M 311 – L
advertisement

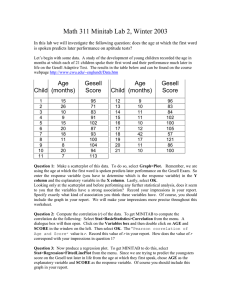
24 JULY 2016 MATH 311 LAB 2 – SCATTERPLOTS, REGRESSION, GENERATING DATA & NORMALITY TEST Scatterplots and regression: Let’s begin with some data. A study of the development of young children recorded the age in months at which each of 21 children spoke their first word and their performance much later in life on the Gesell Adaptive Test. The results in the table below Child Age (months) 1 2 3 4 5 6 7 8 9 10 11 15 26 10 9 15 20 18 11 8 20 7 Gesell Score 95 71 83 91 102 87 93 100 104 94 113 Child Age (months) 12 13 14 15 16 17 18 19 20 21 9 10 11 11 10 12 42 17 11 10 Gesell Score 96 83 84 102 100 105 57 121 86 100 Question 1: Make a scatterplot of this data. To do so, select Graph>Scatterplot>Simple. Remember, we are using the age at which the first word is spoken predicts later performance on the Gesell Exam. So enter the response variable (you have to determine which is the response variable) in the Y variable and the explanatory variable in the X variable. Lastly, select OK. Looking only at the scatterplot and before performing any further statistical analysis, does it seem to you that the variables have a strong association? Record your impressions in your report. Specify exactly what kind of association you think these variables have. Of course, you should include the graph in your report. We will make your impressions more precise throughout this worksheet. Question 2: Compute the correlation (r) of the data. To get MINITAB to compute the correlation do the following: Select Stat>BasicStatistics>Correlation from the menu. A dialogue box will then open. Click on the Variables box and then double click on AGE and SCORE in the window on the left. Then select OK. The “Pearson correlation of Age and Score” value is r. Record this value of r in your report. How does the value of r correspond with your impressions in question 1? Question 3: Now produce a regression plot. To get MINITAB to do this, select Stat>Regression>FittedLinePlot from the menu. Since we are trying to predict the youngsters score on the Gesell test later in life from the age at which they first speak, chose AGE as the explanatory variable and SCORE as the response variable. Of course you should include this graph in your report. Question 4: Use the equation given by MINITAB to predict the Gesell score of a kid who spoke her first words at 30 months by plugging 30 in for AGE and solving for SCORE. Include your answer in your report. Generating Data Minitab lives to generate data – you pick the type of distribution the data should have and Minitab does all the work. For example: let’s suppose you want to generate 10,000 data points of normally distributed data with a mean of 6 and a standard deviation of 1.8. To do so, use the following commands: Calc>Random Data>Normal Enter 10000 in the Generate _____ rows of data box Enter C1 in the Store in column(s): box Enter 6 in the Mean: box Enter 1.8 in the Standard deviation box Select OK Pretty cool, huh? Make a histogram of your data to check it. Repeat the above with Uniformly distributed data (min of –3, max of 7). Make a histogram of to check. If you wanted to generate, say, 17 columns of normally distributed data, you would enter C1 – C17 in the Store in column(s) box. How Normal Is Normal? Let’s suppose you’re given data. Of course, like any good junior statistician, you wonder about the shape, center, and spread of these data. Towards that end, you construct a histogram of the data (how else would you be able to describe the shape?) and notice that the histogram is symmetric and single-peaked. But, is it normal…? There are distributions that are bell-shaped, but not normal. We need a test! How do we test data for normality? One option would be to compute the mean and standard deviation of the data, determine how much of the data lies within 1 standard deviation of the mean, 2 standard deviations, 3 standard deviations, etc. and then compare this to the percentages listed in Table A. OR The other option is we let Minitab do the work as follows. Have Minitab generate 10,000 rows of normally distributed data. Then use the following commands: Graph>Probability Plot Select Single In the Graph Variables: window, enter the column in which your data lives (probably C1). Select OK See how the red dots are pretty much essentially following the blue lines – that tells you that the data are normally distributed. Now repeat the above procedure with 10,000 uniformly (or any other non-normally) distributed data. The red dots won’t follow the blue lines – that’s how you know that the data are not normally distributed. Red dots on line = normal … red dots not on line = not normal. … red dots kinda on the line = kinda normal. Note, the dots rarely lie on the line at the extreme ends – check this.