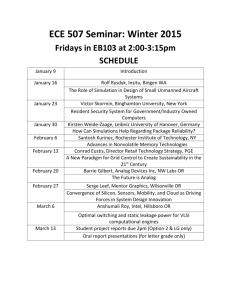
General-Purpose Code Acceleration with Limited-Precision Analog Computation
advertisement

Appears in the Proceedings of the 41st International Symposium on Computer Architecture, 2014 General-Purpose Code Acceleration with Limited-Precision Analog Computation Renée St. Amant? Hadi Esmaeilzadeh§ Amir Yazdanbakhsh§ Arjang Hassibi? ? University of Texas at Austin † University of Washington Jongse Park§ Bradley Thwaites§ Luis Ceze† Doug Burger‡ § Georgia Institute of Technology ‡ Microsoft Research stamant@cs.utexas.edu a.yazdanbakhsh@gatech.edu jspark@gatech.edu bthwaites@gatech.edu hadi@cc.gatech.edu arjang@mail.utexas.edu luisceze@cs.washington.edu dburger@microsoft.com Abstract As improvements in per-transistor speed and energy efficiency diminish, radical departures from conventional approaches are becoming critical to improving the performance and energy efficiency of general-purpose processors. We propose a solution—from circuit to compiler—that enables general-purpose use of limited-precision, analog hardware to accelerate “approximable” code—code that can tolerate imprecise execution. We utilize an algorithmic transformation that automatically converts approximable regions of code from a von Neumann model to an “analog” neural model. We outline the challenges of taking an analog approach, including restricted-range value encoding, limited precision in computation, circuit inaccuracies, noise, and constraints on supported topologies. We address these limitations with a combination of circuit techniques, a hardware/software interface, neuralnetwork training techniques, and compiler support. Analog neural acceleration provides whole application speedup of 3.7× and energy savings of 6.3× with quality loss less than 10% for all except one benchmark. These results show that using limited-precision analog circuits for code acceleration, through a neural approach, is both feasible and beneficial over a range of approximation-tolerant, emerging applications including financial analysis, signal processing, robotics, 3D gaming, compression, and image processing. 1. Introduction Energy efficiency now fundamentally limits microprocessor performance gains. CMOS scaling no longer provides gains in efficiency commensurate with transistor density increases [16, 25]. As a result, both the semiconductor industry and the research community are increasingly focused on specialized accelerators, which provide large gains in efficiency and performance by restricting the workloads that benefit. The community is facing an “iron triangle”; we can choose any two of performance, efficiency, and generality at the expense of the third. Before the effective end of Dennard scaling, we improved all three consistently for decades. Solutions that improve performance and efficiency, while retaining as much generality as possible, are highly desirable, hence the growing interest in GPGPUs and FPGAs. A growing body of recent work [13, 17, 44, 2, 35, 8, 28, 38, 18, 51, 46] has focused on approximation as a strategy for the iron triangle. Many classes of applications can tolerate small errors in their outputs with no discernible loss in QoR (Quality of Result). Many conventional techniques in energy-efficient computing navigate a design space defined by the two dimensions of performance and energy, and traditionally trade one for the other. General-purpose approximate computing explores a third dimension—that of error. Many design alternatives become possible once precision is relaxed. An obvious candidate is the use of analog circuits for computation. However, computation in the analog domain has several major challenges, even when small errors are permissible. First, analog circuits tend to be special purpose, good for only specific operations. Second, the bit widths they can accommodate are smaller than current floating-point standards (i.e. 32/64 bits), since the ranges must be represented by physical voltage or current levels. Another consideration is determining where the boundaries between digital and analog computation lie. Using individual analog operations will not be effective due to the overhead of A/D and D/A conversions. Finally, effective storage of temporary analog results is challenging in current CMOS technologies. These limitations has made it ineffective to design analog von Neumann processors that can be programmed with conventional languages. Despite these challenges, the potential performance and energy gains from analog execution are highly attractive. An important challenge is thus to architect designs where a significant portion of the computation can be run in the analog domain, while also addressing the issues of value range, domain conversions, and relative error. Recent work on Neural Processing Units (NPUs) may provide a possible approach [18]. NPU-enabled systems rely on an algorithmic transformation that converts regions of approximable general-purpose code into a neural representation (specifically, multi-layer perceptrons) at compile time. At run-time, the processor invokes the NPU instead of running the original code. NPUs have shown large performance and efficiency gains, since they subsume an entire code region (including all of the instruction fetch, decode, etc., overheads). They have an added advantage in that they convert many distinct code patterns into a common representation that can be run on a single physical accelerator, improving generality. NPUs may be a good match for mixed-signal implementations for a number of reasons. First, prior research has shown that neural networks can be implemented in analog domain to solve classes of domain-specific problems, such as pattern recognition [5, 47, 49, 32]. Second, the process of invoking a neural network and returning a result defines a clean, coarse-grained interface for D/A and A/D conversion. Third, the compile-time training of the network permits any analogspecific restrictions to be hidden from the programmer. The programmer simply specifies which region of the code can be approximated, without adding any neural-network-specific information. Thus, no additional changes to the programming model are necessary. In this paper we evaluate an NPU design with mixed-signal components and develop a compilation workflow for utilizing the mixed-signal NPU for code acceleration. The goal of this study is to investigate challenges and define potential solutions to enable effective mixed-signal NPU execution. The objective is to both bound application error to sufficiently low levels and achieve worthwhile performance or efficiency gains for general-purpose approximable code. This study makes the following four findings: 1. Due to range limitations, it is necessary to limit the scope of the analog execution to a single neuron; inter-neuron communication should be in the digital domain. 2. Again due to range issues, there is an interplay between the bit widths (inputs and weights) that neurons can use and the number of inputs that they can process. We found that the best design limited weights and inputs to eight bits, while also restricting the number of inputs to each neuron to eight. The input count limitation restricts the topological space of feasible neural networks. 3. We found that using a customized continuous-discrete learning method (CDLM) [10], which accounts for limitedprecision computation at training time, is necessary to reduce error due to analog range limitations. 4. Given the analog-imposed topology restrictions, we found that using a Resilient Back Propagation (RPROP) [30] training algorithm can further reduce error over a conventional backpropagation algorithm. We found that exposing the analog limitations to the compiler allowed for the compensation of these shortcomings and produced sufficiently accurate results. The latter three findings were all used at training time; we trained networks at compile time using 8-bit values, topologies restricted to eight inputs per neuron, plus RPROP and CDLM for training. Using these techniques together, we were able to bound error on all applications but one to a 10% limit, which is commensurate with entirely digital approximation techniques. The average time required to compute a neural result was 3.3× better than a previous digital implementation with an additional energy savings of 12.1×. The performance gains result in an average full-application-level improvement of 3.7× and 23.3× in performance and energy-delay product, respectively. This study shows that using limited-precision analog circuits for code acceleration, by converting regions of imperative code to neural networks and exposing the circuit limitations to the compiler, is both feasible and advantageous. While it may be possible to move more of the accelerator architecture design into the analog domain, the current mixed-signal design performs well enough that only 3% and 46% additional improvements in application-level energy consumption and performance are possible with improved accelerator designs. However, improving the performance of the analog NPU may lead to higher overall performance gains. 2. Overview and Background Programming. We use a similar programming model as described in [18] to enable programmers to mark error-tolerant regions of code as candidates for transformation using a simple keyword, approximable. Explicit annotation of code for approximation is a common practice in approximate programming languages [45, 7]. A candidate region is an error-tolerant function of any size, containing function calls, loops, and complex control flow. Frequently executed functions provide a greater opportunity for gains. In addition to error tolerance, the candidate function must have well-defined inputs and outputs. That is, the number of inputs and outputs must be known at compile time. Additionally, the code region must not read any data other than its inputs, nor affect any data other than its outputs. No major changes are necessary to the programming language beyond adding the approximable keyword. Exposing analog circuits to the compiler. Although an analog accelerator presents the opportunity for gains in efficiency over a digital NPU, it suffers from reduced accuracy and flexibility, which results in limitations on possible network topologies and limited-precision computation, potentially resulting in a decreased range of applications that can utilize the acceleration. These shortcomings at the hardware level, however, can be exposed as a high-level model and considered in the training phase. Four characteristics need to be exposed: (1) limited precision for input and output encoding, (2) limited precision for encoding weights, (3) the behavior of the activation function (sigmoid), (4) limited feasible neural topologies. Other lowlevel circuit behavior such as response to noise can also be exposed to the compiler. Section 5 describes this necessary hardware/software interface in more detail. Analog neural accelerator circuit design. To extract the high-level model for the compiler and to be able to accelerate execution, we design a mixed-signal neural hardware for multilayer perceptrons. The accelerator must support a large enough variety of neural network topologies to be useful over a wide range of applications. As we will show, each applications requires a different topology for the neural network that is replacing its approximable regions of code. Section 4 describes a candidate A-NPU circuit design, and outlines the challenges and tradeoffs present with an analog implementation. Compiling for analog neural hardware. The compiler aims to mimic approximable regions of code with neural networks that can be executable on the mixed-signal accelerator. While considering the limitation of the analog hardware, the compiler searches the topology space of the neural networks and selects and trains a neural network to produce outputs Profiling,Path,for, Training,Data, Collec<on Annotated, Source,Code A"NPU Circuit,Design Training,Data Programmer A-NPU High-Level Model Programming Design Instrumented, Binary Trained,Neural, Network CORE Code, Genera<on Custom,Training, Algorithm,for, Limited"Precision, Analog,Accelerator Accelerator, Config A"NPU Compila/on Accelera/on Figure 1: Framework for using limited-precision analog computation to accelerate code written in conventional languages. comparable to those produced by the original code segment. 1) Profile-driven training data collection. During a profiling stage, the compiler runs the application with representative profiling inputs and collects the inputs and outputs to the approximable code region. This step provides the training data for the rest of the compilation workflow. 2) Training for a limited-precision A-NPU. This stage is where our compilation workflow significantly deviates from the framework presented in [18] that targets digital NPUs. The compiler uses the collected training data to train a multilayer perceptron neural network, choosing a network topology, i.e. the number of neurons and their connectivity, and taking a gradient descent approach to find the synaptic weights of the network while minimizing the error with respect to the training data. This compilation stage does a neural topology search to find the smallest neural network that (a) adheres to the organization of the analog circuit and (b) delivers acceptable accuracy at the application level. The network training algorithm, which finds optimal synaptic weights, uses a combination of a resilient back propagation algorithm, RPROP [30], that we found to outperform traditional back propagation for restricted network topologies, and a continuous-discrete learning method, CDLM [10], that attempts to correct for error due to limited-precision computation. Section 5 describes these techniques that address analog limitations. 3) Code generation for hybrid analog-digital execution. Similar to prior work [18], in the code generation phase, the compiler replaces each instance of the original program code with code that initiates a computation on the analog neural accelerator. Similar ISA extensions are used to specify the neural network topology, send input and weight values to the A-NPU, and retrieve computed outputs from the A-NPU. 3. Analog Circuits for Neural Computation This section describes how analog circuits can perform the computation of neurons in multi-layer perceptrons, which are widely used neural networks. We also discuss, at a highlevel, how limitations of the analog circuits manifest in the computation. We explain how these restrictions are exposed to the compilation framework. The next section presents a concrete design for the analog neural accelerator. As Figure 2a illustrates, each neuron in a multi-layer perceptron takes in a set of inputs (xi ) and performs a weighted sum of those input values (∑i xi wi ). The weights (wi ) are the result of training the neural network on . After the summation x0 xi … w0 … wn wi X xn (xi wi ) x0 xi xn DAC DAC DAC … I(x0 ) R(w0 ) V to I y = sigmoid( (a) (xi wi )) R(wi ) V to I X X … I(xi ) I(xn ) R(wn ) V to I (I(xi )R(wi )) ADC y ⇡ sigmoid( X (I(xi )R(wi ))) (b) Figure 2: One neuron and its conceptual analog circuit. stage, which produces a linear combination of the weighted inputs, the neuron applies a nonlinearity function, sigmoid, to the result of summation. Figure 2b depicts a conceptual analog circuit that performs the three necessary operations of a neuron: (1) scaling inputs by weight (xi wi ), (2) summing the scaled inputs (∑i xi wi ), and (3) applying the nonlinearity function (sigmoid). This conceptual design first encodes the digital inputs (xi ) as analog current levels (I(xi )). Then, these current levels pass through a set of variable resistances whose values (R(wi )) are set proportional to the corresponding weights (wi ). The voltage level at the output of each resistance (I(xi )R(wi )), is proportional to xi wi . These voltages are then converted to currents that can be summed quickly according to Kirchhoff’s current law (KCL). Analog circuits only operate linearly within a small range of voltage and current levels, outside of which the transistors enter saturation mode with IV characteristics similar in shape to a non-linear sigmoid function. Thus, at the high level, the non-linearity is naturally applied to the result of summation when the final voltage reaches the analog-to-digital converter (ADC). Compared to a digital implementation of a neuron, which requires multipliers, adder trees and sigmoid lookup tables, the analog implementation leverages the physical properties of the circuit elements and is orders of magnitude more efficient. However, it operates in limited ranges and therefore offers limited precision. Analog-digital boundaries. The conceptual design in Figure 2b draws the analog-digital boundary at the level of an algorithmic neuron. As we will discuss, the analog neural accelerator will be a composition of these analog neural units (ANUs). However, an alternative design, primarily optimizing for efficiency, may lay out the entirety of a neural network with only analog components, limiting the D-to-A and A-to-D conversions to the inputs and outputs of the neural network and not the individual neurons. The overhead of conversions in the ANUs significantly limits the potential efficiency gains of an analog approach toward neural computation. However, there is a tradeoff between efficiency, reconfigurability (generality), and accuracy in analog neural hardware design. Pushing more of the implementation into the analog domain gains efficiency at the expense of flexibility, limiting the scope of supported network topologies and, consequently, limiting potential network accuracy. The NPU approach targets code approximation, rather than typical, simpler neural tasks, such as recognition and prediction, and imposes higher accuracy requirements. The main challenge is to manage this tradeoff to achieve acceptable accuracy for code acceleration, while delivering higher performance and efficiency when analog neural circuits are used for general-purpose code acceleration. As prior work [18] has shown and we corroborate, regions of code from different applications require different topologies of neural networks. While a holistically analog neural hardware design with fixed-wire connections between neurons may be efficient, it effectively provides a fixed topology network, limiting the scope of applications that can benefit from the neural accelerator, as the optimal network topology varies with application. Additionally, routing analog signals among neurons and the limited capability of analog circuits for buffering signals negatively impacts accuracy and makes the circuit susceptible to noise. In order to provide additional flexibility, we set the digital-analog boundary in conjunction with an algorithmic, sigmoid-activated neuron. where a set of digital inputs and weights are converted to the analog domain for efficient computation, producing a digital output that can be accurately routed to multiple consumers. We refer to this basic computation unit as an analog neural unit, or ANU. ANUs can be composed, in various physical configurations, along with digital control and storage, to form a reconfigurable mixed-signal NPU, or A-NPU. One of the most prevalent limitations in analog design is the bounded range of currents and voltages within which the circuits can operate effectively. These range limitations restrict the bit-width of input and weight values and the network topologies that can be computed accurately and efficiently. We expose these limitations to the compiler and our custom training algorithm and compilation workflow considers these restrictions when searching for optimal network topologies and training neural networks. As we will show, one of the insights from this work is that even with limited bit-width (≤ 8), and a restricted neural topology, many general-purpose approximate applications achieve acceptable accuracy and significantly benefit from mixed-signal neural acceleration. Value representation and bit-width limitations. One of the fundamental design choices for an ANU is the bit-width of inputs and weights. Increasing the number of bits results in an exponential increase in the ADC and DAC energy dissipation and can significantly limit the benefits from analog acceleration. Furthermore, due to the fixed range of voltage and current levels, increasing the number of bits translates to quantizing this fixed value range to fine granularities that practical ADCs can not handle. In addition, the fine granularity encoding makes the analog circuit significantly more susceptible to noise, thermal, voltage, current, and process variations. In practice, these non-ideal effects can adversely affect the final accuracy when more bit-width is used for weights and inputs. We design our ANUs such that the granularity of the voltage and current levels used for information encoding is to a large degree robust to variations and noise. Topology restrictions. Another important design choice is the number of inputs in the ANU. Similar to bit-width, increasing the number of ANU inputs translates to encoding a larger value range in a bounded voltage and current range, which, as discussed, becomes impractical. There is a tradeoff between accuracy and efficiency in choosing the number ANU inputs. The larger the number of inputs, the larger the number of multiply and add operations that can be done in parallel in the analog domain, increasing efficiency. However, due to the bounded range of voltage and currents, increasing the number of inputs requires decreasing the number of bits for inputs and weights. Through circuit-level simulations, we empirically found that limiting the number of inputs to eight with 8-bit inputs and weights strikes a balance between accuracy and efficiency. A digital implementation does not impose such restrictions on the number of inputs to the hardware neuron and it can potentially compute arbitrary topologies of neural networks. However, this unique ANU limitation restricts the topology of the neural network that can run on the analog accelerator. Our customized training algorithm and compilation workflow takes into account this topology limitation and produces neural networks that can be computed on our mixed-signal accelerator. Non-ideal sigmoid. The saturation behavior of the analog circuit that leads to sigmoid-like behavior after the summation stage represents an approximation of the ideal sigmoid. We measure this behavior at the circuit level and expose it to the compiler and the training algorithm. 4. Mixed-Signal Neural Accelerator (A-NPU) This section describes a concrete ANU design and the mixedsignal, neural accelerator, A-NPU. 4.1. ANU Circuit Design Figure 3 illustrates the design of a single analog neuron (ANU). The ANU performs the computation of one neuron, or y ≈ sigmoid(∑i wi xi ). We place the analog-digital boundary at the ANU level, with computation in the analog domain and storage in the digital domain. Digital input and weight values are represented in sign-magnitude form. In the figure, swi and sxi represent the sign bits and wi and xi represent the magnitude. Digital input values are converted to the analog domain through current-steering DACs that translate digital values to analog currents. Current-steering DACs are used for … I(|xn |) Resistor' Ladder R(|w0 |) V (|w0 x0 |) I + (wn xn ) I (w0 x0 ) V w i xi V R(|wn |) ⇣X w i xi ⌘ -; 8"Wide AnalogNeuron 8"Wide AnalogNeuron … 8"Wide AnalogNeuron 8"Wide AnalogNeuron Column'Selector I (wn xn ) + + Diff' ⌘ Config'FIFO Input'FIFO Row'Selector Current' Steering' DAC Diff' Pair I + (w0 x0 ) ⇣X xn V (|wn xn |) Diff' Pair + sxn Weight'Buffer Resistor' Ladder Current' Steering' DAC wn Weight'Buffer I(|x0 |) s wn x0 Weight'Buffer sx0 w0 Weight'Buffer s w0 Amp Flash ADC sy y ⇣ ⇣X ⌘⌘ y ⇡ sigmoid V w i xi Figure 3: A single analog neuron (ANU). their speed and simplicity. In Figure 3, I(|xi |) is the analog current that represents the magnitude of the input value, xi . Digital weight values control resistor-string ladders that create a variable resistance depending on the magnitude of each weight (R(|wi |)) . We use a standard resistor ladder thats consists of a set of resistors connected to a tree-structured set of switches. The digital weight bits control the switches, adjusting the effective resistance, R(|wi |), seen by the input current (I(|xi |)). These variable resistances scale the input currents by the digital weight values, effectively multiplying each input magnitude by its corresponding weight magnitude. The output of the resistor ladder is a voltage: V (|wi xi |) = I(|xi |) × R(|wi |). The resistor network requires 2m resistors and approximately 2m+1 switches, where m is the number of digital weight bits. This resistor ladder design has been shown to work well for m ≤ 10. Our circuit simulations show that only minimally sized switches are necessary. V (|wi xi |), as well as the XOR of the weight and input sign bits, feed to a differential pair that converts voltage values to two differential currents (I + (wi xi ), I − (wi xi )) that capture the sign of the weighted input. These differential currents are proportional to the voltage applied to the differential pair, V (|wi xi |). If the voltage difference between the two gates is kept small, the current-voltage relationship is linear, producing Ibias − I + (wi xi ) = Ibias 2 + ∆I and I (wi xi ) = 2 − ∆I. Resistor ladder values are chosen such that the gate voltage remains in the range that produces linear outputs, and consequently a more accurate final result. Based on the sign of the computation, a switch steers either the current associated with a positive value or the current associated with a negative value to a single wire to be efficiently summed according to Kirchhoff’s current law. The alternate current is steered to a second wire, retaining differential operation at later design stages. Differential operation combats environmental noise and increases gain, the later being particularly important for mitigating the impact of analog range challenges at later stages. Resistors convert the resulting pair of differential currents to voltages, V + (∑i wi xi ) and V − (∑i wi xi ), that represent the weighted sum of the inputs to the ANU. These voltages are Output'FIFO Figure 4: Mixed-signal neural accelerator, A-NPU. Only four of the ANUs are shown. Each ANU processes eight 8-bit inputs. used as input to an additional amplification stage (implemented as a current-mode differential amplifier with diode-connected load). The goal of this amplification stage is to significantly magnify the input voltage range of interest that maps to the linear output region of the desired sigmoid function. Our experiments show that neural networks are sensitive to the steepness of this non-linear function, losing accuracy with shallower, non-linear activation functions. This fact is relevant for an analog implementation because steeper functions increase range pressure in the analog domain, as a small range of interest must be mapped to a much larger output range in accordance with ADC input range requirements for accurate conversion. We magnify this range of interest, choosing circuit parameters that give the required gain, but also allowing for saturation with inputs outside of this range. The amplified voltage is used as input to an ADC that converts the analog voltage to a digital value. We chose a flash ADC design (named for its speed), which consists of a set of reference voltages and comparators [1, 31]. The ADC requires 2n comparators, where n is the number of digital output bits. Flash ADC designs are capable of converting 8 bits at a frequency on the order of one GHz. We require 2–3 mV between ADC quantization levels for accurate operation and noise tolerance. Typically, ADC reference voltages increase linearly; however, we use a non-linearly increasing set of reference voltages to capture the behavior of a sigmoid function, which also improves the accuracy of the analog sigmoid. 4.2. Reconfigurable Mixed-Signal A-NPU We design a reconfigurable mixed-signal A-NPU that can perform the computation of a wide variety of neural topologies since each requires a different topology. Figure 4 illustrates the A-NPU design with some details omitted for clarity. The figure shows four ANUs while the actual design has eight. The A-NPU is a time-multiplexed architecture where the algorithmic neurons are mapped to the ANUs based on a static scheduling algorithm, which is loaded to the A-NPU before invocation. The multi-layer perceptron consists of layers of neurons, where the inputs of each layer are the outputs of the previous layer. The ANU starts from the input layer and performs the computations of the neurons layer by layer. The Input Buffer always contains the inputs to the neurons, either coming from the processor or from the previous layer computation. The Output Buffer, which is a single entry buffer, collects the outputs of the ANUs. When all of its columns are computed, the results are pushed back to the Input Buffer to enable calculation of the next layer. The Row Selector determines which entry of the input buffer will be fed to the ANUs. The output of the ANUs will be written to a single-entry output buffer. The Column Selector determines which column of the output buffer will be written by the ANUs. These selectors are FIFO buffers whose values are part of the preloaded A-NPU configuration. All the buffers are digital SRAM structures. Each ANU has eight inputs. As shown in Figure 4, each A-NPU is augmented with a dedicated weight buffer, storing the 8-bit weights. The weight buffers simultaneously feed the weights to the ANUs. The weights and the order in which they are fed to the ANUs are part of the A-NPU configuration. The Input Buffer and Weight Buffers synchronously provide the inputs and weights for the ANUs based on the pre-loaded order. A-NPU configuration. During code generation, the compiler produces an A-NPU configuration that constitutes the weights and the schedule. The static A-NPU scheduling algorithm first assigns an order to the neurons of the neural network, in which the neurons will be computed in the ANUs. The scheduler then takes the following steps for each layer of the neural network: (1) Assign each neuron to one of the ANUs. (2) Assign an order to neurons. (3) Assign an order to the weights. (4) Generate the order for inputs to feed the ANUs. (5) Generate the order in which the outputs will be written to the Output Buffer. The scheduler also assigns a unique order for the inputs and outputs of the neural network in which the core communicates data with the A-NPU. 4.3. Architectural interface for A-NPU We adopt the same FIFO-based architectural interface through which a digital NPU communicates with the processor [18]. The A-NPU is tightly integrated to the pipeline. The processor only communicates with the ANUs through the Input, Output, Config FIFOs. The processor ISA is extended with special instructions that can enqueue and dequeue data from these FIFOs as shown in Figure 4. When a data value is queued/dequeued to/from the Input/Output FIFO, the A-NPU converts the values to the appropriate representation for the A-NPU/processor. 5. Compilation for Analog Acceleration As Figure 1 illustrates, the compilation for A-NPU execution consists of three stages: (1) profile-driven data collection, (2) training for a limited-precision A-NPU, and (3) code generation for hybrid analog-digital execution. In the profile-driven data collection stage, the compiler instruments the application to collect the inputs and outputs of approximable functions. The compiler then runs the application with representative inputs and collects the inputs and their corresponding outputs. These input-output pairs constitute the training data. Section 4 briefly discussed ISA extensions and code generation. While compilation stages (1) and (3) are similar to the techniques presented for a digital implementation [18], the training phase is unique to an analog approach, accounting for analog-imposed, topology restrictions and adjusting weight selection to account for limited-precision computation. Hardware/software interface for exposing analog circuits to the compiler. As we discussed in Section 3, we expose the following analog circuit restrictions to the compiler through a hardware/software interface that captures the following circuit characteristics: (1) input bit-width limitations, (2) weight bit-width limitations, (3) limited number of inputs to each analog neuron (topology restriction), and (4) the nonideal shape of the analog sigmoid. The compiler internally constructs a high-level model of the circuit based on these limitations and uses this model during the neural topology search and training with the goal of limiting the impact of inaccuracies due to an analog implementation. Training for limited bit widths and analog computation. Traditional training algorithms for multi-layered perceptron neural networks use a gradient descent approach to minimize the average network error, over a set of training input-output pairs, by backpropagating the output error through the network and iteratively adjusting the weight values to minimize that error. Traditional training techniques, however, that do not consider limited-precision inputs, weights, and outputs perform poorly when these values are saturated to adhere to the bit-width requirements that are feasible for an implementation in the analog domain. Simply limiting weight values during training is also detrimental to achieving quality outputs because the algorithm does not have sufficient precision to converge to a quality solution. To incorporate bit-width limitations into the training algorithm, we use a customized continuous-discrete learning method (CDLM) [10]. This approach takes advantage of the availability of full-precision computation at training time and then adjusts slightly to optimize the network for errors due to limited-precision values. In an initial phase, CDLM first trains a fully-precise network according to a standard training algorithm, such as backpropagation [43]. In a second phase, it discretizes the input, weight, and output values according the the exposed analog specification. The algorithm calculates the new error and backpropagates that error through the fully-precise network using full-precision computation and updates the weight values according to the algorithm also used in stage 1. This process repeats, backpropagating the ’discrete’ errors through a precise network. The original CDLM training algorithm was developed to mitigate the impact of limited-precision weights. We customize this algorithm by incorporating the input bit-width limitation and the output bit-width limitation in addition to limited weight values. Additionally, this training scheme is advantageous for an analog implementation because it is general enough to also make up for errors that arise due to an analog implementation, such as a non-ideal sigmoid function and any other analog non-ideality that behaves consistently. In essence, after one round of full-precision training, the compiler models an analog-like version of the network. A second, CDLM-based training pass adjusts for these analogimposed errors, enabling the inaccurate and limited A-NPU as an option for a beneficial NPU implementation by maintaining acceptable accuracy and generality. Training with topology restrictions. In addition to determining weight values for a given network topology, the compiler searches the space of possible topologies to find an optimal network for a given approximable code region. Conventional multi-layered perceptron networks are fully connected, i.e. the output of each neuron in one layer is routed to the input of each neuron in the following layer. However, analog range limitations restrict the number of inputs that can be computed in a neuron (eight in our design). Consequently, network connections must be limited, and in many cases, the network can not be fully connected. We impose the circuit restriction on the connectivity between the neurons during the topology search and we use a simple algorithm guided by the mean-squared error of the network to determine the best topology given the exposed restriction. The error evaluation uses a typical cross-validation approach: the compiler partitions the data collected during profiling into a training set, 70% of the data, and a test set, the remaining 30%. The topology search algorithm trains many different neural-network topologies using the training set and chooses the one with the highest accuracy on the test set and the lowest latency on the A-NPU hardware (prioritizing accuracy). The space of possible topologies is large, so we restrict the search to neural networks with at most two hidden layers. We also limit the number of neurons per hidden layer to powers of two up to 32. The numbers of neurons in the input and output layers are predetermined based on the number of inputs and outputs in the candidate function. To further improve accuracy, and compensate for topologyrestricted networks, we utilize a Resilient Back Propagation (RPROP) [30] training algorithm as the base training algorithm in our CDLM framework. During training, instead of updating the weight values based on the backpropagated error (as in conventional backpropagation [43]), the RPROP algorithm increases or decreases the weight values by a predefined value based on the sign of the error. Our investigation showed that RPROP significantly outperforms conventional backpropagation for the selected network topologies, requiring only half of the number of training epochs as backpropagation to converge on a quality solution. The main advantage of the application of RPROP training to an analog approach to neural computing is its robustness to the sigmoid function and topology restrictions imposed by the analog design. Backpropagation, for example, is extremely sensitive to the steepness of the sigmoid function, and allowing for a variety of steepness levels in a fixed, analog implementation is challenging. Additionally, backpropagation performs poorly with a shallow sigmoid function. The require- ment of a steep sigmoid function exacerbates analog range challenges, possibly making the implementation infeasible. RPROP tolerates a more shallow sigmoid activation steepness and performs consistently utilizing a constant activation steepness over all applications. Our RPROP-based, customized CDLM training phase requires 5000 training epochs, with the analog-based CDLM phase adding roughly 10% to the training time of the baseline training algorithm. 6. Evaluations Cycle-accurate simulation and energy modeling. We use the MARSSx86 x86-64 cycle-accurate simulator [39] to model the performance of the processor. The processor is modeled after a single-core Intel Nehalem to evaluate the performance benefits of A-NPU acceleration over an aggressive out-oforder architecture1 . We extended the simulator to include ISAlevel support for A-NPU queue and dequeue instructions. We also augmented MARSSx86 with a cycle-accurate simulator for our A-NPU design and an 8-bit, fixed-point D-NPU with eight processing engines (PEs) as described in [18]. We use GCC v4.7.3 with -o3 to enable compiler optimization. The baseline in our experiments is the benchmark run solely on the processor without neural transformation. We use McPAT [33] for processor energy estimations. We model the energy of an 8-bit, fixed-point D-NPU using results from McPAT, CACTI 6.5 [37], and [22] to estimate its energy. Both the D-NPU and the processor operate at 3.4GHz at 0.9 V, while the A-NPU is clocked at one third of the digital clock frequency, 1.1GHz at 1.2 V, to achieve acceptable accuracy. Circuit design for ANU. We built a detailed transistor-level SPICE model of the analog neuron, ANU. We designed and simulated the 8-bit, 8-input ANU in the Cadence Analog Design Environment using predictive technology models at 45 nm [6]. We ran detailed Spectre SPICE simulations to understand circuit behavior and measure ANU energy consumption. We used CACTI to estimate the energy of the A-NPU buffers. Evaluations consider all A-NPU components, both digital and analog. For the analog parts, we used direct measurements from the transistor-level SPICE simulations. For SRAM accesses, we used CACTI. We built an A-NPU cycle-accurate simulator to evaluate the performance improvements. Similar to McPAT, we combined simulation statistics with measurements from SPICE and CACTI to calculate A-NPU energy. To avoid biasing our study toward analog designs, all energy and performance comparisons are to an 8-bit, fixed-point D-NPU (8-bit inputs/weights/multiply-adders). For consistency with the available McPAT model for the baseline processor, we 1 Processor: Fetch/Issue Width: 4/5, INT ALUs/FPUs: 6/6, Load/Store FUs: 1/1, ROB Entries: 128, Issue Queue Entries: 36, INT/FP Physical Registers: 256/256, Branch Predictor: Tournament 48 KB, BTB Sets/Ways: 1024/4, RAS Entries: 64, Load/Store Queue Entries: 48/48, Dependence Predictor: 4096-entry Bloom Filter, ITLB/DTLB Entries: 128/256 L1: 32 KB Instruction, 32 KB Data, Line Width: 64 bytes, 8-Way, Latency: 3 cycles L2: 256 KB, Line Width: 64 bytes, 8-Way, Latency: 6 cycles L3: 2 MB, Line Width 64 bytes, 16-Way, Latency: 27 cycles Memory Latency: 50 ns Application Speedup Application Topology Core + D-NPU Core + A-NPU blackscholes 6 -> 8 -> 8 -> 1 14.1441013944802 24.5221729784241 48.0035326510468 0.294647093939904 0.510841007404262 0.489158992595738 fft 1 -> 4 -> 4 -> 2 1.12709929506364 1.32327013458615 Core + Ideal NPU 1.64546022960568 Core + D-NPU 0.68497510592142 0.804194541306698 0.195805458693302 Core + A-NPU speedup inversek2j 2 -> 8 -> 2 7.98161179269307 10.9938617211157 14.9861613789597 0.53259881505741 0.733600916412848 0.266399083587152 jmeint 18 -> 32 -> 8 -> 2 2.39085372136084 6.26190545947988 14.0755862116774 0.169858198827793 0.444877063399665 0.555122936600335 jpeg 64 -> 16 -> 8 -> 64 1.5617504494923 1.87946485929561 1.90676591975013 0.819057249406344 0.985682007334125 0.014317992665875 kmeans 6 -> 8 -> 4 -> 1 0.590012411780286 0.844832278645737 1.20518169214864 0.489563039020608 0.700999927354972 0.299000072645028 sobel 9 -> 8 -> 1 2.4864550898745 3.10723166292606 3.62429006473114 0.686053004992842 0.857335259438336 Table 1: The evaluated benchmarks, characterization of each offloaded function,0.142664740561664 training data, and the trained neural network. Miss*Rate 17.68% 19.7% Image*Diff 5.48% 8.4% Image*Diff 3.21% 7.3% Image*Diff 3.89% 5.2% 12.1 3.3 1 0 blackscholes 0 inversek2j jmeint jpeg kmeans sobel geomean Figure 5: A-NPU with 8 ANUs vs. D-NPU with 8 PEs. ble 1, each application benefits from a different neural network topology, so the ability to reconfigure the A-NPU is critical. 10 A-NPU vs 8-bit D-NPU. Figure 5 shows the average energy improvement and speedup for one invocation of an A-NPU over one invocation of an 8-bit D-NPU, where the A-NPU 8 is clocked at 13 the D-NPU frequency. On average, the ANPU is 12.1× more energy efficient and 3.3× faster than the D-NPU. While consuming significantly less energy, the A-NPU 6 can perform 64 multiply-adds in parallel, while the D-NPU can only perform eight. This energy-efficient, parallel computation explains why jpeg–with the largest neural network (64→16→8→64)–achieves the highest energy and 4 performance improvements, 82.2× and 15.2×, respectively. The larger the network, the higher the benefits from A-NPU. Compared to a D-NPU, an A-NPU offers a higher level of parallelism with low energy cost that can potentially enable using 2 larger neural networks to replace more complicated code. Whole application speedup and energy savings. Figure 6 shows the whole application speedup and energy savings when 0 the processor is augmented with an 8-bit, 8-PE D-NPU, our blackscholes 0 idealinversek2j 8-ANU A-NPU, and an NPU, whichjmeint takes zero jpeg cycles kmeans and consumes zero energy. Figure 6c shows the percentage of dynamic instructions subsumed by the neural transformation of the 10 candidate code. The results show, following the Amdahl’s Law, that the larger the number of dynamic instructions subsumed, the larger the benefits from neural acceleration. 2.3 8 6 0.5 0.8 1.2 6.2 7.9 used McPAT and CACTI to estimate D-NPU energy. Even though we do not have a fabrication-ready layout for the design, in Table 2, we provide an estimate of the ANU area in terms of number of transistors. T denotes a transistor with width length = 1. As shown, each ANU (which performs eight, 8-bit analog multiply-adds in parallel followed by a sigmoid) requires about 10,964 transistors. An equivalent digital neuron that performs eight, 8-bit multiply-adds and a sigmoid would require about 72,456 T from which 56,000 T are for the eight, 8-bit multiply-adds and 16,456 T for the sigmoid lookup. With the same compute capability, the analog neuron requires 6.6× fewer transistors than its equivalent digital implementation. Benchmarks. We use the benchmarks in [18] and add one more, blackscholes. These benchmarks represent a diverse set of application domains, including financial analysis, signal processing, robotics, 3D gaming, compression, image processing. Table 1 summarizes information about each benchmark: application domain, target code, neural-network topology, training/test data and final application error levels for fully-digital neural networks and analog neural networks using our customized RPROP-based CDLM training algorithm. The neural networks were trained using either typical program inputs, such as sample images, or a limited number of random inputs. Accuracy results are reported using an independent data set, e.g, an input image that is different than the image used during training. Each benchmark requires an application-specific error metric, which is used in our evaluations. As shown in Ta- Speedup EnergyBSaving 1.1 1.3 1.6 ≈ 10,964 T 2 14.1 24.5 48.0 Total 3 42.5 51.2 52.5 3,096 T∗ 4,096 T + 1 KΩ (≈ 450T) 48 T 20 KΩ (≈ 30 T) 244 T 2550 T + 1 KΩ (≈ 450 T) Improvement 8×8-bit DAC 8×Resistor Ladder (8-bit weights) 8×Differential Pair I-to-V Resistors Differential Amplifier 8-bit ADC 4 Applica'on*Speedup Area rgy*Reduc'on Sub-circuit 5 3.3 Table 2: Area estimates for the analog neuron (ANU). ∗ Transistor with width/length = 1 9.4% 1.5 1.8 1.9 3 6.2% 11.8 sobel Image* Processing Avg.*Rela've*Error 2.7 1 Sobel*edge* detector 4.1% 14.0 kmeans 2.75% 17.8 18.8 3 Avg.*Rela've*Error 8.5 1 -> 16 -> 8 -> 1 Machine* KEmeans*clustering Learning 10.2% 2.4 9 -> 8 -> 1 Compression geomean 6.02% 7.3 32 6 -> 8 -> 4 -> 1 Avg.*Rela've*Error 0.00228 15.2 82.2 swaptions 64 -> 16 -> 8 -> 64 0.000011 2048*Random* 32768*Random* 0 0 34 Floa'ng*Point* Floa'ng*Point* 1*E>*4*E>*4*E>*2 0.00002 0.00194 Application Speedup-1 Numbers Numbers Core + A-NPU Core + Ideal NPU Core10000*(x,*y)* + D-NPU Core + A-NPU speedup 10000*(x,*y)* 0 0 100 Random* Random* 2*E>*8*E>*2 0.000341 0.00467 Coordinates Coordinates 10000*Random* 10000*Random* Pairs*of*3D* Pairs*of*3D* 0 23 1,079 18*E>*32*E>*8*E>*2 0.05235 0.06729 Triangle* Triangle* Coordinates Coordinate 220x200EPixel* Three*512x512E 4 0 1,257 64*E>*16*E>*8*E>*64 0.0000156 0.0000325 Color*Image Pixel*Color*Images 220x200EPixel* 50000*Pairs*of* 0 0 26 Color*Image Random*(r,*g,*b)* 6*E>*8*E>*4*E>*1 0.00752 0.009589 Values 220x200EPixel* One*512x512E 2 1 88 9*E>*8*E>*1 0.000782 0.00405 Color*Image Pixel*Color*Image 10.9 14.9 JPEG*encoding 18 -> 32 -> 8 -> 2 3D*Gaming 4 Analog* Error 28.2 2 -> 8 -> 2 Fully* Digital* Error 25.8 30.0 31.4 1 -> 4 -> 4 -> 2 inversek2j 2 Core + D-NPU Applica0on*Error* Metric 3.9 fft sobel jpeg 5 Fully* Analog*NN* Digital*NN* MSE*(8@bit) MSE 4.5 Topology kmeans 0 Signal* Processing Application Triangle* jmeint intersec'on* jpeg detec'on jmeint 5 Financial* Analysis Inverse*kinema'cs* Robo'cs blackscholes 6 -> 8 -> 8 -> 1 for*2Ejoint*arm inversek2j #*of*Ifs/ elses 2.4 RadixE2*CooleyE Tukey*fast*fourier M #*of* Loops 3.7 Mathema'cal* model*of*a* financial*market* Type 5.42766338726694 0.469422021014693 0.696386462789426 0.189114065410968 #*of* x86@64* Evalua0on*Input* Neural*Network* Training*Input*Set Instruc0on Set Topology s 4096*Data*Point* 16384*Data*Point* 309 from*PARSEC from*PARSEC 6*E>*8*E>*8E>*1 9.5 blackscholes Descrip0on 3.7797513074705 1.8 Benchmark*Name 2.5478647166383 #*of* Func0on* Calls 2.5 geomean geomean 7.28 0.0118 4.28 5.21 0.0093 2.61 3.34 0.0073 6.02 7.32 0.01 8 6 Fully Precise Digital Sigmoid Analog Sigmoid blackscholes 8.39% 10.21% fft 3.03% 4.13% inversek2j 8.13% jmeint 18.41% jpeg 6.62% 4.28% swaptions 2.61% geomean 6.02% 10 8 inversek2j jmeintblackscholes jpeg Other Instructions 8 6 2.4% 31.4% 3.3% 0.3% 1.2% 0.8% 97.2% blackscholes fft inversek2j jmeint jpeg kmeans sobel 2.4% 31.4% 3.3% 3.1% 43.3% 65.5% 40.5% blackscholes 01.2% inversek2j jmeint 0.3% 0.8% 1.8% 0.5% 4.8% blackscholes 0 jpeg jpeg 4 9 inversek2j jmeint fft swaptions swaptions geomean kmeans sobel 65.5% 40.5% fft jpeg 2.50 95.9% Analog Sigmoid 10.2% Energy 29.7% 57.1% (1.7 Improvement GHz) 8.48 2.04 6 3.33 2.33 4 0.51 4.05 28.28 25.50 1.36 15.21 7.57 0.46 2.75 4.13 11.81 10.45 0.79 3.33 5.00 12.14 10.79 2.7 2.4 sobel 12.1 3.3 swaptions geomean 2.0 2.7 2.4 kmeans 8.4 11.8 3.3 8.4 15.2 2.0 3.9 2.4 jpeg 3.3 8.56 1.8 jmeint 11.8 8.5 73.76 3.67 12.1 82.21 2.44 3.3 22.81 0.67 2.4 3.7 2.4 inversek2j 4.05 12.1 4.57 5.88 82.2 3.63 3.92 2.7 82.2 15.2 3.9 4.5 4.5 2.42 1.99 11.8 82.2 fft inversek2j 28.2 fft 0.51 2.4 3.9 4.5 2.4 1.8 3.7 2.5 1.8 kscholes 3.33 11.8 6.15 8.48 3.79 12.1 4 9.63 3.7 5.49 9.53 2.83 15.2 6 11.81 2.7 8 5.77 3.75 1.89 8.5 111.54 2.50 8.5 12 4.13 0.54 4.5 4 9.5 2.33 56.26 Improvement 2.75 Improvement (1.7 (1.1336 GHz) GHz) 0.86 3.9 6 82.2 2.04 Improvement 0.46 (1.7 GHz) 10.45 Geometric mean and energy with an A-NPU 6.15 0.79 speedup 3.33 5.00 savings 12.14 10.79 is 3.7× and 6.3× respectively, which is 48% and 24% better than an 8-bit, 8-PE NPU. Among the benchmarks, kmeans sees slow down with D-NPU and A-NPU-based acceleration. Speedup All benchmarks benefit in termsEnergy of energy. Saving The speedup with A-NPU acceleration ranges from 0.8× to 24.5×. The energy savings range from 1.3× to 51.2×.As the results show, the Speedup Saving closely follows the ideal case, and, savings with anEnergy A-NPU in terms of “energy”, there is little value in designing a more sophisticated A-NPU. This result is due to the fact that the energy cost of executing instructions in the von Neumann, out-of-order pipeline is much higher than performing simple multiply-adds in the analog domain. Using physics laws (Ohm’s law for multiplication and Kirchhoff’s law for summainversek2j kmeansof devices sobel geomean tion)jpegandjmeint analogsobeljpeg properties to perform computation jmeint kmeans geomean can lead to significant energy and performance benefits. Application error. Table 3 shows the application-level errors with a floating point D-NPU, A-NPU with ideal sigmoid Energy Saving and our A-NPU which incorporates non-idealities of the anaSpeedup Energy Savingshows error above 10%, log sigmoid. Except for jmeint , which Speedup all of the applications show error less than or around 10%. Application average error rates with the A-NPU range from 28.2 8.15 9.636 15.2 7 Improvement 4 (1.1336 GHz) 28.2 5.49 2.4 3 jpeg A-NPU + Ideal Sigmoid 8.4% 3.0% 8.1% 18.4% 6.6% 6 6.1% 4.3% 10.2% 4.1% 9.4% 19.7% 8.4% 7.3% 5.2% 100% 80% blackscholes fft inversek2j 8.4% 3.0% 8.1% 10.2% 4.1% 9.4% Percentage instructions subsumed 60% Analog Sigmoid geomean 0% 7.3% 20% jpeg kmeans sobel swaptions geomean 18.4% 6.6% 6.1% 4.3% 2.6% 6.0% 19.7% 8.4% 7.3% 5.2% 3.3% 7.3% blackscholes 2 fft jmeint inversek2j jpeg kmeans 0 sobel 4.3% 10% 5.2% 4 jmeint 30% 40% 50% 60% 70% 80% blackscholes 90% 100% fft inve Error kmeans sobel swaptions Figure 7: CDF plot of application output error. A point (x,y) indicates 8.4% 56.3% 3.0% 8.1% 6.1% 4.3% 2.6% 6.0% 95.1% 29.7% 57.1% that y% of18.4% the6.6% output elements see error ≤ x%. kmeans sobel 9.53 8.5 ) jmeint fft inversek2j jmeint jpeg kmeans sobel swaptions geomean 4.1% 9.4% 19.7% 8.4% 7.3% 5.2% 3.3% 7.3% Percentage instructions subsumed geomean 4.57 jpeg blackscholes (c) % dynamic 0.54 1.89 instructions 2.83 subsumed. 3.79 28.2 5 swaptions inversek2j jmeint 56.26 4 3.8% 19.7% 8.4% 0.86 3.63 3.2% 18.4% 6.6% 0% 6.1% 6 2.42 sobel 17.6% 5.4% 9.4% Energy Improvement 3.75 kmeans 6.2% 8.1% sobel geomean inversek2j jmeint inversek2j 2.7% 4.1% sobel geomean Cycle Improvement fft 6.0% 3.0% kmeans Cycle Cycle Energy 97.2% 67.4% Improvement 95.9% (1.7 95.1% 56.3% Improvement Improvement (1.1336 GHz) GHz) (1.1336 GHz) blackscholes 8.4% Figure126: Whole 1.99 application3.92 speedup and saving with25.50 D-NPU, 5.88 energy 28.28 8-bit111.54 D-NPU vs. A-NPU-1 1.36 15.21 consumes 22.81 zero energy 82.21 and takes 73.76 zero A-NPU,8 and an Ideal NPU that 8-bit A-NPU Cycle Improvement Energy Improvement 5.77 6 0.67 2.44 3.67 8.56 7.57 for neural Cycle Energy cycles Cycle Cycle computation. Energy Energy 1 10 swaptions geomean Floating Point D-NPU 10.2% kmeans 2.3% sobel (b) Whole application energy saving. blackscholes sobel 40% CoreB+BDHNPU CoreB+BAHNPU 1.8% 0.5% 4.8% 2.3% CoreB+BIdealB CoreB+BDHNPU CoreB+BAHNPUblackscholes fft inversek2j jmeint jpeg 20% kmeans sobel CoreB+BIdealB Floating Point 6.0% 2.7% 6.2% 17.6% 5.4% 3.2% 3.8% 67.4% Other Instructions Percentage Energy Instructions Subsumed 8.15 43.3% A-NPU + Ideal Sigmoid blackscholes 8-bit A-NPU 5 3.1% D-NPU Percentage Instructions Subsumed 8-bit D-NPU vs. A-NPU-1 Cycle inversek2j jmeint jpeg kmeans kmeans sobel geomean Benchmarks 0 Energy (nJ) fft A-NPU 6 4 2 0 kmeans A-NPU Benchmarks blackscholes fft inversek2j jpeg inversek2j jmeint jpegspeedup. kmeans sobeljmeint geomean Whole application NPU Queue Instructions 4 2 14.1 24.5 48.0 11.8 0% NPU Queue Instructions D-NPU Applic 3.3 12.1 3.3 2% 7.3 7.3 6.1% sobel 2 19.67% 0 8.35% blackscholes 0 7.28% 0 5.21% blackscholes 0 (a) 3.34% 10 7.32% 9.42% 25.8 25.8 30.0 30.0 31.4 31.4 kmeans 4% 1.1 1.1 1.3 1.3 1.6 1.6 4 2 Benchmarks Applica'on*Energy*Reduc'on Applica'on*Energy*Reduc'on ron 3.3 6% 1.6 1.6 1.7 1.7 1.7 1.7 5.76% 12.1 8.5 8% 6 4 42.5 42.5 51.2 51.2 52.5 52.5 16 CoreB+BAHNPU Analog Sigmoid CoreB+BIdealB Fully Precise Digital Sigmoid 10% Application Level Error h 11.8 12% Percentage of Output Elements 6.10 10 8 28.28 25.5 4.1% to 10.2%. This quality-of-result loss 10is commensurate 9.53 with other work on quality trade-offs. Among digital hard8.5 ware approximation techniques, Truffle [17] and EnerJ [45] 8 shows similar error (3–10%) for some applications and much greater error (above 80%) for others in a moderate configura6 tion. Green [3] has error rates below 1% for some applications 4.57 but greater than 20% for others. A case study [36] explores 4.1 3.79 4 3.3 manual optimizations of the x264 video encoder that trade off 0.5–10% quality loss. As expected, the quality-of-results 2 degradation with an A-NPU is more than a floating point D-NPU. However, the quality losses are commensurate with 0 digital approximate computing techniques. blackscholes fft inversek2j jmeint To study the application-level quality loss in more detail, Figure 7 illustrates the CDF (cumulative distribution function) 1/3 Digital of Frequency plot of final error for each element application’s output. 1/2 Digital Frequency Each benchmark’s output a collection of elements– blackscholes fft inversek2j jmeint jpeg consists kmeans sobel of swaptions geomean an image consists of pixels; a vector consists of scalars; etc. This CDF reveals the distribution of error among an application’s output elements and shows that only a small fraction of the output elements see large quality loss with analog acceleration. The majority (80% to 100%) of each application’s output elements have error less than 10% except for jmeint. Exposing circuit limitations to the compiler. Figure 8 shows the effect of bit-width restrictions on application-level error, assuming 8 inputs per neuron. As the results suggest, exposing the bit-width limitations and the topology restrictions to the compiler enables our RPROP-based, customized CDLM training algorithm to find and train neural networks that can achieve accuracy levels commensurate with the digital approximation techniques, using only eight bits of precision for inputs, outputs, and weights, and eight inputs to the analog neurons. Several applications show less than 10% error even with fewer than eight bits. The results shows that there are many applications that can significantly benefit from analog 10 28.28 25.5 4.57 0 4.1 3.79 3.3 82.21 73 12.14 10.3 8.45 7.6 6 2 11.81 10.5 8.56 8 4 82.21 73.8 9.53 8.5 Energy Improvement 0.0173 jpeg Table 3: Error with a floating point D-NPU, A-NPU with ideal sigmoid, 8 and A-NPU with non-ideal sigmoid. 5.1 5.1 6.3 6.3 6.5 6.5 0.0126 jmeint 2.4 2.4 3.1 3.1 3.6 3.6 2.5 2.5 3.7 3.7 5.4 5.4 0.0129 8.35 0.5 0.5 0.8 0.8 1.2 1.2 9.42 19.67 6.62 1.1 1.1 1.3 1.3 1.3 1.3 2.7 2.7 2.8 2.8 2.8 2.8 8.13 18.41 inversek2j CoreB+BDHNPU CoreB+BAHNPU CoreB+BIdealB CoreB+BDHNPU 1.5 1.5 1.8 1.8 1.9 1.9 0.011 2.2 2.2 2.3 2.3 2.3 2.3 4.13 fft kmeans sobel geomean Level Error 2.3Application 2.3 6.2 6.2 3.03 jpeg 7.32% 17.8 17.8 18.8 18.8 0.0182 3.34% inversek2j jmeint 6.02% 7.9 7.9 10.21 Applica'on*Speedup Applica'on*Speedup 8.39 10 blackscholes kmeans sobel geomean 7.9 2.61% blackscholes 0 Analog Sigmoid 0% inver 1.1 1.3 1.6 7.28% 14.0 14.0 14.1 14.1 24.5 24.5 48.0 48.0 Analog Sigmoid 10.32 Application Speedup 8.35% 6.1% fft Energy Improvement 6.62% blackscholes 2% Speedup 7.58 EnergyBSaving 12.14 04.28% inversek2j jmeint jpeg 5.21% swaptions 0 se moid 8.45 0 4% 10.45 3.3 4.5 0 1 blackscholes sobel 9.42% 19.67% 2.4 2.5 1 2 kmeans 8.5 9.5 3.7 9.5 3.7 4.71 18.41% 1.8 jpeg 3.13 1.8 3.33 2 3 4.13%11.81 8.13% 2.5 3 2.08 jmeint Speedup EnergyBSaving 7.57 2.7 inversek2j 4 0.84 10.21%8.56 4.13 3.03% 25.50 73.76 2.4 1.22 16 9.71 8.39% 3.67 82.21 2.7 fft 8 5.76% 6.35 10.30 4 5 2.75 Improvement Improvement 8 % blackscholes 2.44 4.05 Analog28.28 Sigmoid 2.4 0.46 22.81 28.2 0.67 4 4.57 Fully Precise 5.88 Digital Sigmoid 15.2 82.2 6 5.49 3.63 5 15.21 15.2 82.2 5.77 apses to each 2.42 Benchmarks 3.92 10.9 10.9 14.9 14.9 1.36 4.5 1.99 3.9 28.2 0.51 8 3.9 4 12 2.4 2.33 56.26 111.54 7.6 Applic blacks fft jpeg inverse jmeint jpeg kmean sobel swapti geome Energy Speedup Application Topology blackscholes 80% Offloading 6 -> 8 -> 8 -> 1 85% Offloading 4.29879115398644 90% Offloading 5.4152844266765 95% Offloading 7.31520984460266 100% Offloading 11.2688183058235 11.2688183058235 fft 1 -> 4 -> 4 -> 2 1.24291093738476 1.26207162497662 1.28183232380289 inversek2j 2 -> 8 -> 2 3.66612081850573 4.39916488650216 5.49861846323813 7.33074108518411 10.9938617211157 jmeint 18 -> 32 -> 8 -> 2 3.05104421601116 3.49966751720672 4.10296438810026 4.9575875972808 6.26190545947988 4.9575875972808 jpeg 64 -> 16 -> 8 -> 64 1.59832986868194 1.66042238801816 1.7275342892346 1.80029983714727 1.87946485929561 1.80029983714727 kmeans 6 -> 8 -> 4 -> 1 sobel 1.30222166592591 24.5221729784241 1.32327013458615 1.30222166592591 7.33074108518411 0.871890119261146 0.864964463370785 0.858147965078337 0.851438063857892 0.844832278645737 0.851438063857892 9 -> 8 -> 1 geomean 2.18596481041593 2.36096624039658 2.56642620661238 2.8110545094951 3.10723166292606 2.8110545094951 2.10323387019544 2.31542035187076 2.60078141883403 3.02129183761473 3.7797513074705 3.02129183761473 Application Topology blackscholes 6 -> 8 -> 8 -> 1 80% Offloading 4.63801183770937 6.00293321989393 8.50623461623297 14.5907800958696 51.250425520663 fft 1 -> 4 -> 4 -> 2 1.49339422451373 1.54091152752417 1.59155204808073 1.64563417396981 1.70352109148241 inversek2j 2 -> 8 -> 2 4.41210751318201 5.60806507402552 7.69348022144627 12.2480344702273 30.0198258158588 jmeint 18 -> 32 -> 8 -> 2 4.08646628510342 5.06317341211034 6.65340510063347 9.69994502836948 17.8930069836166 jpeg 64 -> 16 -> 8 -> 64 1.87320180113408 1.9813332883883 2.10271344731737 2.23993609469231 2.39631940662302 kmeans 6 -> 8 -> 4 -> 1 1.25276901445104 1.27287802214948 1.29364312672525 1.31509697041071 1.33727439731608 sobel 9 -> 8 -> 1 2.07272551473412 2.22167873100213 2.39369814970405 2.59459132340805 2.83229403346624 2.49828814534424 2.83493584289978 3.32702119489218 4.166650961657 6.37013417935512 geomean 85% Offloading 90% Offloading 95% Offloading 100% Offloading 17.8 30.0 51.2 24.5 10.9 Figure 8: Application error with limited bit-width analog neural computation. significant improvements in accuracy and generality. 80%BOffloading Other design points. This study evaluates the performance 85%BOffloading 90%BOffloading 8 8 and energy improvements of an A-NPU 80%BOffloading assuming integration 100%BOffloading with a modern, high-performance processor. If low-power 6 6 cores are used instead, we expect to see, and preliminary 4 4 results confirm, that the performance benefits of an A-NPU increase, and that the energy benefits decrease. 2 2 Variability and noise. We designed the circuit with vari0 0 ability noise as first-order concerns, and we made several blackscholes 0 inversek2j jmeint jpeg kmeans sobel geomean blackscholes 0 and inversek2j jmeint jpeg kmeans sobel geomean design decisions to mitigate them. We limit both the input and (a) Total application speedup with limited A-NPU invocations. weight bit widths, as well as the analog neuron input count 10 80%BOffloading to eight to provide quantization margins for variation/noise. 80%BOffloading 85%BOffloading 85%BOffloading 90%BOffloading We designed the sigmoid circuit one order of magnitude more 90%BOffloading 8 80%BOffloading 80%BOffloading 100%BOffloading 100%BOffloading shallow than the digital implementation to provide additional 6 margins for variation and noise. We used a differential design, which provides resilience to noise by representing a value by 4 the difference between two signals; as noise affects the pair 2 of nearby signals similarly, the difference between the signals remains intact and the computation correct. Conversion 0 kmeans sobel geomean blackscholes 0 inversek2j jmeint jpeg kmeans sobel geomean to the digital domain after each analog neuron computation (b) Total application energy saving for limited A-NPU invocations. enforces computation integrity and reduces variation/noise susceptibility, while incurring energy and speed overheads. Figure 9: Speedup/energy saving with limited A-NPU invocations. As mentioned in Section 6, to further improve the quality of 80% Offloading acceleration without significant output quality loss. 80% Offloading 85% Offloading 85% Offloading 90% Offloading the final result, we can refrain from A-NPU invocations and 90% Offloading 95% Offloading Limited analog acceleration. We examine the effects on 95% Offloading 100% Offloading 100% Offloading fall back to the original code as needed. An online noisethe benefits when, due to noise or pathological inputs, only monitoring system could potentially limit the invocation of a fraction of the invocations are offloaded to the A-NPU. In the A-NPU to low-noise situations. Incorporating a quantithis case, the application falls back to the original code for tative noise model into the training algorithm may improve the remaining invocations. Figure 9 depicts the application robustness to analog noise. speedup and energy improvement when only 80%, 85%, 90%, Training for variability. A neural approach to approximate 95%, and 100% of the invocations are offloaded to the A-NPU. blackscholes fft inversek2j jmeint jpeg kmeans sobel geomean blackscholes fft inversek2j jmeint kmeans sobel swaptions computing presents the jpeg opportunity to correct for certain types The results suggest that even limited analog accelerators can of analog-imposed inaccuracy, such as process variation, nonprovide significant energy and performance improvements. linearity, and other forms of non-ideality that are consistent for 80% Offloading 80% Offloading 7. Limitations and Considerations 85% Offloading 85% Offloading executions on a particular A-NPU hardware instance for some 90% Offloading 90% Offloading 95% Offloading Offloading 100% Offloading period of time. After an initial training phase that accounts for 100% Offloading Applicability. Not all applications can benefit 95% from analog the predictable, compiler-exposed analog limitations, a second acceleration; however, our work shows that there are many that (shorter) training phase can adjust for hardware-specific noncan. More rigorous optimization at the circuit level, as well as idealities, sending training inputs and outputs to the A-NPU broadening the scope off application coverage by continued and adjusting network weights to minimize error. This correcadvancements at the neural transformation step, may provide 7 0.851438063857892 0.844832278645737 0.851438063857892 2.8110545094951 3 3.02129183761473 3.7797513074705 3.02129183761473 6.3 17.8930069836166 2.23993609469231 2.39631940662302 6 -> 8 -> 4 -> 1 1.25276901445104 1.27287802214948 1.29364312672525 1.31509697041071 1.33727439731608 9 -> 8 -> 1 2.07272551473412 2.22167873100213 2.39369814970405 2.59459132340805 2.83229403346624 2.49828814534424 2.83493584289978 3.32702119489218 4.166650961657 6.37013417935512 2.8 2.5 4.0 2.0 30.0198258158588 9.69994502836948 2.10271344731737 1.3 12.2480344702273 6.65340510063347 1.9813332883883 2.3 7.69348022144627 5.06317341211034 1.87320180113408 1.5 5.60806507402552 4.08646628510342 1.2 1.70352109148241 1.8 3.0 51.250425520663 1.64563417396981 4.41210751318201 geomean 4.4 sobel 100% Offloading 14.5907800958696 1.59155204808073 1.7 kmeans 4.6 64 -> 16 -> 8 -> 64 3.7 18 -> 32 -> 8 -> 2 jpeg 3.1 2 -> 8 -> 2 jmeint 95% Offloading 8.50623461623297 6.3 Energy Improvement Energy-1 4.4 2.8 2.5 2.0 1.3 2.3 1.8 1.7 1.5 1.2 4.6 3.7 3.1 2.1 2.1 0.8 0.8 90% Offloading 2.1 inversek2j 30.0 3.10723166292606 1.54091152752417 51.2 2.8110545094951 1.49339422451373 2.1 7.33074108518411 8 1 -> 4 -> 4 -> 2 0.8 1.80029983714727 fft 1.8 4.9575875972808 1.87946485929561 85% Offloading 0.8 6.26190545947988 Energy Improvement 6.2 10.9938617211157 4.9575875972808 1.80029983714727 80% Offloading 17.8 7.33074108518411 6 6.00293321989393 1.5 1.30222166592591 6 4.63801183770937 3.6 4.2 11.2688183058235 1.32327013458615 6 -> 8 -> 8 -> 1 4.0 1.30222166592591 24.5221729784241 Energy Topology blackscholes 1.3 11.2688183058235 10 80%BOffloading 85%BOffloading 90%BOffloading 80%BOffloading 100%BOffloading Application Application Topology 60% Offloading blackscholes 6 -> 8 -> 8 -> 1 2.42891052606711 3.1881815570466 4.63801183770937 8.50623461623297 51.250425520663 fft 1 -> 4 -> 4 -> 2 1.32941304492404 1.40664067630675 1.49339422451373 1.59155204808073 1.70352109148241 inversek2j 2 -> 8 -> 2 2.38102726132093 3.09293091260182 4.41210751318201 7.69348022144627 30.0198258158588 jmeint 18 -> 32 -> 8 -> 2 2.30663132833562 2.94879625663539 4.08646628510342 6.65340510063347 17.8930069836166 jpeg 64 -> 16 -> 8 -> 64 1.53755323713305 1.68886212045322 1.87320180113408 2.10271344731737 2.39631940662302 kmeans 6 -> 8 -> 4 -> 1 sobel 9 -> 8 -> 1 swaptions 1 -> 16 -> 8 -> 1 geomean 70% Offloading 80% Offloading 90% Offloading 1.178309012499 1.21439871854634 1.25276901445104 1.29364312672525 1.33727439731608 1.82765411462566 2.07272551473412 2.39369814970405 2.83229403346624 1.76097005127676 2.05223572654731 2.49828814534424 3.32702119489218 6.37013417935512 24.5221729784241 1.28183232380289 1.32327013458615 inversek2j 2 -> 108 -> 2 2.19985260892858 2.7497313266094 3.66612081850573 5.49861846323813 10.9938617211157 jmeint 18 -> 32 -> 8 -> 2 2.01687120906375 2.42843959329192 3.05104421601116 4.10296438810026 6.26190545947988 jpeg 64 -> 16 -> 8 -> 64 1.39035685940477 1.48710728068585 1.59832986868194 1.7275342892346 1.87946485929561 kmeans 6 -> 88 -> 4 -> 1 0.900738494539225 0.886079562648145 0.871890119261146 0.858147965078337 0.844832278645737 9 -> 8 -> 1 1.68606220082748 1.90374324790557 1 -> 16 -> 8 -> 1 6 2.56642620661238 Energy-1 10 3.10723166292606 9 -> 8 -> 1 swaptions 1 -> 16 -> 8 -> 1 2.49828814534424 3.32702119489218 6.37013417935512 6.3 0 blackscholes fft inversek2j jmeint 2.8 jpeg 1.7 2 1.6 1.6 geomean 4 1.3 3.1 1.6 0.8 sobel 6 1.1 3.7797513074705 2.3 0078141883403 8 1.5 3.10723166292606 3.7 6642620661238 2.3 58147965078337 0.844832278645737 17.8 10 30.0 1.87946485929561 51.2 6.26190545947988 7275342892346 1.3 10.9938617211157 0296438810026 2.4 1.32327013458615 9861846323813 Energy Improvement 24.5221729784241 8183232380289 kmeans sobel swaptions 0 2.8 1.7 2.05223572654731 1.6 2.83229403346624 1.76097005127676 1.3 2.39369814970405 1.1 2.07272551473412 2.3 1.82765411462566 1.5 2 1.33727439731608 1.63440778233613 2.3 1.29364312672525 0.8 1.25276901445104 0.9 2.39631940662302 1.21439871854634 1.4 2.10271344731737 6 -> 8 -> 4 -> 1 sobel 17.8930069836166 1.87320180113408 1.7 2.3 1.178309012499 kmeans 30.0198258158588 4 6.65340510063347 1.3 1.68886212045322 1.70352109148241 7.69348022144627 4.08646628510342 2.4 1.53755323713305 3.7 64 -> 16 -> 8 -> 64 jpeg 1.59155204808073 4.41210751318201 100% Offloading 1520984460266 8 1.49339422451373 1.6 2.94879625663539 3.1 3.09293091260182 2.30663132833562 1.6 1.40664067630675 2.38102726132093 18 -> 32 -> 8 -> 2 1.8 1.32941304492404 2 -> 8 -> 2 jmeint 2.0 1 -> 4 -> 4 -> 2 inversek2j 1.1 2 fft 1.3 2.2 2.3 4 geomean kmeans 2.18596481041593 100% Offloading Application Topology 60% Offloading 70% Offloading 80% Offloading 90% Offloading 100% 6 Offloading 1.59150802823661 1.80117697344101 2.10323387019544 2.60078141883403 3.7797513074705 blackscholes 6 -> 8 -> 8 -> 1 2.42891052606711 3.1881815570466 4.63801183770937 8.50623461623297 51.250425520663 0 % Offloading 90% Offloading 6.3 7.31520984460266 1.24291093738476 geomean 80% Offloading 17.8 4.29879115398644 1.20628350525801 swaptions 70% Offloading 30.0 3.04371757679209 1.17175303062181 sobel 60% Offloading 51.2 2.3558921269523 1 -> 4 -> 4 -> 2 Energy Improvement 6 -> 8 -> 8 -> 1 fft 6.2 Topology blackscholes Application Speedup Application 100% Offloading 1.63440778233613 Speedup-1 1.7 2.3 3 100% Offloading 1.2 9 95% Offloading Applica'on*Speedup 6 10 tion technique is able to address inter and intra-chip process variation and hardware-dependent, non-ideal analog behavior. Smaller technology nodes. This work is the start of using analog circuits for code acceleration. Providing benefits at smaller nodes may require using larger transistors for analog parts, trading off area for resilience. Energy-efficient performance is growing in importance relative to area efficiency, especially as CMOS scaling benefits continue to diminish. 8. Related Work This research lies at the intersection of (a) general-purpose approximate computing, (b) accelerators, (c) analog and digital neural hardware, (d) neural-based code acceleration, (e) and limited-precision learning. This work combines techniques in all these areas to provide a compilation workflow and the architecture/circuit design that enables code acceleration with limited-precision mixed-signal neural hardware. In each area, we discuss the key related work that inspired our work. General-purpose approximate computing. Several studies have shown that diverse classes of applications are tolerant to imprecise execution [20, 54, 34, 12, 45]. A growing body of work has explored relaxing the abstraction of full accuracy at the circuit and architecture level for gains in performance, energy, and resource utilization [13, 17, 44, 2, 35, 8, 28, 38, 18, 51, 46]. These circuit and architecture studies, although proven successful, are limited to purely digital techniques. We explore how a mixed-signal, analog-digital approach can go beyond what digital approximate techniques offer. Accelerators. Research on accelerators seeks to synthesize efficient circuits or FPGA configurations to accelerate generalpurpose code [41, 42, 11, 19, 29]. Similarly, static specialization has shown significant efficiency gains for irregular and legacy code [52, 53]. More recently, configurable accelerators have been proposed that allow the main CPU to offload certain code to a small, efficient structure [23, 24]. This paper extends the prior work on digital accelerators with a new class of mixed-signal, analog-digital accelerators. Analog and digital neural hardware. There is an extensive body of work on hardware implementations of neural networks both in digital [40, 15, 55] and analog [5, 47, 49, 32, 48]. Recent work has proposed higher-level abstractions for implementation of neural networks [27]. Other work has examined fault-tolerant hardware neural networks [26, 50]. In particular, Temam [50] uses datasets from the UCI machine learning repository [21] to explore fault tolerance of a hardware neural network design. In contrast, our compilation, neural-network selection/training framework, and architecture design aim at applying neural networks to general-purpose code written in familiar programming models and languages, not explicitly written to utilize neural networks directly. Neural-based code acceleration. A recent study [9] shows that a number of applications can be manually reimplemented with explicit use of various kinds of neural networks. That study did not prescribe a programming workflow, nor a preferred hardware architecture. More recent work exposes analog spiking neurons as primitive operators [4]. This work devises a new programming model that allows programmers to express digital signal-processing applications as a graph of analog neurons and automatically maps the expressed graph to a tiled analog, spiking-neural hardware. The work in [4] is restricted to the domain of applications whose inputs are realworld signals that should be encoded as pulses. Our approach addresses the long-standing challenges of using analog computation (programmability and generality) by not imposing domain-specific limitations, and by providing analog circuitry that is integrated with a conventional digital processor in a way that does not require a new programming paradigm. Limited-precision learning. The work in [14] provides a complete survey of learning algorithms that consider limited precision neural hardware implementation. We tried various algorithms, but we found that CDLM [10] was the most effective. More sophisticated limited-precision learning techniques can improve the reported quality results in this paper and further confirm the feasibility and effectiveness of the mixed-signal, approach for neural-based code acceleration. 9. Conclusions For decades, before the effective end of Dennard scaling, we consistently improved performance and efficiency while maintaining generality in general-purpose computing. As the benefits from scaling diminish, the community is facing an iron triangle; we can choose any two of performance, efficiency, and generality at the expense of the third. Solutions that improve performance and efficiency, while retaining as much generality as possible, are growing in importance. Analog circuits inherently trade accuracy for significant gains in energy-efficiency. However, it is challenging to utilize them in a way that is both programmable and generally useful. As this paper showed, the neural transformation of general-purpose approximable code provides an avenue for realizing the benefits of analog computation while targeting code written in conventional languages. This work provided an end-to-end solution for utilizing analog circuits for accelerating approximate applications, from circuits to compiler design. The insights from this work show that it is crucial to expose analog circuit characteristics to the compilation and neural network training phases. The NPU model offers a way to exploit analog efficiencies, despite their challenges, for a wider range of applications than is typically possible. Further, mixed-signal execution delivers much larger savings for NPUs than digital. However, this study is not conclusive. The full range of applications that can exploit mixed-signal NPUs is still unknown, as is whether it will be sufficiently large to drive adoption in high-volume microprocessors. It is still an open question how developers might reason about the acceptable level of error when an application undergoes an approximate execution including analog acceleration. Finally, in a noisy, high-performance microprocessor environment, it is unclear that an analog NPU would not be adversely affected. However, the significant gains from ANPU acceleration and the diversity of the studied applications suggest a potentially promising path forward. Acknowledgments This work was supported in part by gifts from Microsoft Research and Google, NSF award CCF-1216611, and by C-FAR, one of six centers of STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA. References [1] P. E. Allen and D. R. Holberg, CMOS Analog Circuit Design. Oxford University Press, 2002. [2] C. Alvarez, J. Corbal, and M. Valero, “Fuzzy memoization for floatingpoint multimedia applications,” IEEE TC, 2005. [3] W. Baek and T. M. Chilimbi, “Green: A framework for supporting energy-conscious programming using controlled approximation,” in PLDI, 2010. [4] B. Belhadj, A. Joubert, Z. Li, R. Héliot, and O. Temam, “Continuous real-world inputs can open up alternative accelerator designs,” in ISCA, 2013. [5] B. E. Boser, E. Säckinger, J. Bromley, Y. L. Cun, L. D. Jackel, and S. Member, “An analog neural network processor with programmable topology,” JSSC, 1991. [6] Y. Cao, “Predictive technology models,” 2013. Available: http: //ptm.asu.edu [7] M. Carbin, S. Misailovic, and M. C. Rinard, “Verifying quantitative reliability for programs that execute on unreliable hardware,” in OOPSLA, 2013. [8] L. N. Chakrapani, B. E. S. Akgul, S. Cheemalavagu, P. Korkmaz, K. V. Palem, and B. Seshasayee, “Ultra-efficient (embedded) SOC architectures based on probabilistic CMOS (PCMOS) technology,” in DATE, 2006. [9] T. Chen, Y. Chen, M. Duranton, Q. Guo, A. Hashmi, M. Lipasti, A. Nere, S. Qiu, M. Sebag, and O. Temam, “BenchNN: On the broad potential application scope of hardware neural network accelerators,” in IISWC, 2012. [10] F. Choudry, E. Fiesler, A. Choudry, and H. J. Caulfield, “A weight discretization paradigm for optical neural networks,” in ICOE, 1990. [11] N. Clark, M. Kudlur, H. Park, S. Mahlke, and K. Flautner, “Applicationspecific processing on a general-purpose core via transparent instruction set customization,” in MICRO, 2004. [12] M. de Kruijf and K. Sankaralingam, “Exploring the synergy of emerging workloads and silicon reliability trends,” in SELSE, 2009. [13] M. de Kruijf, S. Nomura, and K. Sankaralingam, “Relax: An architectural framework for software recovery of hardware faults,” in ISCA, 2010. [14] S. Draghici, “On the capabilities of neural networks using limited precision weights,” Elsevier NN, 2002. [15] H. Esmaeilzadeh, P. Saeedi, B. N. Araabi, C. Lucas, and S. M. Fakhraie, “Neural network stream processing core (NnSP) for embedded systems,” in ISCAS, 2006. [16] H. Esmaeilzadeh, E. Blem, R. St. Amant, K. Sankaralingam, and D. Burger, “Dark silicon and the end of multicore scaling,” in ISCA, 2011. [17] H. Esmaeilzadeh, A. Sampson, L. Ceze, and D. Burger, “Architecture support for disciplined approximate programming,” in ASPLOS, 2012. [18] H. Esmaeilzadeh, A. Sampson, L. Ceze, and D. Burger, “Neural acceleration for general-purpose approximate programs,” in MICRO, 2012. [19] K. Fan, M. Kudlur, G. Dasika, and S. Mahlke, “Bridging the computation gap between programmable processors and hardwired accelerators,” in HPCA, 2009. [20] Y. Fang, H. Li, and X. Li, “A fault criticality evaluation framework of digital systems for error tolerant video applications,” in ATS, 2011. [21] A. Frank and A. Asuncion, “UCI machine learning repository,” 2010. Available: http://archive.ics.uci.edu/ml [22] S. Galal and M. Horowitz, “Energy-efficient floating-point unit design,” IEEE TC, 2011. [23] V. Govindaraju, C. Ho, and K. Sankaralingam, “Dynamically specialized datapaths for energy efficient computing,” in HPCA, 2011. [24] S. Gupta, S. Feng, A. Ansari, S. Mahlke, and D. August, “Bundled execution of recurring traces for energy-efficient general purpose processing,” in MICRO, 2011. [25] N. Hardavellas, M. Ferdman, B. Falsafi, and A. Ailamaki, “Toward dark silicon in servers,” IEEE Micro, 2011. [26] A. Hashmi, H. Berry, O. Temam, and M. Lipasti, “Automatic abstraction and fault tolerance in cortical microarchitectures,” in ISCA, 2011. [27] A. Hashmi, A. Nere, J. J. Thomas, and M. Lipasti, “A case for neuromorphic ISAs,” in ASPLOS, 2011. [28] R. Hegde and N. R. Shanbhag, “Energy-efficient signal processing via algorithmic noise-tolerance,” in ISLPED, 1999. [29] Y. Huang, P. Ienne, O. Temam, Y. Chen, and C. Wu, “Elastic cgras,” in FPGA, 2013. [30] C. Igel and M. Hüsken, “Improving the RPROP learning algorithm,” in NC, 2000. [31] D. A. Johns and K. Martin, Analog Integrated Circuit Design. John Wiley and Sons, Inc., 1997. [32] A. Joubert, B. Belhadj, O. Temam, and R. Héliot, “Hardware spiking neurons design: Analog or digital?” in IJCNN, 2012. [33] S. Li, J. H. Ahn, R. D. Strong, J. B. Brockman, D. M. Tullsen, and N. P. Jouppi, “McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures,” in MICRO, 2009. [34] X. Li and D. Yeung, “Exploiting soft computing for increased fault tolerance,” in ASGI, 2006. [35] S. Liu, K. Pattabiraman, T. Moscibroda, and B. G. Zorn, “Flikker: Saving dram refresh-power through critical data partitioning,” in ASPLOS, 2011. [36] S. Misailovic, S. Sidiroglou, H. Hoffman, and M. Rinard, “Quality of service profiling,” in ICSE, 2010. [37] N. Muralimanohar, R. Balasubramonian, and N. Jouppi, “Optimizing NUCA organizations and wiring alternatives for large caches with CACTI 6.0,” in MICRO, 2007. [38] S. Narayanan, J. Sartori, R. Kumar, and D. L. Jones, “Scalable stochastic processors,” in DATE, 2010. [39] A. Patel, F. Afram, S. Chen, and K. Ghose, “MARSSx86: A full system simulator for x86 CPUs,” in DAC, 2011. [40] K. W. Przytula and V. K. P. Kumar, Eds., Parallel Digital Implementations of Neural Networks. Prentice Hall, 1993. [41] A. Putnam, D. Bennett, E. Dellinger, J. Mason, P. Sundararajan, and S. Eggers, “CHiMPS: A high-level compilation flow for hybrid CPUFPGA architectures,” in FPGA, 2008. [42] R. Razdan and M. D. Smith, “A high-performance microarchitecture with hardware-programmable functional units,” in MICRO, 1994. [43] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning internal representations by error propagation,” in Parallel Distributed Processing: Explorations in the Microstructure of Cognition. MIT Press, 1986. [44] M. Samadi, J. Lee, D. A. Jamshidi, A. Hormati, and S. Mahlke, “Sage: Self-tuning approximation for graphics engines,” in MICRO, 2013. [45] A. Sampson, W. Dietl, E. Fortuna, D. Gnanapragasam, L. Ceze, and D. Grossman, “EnerJ: Approximate data types for safe and general low-power computation,” in PLDI, 2011. [46] A. Sampson, J. Nelson, K. Strauss, and L. Ceze, “Approximate storage in solid-state memories,” in MICRO, 2013. [47] J. Schemmel, J. Fieres, and K. Meier, “Wafer-scale integration of analog neural networks,” in IJCNN, 2008. [48] R. St. Amant, D. A. Jiménez, and D. Burger, “Mixed-signal approximate computation: A neural predictor case study,” IEEE MICRO Top Picks, vol. 29, no. 1, January/February 2009. [49] S. M. Tam, B. Gupta, H. A. Castro, and M. Holler, “Learning on an analog VLSI neural network chip,” in SMC, 1990. [50] O. Temam, “A defect-tolerant accelerator for emerging highperformance applications,” in ISCA, 2012. [51] S. Venkataramani, V. K. Chippa, S. T. Chakradhar, K. Roy, and A. Raghunathan, “Quality-programmable vector processors for approximate computing,” in MICRO, 2013. [52] G. Venkatesh, J. Sampson, N. Goulding, S. Garcia, V. Bryksin, J. LugoMartinez, S. Swanson, and M. B. Taylor, “Conservation cores: Reducing the energy of mature computations,” in ASPLOS, 2010. [53] G. Venkatesh, J. Sampson, N. Goulding, S. K. Venkata, M. Taylor, and S. Swanson, “QsCores: Trading dark silicon for scalable energy efficiency with quasi-specific cores,” in MICRO, 2011. [54] V. Wong and M. Horowitz, “Soft error resilience of probabilistic inference applications,” in SELSE, 2006. [55] J. Zhu and P. Sutton, “FPGA implementations of neural networks: A survey of a decade of progress,” in FPL, 2003.