Document 15435880
advertisement

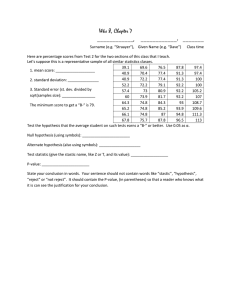
For each scenario the last sentence is statistically incorrect. Rewrite the sentence making only small changes that still explain what the author should have been trying to say. 1. A hypothesis test examined whether the average age of a UW student was equal to 25 years. The p-value was 0.32. Thus we conclude that the true average age of all UW students really is 25 years old. Thus we cannot conclude that the average age of a UW student cannot be 25 (fail to reject, not accept Ho) 2. A regression analysis on temperature verses stress level found an R2 of 0.90. That means that 90% of the temperatures can be explained by stress level That means that 90% of the variability in temperature can be explained by stress level 3. A 95% confidence interval for the average number of calories a person eats in a day was (1800, 2977). That means that 95% of the time the average will be between 1800 and 2977 calories. That means that we used a method that works 95% of the time to say the average is between 1800 and 2977. 4. A study of 500 children in grade school found a prediction equation for math scores as a function of age. My age is 34, and using this equation my math score should be 540%! My age is 34, which is outside the data range used in the study, and as such I cannot predict my math score with this study. (extrapolation) 5. A hypothesis test for a difference in the number of shoes owned by each gender found a p-value of 0.03. That means that 3% of the time the gender will explain the shoes. That means that 3% of the time we would see a difference like this between the genders when there really is no difference at all. 6. Regression on profit verses age of the CEO found a p-value of 0.84 with an R2 of 0.85. That tells us that we can predict the profit easily based on the age of the CEO That tells us that although the data fits a line very well, there is not enough data here to decisively claim there is a relationship between age of CEO and profit (this happens when you have only a few dots, but they go in a nice line) 7. The R2 for height vs weight was 0.99 with a p-value of 0.01. Since the slope was positive that tells us that if you gain more weight, your height will increase. Since that slope was positive that tells us that if you are heavier, then you are expected to be taller (correlation, not causation) 8. The distribution for the price of a math textbook has a standard deviation of $10. That means that 68% of all math textbooks are within $20 of each other. That means that 68% of all math textbooks are within $20 of each other IF WE ASSUME NORMALITY 9. A hypothesis test examined whether there was a relationship between height and salary. The p-value was 0.02 with R2=0.03. This means that we can easily predict your salary based on your height. This means that there is mostly certainly a relationship between height and salary, but there is so much variability that it is very difficult to actually get any good predictions. (this happens when there’s a large sigma, but a massively huge data set) 10. A hypothesis test examined whether genetically modified apples are more likely to give you cancer than regular apples. The percentage of cancer incidents doubled with the genetically modified apples, going from 0.002% to 0.004%. This leads us to conclude that genetically modified apples are dangerous and should be banned from the US. This leads us to conclude that genetically modified apples might have an increased chance of cancer, but that increase is so incredibly small as to be unimportant (statistically significant, but not practically significant)