area efficient implementation of gf (2 ) multipliers for finite fields
advertisement
 multipliers for finite fields")
International Journal of Electrical, Electronics and Data Communication, ISSN: 2320-2084
Volume-2, Issue-5, May-2014
M
AREA EFFICIENT IMPLEMENTATION OF GF (2 ) MULTIPLIERS
FOR FINITE FIELDS
1
SONIA SOPHIA JOSEPH, 2S PRAKASH
1
PG Scholar, Applied Electronics, Jerusalem College of Engineering, Chennai, India.
2
Professor, E.C.E Department, Jerusalem College of Engineering, Chennai, India.
Email: soniasjoseph@gmail.com, prakash.sav4@gmail.com
Abstract— Galios field arithmetic have many applications in cryptography and other fields. Multiplication is the most
expensive operation in Galios field. Multipliers for Galios Field, GF (2m) have wide applications in Cryptography and error
control coding systems. The existing multipliers for Galios Field require large area and time complexity, which is
undesirable for real time applications. This paper presents an area-time efficient systolic structure for multiplication over GF
(2m) based on irreducible all-one polynomial (AOP). A novel cut-set retiming is used to reduce the critical path to one XOR
delay. The systolic structure can be further divided into two or more parallel branches to reduce the delay. The multiplier is
synthesized using Verilog HDL. Area can be further reduced using a novel register sharing technique. The result shows that
this multiplier has reduced area-time complexity than the existing multipliers.
Keywords—All One Polynomial, Finite Field, Systolic Design, Verilog HDL
I.
the critical delay. Using cut set retiming we can
introduce certain number of delays on all the edges in
one direction of any cut-set of a signal flow-graph
(SFG) by removing equal number of delays on all
the edges in the reverse direction of the same cut-set. It
is useful for pipelining digital circuits. This systolic
multiplier can be divided into two or more parallel
branches for reducing the delay. These parallel
branches share the same input. The area can be
further reduced by using a novel register sharing
technique. In this technique a shared register is used
for two processing elements that share the same input
operand.
This paper presents an area- time efficient systolic
structure for multiplication over GF (2m) based on all
one polynomial. The multiplier is synthesized using
Verilog HDL. The logic verification is done using
Modelsim 6.4e and the result is compared with the
existing designs.
INTRODUCTION
finite field multipliers over GF (2m) have many
applications cryptography and error control coding
system such as Reed-Solomon codes. In elliptical
curve cryptography (ECC) and many other
cryptographic applications finite field multipliers are
used. Efficient hardware design for polynomialbased multiplication is important for real-time
applications. All-one polynomial (AOP) is an
irreducible polynomial for efficient implementation
of finite field multiplication. Since AOP-based
multipliers are simple and regular, a number of works
have been done on its efficient realization. AOPbased fields could also be used for efficient
implementation of Reed-Solomon encoders. Since
irreducible AOPs are not abundant nearly AOP
(NAOP) is also used for the implementation of
finite field multipliers. Also, the AOP-based
architectures are also used as a kernel circuit for
exponentiation, inversion, and division architectures.
Systolic design is a preferred hardware for finite field
multipliers because of its high level of pipeline
ability, local connectivity and many other
advantageous features. Systolic array consists of a
network of processing elements. A digit serial
systolic
multiplier
based
on
Montgomery
multiplication algorithm was proposed in. In some
papers bit-parallel implementation of finite field
multipliers are synthesized based on AOP. In systolic
design only local interconnections exists. It provides
high throughput rates.
Systolic structure provides pipeline ability, but it has
two major disadvantages. The first is, systolic
structure consumes large area and power. Second is,
the latency is high for systolic design. If the order of
the field is m, then its latency is nearly m cycles. This
makes it undesirable for real time applications. A
novel cut set retiming is used in this paper to reduce
II.
ALGORITHM
Let f(x) =xm+xm-1+…+x+1 is an irreducible AOP of
degree m over GF (2). The set {m+1,m-2,….,1}
forms the polynomial basis (where is a root of f(x)
), such that an element X of the binary field can be
given by
X=Xm-1m-1+Xm-2m-2+…+X1+X0, where XiGF (2)
for i=m-1… 2, 1, 0.
Since is a root of f(x),
f()=0,and
f()+f()=(m+m-1+….++1)+
(m+m1
m+1
+….++1) = +1=0
Therefore, we have m+1=1
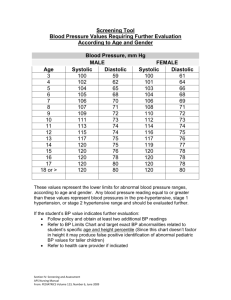
This property of All one polynomial is used for the
multiplication of GF (2m) to reduce the complexity as
discussed in the following.
Area Efficient Implementation of GF (2m) Multipliers for Finite Fields
16
International Journal of Electrical, Electronics and Data Communication, ISSN: 2320-2084
Volume-2, Issue-5, May-2014
A=
j B=
j C =
j
,
Where aj bj, cj GF (2), for 0<= j <= m-1, and am=0,
bm=0, cm=0 If C is the product of elements.
…………………………….. .. (1)
Xi=bi*Ai …………………………………….. (2)
Ai+1=a0i+1 + a0i+1+ a1i+1.α+…..+ ami+1.αm …… (3)
The systolic implementation of multiplication over
GF (2m), the operations of (1), (2) and (3) can be
performed recursively. Each recursion is composed of
three steps, i.e., bit-addition of (1), bit-multiplication
of (2), and modular reduction of (3).
III.
Fig. 2. Cut-set retiming of the SFG. (a) Cut-set retiming in a
general way. (b) Proposed cut-set retiming. (c) Formation of PE.
“D” denotes unit delay.
The regular PE consists of bit shift cell (BSC),
addition cell and XOR cell. Bit shift cell performs
modular reduction operation and XOR cell performs
addition. The bit multiplication is done using AND
cell. The AND cell and the XOR cell consists of
(m+1) AND and XOR gates working in parallel.
The systolic multiplier produces the first output
(m+2) cycles after the first input is fed into it.
SYSTOLIC MULTIPLER DESIGN
A.
Basic systolic multiplier design
The systolic multiplier performs the operations of bit
addition (1), bit multiplication (2) and modular
reduction (3) recursively. This can be represented by
the SFG as in Fig.1.
Fig. 3. Proposed systolic structure.
Fig. 3 (b) Regular PE
Fig. 1. SFG of the algorithm. (a) The SFG. (b) Function of
node R(i). (c) Function of node M(i) . (d) Function of node A(i).
The node M (i) performs multiplication, A (i)
performs addition and R(i) performs modular
reduction operations. The proposed cut set retiming is
shown in Fig.2. The critical path is TA+TX in Fig 2(a),
where TA and TX are the propagation delay of AND
and XOR gates. The bit reduction node does not
perform any computation, therefore does not involve
any time consumption. Using the proposed cut set
retiming, the operations of (1), (2) and (3) can be
performed simultaneously. So the critical delay is
reduced to max (TA,TX). The processing elements
(PE) are formed based on the proposed cut set
retiming. The Fig 2(c) shows the formation of PE.
The basic systolic design is shown in Fig 3. This
multiplier has (m+2) PE. The structure of regular PE
is shown in Fig 3(d). It performs bit addition, bit
multiplication and modular reduction concurrently.
The PE and PE perform multiplication and modular
reduction only.
Fig. 4. Structure of PEs. (a) Internal structure of a regular PE. (b)
Internal struc- ture of PE[0] (c) An example of AND cell for
m=4. (d) Structure of the AC. (e) Structure of BSC . (f)
Alternate structure of a regular PE. (g) Alternate structure of
PE.
B.
Low latency systolic multiplier design
The systolic structure for multiplication can be
divided into two parallel branches
using the
equation to get the low latency systolic multiplier.
C=
+
Area Efficient Implementation of GF (2m) Multipliers for Finite Fields
17
International Journal of Electrical, Electronics and Data Communication, ISSN: 2320-2084
One of the sum contains [(m/2) +1] partial products
while the other has m/2 partial products. The low
latency systolic multiplier is shown in Fig 5. The
upper branch consists of [(m/2) +2] PE and the lower
branch consists of (m/2+1) PEs and a delay cell.
Besides, an addition-cell (AC) is required to perform
the final addition of the outputs of the two systolic
arrays.
Volume-2, Issue-5, May-2014
CONCLUSION
An area time efficient systolic design for the
multiplication over GF(2m) based on irreducible AOP
is proposed. By novel cut-set retiming we have been
able to reduce the critical path to one XOR gate
delay and a low latenc y bit-parallel systolic
multiplier is derived. Compared with the existing
systolic structures for bit-parallel realization of
multiplication over GF(2m), the proposed one requires
lesser area, shorter critical path and lower latency. The
proposed design can be improved using register
sharing technique to further reduce the latency.
REFERENCES
Fig. 5. Proposed low latency systolic structure. (a) The
systolic structure. (b) Function of the AC.
[1]
The low latency systolic structure consumes the same
space complexity as the systolic multiplier but the
delay is reduced to (m/2+3).
IV.
[2]
[3]
SIMULATION RESULTS
The simulation result for the area efficient systolic
structure for multiplication in GF (2m) is obtained
using modelsim 6.4c. The design is coded using
Verilog HDL. The value of m is chosen as 6 GF
(26). The proposed structure require (m+3) PE and an
addition cell. The latency of the design is (m/2+3)
cycles, where the duration of the clock-period is TX.
The simulation output of systolic multiplier for GF
(26) is shown in Fig 6.
[4]
[5]
[6]
[7]
[8]
[9]
[10]
Fig. 6. Simulation output of systolic multiplier GF (26)
[11]
The simulation output of low latency systolic
multiplier for GF (26) is shown in Fig 7.
[12]
[13]
[14]
Fig. 7. Simulation output of low latency systolic multiplier GF
(26)
M. Ciet, J. J. Quisquater, and F. Sica, “A secure family of
composite finite fields suitable for fast implementation of
elliptic curve cryptography,” in Proc. Int. Conf. Cryptol.
India, 2001, pp. 108–116.
H. Fan and M. A. Hasan, “Relationship between GF(2m)
Montgomery and shifted polynomial basis multiplication
algorithms,” IEEE Trans. Computers, vol. 55, no. 9, pp.
1202–1206, Sep. 2006.
C.L.Wang and J.L. Lin, “Systolic array implementation of
multipliers for finite fields GF(2m) ,” IEEE Trans. Circuits
Syst., vol. 38, no. 7, pp. 796–800, Jul. 1991.
B. Sunar and C. K. Koc, “Mastrovito multiplier for all
trinomials,” IEEE Trans. Comput., vol. 48, no. 5, pp. 522–
527, May 1999.s
C. H. Kim, C.-P. Hong, and S. Kwon, “A digit-serial
multiplier for finite field GF(2m) ,” IEEE Trans. Very Large
Scale Integr. (VLSI) Syst., vol. 13, no. 4, pp. 476–483,
2005.
C. Paar, “Low complexity parallel multipliers for Galois
fields based on s GF(2m) special types of primitive
polynomials,” in Proc. IEEE Int. Symp. Inform. Theory,
1994, p. 98.
H. Wu, “Bit-parallel polynomial basis multiplier for new
classes of finite fields,” IEEE Trans. Computers, vol. 57, no.
8, pp. 1023–1031, Aug. 2008.
S. Fenn, M.G. Parker,M. Benaissa, and D. Taylor, “Bitserial multiplication in GF(2m) using all-one polynomials,”
IEE Proc. Com. Digit. Tech., vol. 144, no. 6, pp. 391–393,
1997.
K.Y. Chang, D. Hong, and H.S. Cho, “Low complexity bitparallel multiplier for GF(2m)
defined by all-one
polynomials using redundant representation,” IEEE Trans.
Computers, vol. 54, no. 12, pp. 1628–1629, Dec. 2005.
H.S. Kim and S.W. Lee, “LFSR multipliers over GF(2m)
defined by all-one polynomial,” Integr., VLSI J., vol. 40,
no. 4, pp. 571–578, 2007.
P. K. Meher, Y. Ha, and C.Y. Lee, “An optimized design of
serial-parallel finite field multiplier for GF(2m) based on
all-one polynomials,” in Proc. ASP-DAC, 2009, pp. 210–
215.
M. Sandoval, M. F. Uribe, and C. Kitsos, “Bit-serial and
digit-serial GF(2m) montgomery multipliers using linear
feedback shift registers,” IET Comput. Digit. Tech., vol. 5,
no. 2, pp. 86–94, 2011.
C.Y. Lee, E.H. Lu, and J.Y. Lee, “Bit-parallel systolic
multipliers for GF(2m) fields defined by all-one and equally
spaced polynomials,” IEEE Trans. Computers, vol. 50, no.
6, pp. 385–393, May 2001.
Y.R. Ting, E.H. Lu, and Y.C. Lu, “Ringed bit-parallel
systolic multipliers over a class of fields GF(2m) ,” Integr.,
VLSI J., vol. 38, no. 4, pp. 571–578, 2005.
[15]
C.-Y. Lee, J.S. Horng, I.C. Jou, and E.H. Lu,
“Low-complexity
bit-parallel
systolic
montgomery
ultipliers for special classes of GF(2m),” IEEE Trans.
Computers, vol. 54, no. 9, pp. 1061–1070, Sep. 2005.
Area Efficient Implementation of GF (2m) Multipliers for Finite Fields
18