Word_LaGrange_ideas.doc
advertisement

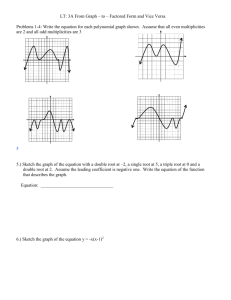
Suppose we want to minimize the quadratic function f(X) = X2 subject to the restriction that (X-1)2 = 4. Of course this is easy since the only possibilities are X=3, X=-1 and 2X=0 so we can just plug in these numbers and get both a maximum and a minimum, which we know exist at the endpoints or in the interior because our function f(X) is continuous within the closed interval [3, -1]. Now suppose we want to minimize some complicated continuous function f(X,Y,W,Z) subject to the restriction that (X,Y,W,Z) is a point on a sphere of radius 2. That’s not so simple! In what follows I will show how to solve the first, simple problem using a method that is overkill for that problem but will extend to the not so easy problems like the second one mentioned here. First, let’s notice something about derivatives. If we think about all the points (X,Y) such that Y= (X-1)2 we are talking about a parabola which can also be written as Y-(X-1)2=0 . If we take all points with Y2 =(X-1)2 +4 we are talking about a circle of radius 2 with center at (1,0) namely (Y-0)2+(X-1)2-4=0 or 2(Y0)2+2(X-1)2-8=0 or 3.5(Y-0)2+3.5(X-1)2-14=0 or in general [(Y-0)2+(X-1)2-4]=0 etc., that is, any arbitrary scaling factor gives the same circle. Think of the parabola as g(X,Y) = Y-(X-1)2 =0 so our parabola satisfies g(X,Y)=0. Differentiating g(X,Y) with respect to X gives us g(1)(X,Y) = -2(X-1) or -4(X-1) or -7(X-1) or 2(X-1) in general. Differentiating with respect to Y gives g(2)(X,Y)=1 or 2 or 3.5 or . Now a secant to the curve g(X,Y)=0 would be the line connecting g(X,Y) with g(X+dX, Y+dY) where now dX and dY represent small perturbations in the coordinates so, by Taylor’s theorem, we have approximately g(X+dX, Y+dY)= g(X,Y)+ g(1)(X,Y)dX + g(2)(X,Y)dY. For both points to be on the curve we need them to satisfy the curve’s equation, namely g(X+dX, Y+dY)= g(X,Y)=0, from which it follows that g(1)(X,Y)dX + g(2)(X,Y)dY=0 or dY/dX = - g(1)(X,Y)/ g(2)(X,Y) = -(-2(X-1)/) = 2(X-1) where is a scaling factor (1, 2, or 3.5 in our above examples). Taking limits we have the derivative, that is the secant approaches a tangent, and its slope approaches the slope of the curve. It is the RATIO of these partial derivatives that matters, not the scaling. As a second example, for the circle Y2 +(X-1)2=4 we define g(X,Y)= [(Y-0)2+(X-1)2-4] . We can differentiate implicitly with respect to Y -> (2 Y) and X -> (2 (X-1)) to get the ratio - (X-1)/Y so again, the scaling factor is irrelevant. The derivative is –(X-1)/Y. Here, although g(X,Y) is a function of X and Y, the set of points where g(X,Y)=0 does NOT define Y as a function of X because for the X values of interest there are two Y values. We have Y 4 ( X 1) 2 so taking the top of the circle as a function, the derivative is and for the bottom dY 2( X 1) / [2 4 ( X 1) 2 ] ( X 1) / 4 ( X 1) 2 ( X 1) / Y dX dY 2( X 1) / [2 4 ( X 1) 2 ] ( X 1) / 4 ( X 1) 2 ( X 1) / Y since for dX the bottom, Y 4 ( X 1) 2 . So we have 2 ways to get dY/dX and have verified they are both the same. Now for the LaGrange method. We want to minimize or maximize some function f(X,Y) subject to a restriction which we can write as g(X,Y)=0. Suppose we know that f has a maximum or minimum over the set of (X,Y) values with g(X,Y)=0. In our cases g will represent a sphere (circle) and f a differentiable function so we have a differentiable function f over a closed bounded curve (circle) or surface (sphere) which must have at least one maximum and minimum on that curve. The LaGrange method expands f to h(X,Y,) = f(X,Y) – g(X,Y). The “gradient” is the vector of 3 partial derivatives as follows: dh dh g ( X , Y ) , (2) f (1) ( X , Y ) g (1) ( X , Y ) d dX dh f (2) ( X , Y ) g (2) ( X , Y ) (3) dX (1) Setting the derivatives to 0 we see that (1) forces the critical point to be on the function g(X,Y)=0 so we definitely satisfy the restriction. The resulting three equations in three unknowns can be solved to produce two or more (X,Y,) triplets (unless the surface f(X,Y) is a horizontal plane f(X,Y)=C). We know this because we must have a maximum and a minimum of f as we look over all points with g(X,Y)=0. Setting (2) and (3) to 0 gives “gradient” vectors ( f (1) ( X , Y ), f (2) ( X , Y )) ( g (1) ( X , Y ), g (2) ( X , Y )) . Since the slopes of the tangent lines to f and g are the (negative) ratios of the two coordinates, the scaling factor is, as before, irrelevant and we see that the solution is a point that is common to both functions (an intersection point) at which the slopes are the same, that is, it is at a tangent point. We do need a in our h( ) function to force the solution to satisfy the restriction. In our specific applications we will be interested in finding extrema of some quadratic function f(X1,X2,…,Xp) of several variables, like X1=pH, X2=moisture, X3=soil compaction, X4=soil porosity, X5=plowing depth, etc. We will normalize the data in some reasonable way, for example subtracting the average of the high and low values of each X variable (e.g. pH) from each observation on that variable then dividing these deviations by half the distance between max and min so that each X variable has entries between -1 and 1. We will then consider the sphere consisting of all (X1,X2,…,Xp) points, now on this normalized scale, that are a distance r from the origin. This forms a circle in 2 dimensions, a sphere in 3 dimensions, or what we call a “hypersphere” in 4 or more dimensions. That is our g(X1,X2,…,Xp). Because g is a hypersphere, the set of function values f(X1,X2,…,Xp) restricted to the cases where g(X1,X2,…,Xp)=0 must have a maximum and minimum point. Let’s return to the simple example, the function f(X) = X2 subject to the restriction that (X-1)2 = 4. We have g(X) = (X-1)2-4, and h(X,Y,) = X2-(X-1)2-4). We now have just two derivatives to set to 0, getting 2X-2(X-1) =0 and (X-1)2-4=0. We see that X/(X-1) which is positive for X>1, and negative otherwise. We see that X is -1 or 3. The second derivative of h with respect to X is 2-2 = 2(1- X/(X-1)) = -2/(X-1) which is negative if X>1 and positive if X<1. The second derivative with respect to is (always) 0 and the mixed partial is -2(X-1) which is negative when X>1 and positive otherwise. Thus if X>1 we have a maximum (so X=3) and if X<1 (X=-1) we have a minimum. Again, this is using way too much machinery to solve a simple problem but the machinery still works in more complex problems. Another example: Suppose we want to find the lowest C for which the 45 degree line Y=C-X intersects the curve Y = (X-2)2. The curve gives us our restriction. The quadratic curve has a minimum at X=2 and a value 4 as its intercept. Clearly the line Y=4-X will intersect the curve at X=0 and somewhere else so that line is too high, and the line Y=1-X will not intersect that curve at all so it is too low and thus C is somewhere between 1 and 4. Our LaGrangian expression is h(X,Y,) = C – (Y-(X-2)2) = X+Y – (Y-(X-2)2). Note here again how our intuition suggests that the point of intersection will be where the line Y=C-X is tangent to the curve Y - (X-2)2=0. Our derivatives of h( ) are set to 0 to give Y-(X-2)2 =0 (of course) , 1 – = 0 (because h happens to be linear in Y), and 1 + 2(X-2)=0. Clearly from the Y derivative, =1. From the X derivative, 1+2(X-2)= 2X-3=0 so X=1.5 and thus Y=(1.5-2)2 = 0.25. This means that C=X+Y = 1.75. Notice that the point (X,Y) = (1.5,0.25) is on the curve and on the 45 degree line since Y = 1.75-X is just 0.25=1.75-1.5. As a check, notice that the vertical distance between Y=1.75-X on the line Y = (X-2)2 is, of course, (X-2)2-(1.75-X) which is minimzed at 2(X-2)+1=0 or X=1.5, and is convex up, that is, any movement away from X=1.5 makes the distance bigger. Therefore this is a unique point of contact and, since both curves are differentiable, the line is the tangent line of the curve at that intersection point.