Lecture 3 – Tuesday, October 6 3.1 Problem set up and motivation
advertisement

Nachdiplom Lecture: Statistics meets Optimization
Fall 2015
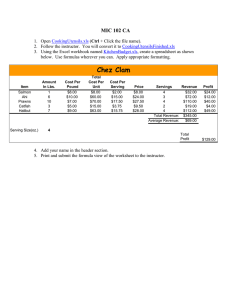
Lecture 3 – Tuesday, October 6
Lecturer: Martin Wainwright
Scribe: Yuting Wei
Today, we analyze an application of random projection to compute approximate solutions of constrained
least-squares problems. This method is often referred to as sketched least-squares.
3.1
Problem set up and motivation
Suppose that we are given an observation vector y ∈ Rn and matrix A ∈ Rn×d , and that for some convex
set C ⊂ Rd , we would like to compute the constrained least-squares solution
1
xLS : = argmin ky − Axk22 .
x∈C 2
|
{z
}
(3.1)
: =f (x)
In general, this solution may not be unique, but we assume throughout this lecture that uniqueness holds
(so that n ≥ d necessarily).
Different versions of the constrained least-squares problem arise in many applications:
• In the simplest case of an unconstrained problem (C = Rd ), it corresponds to the usual least-squares
estimator, which has been widely studied. Most past work on sketching least-squares has focused on
this case.
• When C is a scaled form of the `1 -ball—that is, C = {x ∈ Rd | kxk1 ≤ R}—then the constrained
problem is known as the Lasso. It is widely used for estimating sparse regression vectors.
• The support vector machine for classification, when solved in its dual form, leads to a least-squares
problem over a polytope C.
Problems of the form (3.1) can also arise as intermediate steps of using Newton’s method to solve a constrained optimization problem.
The original problem can be difficult to solve if the first matrix dimension n is too large. Thus, in order
to reduce both storage and computation requirements, a natural idea is to randomly project the original
data to a lower-dimensional space. In particular, given a random sketch matrix S ∈ Rm×n , consider the
sketched least-squares problem
1
x
b : = argmin kS(y − Ax)k22 .
x∈C 2
|
{z
}
: =g(x)
1
(3.2)
2
Lecture 3 – Tuesday, October 6
The row dimensions of the sketched problem are now m-dimensional as opposed to n-dimensional, which
will lead to savings whenever we can choose m n. This idea (in the unconstrained case C = Rd ) was first
proposed and analyzed by Sarlos [9]. The more general analysis to be described here is due to Pilanci and
Wainwright [8].
There are different ways to measure the quality of the sketched solution. For a given tolerance parameter
δ ∈ (0, 1), we say that it is δ-accurate cost approximation if
f (xLS ) ≤ f (b
x) ≤ (1 + δ)2 f (xLS ).
(3.3)
On the other hand, we say that it is a δ-accurate solution approximation if
1
√ A(xLS − x
b)
≤ δ.
n
2
(3.4)
In this lecture, we will focus on the cost notion of performance (3.3).
In particular, our main goal is to give a precise answer to the following question: how large must the projection dimension m be to guarantee that the sketched solution x
b provides a δ-accurate cost approximation?
(a)
(b)
Figure 3.1: Illustration of the tangent cone at xLS .
The answer depends on a natural geometric object associated with the convex program (3.1), namely the
tangent cone of C at xLS . In particular, it is the set
n
o
K(xLS ) = ∆ ∈ Rd | ∆ = t(x − xLS ), x ∈ C, t ≥ 0 .
(3.5)
Our theory shows that the projection dimension m required depends on the “size” of (a transformed version
of) this tangent cone. Note that the structure of this K(xLS ) can vary drastically as a function of xLS .
Figure 3.1(a) shows a favorable case, where xLS lies at a vertex of a polyhedral constraint set; panel (b)
shows a less favorable case, where xLS lies on a higher-dimensional face. The worst case for our theory is
when xLS is an interior point of C, so that K(xLS ) = Rd . Note that this worst case always occurs for an
unconstrained problem.
Lecture 3 – Tuesday, October 6
3.2
3
Projection theorem for constrained least square problem
Consider the set
AK(xLS ) ∩ S n−1 = {v ∈ Rn | ∃ ∆ ∈ K(xLS ), v = A∆, kvk2 = 1},
(3.6)
corresponding the intersection of the transformed tangent cone AK(xLS ) with the Euclidean sphere. We
define its Gaussian width in the usual way
hu, gi
where g ∼ N (0, In×n ).
(3.7)
W(AK(xLS ) ∩ S n−1 ) : = E
sup
u∈AK(xLS )∩S n−1
Theorem 3.2.1. Consider the sketched least-squares solution (3.2) based on a Gaussian random matrix
S ∈ Rm×n . Given a projection dimension m ≥ δC2 W2 (AK(xLS ) ∩ S n−1 ), it is a δ-accurate cost approximation
with probability at least 1 − c0 exp{−c1 mδ 2 }.
Here (C, c0 , c1 ) are universal constants independent of all problem parameters.
Proof. In order to simplify notation, we omit the dependence of K(xLS ) on xLS , and write K instead. We
define the following two quantities:
Z1 (AK) =
inf
v∈AK(xLS
)∩S n−1
kSvk22
m
(3.8a)
and
Z2 (AK, u) =
sup
v∈AK(xLS )∩S
T ST S
,
u (
−
I)v
m
n−1
where u ∈ S n−1 is some fixed vector.
(3.8b)
For a random sketch, note that Z1 and Z2 are also random variables, but parts of our theory hold deterministically for any choice of S. The following lemma shows that the ratio Z2 /Z1 controls the quality of x
b as a
cost approximation for f (x) = 21 kAx − yk22 .
Lemma 3.2.1. For any sketch matrix S ∈ Rm×n , we have
f (b
x) ≤
2
Z2 (AK, uLS )
1+
f (xLS )
Z1 (AK)
where uLS : =
y−AxLS
ky−AxLS k2 .
(3.9)
Proof. Define the error vector eb = x
b − xLS . By the triangle inequality, we have
kAb
ek2
.
kAb
x − yk2 ≤ kAxLS − yk2 + kAb
ek2 = kAxLS − yk2 1 +
kAxLS − yk2
By definition, we have kAb
x − yk2 =
p
2f (b
x) and kAxLS − yk2 =
f (b
x) ≤ f (xLS ) 1 +
p
2f (xLS ), and hence
kAb
ek2
kAxLS − yk2
2
.
Consequently, in order to prove the lemma, it suffices to upper bound the ratio
(3.10)
kAb
ek2
kAxLS −yk2
by Z2 /Z1 .
4
Lecture 3 – Tuesday, October 6
Note that x
b is optimal and xLS is feasible for the sketched problem (3.2). Thus, the first-order conditions
for optimality guarantee that
h∇g(b
x), −b
e i ≥ 0 =⇒ hS(Ab
x − y), −SAb
ei≥0
=⇒
1
1
kSAb
ek22 ≤ − hS(AxLS − y), −SAb
e i = (AxLS − y)T
m
m
−
ST S
+ I Ab
e − hAxLS − y, Ab
e i.
m
(3.11)
On the other hand, by the optimality of xLS and feasibility of x
b for the original problem (3.1), we have
h∇f (xLS ), eb i ≥ 0 =⇒ hAxLS − y, Ab
ei≥0
(3.12)
Combining inequalities (3.11) and (3.12) yields
1
kSAb
ek22 ≤ (AxLS − y)T
m
−
ST S
+ I Ab
e −hAxLS − y, Ab
ei
|
{z
}
m
≤0
ST S
≤ (AxLS − y)T −
+ I Ab
e.
m
Dividing through by Euclidean norms to normalize then yields
(AxLS − y)T S T S
Ab
e kSAb
ek22
kAb
ek22
≤
−
I
kAxLS − yk2 kAb
ek2 .
kAxLS − yk2
mkAb
ek22
m
kAb
ek2 Recalling the definitions of Z1 and Z2 , we have
kSAb
ek22
kAb
ek2 ≥ Z1 kAb
ek22 ,
mkAb
ek22
and
(AxLS − y)T S T S
Ab
e kAxLS − yk2 kAb
ek2 ≤ Z2 kAxLS − yk2 kAb
ek 2 .
−I
kAxLS − yk2
m
kAb
ek 2 Putting together the pieces yields the desired bound
kAb
ek2
Z2 (AK, uLS )
.
≤
kAxLS − yk2
Z1 (AK)
n
o
For a given δ ∈ (0, 1/2), define the event E(δ) : = Z1 ≥ 1 − δ, Z2 ≤ δ/2 . Conditioned on this event, we
have
2
f (b
x)
Z2 (AK, uLS ) 2 δ/2 2
≤ 1+
≤ 1+
≤ 1+δ ,
f (xLS )
Z1 (AK)
1−δ
which is our desired form of δ-accurate cost approximation. Consequently, in order to complete the proof,
2
we need to state a lower bound on the projection dimension that ensures that P[E(δ)] ≥ 1 − c1 e−c2 mδ .
Lemma 3.2.2. For a Gaussian sketch matrix, there is a universal constant C such that m ≥
2
S n−1 ) implies that P[E(δ)] ≥ 1 − c1 e−c2 mδ .
C
2
δ 2 W (AK
∩
We only sketch the proof of this lemma here, since it follows essentially from our main result in Lecture #2.
Define the random variable
ST S
T
Z(AK) =
sup
− In v .
(3.13)
v
m
n−1
v∈AK∩S
Lecture 3 – Tuesday, October 6
5
From Lecture #2, given our stated lower bound on the projection dimension, we have Z(AK) ≤ δ/C 0 with
2
probability at least 1 − c1 e−c2 mδ . Here the constant C 0 > 0 can be made as large we please by choosing the
constant C in Lemma 3.2.2 larger.
Thus, let us suppose that the bound Z(AK) ≤ δ/C 0 holds. As long as C 0 > 1, we are guaranteed that
Z1 ≥ 1 − δ. On the other hand, showing that Z2 ≤ δ/2 requires a little more work, involving splitting into
two cases, depending on whether the inner product huLS , vi is positive or negative. We refer to the paper [8]
for details.
3.3
Some illustrative examples
Let’s consider some examples to illustrate.
Unconstrained least squares: When K = Rd , then the transformed tangent cone AK is the range space of
matrix A. Using our calculations of Gaussian widths, we see that a projection dimension m & rank(A)/δ 2 is
sufficient to give a δ-accurate cost approximation. This result (modulo some superfluous logarithmic factors)
was first shown by Sarlos [9].
Noiseless compressed sensing: Suppose that our goal is to recover a sparse vector x∗ ∈ Rd based on
observing the random projection z = Sx∗ . We can recover known bounds for exact recovery as a special
case of our general result, one with A = Id (and hence n = d).
Consider the `1 -constrained least squares problem minkxk1 ≤R 12 kx∗ − xk22 , say with the radius chosen as
R = kx∗ k1 . By construction, we have xLS = x∗ for this problem. The sketched analog is given by
min
kxk1 ≤R
1
kS(x∗ − x)k22 =
2
min
kxk1 ≤R
1
kz − Sxk22 ,
2
where z = Sx∗ is observed.
(3.14)
Suppose that kx∗ k0 = k, meaning that x∗ is a k-sparse vector. It turns out that (with high probability) the
sketched problem (3.14) has x
b = x∗ has its unique solution whenever m % k log(ed/k). This is a standard
result in compressed sensing [5, 4], and can be derived as a corollary of our general theorem.
We begin by noting that if xLS provides a δ-accurate cost approximation, then we are guaranteed that
2
kx∗ − x
bk22 ≤ 1 + δ kx∗ − xLS k22 = 0,
which implies that x
b = x∗ . So for this special noiseless problem, a cost approximation of any quality
automatically yields exact recovery.
How large a projection dimension m is needed for a cost approximation (and hence exact recovery)? We
need to bound the Gaussian width W(AK ∩ S n−1 ). The following lemma provides an outer bound on this
set. We use the notation Bp (r) = {x ∈ Rd | kxkp ≤ r} for the `p -norm ball of radius r, and clconv to denote
the closed convex hull.
Lemma 3.3.1. For any vector x∗ that is k-sparse, we have
n
o
(b)
(a)
√
K(x∗ ) ∩ S d−1 ⊆ B1 (2 k) ∩ B2 (1) ⊆ 2 clconv B0 (4k) ∩ B2 (1) .
(3.15)
6
Lecture 3 – Tuesday, October 6
Let us use this lemma to bound the Gaussian width. From inclusion (a) in equation (3.15), we have
W(K(x∗ ) ∩ S d−1 ) ≤ E
sup √ hx, gi
kxk1 ≤2 k
kxk2 =1
√
≤ 2 k Ekgk∞
(ii) p
≤ 2 2k log d
(i)
a very crude bound!
where inequality (i) follows from Holder’s inequality; and step (ii) follows from our bound on the expected
maximum of d independent Gaussian (shown in Lecture #2). This bound shows that it suffices to take
m % k log d.
Now let’s use inclusion (b) in equation (3.15), along with a more careful argument, to obtain a sharper
bound. We have
h
i
W(K(x∗ ) ∩ S d−1 ) ≤ 2E max sup hxS , gS i ≤ 2E[ max kgS k2 ]
where g ∼ N (0, Id ).
|S|=4k kxS k2 ≤1
|S|=4k
p
√
Each variable kgS k2 has mean at most |S| = 4k, and is concentrated around its mean with sub-Gaussian
tails (Lecture #2, concentration of Lipschitz functions). Consequently, we have
s h
i
p
√
d
E max sup hxS , gS i ≤ 4k + c log
= c0 k log(ed/k).
4k
|S|=4k kxS k2 ≤1
This calculation shows that it is sufficient to take m % k log(ed/k).
It remains to prove Lemma 3.3.1.
Proof. We prove the first inclusion here. For any x ∈ C, the difference vector ∆ = x − x∗ (and scaled copies
of it) belong to the tangent cone K(x∗ ). Let us write the support set of x∗ as S and zero part S c . Since
x ∈ C, we have
kxk1 = kx∗ + ∆k1 = kx∗S + ∆S k1 + k∆S c k1 ≤ kx∗S k1 .
By triangle inequality,
kx∗S k1 − k∆S k1 + k∆S c k1 ≤ kx∗S + ∆S k1 + k∆S c k1 ≤ kx∗S k1 .
Combining the two bounds yields k∆S c k1 ≤ k∆S k1 , and hence
√
k∆k1 = k∆S k1 + k∆S c k1 ≤ 2k∆S k1 ≤ 2 kk∆k2 ,
as claimed.
For the proof of inclusion (b) in equation (3.15), we refer the reader to Loh and Wainwright [7].
3.4
Other random projection methods
Up until now, we have showed that through Gaussian projection we can reduce the problem dimension to
its intrinsic dimension which characterized by a geometric object: Gaussian Width of the tangent cone at
Lecture 3 – Tuesday, October 6
7
xLS . If we only care about the data storage issue, this projection does help us. However, from a complexity
of computing point of view, the cost of doing Gaussian sketching to get Sy, SA where A ∈ Rn×d , is of order
O(mnd). The computing complexity of doing the sketching can be even larger than solving the original least
square problem directly. Then why bother using the sketching technique?
The key is that our theory holds for many other types of random sketches apart from Gaussian. In fact,
our theory gives bounds for any matrix S for which we can control the quantity
Z(AK(xLS ) ∩ S n−1 ) =
sup
v∈AK(xLS )∩S n−1
|
1
kSvk22 − 1|.
m
What type of matrices can be used to speed up the projection step?
• Fast JL transforms: These methods are based on structured forms of random matrices for which
the projection can be computed quickly [1, 2].
• Sparse JL transforms: These methods are based on constructing projection matrices S with a very
large number of zero entries, so that the matrix multiplication can be sped up by using routines for
sparse matrices [6, 3].
One class of fast JL transforms based on structured matrices take the following form:
1. Start with an orthonormal matrix H ∈ Rn×n for which it is possible to perform fast matrix multiplication. Examples include the discrete Fourier matrix (multiplies carried out by fast Fourier transform),
or the Hadamard matrix (multiplies carried out with the fast Hadamard transform).
2. Form the projection matrix S = Hm D where
• the matrix Hm ∈ Rm×n is obtained by sampling m rows from H uniformly at random (without
replacement)
• the matrix D is a diagonal matrix with i.i.d. {−1, 1} entries
Bibliography
[1] N. Ailon and B. Chazelle. Approximate nearest neighbors and the fast Johnson-Lindenstrauss transform.
In Proceedings of the 38th Annual ACM Symposium on Theory of Computing, pages 557–563. ACM,
2006.
[2] N. Ailon and E. Liberty. Fast dimension reduction using rademacher series on dual bch codes. Discrete
Comput. Geom, 42(4):615–630, 2009.
[3] J. Bourgain, S. Dirksen, and J. Nelson. Toward a unified theory of sparse dimensionality reduction in
euclidean space. Geometric and Functional Analysis, 25(4), 2015.
[4] E. J. Candès and T. Tao. Decoding by linear programming. IEEE Trans. Info Theory, 51(12):4203–4215,
December 2005.
[5] D. L. Donoho. Compressed sensing. IEEE Trans. Info. Theory, 52(4):1289–1306, April 2006.
[6] D. M. Kane and J. Nelson. Sparser Johnson-Lindenstrauss transforms. Journal of the ACM, 61(1), 2014.
[7] P. Loh and M. J. Wainwright. High-dimensional regression with noisy and missing data: Provable
guarantees with non-convexity. Annals of Statistics, 40(3):1637–1664, September 2012.
[8] M. Pilanci and M. J. Wainwright. Randomized sketches of convex programs with sharp guarantees. IEEE
Trans. Info. Theory, To appear. Presented in part at ISIT 2014.
[9] T. Sarlos. Improved approximation algorithms for large matrices via random projections. In 47th Annual
IEEE Symposium on Foundations of Computer Science, pages 143–152. IEEE, 2006.
8