252solngr2-08(revised!!!) 2/23/08 R. E. Bove Name:
advertisement
 2/23/08 R. E. Bove Name:")
252solngr2-08(revised!!!) 2/23/08
ECO 252 Second Graded Assignment
R. E. Bove
Name:
Class days and time:
Student Number:
Please include class and student number on what you hand in! Papers should be stapled. Your
writeup should state clearly what you did and concluded. In diagrams of confidence intervals, shade
the interval. In diagrams of test ratios and critical values for a sample statistic, shade the ‘reject zone.
Problem 1: Which of the following could be null hypotheses? Which could be an alternate hypothesis? Which could be neither?
Why? If some of these are valid null hypotheses, state the alternate. If some of these are valid alternative hypotheses, state the null.
H 0 and H 1 clearly. (i) 3 , (ii) 3 , (iii) 3 , (iv) x 3 , (v) p 0.3 , (vi) p 3 , (vii) s 2 3 , (viii)
3 , (ix) 3 (x) 3
Label
Problem 2: A man walks into a bar. He drinks 10 a bottles of beer. These bottles are supposed to contain 12 ounces of beer with
a population standard deviation of 0.4 ounces. On the basis of the man's condition when he leaves the bar, we conclude that the total
amount he drank was 115 13 .5a ounces. Personalize the data by replacing a by the second to last digit of your student number.
If the second to last digit is zero, a 10 . For example, Ima Badrisk has student number 012345, so a 4 and she claims that he
drank 14 bottles of beer and a total of
115 13 .54 169 .0 . She then uses the total amount he drank and the total number of
bottles to compute a sample mean for the bottles.
Test the hypothesis that the population mean for these bottles was 12 ounces. Assume that the confidence level is 95%.
a) State your null and alternative hypotheses.
b) Find critical values for the sample mean and test the hypothesis. Show your ‘reject’ region on a diagram.
c) Find a confidence interval for the sample mean and test the hypothesis. Show your results on a diagram.
d) Use a test ratio for a test of the sample mean. Show your ‘reject’ region on a diagram.
e) Find a p-value for the null hypothesis using your test ratio and the Normal table. Use the p-value to test the null
hypothesis. Will you reject the null hypothesis with a confidence level of 10%, 5%, 1%, .002? No answer will be accepted
without a brief explanation.
Problem 3: Continue with your results from problem 2.
a) Use the test ratio that you found on problem 1 to find an approximate p-value using the t-table and assuming that 0.4
ounces was a sample standard deviation? Does this change any of your results in e)?
b) Assume once again that 0.4 is a population standard deviation. Test the hypothesis that the population mean is 12
ounces. Show your ‘reject region on a diagram. Find a p-value.
Note: b) as written was a typo. It should have read ‘0.4 is a sample standard deviation. This error may appear in c) too. This is what
I get for writing the solution before writing the problem!!!
c) Assume that 0.4 is a i) population ii) sample standard deviation. Test the hypothesis that the population mean
is above 12 ounces using the test ratio that you found in 1d). State your null and alternative hypotheses. Show your ‘reject
region on a diagram.
d) Assume that 0.4 is a population standard deviation. Test the hypothesis that the population mean is above 12 ounces
using a critical value for the sample mean. State your null and alternative hypotheses. Show your ‘reject region on a
diagram.
e) Assume that 0.4 is a population standard deviation. Test the hypothesis that the population mean is above 12 ounces
using a one-sided confidence interval. Shade the confidence interval in your diagram.
Problem 4: (Steinberg) Supposedly at least 36% of college students change their major between freshman year and graduation. You
take a survey of 630 graduating seniors and find that 220 b changed their majors, where b is the last digit of your student
number. For example, Ima Badrisk has student number 12345, so b 5 and she claims that 220 b 220 5
their majors. Test the hypothesis.
a) State your null and alternative hypotheses.
b) Find a test ratio for a test of the proportion.
c) Make a diagram showing the rejection region for the test ratio if you use a 99% confidence level.
d) Find a p-value for this ratio and use it to test the hypothesis at a 1% significance level
225 changed
Extra Credit Problem 5:
a) Assume that the sample size is 20 2 changed majors and you are testing the statement that at least 40% changed
majors. Do the test at the 90% confidence level without using the Normal distribution.
The following data can be used in b) and c).
252solngr2-08(revised!!!) 2/23/08
Make sure that your student number is easily readable. Choose one of the columns below using the second to last digit of your
Student Number. Example: Ima Badrisk has student number 123456; so she picks column x5. Forget about the rest of the columns!
Row
1
2
3
4
5
6
7
8
9
10
11
12
13
x0
x1
x2
x3
x4
x5
x6
x7
x8
x9
2.3
8.8 12.1 5.7 16.0 11.4
3.3 -2.5
6.7
3.0
7.9
2.9
3.6 5.7
3.5 -4.6
3.5
1.6
1.7
5.3
11.5
2.5
1.8 2.8 -1.7
4.7 12.2
2.7
2.0
1.1
2.1
6.5
9.9 2.9
6.8 -2.7 -1.6 -0.8 10.5
6.0
9.1
3.4
9.8 1.2
8.9 -3.6
7.1 -0.3
4.6
8.9
5.8 -3.6
6.8 6.8
4.1 -0.5
4.1
3.0 11.3
7.4
2.7
3.4
3.9 0.3 -2.9 -1.2
0.1
0.3
6.7
1.2
12.0 -1.5
9.9 9.6 15.5 -2.6
7.1 10.6
4.1
0.6
0.6 11.5
8.2 3.8
1.9 13.4 -1.5
4.9
5.2
4.2
-8.7 16.1 14.1 0.7 -0.9
0.5
1.0
3.3
3.7
7.1
4.1
4.6
6.8 9.3
3.0
3.2
6.2 14.8
9.9
5.0
-0.6
1.4 13.9 9.4
2.8
9.1
1.7 17.4
4.9 -2.5
-0.4
4.4
6.7 6.1
4.1
0.8 -2.3
9.5
9.7
8.8
b) Compute a sample standard deviation for your column and test the hypothesis
c) Using the same data, test the hypothesis that the median is below 4.
4
e) Use Minitab to check your answer to problem 4. Do this three ways.
First: Enter Minitab. Use the Editor pull-down menu to enable commands. Then enter the
commands below.
Pone 630 220+b;
(Replace 220+b with the number you used.)
Test 0.36;
Conf 99;
(Sets a 99% confidence level)
Alter -1;
(Makes H1 ‘less than.’)
useZ.
(Uses normal approx. to binomial)
Second: Use the Stat pull-down menu. Choose ‘Basic Stat’ and then ‘1 proportion.’
Check ‘summarized data’ and enter your n for ‘number of trials’ and 220+b for ‘number of events.’ Check ‘perform
hypothesis test.’ Set ‘hypothesized proportion’ as 0.36. Press Options. Set ‘confidence level’ as 99, alternative hypothesis
as ‘less than’ and check ‘Normal distribution.’ Go.
Third: Use the pull-down menu again. But before you start put 220+b yeses and 410+b noes in column 1. (You should
have 630 rows of data. You can do this entry very rapidly if you use only y or 1 for yes and n or 0 for no. Just enter y
220+b times and then n until you get to row 630. Even better, put a zero in the first row and use the fill handle on the
bottom right of the cell to enter 1 an appropriate number of times then put a zero in the rest of the column the same way.)
Uncheck ‘summarized data’ and let Minitab know that the data are in column 1 (C1). Other options are unchanged.
(Fourth: repeat your third try, but uncheck ‘Normal distribution.’)
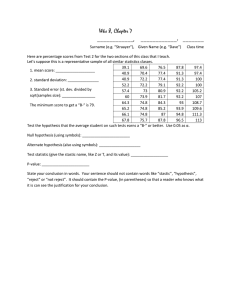
Problem 1 Solution: Remember the following:
α) Only numbers like , p, 2 , and (the population mean, proportion, variance,
standard deviation and median) that are parameters of the population can be in a
hypothesis; x , p, s 2 , s and x.50 (the sample mean, proportion, variance, standard deviation
and median) are statistics computed from sample data and cannot be in a hypothesis because
a hypothesis is a statement about a population;
β) The null hypothesis must contain an equality;
γ) p must be between zero and one;
δ) A variance or standard deviation cannot be negative.
(i) 3 can be H 0 since it contains a parameter and an equality. H 1 would be 3 .
(ii) 3 can be H1 since it contains a parameter and an inequality. H 0 would be 3 .
(iii) 3 can be H 0 since it contains a parameter and an equality. H 1 would be 3 .
(iv) x 3 could not be H 0 or H 1 because x is a sample statistic, not a parameter.
(v) p 0.3 could not be H 0 or H 1 because p is a sample statistic, not a parameter.
(vi) p 3 could not be H 0 or H 1 since it contains an unreasonable value for a parameter. A probability or
proportion must be between zero and one.
(vii) s 2 3 could not be H 0 or H 1 because s is a sample statistic, not a parameter.
(viii) 3 can be H1 since it contains a parameter and an inequality. H 0 would be 3 .
252solngr2-08(revised!!!) 2/23/08
(ix) 3 could not be H 0 or H 1 since it contains an unreasonable value for a parameter. A variance or
standard deviation must be positive.
(x) 3 can be H 0 since it contains a parameter and an equality. H 1 would be 3 .
Learn to make and call it ‘mu.’ It’s not a ‘u’ and you are too young to be unable
to adjust to using a Greek letter!
Problem 2: A man walks into a bar. He drinks 10 a bottles of beer. These bottles are supposed to contain
12 ounces of beer with a population standard deviation of 0.4 ounces. On the basis of the man's condition
when he leaves the bar, we conclude that the total amount he drank was 115 13.5a ounces. Personalize the
data by replacing a by the second to last digit of your student number. If the second to last digit is zero,
a 10 . For example, Ima Badrisk has student number 12345, so a 4 and she claims that he drank 14
bottles of beer and a total of 115 13 .54 169 .0 . She then uses the total amount he drank and the total
number of bottles to compute a sample mean for the bottles.
Test the hypothesis that the population mean for these bottles was 12 ounces. Assume that the confidence
level is 95%.
a) State your null and alternative hypotheses.
Solution: The question asks us to test the hypothesis that the mean is 12 ounces. This is 12 and must be
H 0 : 12
a null hypothesis because it contains an equality. Our hypotheses are
, so 0 12 .
H 1 : 12
b) Find critical values for the sample mean and test the hypothesis. Show your ‘reject’ region on a
diagram.
Solution: The general formula for a critical value for the sample mean when the population standard
deviation is known is x cv 0 z x {Table 3}. Because this is a two-sided hypothesis, we need two
2
critical values.
Computation of the mean
We have been told that
x 115 13.5a . n 10 a . Thus x
that 0.4
Computation of Standard Errors
x
2
. For n 11 this would be x
0.4
x 115 13.5a . We have been told
n
10 a
0.16
0.01454 0.120605 .
11
n
n
11
Finding z
The significance level is given as 95%. 1 .95 , .05 and
2
.025 . From the bottom of the t-table,
we find z z.025 1.960 . {ttable}
2
The following table gives us the values of the sample size, the total amount of beer consumed, the sample
mean and the standard error.
x
x
x
Row n
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
128.5
142.0
155.5
169.0
182.5
196.0
209.5
223.0
236.5
250.0
11.6818
11.8333
11.9615
12.0714
12.1667
12.2500
12.3235
12.3889
12.4474
12.5000
0.12060
0.11547
0.11094
0.10690
0.10328
0.10000
0.09701
0.09428
0.09177
0.08944
252solngr2-08(revised!!!) 2/23/08
For n 11 we have x cv 0 z x 12 1.960 0.12060 12 0.2364 or we can say that the lower
2
and upper critical values are cv L 11.7636 and cvU 12 .2364 . We compare the sample mean of 11.6818.
Since it lies below our two critical values, we can reject the null hypothesis.
For n 20 we have x cv 0 z x 12 1.960 0.08944 12 0.1753 or we can say that the lower
2
and upper critical values are cv L 11.8247 and cvU 12 .1753 . We compare the sample mean of 12.5000.
Since it lies above our two critical values, we can reject the null hypothesis.
Make a diagram. Center a Normal curve at 12. Mark the two critical values cv L and cvU . To represent the
two ‘reject’ regions shade the area above cvU and below cv L . Indicate where your sample mean falls on
the diagram. If your sample mean falls between cv L and cvU , do not reject the null hypothesis. If your
sample mean does not fall between cv L and cvU , reject the null hypothesis. In both cases we can say that
there is a significant difference between our sample mean and 12. This will not be true for all values of n .
c) Find a confidence interval for the sample mean and test the hypothesis. Show your results on a
diagram.
Solution: The general formula for a confidence interval for the population mean when the population
standard deviation is known is x z x {Table 3}. We have essentially reversed the sample and
2
population means in the critical value formula, so we should get exactly the same results.
For n 11 we have x z x 11.6818 1.960 0.12060 11.6818 0.2364 or we can say
2
P11.4454 11.9182 .95 . We compare the hypothesized population mean of 12. Since 12 lies above
our confidence interval, we can reject the null hypothesis.
For n 20 we have x z x 12.5000 1.960 0.08944 12.5000 0.1753 or we can say
2
P12.3247 12 .6753 .95 . We compare the hypothesized population mean of 12. Since 12 lies below
our confidence interval, we can reject the null hypothesis.
Make a diagram. Center a Normal curve at the sample mean. Mark the two limits of the confidence
interval and shade the area between them. Indicate where your hypothesized population mean falls on the
diagram. If your population mean falls within the confidence interval, do not reject the null hypothesis. If
your sample mean does not fall within the confidence interval, reject the null hypothesis.
d) Use a test ratio for a test of the sample mean. Show your ‘reject’ region on a diagram.
Solution: The general formula for a test ratio for the population mean when the population standard
x 0
deviation is known is z
{Table 3}. This is a rearrangement of the terms in critical value formula,
x
so we should get exactly the same results.
x 0 11 .6818 12
2.6385 . We compare this with a 95% interval around
For n 11 we have z
0.12060
x
zero, this interval is between z z.025 1.960 and z z.025 1.960 . Since -2.6385 lies below
2
2
both values of z, we can reject the null hypothesis.
x 0 12 .5000 12
5.5903 . We compare this with a 95% interval around
For n 20 we have z
0.08944
x
zero, this interval is between z z.025 1.960 and z z.025 1.960 . Since 3.9667 lies above both
2
2
values of z, we can reject the null hypothesis.
252solngr2-08(revised!!!) 2/23/08
e) Find a p-value for the null hypothesis using your test ratio and the Normal table. Use the p-value
to test the null hypothesis. Will you reject the null hypothesis with a confidence level of 10%? 5%?
1%? .002 (0.2%)? No answer will be accepted without a brief explanation.
x 0
Solution: We already know that, if the population standard deviation is known, z
{Table 3}. For
x
a two sided test, the p-value is defined as the probability of getting results as extreme or more extreme than
those actually observed. If we call the value of z that we actually obtained z 0 and z 0 is negative,
p value 2Pz z 0 2.5 Pz 0 z 0 . If z 0 is positive, p value 2Pz z 0
2.5 P0 z z 0 . In either case, P0 z z 0 can be found on the Normal table {norm}.
For n 11 we have z
x 0
x
11 .6818 12
2.6385 . If we round this to 2.64 because of the
0.12060
limitations of Table 17, we find p value 2Pz 2.64 2.5 .4959 .0082 . We compare this with
.10 , .05 , .01 and .002 . Since .0082 is below .10, .05 and .01, we reject the null
hypothesis at the 90%, 95% and 99% confidence levels. But, since .0082 is above .002, we cannot reject the
null hypothesis at the 99.8% confidence level.
x 0 12 .5000 12
5.5903 . If we round this to 5.59 because of the limitations
For n 20 we have z
0.08944
x
of Table 17, we find p value 2Pz 5.59 2.5 .5000 0 . We compare this with .10 , .05 ,
.01 and .002 . Since 0 is below .10, .05, 01 and .002, we reject the null hypothesis at the 90%,
95%, 99% and 99.8% confidence levels. If we had a much better table, we could find a confidence level
between 99.8% and 100% at which we could not reject the null hypothesis.
Though Minitab does allow you to state that the population variance is known, the routine I used assumed
that 0.4 was a sample variance. Thus the values of z that it computed were correct, but the p-values were
wrong. In the table below, Minitab computed z, but I did the p-value.
Row
1
2
3
4
5
6
7
8
9
10
n
x
x
x
11
12
13
14
15
16
17
18
19
20
128.5
142.0
155.5
169.0
182.5
196.0
209.5
223.0
236.5
250.0
11.6818
11.8333
11.9615
12.0714
12.1667
12.2500
12.3235
12.3889
12.4474
12.5000
0.12060
0.11547
0.11094
0.10690
0.10328
0.10000
0.09701
0.09428
0.09177
0.08944
z0
x 0
x
-2.64
-1.44
-0.35
0.67
1.61
2.50
3.33
4.12
3.68
5.59
P0 z z 0
or P z 0 z 0
.4959
.4251
.1368
.2794
.4463
.4938
.4996
.5000
.4999
.5000
p-value
.0082
.1498
.7264
.4412
.1074
.0124
.0008
0.0000
.0002
0.0000
To decide whether to reject the null hypothesis use the rule on p-value:
If the p-value is less than the significance level (alpha) reject the null hypothesis; if the pvalue is greater than or equal to the significance level, do not reject the null hypothesis.
252solngr2-08(revised!!!) 2/23/08
Problem 3: Continue with your results from problem 2. We are still testing if the mean is 12.
a) Use the test ratio that you found on problem 2 to find an approximate p-value using the t-table
and assuming that 0.4 ounces was a sample standard deviation? Does this change any of your
results in 2e)?
s
Solution: If 0.4 is a sample standard deviation, s 0.4 and s x
s2
n
n
x 0
0.16
and t
.
n
sx
H : 12
{Table 3}. Our hypotheses are 0
, so 0 12 . Degrees of freedom are n 1 10 a 1 . The
H 1 : 12
relevant part of the t-table follows. {ttable}.
df .45 .40 .35 .30 .25 .20 .15 .10 .05 .025 .01 .005 .001
10 0.129 0.260 0.397 0.542 0.700 0.879 1.093 1.372 1.812 2.228 2.764 3.169 4.144
11
12
13
14
15
16
17
18
19
20
0.129
0.128
0.128
0.128
0.128
0.128
0.128
0.127
0.127
0.127
0.260
0.259
0.259
0.258
0.258
0.258
0.257
0.257
0.257
0.257
0.396
0.395
0.394
0.393
0.393
0.392
0.392
0.392
0.391
0.391
0.540
0.539
0.538
0.537
0.536
0.535
0.534
0.534
0.533
0.533
0.697
0.695
0.694
0.692
0.691
0.690
0.689
0.688
0.688
0.687
0.876
0.873
0.870
0.868
0.866
0.865
0.863
0.862
0.861
0.860
1.088
1.083
1.079
1.076
1.074
1.071
1.069
1.067
1.066
1.064
If n 11 , we have 11 – 1 = 10 degrees of freedom s x
s
1.363
1.356
1.350
1.345
1.341
1.337
1.333
1.330
1.328
1.325
1.796
1.782
1.771
1.761
1.753
1.746
1.740
1.734
1.729
1.725
s2
2.201
2.179
2.160
2.145
2.131
2.120
2.110
2.101
2.093
2.086
2.718
2.681
2.650
2.624
2.602
2.583
2.567
2.552
2.539
2.528
3.106
3.055
3.012
2.977
2.947
2.921
2.898
2.878
2.861
2.845
4.025
3.930
3.852
3.787
3.733
3.686
3.646
3.611
3.579
3.552
x 0
0.16
.12060 . t
11
sx
11
11
11 .6818 12
2.6385 . For a two sided test, the p-value is defined as the probability of getting results as
0.12060
extreme or more extreme than those actually observed. If we call the value of t that we actually obtained
t 0 and t 0 is negative p value 2Pt t 0 . To find values of Pt 2.6832 , look at the df 10 row of
the t-table. Note that t 10 2.228 , t 10 2.764 and that 2.6385 is between them. Since the table is telling
.025
.01
us that, for 10 degrees of freedom, Pt 2.228 .025 and Pt 2.764 .01 , we can conclude that
.01 Pt 2.6832 .025 . If we double this, we have .02 p value .05 . We compare this with
.10 , .05 , .01 and .002 . Since our p-value is below is below .10 and .05 but above 01
and .002, we reject the null hypothesis at the 90% and 95% confidence levels, but do not reject the null
hypothesis at the 99% and 99.8% confidence levels.
x 0
t0
x
Row n
This is between
Approximate p-value
sx
sx
1
11
11.6818
0.12060
-2.64
2
12
11.8333
0.11547
-1.44
3
13
11.9615
0.11094
-0.35
4
14
12.0714
0.10690
0.67
5
15
12.1667
0.10328
1.61
6
16
12.2500
0.10000
2.50
7
17
12.3235
0.09701
3.33
8
18
12.3889
0.09428
4.12
9
19
12.4474
0.09177
3.68
10
20
12.5000
0.08944
5.59
10
10
t .025
2.228 and t .01
2.764 .02 p value .05
11
11
t .10
1.363 and t .05
1.796
.10 p value .20
12
t .40
0.259 and
13
t
0.538 and
12
t .35
0.395 .70 p value .80
13
t .25 0.694 .50 p value ..60
.30
14
14
t .10 1.345 and t .05
1.761 .10 p value .20
15
15
t .025 2.131 and t .01 2.602 .02 p value .05
t 16 2.921 and t 16 3.686 .01 p value .002
.005
17
t .001
18
t .001
19
t .001
.001
3.636 and nothing
p value .002
3.611 and nothing
p value .002
3.579 and nothing
p value .002
252solngr2-08(revised!!!) 2/23/08
I got lucky. The excessively rounded values of t produced by Minitab were still distinct from the values
from the t-table. To decide whether to reject the null hypothesis use the rule on p-value:
If the p-value is less than the significance level (alpha) reject the null hypothesis; if the pvalue is greater than or equal to the significance level, do not reject the null hypothesis.
To get greater accuracy, I ran this on the computer. Notice that the p-values are in the expected range.
MTB > Onet 11 11.6818 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean StDev SE Mean
95% CI
11 11.682 0.400
0.121 (11.413, 11.951)
T
-2.64
P
0.025
MTB > Onet 12 11.8333 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean StDev SE Mean
95% CI
12 11.833 0.400
0.115 (11.579, 12.087)
T
-1.44
P
0.177
MTB > Onet 13 11.9615 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean StDev SE Mean
95% CI
13 11.961 0.400
0.111 (11.720, 12.203)
T
-0.35
P
0.735
MTB > Onet 14 12.0714 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean StDev SE Mean
95% CI
14 12.071 0.400
0.107 (11.840, 12.302)
T
0.67
P
0.516
MTB > Onet 15 12.1667 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean StDev SE Mean
95% CI
15 12.167 0.400
0.103 (11.945, 12.388)
T
1.61
P
0.129
MTB > Onet 16 12.2500 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean StDev SE Mean
95% CI
16 12.250 0.400
0.100 (12.037, 12.463)
T
2.50
P
0.025
MTB > Onet 17 12.3235 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean
StDev SE Mean
17 12.3235 0.4000
0.0970
95% CI
(12.1178, 12.5292)
T
3.33
P
0.004
MTB > Onet 18 12.3889 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean
StDev SE Mean
18 12.3889 0.4000
0.0943
95% CI
(12.1900, 12.5878)
T
4.12
P
0.001
MTB > Onet 19 12.3373 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean
StDev SE Mean
19 12.3373 0.4000
0.0918
95% CI
(12.1445, 12.5301)
T
3.68
P
0.002
252solngr2-08(revised!!!) 2/23/08
MTB > Onet 20 12.5000 .4;
SUBC>
Test 12.
One-Sample T
Test of mu = 12 vs not = 12
N
Mean
StDev SE Mean
20 12.5000 0.4000
0.0894
95% CI
(12.3128, 12.6872)
T
5.59
P
0.000
b) Assume once again that 0.4 is a sample standard deviation. Test the hypothesis that the
population mean is 12 ounces. Show your ‘reject region on a diagram. .05 .
Note: b) as written was a typo. It should have read ‘0.4 is a sample standard deviation. As written, the
answer is the same as to 2b. The answer below is very important. Read it!
H : 12
Solution: After the last section this is pretty easy. We are still testing 0
. The wording of the
H 1 : 12
question implies that we should use a test ratio or a critical value for x . Only one of these is needed.
x 0
If we want to use a test ratio, compute t
.
sx
If n 11 , we have 11 – 1 = 10 degrees of freedom s x
s
s2
11
11
x 0
0.16
0.12060 . t
11
sx
11 .6818 12
10
2.6385 . The t-table tells us that t .025
2.228 . We have two reject regions for t. Make a
0.12060
diagram with zero in the center. Shade a lower reject zone below -2.228 and an upper ‘reject’ zone above
+2.228. Since -2.6385 is below -2.228, it is in the lower ‘reject’ zone, so we reject the null hypothesis.
If we want to use a critical value for x , remember x cv 0 t x {Table 3}.
2
If n 11 , we have 11 – 1 = 10 degrees of freedom s x
s
11
s2
11
0.16
0.12060 . The t-table tells
11
10
us that t .025
2.228 . x cv 0 t x 12 2.228 0.12060 12 0.2687 . Make a diagram with 12 in
2
the center. Shade a lower reject zone below 11.73 and an upper ‘reject’ zone above 12.27. Since
x 11.6818 is below 11.73, it is in the lower ‘reject’ zone, so we reject the null hypothesis.
The table below shows test ratios only, but it should be easy to construct critical values for x or confidence
intervals for from the information in the table.
Row
1
n
11
x
11.6818
sx
0.12060
t0
x 0
sx
-2.64
df
9 a
t n1 t.025
Conclusion
2
10
10
t .025
2.228
Reject H 0 .
2
12
11.8333
0.11547
-1.44
11
3
13
11.9615
0.11094
-0.35
12
11
t .025
2.201
t 12 2.179
4
14
12.0714
0.10690
0.67
13
2.160
Do not reject H 0 .
5
15
12.1667
0.10328
1.61
14
2.145
Do not reject H 0 .
6
16
12.2500
0.10000
2.50
15
2.131
Reject H 0 .
7
17
12.3235
0.09701
3.33
16
2.120
Reject H 0 .
8
18
12.3889
0.09428
4.12
17
2.110
Reject H 0 .
9
19
12.4474
0.09177
3.68
18
2.101
Reject H 0 .
10
20
12.5000
0.08944
5.59
19
2.093
Reject H 0 .
.025
13
t .025
14
t .025
15
t .025
16
t .025
17
t .025
18
t .025
19
t .025
Do not reject H 0 .
Do not reject H 0 .
252solngr2-08(revised!!!) 2/23/08
s
If n 11 , we have 11 – 1 = 10 degrees of freedom s x
11
s2
11
0.16
0.12060 . The t-table tells
11
10
us that t .025
2.228 . x cv 0 t x 12 2.228 0.12060 12 0.2687 . Make a diagram with 12 in
2
the center. Shade a lower reject zone below 11.73 and an upper ‘reject’ zone above 12.27. Since
x 11.6818 is below 11.73, it is in the lower ‘reject’ zone, so we reject the null hypothesis.
The table below shows test ratios only, but it should be easy to construct critical values for x or confidence
intervals for from the information in the table.
If we want to use a confidence interval, remember x t x .
2
10
If n 11 , we have 11 – 1 = 10 . We have already computed s x , found t .025
2.228 and computed
t x 2.228 0.12060 0.2687 , so we have x t x 11.6818 0.2687 . Make a diagram with
2
2
11.6818 in the center. Shade the confidence interval between 11.4131 and 11.9505. Since 0 12 is above
this interval, the null hypothesis is contradicted by the confidence interval and we reject the null hypothesis.
c) i) Assume that 0.4 is a population standard deviation. Test the hypothesis that the population
mean is above 12 ounces using the test ratio that you found in 1d). State your null and alternative
hypotheses. Show your ‘reject region on a diagram.
Solution: This is very important. The problem asks us to test ' 0' . This is an alternative hypothesis
H 0 : 12
because it does not contain an equality. this implies that our hypotheses are
.
H 1 : 12
x 0
If we want to use a test ratio, compute z
. We have already done this. But now we must test this
sx
value of z against z . Since 0 12 values of x above 12 will result in positive values of z . Make a
diagram with zero in the center. Shade a ‘reject’ zone above z .05 1.645 . The table from 2e is repeated
with values of z and p-values. The pvalues for the first few are important because they exceed .5. Because
this is a right-sided test, if your value of the sample mean is x a and your value of z is z 0 , the p-value is
Px x a Pz z 0 . There are two methods of testing in the table. If the value of z 0 is above 1.645, the
z 0 is marked with an ‘r’ for ‘reject.’ The p-value is also computed, so that you coule also reject the null
hypothesis if the p-value is below .05.
x 0 P0 z z 0
x
z0
Row n
p-value
x
x
or P z 0 z 0
x
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
128.5
142.0
155.5
169.0
182.5
196.0
209.5
223.0
236.5
250.0
11.6818
11.8333
11.9615
12.0714
12.1667
12.2500
12.3235
12.3889
12.4474
12.5000
0.12060
0.11547
0.11094
0.10690
0.10328
0.10000
0.09701
0.09428
0.09177
0.08944
-2.64
-1.44
-0.35
0.67
1.61
2.50r
3.33r
4.12r
3.68r
5.59r
.4959
.4251
.1368
.2794
.4463
.4938
.4996
.5000
.4999
.5000
.9959
.9251
.6368
.2206
.0537
.0062r
.0004r
0.0000r
.0001r
0.0000r
c) ii) If this was a typo and the question should have read ‘Assume that 0.4 is a sample standard
deviation. Test the hypothesis that the population mean is above 12 ounces using the test ratio that you
found in 1d). State your null and alternative hypotheses. Show your ‘reject region on a diagram.’ The
solution is below.
252solngr2-08(revised!!!) 2/23/08
Solution: This is very important. The problem asks us to test ' 0' . This is an alternative hypothesis
H 0 : 12
because it does not contain an equality. this implies that our hypotheses are
.
H 1 : 12
x 0
If we want to use a test ratio, compute t
. We have already done this. But now we must test this
sx
value of t against t n 1 . Since 12 values of x above 12 will result in positive values of t .
0
If n 11 , we have 11 – 1 = 10 degrees of freedom s x
s
11
s2
11
x 0
0.16
0.12060 . t
11
sx
11 .6818 12
10
2.6385 . The t-table tells us that t .05
1.812 . We want one ‘reject’ region for t . Make
0.12060
a diagram with zero in the center. Shade a ‘reject’ zone above 1.812. Since -2.6385 is below 1.812, it is
not in the ‘reject’ zone, so we do not reject the null hypothesis.
Since we will need tn 1 , the table from the last section is repeated with these new values of t .
Row
1
n
x
sx
11
11.6818
0.12060
t0
x 0
sx
-2.64
df
10
9 a
tn1 t .05
Conclusion
10
t .05
1.812
Do not reject H 0 .
2
12
11.8333
0.11547
-1.44
11
3
13
11.9615
0.11094
-0.35
12
11
t .05
1.796
t 12 1.782
4
14
12.0714
0.10690
0.67
13
1.771
Do not reject H 0 .
5
15
12.1667
0.10328
1.61
14
1.761
Do not reject H 0 .
6
16
12.2500
0.10000
2.50
15
1.753
Reject H 0 .
7
17
12.3235
0.09701
3.33
16
1.746
Reject H 0 .
8
18
12.3889
0.09428
4.12
17
1.740
Reject H 0 .
9
19
12.4474
0.09177
3.68
18
1.734
Reject H 0 .
10
20
12.5000
0.08944
5.59
19
1.729
Reject H 0 .
.05
13
t .05
14
t .05
15
t .05
16
t .05
17
t .05
18
t .05
19
t .05
Do not reject H 0 .
Do not reject H 0 .
d) Assume that 0.4 is a population standard deviation. Test the hypothesis that the population
mean is above 12 ounces using a critical value for the sample mean. State your null and alternative
hypotheses. Show your ‘reject region on a diagram.
Solution: If we want to use a critical value for x , remember x cv 0 t x is the formula for a 2-sided
2
H 0 : 12
test. {Table 3} However, our hypotheses are now
and we are only interested in values above
H 1 : 12
12. We are essentially asking how far above 12 the sample mean must be to make us strongly doubt the
truth of the null hypothesis. This means that the critical value formula becomes xcv 0 t x .
If n 11 , we have 11 – 1 = 10 degrees of freedom s x
s
11
s2
11
0.16
0.12060 . Remember also
11
10
1.812 . We want one ‘reject’
that 0 12 cannot be in the ‘reject’ zone. The t-table tells us that t .05
region for x . It will be the area above xcv 0 t x 12 1.812 0.12060 12.2185 . Make a
diagram with 12 in the center. Shade a ‘reject’ zone above 12.2185. . Since x 11.6818 is not above
12.2185, it is not in the ‘reject’ zone, so we do not reject the null hypothesis. The values in the table in 3c)
252solngr2-08(revised!!!) 2/23/08
should enable you to check your critical value. The conclusions should be identical with the conclusions on
the table.
e) Assume that 0.4 is a population standard deviation. Test the hypothesis that the population
mean is above 12 ounces using a one-sided confidence interval. Shade the confidence interval in
your diagram.
If we want to use a confidence interval, remember x t x is the formula for a two sided interval.
2
H : 12
We now need a 1-sided interval. Remember that our hypotheses are now 0
and that a
H 1 : 12
confidence interval to test the null hypothesis must go in the direction of the alternative hypothesis. Also
remember that the confidence interval must include x . Under those circumstances we are constructing a
lower limit for 0 , and the confidence interval formula becomes x t x .
If n 11 , we have 11 – 1 = 10 degrees of freedom. We have already found s x 0.12060 and that
10
t .05
1.812 . The confidence interval will be x t x 11.6818 1.812 0.12060 11.4633 .
Make a diagram with x 11.6818 in the center. Shade the one-sided confidence interval 11.4633 ,
which is the entire area above 11.4633. This interval will include x 11.6818 . You can indicate the null
hypothesis 12 by shading the entire area below 12 with a different type of shading from the shading
you used for the confidence interval. You then should observe that these overlap, indicating that it is
possible that both 11.4633 and 12 are possible. More simply, just draw the one-sided confidence
interval 11.4633 and show that 0 12 is on that interval.
In cases where we must reject the null hypothesis, the confidence interval and the area representing the null
hypothesis will not overlap, or, more simply, 0 12 will not be on the confidence interval. The
conclusions should be identical with the conclusions on the table in 3c).
252solngr2-08(revised!!!) 2/23/08
Problem 4: (Steinberg) Supposedly at least 36% of college students change their major between freshman
year and graduation. You take a survey of 630 graduating seniors and find that 220 b changed their
majors, where b is the last digit of your student number. For example, Ima Badrisk has student number
12345, so b 5 and she claims that 220 b 220 5 225 changed their majors. Test the hypothesis.
a) State your null and alternative hypotheses.
Solution: ‘At least 36% can be written as p .36 . Because this contains an equality, it is a null hypothesis.
H : p .36
Our hypotheses are thus 0
. Because the null hypothesis will only be jeopardized if the
H 1 : p .36
observed proportion is smaller than 36%, this is a left-sided test.
b) Find a test ratio for a test of the proportion.
p0 q0
H 0 : p p 0
p p0
For the hypotheses
, the test ratio is z
where p
and q 0 1 p 0
p
n
H 1 : p p 0
{Table 3}. For a left sided test, we use the same ratio. We have p 0 .36 and q 0 1 .36 .64
If b 0 ,
x 220 b 220 0 220 changed their minds and p x 220 .3492 . q 1 p 1 .3492
.6508 . This means p
n
.36 .64
630
630
p p0
.2304
.0003657 .01912 . The test ratio will be z
630
p
.3492 .36
0.5649 .
.01912
c) Make a diagram showing the rejection region for the test ratio if you use a 99% confidence
level.
Solution: The test is the same for every value of b . Since this is a left-sided test we will reject the null
hypothesis if the test ratio is below z .01 2.327 {ttable}. Make a diagram. Center a Normal curve at
zero. Shade the area below -2.327.
d) Find a p-value for this ratio and use it to test the hypothesis at a 1% significance level.
Because this is a left-sided test, the p-value is defined as the probability that p p 0 or P z z 0 , where
z 0 is the computed value of z and . p 0 is the value of p that we actually got.
If b 0 , we have found p .3492 , so we want P p .3492 Pz 0.5649 Pz 0.56
Pz 0 P0.56 z 0 .5 .2123 .2877 . Since this p-value is above .01 , we cannot reject the
null hypothesis.
252solngr2-08(revised!!!) 2/23/08
Extra Credit Problem 5:
a) Assume that the sample size is 20, 2 changed majors and you are testing the statement that at
least 40% changed majors. Do the test at the 90% confidence level without using the Normal
distribution.
H 0 : p .40
Solution: Our hypotheses are
. Use the Binomial table with p .40 and n 20 . Since
H 1 : p .40
x 2 , we can say p value Px 2 .00020 . {bin} Since this is below the significance level of .10, we
reject the null hypothesis.
The following data can be used in b) and c). Fortunately, these were the data for the current ECO
251 graded assignment, so that I could just copy most of the next two pages.
Make sure that your student number is easily readable. Choose one of the columns below using the second
to last digit of your Student Number. Example: Ima Badrisk has student number 123456; so she picks
column x5. Forget about the rest of the columns!
Row
1
2
3
4
5
6
7
8
9
10
11
12
13
x0
2.3
7.9
11.5
2.1
9.1
5.8
2.7
12.0
0.6
-8.7
4.1
-0.6
-0.4
x1
8.8
2.9
2.5
6.5
3.4
-3.6
3.4
-1.5
11.5
16.1
4.6
1.4
4.4
x2
12.1
3.6
1.8
9.9
9.8
6.8
3.9
9.9
8.2
14.1
6.8
13.9
6.7
x3
5.7
5.7
2.8
2.9
1.2
6.8
0.3
9.6
3.8
0.7
9.3
9.4
6.1
x4
16.0
3.5
-1.7
6.8
8.9
4.1
-2.9
15.5
1.9
-0.9
3.0
2.8
4.1
x5
11.4
-4.6
4.7
-2.7
-3.6
-0.5
-1.2
-2.6
13.4
0.5
3.2
9.1
0.8
x6
3.3
3.5
12.2
-1.6
7.1
4.1
0.1
7.1
-1.5
1.0
6.2
1.7
-2.3
x7
-2.5
1.6
2.7
-0.8
-0.3
3.0
0.3
10.6
4.9
3.3
14.8
17.4
9.5
x8
6.7
1.7
2.0
10.5
4.6
11.3
6.7
4.1
5.2
3.7
9.9
4.9
9.7
x9
3.0
5.3
1.1
6.0
8.9
7.4
1.2
0.6
4.2
7.1
5.0
-2.5
8.8
b) Compute a sample standard deviation for your column and test the hypothesis 4
Solution: The solutions for all 10 versions of this problem are presented simultaneously. You should
have done only one. First we compute sums
Row
x0
1
2
3
4
5
6
7
8
9
10
11
12
13
2.3
7.9
11.5
2.1
9.1
5.8
2.7
12.0
0.6
-8.7
4.1
-0.6
-0.4
48.4
x1
x2
x3
8.8 12.1 5.7
2.9
3.6 5.7
2.5
1.8 2.8
6.5
9.9 2.9
3.4
9.8 1.2
-3.6
6.8 6.8
3.4
3.9 0.3
-1.5
9.9 9.6
11.5
8.2 3.8
16.1 14.1 0.7
4.6
6.8 9.3
1.4 13.9 9.4
4.4
6.7 6.1
60.4 107.5 64.3
x4
16.0
3.5
-1.7
6.8
8.9
4.1
-2.9
15.5
1.9
-0.9
3.0
2.8
4.1
61.1
x5
11.4
-4.6
4.7
-2.7
-3.6
-0.5
-1.2
-2.6
13.4
0.5
3.2
9.1
0.8
27.9
x6
x7
x8
3.3
3.5
12.2
-1.6
7.1
4.1
0.1
7.1
-1.5
1.0
6.2
1.7
-2.3
40.9
-2.5
1.6
2.7
-0.8
-0.3
3.0
0.3
10.6
4.9
3.3
14.8
17.4
9.5
64.5
6.7
1.7
2.0
10.5
4.6
11.3
6.7
4.1
5.2
3.7
9.9
4.9
9.7
81.0
Next we square individual columns to get the sum of x-squared.
Row
x 02
x12
x 22
x 32
x 42
x 52
1
2
3
4
5
6
7
8
9
10
11
12
13
5.29 77.44 146.41 32.49
62.41
8.41
12.96 32.49
132.25
6.25
3.24
7.84
4.41 42.25
98.01
8.41
82.81 11.56
96.04
1.44
33.64 12.96
46.24 46.24
7.29 11.56
15.21
0.09
144.00
2.25
98.01 92.16
0.36 132.25
67.24 14.44
75.69 259.21 198.81
0.49
16.81 21.16
46.24 86.49
0.36
1.96 193.21 88.36
0.16 19.36
44.89 37.21
565.48 606.62 1066.51 448.15
256.00
12.25
2.89
46.24
79.21
16.81
8.41
240.25
3.61
0.81
9.00
7.84
16.81
700.13
129.96
21.16
22.09
7.29
12.96
0.25
1.44
6.76
179.56
0.25
10.24
82.81
0.64
475.41
x9
3.0
5.3
1.1
6.0
8.9
7.4
1.2
0.6
4.2
7.1
5.0
-2.5
8.8
56.1
x 62
10.89
12.25
148.84
2.56
50.41
16.81
0.01
50.41
2.25
1.00
38.44
2.89
5.29
342.05
x 72
x 82
x 92
6.25 44.89
9.00
2.56
2.89 28.09
7.29
4.00
1.21
0.64 110.25 36.00
0.09 21.16 79.21
9.00 127.69 54.76
0.09 44.89
1.44
112.36 16.81
0.36
24.01 27.04 17.64
10.89 13.69 50.41
219.04 98.01 25.00
302.76 24.01
6.25
90.25 94.09 77.44
785.23 629.42 386.81
252solngr2-08(revised!!!) 2/23/08
Let us summarize our results so far. n 13 for all columns.
The sums are
x 48.4,
x 60.4,
x 107.5,
x
5
27.9,
0
x
40.9,
6
The sums of squares are
x
x42
700.13,
2
9
386.81.
x52
x 02
1
x
7
565.48,
475.41,
x
2
n
= 4.70000, x 5
x
x
4.96154, x8
8
5
s12
nx1
n 1
= 14.7973,
s 32
2
x 02
n 1
x 32
nx3
2
nx 6
n 1
38.7676, s 8
2
x
n 1
6
x 52
x
0
n
nx8
n 1
2
3
1
n
56 .1
4.31538.
13
448.150,
629.42 and
x82
x
40 .9
3.14615,
13
s 22
2
60 .4
=
13
x
x7
4
n
x
7
n
61 .1
13
64 .5
=
13
x
2
2
nx 2 2
n 1
1066 .51 138.26923 2
12
x
2
4
nx 4 2
n 1
475 .41 132.14615
34.6277,
12
342 .05 133.14615
17.7810, s 72
12
2
x
565 .48 133.72308 2
32.1069,
12
nx 5
n 1
2
x82
785.23,
61.1,
4
56.1.
9
64 .3
4.94615, x 4
13
n
x
1066.51,
x22
448 .15 134.94615 2
10.8427, s 42
12
700 .13 134.70000
= 34.4133, s 52
12
s 62
nx 0
3
n
2
x72
x
64.3,
48 .4
3.72308, x1
13
606 .62 134.64615 2
27.1660,
12
2
x
81 .0
6.23077 and x 9
13
2
x 62
27 .9
2.14615, x 6
13
We can put this all together to get s 02
x12
n
107 .5
8.26923, x 3
13
n
0
n
606.62,
x
3
81.0 and
8
342.05,
x62
We can thus calculate the means and get x 0
4.64615, x 2
x
64.5,
x12
x
2
2
x
2
7
nx 7 2
n 1
629 .42 136.23077 2
10.3940 and s 92
12
785 .23 134.96154 2
=
12
x
2
9
nx 9 2
n 1
386 .81 134.315388
12.0597.
12
To get the standard deviation, take the square root of the variance. s 0 32.1069 = 5.66630,
2
s1 27 .1660 = 5.21210, s 2 14 .7973 = 3.84673, s 3 10 .8472 = 3.29282,
s 4 34 .4133 = 5.86629, s 5 34 .6227 = 5.88453, s 6 17 .7810 = 4.21676, s 7 38 .7676
= 6.22636, s 8 10 .3940 = 3.22397 and s 9 12 .0597
H 0 : 4
We are testing
or
H 1 : 4
sample we have the following.
= 3.47271.
H 0 : 2 16
. According to the formula table {Table 3}., for a small
H 1 : 2 16
252solngr2-08(revised!!!) 2/23/08
Interval for
Confidence
Interval
VarianceSmall Sample
2
Hypotheses
Test Ratio
n 1s 2
H 0 : 2 02
.25 .5 2
H1: : 2 02
2
Critical Value
n 1s 2
2
s cv
02
If we assume a 90% confidence level, we will not reject our null hypothesis if 2
.25 .5 2 02
n 1
n 1s 2 = 12 s 2
02
16
is
12
12
between 2 .95 5.2260 and 2 .05 21.0262 . If we assume a 95% confidence level, we will not reject
our null hypothesis if 2
02
16
12
12
is between 2 .975 4.4038 and 2 .025 23.3367 .
Conclusion if .10
2
s2
s 02 32.1069
s12 27.1660
s 22 = 14.7973
s32 10.8427
s 42 = 34.4133
s52 34.6277
s 62 17.7810
s 72 = 38.7676
s82 10.3940
s92 12.0597
n 1s 2 = 12 s 2
24.0802
Reject H 0
Conclusion if .05
Reject H 0
20.3745
Do not reject H 0
Do not reject H 0
11.0979
Do not reject H 0
Do not reject H 0
8.1320
Do not reject H 0
Do not reject H 0
25.8099
Reject H 0
Reject H 0
25.8100
Reject H 0
Reject H 0
13.3358
Do not reject H 0
29.0757
Reject H 0
Do not reject H 0
Reject H 0
7.7955
Do not reject H 0
Do not reject H 0
9.0434
Do not reject H 0
Do not reject H 0
c) Using the same data, test the hypothesis that the median is below 4.
The numbers in order follow. x is the number that are above 4. p is the observed proportion above 4.
Index
1
2
3
4
5
6
7
8
9
10
11
12
13
x0
x1
x2
x3
-8.7 -3.6
1.8 0.3
-0.6 -1.5
3.6 0.7
-0.4
1.4
3.9 1.2
0.6
2.5
6.7 2.8
2.1
2.9
6.8 2.9
2.3
3.4
6.8 3.8
2.7
3.4
8.2 5.7
4.1
4.4
9.8 5.7
5.8
4.6
9.9 6.1
7.9
6.5
9.9 6.8
9.1
8.8 12.1 9.3
11.5 11.5 13.9 9.4
12.0 16.1 14.1 9.6
x
6
6
10
7
p .4625 .4625 .7692 .5385
x4
x5
x6
-2.9
-1.7
-0.9
1.9
2.8
3.0
3.5
4.1
4.1
6.8
8.9
15.5
16.0
6
.4625
-4.6
-3.6
-2.7
-2.6
-1.2
-0.5
0.5
0.8
3.2
4.7
9.1
11.4
13.4
5
.3846
-2.3
-1.6
-1.5
0.1
1.0
1.7
3.3
3.5
4.1
6.2
7.1
7.1
12.2
5
.3846
x7
-2.5
-0.8
-0.3
0.3
1.6
2.7
3.0
3.3
4.9
9.5
10.6
14.8
17.4
5
.3846
x8
x9
1.7 -2.5
2.0
0.6
3.7
1.1
4.1
1.2
4.6
3.0
4.9
4.2
5.2
5.0
6.7
5.3
6.7
6.0
9.7
7.1
9.9
7.4
10.5
8.8
11.3
8.9
10
8
.7962 .6154
252solngr2-08(revised!!!) 2/23/08
H : p .50
Our hypotheses are 0
According to table 3, the critical values for p are p cv p 0 z p ,
2
H 1 : p .50
p0 q0
.5.5
.1387 . If .05 , z .025 1.960 , so p cv .5 1.960 .1387 .5 .2719
n
13
or .2281 and .7719 and if .10 , z 05 1.645 , so p cv .5 1.645 .1387 .5 .2282 or .2718 and
.7282.
where p
Index
x
p
.05
.10
p-value
x0
x1
x2
x3
x4
x5
x6
x7
x8
x9
6
6
10
7
6
5
5
5
10
8
.4625 .4625 .7692 .5385 .4625 .3846 .3846 .3846 .7962 .6154
Don’t Don’t Don’t Don’t Don’t Don’t
Don’t Don’t Reject Don’t Don’t Don’t
1.0000 1.0000 .0923 1.0000 1.0000 .5831
Don’t
Don’t
.5831
Don’t Don’t Don’t
Don’t Reject Don’t
.5831 .0923 .5811
The p-values are more accurate at small values of n, and are gotten as follows from the binomial table with
n 13 . {bin}
x
p-value
5
2Px 5 2.29053 .5831
6
7
8
10
2Px 6 2.50000 1.0000
2Px 7 21 Px 6 2.50000 1.0000
2Px 8 21 Px 7 21 .70947 .5811
2Px 10 21 Px 9 21 .95386 .0923
e) Use Minitab to check your answer to problem 4. Do this three ways.
First: Enter Minitab. Use the Editor pull-down menu to enable commands. Then enter the
commands below.
Pone 630 220+b;
(Replace 220+b with the number you used.)
Test 0.36;
Conf 99;
(Sets a 99% confidence level)
Alter -1;
(Makes H1 ‘less than.’)
useZ.
(Uses normal approx. to binomial)
Second: Use the Stat pull-down menu. Choose ‘Basic Stat’ and then ‘1 proportion.’
Check ‘summarized data’ and enter your n for ‘number of trials’ and 220+b for ‘number of
events.’ Check ‘perform hypothesis test.’ Set ‘hypothesized proportion’ as 0.36. Press Options. Set
‘confidence level’ as 99, alternative hypothesis as ‘less than’ and check ‘Normal distribution.’ Go.
Third: Use the pull-down menu again. But before you start put 220+b yeses and 410+b noes in
column 1. (You should have 630 rows of data. You can do this entry very rapidly if you use
only y or 1 for yes and n or 0 for no. Just enter y 220+b times and then n until you get to row
630. Even better, put a zero in the first row and use the fill handle on the bottom right of the cell to
enter 1 an appropriate number of times then put a zero in the rest of the column the same way.)
Uncheck ‘summarized data’ and let Minitab know that the data are in column 1 (C1). Other
options are unchanged.
(Fourth: repeat your third try, but uncheck ‘Normal distribution.’ )
Here’s my output. I only did one version.
————— 2/5/2008 5:45:38 PM ———————————————————
Welcome to Minitab, press F1 for help.
MTB > WOpen "C:\Documents and Settings\RBOVE\My Documents\Minitab\2gr2081b.MTW".
Retrieving worksheet from file: 'C:\Documents and Settings\RBOVE\My
Documents\Minitab\2gr2-081b.MTW'
Worksheet was saved on Tue Feb 05 2008
252solngr2-08(revised!!!) 2/23/08
Results for: 2gr2-081b.MTW
MTB >
SUBC>
SUBC>
SUBC>
SUBC>
pone 630 220;
test 0.36;
conf 99;
alter -1;
useZ.
Test and CI for One Proportion
Test of p = 0.36 vs p < 0.36
99% Upper
Sample
X
N Sample p
Bound
1
220 630 0.349206
0.393391
Using the normal approximation.
Z-Value
-0.56
P-Value
0.286
Z-Value
-0.56
P-Value
0.286
MTB > POne 630 220;
SUBC>
Test .36;
SUBC>
Confidence 99.0;
SUBC>
Alternative -1;
SUBC>
UseZ.
Test and CI for One Proportion
Test of p = 0.36 vs p < 0.36
99% Upper
Sample
X
N Sample p
Bound
1
220 630 0.349206
0.393391
Using the normal approximation.
MTB > print c1
Data Display
C1
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
y
y
y
y
y
y
y
y
y
y
y
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
252solngr2-08(revised!!!) 2/23/08
MTB > POne c1;
SUBC>
Test .36;
SUBC>
Confidence 99.0;
SUBC>
Alternative -1;
SUBC>
UseZ.
Test and CI for One Proportion: C1
Test of p = 0.36 vs p < 0.36
Event = y
99% Upper
Variable
X
N Sample p
Bound
C1
220 630 0.349206
0.393391
Using the normal approximation.
Z-Value
-0.56
P-Value
0.286
MTB > print c3
Data Display
C3
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
MTB > POne c3;
SUBC>
Test .36;
SUBC>
Confidence 99.0;
SUBC>
Alternative -1;
SUBC>
UseZ.
Test and CI for One Proportion: C3
Test of p = 0.36 vs p < 0.36
Event = 1
99% Upper
Variable
X
N Sample p
Bound
C3
220 630 0.349206
0.393391
Using the normal approximation.
Z-Value
-0.56
P-Value
0.286
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
252solngr2-08(revised!!!) 2/23/08
MTB > POne c1;
SUBC>
Test .36;
SUBC>
Confidence 99.0;
SUBC>
Alternative -1.
Test and CI for One Proportion: C1
Test of p = 0.36 vs p < 0.36
Event = y
Variable
C1
X
220
N
630
Sample p
0.349206
99% Upper
Bound
0.395036
Exact
P-Value
0.302