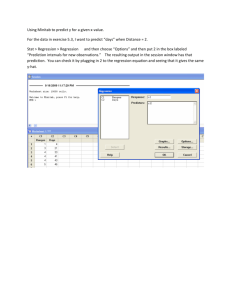
252y0581 1/4/06 KEY
advertisement

252y0581 1/4/06 ECO252 QBA2 Final EXAM December 14, 2005 Name and Class hour:____KEY_________________ I. (12+ points) Do all the following. Note that answers without reasons receive no credit. Most answers require a statistical test, that is, stating or implying a hypothesis and showing why it is true or false by citing a table value or a p-value. If you haven’t done it lately, take a fast look at ECO 252 - Things That You Should Never Do on a Statistics Exam (or Anywhere Else) Berenson et. al. present a file called RESTRATE. It contains Zagat ratings for 50 restaurants in New York City and 50 more restaurants on Long Island. The data columns are described below. ‘Location’ New York or Long Island ‘Food’ Quality of food on a 0-25 scale ‘Décor’ Quality of décor on a 0-25 scale ‘Service’ Quality of service on a 0-25 scale ‘Summated Rating’ The sum of the food, décor, and service variables. ‘Locate’ A dummy variable – 1 if the restaurant is on Long Island ‘Price’ Average price for a meal ($), the dependent variable. ‘Inter’ The product of ‘Location’ and ‘Summated Rating’ The values of these data and the correlation matrix between them appear at the end of this section. We are trying to explain price based on the Zagat rating and the dummy variable for location. The regression is run as follows. Assume a 5% significance level. Regression Analysis: Price versus Locate, Summated rating The regression equation is Price = - 13.7 - 7.54 Locate + 0.961 Summated rating Predictor Constant Locate Summated rating S = 5.94216 Coef -13.699 -7.537 0.96079 SE Coef 5.054 1.197 0.08960 R-Sq = 59.2% Analysis of Variance Source DF SS Regression 2 4960.2 Residual Error 97 3425.0 Total 99 8385.2 Source Locate Summated rating DF 1 1 T -2.71 -6.30 10.72 P 0.008 0.000 0.000 VIF 1.0 1.0 R-Sq(adj) = 58.3% MS 2480.1 35.3 F 70.24 P 0.000 Seq SS 900.0 4060.2 a) What is the difference (in dollars) in expected price of a meal at restaurants of similar quality in New York and Long Island? (1) Solution: The Equation reads Y 13.7 7.54 X 1 0.961 X 2 , where X 1 is the dummy variable ‘Locate’ and X 2 is the Zagat rating. Since X 1 1 on Long Island and X 1 0 in the city, the expected price on Long Island is $7.54 lower than in New York City. This was, quite predictably the easiest question on the exam. Why did so few people get it? b) How much would you expect to pay for a meal at a New York restaurant with a Zagat (summated) rating of 50? (1) Solution: Since Y 13.7 7.54 X 1 0.961 X 2 , and X 1 0 in New York, we have Y 13.7 7.540 0.96150 $34.35 . Again a terribly easy question. c) Which of the coefficients are significant? Do not answer this without evidence from the printout. (2) Solution: As usual many people thought that this was an opinion question or had no idea what statistical significance means. The easiest way to do this is to note that all the p-values are below 5% and 1% so that 1 252y0581 1/4/06 97 the constant and the coefficients of both X 1 and X 2 are significant. Of course, you could look up t .05 and note that all the t-ratios in the printout are above it, but why bother? d) Compute the coefficient of partial determination (partial correlation squared) for ‘locate’ and explain its meaning. (2) Solution: As explained in the outline, the easy way to do this problem is to note that on the t2 6.30 2 .2904 . If you would printout, t1 6.30 and DF 97 . Therefore rY22.1 2 1 t1 DF 6.30 2 97 rather work harder, note that in the regression above RY212 .592 , and in the stepwise regression on the next page RY22 .4246 , rY22.1 RY212 RY22 1 RY22 .592 .4246 .2909 . This is the fraction of the remaining 1 0.4246 variation in the dependent variable explained by ‘locate’ after ‘summated rating’ is used alone. Now the authors suggest that we add the interaction term to the equation. The new result is. Regression Analysis: Price versus Locate, Summated rating, Inter The regression equation is Price = - 26.3 + 13.1 Locate + 1.19 Summated rating - 0.368 Inter Predictor Constant Locate Summated rating Inter S = 5.84913 Coef -26.291 13.13 1.1872 -0.3676 SE Coef 7.957 10.26 0.1423 0.1813 R-Sq = 60.8% Analysis of Variance Source DF SS Regression 3 5100.9 Residual Error 96 3284.4 Total 99 8385.2 Source Locate Summated rating Inter DF 1 1 1 T -3.30 1.28 8.34 -2.03 P 0.001 0.204 0.000 0.045 R-Sq(adj) = 59.6% MS 1700.3 34.2 F 49.70 P 0.000 Seq SS 900.0 4060.2 140.6 d) Is this a better regression than the previous one? In order to answer this comment on R-squared, Rsquared adjusted and the sign and significance of the coefficients. (3) Solution: If we look at R-squared alone, we go from RY212 .592 and RY212 .583 to RY2123 .608 and RY2123 .596 , so that both R-squares have risen and there seems to be an improvement. Note, however, that the coefficient of ‘locate’ is no longer significant and that the coefficient of ‘inter’ is only significant at the 5% level. This suggests that the location of the restaurant changes the slope of the regression line more than the intercept and that we might do just as well without ‘locate.’ Furthermore the coefficient of ‘locate’ is positive which seems to be telling us that LI restaurants are more expensive than city restaurants, which sounds unlikely. Note that our first regression Y 13.7 7.54 X 1 0.961 X 2 has been replaced by Y 26.3 13.1X 1 1.19 X 2 0.368 X 3 26.3 13.1X 1 1.19 X 2 0.368 X 1 X 2 [9] 2 252y0581 1/4/06 At this point I was on my own. First I ran a stepwise regression and got the following. Stepwise Regression: Price versus Food, Décor, ... Alpha-to-Enter: 0.15 Alpha-to-Remove: 0.15 Response is Price on 6 predictors, with N = 100 Step Constant 1 -13.66 2 -18.40 3 -15.14 4 -15.82 0.893 8.50 0.000 1.047 11.51 0.000 1.323 9.14 0.000 1.953 4.53 0.000 -0.137 -6.57 0.000 -0.137 -6.74 0.000 -0.139 -6.85 0.000 -0.93 -2.42 0.018 -1.85 -2.62 0.010 Summated rating T-Value P-Value Inter T-Value P-Value Food T-Value P-Value Décor T-Value P-Value -0.93 -1.55 0.125 S R-Sq R-Sq(adj) 7.02 42.46 41.87 5.87 60.16 59.34 5.73 62.44 61.27 5.69 63.37 61.83 More? (Yes, No, Subcommand, or Help) SUBC> n The results here don’t seem very practical. For example the fourth version of the regression this gives me is Price = - 15.82 + 1.953 Summated rating – 0.139 Inter – 1.85 Food -0.93 Décor Note that the number under the coefficient is a t-ratio and the number under that is a p-value for the significance test. e) What are the two ‘best’ variables the stepwise regression picks? Why might I be reluctant to add ‘Food’ and ‘Décor’ in spite of evidence in the significance tests? (2) [11] Solution: If we look at the previous regression, we could have predicted that ‘locate’ would be dropped, making ‘summated rating’ and ‘inter’ the ‘best’ predictors. The stepwise procedure then added ‘food’ and ‘décor,’ and the coefficient of ‘food’ was significant at the 5% level. But ‘food’ is already part of ‘summated rating,’ so it seems reasonable that if we use ‘food’ and ‘décor’ we should drop ‘summated rating.’ So, the next version of the regression that I did was. MTB > regress c7 2 locate inter; SUBC> VIF. Regression Analysis: Price versus Locate, Inter The regression equation is Price = 39.7 - 52.9 Locate + 0.820 Inter Predictor Constant Locate Inter Coef 39.740 -52.896 0.8196 S = 7.64274 SE Coef 1.081 8.541 0.1469 R-Sq = 32.4% Analysis of Variance Source DF SS Regression 2 2719.3 Residual Error 97 5665.9 Total 99 8385.2 Source Locate Inter DF 1 1 T 36.77 -6.19 5.58 P 0.000 0.000 0.000 VIF 31.2 31.2 R-Sq(adj) = 31.0% MS 1359.7 58.4 F 23.28 P 0.000 Seq SS 900.0 1819.3 3 252y0581 1/4/06 This was pretty much as I expected, so I added the components of Zagat’s rating to the equation. MTB > regress c7 5 c6 c8 c2 c3 c4; SUBC> VIF. Regression Analysis: Price versus Locate, Inter, Food, Décor, Service The regression equation is Price = - 21.1 + 8.8 Locate - 0.294 Inter + 0.251 Food + 1.15 Décor + 1.97 Service Predictor Constant Locate Inter Food Décor Service Coef -21.130 8.84 -0.2937 0.2505 1.1465 1.9678 S = 5.69379 SE Coef 7.979 10.22 0.1804 0.3766 0.2798 0.4322 R-Sq = 63.7% Analysis of Variance Source DF SS Regression 5 5337.8 Residual Error 94 3047.4 Total 99 8385.2 Source Locate Inter Food Décor Service DF 1 1 1 1 1 T -2.65 0.86 -1.63 0.67 4.10 4.55 P 0.009 0.390 0.107 0.508 0.000 0.000 VIF 80.6 84.9 2.7 2.3 3.2 R-Sq(adj) = 61.7% MS 1067.6 32.4 F 32.93 P 0.000 Seq SS 900.0 1819.3 371.6 1574.8 672.1 f) Use an F test to compare Price = 39.7 - 52.9 Locate + 0.820 Inter with Price = - 21.1 + 8.8 Locate - 0.294 Inter + 0.251 Food + 1.15 Décor + 1.97 Service What does the F test show about the 3 variables that we added? (3) [14] Solution: All I got on this from anybody was BS. Yes, it is true that the F tests done by the computer showed that there was a relationship between the independent variables and the dependent variables. But as the posted problems and the material presented in class show, the way to do a comparison for a group of variables is to note from the sequential SS printout that the sum of squares explained by the first two independent variables is 900.0 + 1819.3 = 2719.3. The next three variables explain 371.6 + 1574.8 + 672.1 = 2618.5. We can make the ANOVA table below. We will use X 1 and X 3 for ‘locate’ and ‘inter’ and X 4 , X 5 and X 6 for ‘food,’ ‘décor’ and ‘service.’ Source SS DF MS F X1, X 2 2719.3 2 X 4, X5, X6 2618.5 3 872.8 26.938 Error Total 3047.4 94 8385.2 99 32.4 F.05 3,94 2.71 F.05 2 2 n k r 1 Rk r Rk 94 .637 .324 28 .6 r 3 1 .637 1 Rk2 r Since our computed F is far larger than the table F, we can reject the null hypothesis that these new variables as a group do not help explain the variation in Y. Note, however, that the coefficients of ‘locate’ ‘inter’ and ‘food are not significant. However, except for ‘locate,’ all the coefficients have a plausible sign. We could also do this by computing 4 252y0581 1/4/06 g) Now compare Price = - 21.1 + 8.8 Locate - 0.294 Inter + 0.251 Food + 1.15 Décor + 1.97 Service with Price = - 26.3 + 13.1 Locate + 1.19 Summated rating - 0.368 Inter You can’t use an F test here but you can look at R-squared and significance. Does the equation that I just fitted look like an improvement? As always, give reasons. (2). [16] 2 Solution: For the second of these equations we had RY123 .608 and RY2123 .596 and for our newest equation we have RY213456 .637 and RY213456 .617 . This looks like an improvement. Both equations, however, have an insignificant coefficient for ‘locate.’ h) I don’t think I am finished. Should I drop some variables from Price = - 21.1 + 8.8 Locate - 0.294 Inter + 0.251 Food + 1.15 Décor + 1.97 Service ? Why? Which would you suggest that I drop first? Why? Check VIFs and significance. (2) [18] Solution: Normally, the high VIFs for ‘locate’ and ‘inter’ would be an alarm. But we know that these come from the same source. Nevertheless the poor results we have gotten generally for ‘locate’ and its high pvalue suggest that it would be dropped. The coefficient of ‘food’ is also not significant. So we should probably drop each of them separately and then try the equation with both variables removed. 5 252y0581 1/4/06 ————— 12/6/2005 8:46:21 PM ———————————————————— Welcome to Minitab, press F1 for help. MTB > print c1-c8 Data Display Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 Location NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC NYC LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI Food 19 18 19 23 23 23 20 20 19 21 20 21 24 20 17 21 21 20 17 21 23 17 22 19 21 19 19 21 24 19 17 19 22 22 14 22 20 18 18 24 21 18 20 21 19 18 20 21 19 21 21 17 17 23 23 21 21 21 22 22 23 23 21 17 23 15 Décor 21 17 16 18 20 18 17 15 18 19 17 23 20 17 18 17 19 16 11 16 20 19 14 19 19 14 17 13 21 16 15 16 19 18 15 22 15 14 20 18 17 17 19 10 14 17 16 12 17 20 18 14 17 19 22 18 19 18 18 20 20 18 14 17 23 17 Service 18 17 19 21 21 20 16 17 18 19 16 21 22 20 14 20 21 19 13 20 23 16 15 18 20 16 19 21 21 19 15 19 21 20 15 21 18 17 16 21 18 17 19 17 19 17 17 14 19 20 21 17 18 18 21 19 23 18 20 20 22 20 19 17 22 15 Summated rating Locate 58 0 52 0 54 0 62 0 64 0 61 0 53 0 52 0 55 0 59 0 53 0 65 0 66 0 57 0 49 0 58 0 61 0 55 0 41 0 57 0 66 0 52 0 51 0 56 0 60 0 49 0 55 0 55 0 66 0 54 0 47 0 54 0 62 0 60 0 44 0 65 0 53 0 49 0 54 0 63 0 56 0 52 0 58 0 48 0 52 0 52 0 53 0 47 0 55 0 61 0 60 1 48 1 52 1 60 1 66 1 58 1 63 1 57 1 60 1 62 1 65 1 61 1 54 1 51 1 68 1 47 1 Price 50 38 43 56 51 36 25 33 41 44 34 39 49 37 40 50 50 35 22 45 44 38 14 44 51 27 44 39 50 35 31 34 48 48 30 42 26 35 32 63 36 38 53 23 39 45 37 31 39 53 37 37 29 38 37 38 39 29 36 38 44 27 24 34 44 23 Inter 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 60 48 52 60 66 58 63 57 60 62 65 61 54 51 68 47 6 252y0581 1/4/06 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI LI 19 20 20 20 23 19 15 20 21 23 27 17 22 20 20 25 17 25 19 27 21 19 20 23 24 18 15 16 18 20 21 21 23 19 14 19 15 12 19 21 13 17 17 20 16 17 11 16 12 25 17 22 18 20 11 18 21 19 27 18 16 20 16 12 24 18 15 14 17 18 17 18 20 19 15 22 18 21 19 16 17 19 16 24 18 23 19 24 17 19 20 21 23 20 14 17 17 18 21 19 20 16 50 57 52 50 62 59 43 59 56 64 62 50 50 55 48 74 52 70 56 71 49 56 61 63 74 56 45 53 51 50 66 58 58 49 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 30 32 25 29 43 31 26 34 23 41 32 30 28 33 26 51 26 48 39 55 24 38 31 30 51 30 27 38 26 28 33 38 32 25 50 57 52 50 62 59 43 59 56 64 62 50 50 55 48 74 52 70 56 71 49 56 61 63 74 56 45 53 51 50 66 58 58 49 MTB > Correlation c2 c3 c4 c5 c6 c8. Correlations: Food, Décor, Service, Summated rating, Locate, Inter Food 0.374 0.000 Décor Service 0.727 0.000 0.633 0.000 Summated rat 0.800 0.000 0.824 0.000 0.914 0.000 Locate 0.089 0.381 0.084 0.406 0.137 0.175 0.120 0.235 Inter 0.203 0.043 0.201 0.045 0.253 0.011 0.257 0.010 Décor Service Summated rat Locate 0.984 0.000 7 252y0581 1/4/06 II. Do at least 4 of the following 6 Problems (at least 10 each) (or do sections adding to at least 38 points – (Anything extra you do helps, and grades wrap around). You must do parts a) and b) of problem 1. Show your work! State H 0 and H1 where applicable. Use a significance level of 5% unless noted otherwise. Do not answer questions without citing appropriate statistical tests – That is, explain your hypotheses and what values from what table were used to test them. Clearly label what section of each problem you are doing! The entire test has 151+ points, but 70 is considered a perfect score. Is there some reason why most of you couldn’t be bothered to state your hypotheses? 1. a) If I want to test to see if the mean of x 2 is larger than the mean of x1 my null hypotheses are: (Note: D 1 2 ) v) 1 2 and D 0 vi) 1 2 and D 0 i) 1 2 and D 0 ii) 1 2 and D 0 iii) 1 2 and D 0 vii) 1 2 and D 0 iv) 1 2 and D 0 viii) 1 2 and D 0 (2) Solution: I’m not going to answer this one. You all had this question in advance and there is no excuse for the fact that most of you got it wrong. Let us revisit Problem B in the take-home. We are going to evaluate the evaluators. Candidate 1 2 3 4 5 6 7 8 9 Moore 52 25 29 33 24 36 42 49 20 Gaston Difference 38 14 31 -6 24 5 29 4 27 -3 28 8 41 1 27 22 31 -11 Assume that we can use the Normal distribution for these data. There are 4 columns here: first, the number of the candidate; second Moore’s evaluation of the candidate; third Gaston’s evaluation of the same candidates. Finally, we have the difference between the ratings. Don’t forget that the data are cross-classified. Note that x1 310 the sums for Moore’s column are and x12 11696 . For the difference column, they are d 34 and d 2 952 b) Compute the mean and standard deviation for Gaston. (2) Show your work! c) The mean rating that has been given to hundreds of job candidates interviewed over the last year is 35. Regard Gaston’s ratings as a random sample from a Normal population and test that his mean rating is below 35. Use (i) Either a test ratio or a critical value for the mean (3) and (ii) an appropriate confidence interval. (2) d) Test the hypothesis that the population mean for Moore is higher than for Gaston. Don’t forget that the data is cross-classified. (3) e) To see how well they agree, compute a correlation between Moore’s and Gaston’s ratings and check it for significance. (5) [17] Solution: Assume .05 . Note that this is paired data! By now you should know why. Spare Parts computation Candidate Gaston x2 1 2 3 4 5 6 7 8 9 38 31 24 29 27 28 41 27 31 276 x 22 x1 x 2 1444 961 576 841 729 784 1681 729 961 8706 1976 775 696 957 648 1008 1722 1323 620 9725 x x 1 2 9725 n9 8 252y0581 1/4/06 x 310 and x 11696 x 276 and x 8706 d 34 and d 952 x 310 34.4444 x 1 2 1 2 2 2 x2 2 d x 2 n 276 30 .6667 9 d 34 3.7778 n 9 1 1 n 9 x nx 11696 934.4444 1018 .25 s 8 127 .281 s S x1x 2 x1 x 2 nx1 x 2 9725 934.4444 30.6667 218 .3352 241 .98 SS x nx 8706 930 .6667 241 .98 s 30 .248 s 8 SS x1 2 1 2 1 x2 2 2 2 2 d nd x nx SS d 2 2 2 2 2 2 1 2 1018 .45 1 2 2 2 952 93.7778 2 823 .5540 s d2 127 .281 11 .2819 30 .248 5.4998 823 .5540 102 .944 s d 102 .944 10 .1461 8 2 2 s 2 30 .248 5.4998 30 .248 n 1 c) H 0 : 35 H 1 : 35 Did you state your hypotheses? From the Formula Table: b) s 22 Interval for Confidence Interval x t 2 s x Mean ( unknown) x2 x 2 DF n 1 Hypotheses Test Ratio H0 : 0 t H1 : 0 276 30 .6667 s 2 30 .248 5.4998 9 n n 1 t t.805 1.860 n9 Critical Value xcv 0 t 2 s x x 0 sx sx2 s2 n sx s n 30 .248 1.833 9 0 35 x 0 30 .6667 35 2.364 Make a diagram: The diagram should show sx 1.833 an almost Normal curve centered at zero. Since this is a left-sided test, the ‘reject’ region is the area below tn1 t.805 1.860 . Shade the area below -1.860. Since t calc 2.364 falls in the reject region, reject the null hypothesis. Critical Value for x : This is a left-sided test, so that the critical value will be below 0 35 . xcv 0 t s x 35 1.860 1.833 31.5906 . Make a diagram: The diagram should show an almost Normal curve centered at 0 35 . Since this is a left-sided test, the ‘reject’ region is the area below x cv 31 .5906 . Shade the area below 31.5906. Since x 2 30 .6667 falls in the reject region, reject the null hypothesis. (iii) Confidence Interval. Since the alternative hypothesis is H 1 : 35 , we want a confidence interval of the form x t s x 30.6667 1.860 1.833 34.0760 . Make a diagram: The diagram should show an almost Normal curve centered at x 2 30 .6667 . The confidence interval is the area below 30.6667. Shade the area below 30.6667. Since 0 35 does not fall in the confidence interval, reject the null hypothesis. (i) Test Ratio: t 9 252y0581 1/4/06 d) H 0 : 1 2 and D 0 H 1 : 1 2 and D 0 Did you state your hypotheses? Interval for Confidence Interval Hypotheses Test Ratio Difference between Two Means (paired data.) D d t 2 s d H 0 : D D0 * t H 1 : D D0 , d x1 x 2 df n 1 where n1 n 2 n D 1 2 d 3.7778 s d 102 .944 10 .1461 n 9 s d sd Critical Value d D0 sd sd d cv D0 t 2 s d sd n 102 .944 3.382 tn1 t.805 1.860 D0 0 . 9 n Use only one of the following three methods. d D0 3.7778 0 Test Ratio: t 1.117 Make a diagram: The diagram should show an sd 3.382 almost Normal curve centered at zero. Since this is a right-sided test, the ‘reject’ region is the area above tn1 t.805 1.860 . Shade the area above 1.860. Since t calc 1.117 does not fall in the reject region, do not reject the null hypothesis. Critical Value for x : This is a right-sided test, so that the critical value will be below D0 0 . d cv D0 t s d 0 1.860 3.382 6.291 . Make a diagram: The diagram should show an almost Normal curve centered at D0 0 . Since this is a left-sided test, the ‘reject’ region is the area below d cv 6.291 . Shade the area below -6.291. Since d 3.7778 does not fall in the reject region, do not reject the null hypothesis. Confidence Interval: Since the alternative hypothesis is H 1 : 1 2 and D 0 , we want a confidence interval of the form D d t s d 3.7778 1.860 3.382 2.513 . Make a diagram: The diagram should show an almost Normal curve centered at d 3.7778 . The confidence interval is the area above -2.513. Shade the area above -2.513. Since D0 0 falls in the confidence interval, do not reject the null hypothesis. e) r X X 1 2 nX 1 X 2 X 12 nX 12 X 22 nX 22 S x1x 2 SS x1 SS x 2 S x21x 2 SS x1 SS x 2 The sign is that of S x1x 2 . We have already computed SS x1 1018 .25 S x1x 2 218 .3352 and SS x 2 241 .98 . So r 218 .3352 2 .1934 .4398 . As always 1 r 1 . According to the outline the test for 1018 .25 241 .98 significance or H 0 : xy 0 against H1 : xy 0 is to use the test ratio t n 2 r sr r 1 r n2 2 .4398 1 .1934 7 .4398 .1152 .4398 1.295 . If this is a two-sided test, compare this .33945 7 ratio with t n2 t .025 2.365 and reject the null hypothesis if t calc is below -2.365 or above 2.365 and say 2 that the correlation is significant. However, the wording of the problem is more likely to be asking for H 0 : xy 0 against H1 : xy 0 in which case we should reject the null hypothesis if t calc is above 7 tn 2 t .05 1.895 . Either seems to me acceptable, and in any case, since t calc is not in either ‘reject’ zone, do not reject the null hypothesis. You can say that the amount of agreement is insignificant. 10 252y0581 1/4/06 2. Of course it was nonsense to assume that the data was Normally distributed in Problem 1. Candidate 1 2 3 4 5 6 7 8 9 Moore 52 25 29 33 24 36 42 49 20 Gaston Difference 38 14 31 -6 24 5 29 4 27 -3 28 8 41 1 27 22 31 -11 a) But, just in case, test Moore’s column for Normality. Remember that the sample mean and variance were calculated from the data. (5) b) Now test that the median for Gaston is below 35. If you can do it, use the Wilcoxon signed rank test. (4) c) Now test to see if the median for Moore is higher than the median for Gaston. Don’t forget that the data is cross-classified. (4) d) Compute a rank correlation between Moore and Gaston’s ratings and test it for significance. (5) [13] Solution: a) H 0 : Normal We know from the previous problem that x1 34 .4444 and s1 127 .281 11 .2819 . The best method to use here is Lilliefors because the sample is small, the data is not stated by intervals, the distribution for which we are testing is Normal, and the parameters of the distribution are unknown. We begin by putting the numbers in order and computing x x x 34 .4444 (actually t ) and proceed as in the Kolmogorov-Smirnov method. z s 11 .2819 From the Lilliefors table for .05 and n 6 , the critical value is .217. Since the maximum deviation (.1328) is below the critical value, we do not reject H 0 . O cum O F F D x z o 20 24 25 29 33 36 42 49 52 -1.28 -0.93 -0.84 -0.48 -0.13 0.14 0.67 1.29 1.56 1 1 1 1 1 1 1 1 1 1 2 3 4 5 6 7 8 9 0.1111 0.2222 0.3333 0.4444 0.5556 0.6667 0.7778 0.8889 1.0000 e .5-.3997=.1003 .5-.3238=.1762 .5-.2995=.2005 .5-.1844=.3156 .5-.0517=.4483 .5+.0557=.5557 .5+.2486=.7484 .5+.4015=.9015 .5+.4406=.9406 .0108 .0460 .1328 .1288 .1073 .1110 .0294 .0126 .0594 H 0 : 1 35 b) Wilcoxon Signed Rank Test: n 9 and .05 . Did you state your hypotheses? The H 1 : 1 35 data are below: The column d is the absolute value of d , the column r ranks absolute values, and the column r * is the ranks corrected for ties and marked with the signs on the differences. x 2 0 median ? d x 2 0 d r* r 38 31 24 29 27 28 41 27 31 35 35 35 35 35 35 35 35 35 3 -4 -11 -6 -8 -7 6 -8 -4 3 4 11 6 8 7 6 8 4 1 2 9 4 7 6 5 8 3 1.0+ 2.59.04.57.56.04.5+ 7.52.5 If we add together the numbers in r * with a + sign we get . T 5.5 . If we do the same for numbers with a – sign, we get T 39.5 To check this, note that these two numbers must sum to the sum of the first n nn 1 910 45 , and that T T 5.5 39.5 45 . numbers, and that this is 2 2 11 252y0581 1/4/06 We check 5.5, the smaller of the two rank sums against the numbers in table 7. For a one-sided 5% test, we use the .05 column. For n 9 , the critical value is 8, and we reject the null hypothesis only if our test statistic is below this critical value. Since our test statistic is 5.5, we reject the null hypothesis. Sign Test: 2 out of 9 are above 35. According to the Binomial table, if n 9 and p .5, Px 2 .08984 . Since this is not below .05 , do not reject the null hypothesis. As usual, some people calculated the median of both columns. They got absolutely no credit. An awfully large number of people did a solution that would be correct for c) for section b). There is no excuse for failing to read a problem before you do it. H 0 : 1 2 c) This is a Wilcoxon Signed rank test again. n 9 and .05 . Did you state your H 1 : 1 2 hypotheses? The data are below: The column d is the absolute value of d , the column r ranks absolute values, and the column r * is the ranks corrected for ties and marked with the signs on the differences. x1 52 25 29 33 24 36 42 49 20 d x1 x 2 x2 38 31 24 29 27 28 41 27 31 d 14 -6 5 4 -3 8 1 22 -11 14 6 5 4 3 8 1 22 11 r r* 8 5 4 3 2 6 1 9 7 8+ 54+ 3+ 26+ 1+ 9+ 7- If we add together the numbers in r * with a + sign we get T 31 . If we do the same for numbers with a – sign, we get T 14 . To check this, note that these two numbers must sum to the sum of the first n nn 1 910 45 , and that T T 31 14 45 . We check 14, the numbers, and that this is 2 2 smaller of the two rank sums against the numbers in table 7. For a one-sided 5% test, we use the .05 column. For n 9 , the critical value is 8, and we reject the null hypothesis only if our test statistic is below this critical value. Since our test statistic is 14, we cannot reject the null hypothesis. H 0 : s 0 d) In this case, we have a 1-sided test . n9 H 1 : s 0 Candidate 1 2 3 4 5 6 7 8 9 rs 1 x1 r1 x2 r2 d d2 52 25 29 33 24 36 42 49 20 9 3 4 5 2 6 7 8 1 38 31 24 29 27 28 41 27 31 8.0 6.5 1.0 5.0 2.5 4.0 9.0 2.5 6.5 1.0 -3.5 3.0 0.0 -0.5 2.0 -2.0 5.5 -5.5 0.0 1.00 12.25 9.00 0.00 0.25 4.00 4.00 30.25 30.25 91.00 Note that and d d 0 2 (a check on ranking) 91 . d 1 691 1 546 1 .7583 0.2417 . If we check the table ‘Critical Values of 720 nn 1 99 1 2 6 2 2 rs , the Spearman Rank Correlation Coefficient,’ we find that the critical value for n 9 and .05 is .5833 so we must not reject the null hypothesis and we conclude that we cannot say that the rankings agree. 12 252y0581 1/4/06 3. (Lind et al -190) We are trying to locate a new day-care center. We want to know if the proportion of parents who are eligible to put children in day care is larger on the south side of town than on the east side of town. a) If the south side is Area 1 and the north side is area 2, state the null and alternate hypotheses and do the test. Answer the question “Should we put the center on the south side?” with a yes, no or maybe depending on your result. (4) b) Find a p-value for the null hypothesis in a) (2) South East c) Do a 2-sided 99% confidence interval for the Number eligible 88 57 proportion eligible on the South side. (2) Sample size 200 150 d) Do a 2-sided 89% confidence interval for the f) Use the Marascuilo procedure to determine proportion eligible on the South side. Do not use whether there is a significant difference between a value of z from the t table! (1) the areas with the largest and second largest e) We suddenly realize that out of 100 parents proportion of eligible parents. (3) [17] surveyed on the North side 51 are eligible. Do a test of the hypothesis that the proportion is the same in all 3 areas. (5) Solution: From the formula table Interval for Confidence Hypotheses Test Ratio Critical Value Interval pcv p0 z 2 p Difference p p 0 p p z 2 s p H 0 : p p 0 z between If p 0 p H 1 : p p 0 p p1 p 2 proportions 1 1 If p 0 p 0 p 01 p 02 p p 0 q 0 p1 q1 p 2 q 2 q 1 p n n s p 1 2 p 01q 01 p 02 q 02 p n1 n2 or p 0 0 n1 n2 n p n2 p 2 p0 1 1 Or use s p n1 n 2 If p1 is the proportion of successes in the first sample (South side), and p2 is the proportion of successes in the second sample (North side), we define p p1 p 2 . Then our hypotheses will be H 0 : p1 p 2 H 1 : p1 p 2 or H 0 : p p 0 0 H 1 : p p 0 0 . Let p1 x1 88 .44 , p2 x2 57 .38 and p p1 p2 .06 where x1 is the number of successes n1 200 n2 150 in the first sample, x 2 is the number of successes in the second sample, n1 and n 2 are the sample sizes and q 1 p . Only one of the usual three approaches to testing the hypotheses should be used. As usual, some people noted that .44 is larger than .38 and did not do a statistical test. They got no credit! Confidence Interval: p p z s p or p1 p 2 p1 p 2 z s p , where 2 s p 2 p1 q1 p 2 q 2 .44 .56 .38.62 .001232 .001571 .002803 .05294 The one n1 n2 200 150 sided interval is p p z s p .06 1.645.05294 .2709 . Compare this interval with p 0 0 . Since p .2709 does not contradict p 0 , do not reject H 0 . Make a diagram: The diagram should show a Normal curve centered at p .06 . The confidence interval is the area above -.2709. Shade the area above -.2709. Since p 0 0 falls in the confidence interval, do not reject the null hypothesis. p p 0 .06 1.1277 where Test Ratio: z p .053207 1 1 1 1 3 4 .4143 .5857 .24266 .002831 .053207 n n 200 150 600 2 1 p p 0 q 0 13 252y0581 1/4/06 and p 0 n1 p1 n 2 p 2 x1 x 2 88 57 145 .4143 . Because our alternate hypothesis is n1 n 2 n1 n 2 200 150 350 p 0 , this is a right-sided test and the rejection zone is above z .05 1.645 . Since the test ratio is not in that interval, do not reject H 0 . Make a diagram: The diagram should show a Normal curve centered at zero. The ‘reject’ region is the area above z .05 1.645 . Shade the area above 1.645. Since z 1.1277 does not fall in the ‘reject’ zone, do not reject the null hypothesis. Critical Value: pCV p0 z p becomes pCV p0 z p 2 0 1.645 .053207 0.0875 and the rejection zone is above 0.0875. If we test this against p .06 , we cannot reject H 0 . For calculation of p , see Test Ratio above. Make a diagram: The diagram should show a Normal curve centered at p 0 0 . The ‘reject’ region is the area above p CV 0.0875 . Shade the area above 0.0875. Since p .06 does not fall in the ‘reject’ zone, do not reject the null hypothesis. The answer to “Should we put the center on the south side?” is a maybe since we have no proof that any area has a greater proportion of eligibles. b) The p-value is Pp .06 Pz 1.127 , where 1.127 is the value of the test ratio found in a). Make a diagram: The diagram should show a Normal curve centered at zero. The p-value is represented by the area above 1.127. Shade the area above 1.127. Pz 1.127 Pz 0 P0 z 1.13 .5 .3708 .1292 . c) 1 .99 , so .01 . p p z s p , where z z.005 2.576 , p .06 and 2 2 sp p1 q1 .44 .56 .035099 . So p .44 2.576 .035099 .44 0.09 . n1 200 d) 1 .89 , so .11 and 2 .112 .055 . So we need to find z 2 z.055 . Make a diagram: The diagram should show a Normal curve centered at zero. Mark z .055 to the right of zero and show, by definition, that it has 5.5% above it and 50% - 5.5% = 44.5% between it and zero. So P0 z z.055 .4450 . The closest we can come to this on the Normal table is P0 z 1.60 .4452 . So z.055 1.60 and our interval is p .44 1.60.035099 .44 0.06. e) With the discovery of the North side, our table changes. South East North Number eligible 88 57 51 Sample size 200 150 100 We now have a chi-squared test of homogeneity. H 0 : p1 p 2 p 3 H 1 : Not all proportions equal O Elig S E N total pr 88 57 51 196 .4356 Our observed data reads as follows. Not 112 93 49 254 .5644 total 200 150 100 450 1.0000 14 252y0581 1/4/06 If we apply the proportions in the p r column to the totals in the columns we get the following. E Elig S E N total pr 87 .12 65 .34 43 .56 196 .02 .4356 Not 112 .88 84 .66 56 .44 253 .98 .5644 total 200 .00 150 .00 100 .00 450 1.0000 We can now compute 2 Row O E 1 2 3 4 5 6 88 112 57 93 51 49 450 87.12 112.88 65.34 84.66 43.56 56.44 450.00 O E 2 E O2 n. E O E 2 O2 E E or 2 O E 2 OE -0.88 0.88 8.34 -8.34 -7.44 7.44 0.00 0.7744 0.7744 69.5556 69.5556 55.3536 55.3536 0.00889 0.00686 1.06452 0.82159 1.27074 0.98075 4.15335 88.889 111.127 49.725 102.162 59.711 42.541 454.153 The degrees of freedom for this application are r 1c 1 2 13 1 2 . .2052 5.9915 . Our computed chi-squared is 2 O2 n 454 .153 450 4.153 . Since this is not larger than .2052 , we E cannot reject the null hypothesis. f) We now know p1 x1 88 .44 , p2 x2 57 .38 and p3 x3 51 .51 n1 200 n2 150 n3 100 The Marascuilo procedure says for 2 by c tests, is equivalent to using a confidence interval of c 1 p a q a p a pb p a pb 2 n a pb qb nb , where a and b represent 2 groups, the chi - squared has 2 p q pq c 1 degrees of freedom. For groups 3 and 1, it gives us p 3 p1 p 3 p1 2 .05 3 3 1 1 n1 n3 .51.49 .44 .56 .51 .44 5.9915 .07 5.9915 .002499 .001232 200 100 .07 0.022354 .07 0.15 . Of course this is not significant since the error part is larger than the difference between the sample proportions. 15 252y0581 1/4/06 Row 1 2 3 4 5 6 7 8 9 10 4. From the data on the right find the following. xy (1) a) b) R 2 (2) c) The sample correlation rxy (1) d) Test the hypothesis that the population correlation between x and y is 0.75 (5) e) Compute a simple regression of x against y . Remember that y is the dependent variable. (4) [13] Solution: a) Row 1 2 3 4 5 6 7 8 9 10 X 3 8 6 9 6 9 6 4 8 5 xy 4206. Y 22 68 68 96 46 80 52 38 78 48 X 3 8 6 9 6 9 6 4 8 5 Y 22 68 68 96 46 80 52 38 78 48 X 64, X 448 Y 596. Y 40000 xy x y and xy x y 2 2 As was stressed in class XY 66 544 408 864 276 720 312 152 624 240 4206 It’s time to compute spare parts. x x 64 6.4 y n 10 y n x nx xy nx y SS x S xy 596 59 .6 10 2 2 448 10 6.42 38 .4 * 4206 106.459.6 391 .60 Note that n 10 not 20. All of you should have learned this from the last exam. SS y y 2 ny 2 40000 1059 .62 4478 .40 * Note: * These spare parts must be positive. The rest may well be negative. XY nXY Sxy 391 .60 .8917 SSy 38.44478 .4 SSx X nX Y nY 2 b) R 2 2 also true that R 2 2 2 2 2 2 As always 0 R 2 1 . It is b1 Sxy 10 .1979 391 .60 .8917 , but you probably haven’t found b1 yet. SSy 4478 .4 c) r .8917 .9443 As always 1 r 1 . d) H 0 : xy .75 . H1 : xy .75 . According to the outline “If we are testing H 0 : xy 0 against H 1 : xy 0 , and 0 0 , the test is quite different. We need to use Fisher's z-transformation. Let 1 1 r 1 1 0 ~ z ln . This has an approximate mean of z ln 2 1 r 2 1 0 ~ n 2 z z 1 sz , so that t . n3 sz and a standard deviation of (Note: To get ln , the natural log, compute the log to the base 10 and divide by .434294482. )” 1 1 r 1 1.9443 1 1 ~ z ln ln ln 34 .9066 3.5527 1.7763 2 1 r 2 0.0557 2 2 16 252y0581 1/4/06 1 1 0 0 0.75 , so z ln 2 1 0 1 1.75 1 1 ln 2 0.25 2 ln 7.00 2 1.9459 0.9730 ~ n 2 z z 0.7763 0.9730 1 1 sz 0.377965 and t 0.5204 . Since this is between n3 7 sz 0.377965 8 8 t n2 t .025 2.306 and t n2 t .025 2.306 , we do not reject the null hypothesis and we can say that 2 2 the correlation is not significantly different from 0.75. e) We conclude that b1 Sxy SSx xy nxy 391 .6 10.1979 x nx 38.4 2 2 b0 y b1 x 59.6 10.1979 6.4 5.6666 . So Yˆ b0 b1 x becomes Yˆ 5.6666 10.1979 x . This is the regression equation. It is not time to start substituting in values of X. . 17 252y0581 1/4/06 Row 1 2 3 4 5 6 7 8 9 10 5. From the data in Problem 4 find the following a) s e (3) b) Do a significance test for the slope b1 (3) c) Find a confidence interval for the constant b0 (3) d) Do an ANOVA for this regression and explain its meaning. (3) e) Find the value of Y when X is 9 and build a prediction interval around it (3) [15] Solution: From the last page we have n 10, SS x X 3 8 6 9 6 9 6 4 8 5 Y 22 68 68 96 46 80 52 38 78 48 X 64, X Y 596. Y x 2 2 448 2 40000 nx 2 38 .4 , S xy xy nxy 391 .60 , SST SS y 4478 .40 , R 2 .8917 and that our equation is Yˆ b0 b1 x 5.6666 10.1979 x . a) Compute s e . SSR b1 Sxy b1 xy nxy 10.1979 391 .60 3993 .50 and SSE SST SSR 4478 .40 3993 .50 484 .90 or SSR R 2 SST .89174478.40 3993.38 and SSE 1 R 2 SST 1 .8917SST .10834478.40 485.01 s e2 ( s e2 is always positive!) SSE 484 .90 60 .6125 So s e 60 .6125 7.7854 n2 8 b) Compute s b1 and do a significance test on b1 (1.5) Recall n 10, .05 , SSx 391 .60 , s e2 60.6125 and b1 10 .1979 . H 0 : 1 10 For most two-sided tests use t n2 2 t .8025 2.306 . From the outline – “To test use H 1 : 1 10 b 10 t 1 . Remember 10 is most often zero – and if the null hypothesis is false in that case we s b1 1 60 .6125 say that 1 is significant.” s b21 s e2 1.5785 and s b 1.5785 1.2564 . So 1 38 .4 SS x b 10 10 .1979 0 t 1 8.117 . Our rejection zone is below -2.306 and above 2.306. Since s b1 1.2564 our calculated t falls in the upper reject zone, we can say that b1 is significant. c) Compute s b0 and do a confidence interval for b0 (1.5) Recall n 10, .05 , SSx 38.4 , s e2 60.6125 , x 6.4 and b0 5.6666 . 1 s b20 s e2 n 2 60 .6125 1 6.4 60 .6125 1 1.06667 70 .7145 10 X 2 nX 2 10 38 .4 X2 s b 70 .7145 8.4012 0 b0 t 2 sb0 5.6666 2.3068.4012 5.67 19.37 . 0 Since the error part of the interval is larger than b0 5.6666 , we can conclude that the intercept is not significant. 18 252y0581 1/4/06 d) The general format for a regression ANOVA table reads: Source SS DF MS Fcalc Regression SSR k MSR MSR MSE F F k , nk 1 Error n k 1 MSE SSE Total SST n 1 xy nx y 3993 .50 , SST 4478 .40 and SSE 484 .90 . From a) SSR b1 Sxy b1 n 10 and the number of independent variables is k 1 . The ANOVA table for the regression reads: Source SS DF MS Fcalc F.05 1,8 5.32 F.05 Regression 3993.5 1 3993.5 65.89s Error(Within) 484.9 8 60.6125 Total 4478.4 9 Since our computed F is larger than the table F, we conclude that there is a linear relationship between the dependent and independent variable. In a simple regression this is the same as saying that the slope is significant. e) Recall that our equation is Yˆ b0 b1 x 5.6666 10.1979 x . X 0 9 , n 10, .05 , SSx 38.4 , s e2 60.6125 and x 6.4 . The Prediction Interval is Y0 Yˆ0 t sY , where Yˆ 5.6666 10.1979 X 0 1 X X 5.6666 10.1979 9 86.1145 sY2 s e2 0 n SS x 2 1 60.6125 1 9 6.42 1 10 38 .4 60.6125 1.1 0.1760 77.3441 . sY 77 .3441 8.7945 . So Y0 Yˆ0 t sY 86.1145 2.306 8.7945 86.11 20.28 . As usual for small samples these intervals are gigantic. 19 252y0581 1/4/06 6. Do the following a) Assume that n1 10, n 2 12, n3 15, s12 20, and s 22 15, s32 10, .10 and that all come from a Normal distribution. Test the following: 1 15 (2) (i) (ii) 1 2 (2) (iii) Explain what test would be appropriate to test 1 2 3 (1) b) Read both parts of this question before you start. To test the response of an 800 number, I make 20 40 attempts to reach the number, continuing to call until I get through. (i) I hypothesize that the results follow a Poisson distribution with an unknown mean. Test this – data are at right. (6) (ii) I hypothesize that the results follow a Poisson distribution with a mean of 2 (5) Do not do these two parts using the same method. [16] Solution: From the Formula Table. Interval for Confidence Interval Variancen 1s 2 2 2 Small Sample .5 .5 2 Ratio of Variances 1 , DF2 F1DF 2 1 FDF1 , DF2 2 22 s22 DF1 , DF2 F 12 s12 .5 .5 2 DF1 n1 1 DF2 n 2 1 2 .5 .5 2 or 1 2 Number of Unsuccessful Tries before success. 0 1 2 3 4 5 6 7 Hypotheses Test Ratio H 0 : 2 02 2 H1: : 2 02 H0 : 12 22 H1 : 12 22 O 4 2 8 12 10 0 2 2 40 Critical Value n 1s 2 2 s cv 02 F DF1 , DF2 Observed Frequency 2 1 4 6 5 0 1 1 20 .25 .5 2 02 n 1 s12 s 22 and F DF2 , DF1 s 22 s12 a) n1 10, n 2 12, n3 15, s12 20, and s 22 15, s32 10, .10 . So df1 n1 1 10 1 9 and df 2 n 2 1 12 1 11 . (i) H 0 : 1 15 is the same as H 0 : 12 15 , so 2 n 1s 2 02 920 12 . From the 15 9 9 chi-squared table, 2 .05 16.9190 and 2 .95 3.3251 . This is a 2-sided test, and our computed chi-squared must be between these 2 values if we are not to reject the null hypothesis. Since the computed F-ratio is not below the lower table chi-squared, we cannot reject the null hypothesis. (ii) H 0 : 1 2 is the same as H0 : 12 22 . Our two possible ratios are F 9,11 20 15 1.3333 and F 11,9 0.75 . F 11,9 is below one and thus cannot possibly 15 20 20 9 1.3333 3.10 since all numbers on the F-table are at least one. F 9,11 be above F 11.,05 15 20 252y0581 1/4/06 must be compared with F 9,11 .05 2.90 . Since both our computed F’s are below the corresponding table values, we cannot reject the null hypothesis. (iii) Explain what test would be appropriate to test 1 2 3 . The two tests mentioned for multiple variances are the Bartlett and Levene tests. The Bartlett test is appropriate if the underlying distribution is Normal, as it is here. b) To test the response of an 800 number, I make 40 attempts to reach the number, continuing to call until I get through. (i) I hypothesize that the results follow a Poisson distribution with an unknown mean. Test this – data are at right. (6) H 0 : Poisson The only method we have to test a Poisson distribution with an unknown mean is the chi-squared method. First we must find a mean from the data. Number of Unsuccessful Observed Total Tries before success. Frequency Tries 0 4 0 If there are 60 successes in 20 tries the 1 2 2 mean number of unsuccessful tries before a 2 8 16 success is 3. 3 12 36 4 10 40 5 0 0 6 2 12 7 2 14 40 120 The first 3 columns x, f and E are the number of tries, the probability from the Poisson table and the values of E that come from multiplying the probabilities by n 120 . There is a rule here that we should avoid values of E below 5, and I expect you to have eliminated at least the last value of E . This is 2 probably not enough given the large value of D that we get for x 5 . In any case, I left the remaining E cells alone and went ahead to compute the sums. To save space, I used D for O E . As usual, I used both O E 2 O2 n . Actually the regular method E E should be used here to check out the effect of the undersized values of E . x x O E E D f D2 O2 D2 E E the regular and shortcut methods to get 2 0 1 2 3 4 5 6 7+ Sum .049787 .149361 .224042 .224042 .168031 .100819 .050409 .03351 1.991 5.974 8.961 8.961 6.721 4.032 2.016 1.340 0 1 2 3 4 5 6+ 4 2 8 12 10 0 4 1.991 5.974 8.961 8.961 6.721 4.032 3.354 -2.009 3.974 0.961 -3.039 -3.279 4.032 -0.644 40 40.00 -0.004 4.0361 15.7927 0.9235 9.2355 10.7518 16.2570 0.4147 2.02716 2.64357 0.10306 1.03064 1.59974 4.03200 0.12358 8.0362 0.6696 7.1421 16.0696 14.8787 0.0000 4.7676 11.5637 51.5637 In any case, our value of seems to be about 11.56. Since there are 7 rows, but we used the data to 2 estimate one parameter, we get 7 – 1 – 1 = 5 degrees of freedom. .705 14.0671. Since this is larger than our computed 2 , we do not reject the null hypothesis. 21 252y0581 1/4/06 (ii) I hypothesize that the results follow a Poisson distribution with a mean of 2. H 0 : Poisson2 Things suddenly got much easier. I computed the cumulative observed Fo and copied Fe from the cumulative Poisson table. I checked the 5% critical value from the Kolmogorov-Smirnov table and found it was .210. When I got to my second computation in the D F0 Fe column, I had already found a value of D above the critical value, so I decided to reject the null hypothesis and quit. x 0 1 2 3 4 5 6 7 Above 7 Total O 4 2 8 12 10 0 2 2 2 40 O n Fo .10 .05 .20 .30 .25 .00 .05 .05 .00 1.00 .10 .15 .35 .65 .90 .90 .95 1.00 1.00 Fe 0.13534 0.49601 0.67668 0.85712 0.94735 0.98344 0.99547 0.99890 1.00000 D F0 Fe .03534 .34601 22 252y0581 1/4/06 ECO252 QBA2 Final EXAM December 14-16, 2005 TAKE HOME SECTION Name: _________________________ Student Number: _________________________ Class days and time: _________________________ III Take-home Exam (20+ points). Note that interpretation of ANOVA and OLS computer output was presented in class and discussed in documents 252anovaex1, 252anovaex2, 252regrex1 and252regrex2. A) 4th computer problem (5+) This is an internet project. You should do only one of the following 2 problems. Problem 1: In his book, Statistics for Economists: An Intuitive Approach (New York, HarperCollins, 1992), Alan S. Caniglia presents data for 50 states and the District of Columbia. These data are presented as an appendix at the end of this section. The Data consists of six variables. The dependent variable, MIM, the mean income of males (having income) who are 18 years of age or older. PMHS, the percent of males 18 and older who are high school graduates. PURBAN, the percent of total population living in an urban area. MAGE, the median age of males. Using his data, I got the results below. Regression Analysis: MIM versus PMHS The regression equation is MIM = 2736 + 180 PMHS Predictor Constant PMHS Coef 2736 180.08 S = 1430.91 SE Coef 2174 31.31 R-Sq = 40.3% T 1.26 5.75 P 0.214 0.000 R-Sq(adj) = 39.1% Analysis of Variance Source DF SS Regression 1 67720854 Residual Error 49 100328329 Total 50 168049183 MS 67720854 2047517 F 33.07 P 0.000 Unusual Observations Obs PMHS MIM Fit SE Fit Residual St Resid 1 69.1 12112 15180 200 -3068 -2.17R 3 71.6 12711 15630 215 -2919 -2.06R 50 81.9 21552 17485 447 4067 2.99R R denotes an observation with a large standardized residual. His only comment is that a 1% increase in the percent of males that are college graduates results is associated with about a $180 increase in male income and that there is evidence here that the relationship is significant. He then describes three dummy variables: NE = 1 if the state is in the Northeast (Maine through Pennsylvania in his listing); MW = 1 if the state is in the Midwest (Ohio through Kansas) and SO = 1 if the state is in the South (Delaware through Texas). If all of the dummy variables are zero, the state is in the West (Montana through Hawaii). I ran the regression with all six independent variables. To check these variables, look at his data. MTB > regress c2 6 c3-c8; SUBC> VIF; SUBC> brief 2. 23 252y0581 1/4/06 Regression Analysis: MIM versus PMHS, PURBAN, MAGE, NE, MW, SO The regression equation is MIM = - 1294 + 198 PMHS + 49.4 PURBAN - 42 MAGE + 247 NE + 757 MW + 1269 SO Predictor Constant PMHS PURBAN MAGE NE MW SO Coef -1294 198.13 49.36 -42.1 246.6 756.7 1268.9 S = 1271.71 SE Coef 5394 53.97 14.27 151.6 723.7 608.2 863.0 R-Sq = 57.7% T -0.24 3.67 3.46 -0.28 0.34 1.24 1.47 DF 1 1 1 1 1 1 VIF 3.8 1.4 1.5 2.4 2.1 5.2 R-Sq(adj) = 51.9% Analysis of Variance Source DF SS Regression 6 96890414 Residual Error 44 71158768 Total 50 168049183 Source PMHS PURBAN MAGE NE MW SO P 0.811 0.001 0.001 0.783 0.735 0.220 0.149 MS 16148402 1617245 F 9.99 P 0.000 Seq SS 67720854 23781889 281110 1416569 193443 3496549 Unusual Observations Obs PMHS MIM Fit SE Fit Residual St Resid 50 81.9 21552 16999 543 4553 3.96R R denotes an observation with a large standardized residual. He has asked whether region affects the independent variable, on the strength of the significance tests in the output above, he concludes that the regional variables do not have any affect on male income. (Median Age looks pretty bad too.) There are two ways to confirm these conclusions. Caniglia does one of these, an F test that shows whether the regional variables as a group have any effect. He says that they do not. Another way to test this is by using a stepwise regression. MTB > stepwise c2 c3-c8 Stepwise Regression: MIM versus PMHS, PURBAN, MAGE, NE, MW, SO Alpha-to-Enter: 0.15 Alpha-to-Remove: 0.15 Response is MIM on 6 predictors, with N = 51 Step Constant 1 2736 2 2528 PMHS T-Value P-Value 180 5.75 0.000 134 4.46 0.000 PURBAN T-Value P-Value S R-Sq R-Sq(adj) Mallows C-p 50 3.86 0.000 1431 40.30 39.08 15.0 1263 54.45 52.55 2.3 More? (Yes, No, Subcommand, or Help) SUBC> y No variables entered or removed More? (Yes, No, Subcommand, or Help) SUBC> n What happens is that the computer picks PMHS as the most valuable independent variable, and gets the same result that appeared in the simple regression above. It then adds PURBAN and gets 24 252y0581 1/4/06 The coefficients of the 2 independent variables are significant, the adjusted R-Sq is higher than the adjusted R-sq with all 6 predictors and the computer refuses to add any more independent variables. So it looks like we have found our ‘best’ regression. (See the text for interpretation VIFs and C-p’s.) So here is your job. Update this work. Use any income per person variable, a mean or a median for men, women or everybody. Find measures of urbanization or median age. Fix the categorization of states if you don’t like it. Regress state incomes against the revised data. Remove the variables with insignificant coefficients. If you can think of new variables add them. (Last year I suggested trying percent of output or labor force in manufacturing.) Make sure that you pick variables that can be compared state to state. Though you can legitimately ask whether size of a state affects per capita income, using total amount produced in manufacturing is poor because it’s just going to be big for big states. Similarly the fraction of the workforce with a certain education level is far better then the number. For instructions on how to do a regression, try the material in Doing a Regression. For data sources, try the sites mentioned in 252Datalinks. Use F tests for adding the regional variables and use stepwise regression. Don’t give me anything you don’t understand. MIM = 2528 + 134 PMHS + 50 PURBAN. Problem 2: Recently the Heritage Foundation produced the graph below. What I want to know is if you can develop an equation relating per capita income (the dependent variable) and Economic freedom x . Because it is pretty obvious that a straight line won’t work, you will probably need to create a x 2 variable too. But I would like to know what parts of ‘economic freedom’ affect per capita income. In addition to the Heritage Foundation Sources, the CIFP site mentioned in 252datalinks, and the CIA Factbook might provide some interesting independent variables. You should probably use a sample of no more than 50 countries and it’s up to you what variables to use. You are, of course, looking for significant coefficients and high R-squares. For instructions on how to do a regression, try the material in Doing a Regression. 25 252y0581 1/4/06 B. Do only Problem 1 or problem 2. (Problem Due to Donald R Byrkit). Four different job candidates are interviewed by seven executives. These are rated for 7 traits on a scale of 1-10 and the scores are added together to create a total score for each candidate-rater pair that is between 0 and 70. The results appear below. Row 1 2 3 4 5 6 7 Sum Sum Sum Sum Sum Sum Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce of of of of of of Lee 52 38 54 43 58 36 52 Candidates Jacobs 25 31 38 30 44 28 41 Wilkes 29 24 40 31 46 22 37 Delap 33 29 39 28 47 25 45 Jacobs = 237 squares (uncorrected) of Jacobs = 8331 Wilkes = 229 squares (uncorrected) of Wilkes = 7947 Delap = 246 squares (uncorrected) of Delap = 9094 Personalize the data by adding the second to last digit of your student number to Lee’s column. For example Roland Dough’s student number is 123689, so he uses 52 + 8 = 60, 38 + 8 = 46, 62 etc. If the second to last digit of your student number is zero, add 10. Problem 1: a) Assume that a Normal distribution applies and use a statistical procedure to compare the column means, treating each column as an independent random sample. If you conclude that there is a difference between the column means, use an individual confidence interval to see if there is a significant difference between the best and second-best candidate. If you conclude that there is no difference between the means, use an individual confidence interval to see if there is a significant difference between the best and worst candidate. (6) b) Now assume that a Normal distribution does not apply but that the columns are still independent random samples and use an appropriate procedure to compare the column medians. (4) [16] Problem 2: a) Assume that a Normal distribution applies and use a statistical procedure to compare the column means, taking note of the fact that each row represents one executive. If you conclude that there is a difference between the column means, use an individual confidence interval to see if there is a significant difference between the best and second-best candidate. If you conclude that there is no difference between the column means, use an individual confidence interval to see if there is a significant difference between the kindest and least kind executive. (8) b) Now assume that a Normal distribution does not apply but that each row represents the opinion of one rater and use an appropriate procedure to compare the column medians. (4) c) Use Kendall’s coefficient of concordance to show how the raters differ and do a significance test. (3) Problem 3: (Extra Credit) Decide between the methods used in Problem a and Problem b. To do this, test for equal variances and for Normality on the computer. What is your decision? Why? (4) You can do most of this with the following commands in Minitab if you put your data in 3 columns of Minitab with A, B, C and D above them. MTB > MTB > SUBC> SUBC> MTB > MTB > AOVOneway A B C D stack A B C D C11; subscripts C12; UseNames. rank C11 C13 vartest C11 C12 MTB > Unstack (c13); SUBC> Subscripts c12; SUBC> After; SUBC> VarNames. MTB > NormTest ‘A’; SUBC> KSTest. #Does a 1-way ANOVA # Stacks the data in c12, col.no. in c12. #Puts the ranks of the stacked data in c13 #Does a bunch of tests, including Levene’s On stacked data in c11 with IDs in c12. #Unstacks the ranks in the next available # columns. Uses IDs in c12. #Does a test (apparently Lilliefors) for Normality # on column A. 26 252y0581 1/4/06 Original Version Row 1 2 3 4 5 6 7 Sum Sum Sum Sum Sum Sum Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce of of of of of of Lee 52 38 54 43 58 36 52 Jacobs 25 31 38 30 44 28 41 Wilkes 29 24 40 31 46 22 37 Delap 33 29 39 28 47 25 45 Jacobs = 237 squares (uncorrected) of Jacobs = 8331 Wilkes = 229 squares (uncorrected) of Wilkes = 7947 Delap = 246 squares (uncorrected) of Delap = 9094 Personalize the data by adding the second to last digit of your student number to Lee’s column. For example Roland Dough’s student number is 123689, so he uses 52 + 8 = 60, 38 + 8 = 46, 62 etc. If the second to last digit of your student number is zero, add 10. Row Raters Lee Jacobs Wilkes Delap sum cnt mean sq mnsq 1 Moore 52 25 29 33 139 4 34.75 5259 1207.56 2 Gaston 38 31 24 29 122 4 30.50 3822 930.25 3 Heinrich 54 38 40 39 171 4 42.75 7481 1827.56 4 Seldon 43 30 31 28 132 4 33.00 4494 1089.00 5 Greasy 58 44 46 47 195 4 48.75 9625 2376.56 6 Waters 36 28 22 25 111 4 27.75 3189 770.06 7 Pierce 52 41 37 45 175 4 43.75 7779 1914.06 sum 333 237 229 246 1045 28 41649 10115.06 count 7 7 7 7 28 mean 47.571 33.857 32.714 35.143 Grand mean = 1045/28 = 37.321 ssq 16277 8331 7947 9094 41649 meansq 2263.00 1146.30 1070.21 1235.03 5714.54 From the above x x 1045 , n 28 , x x 1045 37.321 . n x SSC n SST 28 Note 2837 .321 39000 .00 2 2 ij 41649 , 2 ij x 2 i. 10115 .06 x 2 .j 5714 .54 and n x 41649 2837 .321 2 2649 .00 . 2 2 j x j n x 75714 .54 2837 .321 2 2 40001 .78 39000 .00 1001 .78 . This is SSB in a one way ANOVA. SSR n x 2 i i. n x 410115 .06 2837 .321 2 40460 .24 39000 .00 1460 .24 2 Problem 1: a) Assume that a Normal distribution applies and use a statistical procedure to compare the column means, treating each column as an independent random sample. If you conclude that there is a difference between the column means, use an individual confidence interval to see if there is a significant difference between the best and second-best candidate. If you conclude that there is no difference between the means, use an individual confidence interval to see if there is a significant difference between the best and worst candidate. (6) Solution: SSW SST SSB 2649 .99 1001 .78 1648 .21 Source SS DF Between 1001.78 3 Within Total 1648.21 2649.99 24 27 MS 333.93 F 4.86S F .05 3, 24 = 3.01 F.05 H0 Column means Equal 68.675 The ‘S’ next to the calculated F indicates that since it is larger than the table F we reject the null hypothesis. 27 252y0581 1/4/06 The outline gives a formula for an individual contrast 1 2 x1 x2 t n m s 2 1 1 , where n1 n 2 s MSW . 1 4 x1 x4 t 24 MSW 2 1 1 1 1 47 .571 35 .143 2.064 68 .675 7 7 n1 n 4 2 12 .398 2.064 68 .675 12.398 2.064 4.4296 12.4 9.1 . Since the error part is less than the 7 difference between the two sample means, the difference is significant. b) Now assume that a Normal distribution does not apply but that the columns are still independent random samples and use an appropriate procedure to compare the column medians. (4) Solution: H 0 : Equal medians While doing Problem 3, I ranked the data. Since there are 28 numbers, the ranks must extend from 1 to 28. Any ties must be given the average rank. Data Display – This is the ranked data for Kruskal – Wallis. Row C13_Lee 1 25.5 2 15.5 3 27.0 4 20.0 5 28.0 6 13.0 7 25.5 Sum 154.5 C13_Jacobs 3.5 10.5 15.5 9.0 21.0 5.5 19.0 84.0 C13_Wilkes 7.5 2.0 18.0 10.5 23.0 1.0 14.0 76.0 C13_Delap 12.0 7.5 17.0 5.5 24.0 3.5 22.0 91.5 To check our work, the sum of these 4 column sums is 406. The sum of the numbers from 1 to 28 is 2829 406 so we are unlikely to have made a mistake. As always happens, a fairly large group of 2 people lost a fair amount of credit by changing the 12 in the formula below to 28. As I pointed out in class, this is completely unreasonable. If Kruskal and Wallis had wanted the 12 changed to n , they 1 would have written the formula as n 1 i SRi 2 ni 12 Now, compute the Kruskal-Wallis statistic H nn 1 12 154 .5 2 84 2 76 2 91 .5 2 4 4 4 28 29 4 3n 1 . i SRi 2 ni 3n 1 329 12 45074 .5 329 4 2829 12 45074 .5 87 166 .5314 87 79 .5314 . Our Kruskal-Wallis table has no values for tests 4 2829 with four columns, so we compare this with 2 we reject the null hypothesis. 3 .05 7.8147 and, since our computed chi-square is larger, Problem 2: a) Assume that a Normal distribution applies and use a statistical procedure to compare the column means, taking note of the fact that each row represents one executive. If you conclude that there is a difference between the column means, use an individual confidence interval to see if there is a significant difference between the best and second-best candidate. If you conclude that there is no difference between the column means, use an individual confidence interval to see if there is a significant difference between the kindest and least kind executive. (8) 28 252y0581 1/4/06 b) Now assume that a Normal distribution does not apply but that each row represents the opinion of one rater and use an appropriate procedure to compare the column medians. (4) c) Use Kendall’s coefficient of concordance to show how the raters differ and do a significance test. (3) Solution: We already have SST Note 2837 .3212 39000 .00 x n x 41649 2837.321 2649 .00 . SSC n x n x 75714 .54 2837 .321 2 2 ij 2 2 j j 2 2 40001 .78 3900 .00 1001 .78 . This is SSB in a one way ANOVA. SSR n x 2 i i. n x 410115 .06 2837 .321 2 40460 .24 39000 .00 1460 .24 2 SSW SST SSR SSC 2649 .99 1460 .24 1001 .78 187 .97 Source SS DF MS F F .05 H0 Rows 1460.24 6 243.37 23.30S 6,18 2.66 F.05 Column means Equal Columns 1001.78 3 333.93 31.98S 3,18 3.16 F.05 Column means Equal Within Total 187.97 2649.99 18 27 10.443 Since both our computed Fs exceed our table Fs, it looks like there is a difference between both row and column means. An individual confidence interval has the formula for column means 2MSW . Where the outline says to set m 1 and that if P 1 , 1 2 x1 x2 t RC P 1 2m PR replace RC P 1 with R 1C 1 . The formula becomes 2MSW 18 210 .443 47 .571 35 .143 t .025 7 PR 12.398 2.1011.727 12.4 3.6 Since the error part is less than the difference between the two sample means, the difference is significant. 1 4 x1 x4 t R1C 1 2 b) Now assume that a Normal distribution does not apply but that each row represents the opinion of one rater and use an appropriate procedure to compare the column medians. (4) Solution: This is unambiguously cross classified data, so we must use a Friedman test here. The original data is shown with ranks in row. I ranked top down, but bottom up should give the same results. Row 1 2 3 4 5 6 7 Sum Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce Lee r1 52 1 38 1 54 1 43 1 58 1 36 1 52 1 7 Jacobs r2 25 4 31 2 38 4 30 3 44 4 28 2 41 3 22 Wilkes r3 Delap r4 29 3 33 2 24 4 29 3 40 2 39 3 31 2 28 4 46 3 47 2 22 4 25 3 37 4 45 2 22 19 To check our work, the sum of these 4 column sums is 70. The sum of the numbers from 1 to 4 in each row 45 10 . Since there are 7 rows, multiply 10 by 7 to get 70 as the value for the column sums, so we are is 2 unlikely to have made a mistake. Note that the 12 in this formula is a 12, not something that you might find more convenient. 12 12 12 1378 105 7 2 22 2 22 2 19 2 37 5 F2 SRi2 3r c 1 140 745 rc c 1 i 29 252y0581 1/4/06 118 .1143 105 13.1143 Our Friedman table has no values for tests with four columns and 7 rows, so we compare this with 2 hypothesis. 3 .05 7.8147 and, since our computed chi-square is larger, we reject the null c) Use Kendall’s coefficient of concordance to show how the raters differ and do a significance test. (3) The outline says to take k columns with n items in each and rank each column from 1 to n . Then compute a sum of ranks SRi for each row. The null hypothesis is that the rankings disagree. I have ranked bottom to top. Row 1 2 3 4 5 6 7 Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce Lee 52 38 54 43 58 36 52 r1 4.5 2.0 6.0 3.0 7.0 1.0 4.5 Jacobs 25 31 38 30 44 28 41 r2 1 4 5 3 7 2 6 Wilkes r3 29 3 24 2 40 6 31 4 46 7 22 1 37 5 Delap 33 29 39 28 47 25 45 r4 4 3 5 2 7 1 6 SRi SRi 2 12.5 11.0 22.0 12.0 28.0 5.0 21.5 156.25 121.00 484.00 144.00 784.00 25.00 462.25 We can see that the sum of SRi = 112 and the sum of SRi 2 = 2176.5. The average of the SRi column is SR S n 1k 84 16. Then 112 16 . This serves as a check, since the outline says SR 7 2 2 SR 2 n SR 2 2176 .5 716 2 384 .5 . The 5% critical value for Kendall’s S is, according to Table 12, 217.0. Since our computed S is above the table value, reject the null hypothesis. We can also compute the Kendall Coefficient of Concordance (which must be must be between 0 and 1) S 384 .5 384 .5 W 0.8583 . 2 3 2 3 1 k n n 1 4 7 7 448 12 12 Note: To find your numbers for Lee note that Lee’s column x 1 c 333 7c and x x .1 1 333 and x 2 1 16277 If we add the quantity c to c2 16277 2c(333) 7c 2 . 30 252y0581 1/4/06 Problem 3: Computer output is annotated. ————— 12/13/2005 6:03:40 PM ———————————————————— Welcome to Minitab, press F1 for help. Results for: 252x05081-100.MTW MTB > WSave "C:\Documents and Settings\rbove\My Documents\Minitab\252x05081100.MTW"; SUBC> Replace. Saving file as: 'C:\Documents and Settings\rbove\My Documents\Minitab\252x05081-100.MTW' MTB > let c20 = c2+c3+c4+c5 MTB > let c22 = c20/c21 MTB > let c23 = c2*c2+c3*c3+c4*c4+c5*c5 MTB > let c24 = c22*c22 MTB > AOVOneway c2 c3 c4 c5 One-way ANOVA: Lee, Jacobs, Wilkes, Delap Source Factor Error Total DF 3 24 27 S = 8.284 Level Lee Jacobs Wilkes Delap N 7 7 7 7 SS 1001.3 1646.9 2648.1 MS 333.8 68.6 F 4.86 R-Sq = 37.81% Mean 47.571 33.857 32.714 35.143 StDev 8.522 7.151 8.712 8.649 P 0.009 R-Sq(adj) = 30.04% Individual 95% CIs For Mean Based on Pooled StDev --+---------+---------+---------+------(--------*--------) (--------*---------) (--------*--------) (--------*--------) --+---------+---------+---------+------28.0 35.0 42.0 49.0 Pooled StDev = 8.284 MTB > MTB > SUBC> SUBC> MTB > MTB > stack c2 c3 c4 c5 c11 stack c2 c3 c4 c5 c11; subscripts c12; useNames. rank c11 c13 vartest c11 c12 Test for Equal Variances: C11 versus C12 95% Bonferroni confidence intervals for standard deviations C12 N Lower StDev Upper Delap 7 4.99463 8.64925 24.7451 Jacobs 7 4.12969 7.15142 20.4599 Lee 7 4.92097 8.52168 24.3801 Wilkes 7 5.03106 8.71233 24.9256 Bartlett's Test (normal distribution) Test statistic = 0.28, p-value = 0.964 Levene's Test (any continuous distribution) Test statistic = 0.08, p-value = 0.968 31 252y0581 1/4/06 Test for Equal Variances: C11 versus C12 – The high p-value for Bartlett’s test means that we cannot reject the null hypothesis of equal variances at any reasonable significance level. MTB > SUBC> SUBC> SUBC> MTB > SUBC> unstack c13; subscripts c12; after; varNames. NormTest c2; KSTest. Probability Plot of Lee – The high p-value for the KS (actually Lilliefors) test means that we cannot reject the null hypothesis of Normality. This is probably because the sample is so small since the plot hints at deviations from Normality. Between these two, we find justification in using part a rather than part b of Problems 1 and 2. MTB > print c1 c2 c3 c4 c5 c20 c21 c22 c23 c24 Data Display – The material on the right is the setup for comparing rows in 2-way ANOVA Row 1 2 3 4 5 6 7 Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce Lee 52 38 54 43 58 36 52 Jacobs 25 31 38 30 44 28 41 Wilkes 29 24 40 31 46 22 37 Delap 33 29 39 28 47 25 45 sum 139 122 171 132 195 111 175 cnt 4 4 4 4 4 4 4 mean 34.75 30.50 42.75 33.00 48.75 27.75 43.75 sq 5259 3822 7481 4494 9625 3189 7779 mnsq 1207.56 930.25 1827.56 1089.00 2376.56 770.06 1914.06 MTB > print c25-c28 Data Display – This is the ranked data for Kruskal – Wallis. Row 1 2 3 4 5 6 7 C13_Delap 12.0 7.5 17.0 5.5 24.0 3.5 22.0 C13_Jacobs 3.5 10.5 15.5 9.0 21.0 5.5 19.0 C13_Lee 25.5 15.5 27.0 20.0 28.0 13.0 25.5 C13_Wilkes 7.5 2.0 18.0 10.5 23.0 1.0 14.0 32 252y0581 1/4/06 MTB > print c11 c14 c12 Data Display – This is the input for a 2-way ANOVA. Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 C11 52 38 54 43 58 36 52 25 31 38 30 44 28 41 29 24 40 31 46 22 37 33 29 39 28 47 25 45 C14 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 C12 Lee Lee Lee Lee Lee Lee Lee Jacobs Jacobs Jacobs Jacobs Jacobs Jacobs Jacobs Wilkes Wilkes Wilkes Wilkes Wilkes Wilkes Wilkes Delap Delap Delap Delap Delap Delap Delap MTB > Table c14 c12 Tabulated statistics: C14, C12 Rows: C14 Columns: C12 Delap Jacobs Lee 1 1 2 1 3 1 4 1 5 1 6 1 7 1 All 7 Cell Contents: Wilkes All 1 1 1 1 1 1 1 7 4 4 4 4 4 4 4 28 1 1 1 1 1 1 1 7 1 1 1 1 1 1 1 7 Count MTB > Table c14 c12; SUBC> means c11. Tabulated statistics: C14, C12 – Since there is only one measurement per cell, this shows all data and all means. Rows: C14 Columns: C12 Delap Jacobs Lee 1 33.00 2 29.00 3 39.00 4 28.00 5 47.00 6 25.00 7 45.00 All 35.14 Cell Contents: 25.00 52.00 31.00 38.00 38.00 54.00 30.00 43.00 44.00 58.00 28.00 36.00 41.00 52.00 33.86 47.57 C11 : Mean Wilkes All 29.00 24.00 40.00 31.00 46.00 22.00 37.00 32.71 34.75 30.50 42.75 33.00 48.75 27.75 43.75 37.32 33 252y0581 1/4/06 MTB > Twoway c11 c14 c12; SUBC> Means c14 c12. Two-way ANOVA: C11 versus C14, C12 Source C14 C12 Error Total DF 6 3 18 27 SS 1459.36 1001.25 187.50 2648.11 MS 243.226 333.750 10.417 F 23.35 32.04 P 0.000 0.000 S = 3.227 R-Sq = 92.92% C14 1 2 3 4 5 6 7 Individual 95% CIs For Mean Based on Pooled StDev -----+---------+---------+---------+---(----*---) (----*---) (----*----) (----*----) (----*---) (----*---) (----*---) -----+---------+---------+---------+---28.0 35.0 42.0 49.0 Mean 34.75 30.50 42.75 33.00 48.75 27.75 43.75 C12 Delap Jacobs Lee Wilkes Mean 35.1429 33.8571 47.5714 32.7143 R-Sq(adj) = 89.38% Individual 95% CIs For Mean Based on Pooled StDev +---------+---------+---------+--------(----*----) (----*----) (----*----) (----*-----) +---------+---------+---------+--------30.0 35.0 40.0 45.0 MTB > sum c2 Sum of Lee Sum of Lee = 333 MTB > ssq c2 Sum of Squares of Lee Sum of squares (uncorrected) of Lee = 16277 MTB > sum c20 Sum of sum Sum of sum = 1045 MTB > sum c21 Sum of cnt Sum of cnt = 28 MTB > sum c23 Sum of sq Sum of sq = 41649 MTB > sum c24 Sum of mnsq Sum of mnsq = 10115.1 34 252y0581 1/4/06 Version 10 Row 1 2 3 4 5 6 7 Sum Sum Sum Sum Sum Sum Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce of of of of of of Lee 52 38 54 43 58 36 52 Jacobs 25 31 38 30 44 28 41 Wilkes 29 24 40 31 46 22 37 Delap 33 29 39 28 47 25 45 Jacobs = 237 squares (uncorrected) of Jacobs = 8331 Wilkes = 229 squares (uncorrected) of Wilkes = 7947 Delap = 246 squares (uncorrected) of Delap = 9094 We personalize the data by adding 10 Lee’s column. Row Raters Lee Jacobs Wilkes Delap sum cnt mean sq mnsq 1 Moore 62 25 29 33 149 4 37.25 6399 1387.56 2 Gaston 48 31 24 29 132 4 33.00 4682 1089.00 3 Heinrich 64 38 40 39 181 4 45.25 8661 2047.56 4 Seldon 53 30 31 28 142 4 35.50 5454 1260.25 5 Greasy 68 44 46 47 205 4 51.25 10885 2626.56 6 Waters 46 28 22 25 121 4 30.25 4009 915.06 7 Pierce 62 41 37 45 185 4 46.25 8919 2139.06 sum 403 237 229 246 1115 28 49009 11465.11 count 7 7 7 7 28 mean 57.571 33.857 32.714 35.143 Grand mean = 1045/28 = 39.821 ssq 23637 8331 7947 9094 49009 meansq 3314.42 1146.30 1070.21 1235.03 6765.96 x 1115 , n 28 , x From the above x x 1115 39.821 . n x SSC n SST 28 Note 2839 .821 44399 .94 2 2 ij 2 ij 41649 , x 2 i. 11465 .11 x 2 .j 6765 .96 and n x 49009 2839 .821 2 4609 .06 . 2 2 j x j n x 76765 .96 28 39 .821 2 2 47361 .72 44399 .94 2961 .78 . This is SSB in a one way ANOVA. SSR n x 2 i i. n x 411465 .11 2839 .821 2 45860 .44 44399 .94 1460 .50 2 Problem 1: a) Assume that a Normal distribution applies and use a statistical procedure to compare the column means, treating each column as an independent random sample. If you conclude that there is a difference between the column means, use an individual confidence interval to see if there is a significant difference between the best and second-best candidate. If you conclude that there is no difference between the means, use an individual confidence interval to see if there is a significant difference between the best and worst candidate. (6) Solution: SSW SST SSB 4609 .06 2961 .78 1647 .28 Source SS DF Between 2961.78 3 Within Total 1647.28 4609.06 24 27 MS 987.26 F 14.38S F .05 3, 24 F.05 =3.01 H0 Column means Equal 68.636 The ‘S’ next to the calculated F indicates that since it is larger than the table F we reject the null hypothesis. 35 252y0581 1/4/06 The outline gives a formula for an individual contrast 1 2 x1 x2 t n m s 2 1 1 , where n1 n 2 s MSW . 1 4 x1 x4 t 24 MSW 2 1 1 1 1 57 .571 35 .143 2.064 68 .636 7 7 n1 n 4 2 22 .428 2.064 68 .636 22.428 2.064 4.4284 22.4 9.1 . Since the error part is less than the 7 difference between the two sample means, the difference is significant. b) Now assume that a Normal distribution does not apply but that the columns are still independent random samples and use an appropriate procedure to compare the column medians. (4) Solution: H 0 : Equal medians While doing Problem 3, I ranked the data. Since there are 28 numbers, the ranks must extend from 1 to 28 . Any ties must be given the average rank. Data Display – This is the ranked data for Kruskal – Wallis. Row C13_Lee 1 25.5 2 23.0 3 27.0 4 24.0 5 28.0 6 20.5 7 25.5 Sum 173.5 C13_Jacobs 3.5 10.5 14.0 9.0 18.0 5.5 17.0 77.5 C13_Wilkes 7.5 2.0 16.0 10.5 20.5 1.0 13.0 70.5 C13_Delap 12.0 7.5 15.0 5.5 22.0 3.5 19.0 84.5 To check our work, the sum of these 4 column sums is 406. The sum of the numbers from 1 to 28 is 2829 406 so we are unlikely to have made a mistake. Again, note that the 12 in this formula is, in 2 fact, 12 and not some number that you might find more convenient. 12 SRi 2 3n 1 Now, compute the Kruskal-Wallis statistic H nn 1 i ni 12 173 .5 2 77 .5 2 70 .5 2 84 .5 2 4 4 4 2829 4 12 48219 2829 4 329 12 48219 2829 4 329 87 178 .2599 87 91 .2599 . Our Kruskal-Wallis table has no values for tests with four columns, so we compare this with 2 reject the null hypothesis. 3 .05 7.8147 and, since our computed chi-square is larger, we Problem 2: a) Assume that a Normal distribution applies and use a statistical procedure to compare the column means, taking note of the fact that each row represents one executive. If you conclude that there is a difference between the column means, use an individual confidence interval to see if there is a significant difference between the best and second-best candidate. If you conclude that there is no difference between the column means, use an individual confidence interval to see if there is a significant difference between the kindest and least kind executive. (8) b) Now assume that a Normal distribution does not apply but that each row represents the opinion of one rater and use an appropriate procedure to compare the column medians. (4) c) Use Kendall’s coefficient of concordance to show how the raters differ and do a significance test. (3) Solution: We already have SST x 2 ij n x 49009 2839 .821 2 4609 .06 . 2 36 252y0581 1/4/06 Note 2839 .8212 44399 .94 SSC n 2 j x j n x 76765 .96 28 39 .821 2 2 47361 .72 44399 .94 2961 .78 . This is SSB in a one way ANOVA. SSR n x 2 i i. n x 411465 .11 2839 .821 2 45860 .44 44399 .94 1460 .50 . 2 SSW SST SSR SSC 4609 .06 2961 .78 1460 .50 186 .78 Source SS DF MS F F .05 H0 Rows 1460.50 6 243.42 23.46S 6,18 2.66 F.05 Column means Equal Columns 2961.78 3 987.26 95.14S 3,18 3.16 F.05 Column means Equal Within Total 186.78 4609.06 18 27 10.377 Since both our computed Fs exceed our table Fs, it looks like there is a difference between both row and column means. An individual confidence interval has the formula for column means 2MSW . Where the outline says to set m 1 and that if P 1 , 1 2 x1 x2 t RC P 1 2m PR replace RC P 1 with R 1C 1 . The formula becomes 2MSW 18 210 .377 57 .571 35 .143 t .025 7 PR 22.428 2.1011.722 12.4 3.6 Since the error part is less than the difference between the two sample means, the difference is significant. 1 4 x1 x4 t R1C 1 2 b) Now assume that a Normal distribution does not apply but that each row represents the opinion of one rater and use an appropriate procedure to compare the column medians. (4) Solution: This is unambiguously cross classified data, so we must use a Friedman test here. The original data is shown with ranks in row. I ranked top down, but bottom up should give the same results. Row 1 2 3 4 5 6 7 Sum Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce Lee r1 62 1 48 1 64 1 53 1 68 1 46 1 62 1 7 Jacobs r2 25 4 31 2 38 4 30 3 44 4 28 2 41 3 22 Wilkes r3 Delap r4 29 3 33 2 24 4 29 3 40 2 39 3 31 2 28 4 46 3 47 2 22 4 25 3 37 4 45 2 22 19 To check our work, the sum of these 4 column sums is 70. The sum of the numbers from 1 to 4 in each row 45 10 since there are 7 rows multiply 10 by 7 to get 70 as the value for the column sums, so we are is 2 unlikely to have made a mistake. 12 12 12 1378 105 7 2 22 2 22 2 19 2 37 5 F2 SRi2 3r c 1 140 745 rc c 1 i 118 .1143 105 13.1143 Our Friedman table has no values for tests with four columns and 7 rows, so we compare this with 2 hypothesis. 3 .05 7.8147 and, since our computed chi-square is larger, we reject the null c) Use Kendall’s coefficient of concordance to show how the raters differ and do a significance test. (3) 37 252y0581 1/4/06 The outline says Take k columns with n items in each and rank each column from 1 to n then compute a sum of ranks SRi for each row. The null hypothesis is that the rankings disagree. I have ranked bottom to top. Row 1 2 3 4 5 6 7 Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce Lee 62 48 64 53 68 46 62 r1 4.5 2.0 6.0 3.0 7.0 1.0 4.5 Jacobs 25 31 38 30 44 28 41 r2 1 4 5 3 7 2 6 Wilkes r3 29 3 24 2 40 6 31 4 46 7 22 1 37 5 Delap 33 29 39 28 47 25 45 r4 4 3 5 2 7 1 6 SRi SRi 2 12.5 11.0 22.0 12.0 28.0 5.0 21.5 156.25 121.00 484.00 144.00 784.00 25.00 462.25 We can see that the sum of SRi = 112 and the sum of SRi 2 = 2176.5. The average of the SRi column is SR S n 1k 84 16. Then 112 16 . This serves as a check, since the outline says SR 7 2 2 SR 2 n SR 2 2176 .5 716 2 384 .5 . The 5% critical value for Kendall’s S is, according to Table 12, 217.0. Since our computed S is above the table value, reject the null hypothesis. We can also compute the Kendall Coefficient of Concordance (which must be must be between 0 and 1) S 384 .5 384 .5 W 0.8583 . 1 k 2 n3 n 1 42 73 7 448 12 12 38 252y0581 1/4/06 Problem 3: Computer output is annotated. ————— 12/13/2005 10:43:10 PM ———————————————————— Welcome to Minitab, press F1 for help. Results for: 252x05081-110.MTW MTB > WSave "C:\Documents and Settings\rbove\My Documents\Minitab\252x05081110.MTW"; SUBC> Replace. Saving file as: 'C:\Documents and Settings\rbove\My Documents\Minitab\252x05081-110.MTW' Existing file replaced. MTB > let c20 = c2 + c3+ c4 + c5 MTB > let c22 = c20/c21 MTB > let c23 = c2*c2+c3*c3+c4*c4 + c5*c5 MTB > let c24 = c22 *c22 MTB > AOVOneway c2 c3 c4 c5 One-way ANOVA: Lee, Jacobs, Wilkes, Delap Source Factor Error Total DF 3 24 27 S = 8.284 Level Lee Jacobs Wilkes Delap N 7 7 7 7 SS 2961.3 1646.9 4608.1 MS 987.1 68.6 F 14.38 R-Sq = 64.26% Mean 57.571 33.857 32.714 35.143 StDev 8.522 7.151 8.712 8.649 P 0.000 R-Sq(adj) = 59.79% Individual 95% CIs For Mean Based on Pooled StDev ----+---------+---------+---------+----(------*-----) (------*-----) (------*-----) (-----*------) ----+---------+---------+---------+----30 40 50 60 Pooled StDev = 8.284 MTB > SUBC> SUBC> MTB > MTB > stack c2 c3 c4 c5 c11; subscripts c12; useNames. rank c11 c13 vartest c11 c12 Test for Equal Variances: C11 versus C12 95% Bonferroni confidence intervals for standard deviations C12 Delap Jacobs Lee Wilkes N 7 7 7 7 Lower 4.99463 4.12969 4.92097 5.03106 StDev 8.64925 7.15142 8.52168 8.71233 Upper 24.7451 20.4599 24.3801 24.9256 Bartlett's Test (normal distribution) Test statistic = 0.28, p-value = 0.964 Levene's Test (any continuous distribution) Test statistic = 0.08, p-value = 0.968 39 252y0581 1/4/06 Test for Equal Variances: C11 versus C12 – The high p-value for Bartlett’s test means that we cannot reject the null hypothesis of equal variances at any reasonable significance level. MTB > SUBC> SUBC> SUBC> MTB > SUBC> unstack c13; subscripts c12; after; varNames. NormTest c2; KSTest. Probability Plot of Lee– The high p-value for the KS (actually Lilliefors) test means that we cannot reject the null hypothesis of Normality. This is probably because the sample is so small since the plot hints at deviations from Normality. Note that, because of the results of these two tests, we can use ANOVA in the previous two problems. MTB > print c1 c2 c3 c4 c5 c20 c21 c22 c23 c24 Data Display – The material on the right is the setup for comparing rows in 2-way ANOVA Row 1 2 3 4 5 6 7 Raters Moore Gaston Heinrich Seldon Greasy Waters Pierce Lee 62 48 64 53 68 46 62 Jacobs 25 31 38 30 44 28 41 Wilkes 29 24 40 31 46 22 37 Delap 33 29 39 28 47 25 45 sum 149 132 181 142 205 121 185 cnt 4 4 4 4 4 4 4 mean 37.25 33.00 45.25 35.50 51.25 30.25 46.25 sq 6399 4682 8661 5454 10885 4009 8919 mnsq 1387.56 1089.00 2047.56 1260.25 2626.56 915.06 2139.06 40 252y0581 1/4/06 MTB > print c25-c28 Data Display – This is the ranked data for Kruskal – Wallis. Row C13_Delap C13_Jacobs 1 12.0 3.5 2 7.5 10.5 3 15.0 14.0 4 5.5 9.0 5 22.0 18.0 6 3.5 5.5 7 19.0 17.0 MTB > print c11 c14 c12 C13_Lee 25.5 23.0 27.0 24.0 28.0 20.5 25.5 C13_Wilkes 7.5 2.0 16.0 10.5 20.5 1.0 13.0 Data Display – This is the input for a 2-way ANOVA. Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 C11 62 48 64 53 68 46 62 25 31 38 30 44 28 41 29 24 40 31 46 22 37 33 29 39 28 47 25 45 C14 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 C12 Lee Lee Lee Lee Lee Lee Lee Jacobs Jacobs Jacobs Jacobs Jacobs Jacobs Jacobs Wilkes Wilkes Wilkes Wilkes Wilkes Wilkes Wilkes Delap Delap Delap Delap Delap Delap Delap MTB > table c14 c12 Tabulated statistics: C14, C12 Rows: C14 Columns: C12 Delap Jacobs Lee 1 1 2 1 3 1 4 1 5 1 6 1 7 1 All 7 Cell Contents: 1 1 1 1 1 1 1 7 1 1 1 1 1 1 1 7 Count Wilkes All 1 1 1 1 1 1 1 7 4 4 4 4 4 4 4 28 41 252y0581 1/4/06 MTB > table c14 c12; SUBC> means c11. Tabulated statistics: C14, C12 – Since there is only one measurement per cell, this shows all data and all means. Rows: C14 Columns: C12 Delap Jacobs Lee 1 33.00 25.00 62.00 2 29.00 31.00 48.00 3 39.00 38.00 64.00 4 28.00 30.00 53.00 5 47.00 44.00 68.00 6 25.00 28.00 46.00 7 45.00 41.00 62.00 All 35.14 33.86 57.57 Cell Contents: C11 : Mean MTB > Twoway c11 c14 c12; SUBC> Means c14 c12. Wilkes All 29.00 24.00 40.00 31.00 46.00 22.00 37.00 32.71 37.25 33.00 45.25 35.50 51.25 30.25 46.25 39.82 Two-way ANOVA: C11 versus C14, C12 Source C14 C12 Error Total DF 6 3 18 27 SS 1459.36 2961.25 187.50 4608.11 MS 243.226 987.083 10.417 F 23.35 94.76 P 0.000 0.000 S = 3.227 R-Sq = 95.93% C14 1 2 3 4 5 6 7 Individual 95% CIs For Mean Based on Pooled StDev --+---------+---------+---------+------(----*----) (----*----) (----*---) (----*----) (----*----) (----*----) (----*----) --+---------+---------+---------+------28.0 35.0 42.0 49.0 Mean 37.25 33.00 45.25 35.50 51.25 30.25 46.25 C12 Delap Jacobs Lee Wilkes Mean 35.1429 33.8571 57.5714 32.7143 R-Sq(adj) = 93.90% Individual 95% CIs For Mean Based on Pooled StDev --+---------+---------+---------+------(--*--) (--*---) (--*--) (--*--) --+---------+---------+---------+------32.0 40.0 48.0 56.0 MTB > sum c2 Sum of Lee – These are column sums for one-way and 2-way ANOVA Sum of Lee = 403 MTB > ssq c2 Sum of Squares of Lee Sum of squares (uncorrected) of Lee = 23637 MTB > sum c20 Sum of sum Sum of sum = 1115 MTB > sum c21 42 252y0581 1/4/06 Sum of cnt Sum of cnt = 28 MTB > sum c23 Sum of sq Sum of sq = 49009 MTB > sum c24 Sum of mnsq Sum of mnsq = 11465.1 MTB > sum c25 Sum of C13_Delap Sum of C13_Delap = 84.5 MTB > sum c26 Sum of C13_Jacobs Sum of C13_Jacobs = 77.5 MTB > sum c27 Sum of C13_Lee Sum of C13_Lee = 173.5 MTB > sum c28 Sum of C13_Wilkes Sum of C13_Wilkes = 70.5 MTB MTB MTB MTB MTB > > > > > rank c2 rank c3 rank c4 rank c5 let c36 c32 c33 c34 c35 = c32 + c33 + c34 + c35 MTB > sum c36 Sum of C36 Sum of C36 = 112 MTB > let c37 = c36*c36 MTB > sum c37 Sum of C37 Sum of C37 = 2176.5 MTB > print c32-c37 Data Display – This is the ranked data for Kendall’s Coefficient of concordance Row 1 2 3 4 5 6 7 C32 4.5 2.0 6.0 3.0 7.0 1.0 4.5 C33 1 4 5 3 7 2 6 C34 3 2 6 4 7 1 5 C35 4 3 5 2 7 1 6 C36 12.5 11.0 22.0 12.0 28.0 5.0 21.5 C37 156.25 121.00 484.00 144.00 784.00 25.00 462.25 43 252y0581 1/4/06 MTB > print c27 c26 c28 c25 Data Display Row 1 2 3 4 5 6 7 C13_Lee 25.5 23.0 27.0 24.0 28.0 20.5 25.5 C13_Jacobs 3.5 10.5 14.0 9.0 18.0 5.5 17.0 C13_Wilkes 7.5 2.0 16.0 10.5 20.5 1.0 13.0 C13_Delap 12.0 7.5 15.0 5.5 22.0 3.5 19.0 MTB > 44 252y0581 1/4/06 C. You may do both problems. These are intended to be done by hand. A table version of the data for problem 2 is provided in 2005data1 which can be downloaded to Minitab. I do not want Minitab results for these data except for Problem 2e. Problem 1: Using data from the 1970s and 1980s, Alan S. Caniglia calculated a regression of nonresidential investment on the change in level of final sales to verify the accelerator model of investment. This theory says that because capital stock must be approximately proportional to production, investment will be driven by changes in output. In order to check his work I put together a data set 2005series. The last two years of the series are in Exhibit C1 below. Exhibit C1 Row Date 73 1988 01 74 1988 02 75 1988 03 76 1988 04 77 1989 01 78 1989 02 79 1989 03 80 1989 04 RPFI 862.406 879.330 882.704 891.502 900.401 901.643 917.375 902.298 Sales 6637.22 6716.38 6749.47 6835.07 6873.33 6933.55 7015.34 7026.76 Sales-4Q 6344.41 6431.37 6510.82 6542.55 6637.22 6716.38 6749.47 6835.07 Change 292.815 285.006 238.644 292.522 236.106 217.171 265.876 191.695 DEFL %Y 2.897 3.318 3.699 3.724 4.013 4.016 3.596 3.537 MINT % 9.88 9.67 9.96 9.51 9.62 9.79 8.93 8.92 RINT 6.983 6.352 6.261 5.786 5.607 5.774 5.334 5.383 ‘Date’ consists of the year and the quarter. ‘RPFI’ consists of real fixed private investment from 2005InvestSeries1. ‘Sales’ consists of sales data (actually a version of gross domestic product) from 2005SalesSeries1. ‘Sales-4Q’ (Sales 4 Quarters earlier’ is also sales data from 2005SalesSeries1, but is the data of one year earlier. (Note that the 1989 numbers in ‘Sales-4Q’ are identical to the 1988 numbers in ‘Sales.’ ‘Change’ is ‘Sales’ – ‘Sales-4Q. ‘DEFL %Y’ is the percent change in the gross domestic deflator over the last year (a measure of inflation) taken from 2005deflSeries1. ‘MINT %’ is an estimate of the percent return on Aaa bonds taken from 2005intSeries1. Only the values for January, April, July and October are used since quarterly data was not available. ‘RINT’ (an estimate of the real interest rate) is ‘MINT %’ - ‘DEFL %Y’. These are manipulated in the input to the regression program as in Exhibit C2 below. Exhibit C2 Row Time 73 1988 01 74 1988 02 75 1988 03 76 1988 04 77 1989 01 78 1989 02 79 1989 03 80 1989 04 Y 86.2406 87.9330 88.2704 89.1502 90.0401 90.1643 91.7375 90.2298 X1 29.2815 28.5006 23.8644 29.2522 23.6106 21.7171 26.5876 19.1695 X2 6.98 6.35 6.26 5.79 5.61 5.77 5.33 5.38 Here Y is ‘RFPI’ divided by 10. X1 is ‘Change’ divided by 10. X2 is ‘RINT’ rounded to eliminate the last decimal place. If you don’t understand how I got Exhibit C2 from Exhibit C1 find out before you go any further, Personalize the data by adding one year (four values) to the data in 2005 series. Pick the year to be added by adding the last digit of your student number to 1990. Make sure that I know the year you are using. Then get, for your year, ‘RPFI’ from 2005InvestSeries1, ‘Sales’ from 2005SalesSeries1, ‘Sales-4Q’ from 2005SalesSeries1 (Make sure that you use the sales of one year earlier, not 1989 unless your year is 1990.), ‘DEFL %Y’ 2005deflSeries1 and ‘MINT %’ from 2005intSeries1. Calculate ‘Change’ by subtracting ‘Sales-4Q’ from ‘Sales.’ If you are going to do Problem 2, calculate ‘RINT’ by subtracting ‘DEFL %Y’ from ‘MINT %.’ Present your four rows of new values in the format of Exhibit C1. Now manipulate your numbers to the form in Exhibit C2 and again present your four rows of numbers. These are observations 81 through 84. Now it’s time to compute your spare parts. The following are computed for you from the data for 1970 through 1989. 45 252y0581 1/4/06 Sum of Y = 5323.20 Sum of X1 = 1283.42 Sum of X2 = 328.33 Sum of Ysq = 371032 Sum of X1sq = 30307.57 Sum of X2sq = 2080.65 Sum of X1Y = 92676.9 Sum of X2Y = 24188.2 Sum of X1X2 = 6324.09 Y 5323 .2 X 1 1283.42 X 2 328.33 Y 371032 X 30307 .6 X 2080 .65 X 1 Y 92676.9 X 2 Y 24188.2 X 1 X 2 6324.09 n 80 2 2 1 2 2 Add the results of your data to these sums (You only need the sums involving X1 and Y if you are not doing Problem 2.) (Show your work!) and do the following. a. Compute the regression equation Yˆ b0 b1 x1 to predict investment on the basis of change in sales only. (2) b. Compute R 2 . (2) c. Compute s e . (2) d. Compute s b0 and do a significance test on b0 (1.5) e. Compute s b1 and do a significance test on b1 (2) f. In the first quarter of 2001 sales were 9883.167, the interest rate was 7.15% and the gdp inflation rate was 2.176%. In the first quarter of 2000 sales were 9668.827. Get values of Y and X1 from this and predict the level of investment for 2001. Using this, create a confidence interval or a prediction interval for investment in 2001 as appropriate. (3) g. Do an ANOVA table for the regression. What conclusion can you draw from the hypothesis test in the ANOVA? (2) [30] Problem 2: Continue with the data in problem 1. a. Compute the regression equation Yˆ b0 b1 x1 b2 x 2 to predict investment on the basis of real interest rates and change in sales. Do not attempt to use the value of b1 you got in problem 1. Is the sign of the coefficient what you expected? Why? (5) b. Compute R-squared and R-squared adjusted for degrees of freedom for this regression and compare them with the values for the previous problem. (2) c. Using either R – squares or SST, SSR and SSE do an F tests (ANOVA). First check the usefulness of the multiple regression and show whether the use of real interest rates gives a significant improvement in explanatory power of the regression? (Don’t say a word without referring to a statistical test.) (3) d. Use the values in 1f to compute a prediction for 2001 investment. By what percent does the predicted investment change if you add real interest rates? (2) e. If you are prepared to explain the results of VIF and Durbin-Watson (Check the text!), run the regression of Y on X1 and X2 using MTB > Regress Y 2 X1 X2; SUBC> VIF; SUBC> DW; SUBC> Brief 2. Explain your results. (2) [44] Solution: This is the solution to the original Problem. Your solution should not be very different. You have 84 observations instead of n 80. 46 252y0581 1/4/06 Spare Parts Computation: 5323 .20 Y 66 .5400 80 1283 .42 X1 16 .0428 80 328 .33 X2 4.1041 80 X 2 1 X nX SSX 2 733 .16 Y nY SST SSY 16826 .8 X Y nX Y SX1Y 7277 .87 X Y nX Y SX 2Y 2341 .25 X X nX X SX1X 2 1056 .79 2 2 2 2 2 2 1 1 2 2 1 nX 12 SSX1 9717 .86 2 1 2 Problem 1: a. Compute the regression equation Yˆ b0 b1 x1 to predict investment on the basis of change in sales only. (2) b1 Sxy SSx xy nxy 7277 .87 0.7489 x nx 9717 .86 2 2 b0 y b1 x 66.54 0.7489 16.0428 54.526 , So Yˆ b0 b1 x becomes Yˆ 54.526 0.7489 x . b. Compute R 2 . (2) SSR b1 Sxy b1 R2 xy nxy 0.7489 7277 .87 5450 .4 SSR 5450 .4 .3239 or SST 16826 .8 XY nXY Sxy 7277 .87 X nX Y nY SSxSSy 9717 .86 16826 .8 .3239 2 R 2 2 2 2 2 2 2 c. Compute s e . (2) SSE SST SSR 16826 .8 5450 .4 11376 .4 or SSR R 2 SST and SSE 1 R 2 SST should give you the same result. ( s e2 is always positive!) SSE 11376 .4 s e2 145 .851 So s e 145 .851 12 .0768 n2 78 d. Compute s b0 and do a significance test on b0 (1.5) H 0 : 0 0 Recall n 80, .05 , X 2 1 nX 12 SSX1 9717 .86 , s e2 145.851, X 1 16 .0428 and b0 y b1 x 54.526 . t.78 025 1.991 1 s b20 s e2 n 2 145 .851 1 16 .0428 145 .8510.01250 0.02648 5.6853 9717 .86 X 2 nX 2 80 X2 s b0 5.6853 2.3844 So t b0 00 54 .526 0 22 .868 . Since this is larger than 1.991 in s b0 2.3844 absolute value, we reject the null hypothesis. e. Compute s b1 and do a significance test on b1 (2) H 0 : 1 0 Recall n 80, .05 , X 2 1 nX 12 SSX1 9717 .86 , s e2 145.851, X 1 16 .0428 and 145 .851 2 2 1 0.1501 s b 0.1501 0.1225 b1 0.7489 . t.78 025 1.991 s b1 s e 1 SS x 9717 .86 . 47 252y0581 1/4/06 So t b1 10 0.7489 0 6.113 . Our rejection zone is below -1.991 and above 1.991. Since s b1 0.1225 our calculated t falls in the upper reject zone, we can say that b1 is significant. f. In the first quarter of 2001 sales were 9883.167, the interest rate was 7.15% and the gdp inflation rate was 2.176%. In the first quarter of 2000 sales were 9668.827. Get values of Y and X1 from this and predict the level of investment for 2001. Using this, create a confidence interval or a prediction interval for investment in 2001 as appropriate. (3) Recall that our equation is Yˆ 54.526 0.7489 x . X 0 9883 .167 9668 .827 217 .34 , n 80, .05 , X 2 1 nX 12 SSX1 9717 .86 , s e2 145.851 and X 1 16 .0428 . The Prediction Interval is Y0 Yˆ0 t sY , where Yˆ 54.526 0.7489 x 54.526 0.7489 217 .34 217 .291 sY2 1 s e2 n 2 1 217 .34 16 .04 2 X0 X 1 145 .851 1 80 SS x 9717 .86 145 .8511.01250 4.169816 755 .8460 . sY 755 .8460 27 .4926 . So Y0 Yˆ0 t sY 217 .291 1.99127.4926 217 55 . g. Do an ANOVA table for the regression. What conclusion can you draw from the hypothesis test in the ANOVA? (2) The general format for a regression ANOVA table reads: Source SS DF MS Fcalc F k Regression SSR MSR MSR MSE F k , nk 1 Error SSE n k 1 MSE Total SST n 1 SSE SST SSR 16826 .8 5450 .4 11376 .4 . n 80 and the number of independent variables is k 1 . The ANOVA table for the regression reads: Source SS DF MS Fcalc F.05 1,78 3.96 F.05 Regression 5450.5 1 5450.5 37.37s Error 11376.6 78 145.85 Total 16826.8 79 Since our computed F is larger than the table F, we conclude that there is a linear relationship between the dependent and independent variable. In a simple regression this is the same as saying that the slope is significant. Problem 2: Continue with the data in problem 1. a. Compute the regression equation Yˆ b0 b1 x1 b2 x 2 to predict investment on the basis of real interest rates and change in sales. Do not attempt to use the value of b1 you got in problem 1. Is the sign of the coefficient what you expected? Why? (5) Recall the values of the Spare Parts computed above. We substitute these numbers into the Simplified Normal Equations: X 1Y nX 1Y b1 X 12 nX 12 b2 X 1 X 2 nX 1 X 2 X Y nX Y b X X 2 2 1 1 2 nX X b X 1 2 2 2 2 nX 2 2 Actually these can be considered the 2nd and 3rd equations, the first one being Y b0 b1 X 1 b2 X 2 . 48 252y0581 1/4/06 The 2nd and 3rd Normal equations are 7277 .87 9717 .86 b1 2341 .25 1056 .79 b1 1056 .79 1.44142 , multiply Equation (3) by 1.44142. 733 .16 7277 .87 3374 .72 Now, subtract Equation 3' from Equation (2) So b1 get 1056 .79 b2 733 .16 b2 9717 .86 b1 1523 .28b1 3903 .15 8194 .58b1 2 . Since 3 1056 .79 b2 1056 .79 b2 2 3' 0b2 3903 .15 0.4763 . Now, substitute 0.4763 into either Equation (2) or Equation (3). We 8194 .58 7277 .87 9717 .860.4763 1056 .79b2 2" or 2341 .25 1056 .790.4763 733 .16b2 3" Using 2" , we get 1056 .79b2 7277 .87 4628 .62 . So b2 2649 .65 2.5069 1056 .79 1837 .90 2.5068 . The difference is or, using 3" , we get 733 .16b2 2341 .25 503 .35 . So b2 733 .16 due to rounding. Finally, since Y b0 b1 X 1 b2 X 2 , we can write b0 Y b1 X 1 b2 X 2 66.5400 0.4763 16.0428 2.5068 4.1041 66.5400 7.6412 10.2882 48.6106 . Our equation is thus Yˆ 48.611 0.476X 2.507X . The results are questionable. We expect to get 1 2 a positive coefficient for increase in sales as the accelerator theory predicts. The positive coefficient of interest rates looks wrong, rising interest rates should depress investment. It’s possible that we are seeing something else. Could it be that the same forces that posh up investment, also push up interest rates? b. Compute R-squared and R-squared adjusted for degrees of freedom for this regression and compare them with the values for the previous problem. (2) X 1Y nX 1Y SX 1Y 7277 .87 and X 2 Y nX 2 Y SX 2Y 2341 .25 2 2 Y nY SST SSY 16826 .8 SSE SST SSR * . Thus SSR b1 Sx1 y b2 Sx2 y 0.4763 7277 .87 2.507 2341 .25 3466 .449 5869 .514 9336 .0 * so SSE 16826 .8 9336 .0 7490 .8 * In the first regression, we had R 2 RY21 .3239 SSR 9336 .0 .5548 *. If we use R 2 , which is R 2 SST 16826 .8 adjusted for degrees of freedom, for the first regression, the number of independent variables was n 1R 2 k 79 0.3239 1 .3152 and for the second regression k 2 and k 1 and R 2 n k 1 78 In this regression, we have R 2 RY212 R2 n 1R 2 k 79 0.5548 2 .5432 . n k 1 77 49 252y0581 1/4/06 c. Using either R – squares or SST, SSR and SSE do an F tests (ANOVA). First check the usefulness of the multiple regression and show whether the use of real interest rates gives a significant improvement in explanatory power of the regression? (Don’t say a word without referring to a statistical test.) (3) The general format for a regression ANOVA table reads: Source SS DF MS Fcalc F k Regression SSR MSR MSR MSE F k , nk 1 Error SSE n k 1 MSE Total SST n 1 SSE SST SSR 16826 .8 5450 .4 11376 .4 . n 80 and the number of independent variables is k 1 . The ANOVA table for the first regression read: Source SS DF Regression Error Total Our new table is Source 5450.5 11376.6 16826.8 1 78 79 SS DF MS Fcalc 5450.5 145.85 37.37s MS Fcalc F.05 1,78 3.96 F.05 F.05 2,77 2.37 F.05 Regression 9336.0 2 4668.0 47.98s Error 7490.8 77 97.283 Total 16826.8 79 Since our computed F is larger that the table F, we reject the hypothesis that the Xs and Y are unrelated. If we now divide the effects of the two independent variables, we get: Source SS DF MS Fcalc F.05 X1 5450.5 1 1,77 3.96 X2 2855.5 1 2855.5 29.35s F.05 Error 27490.8 77 97.283 Total 16826.8 79 Since our computed F is larger that the table F, we reject the hypothesis that X2 and Y are unrelated. d. Use the values in 1f to compute a prediction for 2001 investment. By what percent does the predicted investment change if you add real interest rates? (2) In the first quarter of 2001 sales were 9883.167, the interest rate was 7.15% and the gdp inflation rate was 2.176%. In the first quarter of 2000 sales were 9668.827. Get values of Y and X1 from this and predict the level of investment for 2001. Using this, create a confidence interval or a prediction interval for investment in 2001 as appropriate. (3) Recall that our equation was Yˆ 54.526 0.7489 x . It predicted a value of Yˆ 217 .291 . Now Yˆ 48.611 0.476X 2.507X , X 9883 .167 9668 .827 217 .34 , and 1 2 1 X 2 7.15 2.167 4.98 , so our predicted value of Y is Yˆ 48.611 0.476217.34 2.5074.98 48.611 103.454 12.485 164.550 , a fall of about 24%. e. If you are prepared to explain the results of VIF and Durbin-Watson (Check the text!), run the regression of Y on X1 and X2 using MTB > Regress Y 2 X1 X2; SUBC> VIF; SUBC> DW; SUBC> Brief 2. 50 252y0581 1/4/06 Explain your results. (2) Here are my results. MTB > regress c2 2 c3 c4; SUBC> VIF; SUBC> DW. Regression Analysis: Y versus X1, X2 The regression equation is Y = 48.6 + 0.476 X1 + 2.51 X2 Predictor Constant X1 X2 Coef 48.610 0.4764 2.5067 S = 9.86336 SE Coef 2.161 0.1090 0.3967 R-Sq = 55.5% Analysis of Variance Source DF SS Regression 2 9335.8 Residual Error 77 7491.0 Total 79 16826.8 Source X1 X2 DF 1 1 T 22.50 4.37 6.32 P 0.000 0.000 0.000 VIF 1.2 1.2 R-Sq(adj) = 54.3% MS 4667.9 97.3 F 47.98 P 0.000 Seq SS 5451.3 3884.5 Unusual Observations Obs X1 Y Fit 50 -4.2 63.70 67.00 51 -8.2 61.93 66.44 SE Fit 3.38 3.91 Residual -3.30 -4.52 St Resid -0.36 X -0.50 X X denotes an observation whose X value gives it large influence. Durbin-Watson statistic = 0.0952666 The VIFs are quite small, so there seems to be no problem of collinearity. The Durbin-Watson statistic is awfully low. The table in the text gives for .05 , d L 1.59 and d U 1.69 and .01 , d L 1.44 and dU 1.54. The 2-sided diagram that I gave you is below. 0 0 dL ? dU 0 2 0 4 dU + + + + + ? 4 dL + 0 4 + Since the D-W statistic is on the right extreme of this diagram, the data seems to be showing an incredible level of Autocorrelation. 51 252y0581 1/4/06 Caniglia’s Original Data Data Display Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 STATE ME NH VT MA RI CT NY NJ PA OH IN IL MI WI MN IA MO ND SD NE KS DE MD DC VA WV NC SC GA FL KY TN AL MS AR LA OK TX MT ID WY CO NM AZ UT NV WA OR CA AK HI MIM 12112 14505 12711 15362 13911 17938 15879 17639 15225 16164 15793 17551 17137 15417 15878 15249 14743 13835 12406 14873 15504 16081 17321 15861 15506 13998 12529 12660 13966 14651 13328 13349 13301 11968 12274 15365 14818 16135 14256 14297 17615 16672 14057 15269 15788 16820 17042 15833 17128 21552 15268 PMHS 69.1 73.0 71.6 74.0 65.1 71.8 68.9 70.0 68.0 69.0 68.8 68.9 69.3 70.9 73.5 71.9 66.2 68.0 68.3 74.2 74.5 70.4 69.2 67.9 64.3 58.6 58.2 58.2 60.4 68.0 55.8 59.0 59.9 57.2 58.3 61.3 68.7 65.3 73.8 73.5 77.9 79.1 70.6 73.4 80.4 76.0 77.5 75.1 74.3 81.9 76.9 PURBAN 47.5 52.2 33.8 83.8 87.0 78.8 84.6 89.0 69.3 73.3 64.2 83.3 70.7 64.2 66.9 58.6 68.1 48.8 46.4 62.9 66.7 70.6 80.3 100.0 66.0 36.2 48.0 54.1 62.4 84.3 50.9 60.4 60.0 47.3 51.6 68.6 67.3 79.6 52.9 54.0 62.7 80.6 72.1 83.8 84.4 85.3 73.5 67.9 91.3 64.3 86.5 MAGE 29.2 29.2 28.4 29.6 30.1 30.6 30.3 30.7 30.4 28.6 28.0 28.6 27.8 28.3 28.3 28.7 29.3 27.5 27.9 28.6 28.7 28.7 29.2 29.9 28.6 29.1 28.1 26.7 27.3 32.9 27.8 28.7 27.8 26.1 29.2 26.2 28.6 27.1 28.4 27.0 26.7 27.9 26.6 28.2 23.8 30.0 29.0 29.5 28.9 26.3 27.6 NE 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 MW 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 SO 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 52