Introduction to Relational Database Design Introduction
advertisement

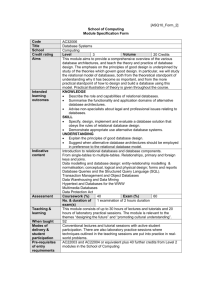
Introduction to Relational Database Design Introduction During the last months, I had great fun presenting a series of articles about the mSQL database and using it to introduce the reader to Web and Java database programming. The feedback I received from you was amazing and inspiring, thanks a lot! So far the articles were about "how to start". We had many examples that I tried to make as close to real and useful applications as I could. But, to create real-world applications, you need more knowledge than simply programming practices. A topic of great importance is to understand how to make a proper design of relational databases. There's been a great hype about "true" Object Data Bases and the hybrid "ObjectRelational" ones. Object databases are not so new. There are many mature products with years on the market but "the big ones" are just now trying to incorporate some of their features. Actually I guess we will stick with Relational Databases for a long time to come, despite all the hype regarding Object Databases. The Relational model is not only very mature, but it has developed a strong knowledge on how to make a relational back-end fast and reliable, and how to exploit different technologies such as massive SMP, Optical jukeboxes, clustering and etc. Object databases are nowhere near to this, and I do not expect then to get there in the short or medium term. The reason for my belief is that Relational Databases have a very well-known and proven underlying mathematical theory, a simple one (the set theory) that makes possible automatic cost-based query optimization, schema generation from high-level models and many other features that are now vital for mission-critical Information Systems development and operations. Maybe the pure Object Databases will never reach these capabilities of Relational Databases. The Object paradigm is already proven for application design and development, but it may simply not be an adequate paradigm for the data store. I think so because a true Object Database is general graph. The graph theory plays a great role on computer science, but is also a great source of unbeatable problems, the NP-complex class: problems for which there are no computationally efficient solution, as there's no way to escape from exponential complexity. This is not a current technological limit. It's a limit inherent to the problem domain. Hybrid Object-Relational databases will probably be the long term solution for the industry. They put a thin object layer above the relational structure, thus providing a syntax and semantics closer to the object oriented design and programming tools. They simply make it easier to build the data layer classes (see my previous articles about Java Servlets and Java GUI applications using mSQL). This article will teach the basis of Relational Database Design, so the readers can make more ambitious projects using mSQL or any other Relational Database under OS/2. I'll provide samples to run under mSQL and SQL Anywhere, but I'll not teach the basis of SQL. Anyway, I hope by the examples you'll get a nice understanding on the subject. If you want to get a deeper understanding on the subject, I recommend the book "An Introduction to Database Systems" by C. J. Date. What is a Relational Database? A relational database stores all its data inside tables, and nothing more. All operations on data are done on the tables themselves or produces another tables as the result. You never see anything except for tables. A table is a set of rows and columns. This is very important, because a set does not have any predefined sort order for its elements. Each row is a set of columns with only one value for each. All rows from the same table have the same set of columns, although some columns may have NULL values, i.e. the values for that rows was not initialized. Note that a NULL value for a string column is different from an empty string. You should think about a NULL value as an "unknown" value. The rows from a relational table is analogous to a record, and the columns to a field. Here's an example of a table and the SQL statement that creates the table: CREATE TABLE ADDR_BOOK ( NAME char(30), COMPANY char(20), E_MAIL char (25) ) +-------------------+---------------+-----------------------+ | NAME | COMPANY | E_MAIL | +===================+===============+=======================+ | Fernando Lozano | EDM2 | fsl@centroin.com.br | +-------------------+---------------+-----------------------+ | Bill Gates | Micro$oft | bill@microsoft.com | +-------------------+---------------+-----------------------+ [note for mSQL users: you do need to add a "\g" to the end of each statement so it gets executed] [note for SQL Anywhere users: you can execute many statements at one, just use a ";" as the statement separator] There are two basic operations you can perform on a relational table. The first one is retrieving a subset of its columns. The second is retrieving a subset of its rows. Here are samples of the two operations: SELECT NAME, E_MAIL FROM ADDR_BOOK +-------------------+-----------------------+ | NAME | E_MAIL | +===================+=======================+ | Fernando Lozano | fsl@centroin.com.br | +-------------------+-----------------------+ | Bill Gates | bill@microsoft.com | +-------------------+-----------------------+ SELECT * FROM ADDR_BOOK WHERE COMPANY = 'EDM2' +-------------------+---------------+-----------------------+ | NAME | COMPANY | E_MAIL | +===================+===============+=======================+ | Fernando Lozano | EDM2 | fsl@centroin.com.br | +-------------------+---------------+-----------------------+ You can also combine these two operations, as in: SELECT NAME, E_MAIL FROM ADDR_BOOK WHERE COMPANY = 'EDM2' +-------------------+-----------------------+ | NAME | E_MAIL | +===================+=======================+ | Fernando Lozano | fsl@centroin.com.br | +-------------------+-----------------------+ You can also perform operations between two tables, treating then as sets: you can make cartesian product of the tables, you can get the intersection between two tables, you can add one table to another and so on. Later we'll present more details about these operations and how then can be useful. Relational Databases versus Database Servers Not all databases are relational, and not all relational databases are built on the client/server paradigm. But most of the time you'll want a relational database server, so it's important to clarify the distinction. Remember: a relational database manipulates only tables and the result of all operations are also tables. The tables are sets, which are themselves sets of rows and columns. You can view the database itself as a set of tables. So a DBF file is not a relational database. You do not manipulate a DBF table as a set (you are always following an index) and you do not perform operation on tables that yield other tables as the result (you are just looping through records from one or more tables, even when you use the "SET RELATION" dBase statement). Most database file formats are not relational databases. Even the BTrieve server NLM is *not* a relational database, because you do not operate on sets tables or sets of tables. Conversely, a MDB file (from MS Access) is a relational database. Although you can open and manipulate a MDB file just like a DBF file, navigating through records and index, you can also perform all operations through a relational view of the database and using SQL statements. Actually, most non-relational databases are based on some "navigational" model: an hierarchy, a linked list, a B-Tree, etc. It's common to refer to these as ISAM (Indexed Sequential Access Method) Databases. Now let's see what is a database server: it's a specialized process that manages the database itself. The applications are clients to the database server and they never manipulates the database directly, but only make requests for the server to perform these operations. This allows the server to add many sophisticated features, such as transaction processing, recovery, backup, access control and etc without increasing the complexity of every application. The server also reduces the risk of data file corruption, if only because only the server writes to the database (a crash on any client machine will not leave unflushed buffers). A nice database server also takes advantage of the client/server architecture to lower network usage. If you open a DBF or MDB file stored on a file server you need to retrieve every record just to filter out which ones you really need. But if you connect to a database server, it filters out the unneeded records and send to the client only the data that really matters. Access is a relational database but it is not a database server. mSQL, SQL Anywhere, DB2, Oracle are both relational databases and database servers. The Btrieve NLM is a database server but it is not a relational database. Relationships and Joins Most set operations between tables are interesting but of limited use. After all, they will work as expected only when the tables have the same set of columns. The fun begins when you operate on tables that do NOT have the same set of columns. For example, see the table COMPANY: +---------------+---------------------------+ | NAME | URL | +===============+===========================+ | EDM2 | http://www.edm2.com | +---------------+---------------------------+ | Micro$oft | http://www.microsoft.com | +---------------+---------------------------+ You want to establish a relationship between the tables COMPANY and ADDR_BOOK we've seen before. These tables have a common column, the name of the company. Even if each table has its own name for the column, we see that the data stored and its meaning is the same on both tables. So we could use this relationship to get a URL for each person on ADDR_BOOK. Here's the SQL statement: SELECT ADDR_BOOK.NAME, COMPANY.URL FROM ADDR_BOOK, COMPANY WHERE ADDR_BOOK.COMPANY = COMPANY.NAME +-------------------+---------------------------+ | NAME | URL | +===================+===========================+ | Fernando Lozano | http://www.edm2.com | +-------------------+---------------------------+ | Bill Gates | http://www.microsoft.com | +-------------------+---------------------------+ Maybe this example was not so useful, but the simple idea of establishing relationships between tables though column values is the basis of most commercial information systems today. This operation, matching rows from one table to another using one or more column value, is called a "join", more specifically an "inner join". Let's go on. Imagine an order form from your preferred on-line shop site. The order itself has the name of the customer, the address of delivery and payment information. Besides, each order has one or more items which the customer has ordered and will be delivered together. We could have the tables: CREATE TABLE ORDER ( ORDER_NO INTEGER, DATE_ENTERED DATE, FIRST_NAME CHAR(30), LAST_NAME CHAR(30), ADDRESS CHAR(50), CITY CHAR(30), ZIP_CODE CHAR(9), COUNTRY CHAR(20) ) CREATE TABLE ORDER_ITEMS ( ORDER_NO INTEGER, ITEM_NO INTEGER, PRODUCT CHAR(30), QUANTITY INTEGER, UNIT_PRICE MONEY ) [Note for SQL Anywhere users: you'll generally use the data type VARCHAR instead of CHAR. On most databases, CHAR appends spaces to fill the column length, but VARCHAR does not] And to list all items from a particular order, say order no. 12345: SELECT * FROM ORDER_ITEMS WHERE ORDER_NO = 12345 So we have two tables, ORDER and ORDER_NO and a relationship between these two tables on field ORDER_NO. The field ITEM_NO allows us to identify each item form the same order. But maybe your preferred site allows you to register so you do not have to retype the delivery address each time you shop. This lead us to a third table, CUSTOMER, and a relationship between ORDER and CUSTOMER. CREATE TABLE CUSTOMER ( CUST_NO INTEGER, FIRST_NAME CHAR(30), LAST_NAME CHAR(30), ADDRESS CHAR(50), CITY CHAR(30), ZIP_CODE CHAR(9), COUNTRY CHAR(20) ) CREATE TABLE ORDER ( ORDER_NO INTEGER, DATE_ENTERED DATE, CUST_NO INTEGER ) And to print the mailing label for each order, you'd use the following query: SELECT ORDER.ORDER_NO, CUSTOMER.NAME, CUSTOMER.ADDRESS, CUSTOMER.CITY, CUSTOMER.ZIP_CIDE, CUSTOMER.COUNTRY FROM ORDER, CUSTOMER WHERE ORDER.CUST_NO = CUSTOMER.CUST_NO Note that a join need not match one row to only one other row. It can match one row to a set of row from other table, as long as all rows match the join condition. Some customers may have no order on the database (eg, their older orders where moved to an "historic" database). These customers will not show on the previous query, because they would not match the join condition. Well, it's unlikely you'll ever list labels for all orders, but maybe you want the mailing labels for all orders entered at November, 20. This shows that a join operation can be combined with other restrictions: SELECT ORDER.ORDER_NO, CUSTOMER.NAME, CUSTOMER.ADDRESS, CUSTOMER.CITY, CUSTOMER.ZIP_CIDE, CUSTOMER.COUNTRY FROM ORDER, CUSTOMER WHERE ORDER.CUST_NO = CUSTOMER.CUST_NO AND ORDER.DATE_ENTERED = '1998-20-11' [Note for mSQL users: you should enter a date value as 'DD-Mon-YYYY', for example '20-Nov-1971'] Some databases may have different syntax for date values, so check your product documentation if this query does not works as expected. We could continue growing our database as we refine our application. You'd probably have a PRODUCTS table, a SHIPING table for the shipping methods and costs, and so on. But before we go to another topic, let's see another example on how powerful relationships can be. Take your favorite web software archive. It probably has many categories on which each package is cataloged. These categories generally have sub categories, such as "Internet/browsers" or "Applications/Graphics/Converters". Such an hierarchical structure is easily implemented as a self-relationship: CREATE TABLE CATEGORY ( ID INTEGER, NAME CHAR(30), PARENT INTEGER ) The table CATEGORY has a relationship with itself using the fields PARENT and ID. For example: +-------+---------------+-----------+ | ID | NAME | PARENT | +=======+===============+===========+ | 1 | Internet | NULL | +-------+---------------+-----------+ | 2 | Browsers | 1 | +-------+---------------+-----------+ | 3 | Applications | NULL | +-------+---------------+-----------+ | 4 | Graphics | 3 | +-------+---------------+-----------+ | 5 | Converters | 4 | +-------+---------------+-----------+ Note the use of a NULL value when the Category has no parent (it's a root category). This is generally better than use a special value such as zero or -1 because NULL will never be a valid value whatever the data type of the column. The application that browses through the software archive will start listing all rows at the root level: SELECT ID, NAME from CATEGORY WHERE PARENT = NULL And, when the user selects a category to enter (or expand) the application would list all subcategories from the selected one, say "Applications": SELECT ID, NAME from CATEGORY WHERE PARENT = 3 The SELECT statement from the SQL language is very powerful. We have seen only the tip of the iceberg. Many books have been written only about SQL syntax and capabilities, and a deeper exploration on the subject would miss the focus of this article. For example, you can sort the result, compute sums, means and other statistic functions, group the data by one or more column values and perform "outer joins". Please visit The mSQL PC Homepage (http://www.blnet.com/msqlpc) to get links for more information about the SQL query language. Primary and Foreign Keys Each time you have data inside a relational table, you need a way to identify each row stored into that table. For example, say Fernando Lozano has changed his e-mail address. How do I know the right row to update? Given the table ADDR_BOOK we've already been presented, I'd say: UPDATE ADDR_BOOK SET E_MAIL = lozano@blnet.com WHERE NAME = 'Fernando Lozano' So the column NAME identifies each row from ADDR_BOOK. Then, NAME is said to be the primary key from table ADDR_BOOK. Well, name is not a good primary key. There's a possibility you'll have another person named 'Fernando Lozano'. Once I was searching through AltaVista and found more than a dozen personal home pages for 'Fernando Lozano', and none were mine! Besides, a woman can change her name when she marries. This leads to what constitutes a nice primary key: It should uniquely identify every possible data for the table, and it's value should not change over time. Sometimes the data you want to store already has one or more columns suitable to be the primary key. If you have the social security number of your employees, this can be the primary key for table EMPLOYEE. You can have a composite primary key. For example, my software archive may have many versions of Netscape Communicator, but only one version 4.04 (I'd not have duplicate copies of any software on my archive). So the primary key for table SOFTWARE could be (NAME, VERSION). Maybe I'd add the field LANGUAGE if my archive contains both English, Portuguese and Germany versions of Communicator. Even if you have a set of columns that meet the requirements for a primary key, you may want to create a "syntethic" primary key. Computers take much more time comparing strings than integers. Shorter strings are much faster than long ones. A long string may lead to typing mistakes. Comparing two or three columns when searching for a record is slower than searching for only one columns. This way we end up with fields like CUST_NO and ORDER_NO. Another reason to create a syntethic primary key is the use of its value as a foreign key by another tables. Remember our order entry system: table ORDER_ITEM has a column named ORDER_NO that identifies the order that contains each item. ORDER_NO is a foreign key for table ORDER_ITEM. Some databases have an auto-increment data type to be used for syntethic primary keys. Other let you explicitly define a "sequence" as a stand alone entity or associated to a specific table. I prefer the sequences as they provide more control when importing/exporting data and make easier to insert related rows into other tables. When the primary key of a table is too long a string or composite by many columns, other related tables may spend more space storing its foreign keys than the actual data they were designed to store. For example, a software database may have a table SOFTWARE with columns SOFT_NAME, VERSION_NAME, VERSION_NO, BUILD_NO, PLATFORM, LANGUAGE, RELEASE_DATE, SUPPLIER, SIZE_BYTES, DESCRIPTION and many other columns so you can build a nice software archive or a bug tracking database. The six first fields uniquely identifies every software. You need all them. Think about Netscape Communicator Professional 4.04 for OS/2 Brasilian Portuguese. Its key would be ( 'Communicator', 'Professional', '4.04', '1.0', 'OS/2', 'PT_BR' ). The '1.0' is needed so you know this is not one of the beta releases nor a bug fix for 4.04. Our database may register many locations, or copies, for this software: an FTP site, a CDROM media, a ZIP drive, and so on. I want to keep track of all copies so I can quickly find one when I need and I can also release storage from obsolete software. I'd have a table COPIES which has a many-to-one relationship with SOFTWARE, that is, one SOFTWARE has one or more COPIES. This means every row from COPIES must store the value of the primary key of a row from SOFTWARE, all six columns. That's too much data for such a simple thing! A syntethic primary key will make our design easier to understand, easier to program and faster for the computer. The table COPIES would need only one column for its foreign key. Some people may even tell you to always create syntethic keys for all tables. I'll not go so far, but use common sense when choosing the primary keys and foreign keys for your tables. Referential Integrity As we have already seen, the foreign keys implement relationships. Some databases allow you to explicitly define your primary key and foreign keys. You could write: CREATE TABLE CUSTOMER ( CUST_NO INTEGER PRIMARY KEY, FIRST_NAME CHAR(30), LAST_NAME CHAR(30), ADDRESS CHAR(50), CITY CHAR(30), ZIP_CODE CHAR(9), COUNTRY CHAR(20) ) CREATE TABLE ORDER ( ORDER_NO INTEGER PRIMARY KEY, DATE_ENTERED DATE, CUST_NO INTEGER REFERENCES CUSTOMER (CUST_NO) ) [Note for mSQL users: this example will not work in mSQL] This is fine when none of your keys is composite. But if you have a composite key, you'll to define your keys outside your table definition: CREATE TABLE ORDER_ITEMS ( ORDER_NO INTEGER, ITEM_NO INTEGER, PRODUCT CHAR(30), QUANTITY INTEGER, UNIT_PRICE MONEY ) ALTER TABLE ORDER_ITEMS ADD PRIMARY KEY PK_ORDER_ITEMS (ORDER_NO, ITEM_NO) ALTER TABLE ORDER_ITEMS ADD FOREIGN KEY FK_ORDER_ITEMS_1 (ORDER_NO) REFERENCES ORDER (ORDER_NO) [Note for mSQL users: this example will not work in mSQL] The smaller databases does not support the explicit definition of primary and foreign keys. The primary key can be emulated by defining a unique index on the primary key: CREATE UNIQUE INDEX PK_ORDER_ITEMS ON ORDER_ITEMS (ORDER_NO, ITEM_NO) [Note for mSQL users: this example WILL work :-) mSQL does not implement explicit primary and foreign keys, but it does implement INDEXes and SEQUENCES] Some databases do not implement the explicit definition of foreign keys but allow you to define Triggers to enforce referential integrity and then emulate the explicit foreign keys. As trigger definition is very database specific, we will not deep into details here. You may be wondering why I do want to define my keys. As we seen in previous examples, I do not need these definitions to use the relationships. The answer is that most databases are used by more than one application. Each application needs to have its own logic to ensure that the primary key will get a unique value, and to ensure that any foreign key will actually get a value that exists on the referenced table. There are more checks for the applications to do: if you delete an order, you have to delete all its items. And if I try to delete a customer who has pending orders? The user should not be able to do this. Replicating this logic to many applications is very error-prone. Worse yet, the users may be using stand alone query and reporting tools to update the database, and then will be able to circumvent the protective logic built into the applications. If you have explicit defined keys, or some way to emulate then, the database server itself will enforce integrity rules and won't let the user create lost references from one table to another, or duplicate a primary key value. Better yet, query and reporting tools can use the information on the database about foreign keys to help the user build his or her queries. The Three Normal Forms As with anything regarding computers, there's more than one way to design a relational database for a given application. Many of then may work nice, but some may have a negative impact on the long-time suitability of your application for your needs. A nice guide on how to design relational databases that leads to simpler (to implement) applications and to more maintainable systems is the set of rules that define the three normal forms: 1. All column values are atomic 2. All column values depends on the value of the primary key 3. No column value depends on the value of any other column except the primary key. We have instinctively applied these rules on our order entry example. We started with a table that had columns for Address, ZIP code, country and so on. I could easily have just one or two strings to fit the mailing label. But then I'd have non atomic values. What if later I had to use only the State or Country information to calculate shipping costs? I'd have to deal with substring functions or I'd have to change my tables (and consequently the applications that use then, besides converting all data from the old format to the new one). So, to conform with the first rule you split "big" columns into "smaller" ones. Our first design for the order entry database had a table with both the customer and order data. Part of the columns depends on the customer name, and the rest on the order no. While this may appear to represent no harm, it won't allow us to ease the life of our customer when he comes back, and will also make it more expensive to retrieve demographic information about our customers. To conform with the second rule, we split one table into two (or more) distinct tables, and get the benefit of lower storage requirements. The third rule is a little more difficult to demonstrate. Suppose we had included an ORDER_VALUE column on the ORDER table, or an ITEM_VALUE on the ORDER_ITEMS table. Although these columns are unique to each row from the respective table, they do not depends solely on the primary key: they depends on the value of columns for rows from another table (ORDER_VALUE) or the values of other columns on the same row (ITEM_VALUE). While these fields may seen to help, alleviating the reports from the duty of multiplying and adding values, they may actually hurt performance: what if the quantity of some item changes? You'd have to update not only the changed column, but also all it's dependent columns. So, although there are more subtle cases on which you have to apply the third rule, a simple explanation would be "having no calculated values". Please keep in mind that these rules are not The Only Truth. Do not forget to use common sense. For example, you do not have to split a date into Year, Month and Day fields just because you may want a report summarizing the monthly or yearly income. When you have applied the three rules, you say the database is on the Third Normal Form (3NF), or simply it is "normalized". A normalized database generally improves performance, lowers storage requirements, and makes it easier to change the application to add new features. Remember, most software projects change it's requirements during it's development, so the time spend normalizing a database will actually mean less development time. Some specialized databases are explicitly built violating the three rules. They are "denormalized" databases, and its use makes sense when you'll change the data infrequently, but you'll all the time be generating reports against a big data set. These databases are generally tied to decision-support systems and DatawareHouses, and we won't cover these here. Domain Tables Every time you have a column whose value most come from a known set of values you have a "domain" for that column. Your domain may be as simple as the day of the week (SUN, MON, THU .. SAT or 0, 1, 2 .. 6), as long as the Country Names or as unknown as the Books From The Catalog. Sometimes you'll already have the need for a table representing these domain (a book as also an author, ISBN, publisher and etc) but sometimes the need for a table may not be so apparent. If you just let your users type the country name, they can type "BRAZIL", "Brazil", "brazil" or "Brasil" (which is the name we Brasilians use for our country). Sometimes you can just force all input to upper or lower case, but most of the time you'll still be the subject of typing mistakes. Domain tables solve this problem, by associating any ID (or code) to a name or description. The user will choose (or see on reports) the name/description, but the database tables will store the code. You get also the benefits of faster queries, faster sorting (smaller strings, integers instead of strings, and so on), lower storage and ease of localization (do not need to change the code, just the table from which you get the descriptions). The Use of Indexes Conceptually, the relational model is very simple: a set of tables that you operate into and get another set of tables as the result. But if you think that scanning tables should be very inefficient, you are right. During the early days of relational databases, many people said they were too slow to any practical use. At that time people were used to navigating though ISAM files or some linked structure such as IMS. Today relational databases employ a series of techniques to improve performance, and most are based on the use of indexes. The most common type of index is the B-Tree and variants, the same used by DBF files. Some databases may use hash tables, bitmaps and other data structures. But the common point is that the index can speed the search for a particular row or the sorting of a set of rows. But simply creating one or more indexes may not help performance, actually indexes can degrade performance when not used the right way. An index means more writes to the disk and a bigger log for databases that implements transactions (also called "logical units of work"). Most databases have some kind of query optimizer that choose the best path to get the data that satisfies a given query. The query optimizer may not use any index at all, if it thinks it will be necessary to scan most of the table. An index may speed up considerably joins, ORDER BY and GROUP BY clauses from a SELECT statement. It may also speed up many queries, if some conditions match the columns and sort order of the index. When you have a primary key, you already have an implicitly (or explicitly) defined unique index on the primary key columns. It's generally a good idea to define non-unique indexes on the foreign keys. For example, our order entry database would probably benefit from the following indexes: CREATE UNIQUE INDEX PK_CUSTOMER ON CUSTOMER (CUST_NO) CREATE UNIQUE INDEX PK_ORDER ON ORDER (ORDER_NO) CREATE INDEX FK_ORDER_1 ON ORDER (CUST_NO) CREATE UNIQUE INDEX PK_ORDER_ITEMS ON ORDER_ITEMS (ORDER_NO, ITEM_NO) CREATE INDEX FK_ORDER_ITEMS_1 ON ORDER_ITEMS (ORDER_NO) And if we are always querying the orders based on the date they where entered, the following index should also help: CREATE INDEX ORDER_DATE ON ORDER (DATE_ENTERED) The bigger databases have tools that allows you to see the "access plan" for any given query. The access plan describes what the database does to satisfy a query: scan a table, scan an index, sort a table, use temporary storage, etc. The access plan will tell if your SQL statements and your index structure are well designed for speed or form memory. You should always use it for tuning your database and applications when available. Here's a very important characteristic of relational database: you, the programmer or data analyst, have no control on the path the database will use to satisfy a query. That's very nice because your applications are independent of the physical data structure (remember the dozen indexes you had to create with Clipper just to be able to print a new report?), but that's not so good because you may not get the performance you intended to. Never make assumptions about the use or non-use of an index by the database server. Some databases may use indexes for one condition but do not use it for another very similar condition. It depends on the capabilities of the query optimizer and on the statistics the database keeps about the data on its tables. These statistics may, for example, tell that 80% of the CUSTOMERS come from BRAZIL. Then, if I query "WHERE COUNTRY = 'BRAZIL'", the database will not use the index. It will perform less I/O going directly through the table itself. Generally you have to manually update these statistics, so the query optimizer may be making wrong decisions because it is using obsolete statistics. Physical database tuning is a very specialized subject, we will not provide more details here, but this is something you absolutely must study hard if you are using a full featured database. Conclusion Here we only touched the surface of Relational Database Design. I hope the info provided here will be useful to your work and I welcome any feedback about topics for future database, Java and Internet articles. The article cited mSQL and SQL Anywhere, but you could apply the knowledge you (hopefully) got on mySQL, Solid, Oracle, DB2 and many other databases for OS/2 and other platforms. A topic we will almost for sure cover soon is relational to object mapping. Although entities and collections (we've seen on the Java articles) are a very simple idea, thing become more complex when you take into account the relationships and joins. Another nice topic would be Entity-Relationship modeling, but I know no easily trialable OS/2 tool for drawing E-R diagrams. Before we finish, please take the time to visit The mSQL PC Home Page at http://www.blnet.com/msqlpc. Bookmark it and come back regularly to get info and software for web database development. Fernando Lozano