
those on the data side with the addition of comparators to choose between dierent sets.
The comparator that was modeled is shown in Figure 5. The outputs from the sense
ampliers are connected to the inputs labeled bn and bn -bar. The an and an -bar inputs are
driven by tag bits in the address. Initially, the output of the comparator is precharged high;
a mismatch in any bit will close one pull-down path and discharge the output. In order to
ensure that the output is not discharged before the bn bits become stable, node EVAL is
held high until roughly three inverter delays after the generation of the bn -bar signals. This
is accomplished by using a timing chain driven by a sense amp on a dummy row in the tag
array. The output of the timing chain is used as a \virtual ground" for the pull-down paths
of the comparator. When the large NMOS transistor in the nal inverter in the timing
chain begins to conduct, the virtual ground (and hence the comparator output if there is a
mismatch) begins to discharge.
9
To appear in IEEE Journal of Solid State Circuits 1996
4.5 Set Multiplexor and Output Drivers
In a set-associative cache, the result of the A comparisons must be used to select which
of the A possible data blocks are to be sent out of the cache. Since the width of a block
(8B ) is usually greater than the cache output width (bo ), it is also necessary to choose part
of the selected block to drive the output lines. An A-way set-associative cache contains
A multiplexor driver blocks, as shown in Figure 6. Each multiplexor driver uses a single
comparator output bit, along with address bits, to determine which bo data array outputs
drive the output bus.
1
A
Mux driver circuit
Mux driver circuit
bo
bo
bo
bo
8B
bo
8B
bo
bo
data
bus
outputs
Figure 6: Overview of data bus output driver multiplexors
5 Model Derivation
The delay of each component was estimated by decomposing each component into several
equivalent RC circuits, and using simple RC equations to estimate the delay of each stage.
This section shows are resistances and capacitances were estimated, as well as how they
were combined and the delay of a stage calculated. The stage delay in our model depends
on the slope of its inputs; this section also describes how this was done.
5.1 Estimating Resistances
To use the RC approximations described in Sections 5.5 and 5.6, it is necessary to estimate
the full-on resistance of a transistor. The full-on resistance is the resistance seen between
drain and source of a transistor assuming the gate voltage is constant and the gate is fully
conducting. This resistance can also be used for pass transistors that (as far as the critical
path is concerned) are fully conducting.
It is assumed that the equivalent resistance of a conducting transistor is inversely pro10
To appear in IEEE Journal of Solid State Circuits 1996
portional to the transistor width (only minimum-length transistors were used). Thus,
R
equivalent resistance = W
where R is a constant (dierent for NMOS and PMOS transistors) and W is the transistor
width.
5.2 Estimating Gate Capacitances
The RC approximations in Section 5.5 and 5.6 also require an estimation of a transistor's
gate and drain capacitances. The gate capacitance of a transistor consists of two parts: the
capacitance of the gate itself, and the capacitance of the polysilicon line going into the gate.
If Le is the eective length of the transistor, Lpoly is the length of the poly line going into
the gate, Cgate is the capacitance of the gate per unit area, and Cpolywire is the poly line
capacitance per unit area, then a transistor of width W has a gate capacitance of:
gatecap(W) = W Le Cgate + Lpoly Le Cpolywire
The same formula holds for both NMOS and PMOS transistors.
The value of Cgate depends on whether the transistor is being used as a pass transistor,
or as a pull-up or pull-down transistor in a static gate. Thus, two dierent values of Cgate
are required.
5.3 Drain Capacitances
Figure 7 shows typical transistor layouts for small and large transistors. We have assumed
that if the transistor width is larger than 10m, the transistor is split as shown in Figure 7-b.
The drain capacitance is composed of both an area and perimeter component. Using
the geometries in Figure 7, the drain capacitance for a single transistor can be obtained. If
the width is less than 10m,
draincap(W ) = 3Le W Cdiarea + (6Le + W ) Cdiside + W Cdigate
where Cdiarea , Cdiside , and Cdigate are process dependent parameters (there are two
values for each of these: one for NMOS and one for PMOS transistors). Cdigate is the
11
To appear in IEEE Journal of Solid State Circuits 1996
Leff
SOURCE
DRAIN
DRAIN
SOURCE
SOURCE
W/2
W
3 x Leff
3 x Leff
3 x Leff
GATE
3 x Leff
3 x Leff
GATE
a) width < 10m
Leff
b) width 10m
Figure 7: Transistor Geometries
sum of the junction capacitance due to the diusion and the oxide capacitance due to the
gate/source or gate/drain overlap.
If the width is larger than 10m, we assume the transistor is folded (see Figure 7-b),
reducing the drain capacitance to:
draincap(W ) = 3Le W2 Cdiarea + 6Le Cdiside + W Cdigate
Now, consider two transistors (with widths less than 10m) connected in series, with
only a single Le W wide region acting as both the source of the rst transistor and
the drain of the second. If the rst transistor is on, and the second transistor is o, the
capacitance seen looking into the drain of the rst is:
draincap(W ) = 4Le W Cdiarea + (8Le + W ) Cdiside + 3W Cdigate
Figure 8 shows the situation if the transistors are wider than 10m. In this case, the
capacitance seen looking into the drain of the inner transistor (x in the diagram) assuming
it is on but the outer transistor is o is:
draincap(W ) = 5Le W2 Cdiarea + 10Le Cdiside + 3W Cdigate
12
To appear in IEEE Journal of Solid State Circuits 1996
3xLeff
x
W/2
3xLeff
3xLeff
Leff
Leff
Figure 8: Two stacked transistors if each width 10m
5.4 Other parasitic eects
Parasitic resistances and capacitances of the bitlines, wordlines, predecode lines, and various
other signals within the cache are also modeled. These resistances and capacitances are xed
values per unit length; the capacitance includes an expected value for the area and sidewall
capacitances to the substrate and other layers.
5.5 Simple RC Circuits
Each component described in Section 4 can be decomposed into several rst or second
order RC circuits. Figure 9-a shows a typical rst-order circuit. The time for node x to rise
or fall can be determined using the equivalent circuit of Figure 9-b. Here, the pull-down
path (assuming a rising input) of the rst stage is replaced by a resistance, and the gate
capacitances of the second stage and the drain capacitance of the rst stage are replaced by
a single capacitor. The resistances and capacitances are calculated as shown in Sections 5.1
to 5.3. In stages in which the two gates are separated by a long wire, parasitic capacitances
and resistances of the wire are included in Ceq and Req .
The delay of the circuit in Figure 9 can be estimated using an equation due to Horowitz [4]
(assuming a rising input):
s v 2
v
th
delay = tf log V
+ 2trise b 1 , Vth =tf
dd
dd
where vth is the switching voltage of the inverter, trise is the input rise time, tf is the output
13
To appear in IEEE Journal of Solid State Circuits 1996
x
Ceq
Req
x
a) schematic
b) equivalent circuit
Figure 9: Example Stage
time constant assuming a step input (tf = Req Ceq ), and b is the fraction of the input
swing in which the output changes (we used b = 0:5). For a falling input with a fall time of
tfall, the above equation becomes:
s 2
delay = tf log 1 , vth + 2tfall b vth
Vdd
tf Vdd
In this case, we used b = 0:4.
The delay of a gate is dened as the time between the input reaching the switching
voltage (threshold voltage) of the gate, and the output reaching the threshold voltage of
the following gate. If the gate drives a second gate with a dierent switching voltage, the
above equations need to be modied slightly. If the switching voltage of the switching gate
is vth1 and the switching
of the following gate is vth2 , then:
s voltage
2
delay = tf log vVth1 + 2trise b 1 , vVth1 =tf + tf log vVth1 , log vVth2
dd
dd
dd
dd
for a rising input, and
s v 2 2t b v
v v
th
1
th
1
rise
th
1
delay = tf log 1 , V
+ tf log 1 , V , log 1 , Vth2
+ t V
dd
f
dd
dd
dd
for a falling input.
As described in Section 4.2, the size of the wordline driver depends on the number of
cells being driven. For a given array width, the capacitance driven by the wordline driver
can be estimated by summing the gate capacitance of each pass transistor being driven by
the wordline, as well as the metal capacitance of the line. Using this, and the desired rise
14
To appear in IEEE Journal of Solid State Circuits 1996
time, the required pull-up resistance of the driver can be estimated by:
rise time
Rp = ,desired
C ln(0:5)
eq
(recall that the desired rise time is assumed to be the time until the wordline reaches 50%
of its maximum value).
Once Rp is found, the required transistor width can be found using the equation in
Section 5.1. Since this \backwards analysis" did not take into account the non-zero input
fall time, we then use Rp and the wordline capacitance and calculate the adjusted delay
using Horowitz's equations as described earlier. These transistor widths are also used to
estimate the delay of the nal gate in the decoder.
5.6 RC-Tree Solutions
All but two of the stages along the cache's critical path can be approximated by simple
rst-order stages as in the previous section. The bitline and comparator equivalent circuits,
however, require more complex solutions. Figure 10 shows an equivalent circuit that can
be used for the bitline and comparator circuits. From [5], the delay of this circuit can be
written as:
Tstep = [R2C2 + (R1 + R2)C1] ln vvstart
end
where vstart is the voltage at the beginning of the transistion, and vend is the voltage at
which the stage is considered to have \switched" (vstart > vend ). For the comparator, vstart
is Vdd and vend is the threshold voltage of the multiplexor driver. For the bitline subcircuit,
vstart is the precharged voltage of the bitlines (vpre ), and vend is the voltage which causes
the sense amplier output to fully switch (vpre , vsense ).
R1
C2
R2
C1
Figure 10: Equivalent circuit for bitline and comparator
15
To appear in IEEE Journal of Solid State Circuits 1996
When estimating the bitline delay, a non-zero wordline rise time is taken into account
as follows. Figure 11 shows the wordline voltage as a function of time for a step input. The
time dierence Tstep shown on the graph is the time after the input rises (assuming a step
input) until the output reaches vpre , vsense (the output voltage is not shown on the graph).
An equation for Tstep is given above. During this time, we can consider the bitline being
\driven" low. Because the current sourced by the access transistor can be approximated as
i gm(Vgs , Vt)
the shaded area in the graph can be thought of as the amount of charge discharged before
the output reaches vpre , vsense . This area can be calculated as:
area = Tstep (Vdd , Vt)
(Vt is the voltage at which the NMOS transistor begins to conduct).
Vdd
input
voltage
Vt
t
T
step
Figure 11: Step input
If we assume that the same amount of \drive" is required to drive the output to vpre ,
vsense regardless of the shape of the input waveform, then we can calculate the output delay
for an arbitrary input waveform. Consider Figure 12-a. If we assume the area is the same
as in Figure 11, then we can calculate the value of T (delay adjusted for input rise time).
Using simple algebra, it is easy to show that
s
T = 2 Tstep (Vdd , Vt)
m
where m is the slope of the input waveform (this can be estimated using the delay of the
previous stage). Note that the bitline delay is measured from the time the wordline reaches
16
To appear in IEEE Journal of Solid State Circuits 1996
area = T
slope = m
vdd
V
area = T
(V −v )
step dd t
V
dd
input
voltage
t
t
T
(V
dd
−v )
t
input
voltage
slope = m
V
t
step
t
T
a) Slow-rising input
b) Fast-rising input
Figure 12: Non-zero input rise time
Vt. Unlike the version of the model described in [3], the wordline rise time in this model
is dened as the time until the bitlines begin to discharge; this happens when the wordline
reaches Vt .
If the wordline rises quickly, as shown in Figure 12-b, then the algebra is slightly dierent.
In this case,
, Vt
T = Tstep + Vdd2m
The cross-over point between the two cases for T occurs when:
m = V2ddT, Vt
step
The non-zero input rise time of the comparator can be taken into account similarly.
The delay of the comparator is composed of two parts: the delay of the timing chain and
the delay discharging the output (see Figure 5). The delay of the rst three inverters in
the timing chain can be approximated using simple rst-order RC stages as described in
Section 5.5. The time to discharge the comparator output through the nal inverter can
be estimated using the equivalent circuit of Figure 10 and taking into account the non-zero
input rise time using the same technique that was used for the bitline subcircuit. In this
case, the \input" is the output of the third inverter in the timing chain (we assume the
timing chain is long enough that the an and bn lines are stable). The discharging delay of
the comparator output is measured from the time the input reaches the threshold voltage
of the nal timing chain inverter. The equations for this case can be found in [3].
17
To appear in IEEE Journal of Solid State Circuits 1996
6 Total Access and Cycle Time
This section describes how delays of the model components described in Section 4 are
combined to estimate the cache read access and cycle times.
6.1 Access Time
There are two potential critical paths in a cache read access. If the time to read the tag
array, perform the comparison, and drive the multiplexor select signals is larger than the
time to read the data array, then the tag side is the critical path, while if it takes longer to
read the data array, then the data side is the critical path. In many cache implementations,
the designer would try to margin the cache design such that the tag path is slightly faster
than the data path so that the multiplexor select signals are valid by the time the data
is ready. Often, however, this is not possible. Therefore, either side could determine the
access time, meaning both sides must be modeled in detail.
In a direct-mapped cache, the access time is the larger of the two paths:
Taccess dm = max(Tdataside + Toutdrive data; Ttagside dm + Toutdrive valid)
where Tdataside is the delay of the decoder, wordline, bitline, and sense amplier for the
data array, Ttagside dm is the delay of the decoder, wordline, bitline, sense amplier, and
comparator for the tag array, Toutdrive dm is the delay of the cache data output driver, and
Toutdrive valid is the delay of the valid signal driver.
In a set-associative cache, the tag array must be read before the data signals can be
driven. Thus, the access time is:
Taccess;sa = max(Tdataside ; Ttagside sa ) + Toutdrive data
where Ttagside sa is the same as Ttagside dm , except that it includes the time to drive the
select lines of the output multiplexors.
Figures 13 to 16 show analytical and Hspice estimations of the data and tag sides for
direct-mapped and 4-way set-associative caches. A 0:8m CMOS process was assumed [6].
To gather these results, the model was rst used to nd the array organization parameters
which resulted in the lowest access time via exhaustive search for each cache size. These
18
To appear in IEEE Journal of Solid State Circuits 1996
12ns
11ns
10ns
9ns
8ns
Data Side 7ns
(including
6ns
output
5ns
driver)
4ns
3ns
2ns
1ns
0ns
2:4:4
1:4:4
1:8:4
1:4:8
g
g
g
g
2:4:4
2:4:2 1:4:4
1:2:4
gg
g
g
2:2:1 1:4:1
1:2:4
2:4:1 1:2:2
1:2:2
g
g
g
g
g
g
2048
Analytical
Hspice
8192
Markers:
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
32768
131072
Cache Size in bytes (B=16 bytes, A=1)
Figure 13: Direct mapped: Tdataside + Toutdrive data
12ns
11ns
10ns
9ns
8ns
Tag 7ns
Side 6ns
5ns
4ns
3ns
2ns
1ns
0ns
1:8:4
1:4:8
2:4:4
1:4:4
g
g
2:4:4
1:4:4
2:4:2
1:4:1 1:2:4
2:2:1 1:2:4
2:4:1 1:2:2
1:2:2
g
g
g
g
gg
gg
gg
g
2048
g
Analytical
Hspice
8192
Markers:
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
32768
131072
Cache Size in bytes (B=16 bytes, A=1)
Figure 14: Direct mapped: Ttagside dm
optimum parameters are shown in the gures (the six numbers associated with each point
correspond to Ndwl , Ndbl, Nspd , Ntwl, Ntbl, and Ntspd in that order). The parameters were
then used in the Hspice model. As the graphs show, the dierence between the analytical
and Hspice results is less than 6% in every case.
6.2 Cycle Time
The dierence between the access and cycle time of a cache varies widely depending on
the circuit techniques used. Usually the cycle time is a modest percentage larger than the
access time, but in pipelined or post-charge circuits [7, 8] the cycle time can be less than
19
To appear in IEEE Journal of Solid State Circuits 1996
12ns
11ns
10ns
9ns
8ns
Data Side 7ns
(plus output 6ns
driver)
5ns
4ns
3ns
2ns
1ns
0ns
1:8:1
2:4:1 1:4:2
1:4:2
g
g
g
2:2:1
4:1:1 1:4:1
1:2:1
g
g
4:1:1
1:1:1
4:2:1
1:2:1
g
g
g
4:2:1
1:2:1
g
g
g
gg
g
g
2048
Analytical
Hspice
8192
Markers:
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
32768
131072
Cache Size in bytes (B=16 bytes, A=4)
Figure 15: 4-way set associative: Tdataside + Toutdrive data
14ns
13ns
12ns
11ns
10ns
9ns
8ns
Tag
7ns
Side
6ns
5ns
4ns
3ns
2ns
1ns
0ns
1:8:1
1:4:2
g
2:4:1
1:4:2
g
g
g
2:2:1
4:1:1 1:4:1
4:2:1 1:2:1
4:2:1 1:2:1
4:1:1 1:2:1
1:1:1
g
g
g
g
gg
gg
gg
g
2048
g
Analytical
Hspice
8192
Markers:
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
32768
131072
Cache Size in bytes (B=16 bytes, A=4)
Figure 16: 4-way set associative: Ttagside;sa
the access time. We have chosen to model a more conventional structure with the cycle
time equal to the access time plus the precharge.
There are three elements in our assumed cache organization that need to be precharged:
the decoders, the bitlines, and the comparator. The precharge times for these elements
are somewhat arbitrary, since the precharging transistors can be scaled in proportion to
the loads they are driving. We have assumed that the time for the wordline to fall and
bitline to rise in the data array is the dominant part of the precharge delay. Assuming
properly ratioed transistors in the wordline drivers, the wordline fall time is approximately
the same as the wordline rise time. It is assumed that the bitline precharging transistors are
20
To appear in IEEE Journal of Solid State Circuits 1996
scaled such that a constant (over all cache organizations) bitline charge time is obtained.
This constant will, of course, be technology dependent. In the model, we assume that this
constant is equal to four inverter delays (each with a fanout of four). Thus, the cycle time
of the cache can be written as:
Tcache = Taccess + Twordline delay + 4 (inverter delay)
7 Applications of the Model
This section gives examples of how the analytical model can be used to quickly gather data
that can be used in architectural studies.
7.1 Cache Size
First consider Figure 17. These graphs show how the cache size aects the cache access
and cycle times in a direct-mapped and 4-way set-associative cache. In these graphs (and
all graphs in this report), bo = 64 and baddr = 32. For each cache size, the optimum array
organization parameters were found (these optimum parameters are shown in the graphs
as before; the six numbers associated with each point correspond to Ndwl , Ndbl , Nspd , Ntwl,
Ntbl, and Ntspd in that order), and the corresponding access and cycle times were plotted.
In addition, the graph breaks down the access time into several components.
There are several observations that can be made from the graphs. Starting from the
bottom, it is clear that the time through the data array decoders is always longer than the
time through the tag array decoders. For all but one of the organizations selected, there
are more data subarrays (Ndwl Ndbl ) than tag subarrays (Ntwl Ntbl). This is because the
total tag storage is usually much less than the total data storage.
In all caches shown, the comparator is responsible for a signicant portion of the access
time. Another interesting trend is that the tag side is always the critical path in the
cache access. In the direct-mapped cases, organizations are found which result in very
closely matched tag and data sides, while in the set-associative case, the paths are not
matched nearly as well. This is due primarily to the delay driving select lines of the output
multiplexor.
21
To appear in IEEE Journal of Solid State Circuits 1996
Markers:
g
15ns
10ns
Time
5ns
g
`
`
`
`
.`. . . . . . . . .`
.
.
.
.
.
.
.
.
.
.
.
∇
∇.
f
f
f. . . . . . . . . . f.
∗
∗
∗. . . . . . . . . .∗.
†
†
†. . . . . . . . . .†.
Markers:
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
Cycle time
Access time
Data side
Tag side
Compare
Data bitline & sense
Tag bitline & sense
Data wordline
Tag wordline
Data decode
Tag decode
g
1:8:4
1:4:8
15ns
g
2:4:4
1:4:4
`.̀
..
.. ∇
.
2:4:4
.
.
. .
.. ..
1:4:4
.. ... `
.
g
.̀. .
2:4:2
. .`
` ..
f
. . ..
. . . .∇
1:4:1 1:2:4
.
. .. f
g
.
.
.̀.
1:2:4
. .` . .
2:2:1
. . ...
g
. . . .∇
`
. f.
.
2:4:1 1:2:2
.
..
.̀. . . .
g
.. ∗
. .`
.
`
.
.
.
.
1:2:2
.
.
f
.
..
.̀. . . . . .∇
. f.
g
. .`
f
..
.. ∗
...
...
.̀. . . . . .∇
..
.
`
.
.
`
.
†.
..
... `
.∗
...
..
`.̀ . . . . . . .∇
†. . . . . . .
f
f. .
f
`. . .
. . .∗
∗
.
.
∇
.
.
∗.
..
.
.... †
. f. .
f
..
...
†. . . . . . .†. . .
†
...
.
∗
.
.
.
.
.
f
.
.. ∗
..
...
∗ . . .∗f. . . . .
..
...
.
. . . ∗ . . . .†
.
†f. . . . †. . . . . . . .†
....
.
∗
.
.
. .†
. .∗
...
....
∗. . .. . . . . .†. . . . . . . .†. .
.
†.
g
`
`
`. . . . . . . . . .`.
∇. . . . . . . . . .∇.
f
f
f. . . . . . . . . . f.
∗
∗
∗. . . . . . . . . .∗.
†
†
†. . . . . . . . . .†.
Cycle time
Access time
Mux drv & sel inv
Compare
Data bitline & sense
Tag bitline & sense
Data wordline
Tag wordline
Data decode
Tag decode
g
10ns
Time
4:2:1
1:2:1
4:1:1
1:1:1
`
.̀
5ns
`
...
....
∇. . . . .
..̀ . .
g
2:4:1
1:4:2
g
g
`
...
.
...
. . .∇
.
. . .̀.
.
`
..
...
.
...
. . .∇
..
f
f
`
g
2:2:1
1:4:1
4:1:1
1:2:1
4:2:1
1:2:1
g
g
1:8:1
1:4:2
. .̀.
..
...
f. . . .
. .∇
.
g
`
`
.̀.
..
.
. . .̀.
..
.
..
.∇
... f
∗. . . . .
. . f.
.
f. .
. .∗
..
..
..
..
..
f. .
. .∇
f. .
.∗
..
..
.
..
.
..
.
..
..
.
..
..
..
..
..
.̀
.
.∇
f
. f.
∗
∗.
.†
† .....
.
.
..
.†
.∗
..
...
..
.
∗. . . . . †
..
†. . . .
..
.
. .∗
..
...
. .†
∗ . . . . . .†f
.....
...
.
.
.
∗
.
.
†
.
.
.
.
f
.
...... †
...
....
∗f.
...
. . . .∗
. . .†
....
....
. . . . .∗
.
.
.
.
.†
†
.
∗
..
....
. . .†
†. . . . .
f
0ns
0ns
4096
16384
65536
262144
Cache Size in bytes (B=16 bytes, A=1)
4096
16384
65536
262144
Cache Size in bytes (B=16 bytes, A=4)
a) direct-mapped
b) set-associative
Figure 17: Access/cycle time as a function of cache size
7.2 Block Size
Figure 18 shows how the access and cycle times are aected by the block size (the cache size
is kept constant). In the direct-mapped graph, the access and cycle times drop as the block
size increases. Most of this is due to a drop in the decoder delay (a larger block decreases
the depth of each array and reduces the number of tags required).
In the set-associative case, the access and cycle time begins to increase as the block size
gets above 32. This is due to the output driver; a larger block size means more drivers
share the same cache output line, so there is more loading at the output of each driver.
This trend can also be seen in the direct-mapped case, but it is much less pronounced. The
number of output drivers that share a line is proportional to A, so the proportion of the
total output capacitance that is the drain capacitance of other output drivers is smaller in
a direct-mapped cache than in the 4-way set associative cache. Also, in the direct-mapped
case, the slower output driver only aects the data side, and it is the tag side that dictates
22
To appear in IEEE Journal of Solid State Circuits 1996
g
15ns
10ns
Time
5ns
g
`
`
`
`
`. . . . . . . . . . . .`.
∇. . . . . . . . . . . .∇.
f
f
f. . . . . . . . . . . . f.
∗
∗
∗. . . . . . . . . . . . ∗.
†
†
†. . . . . . . . . . . . †.
Cycle time
Access time
Data side
Tag side
Compare
Data bitline & sense
Tag bitline & sense
Data wordline
Tag wordline
Data decode
Tag decode
Markers:
Markers:
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
g
15ns
g
`
`
`. . . . . . . . . . . .`.
∇. . . . . . . . . . . .∇.
f
f
f. . . . . . . . . . . . f.
∗
∗
∗. . . . . . . . . . . . ∗.
†
†
†. . . . . . . . . . . . †.
4:2:1
1:4:1
2:4:2
1:4:4
g
2:4:2
1:2:4
10ns
Time
1:4:1
g
`
.̀ . . . . .
......
∇f. . . . . . .
5ns
0ns
`
.̀. . . . . . .
4:2:1
1:2:1
4:2:1
1:2:1
8:1:1
1:4:1
g
g
1:2:4
`.̀ . . . .
2:2:1
1:4:1
g
1:2:2
`. . . . . . . . . .
∇
.
.
1:2:2
g
f . . . . . .`.̀. . . . .
....
...
g
∇
`. . . . . . . . . .`.̀. . . . .
....
....
.
.
.
f
∇
`. . . . . . . . . . . .`.̀. . . . . . . . . . .
.∇
. .̀
∗
f
f. . . . . . . . . . . .`
`.
.†
f. .. . .. ..
∇
. . .∗
f. . . . . . .
f
....
. f. . . . .
∗ . . . . . . .∗. .
∗. . . . . . . . . †
f ....... ∗
.....
....
†. . . . . . . . . ∗ . . . . . . . . . .†
f
∗. . . . . . . . . . . .†
.....
∗. . . . . . . . . . . .
† .........
†.
∗
.†
. . . . . . . . . . . .†
........
.....
†
Cycle time
Access time
Mux drv & sel inv
Compare
Data bitline & sense
Tag bitline & sense
Data wordline
Tag wordline
Data decode
Tag decode
g
g
`
`
. . . . . .̀. . . .
f
....
.∇
....
....
4:1:1
1:1:1
g
`
. . . . . . . . .̀. . . . . . . . . . . . .̀
.
....
∇. . . . . . . .
∗
......
f
∇f . . . . . . . . . .
†
∇
....
. f. . . .
f
.....
. . .∗
f. . . . . . . . . ∗
∗. . . . . . . . . . .
.
†
. . f. . . . .
.∗
.....
.....
† . . . . . . .∗f.
....
†. . . . . . . . . . . .
†. . . . . . . . . . ∗ . . . . . . . . . .∗. . . . . . . . . . . .
. .†
†.
.........
∗
. . .†
..........
. .†
.
∗
†f. . . . . . .
0ns
4
8
16
32
64
4
Block Size in bytes (C=16 Kbytes, A=1)
8
16
32
64
Block Size in bytes (C=16 Kbytes, A=4)
a) direct-mapped
b) set-associative
Figure 18: Access/cycle time as a function of block size
the access time in all the organizations shown.
7.3 Associativity
Finally, consider Figure 19 which shows how the associativity aects the access and cycle
time of a 16KB and 64KB cache. As can be seen, there is a signicant step between a
direct-mapped and a 2-way set-associative cache, but a much smaller jump between a 2way and a 4-way cache (this is especially true in the larger cache). As the associativity
increases further, the access and cycle time begin to increase more dramatically.
The real cost of associativity can be seen by looking at the tag path curve in either
graph. For a direct-mapped cache, this is simply the time to output the valid signal, while
in a set-associative cache, this is the time to drive the multiplexor select signals. Also, in
a direct-mapped cache, the output driver time is hidden by the time to read and compare
the tag. In a set-associative cache, the tag array access, compare, and multiplexor driver
23
To appear in IEEE Journal of Solid State Circuits 1996
Markers:
g
15ns
Cycle time
Access time
Tag Path
Compare
Data bitline & sense
Tag bitline & sense
Data wordline
Tag wordline
Data decode
Tag decode
g
`
`
`. . . . . . . . . . `.
∇. . . . . . . . . .∇.
f
f
f. . . . . . . . . . f.
∗
∗
∗. . . . . . . . . . ∗.
†
†
†. . . . . . . . . . †.
8:1:1
1:2:2
10ns
Time
g
1:4:1
1:2:4
`
g
.
..
5ns
4:2:1
1:2:1
..
..
..
.
`
...
.̀. . . . . . . . . . .̀. . . . .
g
g
`
4:1:1
1:1:1
15ns
`
`
`. . . . . . . . . . `.
∇. . . . . . . . . .∇.
f
f
f. . . . . . . . . . f.
∗
∗
∗. . . . . . . . . . ∗.
†
†
†. . . . . . . . . . †.
g
`
`
.
. . .̀.
. . .̀. .
f
...
...
..
..
. .∇
..
..
..
..
.
.
..
..
.
..
..
..
. .̀
2:4:1
1:4:2
Time
10ns
∇.
..
2:4:4
1:4:4
g
.
. f.
.
`.̀
..
...
..
∇. . . . . . . . . .∇. . . . . . . . . .∇. . . . . . . . . .∇. . . .
..
.
∗
f
..
f.
f
.∗
..
f
..
†
..
.
..
f
.
.. f
..
.
∗
.
.
∗
..
...
..
∗f. . . . . . . . . . f. . . . . . . . . .†f. . . . . . . . . .∗f.
..
. .∗
†
.
.
∗
.
† ..
†
∗. . . . . . . . . .∗. . . . . . . . . .∗. . . . . . . . . .∗. . .
†
†. . . . . . . . . .†. . . . . . . . . .†. . . . . . . . . . . . . .
† . . . . . .†. . . . . . . . . .†.
5ns
0ns
..
...
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
4:1:1
1:1:1
Cycle time
Access time
Tag Path
Compare
Data bitline & sense
Tag bitline & sense
Data wordline
Tag wordline
Data decode
Tag decode
g
g
4:2:1
1:2:1
g
Markers:
Ndwl:Ndbl:Nspd
Ntwl:Ntbl:Ntspd
8:1:1
1:1:1
..
2:2:1
1:4:1
g
g
`
`
g
`
2:1:1
1:2:1
g
2:2:1
1:2:1
g
`
`
. .̀. . . . . . . . . . .̀. . . . . . . . . . .̀.
...
. . .̀.
....
..
..
.
..
.
..
.
..
..
..
..
..
. .̀
∇
..
.
`.̀ .
..
.
. .∇
. .f
∇. . . . . . . . . . f. . . . . . . . . . . . . . . . . . . . . . . . .
..
∇
.∇
∇
.f .
..
.
.
f
..
f . . . . . f. . .
f.
∗
.
.∗
.
.....
..
..
∗f. . . . . . . . . .†f. . . . . . . . . .∗f. . . . . . . . f
.
.
..
∗
..
. .∗
†
.... ∗
†. . . . . . . . . .∗
∗. . . . . . . . . .∗. . . . . . . . . .∗
.∗. . .
†. . . . . . . . . .†. . . . . . . . . .†. . . . . . . . . †
†
.†
. . . . . . . . . .†
†. . . . . . . . . .†.
0ns
1
2
4
8
16
32
1
Associativity (C=16 Kbytes, B=16 bytes )
2
4
8
16
32
Associativity (C=64 Kbytes, B=16 bytes)
a) 16KB cache
b) 64KB cache
Figure 19: Access/cycle time as a function of associativity
must be completed before the output driver can begin to send the result out of the cache.
Looking at the 16KB cache results, there seems to be an anomaly in the data array
decoder at A = 2. This is due to a larger Ndwl at this point. This doesn't aect the overall
access time, however, since the tag access is the critical path.
8 Conclusions
In this paper, we have presented an analytical model for the access and cycle time of a
cache. By comparing the model to an Hspice model, CACTI was shown to be accurate to
within 6%. The computational complexity, however, is considerably less than Hspice.
Although previous models have also given results close to Hspice predictions, the underlying assumptions in previous models have been very dierent from typical on-chip cache
memories. Our extended and improved model xes many major shortcomings of previous
24
To appear in IEEE Journal of Solid State Circuits 1996
models. Our model includes the tag array, comparator, and multiplexor drivers, non-step
stage input slopes, rectangular stacking of memory subarrays, a transistor-level decoder
model, column-multiplexed bitlines, an additional array organizational parameter and loaddependent transistor sizes for wordline drivers. It also produces cycle times as well as access
times. This makes the model much closer to real memories.
It is dangerous to make too many conclusions directly from the graphs without considering miss rate data. Figure 19 seems to imply that a direct-mapped cache is always the
best. While it is always the fastest, it is important to remember that the direct-mapped
cache will have the lowest hit-rate. Hit rate data obtained from a trace-driven simulation
(or some other means) must be included in the analysis before the various cache alternatives
can be fairly compared. Similarly, a small cache has a lower access time, but will also have
a lower hit rate. In [9], it was found that when the hit rate and cycle time are both taken
into account, there is an optimum cache size between the two extremes.
Appendix A: Obtaining and Using the CACTI Software
A program that implements the CACTI model described in this paper is available. To
obtain the software, log into gatekeeper.dec.com using anonymous ftp (use \anonymous"
as the login name and your machine name as the password). The les for the program
are stored together in \/archive/pub/DEC/cacti.tar.Z". Get this le, \uncompress" it, and
extract the les using \tar".
The program consists of a number of C les; time.c contains the model. Transistor
widths and process parameters are dened in def.h. A makele is provided to compile the
program.
Once the program is compiled, it can be run using the command:
cacti C B A
where C is the cache size (in bytes), B is the block size (in bytes), and A is the associativity.
The output width and internal address width can be changed in def.h.
When the program is run, it will consider all reasonable values for the array organization
parameters (discussed in Section 3) and choose the organization that gives the smallest
access time. The values of the array organization parameters chosen are included in the
output report.
25
To appear in IEEE Journal of Solid State Circuits 1996
The extended description of model details is available on the World Wide Web at URL
\http://nsl.pa.dec.com/wrl/techreports/93.5.html#93.5".
Acknowledgements
The authors wish to thank Stefanos Sidiropoulos, Russell Kao, and Ken Schultz for their
helpful comments on various drafts of the manuscript. Financial support was provided
by the Natural Sciences and Engineering Research Council of Canada and the Walter C.
Sumner Memorial Foundation.
References
[1] J. M. Mulder, N. T. Quach, and M. J. Flynn, \An area model for on-chip memories and
its application," IEEE Journal of Solid-State Circuits, Vol. 26, No. 2, pp. 98{106, Feb.
1991.
[2] T. Wada, S. Rajan, and S. A. Przybylski, \An analytical access time model for on-chip
cache memories," IEEE Journal of Solid-State Circuits, Vol. 27, No. 8, pp. 1147{1156,
Aug. 1992.
[3] S. J. Wilton and N. P. Jouppi, \An access and cycle time model for on-chip caches,"
Tech. Rep. 93/5, Digital Equipment Corporation Western Research Lab, 1994.
[4] M. A. Horowitz, \Timing models for mos circuits," Tech. Rep. Technical Report SEL83003, Integrated Circuits Laboratory, Stanford University, 1983.
[5] J. Rubinstein, P. Peneld, and M. A. Horowitz, \Signal delay in RC tree networks,"
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, Vol.
2, No. 3, pp. 202{211, July 1983.
[6] M. G. Johnson and N. P. Jouppi, \Transistor model for a synthetic 0.8um CMOS process," Class notes for Stanford University EE371, Spring 1990.
[7] R. J. Proebsting, \Post charge logic permits 4ns 18K CMOS RAM." 1987.
[8] T. I. Chappell, B. A. Chappel, S. E. Schuster, J. W. Allen, S. P. Klepner, R. V. Joshi, and
R. L. Franch, \A 2ns cycle, 3.8ns access 512kb CMOS ECL RAM with a fully pipelined
architecture," IEEE Journal of Solid-State Circuits, Vol. 26, No. 11, pp. 1577{1585,
Nov. 1991.
[9] N. P. Jouppi and S. J. Wilton, \Tradeos in two-level on-chip caching," in Proceedings of
the 21th Annual International Symposium on Computer Architecture, pp. 34{45, April
1994.
26