=============================================================================== 114 ...
advertisement

===============================================================================
114
Block 1
Chaires
-------------------------------------------------------------------------------------------------------------------------- 6 / 2 / 2008
You are required to Learn, Understand, and Remember, Everything in Block 1.
This is the LURE system
= 1.1 ===========================================================================
1 A Population is the collection of all measurements or observations to be studied.
--------------------------------------------------------------------------------------------------------------------------------------Example populations:
The number of minutes it takes every student at PGCC to run one mile. measurements
The color of each car licensed in Maryland. observations
===============================================================================
2 A Sample is part of a population. n is the number of items in a sample.
n = the sample size.
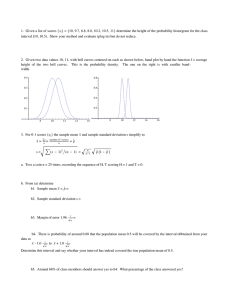
--------------------------------------------------------------------------------------------------------------------------------------N is the number of items in a population. N = the size of the population.
===============================================================================
3 Data is any collection of measurements or observations.
--------------------------------------------------------------------------------------------------------------------------------------Examples of data: Measurements: 6.23, 8.92, 12.27, 7.85
Observations:
blue, red, yellow, red, green
===============================================================================
Statistics is the collection, organization, analyses, and interpretation of data
===============================================================================
4 Descriptive Statistics uses numerical and graphical methods to describe data.
Page 10
-------------------------------------------------------------------------------------------------------------------------------------Some descriptive statistics for the sample 2, 6, 7 are: The sample size n = 3,
the maximum value is 7, the middle number is 6, the average is 5.
===============================================================================
5 Inferential Statistics uses a sample to make predictions about the population.
Page 10
--------------------------------------------------------------------------------------------------------------------------------------The sample 2, 6, 7 has an average of 5, therefore we predict the population it came from has an
average “close to 5”. How reliable is this prediction? We will learn about this in our study of statistics.
== 1.2 ==========================================================================
A Sampling Procedure is a method of selecting a sample.
===============================================================================
6 A Simple Random Sample of size n is a sample selected using a sampling procedure that assures that
(a) every item of a population has the same chance of being included in the sample, and
(b) every sample of size n has the same chance of being selected.
Page 13
===============================================================================
A Random Number Table can be used to select a simple random sample.
Page A9-A10.
Today, computers generate random numbers. We will use the calculator to compute random numbers.
===============================================================================
To prepare your calculator for random sampling, do the following.
Start with a screen. Type any 3 digit number. Press .
You do not need to do this again.
===============================================================================
1
===============================================================================
14,6 Pick a simple random sample of 30 cars to be tested from a shipment of 500 cars. Do not use the table.
1. Number each car from 1 to 500. Use RANDOM to compute 30 random numbers.
Note: Your calculator will display a different list of random numbers.
RANDOM
Copy the 1st 7 numbers in L3 Arrow down to highlight entry L3(14). Copy the numbers
32, 34, 62, 102, 105, 106,118
136,178,186, 192, 210, 211,231
Arrow down to L3(21) Copy the 7 numbers to paper. Arrow down to L3(28) Copy the 7 numbers to paper.
268,270,290,295,309,328, 336
350,396,403,409,425,483,484
Arrow down to L3(30) Copy the last 2 numbers.
493,500
Note: If any numbers were repeated in the list of 30 numbers, we would need to
run the program again and select the remaining numbers beginning at the
top of L1
We now have 30 random numbers to use to select the cars to be tested.
===============================================================================
15,7 This problem uses 15 numbers (even and odd) to simulate the rises and fall of the price of a stock.
RANDOM Arrow down to get your next two screens QUIT
Let 1 An increase of $1 and 0 A decrease of $1.
On the 15th day the price of the stock is $47.
Price 50 49 50 49 48 49 50 51 50 51 50 51 50 49 48 47
Day
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Digit
0 1 0 0 1 1 1 0 1 0 1 0 0 0 0
===============================================================================
2
= 2.2 ===========================================================================
7 A Histogram is a bar graph with bars that touch and have the same width.
===============================================================================
Four Histogram Shapes Use HIST to make these histograms after doing the example below.
Symmetrical
Uniform
Skewed right
Bimodal
2, 3,3, 4,4,4, 5,5, 6
2
3
4
3,3, 4,4, 5,5 6,6
3
5 6
n=9
4
5
n=8
6
1,1,2,2,2,2,2, 3,3,3,3, 4,4,4,5,5,6
1 2 3 4
1,2,2,2,2, 3,3, 4,4,4,4,5,5,5
5 6
1
n = 17
2
3
4
5
n = 14
=============================================================================
The Measurement Classes are the intervals corresponding to the bars of a histogram.
=============================================================================
The Index i of a class is the name of each class. i = 1, 2, 3, 4, …, K. K is the number of classes or bars.
=============================================================================
8 The Frequency fi of Class i is the number of measurements in class i.
In the histogram below, f2 = 2.
=============================================================================
f
9 The Relative Frequency rfi of Class i is i , where n is the total number of data values.
n
---------------------------------------------------------------------------------------------------------------------------------3
In the example below, the frequency of Class 2 is 3. The relative frequency of Class 2 is
.2727… 27%.
11
=============================================================================
Use HIST to make the histogram for 2 2, 4,4,4, 6,6,6, 6,6, 8. Type all the raw data into L1.
OFFSET = .5 for whole number data. K = the number of bars. W, the width, must be between the given numbers.
HIST
boundaries
f
rf
rf2 =
3
27%.
11
About 27% of the data
are in Class2.
Press and etc. to see
Note: n is used
the
boundaries B and frequencies n.
as the frequency
Class 2 [2.5, 3.5) and n = f2 = 3.
of the class.
===============================================================================
10 A Frequency Distribution shows each different data value (or measurement class) and its frequency.
===============================================================================
A histogram showing frequencies and relative frequencies
To compute the Class limits, add the offset to the lower boundary and subtract the offset from the upper boundary.
45%
L2
3
5
2
3 4
5 6
1.5
3.5
5.5
9%
78 1 9
7.5
9.5
L4
Class Limits
Boundaries
1.5 3.5
3.5 5.5
5.5 7.5
7.5 9.5
Class Boundaries
Frequency Distribution
27%
18%
2
L3
f
2
3
5
1
L2
L3
Boundaries
1.5 3.5
3.5 5.5
5.5 7.5
7.5 9.5
L5
rf
.18
.27
.45
.09
Relative Frequency Distribution
===============================================================================
3
Rules for constructing a histogram by hand
Optional.
1 ln(n)
1) Select the number of bars K. Rule: K
. This is a formula for an appropriate number of bars.
ln(2)
2) Select the OFFSET. Rule: Use .5 for whole data, .05 for data in tenths, .005 for data in hundredths, etc..
3) Compute the left boundary B1. Rule: B1 = (Smallest data value) – OFFSET.
Range
4) Compute W, the class width. Rule: W
(rounded up)
K
5) Compute all class boundaries: B2, B3, B4, etc. Rule: B2 = B1 + W. B3 = B2 + W, etc…
6) Find the number of data in each class: Rule: Count the data in (B1,B2), (B2,B3) etc…
f
7) Compute the relative frequency of each class: Rule: rfi = i . n = the total number of data.
n
8) Put the results in a table.
9) Draw the histogram.
See pages 58 - 60 for a Guided Exercise done by hand.
3.1 and 3.2 =======================================================================
This example combines the concepts of 2.2, 3.1, and 3.2.
It is a preview of how to use the technology of the calculator to find numbers that describe sample data.
Using
HIST, DESCRIPT, ZTXVALUE, INTERVAL, WITDATA
The sample data is on page 53, TABLE 2-4.
HIST
The histogram shows that the data is skewed to the right. Class 2 [9,16] is the model class.
DESCRIPT
etc
The sample size = 60. The sum of the data = 1051. The mean of the sample = 17.517. The median = 15.
The sample standard deviation = 11.721. The sample variance = 137.37. The range = 46.
The modes are 12 and 16. The minimum value = 1. The maximum value is 47.
---------------------------------------------------------------------------------------------------------------------------------------
4
-------------------------------------------------------------------------------------------------------------------------------------- ZTXVALUE
INTERVAL
The coefficient of variation = 66.9%
The standard deviation intervals about the mean are 1sd = (5.8, 29.2) 2sd = (-5.9, 40.96) 3sd = (-17.6, 52.7)
-17.6
-5.9
5.8
17.5
29.2
40.96
52.7
x
-3
-2
-1
0
1
2
3
z
WITDATA
The data [6, 29] 1sd interval
The data [1, 40] 2sd interval
ZTXVALUE
All the data [1, 47] 3sd interval.
restarts the program
The z-score of 40 = 1.92
The z-score of 6 = -.98
== 3.1 ==========================================================================
x data is the name given to a list of values. A second list of data would be called y data.
x denotes “The sum of the x data.” For the x data: 1, 2, 2, 7, x = 12.
Three Measures of Central Tendency of data are Mean, Median, and Mode.
Each of these numbers is an average of the data. The mean is often called “THE AVERAGE”.
===============================================================================
11 The Mode of data is the number, or numbers, with the highest frequency. The book differs.
Page 98
=============================================================================
12 The Median Med is the middle number in an ordered list.
If there are two middle numbers, the median is the mean of the two middle numbers.
Page 99
--------------------------------------------------------------------------------------------------------------------------------------n 1
The position of the median in collection of n numbers is
Page 100
2
===============================================================================
5
===============================================================================
For: 2, 4, 5, 8, 9,
Med = 5. The data has no mode.
69
For: 3, 4, 6, 9, 9, 10, Med =
= 7.5. The mode is 9.
2
For: 1, 1, 3, 5, 5 , Med = 3. There are two modes 1 and 5. Our book says that this data has no mode.
===============================================================================
(the sum of the measurements)
13 The Mean of data is the number given by the division M =
.
Page 101
(the number of measurements)
===============================================================================
x
14 denotes “The Mean of a Sample of x data.” =
. is read “x bar”.
Page 101
n
===============================================================================
x
15 denotes “The Mean of the Population.” is the Greek letter mu. =
.
Page 101
N
-------------------------------------------------------------------------------------------------------------------------------------x
35
If the x data 1,2,2,4,6,7,13 is a population, then =
=
= 5 = the population mean.
N
7
x 12
If the x data 1, 2, 2, 7 is a sample, then =
=
= 3 = the sample mean.
n
4
Extreme Values , or Outliers , are measurements that are very small or very large when compared to the
other data in the list.
--------------------------------------------------------------------------------------------------------------------------------------For the sample: 2, 4, 5, 5, 89, = 21, Med = 5, and Mode = 5.
Is it correct to say that the “average number” in the list is 21 when 80% of the values are below average?
Yes, but does 21 tend to represent the numbers in the list?
Does 5, the median, better represent the list? Does 89 seem to be out of place in the list?
Perhaps the list is really 2, 4, 5, 5, 8, 9. Or 89 may be correct, but just an extreme value.
We discover extreme values by using a box plot in computer assignment C1.
===============================================================================
Find the 5% trimmed mean of the 11 numbers: 4, 5, 6, 7, 9, 10, 12, 13, 15, 15, 155. n = 11.
TRIM
The 5% trimmed mean = 10.2
--------------------------------------------------------------------------------------------------------------------------------------The 5% Trimmed Mean of list of n measurements is found as follows:
Page 102
1) Multiply (.05 n). Round the result to the nearest whole number k.
2) Remove (trim) the k smallest, and the k largest, values from the list.
3) Compute the mean of the trimmed list. This is the 5% trimmed mean.
---------------------------------------------------------------------------------------------------------------------------------------
6
Find the 5% trimmed mean of the 11 numbers: 4, 5, 6, 7, 9, 10, 12, 13, 15, 15, 155. n = 11.
1) .05 11 = .55, this rounds to 1. k = 1.
2) Remove the 1 smallest, and the 1 largest, number from the list.
3) Compute the mean of the 9 remaining numbers: 5, 6, 7, 9, 10, 12, 13, 15, 15.
92
The 5% trimmed mean =
= 10.2.
9
251
The mean of the original 11 numbers is
= 22.8.
11
10.2 is more descriptive (or representative) of the list than 22.8
By hand is optional.
Note also that the median in both lists is 10. The mode in both lists is 15.
The median and mode are not influenced by outliers. They are said to be resistant measures.
Page 102
== 3.2 ==========================================================================
Three Measures of Variation of data are range, variance, and standard deviation.
Variation is the amount of spread in the data.
===============================================================================
16 R denotes “The Range of the Data.” R = (the largest value) – (the smallest value).
-------------------------------------------------------------------------------------------------------------------------------------For 5, 7, 11, 12, 15, R = 10.
15 – 5 = 10
===============================================================================
17 s denotes “The Standard Deviation of a Sample.” The TI-83 and 84 use the symbol Sx.
===============================================================================
18 denotes “The Standard Deviation of a Population.” is the Greek letter sigma.
The TI uses x
--------------------------------------------------------------------------------------------------------------------------------------( x x ) 2
( x ) 2
. =
.
Pages 113, 116
n 1
N
The standard deviation indicates of how far, on average, each value varies from the mean.
===============================================--==-============================
The Variance of a Sample is denoted s2. If s = 3, then the variance is s2 = 9.
The formulas are: s =
The Variance of the Population is 2. If 2 = 14, then the standard deviation is = 14 . 3.73
Computing s using the paper and pencil method. For demonstration only. Optional
Also see 113,6
x 43
Find s for the sample 8, 18, 7, 10.
=
=
= 10.75 = the sample mean.
n
4
Data
x
Deviation
x – 10.75
Deviation2
(x – 10.75)2
8
18
7
10
-2.75
7.25
-3.75
-0.75
7.5625
52.5625
14.0625
0.5625
43
x
0
(x - )
74.75
(x - )2
s=
( x 10.75) 2
=
4 1
74.75
24.917 4.992.
3
s 4.99 = the sample standard deviation.
s2 24.9 = the sample variance.
---------------------------------------------------------------------------------------------------------------------------------------
7
--------------------------------------------------------------------------------------------------------------------------------------Find s for 7, 10, 18, 8 using the calculator.
DESCRIPT
s = 4.992
The Lists Screen
The data has no mode.
1:Finds Sample Statistics
2: Finds Population Parameters: Facts about the population
===============================================================================
s
19 The Coefficient of Variation CV of data is given by CV =
or CV = .
Page 118
x
--------------------------------------------------------------------------------------------------------------------------------------4.99
If = 10.75 and s = 4.99, then CV =
= .464 = 46.4%.
10.75
ZTXVALUE
Use n = 1. We are considering single numbers.
===============================================================================
20 Standard Deviation Intervals about the Mean are the intervals:
( – s, + s), ( – 2s, + 2s), ( – 3s, + 3s), etc..
-------------------------------------------------------------------------------------------------------------------------------------If = 5 and s = 2, the SD intervals about are (3, 7), (1, 9), and (-1, 11).
INTERVAL will do this
-3s
-2s
-s
+s
+2s
+3s
x
-1
1 2.2
3
5
7
9
computation automatically.
See the next sheet.
11
Start with the mean 5 and add 2 repeatedly. Then start with 5 and subtract 2 repeatedly.
A measurement x is within k standard deviations of if it is in the interval ( – ks, + ks).
A measurement x is within 2 standard deviations of the mean 5 if it is in the interval (1, 9).
===============================================================================
21 Chebyshev’s Rule states:
Page 120
1
At least 1 2 of the data of any sample are within k SD of the mean, for k > 1.
k
Specifically: a) At least 75% of the data, of any sample, are within 2s of the mean. k = 2
b) At least 89% of the data, of any sample, are within 3s of the mean. k = 3
c) At least 94% of the data, of any sample, are within 4s of the mean. k = 4
===============================================================================
-4s
-3s
-2s
-s
+s
+2s
+3s
+4s
-----(----------(----------(----------(--------------------)----------)----------)----------)----75% or more of the data are in here
89% or more of the data are in here
94% or more of the data are in this interval
8
===============================================================================
--------------------------------------------------------------------------------------------------------------------------------------1
1
1
When k = 2, 1 – 2 = .75.
When k = 3, 1 – 2 = .888…
When k = 4, 1 – 2 = .9375.
2
4
3
Calculator: 1 – 1 3
-------------------------------------------------------------------------------------------------------------------------------------- CHEBY
===============================================================================
For the sample 7, 8, 10, 18, graph each number in the standard deviations intervals.
INTERVAL
CHEBY
n=1 because we are looking at single numbers.
This topic is in Block 3.
-3s
-2s
-s
+s
+2s
+3s
-----(---------------(---------------(--------------------------)--------------)---------------)----- x
-4.22
.77
5.76
10.75
15.74
20.73
25.72
7 8 10
18
---- (-3) ----------- (-2) ------------ (-1) (-.75) (-.15) (0) ----------------- (1.45) ------ (2) -------------- (3) --- z
3
= 75% of the data.
4
4
The 2 SD interval = (.77, 20.73). 7, 8, 10 and 18 are in this interval. This is = 100% of the data.
4
Chebyshev’s rule says that 75% or more of the data are in the 2 SD interval.
The 1 SD interval = (5.76, 15.74).
7, 8, and 10 are in this interval. This is
Where is the data? 7, 8 , 10, 18
WITDATA
restarts the program.
===============================================================================
xx
22 z denotes “The z-score of a data value x.” z is given by z =
s
The z-score, or z-value, is the number of standard deviations that x is from .
-------------------------------------------------------------------------------------------------------------------------------------(7 10.75)
The z-score of 7, above, is z =
= -.75.
ZTXVALUE
4.99
Press keys ( 7 – 10.75 ) 4.99
This may be written as z(7) = -.75.
9
z(10) = -.15. z(18) = 1.45. 18 is 1.45 SD above the mean 10.75
z(7) = -.75.
--------------------------------------------------------------------------------------------------------------------------------------===============================================================================
A Comparison of Standard Deviations.
Example 1
Two students have the following grades. Which one would you hire based on their grades?
Grade #
1
2
3
4
5
6
7
8
9
10
Student 1 81 74 71 88 78 77 83 77 75 96 80
Student 2 67 90 79 50 100 83 78 78 81 94 80
Med Mode
R
77.5
80
25 7.0
50 13.4
77
78
---------------------------------------------------------------------------------------------------------------------------------Student 1: = 80, = 7.0
66
- 2
73
-
80
87
+
94
+ 2
CV = 8.75%
Notice that 90% of the data is within 2 of the mean. Chebyshev says 75% or more will be in there.
---------------------------------------------------------------------------------------------------------------------------------Student 2: = 80, = 13.4
53.2
66.6
80
93.4
106.8
- 2
-
+
+ 2 CV = 16.75%
---------------------------------------------------------------------------------------------------------------------------------Based on these grades, what can you say about the students? Although both students have the same 80% average, Student
1 is more consistent with = 7.0 compared to = 13.4 for Student 2.
Example 2
1
2
3
4
5
6
7
8
9
10
Med Mode
Sample 1 60 60 60 70 70 70 70 80 80 80 70
Sample 2 60 70 70 70 70 70 70 70 70 80 70
70
70
70
70
R
s
20 8.2
20 4.7
---------------------------------------------------------------------------------------------------------------------------------Sample 1: = 70, s = 8.2
.
53.6
61.8
70
78.2
86.4
- 2s
-s
+s
+ 2s CV = 11.7%
----------------------------------------------------------------------------------------------------------------------------------
Most of the data are clustered at or around the mean 70.
Sample 2: = 70,
s = 4.7
55.9
60.6
65.3
70
- 3s
- 2s
-s
10
74.7
+s
79.4
+ 2s
84.1
+ 3s
CV = 6.7%
Notice that 80% of the data is within 2s of the mean. Chebyshev says that 75% or more will be in there.
Special Note: If every data value is the same, for example all the values are 1’s, then s = 0.
==================================================================
=== Start 4.1 =====================================================================
1 The Fundamental Counting Principal states:
If an activity has r steps, S1 , S2 , S3 ,…, Sr, that can be done in n1 , n2 , n3 ,…, nr ways respectively,
then the activity can be done in n1 n2 n3 … nr ways.
See Multiplication rule of counting: page 200
-------------------------------------------------------------------------------------------------------------------------------------Example: Toss a coin and a die. In how many ways can they land? The activity has 2 steps.
S1: Toss the coin. S2: Toss the die. n1 = 2, n2 = 6. A coin and die can land 12 ways.
The 12 ways are: H1 H2 H3 H4 H5 H6 T1 T2 T3 T4 T5 T6.
===============================================================================
2 A Probability Experiment is an activity with an observable result.
===============================================================================
A Trial is a repetition of an experiment.
An Outcome is the result of a trial.
===============================================================================
3 The Sample Space S is the set of all outcomes of the experiment.
Page 165
===============================================================================
4 An Event E is any subset of the sample space.
Page 165
------------------------------------------------------------------------------------------------------------------------------------Tossing a coin is a probability experiment.
Each toss of a coin is a trial.
The outcomes of tossing a coin are: H , T.
The sample space of tossing a coin is {H, T}
The events of tossing a coin are: {H}, {T}, {H, T}, . = { } = For example, the event of getting a 3.
=============================================================================
5 The Probability of E , denoted P(E), is an indication of how likely it is that E will happen.
=============================================================================
6 A Probability is a Number from 0 to 1, inclusive.
Page 162
------------------------------------------------------------------------------------------------------------------------------------An event with a probability close to 0 is not very likely to happen.
An event with a probability close to 1 is very likely to happen.
If R is the event of rain and
P(R) = 90%, then rain is very likely.
0 .1
.2
.3
.4
.5
.6
.7
.8
.9
1
=============================================================================
An Impossible Event I is an event that will never happen. P(I) = 0.
Page 162
A Certain Event C is an event that will always happen. P(C) = 1.
The experiment: Roll a die. S = {1, 2, 3, 4, 5, 6}.
1 = 100%
Page 162
Event I: Get a number above 7. P(I) = 0.
Event C: Get a number below 7. P(C) = 1.
=============================================================================
7 Equally Likely Events are events that have the same probability.
=============================================================================
A Simple Event is an event with a single outcome.
Events {3} and {5}, when tossing a die, are
1
simple events that are equally likely.
P(3) = P(5) =
= .16666…
Page 165
6
11
=============================================================================
=============================================================================
8 The Basic Probability Theorem states: If an event E, with f outcomes, is from an experiment in which
f
all N outcomes are equally likely, then P(E) =
.
Page 163
N
---------------------------------------------------------------------------------------------------------------------------------(The number of ways that E can happen)
P(E) =
Page 164
(The number of ways that the experiment can happen)
-- Page 176, 3 ---------------------------------------------------------------------------------------------------------------The experiment: Roll two dice. There are 36 equally likely outcomes. 6 6 = 36. N = 36 See page 176.
1
Event E: Get a 5 on each. E can occur one way. f = 1. P(E) =
(.0278)
36
=============================================================================
9 The Basic Sum Property of probability states:
Page 167
The sum of the probabilities of the simple events of an experiment is 1.
---------------------------------------------------------------------------------------------------------------------------------When tossing a coin, the simple events are {H} and {T}. P(H) + P(T) = .5 + .5 = 1
=============================================================================
10 The Complement of Event E , denoted E is the event that E does not happen. The book uses EC Page 168
=============================================================================
11 The Failure Theorem states: P(E) = 1 – P(E).
P(E does not happen) = 1 – P(E does happen).
---------------------------------------------------------------------------------------------------------------------------------If R is the event it rains, then R is the event it does not rain. If P(R) = .80, then P(R) = 1 – .80 = .20.
=============================================================================
12 Let E and F be events.
E F is the event: either E or F occurs. E F is read as “E or F”.
Remark: E F = F E.
E F is the event: both E and F occur. E F is read as “E and F”.
Remark: E F = F E.
=============================================================================
13 The Conditional Probability of E given F , denoted P(EF), is the probability that event E happens,
P(E F)
given that event F has already happened. P(EF) =
Remark: P(EF) P(FE).
P( F)
---------------------------------------------------------------------------------------------------------------------------------Let R be the event of rain and let H be the event of high winds with P(R) = .40, P(H) = .30, and
P(R H) .20 2
67%.
P( H )
.30 3
Note: Since P(R) P(RH), R and H are said to be dependent events. See the next sheet for definitions.
and
P(R H) = .20. If we have high winds, find P(RH).
P(RH) =
P( H R ) .20 1
= 50%,
P( R )
.40 2
=============================================================================
14 The General AND Rule states: P(E F) = P(EF) P(F).
General Multiplication Rule, page 175
Example 2: If we have rain, find P(HR).
P(HR) =
12
Also, P(E F) = P(E) P(FE).
=============================================================================
=============================================================================
15 Independent Events are events such that the occurrence of one has no effect on the other.
Page 174
=============================================================================
16 The Definition of Independent Events states: E and F are independent events if P(EF) = P(E).
=============================================================================
and
17 The Special AND Rule states: E and F are independent events if and only if P(E F) = P(E) P(F).
---------------------------------------------------------------------------------------------------------------------------------If E and F are independent, then P(E F) = P(E) P(F);
and if P(E F) = P(E) P(F), then E and F are independent.
--------------------------------------------------------------------------------------------------------------------------------Dependent Events are events that are not independent. P(E) P(EF)
---------------------------------------------------------------------------------------------------------------------------------The Experiment: Toss a coin twice. S = {HH, HT, TH, TT}.
2 2 = 4.
Event H1: Get heads on the 1st toss. Event H2: Get heads on the 2nd toss.
Are H1 & H2 are independent events?
H1 = {HH, HT}. H2 = {HH, TH}.
P(H1) =
2
.
4
P(H2) =
2
.
4
H1 H2 = {HH}.
P(H1 H2) =
1
.
4
P(H1 H2) = P(H1) P(H2) so
1
4
H1 and H2 are independent events.
=
2
2
.
4
4
1
2
1
P(H2 H1) 4 1
Also P(H2H1) =
= .
. P(H2) =
2
4
P(H1)
2 2
4
Since P(H2H1) = P(H2) we again have shown that H1 and H2 are independent events.
1424
===============================================================================
or
18 The General OR Rule states: P(E F) = P(E) + P(F) – P(E F).
General Addition Rule, page 182
===============================================================================
19 Mutually Exclusive Events are events that cannot occur at the same time.
Page 182
===============================================================================
20 The Special OR Rule states: If E and F are mutually exclusive events, then P(E F) = P(E) + P(F).
------------------------------------------------------------------------------------------------------------------------------------Let H be the event of being at home, and let C be the event of being at PGCC with P(H) = .40 and
P(C) = .20. Since H and C are mutually exclusive events, P(H C) = .40 + .20 = .60.
------------------------------------------------------------------------------------------------------------------------------------In the coin experiment above: S = {HH, HT, TH, TT}. Find P(H1 H2).
H1 = {HH, HT}. H2 = {HH, TH}.
H1 H2 = {HH, HT, TH}.
13
H1 H2 = {HH}.
2
2
1
3
+ –
=
4
4
4
4
===============================================================================
-- Compare to 191,19 & 192,21 ------------------------------------------------------------------------------------------------
P(H1 H2) = P(H1) + P(H2) – P(H1 H2) =
Two instructors, Harris and Smith, had these grades.
They had no students in common.
The experiment: Pick a student.
A
B
C
t
Event A: Get an A. Event B: Get a B.
Event S: Be a Smith student.
1) Are events A and S independent?
2) Are events B and S independent?
Events E and F are independent if
1) P(A) =
17
7
. P(AS) =
.
40
16
Harris Smith T
10
7
17
6
4
10
8
5
13
24
16 40
Since
1. P(E) = P(EF) or
2. P(E F) = P(E) P(F)
17
7
, A and S are dependent events.
40 16
10
4
10
4
. P(BS) =
. Since
=
, B and S are independent events.
40
16
40 16
--------------------------------------------------------------------------------------------------------------------------------------7
7
17 23
Other probabilities: P(SA) =
. P(S A) =
.
P(A) = 1 – P(A) = 1 –
=
.
40
40 40
17
2) P(B) =
7
16 17 7 26
13
P(S A) 40 7
P(S A) P(S) P(A) P(S A)
=
. P(SA) =
20
40 40 40 40
P( A )
17 17
40
-- Page 189, 8 --------------------------------------------------------------------------------------------------------------------The experiment: Roll two dice, one green, one red. This experiment has 36 outcomes. See page 176
or
(a) Event A: Get a sum of 7. A = {16, 25, 34, 43, 52, 61} P(A) = 6/36 = 1/6 17%
P(B) = 2/36 = 1/18 6%.
(b) Event B: Get a sum of 11. B = {56, 65}
(c) A & B are ME P(A B) = 6/36 + 2/36 = 8/36 22%.
-- Page 190, 14 ------------------------------------------------------------------------------------------------------------------The experiment: Pick a person.
F
P( FS)
P(S) = .125
P(FS) = .14
.14
P(S) = .875
S
.125
.86
.875
F
F
P(FS) = .24
The General and Rule
(a) P(S F) = .125 .14 = .0175
P(S)
P(F S)
(b) P(S F) = .875 .24 = .21
P(S )
P(F S )
.24
S
.76
P(FS)
F
Added example (e)
P(F) = .0175 + .21 = .2275
== End Block 1====================================================================
14
=============================================================================
114
Block 1 Language Test Statements
Erdeky
---------------------------------------------------------------------------------------------------------------------------------Ten of the following 43 statements will be on Test L1. They will appear as you see them below.
You are required to be able to do all of them even though only 10 will be on the test.
=============================================================================
1 Define: Population
2 Define: Sample
3 Define: Data
4 Define: Descriptive Statistics
5 Define: Inferential Statistics
6 Define: Simple Random Sampling
7 Define: Histogram
8 Define: The Class Frequency fi
9 Complete: The Relative Class Frequency is
10 Complete: A Frequency Distribution shows
11 Define: Mode
12 Define: Median
13 Define: Mean
14 See 23
15 See 23
16 Define: Range
17 See 23
18 See 23
19 Write a formula for: The Coefficient of Variation
20 Write: The Standard Deviation Intervals about the Mean
21 Complete: Chebyshev’s Rule states: At least ______________ of the data of ____________________ are
within k standard deviations of the mean.
Specifically: a) At least ________ of the data are within 2 SD of the mean.
b) At least ________ of the data are within 3 SD of the mean.
c) At least ________ of the data are within 4 SD of the mean.
22 Complete: The z score of x is given by the formula z =
23 State exactly what each symbol represents:
N
n
s
s2
2
R x
----------------------------------------------------------------------------------------------------------------------------------
15
---------------------------------------------------------------------------------------------------------------------------------1
Complete: The Fundamental Counting Principal states:
2 Define: A Probability Experiment
3 Define: The Sample Space
4 Define: Event
5 Complete: The Probability of E, P(E), is an indication
6 Complete: A probability is a number ____________________________
7 Define: Equally Likely Events
8 Complete: The Basic Probability Theorem states: If an event E, with f outcomes, is part of an
experiment in which all N outcomes are _____________________, then P(E) =
9 Complete: The Basic Sum Property of probability states:
10 Define: The Complement of Event E, E
11 Complete: The Failure Theorem states: P(E) =
12 Complete: E F is the event ________________________________
E F is the event _______________________________
13 Complete: The Conditional Probability of E given F
is the probability of event E, given that event F has ______________________.
The formula is P(EF) =
14 The General and Rule states: P(E F) =
15 Complete: Independent Events are events such that the occurrence of one_____________________
16 Complete: The Definition of Independent Events states:
E and F are independent if P(EF) =
17 Complete: The Special and Rule states:
If E and F are _______________________________, then P(E F) =
18 Complete: The General or Rule states: P(E F) =
19 Define: Mutually Exclusive Events
20 Complete: The Special or Rule states:
If E and F are _________________________________, then P(E F) =
=============================================================================
16
Homework Problems ================================================================
19,3 RANDOM
Your random numbers will be different.
20,8 RANDOM
Arrow down L3 to see if any numbers are repeated
185 is repeated in my list repeats.
Two people out of the 30 have there birthday on the 185th day of the year.
------------------------------------------------------------------------------------------------------------------------------------21,10 b RANDOM
Select a suit off the line at these times:
8:01, 8:12, 9:14, 10:09, 11:05, 11:06, 11:27 , 11:41.
Two of the numbers were pasted over because they
are not useful. Repeat the program and select form
the top of L1.
Also select a suit at 9:04 and 10:12.
21,13
RANDOM
Answer key
Question 1
Random 4
Answers d
1=a, 2=b, 3=c, 4=d, 5=e
2 3 4 5 6 7 8 9 10
2 1 1 4 5 3 4 2 5
b a a d e c d b e
67,1
HIST
wait, wai,t wait
67,3
HIST
wait, wai,t wait
data
boundaries
f
72,15
HIST
data
boundaries
f
data
17
boundaries
f
rf
rf
rf
---------------------------------------------------------------------------------------------------------------------------------------
106,1
DESCRIPT
--------------------------------------------------------------------------------------------------------------------------------------106,5
DESCRIPT
a
DESCRIPT
TRIM
b
d
--------------------------------------------------------------------------------------------------------------------------------------107,7
DESCRIPT
DESCRIPT
108,11
DESCRIPT
a
TRIM
b
--------------------------------------------------------------------------------------------------------------------------------------121,1
DESCRIPT
DESCRIPT
ac
e
---------------------------------------------------------------------------------------------------------------------------------------
18
--------------------------------------------------------------------------------------------------------------------------------------122,4
DESCRIPT
DESCRIPT
bx
by
CHEBY
cx
cy
ZTXVALUE
dx
dy
--------------------------------------------------------------------------------------------------------------------------------------124,7 CHEBY
a
b
--------------------------------------------------------------------------------------------------------------------------------------124,9
DESCRIPT
ZTXVALUE
ab
CHEBY
d
--------------------------------------------------------------------------------------------------------------------------------------125,15 ZTXVALUE
CHEBY
b
Vanguard
Pax
a
Vanguard
Pax
19
---------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------------------------------------148,1
DESCRIPT
ZTXVALUE
DESCRIPT
ZTXVALUE
--------------------------------------------------------------------------------------------------------------------------------------150,7
DESCRIPT
ZTXVALUE
DESCRIPT
ZTXVALUE
--------------------------------------------------------------------------------------------------------------------------------------171,7
FREQDIST
172,9
FREQDIST
--------------------------------------------------------------------------------------------------------------------------------------58
25
174,15
a P(enters walks by) =
b P(buys enters) =
Buys Buy Total
127
58
Enters
25
33
58
0
69
69
25
33
Enters
c P(enters buys) =
d P(buy enters) =
25
102 127
127
58
---------------------------------------------------------------------------------------------------------------------------------S
Total
S
191,19 e P(S) = 474/1160 .4086
A
270 310 580
P(S | A) = 310/474) .6540 S & A are dependent.
p
416 164 580
total 686 474 1160
---------------------------------------------------------------------------------------------------------------------------------
20
--------------------------------------------------------------------------------------------------------------------------------------x
2
3
4
5
6
7
8
9
10
11
12
172,10 S = {2,3,4,5,6,7,8,9,10,11,12}
f
P(x)
FREQDIST
1
1/36
2
2/36
3
3/38
4
4/36
5
5/36
6
6/36
5
5/36
4
4/36
3
3/36
2
2/36
1
1/36
QUIT L2 etc
PROBDIST
PROBDIST
c P(x < 5) = P(x 4) = P(2) + P(3) + P(4) = 1/36 + 1/18 + 1/12 = .1666… = 1/6
d P(5 6) = P(5 x 6) = 1/9 + 5/36 = ¼ = .25
--------------------------------------------------------------------------------------------------------------------------------------174,15 On sheet 20
---------------------------------------------------------------------------------------------------------------------------------190, 15
Person
Polygraph
T2
(a)
P(T1 L2) = .90 .07 = .063 = 6.3%
P(L2L1) = .72
.93
(b) P(L1 L2) = .10 .72 = .072 = 7.2%
T1
P(L2T1) = .07
.90
.07
L2
.10
.28
T2
L1
.72
L2
----------------------------------------------------------------------------------------------------------------------------------
21
---------------------------------------------------------------------------------------------------------------------------------eyes
person
191,17
W
(a) P(W G) = .554 .56 = .31
G
.554
.56
.446
.036
.631
(b) P(M G) = .446 .56 = .25
M
(c) P(W C) = .631 .036 = .023
W
(d) P(M C) = .369 .036 = .013
C
.369
M
.404
N
--------------------------------------------------------------------------------------------------------------------------------191,19 On sheet 20
--------------------------------------------------------------------------------------------------------------------------------192,21 a P(p | cp) = 72/154. f P(p cp) = 72/270
cp cp Total
p
72 37 109
N
82 79 161
total 154 116 270
--------------------------------------------------------------------------------------------------------------------------------First Year
Second Year
193, 25
O2
Profit = O = Over $940,000
A = O1
B = O2
.87
O1
P(O2) = .71
(a) P(O1) = .65, given in problem
.65
.13
O2
(b) P(O2) = .71, given in problem
O2
.35
(c) P(O2 O1) = .87, given in problem
O1
(d) P(O1 O2) = .65 .87 = .57
O2
(e) P(O1 O2) = P(O1) + P(O2) – P(O1 O2) = .65 + .71 – .57 = .79
(f) P(will not close) = P(O1 O2) = . 79. P(will close) = 1 – P(will not close) = 1 – .79 = .21.
---------------------------------------------------------------------------------------------------------------------------------Population
Test
p
Sum
N
194, 27
p (a) P(T p) = .04 .82 = .0328 T
.04.82 .04.13
.04
.0328
.0052
P(p T) = .82
.82
T
(b) P(T) = .96
T .96.09 .96.91
.04
Extra problems
(d) Find P(p)
.13
.96
N
p
.09
(c) P(T p) = .96 .09 = .0864
N
.0864
.1192
.8736
.8788
.96
1
(d) P(p) = P((T p) { T p)) = .0328 + .0864 = .1192
T
.91
sum
22
P(T p) .0328
.275168 28%
P(p)
.1192
----------------------------------------------------------------------------------------------------------------------------------
(e) Find P(T p)
(e) P(T p) =
23