From: AAAI Technical Report WS-97-09. Compilation copyright © 1997, AAAI (www.aaai.org). All rights reserved.
Effective Knowledge
Navigation For ProblemSolving
Using HeterogeneousContent Types
Ralph Barletta and Philip Klahr
Inference Corporation
100 Rowland Way
Novato CA, 94945
ralph.barletta@inference.com
phil.klahr@inference.com
Introduction
Over the past few years manycompanieshave begun emphasizing and implementing processes to capture
and share knowledgewithin their organizations [Davenport &Prusak, 1997; Edvinsson &Malone, 1997;
Stewart, 1997]. Corporateinfrastructures are being developedto facilitate knowledgecreation and reuse,
and a variety of software tools are currently available to support the knowledgemanagement
(creation,
storage, maintenanceand retrieval) process. The maingoal of these efforts is to shorten and improvethe
problemsolving process by providing access to relevant knowledge.Businesses want to build knowledge
managementsystems to solve some of these important problems:
¯ "How do I do X?"
¯
"Has X been done before? If so, how?"
¯
"Whatdid we do to handle this problemthe last time somethinglike it happened?"
Problemsolving knowledgecomesin a variety of forms. Muchof the information we currently collect for
purposes of problemsolving reuse is unstructured: documents,technical notes, policy manuals,e-mails,
presentations, etc., contain a wealth of corporate information that can be useful for problemsolving. A
smaller, but still significant fraction of corporateinformationthat can be useful for problemsolving is in a
highly structured form (typically stored in a database): Customerand demographicdata, sales transactions,
financial data, etc.. Therapid growthof data warehousesfor decision support is a clear indication of the
perceived value of structured data for problemsolving. A smaller still, but rapidly growingform of
information that companiesare collecting is in the form of semi-structured, problem/solutionpairs, or cases
as they are commonly
called. A case [Kolodner, 1993] describes ~ particular problemor scenario that was
encounteredand the solution to that problem/scenario. For example, in a customer support domain, a case
mightconsist of a software failure a user was having, the diagnostic information that was collected to isolate
the cause of the problem and a recommended
fix for the problem[Klahr, 1997]. The collection and use of
cases is of growinginterest in the knowledgemanagement
area because this type of knowledgeis more
explicitly geared towards reuse in a problemsolving context.
Giventhe desire to collect these different formsof information, an organization needssoftware tools for
storing, and more importantly, retrieving the information. Groupwaretools like Notes have been useful in
providing a frameworkfor collecting unstructured and semi-structured information, while relational
database vendors have long provided tools for collecting structured (and semi-structured) information. With
the recent emergenceof "Universal Servers", we are starting to see the potential for a single storage
repository for all types of information, structured semi-structured and unstructured. Technologically,
information storage is not the major hurdle in implementing knowledgemanagementsystems. The major
technological hurdle in implementingeffective knowledgemanagement
systems is in providing effective
navigation and search tools for finding contextually relevant information to a given problemat hand.
This paper proposes an architecture for knowledgenavigation based on our experience in implementing
knowledgesystems for business users, predominantly through the use of cases as the main knowledge
source. This architecture is geared toward searching amongheterogeneous sources of knowledgeusing an
interactive, question driven approachthat we have found to be highly successful in case-based retrieval
systems. Our frameworkaddresses the needs of business users whoare trying to solve business problems,
such as diagnosing customer problems, matchingavailable products to the needs of customers, clarifying
companypolicies and procedures for employees, and even designing new products. These are all
knowledgeactivities that can benefit from corporate knowledgecaptured and effectively searched and
reused.
ProblemSolving In The "Knowledge
Triangle"
The figure below showsthe various different types of knowledgethat are used for problemsolving. As the
figure indicates, knowledgecloser to the bottomis moreprecious for problemsolving and harder to come
by than knowledgein higher layers.
Cost To
Acquire
Solving
Value
High
Automated
Knowledge
Automated Knowledge
At the bottom of the triangle is "AutomatedKnowledge".Automatedknowledgeis essentially knowledge
that can either automatically recognize a problemand/or automatically apply a fix to the problem.In the
case of computer hardware, automated knowledgemight recognize a configuration problem and
automatically apply an adjustment to the configuration. In a marketing application, automated knowledge
might recognize an opportunity to put a product on sale and automatically mark downthe appropriate items
or send out a targeted mailing. Automatedknowledgeis extremelyhigh value but is also very costly to
create and maintain. That is whyit tends to be available only whenit is cost justified to encodeknowledge
in such a detailed way. Automatedknowledgeis often represented as a rule-based or case-based expert
systemthat has been enhancedwith procedural code (scripts) for collecting data and activating the
appropriate action.
Cases
AboveAutomatedKnowledgeare non-automated, Problem/Solution pairs or cases. Cases are used to
represent a specific set of problemscenarios and their associated resolutions. Intuitively, any time a
problemis encountered, the most ideal form of information (beyondautomated knowledge)is to provide the
user with a specific past examplethat mirrors their current problem. Anytime a newproblemis solved it
10
presents us with an opportunity to create a new case. By learning newcases in this way, the knowledge
navigation process gets smarter over time.
The main difference between automatedknowledgeand cases is in the lack of automationscripting. In
manydomains, it is impossible to automatethe gathering of probleminformation or the application of a
solution. This certainly does not diminish the value of collecting non-automated,case knowledge.
The maindifficulty with knowledgein the form of cases is that cases can be expensiveto build and
maintain, relative to things like documentsor databases. Giventhis, cases are most often used to handle
commonly
occurring, well understood problemsor scenarios that are worth spending the time to structure
into case form. For manyorganizations, case knowledgeis often madeavailable to less knowledgeable
personnelor customersfor self-help applications due to the fact that a case can provide an easily
interpretable solution to a commonlyoccurring problem. Morecomplexproblems are better handled by
domainexperts whocan combinetheir expertise with harder to interpret, documentoriented knowledge
available at higher levels of the triangle.
Databases
Certainly, databases have been a mainstayin businesses for a long time. However,it is only recently that
they have been pushedas a key element in building decision support systems, and it is in this context that
databases are relevant to knowledgemanagement.The advent of data warehouses, multi-dimensional
databases, data mining, and on-line analytical processing (OLAP)have signaled the movefrom viewing
data and databases in the domainof the "back office" to viewing data and databases as important
knowledgesources for "front office" problemsolving.
Whilestructured data exists in muchgreater abundancethan automatedknowledgeor cases, it is not
typically organized in a waythat facilities its use for problemsolving. Problemsolving takes place by
mappinga general question like "Howis product X doing relative to its competitors" into complexSQL
statements that produce graphs or tables that must then be interpreted by the user. This makesdatabases
somewhatless attractive for problemsolving than cases or automatedknowledgebecause it requires the
user to knowmoreabout the data and howto formulate a goodquery than is necessary for cases or
automated knowledge. Nevertheless, databases contain complementaryknowledgethat must be taken into
account went building a knowledgenavigation architecture.
CorporateRepositories& Public Internet Sites
The top levels of the knowledgetriangle are predominantlyrepresented as freeform documentcollections.
This information is abundantand contains a wealth of potentially valuable problemsolving information.
The difference betweencorporate repositories and public internet sites is that one is under organizational
control and the other isn’t. Control over the repository effects the quality and form of the informationand
its relevance to the organizationsusers. For this reason, despite the fact that both sources of content are
searched using text retrieval, they are represented in different layers in the triangle. Wegenerally would
prefer corporate information to public information in the context of solving most problemsof corporate
interest.
Whatmakestext storage and retrieval attractive to manycompaniesas their main knowledgemanagement
paradigmis that it is relatively easy to write up a documentin any formand on any subject that will be
accessible via the search engine. While, this certainly makeslife easy for the knowledgeauthor,
unfortunately, it makeslife very difficult for the knowledgesearcher. Text search typically suffers from
lack of precision and recall, particularly whenused in a specific problemsolving context. Usually, too many
documentsare retrieved or they are not the best ones because the user doesn’t knowhowto phrase their
queryrelative to the problemthey are trying to solve.
In general, after formingan initial keywordor natural languagequeryto a text retrieval engine, the user has
one of two unattractive options:
11
1.
2.
Play the "guessing game": Whatkeywordscan I add that will reduce the hit set to a more manageable
size?
Play the "next 20 hits game":CanI find a document(by examiningthe titles) in the first several
hundredthat are close enoughto what I want to use relevance feedbackto refine the query.
Anyoneinteracting with Internet or local text search engines understandsthe tremendousfrustration
involved in playing either (or a combination)of these time consuming"games"whentrying to do real work
(as opposedto just surfing). Whatis neededis a better approachfor assisting the user in formulatingand
refining text retrieval queries so that they can either quickly find whatthey are lookingfor or at least
quickly determinethat what they are looking for doesn’t exist.
The KnowledgeFactory & KnowledgeNavigation
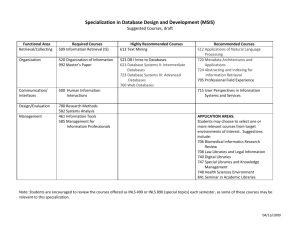
In our view, a complete knowledgemanagementsolution needs to address two major components:
1.
2.
A Factory componentfor establishing the processes to create, monitor, maintain and extend knowledge.
A Navigation componentfor effectively accessing and retrieving knowledge.
Both of these componentsare critical to successful knowledgemanagement.The first deals with creating
useful knowledgecontent, and avoiding the "garbagein, garbage out" syndrome.It is this area that has
been given the most emphasisin knowledgemanagement
efforts, i.e., allowing users to capture their
knowledge,typically in an unstructured form, and makethat knowledgeavailable to other membersof the
organizationor directly to customers(e.g., in electronic manuals,on-line notes, etc.). Wewill not elaborate
on this knowledgemanagement
element other than to say that our approach to the addressing it is to
establish a KnowledgeFactory for creating, maintaining and extending knowledge. The Knowledge
Factory defines the processes (similar to the steps in an manufacturingassemblyline), the tasks to
accomplishedin each process (the deliverables), tools to be used (the machines), and the skills required
definitions). (See, for example, [Borron, Morales &Klahr, 1996] and [Thomas,Foil &Dacus, 1997].)
The KnowledgeFactory needs to be a permanentand evolving structure for it to be effective on an on-going
basis.
The second componentof effective knowledgemanagement,and the main focus of this paper, is called
KnowledgeNavigation. KnowledgeNavigation is the process of finding relevant problem solving
knowledgeamongall the available knowledgein the repository. This navigation process is just as important
as the KnowledgeFactory, but up to nowhas been predominantly viewed and implementedas an open
ended, user driven, text retrieval task. This current approachto navigation is unacceptablefor several
important reasons:
1. As we have claimed, problemsolving knowledgecomesin a variety of forms, including cases and
databases. Thesetypes of knowledgecan play a vital role in effective problemsolving and neither are
well served by text retrieval approaches.
2. Companiesthat take a pure text retrieval approach to knowledgenavigation are finding that casual or
uninformedusers of the knowledgerepository are not capable of formulating effective queries to find
relevant documents.Current interactions with Internet search engines provide clear examplesof the
difficulty in quickly finding relevant knowledgeto suit a user needs based on keywordsearch.
3. Evenwhenusers do find useful unstructuredinformation, they often find it difficult to interpret the
resulting knowledgein the context of the particular problemthey are trying to address.
4. There is no learning mechanismin place that will improveaccess to frequently used documentsand
convert them over time to morestructured forms (like cases) that are moreeasily searched and
interpreted.
Our approach to addressing the current shortcomingsin knowledgesearch involves the creation of an
intelligent Knowledge
Navigatorthat is able to provide a consistent, user friendly, navigational metaphor
across heterogeneoussources of content (text, cases, and databases) using the appropriate search engine
12
technology for each source (see figure below). The navigational metaphorwe are proposing is a dialogbased one in whichthe system promptsthe user with questions that help them narrowthe search for relevant
information. Questiongeneration is intelligent in the sense that the questions are posed relative to the
current context of the search rather than as a static tree.
Unstructured
Knowledge
Semi-structured
Knowledge
Structured
Knowledge
-Documents
-Manuals
- Cases
Diagnostic
- Demographic Data
- Customer Data
-Technical Notes
How To
- E-Mail
- Presentations
Designs&Plans
- FinancialData
Policies &Procedures
- Sales & Product Data
1. Search
Arbitration
4. Navigation
Learning
2. Search
Refinement
5. Knowledge
Acquisition
3. Search
Escalation
The major architectural componentsof the knowledgenavigator we are proposing are:
1. Search Arbitration: This is the process of determining whichsource is the most likely to have content
of relevance in solving the problem.
2. Search Refinement:Oncea particular content source is selected as being potentially relevant, search
refinement is the process of quickly either finding the relevant informationor quickly determiningthat
the relevant information is NOTin this content source.
3. SearchEscalation: If the informationis not in the selected content source, search escalation is the
process of transitioning the search from one source to another. The key to goodsearch escalation is in
building a goodquery for the escalated search based on the information collected at the previous
content source.
4. Navigational Learning:If useful informationis found it is importantto improveaccess to that
information for future users. Navigational learning involves incrementally improvingthe search
arbitration and refinement process based on user success and failure in previous search.
5. Knowledge
Acquisition: As knowledgeis frequently accessed in a less structured content source (i.e.,
documentsor the internet), knowledgeacquisition is the process of movingknowledgedownthe
knowledgetriangle towards morestructured forms (like cases) that are more easily accessible by less
informed users of the knowledgein subsequent searches.
13
Discussion
The KnowledgeFactory and KnowledgeNavigation are clearly dependent on one another. While the
knowledgerepository could contain a wealth of well formedknowledge,if a user cannot effectively
navigate through the knowledgequickly and efficiently in the context of their problem,the knowledgeis
effectively useless. Similarly, allowing users to arbitrarily add knowledgeto the repository without
establishing an effective knowledgefactory for all the different forms of knowledgecontent will defeat the
ability of any navigational software to be effective in helping users solve problems.
The major point of this paper has been to emphasizethe fact that problemsolving knowledgecomesin a
variety of forms, not all of themtext. Giventhis, it is critical that any knowledgemanagement
systemthat
proposes to help people solve problemsmust figure out a way to create and navigate through this
heterogeneousknowledgein a waythat goes beyondusing a wordprocessor and a text retrieval engine, as
is often the case today. Wehave proposed an architecture that enables the navigation through this
heterogeneouscontent by using a common,dialog based search approach, with questions posed to the user
in the context of their current problemsolving needs.
References
Borron, J., Morales, D., and Klahr, P. Developing and Deploying Knowledgeon a Global Scale. In
Proceedingsof the Thirteenth National Conferenceon Artificial Intelligence and the Eighth Innovative
Applications of Artificial Intelligence Conference(IAAI-96), AAAIPress, MenloPark, California, 1996,
1443-1454.
Davenport, T. H., and Prusak, L. Working Knowledge: ManagingWhat Your Organization Knows.
Harvard Business School Press, Cambridge,Massachusetts, 1997 (forthcoming).
Edvinsson, L., and Malone, M. S. Intellectual Capital, Realizing Your Company’sTrue Value by Finding
Its Hidden Brainpower. HarperCollins Publishers, NewYork, 1997.
Klahr, P. Getting Downto Cases: Seven Principles for an Effective CBRStrategy. PCALV. 11, N. 1,
January/February 1997, 16-19.
Koldoner, J. Case-Based Reasoning. MorganKaufmanPublishers, San Mateo, California, 1993.
Stewart, T. A. Intellectual Capital, The NewWealth of Organizations. Doubleday, NewYork, 1997.
Thomas,H., Foil, R., and Dacus, J. NewTechnologyBliss and Pain in a Large CustomerService Center.
In Proceedings of the 2nd International Conference on Case-BasedReasoning, Springer, 1997
(forthcoming).
14