VTLN Based Approaches for Speech Recognition with Very
advertisement

2014 Fifth International Conference on Intelligent Systems, Modelling and Simulation
VTLN Based Approaches for Speech Recognition
with Very Limited Training Speakers
Sung Min Ban, Bo Kyung Choi, Young Ho Choi, Hyung Soon Kim
Department of Electronics Engineering
Pusan National University
Busan, South Korea
Email: {bansungmin, choibok15, choiyh, kimhs}@pusan.ac.kr
techniques have been proposed, and they include maximum a
posteriori (MAP) adaptation [7], maximum likelihood linear
regression (MLLR) adaptation [8] and speaker clulstering
based adaptation such as eigenvoice approach [9]. Eigenvioice adaptation is known to be a fast speaker adaptation
because it needs to estimate only a small number of parameters to describe a particular speaker.
VTLN, one of the speaker normalization techniques, reduces the acoustic mismatch caused by different speakers
by normalizing the length of vocal tract of each speaker.
Unlike the speaker adaptation techniques mentioned above,
VTLN does not usually require additional adaptation data
from the test speaker, which is a strong point in deploying
the technique in real-world applications.
Due to vocal tract length, intrinsic property of speaker,
positions of spectral formant peaks of speech are changed
according to speaker [10]. More specifically the positions
of formant peaks are inversely proportional to the vocal
tract length, which results in the acoustic mismatch. In
VTLN, normalization of the vocal tract length is performed
by optimally warping the frequency axis in the process
of feature extraction, and thereby compensating for the
differences of speaker characteristics.
In this paper, two approaches using VTLN are examined
to deal with the acoustic mismatch due to different speakers
in automatic speech recognition for the special case that
the training data is available only for a small number of
speakers. Target application of this special case is speech
recognition for resource-limited languages, where obtaining
sufficient speech data to build SI models is either not feasible
or very difficult and costly.
This paper is organized as follows: In Section 2, conventional VTLN method is introduced and building a virtually
SI acoustic model is described in Section 3. Finally, the
performance of the two described algorithms are evaluated
in Section 4, and the conclusion of this paper is drawn.
Abstract—In this paper, two approaches using vocal tract
length normalization (VTLN) are examined to deal with the
acoustic mismatch due to different speakers in automatic
speech recognition for the special case that training data is
available only for a small number of speakers. One is the
conventional VTLN approach in which both training and test
utterances are frequency warped according to the maximum
likelihood (ML) based warping factor estimation scheme, in
order to normalize the speaker characteristics. The other approach is to build a virtually speaker-independent (SI) acoustic
model using artificially generated multiple speaker data by
VTLN based frequency warping of training utterances from
the limited speakers. To compare the performance of the two
approaches, Korean isolated word recognition experiments are
performed with a small amount of training data from limited
speakers. The experimental results show that the virtually SI
acoustic model approach yields better performance than both
the conventional VTLN approach and the baseline system in
case of very limited training speakers.
Keywords-speech recognition; vocal tract length normalization
I. I NTRODUCTION
Mismatch between training and test environments degrades the speech recognition performance. Among the
sources of such mismatch, additive noise, channel distortion,
inter-speaker variability and speaking rate are included.
There are many studies to alleviate these discrepancies.
To enhance the speech signals contaminated by additive
noise, Wiener filter and spectral subtraction methods are
widely used [1], [2]. These techniques guarantee a reliable
performance in the stationary noises. Cepstral mean normalization (CMN) is a very simple and powerful tool to
remove short-term convolutional channel distortion [3] and
can be combined with other temporal modulation filtering
methods [4]. There are only a few researches trying to
normalize speaking rate, and recently multiple acoustic modeling method was proposed [5], where multiple feature sets
were generated from various speaking rate by continuous
frame rate normalization technique [6].
In this paper, we focus on the issue to reduce the
mismatch introduced by inter-speaker variability. To reduce
this mismatch, various speaker adaptation and normalization
2166-0662/14 $31.00 © 2014 IEEE
DOI 10.1109/ISMS.2014.55
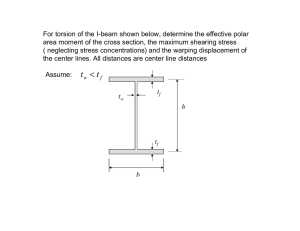
II. C ONVENTIONAL VTLN METHOD
In the process of VTLN, warping factor is estimated to
normalize the acoustic mismatch due to difference of vocal
285
(a)
(b)
Figure 1. Warping functions (a) piece-wise linear warping function (b)
bilinear warping function
tract lengths of each speaker, and then frequency axis is
scaled according to this warping factor in feature extraction.
Using warped features from training data, the normalized
acoustic model is built and test data is also normalized by
estimated warping factor to match the normalized acoustic
model. The following equations represent two commonly
used warping functions: piece-wise linear warping function
[11] and bilinear warping function [12].
αω
if ω < ω0
ω̃ =
(1)
bω + c if ω ≥ ω0
ω̃ = ω + 2tan−1 (
(1 − α)sin(ω)))
)
1 − (1 − α)cos(ω)
Figure 2.
λ and transcription wu to equation (3), and feature vector is
normalized using estimated warping factor. After normalized
model λN with warped features is obtained, then λ is
substituted by λN in equation (3), and this process is iterated
until no additional changes in the estimated warping factors
are observed. Block diagram describing the VTLN based
speech recognition method is shown in Fig. 2. To estimate
warping factor for test data, transcription for test utterance
is required and it is obtained from the 1st-pass speech
recognition step using the unwarped feature vectors. Among
the possible warping factors in the acceptable range, the
optimal warping factor is chosen to maximize the likelihood
of the warped feature vectors. Then, final (or 2nd-pass)
recognition result is determined using the feature vectors
warped with optimal warping factor.
(2)
Here, α is the warping factor representing speaker characteristics, and ω̃ is the transformed frequency from unwarped
freqeuncy ω. ω0 is a fixed value to control the bandwidth
mismatching problem, and values b, and c, can be calculated with ω0 . In equation (2), bilinear warping function
is depends only warping factor and is nonlinear function
contrary to the piece-wise linear function. Fig. 1 shows the
piece-wise linear warping function and the bilinear warping
function. In Fig 1(a), α > 1.0 corresponds to compressing
the spectrum, and α < 1.0 corresponds to stretching the
spectrum, and α = 1.0 corresponds to no warping case. The
same is true for the bilinear warping function in Fig. 1(b),
and it is known that α = 0.42 corresponds to the Mel scale
warping.
In maximum likelihood (ML) method, the optimal warping factor is obtained by maximizing likelihood function as
follows:
u
α̂i = argmax p(xα
i |λ, w )
α
VTLN based speech recognition [10]
III. V IRTUALLY SI ACOUSTIC MODEL
In the case of speech recognition for resource-limited
language, it is difficult to guarantee a stable recognition
performance over a variety of test speakers. Employing
the conventional VTLN method can resolve the problem
to a certain extent. Alternatively, we can approach to this
problem by virtually building SI acoustic model. Generally,
in order to build the SI model, speech data from many
speakers are required, but it may not feasible or very costly
for resource-limited languages. In this paper, instead of
collecting large amount of speech data from many speakers,
a method to build a virtually SI model is proposed to ensure
(3)
Here, xα
i is the feature vectors of speaker i normalized
by warping factor α and wu denotes the transcription of
unwarped feature vectors xi . In training stage, warping
factor α̂i is estimated by applying unwarped acoustic model
286
Table I
Performance of the VTLN based speech recognition with respect to the
normalized acoustic model
8000
7000
6000
Iteration
1
2
3
4
5
Counts
5000
4000
3000
Unwarped test data
82.40
82.57
82.28
80.41
79.86
Warped test data
82.53
83.22
83.61
82.94
83.07
2000
A. Conventional VTLN method
1000
0
In the VTLN based speech recognition process, optimal
warping factor for each speaker is chosen from a set of 13
factors evenly spaced over the range from 0.88 to 1.12 [10].
Fig. 3 represents the distribution of the estimated warping
factor from the test data. These various warping factors
are normalized properly by conventional VTLN. Table 1
shows the speech recognition performance of the VTLN
based speech recognition according to the number of training
iterations. As expected, warping both the training and the
test data shows better performance than warping training
data only. In the case of using the warped test data, best
performance is observed at 3th iteration.
0.88 0.90 0.92 0.94 0.96 0.98 1.00 1.02 1.04 1.06 1.08 1.10 1.12
Warping factor
Figure 3.
Distribution of the estimated warping factor
the diversity of acoustic characteristics of various speakers.
For this purpose, a number of feature sets are extracted
according to multiple warping factors to cover the variety
of speaker characteristics, and then they are used to build
the SI model. The range of warping factors for speaker i is
defined as
max[αmin , α̂i − β] ≤ αiSI ≤ min[αmax , α̂i + β]
B. Virtually SI acoustic model
In training of virtually SI acoustic model, 13 warping
factors are applied to each utterance in the process of feature
extraction. The range of warping factors are bounded by
αmin = 0.8, αmax = 1.2 in equation (4). Fig. 4 shows the
speech recognition performance for the virtually SI acoustic
(4)
Here, α̂i is the optimal warping factor of speaker i which is
obtained from equation (3) and various αiSI values within
this range is applied to building the virtually SI acoustic
model. 2β represents the range of possible warping factor,
and αmin and αmax are the lower and upper limits of the
warping factors, respectively, to prevent excessive warping.
86.5
Virtually SI model
86
Conventional VTLN
IV. E XPERIMENTAL RESULTS
Baseline
85.5
Recognition rate (%)
We compare the virtually SI model with conventional
VTLN method. To evaluate the performance of these methods, Korean isolated word recognition experiment is performed. Phonetically optimized words (POW) DB [13] and
phonetically balanced words (PBW) DB [14] are used for
training and test, respectively. To construct the very limited
training DB set from POW DB, only 4 female and 4 male
speakers are randomly selected. PBW DB contains 452
words from 32 female and 38 male speakers and about
31,000 utterances are used for test. Hidden Markov model
(HMM) based acoustic model is trained and each model
has 3 states with 6 mixtures. There are 150 tied-states
using tree-based clustering (TBC) in case of baseline system.
We get 39-dimensional Mel-frequency cepstral coefficients
(static:13,delta:13,delta-delta:13) with C0.
85
84.5
84
83.5
83
82.5
82
0.04
Figure 4.
287
0.08
0.12
β
0.16
0.20
Performance of virtually SI model method according to β
model according to β assuming α̂i = 1.0. As shown in this
figure, the best result is obtained at β = 0.2 and it has better
performance than both the baseline acoustic model and the
VTLN based speech recognition with error rate reduction of
18.5% and 15.0%, respectively.
[10] L. Lee and R. Rose, “A frequency warping approach to
speaker normalization,” IEEE Trans. on Speech and Audio
Processing, vol. 6, no. 1, pp. 49-59, Jan. 1998.
[11] L. E Uebel and P. C. Woodland, “An investigation into vocal
tract length normalization,” in Proc. of the EUROSPEECH99,
Budapest, Hungary, 1999.
[12] A. Acero and R. M. Stem, “Robust speech recognition by
normalization of the acoustic space,” in Proc. of the ICASSP91,
Toronto. Canada, 1991.
[13] Y. Lim and Y. Lee, “Implementation of the POW (phonetically optimized words) algorithm for speech database,” in
International Conference on
[14] Y.-J Lee, B.-W. Kim, J.-J Kim, O.-Y. Yang, and S.-Y. Lim,
“Some considerations for construction of PBW set,” in Proc.
of the 12th Workshop on Speech Communications and Signal
Processing. Acoustical Society of Korea, pp. 310-314. June
1995.
V. C ONCLUSION
In this paper, two approaches using VTLN are examined
to deal with mismatch introduced by inter-speaker variability
when training data is available only for a small number of
speakers. The experimental results show that the virtually
SI acoustic model approach yields better performance than
the conventional VTLN approach in case of very limited
training speakers. As a future work, in order to improve the
performance of the virtually SI acoustic model for resourcelimited language, it will be examined to use warping factor
according to the ML based measure of reliability with
respect to the acoustic model in building virtually SI acoustic
model.
ACKNOWLEDGMENT
This work was supported by the Quality of Life Technology development program 10036438, ”Development of
speech synthesizer and AAC software for the visually and
vocally impaired” funded by the Ministry of Trade, Industry
and Energy of Korea.
R EFERENCES
[1] J. S. Lim and A. V. Oppenheim, “Enhancement and band width
compression of noisy speech,” Proc. of the IEEE, Vol. 67, No.
12, pp. 1586-1604, Dec. 1979.
[2] S. Boll, “Suppression of acoustic noise in speech using spectral subtraction,” IEEE Trans. Acoustics, Speech and Signal
Processing, vol. 27, no. 2, pp. 113-120, April, 1979.
[3] O. Viikki and K. Laurila, “Cepstral domain segmental feature
vector normalization for noise robust speech recognition,”
Speech Commun., vol. 25, pp. 133-147, 1998.
[4] C. P. Chen amd J. Bilmes, “MVA processing of speech
features,” IEEE Trans. Audio Speech Language Process. vol.
15, no. 1, pp. 257-270, 2007.
[5] S. M. Ban and H. S. Kim, “Speaking rate dependent multiple
acoustic models using continuous frame rate normalization,”
in Proc. Asia-Pacific Signal and Information Processing Association, Dec. 2012.
[6] S. M. Chu and K. Povey, “Speaking rate adaptation using
continuous frame rate normalization,” in Proc. ICASSP, pp.
4306-4309, Mar. 2010.
[7] C.-H. Lee, C.-H. Lin, and B.-H. Juang, “A study on speaker
adaptation of the parameters of continuous density hidden
Markov models,” IEEE Transactions on Signal Processing, vol.
39, no. 4, pp. 806-814, April 1991.
[8] C. J. Leggetter and P. C.Woodland, “Maximum likelihood
linear regression for speaker adaptation of continuous density
hidden Markov models,” Computer Speech and Language, vol.
9, no. 2, pp. 171-185, April 1995.
[9] R. Kuhn, P. Nguyen, J.-C. Junqua, L. Goldwasser, N. Niedzielski, S. Fincke, K. Field, and M. Contolini, “Eigenvoices for
speaker adaptation,” in Proceedings of the 5th International
Conference on Spoken Language Processing, vol. 5, pp. 17711774, 1998.
288