Dynamic clustering of histograms using Wasserstein metric
advertisement

Dynamic clustering of histograms using
Wasserstein metric
Antonio Irpino1 , Rosanna Verde1 , and Yves Lechevallier2
1
2
Facoltá di studi politici e per l’alta formazione europea e mediterranea
Seconda Universitá degli studi di Napoli
Caserta - Italy irpino@unina.it rosanna.verde@unina2.it
INRIA Roquencourt France lechevallier@inria.fr
Summary. In the present paper we present a new distance, based on the Wasserstein metric, to cluster a set of data described by distributions with finite continuous
support (histograms). The proposed distance allows us to define a measure of the
inertia of data with respect a barycenter that satisfies the Huygens theorem. Thus,
this measure is proposed as an allocation function in the dynamic clustering process
because it allows us to optimize the criterion of the minimum within inertia of the
classes with respect to their barycenters. An application to real data is performed
to illustrate the procedure.
Key words: clustering, histogram data, Mallow’s distance, inertia decomposition
1 Introduction
In many real experiences, data are collected and/or represented by frequency distributions. If Y is a numerical and continuous variable, many distinct values yi can
be observed. In these cases, the values are usually grouped in a smaller number H
of consecutive and disjoint bins Ih (groups, classes, intervals, etc.). The frequency
distribution of the variable Y is given considering the number of data values nh
falling in each Ih . The histogram is then the typical graphical representation for the
variable Y.
The interest to analyze data expressed by frequency distributions, as well as by
histograms, is apparent in many fields of research. In particular, we may refer to the
treatment of experimental data that are collected in a range of values, whereas the
measurement instrument gives only approximated (or rounded) values. An example
can be given by sensors for air pollution control located in different zones of an urban
area. The different distributions of measured data about the different levels of air
pollutants across a day, allow us to compare, and then to group into homogeneous
clusters, the different controlled zones.
In a different context of analysis, histograms are the key to understanding digital
images. A digital image is basically a mosaic of square tiles or ”pixels” of uniform
color that are so tiny that the composite image appears uniform and smooth. Instead
870
Antonio Irpino, Rosanna Verde, and Yves Lechevallier
of sorting them by color, they can be sorted into 256 levels of brightness from black
(value 0) to white (value 255) with 254 gray levels in between. The height of each
vertical ”bar” tells you how many pixels there are for that particular brightness level.
In the present paper, we propose to analyze data expressed by distributions as
well as “histograms” of values. The classification of this kind of data can be useful
to discover typologies of phenomena on the basis of the similarity of the frequency
distributions.
Dynamic Clustering (DC) ( [Did71], [DS76]) is proposed as a suitable method
to partition a set of data represented by frequency distributions. We recall that DC
needs to define a proximity function, to assign the individuals to the clusters, and
to choose a way to represent the clusters by means of a description that optimizes
a representation function. Further, the representation of a cluster, called prototype,
is consistent with the description of the clustered elements: i.e., if the data to be
clustered are distributions, then the prototype is also a distribution.
According to the nature of the data, we suggest using a distance based on the
Wassertein metric [GS02]. In section 2, we outline the general schema of DC.
In section 3, after recalling the definition of histogram data we present an extension of the Wassertein distance in order to compare two histogram descriptions.
We also prove that it is possible to define an inertia measure among data that satisfies the Huygens theorem of decomposition of inertia, considering the prototypes as
barycenters. In section 4, we present some results on a climatic dataset. Section 5
reports some concluding remarks.
2 Dynamic clustering algorithm
A proximity measure δ is a non negative function defined on each couple of elements
of the space of descriptions of E, where the closer the individuals are, the lower is
the value assumed by δ. Let E be a set of n data characterized by p continuous
variables Yj (j = 1, . . . , p). The dynamic clustering algorithm looks for the partition
P ∈ PK of E in K classes among all the possible partitions PK , and the vector
L ∈ LK of K prototypes representing the classes in P such that the following ∆
fitting criterion between L and P is minimized:
∆(P ∗ , L∗ ) = M in{∆(P, L) | P ∈ PK , L ∈ LK }.
(1)
Such a criterion is defined as the sum of dissimilarity or distance measures δ(yi , Gk )
of fitting between each element yi belonging to a class Ck ∈ P and the class representation Gk ∈ L:
∆(P, L) =
K
X
X
δ(yi , Gk ).
k=1 yi ∈Ck
A prototype Gk associated with a class Ck is an element of the space of description
of E, and it can be represented, in this context, as a histogram. The algorithm is
initialized by generating K random clusters or, alternatively, K random prototypes.
Generally the criterion ∆(P, L) is based on an additive distance on the p descriptors.
A similar approach has been proposed by [CDL03] in a different context of
analysis.
Dynamic clustering of histograms using Wasserstein metric
871
3 Wasserstein metric for histogram data
Let Y be a continuous variable defined on a finite support S = [y; y], where y and
y are the minimum and maximum values of the domain of Y. The variable Y is
supposed partitioned into a set of contiguous intervals (bins) {I1 , . . . , Ih , . . . , IH },
where Ih = [y h ; y h ). Given N observations on the variable Y, each semi-open interP
val, Ih is associated with a random variable equal to Ψ (Ih ) = N
u=1 Ψyu (Ih ) where
Ψyu (Ih ) = 1 if yu ∈ Ih and 0 otherwise. Thus, it is possible to associate to Ih an
empirical distribution πh = Ψ (Ih )/N .
A histogram of Y is then the graphical representation in which each pair (Ih , πh )
(for h = 1, . . . , H) is represented by a vertical bar, with base interval Ih along the
horizontal axis and the area proportional to πh . Consider E as a set of n empirical
distributions Y(i) (i = 1, . . . , n).
In the case of a histogram description it is possible to assume that S(i) = [y i ; y i ],
h
where yi ∈ R. Considering a set of uniformly dense intervals Ihi = y hi , y hi
that
i. Ili ∩S
Imi = ∅; l 6= m ;
ii.
Isi = [y i ; yi ]
such
s=1,...,ni
the support can also be written as S(i) = {I1i , ..., Iui , ..., Ini i }. In the present paper,
we denote with ψi (y) the (empirical) density function associated with the description
of i and with Ψi (y) its distribution function. It is possible to define the description
of Y(i) as:
Z
Y (i) = {(Iui , πui ) | ∀Iui ∈ S(i); πui =
Z
ψi (y)dy ≥ 0} where
Iui
ψi (y)dy = 1.
S(i)
If F and G are the distribution functions of µ and ν respectively, the Kantorovich
metric is defined by
+∞
Z
Z1
|F (x) − G(x)| dx =
dW (µ, ν) :=
−∞
−1
F (t) − G−1 (t) dt.
0
In particular, we focus our attention on the following distance:
v
u 1
uZ
2
u
dM (Y (i), Y (j)) := t
Ψi−1 (w) − Ψj−1 (w) dw.
(2)
0
It is the well known Mallow’s [Mal72] distance in L2 , derived from the Wasserstein
metric. The main computational drawbacks are related to the invertibility of the
distribution functions. In the following, we show how it can be exactly and efficiently
computed when data are represented by histograms.
Given a histogram description of Y(i) by means of Hi weighted intervals as
follows:
Y (i) = {(I1i , π1i ) , ..., (Iui , πui ) , ..., (IHi i , πHi i )} ,
we define the following quantities wli in order to represent the cumulative weights
associated with the elementary intervals of Y (i):
872
Antonio Irpino, Rosanna Verde, and Yves Lechevallier
(
wli =
P0
l=0
πhi l = 1, . . . , Hi
.
(3)
h=1,...,l
Using (3), and assuming a uniform density for each Ih , we may describe the empirical
distribution function as:
Ψi (y) = wi + y − y li
wli − wl−1i
y li − y li
iff y li ≤ y ≤ y li .
Then, the inverse distribution function is a piecewise function defined as follows:
Ψi−1 (t) = y li +
t − wl−1i y li − y li
wli − wl−1i
wl−1i ≤ t < wli
.
To compute the distance between two histogram descriptions Y(i) and Y(j) we
need to identify a set of uniformly dense intervals to compare on the basis of the
two inverse distribution functions. Let us have the set of the cumulated weights of
the two distributions:
w = w0i , ..., wui , ...., wHi i , w0j , ..., wvi , ...., wHj j .
To compute the distance, we need to sort w without the repetitions. The sorted
values can be represented by the vector
w = [w0 , ..., wl , ...., wm ]
where
w0 = 0
wm = 1
max(Hi , Hj ) ≤ m ≤ (Hi + Hj − 1) .
With the same vector, it is possible to associate a vector of m weights π = [πl ] where
πl = wl − wl−1 . Using this quantity, it is possible to prove that the computation of
the squared distance between the two histogram descriptions is:
d2M (Y (i), Y (j)) :=
w
m Z l
X
2
Ψi−1 (t) − Ψj−1 (t)
dt.
(4)
l=1 w
l−1
Each couple (wl−1 , wl ) allows us to identify two uniformly dense intervals, one for i
and one for j, having respectively the following bounds:
Ili = [Ψi−1 (wl−1 ); Ψi−1 (wl )]
and
Ilj = [Ψj−1 (wl−1 ); Ψj−1 (wl )].
For each interval, it is possible to compute the centers and the radii as follows:
cli = (Ψi−1 (wl ) + Ψi−1 (wl−1 ))/2
rli = (Ψi−1 (wl ) − Ψi−1 (wl−1 ))/2.
Because intervals are uniformly distributed, we may express them as the function of
its center and radius as c + r(2t − 1) for 0 ≤ t ≤ 1. It is possible to rewrite equation
(4) as:
d2M (Y (i), Y (j)) :=
m
X
l=1
Z1
[(cli + rli (2t − 1)) − (clj + rlj (2t − 1))]2 dt
πl
0
Dynamic clustering of histograms using Wasserstein metric
m
X
d2M (Y (i), Y (j)) :=
873
πl (cli − clj )2 +
l=1
1
(rli − rlj )2 .
3
(5)
It is easy to show an extension of the proposed distance to the multivariate case,
i.e. where Y(i) = {Y1 (i), . . . , Yp (i)}. Under the hypotheses that the p variables are
independent, it is possible to express the multivariate version of d2M (Y (i), Y (j)) as
follows:
d2M (Y
p mk
X
X
(i), Y (j)) :=
(k)
πl
(k)
cli
−
k=1 l=1
(k)
clj
2
2 1 (k)
(k)
+
r − rlj
.
3 li
(6)
Equation (6) shows that dM is an Euclidean distance. The theorem of Huygens being
applicable the dynamic clustering algorithm converges.
3.1 Using dM for the dynamic clustering algorithm
Given a set of n histogram data, it is possible to define its “barycenter” as a histogram
itself (the so-called prototype). According to the optimization of a representation
criterion, the prototypal histogram Y(b) can be computed minimizing the following
(sum of distance) function:
f (Y(b)|Y (1), . . . , Y(n)) = f (c1b , r1b , . . . , cmb , rmb ) =
=
n
X
d2 (Y (i), Y (b)) =
i=1
n X
m
X
πj (cji − cjb )2 +
i=1 j=1
1
(rji − rjb )2 .
3
Once fixed m (and so also πm ) equal to the cardinality of the elementary intervals
of the union of the supports of the Y(i)’s, the support of Y(b) can be expressed as
a vector of m couples (cjb , rjb ). The function in (??) reaches a minimum when the
following first order conditions are satisfied:
8
>
<
>
:
∂f
∂cjb
= −2πj
∂f
∂rjb
= − 32 πj
n
P
[(cji − cjb )] = 0
i=1
n
P
[(rji − rjb )] = 0
i=1
for each j = 1, . . . , m. It is easy to prove that function (??) holds a minimum when:
cjb = n−1
n
X
i=1
cji
;
rjb = n−1
n
X
rji .
i=1
The barycenter (prototype) of the n histogram data is then the following:
Y (b) = {([c1b − r1b ; c1b + r1b ], π1 ); . . . ; ([cjb − rjb ; cjb + rjb ], πj ); . . . ;
; . . . ; ([cmb − rmb ; cmb + rmb ], πm )}.
(7)
The identification of a barycenter permits us to show a second property of the
proposed distance. We prove that it is possible to express a measure of inertia of
data using d2M . The total inertia with respect to the barycenter Y(b) of a set of n
histogram data is given by the following quantity:
874
Antonio Irpino, Rosanna Verde, and Yves Lechevallier
n
X
TI =
d2M (Y(i), Y(b)).
i=1
The total inertia can be decomposed into within and between clusters inertia, according to the Huygens theorem. Let us consider a partition of E into K clusters. For
each cluster Ck , k = 1, .., K a histogram barycenter denoted by Y(bk ) is computed
by a local optimization of (??). Minimizing the following function:
f (Y(b)|Y(b1 ), . . . , Y(bK )) = f (c1b1 , r1b1 , . . . , cmbK , rmbK ) =
=
K
P
k=1
|Ck | 2
d (Y(bk ), Y(b))
n
K
P
=
k=1
|Ck |
n
m
P
j=1
πj (cjbk − cjb )2 +
1
3
(rjbk − rjb )2
(8)
where |Ck | is the cardinality of cluster Ck , it is possible to prove that the problem
(??) and (8) have the same solution for Y(b). The last result permits us to obtain
a decomposition of the total inertia3 as follows:
T I = W I + BI =
=
K
P
P
d2M (Y(i), Y(bk )) +
k=1 i∈Ck
K
P
|Ck |d2M (Y(bk ), Y(b)).
(9)
k=1
4 Application
In this section, we present some results of an analysis performed on a climatic
dataset. The original dataset drd964x.tmpst.txt4 contains the sequential “Time
Biased Corrected” state climatic division monthly Average Temperatures recorded
in the 48 states of the US from 1895 to 2004 (Hawaii and Alaska are not present in
the dataset).
The analysis consisted of the following three steps:
1. We have represented the data as the distributions of the monthly temperatures
of each of the 48 states.
2. We have performed 100 dynamic clustering for k = 2...9.
3. For each solution, in order to evaluate the quality of the results we have computed a quality of partition index as the proportion of between inertia on the
total inertia:
QP I = BI/T I.
In Table 1 are the elementary statistics for the 900 runs of the algorithm. To detect
a good choice for the number of clusters, we computed the Calinski and Harabasz
index [CH74] that is defined as:
CH(k) =
BI(k)/(k − 1)
W I(k)/(n − k)
where k denotes the number of clusters, and BI(k) and W I(k) denote the between
and within cluster inertia, in order to identify an optimal number of clusters. It is
defined as a value of k that maximizes CH(k). The results suggest that an optimal
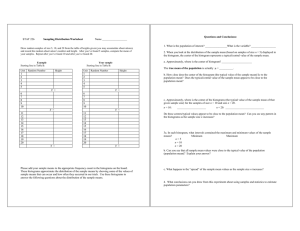
choice for k is 5. In fig. 1, the 48 states are grouped into 5 groups.
3
For the sake of brevity, we do not report here the proof.
freely available at the National Climatic Data Center website of the US
http://www1.ncdc.noaa.gov/pub/data/cirs/
4
Dynamic clustering of histograms using Wasserstein metric
875
Table 1. Dynamic clustering main results: the first 5 columns describe elementary
statistics about the QPI, the last one the best Calinski-Harabasz index
k
2
3
4
5
6
7
8
9
10
QPI min
0.6482
0.8069
0.8449
0.8494
0.8665
0.8577
0.8835
0.9028
0.8917
QPI max
0.6555
0.8190
0.8666
0.8924
0.9086
0.9144
0.9233
0.9350
0.9360
QPI mean
0.6527
0.8125
0.8528
0.8663
0.8847
0.9000
0.9121
0.9174
0.9208
QPI median
0.6527
0.8124
0.8522
0.8646
0.8811
0.9044
0.9135
0.9168
0.9202
QPI std dev
0.0014
0.0029
0.0044
0.0080
0.0115
0.0126
0.0070
0.0048
0.0061
Best CH
44.07
70.94
72.02
77.65
75.05
69.63
70.70
64.05
60.81
Fig. 1. The 48 states grouped into 5 clusters
5 Conclusions
In this paper we have presented a new distance for clustering data represented
by histograms. The main interesting property of the proposed distance is that it
is possible to compute it also when two distributions have different bins, whereas
commonly used distances or dissimilarities, such as the L2 norm or the Kullback
Leibner divergence, compare two distributions with identical bins. This means, for
example, that it is possible to compare two descriptions of the same phenomenon
measured by two sensors that use different scales (a US meter is scaled in inches,
whereas an Italian one is scaled in centimeters). The algorithm SOM of Kohonen
can be also used because dM is a Euclidean distance thus derivable. The proposed
distance has been also proposed by [IV05] in the context of interval data analysis.
References
[CH74] Calinski, R.B. and Harabasz, J. (1974): A dendrite method for cluster analysis, Communications in Statistics, 3, 1–27.
876
Antonio Irpino, Rosanna Verde, and Yves Lechevallier
[CDL03] Chavent, M., De Carvalho, F.A.T., Lechevallier, Y., and Verde, R. (2003):
Trois nouvelles méthodes de classification automatique des données symbolique de type intervalle, Revue de Statistique Appliquée, LI, 4, 5–29.
[DS76] Diday, E., and Simon, J.C. (1976): Clustering analysis, In: Fu, K.S.
(Eds.),Digital Pattern Recognition, 47–94, Springer Verlag, Heidelberg.
[Did71] Diday, E. (1971): Le méthode des nuées dynamique, Revue de Statistique
Appliquée, 19, 2, 19–34.
[GS02] Gibbs, A.L. and Su, F.E. (2002): On choosing and bounding probability
metrics, International Statistical Review, 70, 419.
[IV05] Irpino, A. and Verde, R.(2005): A New Distance for Symbolic Data Clustering, CLADAG 2005, Book of short papers, MUP, 393-396.
[Mal72] Mallows, C. L. (1972): A note on asymptotic joint normality. Annals of
Mathematical Statistics, 43(2),508-515.