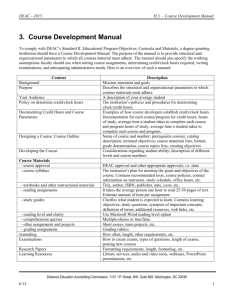
Modeling linguistic variation TechXploration Wake Forest University using machine learning, R,
advertisement

Modeling linguistic variation TechXploration Wake Forest University using machine learning, R, and the WFU DEAC cluster Dr. Jerid Francom, Department of Romance Languages Dr. Damian Valles, Information Systems Humanities & Big Data lat 0 100 Serial processing bottleneck www.PosterPresentations.com Working with the DEAC team, I learned about strategies to overcome the processing bottleneck sending portions of the computational task to multiple cores on a single workstation (PC) or to multiple stations’ CPUs in a cluster. Not all tasks benefit from parallel computation. Parallel processing advantage MBA (64 bit) Performance for Naive Bayes Text Classification DEAC (64 bit) Performance for Naive Bayes Text Classification Elapsed time (mins) 25 20 15 10 5 0 Using R packages doMC, doParallel, and Rmpi I wrote my own NB classifier which implemented parallel processing. Step create_model 15 00 0 14 00 0 13 00 0 12 00 0 11 00 0 00 10 00 0 00 90 00 80 00 70 00 60 00 50 00 40 00 30 20 10 00 15 00 0 14 00 0 13 00 0 12 00 0 11 00 0 00 10 00 0 00 90 00 80 00 70 00 60 00 50 00 40 00 0 Sample size (tweets) Sample size (tweets) create_splits test_model Parallel computing Step Elapsed time (secs) create_model test_model_mc Standard 'tuning' of these parameters was performed in order to improve performance and classification accuracy (i.e. removing common and/ or sparse terms, 3 2 by increasing the chances that the most relevant features are reflected in the model, and, in turn, reducing/ eliminating those features that may blur correct generalizations). Baseline 42.72 1 Run times were improved in the 15k set and a 1+ million Tweet classification model was trained in just over an hour. 0 4 8 12 16 Cores DEAC (64 bit) on 15k 4 Elapsed time (secs) create_splits Model improvement DEAC (64 bit) on ‘GLM‘ task 4 1 0.0 0.2 0.4 0.6 0.8 Elapsed time (mins) 3 Step create_splits 2 create_model test_model_mc DEAC (64 bit) on 1 million Baseline 42.72 1 1 0 20 40 60 Elapsed time (mins) 0 Step Recent applications Asked various native Speakers to watch a video and then send a brief narrative of the events in the video A comparable corpus based on 430 TV/ film transcripts from Argentina, Mexico, and Spain. 3.9+ million total word tokens. 4 8 12 create_splits create_model test_model_mc Overall test accuracy 72% using 1+ million Tweet model 16 Workstations Llega un morrito puberto a la casa de su supuesta novia o cita. Lo recibe un señor que es el papá de la chica. Se ve que es una familia fresa. El chico va vestido de traje y lleva un ramo de flores para ella. El don se porta amable y le empieza a ofrecer un condón, una pachita y un gallo. El chico no quiere esas cosas porque lo comprometen y está sacadísimo de onda, no sabe qué hacer. El pobre acepta todo porque se siente comprometido y probablemente piensa "el ruco es buena onda". Baja la chica toda guapa y se saludan. El papá empieza a actuar diferente y le va sacando todas las cosas que le ofreció al chico para hacerlo quedar mal. Al final el pobre chico queda como el pirata y el papá queda como el bueno. La chica se enoja con el papá. Scores Argentina 32.4 Mexico 36.5 Spain 31.1 ✓ ● 80 ● 60 ● 40 ● ● ● ● ● 20 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 corpus ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Words RESEARCH POSTER PRESENTATION DESIGN © 2012 Parallel computing long Task The goal of this task is to use status posts acquired through the Twitter (API) to develop a text classification model capable of recognizing and classifying tweets/ and related language as associated with one of three countries (Argentina, Mexico, and Spain). The accuracy of the classifier depends on a few things: 1) the language from each of the countries should show sufficiently different distributional patterns, 2) there should be sufficient data at model training time to provide robust estimates for each of the classes (countries in this case) and 3) the model should be tuned correctly to provide the most efficient algorithm to detect any potentially indicative information useful for making accurate predictions. (2) Parallel approach: custom functions infused with code to implement doMC/doParallel parallel processing 200 50+ million Tweets collected via Twitter API in Jan/ Feb 2014 over 3 weeks Conditional probability My interest has been to approach the documentation and research of language variation through access to emerging data sources on the web (TV/film transcripts, onlinenewspapers, and other data repositories). A recent interest of mine is to mine the social media network Twitter for information about what is common and unique about varieties of the Spanish language, in particular the political entities: Mexico, Argentina, and Spain. Knowledge of this sort is valuable in research into dialect variation and can aid students of Spanish to gain a better appreciate of the common and unique characteristics of regional varieties. −100 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Argentina ● Mexico ● Spain ● ● ● ● ● ● ● ● ● ● ● ● ac e a pta amctua ab r b le bu aja buena en ca o ch sa ic co m chi a c pr om c o ita co etid nd o ó c di os n fe a re s n em d te pi on e en za fa oja m il fi ia flo nal r gaes gu llo a h p ha acea ce r r lle lo g lle a v ma n a of ovi l re a c of e re r c on ió p da pi apá en pi sa r pr a ob po ta ab p bre le or m ta e qu nte e qu d e a qu da ie r ra re re mo ci b sa sa e c b sa ande lu o d se an si ñor en to te to da da tra s je va ve v st e id o Language variation Out-of-the box e1071 R package’s naiveBayes() algorithm and base predict() showed infeasible processing times for the 10+ million words to be processed. (1) Serial approach: e1071 and base functions −50 30 ✓ pilot various computing implementations on a text classification task involving millions of Twitter status posts for an ongoing study of Spanish language variation. Naive Bayes Text Classification: a robust machine learning algorithm providing language models that can be explored (unlike some other algorithms Support Vector Machines). 00 ✓ support research, development, and documentation of high-performance computing strategies to process 'big data' resources for applications in the Humanities at WFU. 0 20 STEP 2014 funds were awarded to: Memory management/ performance can be problematic for larger data processing tasks. where words wi, …, wn are used as features and countries are classes c ∈ C. The probability P of a sequence of words predicts a class is estimated by calculating the prior probability P(̂ c) of a country being the source of any given tweet and then calculating the individual conditional probabilities that a word is associated with a given country P(̂ wi|c). 50 Elapsed time (mins) Goals R & text classification R: a free and open source software with a comprehensive package library and an active development community. Naive Bayes Text Classification WorldTweets 2014 Corpus 10 'Big data is a problem in the Humanities. Given the promise of increasing amounts of data in electronic form it would sound counter-intuitive; clearly more data is better. Yet the leaps in the size of data have outpaced the power to process such data on the typical PC. Industry and computationallyminded sectors of higher-education have long turned to high-performance computing to take advantage of these information-rich resources, and have done so with much success. But high-performance computing not a household term in the Humanities in large part due to lacking faculty access to and knowledge of computing resources and programming strategies. Spring 2015 Results ✓ 8 cores on the DEAC workstation was the optimal configuration showing major gains: from 47 to 5.5 minutes on 15k tweets. ✓ After model tuning, 1+ million tweets were processed in just over 1 hour. Upshot Processing increasingly large amounts of textual data can be difficult using traditional, single PC work environments. Typical alternatives employed such as increased CPU power and RAM size can proceed without adjustment to programming routines. However, in some cases these two strategies are not effective to overcome computational requirements. From the tests conducted in this report in R, parallel alternatives can be effectively employed on iterative tasks quite simply with doMC or doParallel packages by interjecting for-loop like code. Findings here pave the way for other scholars on campus with computational tasks that prove too unwieldy for standard PCs. The DEAC environment is now equipped and knowledgeable about how to implement parallelization in R, this will help scholars varying in programming backgrounds access high-performance computing resources more easily and effectively. References Manning, CD, P Raghavan, and H Schütze. 2008. Introduction to information retrieval. Cambridge University Press.