GeometricComparison
of Classifications and Rule Sets,
From: AAAI Technical Report WS-94-03. Compilation copyright © 1994, AAAI (www.aaai.org). All rights reserved.
¯ Trevor J. Monk,R. Scott Mitchell, Lloyd A. Smith and Geoffrey Holmes
Department of Computer Science
University of Waikato
Hamilton, NewZealand
tmonk@cs.waikato.ac.nz,rsm 1 @cs.waikato.ac.nz, las @waikato.ac.nz,geoff@waikato.ac.nz
Abstract
Wepresent a technique for evaluating classifications by geometric comparison of rule sets, Rules ~e represented as objects in an n-dimensional
hyperspace. The similarity of classes is computedfrom the overlap of the
geometricclass descriptions, Thesystem producesa correlation matrix that
¯ indicates the degree of similarity betweeneach pair of classes. Thetechnique can be applied to classifications generated by different algorithms,
with different nt~mbersofclasses and different attribute sets. Experimental
results from a case study in a medical domainare included.
MachineLearning, Classification,
1. Introduction
Inductive learning algorithms fall into two
broad categories based on the learning strat,
egy that is used. In supervised learning
(learning from examples) the system is provided with examples, each of which belongs
¯ to one of a finite numberof classes. Thetask
of the learning algorithmis to inducedescriptiojas of eachclass that will correctly classify
both the training examplesand the unseentest
eases. Unsupervised learning, on the other
hand, does not require pre-classified exampies. Anunsupervised algorithm will attempt
to discover its ownclasses in the examplesby
clustering the data. This learning mechanism
is often referred to as ’learning by observation
and discovery.’
Oneof the most importantcriteria for evaluating alearning schemeis the quality of the
class descriptions it produces. In general,
manydescriptions can be found that cover
the examples equally well, but most perform
badly on unseen cases. Techniques are required for evaluatingthe quality of classifications, either with respect to a classification or
Simplyrelative to each other.
This paper presents anew method for comparing classifications, using a geometricrepresentation of class descriptions. Thesimilarity of classes is determinedfromtheir overlap
Rules, GeometricComparison
in an n-dimensional hyperspace. The technique has a numberof advantages over existing statistical or instance-basedmethodsof
comparison:
Descriptions are producedthat indicate how
twoclassifications are different, rather than
simply howmuchthey differ.
¯ The algorithm bases its evaluation on descriptions of theclassifications (expressed
as productionrules), not on the instances in
the training set. This approachwill tend to
smoothout irregular or anomalousdata that
¯ might otherwise give misleading results.
Classifications using differing numbersor
groups of attributes can be compared,provided there is some overlap between the
attribute sets.
Thetechnique will workwith any clustering
schemewhoseoutput can be expressed as a
set of productionrules.
In this study, the geometric comparison
technique is used to evaluate the performance
of :a clustering algorithm (AuToCLAsS)in a
medical domain. Twoother techniques are
:also used to comparethe automatically generated classifications against a clinical classification producedby experts.
* This project was funded by the New
Zealand Foundation for Research in Science
and Technology
KDD-94
AAAI-94 Workshop on Knowledge Discovery in Databases
Page 395
1.1. Comparlng
Classlflcatlons and Rule
Sets
Regarding evaluation of unsupervised
’clustering’ type methods,Michalsld & Stepp
(1983)state that:
The problem of howto judge the quality of a clustering is difficult; and there
seems to be no universal answer to it.
¯ One can, however, indicate two major
criteria. Thefirst is that the descriptions
formulatedfor clusters (classes) should
be ’simple’, so that it is easy to assign
¯ objects to classes and’ to differentiate between the classes. This criterion alone,
however,could lead to trivial and arbitrary classifications. The second criterion is that class descriptions should’fit
well’ the actual data. To achieve a very
precise ’fit’, however,a description may
have to be complex. Consequently, the
demandsfor simplicity and good fit are
conflicting, and the solution is to find a
balance betweenthe two."
Accuracyis a measureof the predictive ability of the class description whenclassifying
unseen test cases. It is usually measured
by the error rate--the proportion of incorrect
predictions on the test set (Mingers, 1989).
Accuracyis often used to measureclassification quality, but it is knownto have several defects (Mingers, 1989; Kononenko
Bratko, 1991). An information-based measure of classifier performance developed by
Kononenko& Bratko (1991) eliminates these
problemsand provides a more useful measure
of quality in a variety of domains.
Theremainderof this paper is organised as
follows. The next section briefly describes
WEKA,amachine learning workbench cur¯/
rently under developmentat the University of
Waikato.̄ This includes an overview of the
AUTOCLASS
and C4.5 algorithms used in our
experiment. Section 3 describes our experimemalmethodology and the algorithm used
by the geometric rule set comparisonsystem.
Results of the experiment, using a diabetes
data set, are presented in Section 4. These
results are discussed in Section 5, including
someanalysis of the performanceof the geoThe CLUS’m~2
algorithm used a combined metric comparisonalgorithm. Section 6 conmeasure of cluster quality based on a num, tains someconcluding remarks and ideas for
her Of elementarYcriteria including the ’sim- further researchin this area.
: plie~ty of description’ and ’goodnessof fit’
mentionedabove (Michalski & Stepp, 1983).
2, The WEKAWorkbench
Hansen& Bauer (1987) use an informationthe’oretic measureof cluster quality in their
~ the Waikato Environment for
WEKA,
WITTsystem. This cohesion metric evaluKnowledgeAnalysis, is a¯ machine learning
ates clusters in termsof their within-class and workbench currently under development at
¯ between-classsimilarities, using the training ¯ the University of Waikato(McQueen,
et. al,
examples that have been assigned to each
1994). The purpose of the workbenchis to
class. Other ¯measuresare based on the class
give users access to manymachinelearning
descriptionsmin the form of decision trees,
algorithms, and to apply these to real-world
rules or a ’concept hierarchy’ as used by
data.
O~MEM
(Lebowitz, 1987) or COBWEB
(Fisher,
WEKA
provides a uniform interactive in1987). Someclustering systems produceclass
terface
tea variety of tools, including madescriptions as part of their normal, operachine
learning
schemes, data manipulation
tion while others, such as AUTOCLASS
(Cheese,
programs,
and
the
LtsP-S’rATstatistics and
man,et. al., 1988) merely assign examplesto
graphics
package
(Tierney,
1990). Data sets
classes. In this Case, a supervised learning
to
be
manipulated
by
the
workbench
use the
algorithm such as C4.5 (Quinlan, I992) can
ARFF
(Attribute-Relation
File
Format)
interbe used to induce descriptions for the classimediate
file
format.
An
ARFF
file
records
infication. This is the methodused in this study
formation
about
a
relation
such
as
its
name,
atfor evaluating AUTOCLASS
clusterings.
tribute names,types and values, and instances
Mingers(1989) uses the two criteria size
(examples). The WEKA
interface is impleand accuracyfor evaluating a decision tree i mented usingthe TK X-Windowwidget set
(or an equivalent set of rules). Following under the "ICEscripting language(Ousterhout,
the principle of Occam’sRazor, it is generally accepted that the fewer terms in a model 1 The nameis taken from the weka, a small,
the better; therefore, in general, a small tree
inquisitive native NewZealandbird related to
or rule set will performbetter on test data.
the well-knownKiwi.
Page 396
AAAI-94 Workshop on Knowledge Discovery in Databases
KDD-94
Choose
¯ file;,
. ~.
¯
. ,.,~enthec1~1;..~ ’ "¯ "
z ¯ ’1":
~" Z
...thena scheme.
,
1.02137
¯ RELATION:
dlMmt~ ’
&TTRIOUTE8~
i7
INSTANCES:
146
-
important
Included
~. rl
[] . .! #O02~mlaUve_welght
ii
-
C4~i NVol
Spreadsheet
ViewData
1~dlltMlMrout NIn ME-Group
[]
#O09:aclass
!:
Histogram
Stathales
:
~ [~ : ;l’?1#011~las~:
Quit
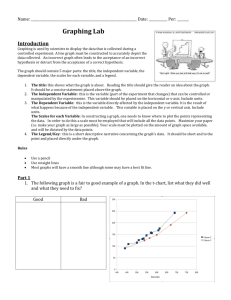
Figure 1. The WEKA
Workbench
1993). ARFFfilters and data manipulation
programs are written in C. WEKA
runs under
UNIXon Sun workstations, Figure 1 showsan
exampledisplay presented by the workbench.
ID3 (Quinlan, 1986). The basic ID3 algorithm
has been extensively described, tested and
modified since its invention (Mingers, 1989;
Utgoff, 1-989) ’and will not be discussed in
detail here. However,C4.5 adds a numberof
enhancementsto ID3, which are worth examining.
2.1. AutoClass
AUTOCLASS
is an unsupervised induction alC4.5uses a new’gain ratio’ criterion to de~orixhrnthat automatically discovers ¯classes
termine
howtO split the examplesat each node
In a databaseusing a Bayesianstatistical techof
the
decision
tree. C4.5. This removesID3’s
nique. The Bayesian approach has several
strong
bias
towards
tests with manyoutcomes
advantages over other methods (Cheeseman,
(Quinlan,
1992),
Additionally,
C4.5 allows
et.:al., 1988). Thenumberof classes is detersplits
to
be
made
on
the
values
of
continuous
minedautomatically; examples are assigned¯
(real
and
integer)
attributes
as
well
as enumerwith a probability to eachclass rather than ab’
ations.
i s01utelyto a singleclass; all attributes are potentially significant to the classification; and
Decisiontrees inducedby I D3are often very
the exampledata can be real or discrete.
complex,with a tendencyto ’over-fit’ the data
An AUTOCLASS
run proceeds entirely with- (Quinlan, 1992). c4.5 provides a solution
out supervision from the user. The program this ¯ problemin the form of pruned decision
trees or production rules. Theseare derived
continuouslygenerates classifications until a
user-speeifiedtime has elapsed. Thebest clas-, from the original decision tree, and lead to
structures that generallycoverthe training set
Sification found is saved at this poinLA variety of reports can be produced-fromsaved tess thoroughly but performbetter on unseen
Cases. Pruned trees and rules are roughly
classifications. ¯ A WEKA
filter has been writequivalent in termsof their classification ac~ten that extracts the most probable class for
curacy; the advantage of a rule representaeach instance, and outputs this informationin
tion is that it is morecomprehensibleto peoa form suitable for inclusion in an ARFF
file.
ple
than a decision tree (Cendrowska,1987;
¯ This allows theAuTOCLASS
classification to be
Quinlan, 1992).
used as input to other programs,such as rule
and decision tree inducers.
Thefirst stage¯ in rule generationis to turn
,
the
initial decision tree ’inside-out’ and gen2.2. C4.5
erate a rule corresponding to each leaf. The
resulting rules are then generalised to remove
04.5 (Quinlan, 1992)is a powerful tool for
inducing decision trees and production rules
conditions that do not contribute to the accufrom a set of examples. Muchof C4.5 is deracy of the classification. Aside-effect of this
rived fromQuinlan’searlier induction system, process is that the rules are no longer exhausKDD-94
AAAI-94 Workshop on Knowledge Discovery in Databases
Page 397
tive or mutually exclusive (Quinlan, 1992).
C4.5 copes with this by using ’ripple-down
rules’ (Compton,et. al., 1992). Therules are
Ordered, and any exampleis then classified by
the first rule that coversit. In fact, only the
classesare ranked, with the twin advantages
that the final rule set is moreintelligible and
the order of rules within each class becomes
irrelevant (Quinlan,1992). c4.5 also defines
default class that is used to classify examples
not coveredby any of the rules.
x~x~
x
.:
x
~X
xX
480
xXx%
x’ e¢.
x
~.~?....
¯
v
SSPG
~**.,~
29
748
9
¢
¢
Insulin
¯ ." .,0
.-:g...~
,." ¯
,X
~’
XX
10
1.57e+03
XX X
X X
3. Methodology
X
Glucose
3.1. TheDataSet
X
X
xX x
X
x
X
x~
X x
>k X
:.~.,.~..,,,.,
:,.’~e~",~.:
269
Reavenand Miller (1979) examinedthe re!ationship between Chemicaland Overt diaFigure 2. Scatterplotmatrixofdiabetesdata
betes in 145 non-obese subjects. The data
set used in this study involvessix attributes:
¯ Normal class
patient age, patient relative weight, fasto Chemical class
ing ¯ plasma Glucose, Glucose, Insulin and
× Overt class
steady state plasma Glucose (SSPG). The
and SSPG),giving a single point in 3-space.
data set also involves twoclassifications, labeled CClass and EClass--presumably repreEach instance is assigned to the class whose
senting’clinical classification’ and’electronic meanlies closest to it (in terms of the miniclassification’. Eachclassification describes mumEuclidean distance). After each instance
three classes: Overt diabetics, those requiring has been assigned to a class, the class means
Insulin injections; Chemical¯diabetics, ¯whose are recalculated. The process of assigning
condition maybe controlled by diet; and a~ instances to classes and recalculating class
Normal group, those without any form of
meansrepeats until no patients are reassigned.
diabetes. The same data set is used in the
The algorithm assumesprior knowledgeof the
present study with the omissionof patient age,
class means:andnumberof classes, to define
Reavenand Miller found the three attributes
the initial classes. Reavenand Miller used the
Glucose, Insulin, and SSPGto be more sig- results¯ of a previous study (Reavenet. al.),
nificant than any of the others.
1976)to determinesuitable starting means.
Both the clinical and electronic classifica3.3. ClassificationusingAutoClass
tions assume¯the presence of three classes.
The scatter plot below (Figure 2) showsthe
Oneobjectiyeof this studywasto determine
data set and its clinical classification. Each ¯ if the patients inthe data set naturally fall into
of the six Small plots showsa different pair
groups,¯ without prior knowledgeof the numof variables (the plots at the lower right are
ber of groupsor the attributes of the groups.
simplyreflections of those at the upper left).
Wealso wishedto determine the effectiveness
For example, the plot in the upper left corof AUTOCLASS’S
classification of the diabetes
ner shows Glucose vs. SSPG.The clinical
data, and compareit to the clinical classificaclassification appears to be highly related to
tion.
the Glucose measurement:in fact, the three
It is difficult to determinewhichattributes
classes appear to be divided by the Glucose
from
the data set are reasonableones to genermeasurementalone+ This is particularly well
atea
classification. Somemaybe irrelevant,
illustrated in the plot of Glucosevs. SSPGin
: and a classification generatedusing themmay
the upperleft plot.
produce insignificant classes. Reaven and
:
Miller considered only Glucose, Insulin and
The Electronic classification (EClass)
enerated using a clustering algorithm by
SSPGto be relevant attributes. They found
¯that fasting plasmaGlucoseexhibited a high
edman and Rubin (1967). Each class
described by the meanof the three variables
degreē of linear association with Glucose(r
of the instances in that class (GlucOse,Insulin 0.96), indicating that these two variables are
~
Page 398
AAAI-94 Workshop on Knowledge Discovery in Databases
KDD-94
Classification Attributes
AClass
Glucose, Insulin, SSPG
AClassl
Relative weight, Fasting
Plasma Glucose, Glucose,
Insulin, SSPG
Glucose, SSPG
AClass2
AClass3
Glucose, Insulin
Table 1. AUTOCLASS
classifications
Classification
CClass
EClass
AClass
AClassl
AClass2
AClass3
Error Rate
7.2%
5.6%
5.6%
7.2%
3.2%
4.8%
tion, and the differencesweretallied. Adifference in the classification of an instance from
the clinical classification is assumedto be a
misclassification. The percentage misclassification gives someindication of the ’goodness’ of a classification. Somemisclassifications aremore important than others, and a
¯ single error statistic doesnot illustrate this. A
large numberof Normalpatients misclassified
as Chemicaldiabetics maynot be important,
since they are in no dangerof dying from this
classification error, howeverif Overt patients
are misclassified as Normalthen death could
result. The Friedman and Rubin automatic
classification (EClass) has 20 misclassifications, giving an error statistic of 13.8%.This
wasdeemedacceptable by Reavenand Miller.
3.3.2. Class comparison
using two
sample comparlsonof means
Table 2. Predictederror rate of rule sets
Each class maybe described by the means
of
the attributes of the instances it contains.
essentially equivalent. Four classifications
This
is similar to the generationof a classifiwere ’madein the present study, using Auto,
cation
using Friedmanand Rubin’s clustering
CLASS.
Eachused different selected attributes,
algorithm,
where the meanscharacterize the
as. shownin Table 1. Since AUTOCLASS
com=
classes.
Each
class is described by the means
pletesits classification after a specified time
land
standard
deviations
of the three mainat-has elapsed, an arbitrary execution time of
tributes:
Glucose,
Insulin,
and SSPG.For
one hour was chosen. Classes did not appear
example,
the
Glucose
mean
for
the Normal
to changesignificantly with longer execution
class
of
the
electronic
classification
(EClass)
times. However, a Comprehensive study of
will
be
compared
with
the
Glucose
mean
for
the effects of differing executiontime has not
the
Normal
class
of
the
clinical
classification
been performed.
(CClass).
Although
different in detail, all the classifi¯ cations divide the data set into classes that bear Weused a twowayt-test (Nie, et. al., 1975)
an obvioussimilarity to the clinical classifica- to comparethe class means.The null hypothtion. Thus we were able to assign the names esis wasthat there is no difference betweenthe
¯ ’Normal’, ’Chemical’and ’Overt’ to the gen- two means. The level of similarity between
two classifications is given by the numberof
erated classes. This is unlikely to be easy to irejected
t-tests. All tests were performedat
achieve in general. C4.5 wasused to generate the 95%level of significance. For exam¯ rule sets describin~ allsix classifications. The ple, the SSPGmean of the Chemical class
attributes used to reduce the rule sets were in for EClassis significantly different from the
all cases the sameas those used to generatethe SSPGmeanofthe Chemical class for CClass.
initial classification. Cross’validationchecks Assuming
that the meansof the classes in one
were performedon the rule sets to derive a classification must be the sameas the meansof
reliable estimate of their accuracy. Thepre- the classes in another classification for the two
dieted error rates of each of the rule sets on classes to be considered equivalent, then we
unseencases is shownin Table 2. Three tech,
cannot say that the Chemicalclass for CClass
niques were used to compare the generated
is equivalent to the Chemicalclass generated
classifications with the clinical classification:
by Friedmanand Rubin’s classification algoclassification differences by instance, classifieation differences by comparisonof means, rithm (EClass).
and classification differences by comparison 3.3.3. Comparingrules:for classification
of rules.
comparison.
Neither technique described above allows
3.3.1. Comparing
individual Instances
us toaccurately comparedifferent classifications. Comparingclassifications by examinThe automatic classification of each ining misclassified instances is dependent on
stance wascompared
to the clinical classificaKDD-94
AAAI-94 Workshop on Knowledge Discovery in Databases
Page 399
thetwoindividual
setsof databeingcom- against anything else. Unfortunately, most
pared.
Examining
misclassifications
maynot of the rules inducedfrom our classifications
take this form, as G4.5worksby splitting atprovide
anaccurate
estimate
oftheciassificatributes rather than explicitly defining regions
tionerrorrate
forunseen
data.
of space. In this study, our solution to this
Assumingthat a rule set accurately dehas been to define absolute upper
scribes the classification of a set of data, then problem
~d
lower
limits for each attribute. Rules that
by comparingtwo sets of rules we :are effecdo
not
specify
a particular boundare then astively comparingthe two classifications. The sumedto use the
appropriate absolute limit.
technique presented in this paper for compar,
We
have
used
the
maximumand minimum
ing rules producesa newset of rules describvalues
in
the
data
set
for each attribute as our
ing the differences betweenthe two classificaabsolute limits. The limits for the Glucose
tions. Ananalysis of this kind allows machine attribute are zero ¯and 1600; for SSPGthey
learning researchers to ask the question "Why are zero and 500. The rule above can then be
are these two classifications different?" Previously it has only been possible to ask "How re-written as:
different are these twoclassifications?"
Glucose > 0 A Glucose < 418 A SSPG> 0
A SSPG < 145 =~ NORM.
3.4. MultidimensionalGeometricRule
~ Comparlson
The geometric representation of the above
ruleis shownin Figure 3. Thesolid dots repThis techniquerepresents each rule as a ge- resent the Normalexamples from the CClass
ometric object in n-space. A rule set produced classification.
using 04.5 is represented as a set of such objects. As a geometric object, a rule forms a
boundarywithin whichall instances are classified accordingto that rule. Thedomaincovo
o
o o
¯ erage of a set of rules is the proportion of
o
0
o
the entire domainwhich they cover. Domain
0
o
coverageis calculated by determiningthe hyo
pervolume(n-dimensional volume)of a set
o
rules as a proportion of the hypervolumeof
o
o
¯
o
the entire domain. The ’ripple down’rules
of 04.S must be mademutually exclusive to
en~ure that no part of the domainis counted
¯ morethan once. The size of the overlap betweentwo sets of rules provides an indication
0
0
of their similarity. Thenon-overlappingportions of the tworule sets are convertedinto a
set of rules describing the differences between
0
the tworule sets.
800 1.2e+03 1.6e+03
0
400
Glucose
3.4.1. Geometric
Representation
of Rules
A production rule can be considered to
Figure 3. Geometricrepresentation of a rule
delimit a region of an n-dimensional space,
where n is the ’dimension’ of the rulemthe
Anentire set of rules describing a data set
numberof distinct attributes used in the terms
can
be represented as a collection of geometon the left handside of the rule. The’volume’
ric
objects of dimension m, where m is the
~
of a rule is then simplythe volumeof the re
maximum
dimension of any rule in the set.
gion it encloses. Anyinstance lying inside
Any
rule
with dimension less than the maxithis region will be classified accordingto the
mum
in
the
set is promoted to the maximum
right handside of the rule. Thereis a problem, dimension.For
example,if another rule,
however,with rules that specify only a single
bound for someattributes. For example, the
Glucose > 741 =:, OVERT
two-dimensional rule
wereaddedto the first, ¯the dimensionof this
Glucose < 418 A SSPG< 145 ~ NORM
rule would have to be increased to two the
current maximum
in the set. This is because
does not give lower boundsfor either of the
two
squares
may
be easily compared, but a
attributes. The volumeof this rule is effecline
and
a
square,
or a square and a cube,
tively infinite, makingit very hard to compare
Page 400
AAAI.94 Workshop on Knowledge Discovery in Databases
KDD-94
B
maynot. Promotionto a higher dimension is
achievedby addinganother attribute to a rule,
but not restricting the rangeof that attribute.
The rule
A
Glucose > 741 =:, OVERT
in one dimensionis equivalent to
Glucose > 741 A SSPG< 500 A SSPG> 0
=:, OVERT
in two dimensions. The range of SSPGis not
a factor in determiningif a patient is Overt
since no patient lies outside the rangeof SSPG
specifiedin this rule.
Figure 5. Before cutting
Consider a comparison between the normal
classes of EClass and AClass. The input rule
the cutting
function.
kall
twoinvolve
dimensional
example
showninConsider
Figure the
5.
sets are as follows:
Rule A overlaps Rule B in every dimension.
EClass:
Rule A is the cutting rule, and Rule B is the
Glucose < 376 =~ NORM
rule being cut.
Glucose < 557 ^ SSPG< 204 =~ NORM
Each dimension in turn is examined; the
AClass:
first being the z dimension. The minimum
bound (left hand edge) of rule A does not
Glucose < 503 ^ SSPG< 145 => NORM
overlap rule B, so it need not be considered.
Glucose< 336 ~ NORM
The
maximum
bound (right hand edge) of rule
Glucose< 418 ^ SSPG < 165 ~ NORM
A cuts rule B into two segments. Rule B becomesthe section of rule B which was overFigure 4 shows the geometric representation of the two rule sets. The solid boxes lapped by A in the z dimension. A new rule,
represent the EClass rules; the dotted ones B I, is created whichis the section of rule B
not overlapped by Rule A in the x dimension
represent the AClassrules.
(Figure 6).
B
8In
i
o
i
i
!
|
!
i
e
o
o
i
i
i
o
i
i
o
i ¯o ¯ °
i ~’ °olii o
oI
o ¢
.
8
tDff’l
n
o’~
¯
o oo
oo
¯
¯ ,~ o
..... ,,,*++:
’1""I~o
8,,’4
A
q
o
o
o
o
o
o
°o , t~,
t’~
o
o°
+.++
"41+I
"~"
I
i i
! ii
i i
i
o
0
400
1.2e+03 1.6e+03
800
Glucose
Figure 4. Geometricinput rules
3.4.2, TheCuttingFunction
Makingrules mutually exclusive, and determining their similarities and differences,
KDD-94
B1
o
o o
Figure 6. After cutting z dimension
Considering dimension2, the y dimension:
All references to rule B refer to the newly
created rule B at the last cut. The minimum
bound of rule A (the bottom edge) does not
overlap rule B, so no cut is made. The maximumbound of rule A (the top edge) overlaps
rule B, creating a new rule B2 which is the
AAAI-94 Workshop on Knowledge Discovery in Databases
Page 401
section of rule B not overlapped by rule A.
Rule B becomesthe section of rule B which
is overlapped by rule A (Figure 7). The remaining portion of the original rule B after
all dimensions have been cut is the overlap
betweenthe two rules.
B2
I
B1
cutters remain,the result is a list of mutually
exclusive rules--which classify all instances
exactly as before.
The mutually exclusive rules for the example comparison between EClass and AClass
are shownbelow (Figure 8). As before, the
s01id boxesrepresent the EClassrules and the
dotted boxes represent the AClassrules. The
rules within each classification do not overlap.
A
o
°
o
o
°
o
o
B
0
¯
o
°°
o
o
*
*
*
:p,’0*0 * ,
o:.
¢,
¯
Figure 7. After cutting y dimension
Thenewrules A, B, B 1, and B2are all mutually exclusive. Rules B 1 and B2 describe
the part of the domaincoveredby the original
Rule B, and not by Rule A. The cutting function generalises to N dimensions, since each
dimensionis cut independentlyof every other
dimension.
Rule A is assumedto have a higher ’priority, than rule B. Anyinstances which lie in
thg overlap between rule A and rule B will
remainwithin rule A after the cut.
,:.,,¢o [
~~ 1." .
.......
o
I
0
0
! I
! I
I iI |
400
800 1.2e+03 1.6e+03
Glucose
Figure 8. Mutually exclusive rules
3.4.4. RuleSet Differences
Theobjective of the geometricalgorithm is
to comparetwo sets of rules and determine
3.4.3, Generating mutually exclusive their differences. Eachclass in the first set
rules
of rules is comparedwith each class in the
The ’ripple down’ rules of C4.5 may be+ second, generating a newrule set describing
¯ the differences betweenthe two classes. Conthought of as a priority ordering of rules-sider two rule subsets: A and B, describing
those that appear first are moreimportantthan
two
classes within different rule sets. Each
those that follow. Anyinstances that fall into
rule
from A is used to cut each rule from B
the overlap of two rules Wouldbe correctly
*+
and
the
resulting set of rules describesthe part
classified by the higher priority rule, that is,
of
the
domain
described by rule set B and not
the one whichappearsfirst in the list.
by rule set A. The same process is used in
Obviouslyhigher priority rules must not be reverse (set B cutting set A) to describe the
cut by ¯lower priority rules; the result would part of the domaincoveredby set Athat is not
no longer correctly classify instances. In an covered by set B.
ordered list of rules from highest to lowest
Thedifference matrix showsrule set coverp.riority, such as those output from04.5, the
ageofthe differences betweenrules describrule at the headof the list will be used as a
cutter for all those followingit+ Eachcut rule ing twoclasses. This is not an accurate statis:is replaced by the segmentsnot overlappedby
tic since bigger rules cover moreof the dothe cutter. B is replaced by B 1 and B2 in the
mainand their differences will therefore apexampleabove. Onceall the rules below the
pear moresignificant than smaller rules, even
though their relative differences maybe simcutter have been cut, the rule following the
ilar.
cutter is chosen as the newcutter. Whenno
Page 402
AAAI-94 Workshop on Knowledge Discovery in Databases
KDD-94
For example, the rules below describe the
part of the domaincovered by EClass (class
Norm)but not by AClass (class Norm). Fig,
ure 9 shows the geometric representation of
these rules in relation to the data set.
Glucose > 336 A Glucose < 376 A
SSPG > 165 =~ NORM
Glucose > 503 A Glucose > 557 A
SSPG < 204 ~ NORM
Glucose > 418 A Glucose < 503 A
SSPG> 145 A SSPG< 204 =¢. NORM
Glucose > 376 A Glucose < 418 A
SSPG> 165 A SSPG < 204 =~ NORM
to
o
°
o
oO
o
o,o
°
8
t’l
t.9
I1.
to
¯
0¯ Qo
,o
o
o
°
°0
o
°
,o
o
o
o
°
o
o
o
o
o
o
o
I
o
o
o
0
400
BOO
Glucose
1.2e+03 1.8e+03.
Figure 9. Output rules.
the hypervolumeof the rule from set A. This
statistic indicates the proportion of the rule
in set A overlapped by the one in set B. The
sumof the proportions indicates the similarity
between the two rule sets. Comparinga set
of rules to itself will producea correlation
matrix with 100%along the main diagonal,
and 0%everywhereelse, indicating that each
class completelyoverlaps itself and each class
is mutuallyexclusive(since all the rules are
mutuallyexclusive).
4. Results
This section presents the results produced
by the three classification comparisonmeth¯ ods described earlier--instance comparison,
tWOsample comparison of means and geo~metric rule comparison. For each method,
the five automatically generated classifications (EClass, AClass, AClassl, AClass2and
¯ AClass3)are ¯comparedagainst the original
clinical classification, CClass.
Table 3 showsthe results of the instance
comparisontest. The numbersin each column
¯ indicate the numberof examplesclassified
differently to CClass. These values are also
expressedas a percentageof the total training
set of 145 instances. The rows of this table
break the misclassifications downfurther to
showwhat types of misclassification are occurring, For example, the row ’Norm~Chem’
¯ ¯represents instances classified as Normalby
CClass, but as Chemical by the automatic
classifications.
Results of the two-samplet-test comparison
are
given in Table 4. Here the entries in the
The EClass rules entirely encompassthose ~
table indicate the attributes for whichthe t-test
¯ ofACIass,so there are no rules describing the failed, for eachclass in the five classifications.
part of the domaincovered by AClassand not
A failed test is one wherethe null hypothesis
by EClass.
wasrejected, ie. ¯the meanof the attribute is
significantly
different from the corresponding
3.4.5. Correlation Matrix
CClass mean, at the 95%significance level.
The matrix provides a similarity measure, The bottom rowof this table showsthe total
numberof rejections for each classification.
or correlation estimate, betweentwo sets of
rules. It ¯describes the amountby which the
Tables 5-9 showthe correlation matrix outtworule sets overlap. Eachclass fromthe first
put
produced by the geometric rule comparset of rules is comparedto each class from ¯ ison¯
system. "Phetable entries indicate the
the second set. Consider again two subsets
amount
of
overlap betweenthe two classes as
of rules~ A and B, each describing a class
a
proportion
of the class listed across the top
within two different sets of rules. A describes of the table--in
this case CClass.
the ideal classification; Set B describes the
classification to be compared
against the ideal.
As with the Difference Matrix, each rule from 5. Discussion
¯ set A is comparedto (cuts) each rule in set
B. The hypervolumeof the overlap between
The correlation matrices produced by the
each pair of rules is taken as a percentageof
geometric rule comparisonsystem can be used
KDD-94
AAAI-94 Workshop on Knowledge Discovery in Databases
Page 403
Difference
Type
Norm=~Chem
Chem~Norm
Overt=:,Norm
Overt=~Chem
Total
Classification
EClass
AClass
AClass 1
AClass2
AClass3
3 (2.1%)
9 (6.2%)
3 (2.1%)
5 (3.4%)
2 (1.4%)
4 (2.8%)
10 (6.9%)
13 (8.9%)
12 (8.3%) 19 (13.1%)
1 (0.7%)
0 (0.0%)
1 (0.7%)
3 (2.1%)
8 (5.5%)
6 (4.1%)
8 (5.5%)
4 (2.8%)
5 (3.4%)
2 (1.4%)
20(13.8%) 2t(14.5%) 21(14.5%) 25(17.2%) 31(21..4%)
Table 3. Results of classification instance comparison
Class
Normal
Chemical
Overt
Total
EClass
SSPG
1
Classification
AClass AClassl AClass2
AClass3
Glucose Glucose Glucose, SSPG
SSPG
SSPG
Insulin, SSPG
Insulin
0
2
2
5
Table 4. Results oft-tests on classification means
EClass
Normal
Chemical
Overt
CClass
Normal Chemical Overt
94.05% 31.33% 0.00%
5.95% 68.67% 14.19%
0.00%
0.00% 85.81%
Table 5. EClassvs. CClasscorrelation
AClass
Normal
~hemical
Overt
CClass
Normal Chemical Overt
86.86% 13.62% 0.00%
13.14% 86.38% 14.19%
0.00%
0.00% 85.81%
Table 6. AClass vs. CClasscorrelation
to determinewhichclassification rule set compares mostclosely to the clinical classification. Choosingthe best rule set to describe
the classification also dependson the particular misclassifications madeby each rule set.
Weindicated previously that misclassifying
Overt patients as Normalcan result in death.
Obviously it is more important to minimise
these types of misclassifications rather than
those from Normalto Chemical for example,
wherethe effect ofmisclassification is not so
important. The correlation matrices indicate
AClassand ECIass have 0%misclassification
of Overt patients to Normal. AClass2has a
Significant misclassification error of 37.2%.
AClass3 has low correlation between similar classes, and significant Overlap between
the Normaland Chemicalclasses. 35.25%of
Chemicaldiabetics are misclassified as Normal and 64.75%of Normalpatients are misPage 404
AClassl
Normal
Chemical
Overt
CClass
Normal Chemical Overt
94.89% 41.68%
1.64%
5.11% 58.32% 2.76%
0.00%
0.00% 95.60%
Table 7. AClassl vs. CClasscorrelation
AClass2
Normal
Chemical
Overt
CClass
Normal Chemical Overt
87.68% 37.20% 37.20%
12.32% 62.80% 8.91%
0.00%
0.00% 53.89%
Table 8. AClass2vs. CClasscorrelation
AClass3
Normal
Chemical
Overt
CClass
Normal Chemical Overt
35.25% 35.25% 8.29%
64.75% 64.75% 20.76%
0.00%
0.00%
70.94%
Table 9. AClass3vs. CClasscorrelation
classified as Chemical.
The Normaland Overt classes of AClass 1
are very similar to the equivalent CClass
classes, but the Chemical classes are not
highly correlated between these two classifications. If misclassification of Chemical
diabetics to Normal were considered unimportant, AClassl wouldobviously be the best
classification.
However, AClass has good
correlation betweensimilar classes (all above
85%), and would be used if an acceptable
AAA/-94 Workshop on Knowledge Discovery in Databases
KDD-94
error rate over all classes weredesired.
It is desirable to havea single metric that
describes the similarity between two rule
sets. This could perhaps be calculated as a
weightedaverage of the correlation percentage for equivalentclasses. In the tables above,
equivalent classes lie on the maindiagonal of
the correlation matrix. If no misclassification
is consideredmoreimportantthan any other, a
weightingof 1.0 wouldbe used for each class.
Table 10 showsthis metric, calculated using
a weight of 1.0, for each rule set compared
to the CClass rule set. Thistabie indicates
that AClassis the classification most similar
to CClass, and that AClass3is the least similar. This supports the ’intuitive’ reading of
the correlation matrices.
Classification
EClass
AClass
AClassl
AClass2
AClass3
Similarity
82.84%
86.35%
82.94%
68.12%
56.98%
Table 10. Overall correlation with CClass
Anadvantage of the instance misclassifications is that the distribution of the data is
inherent in the misclassifications themselves.
The geometricrepresentation of the classifiCations has no knowledgeof the underlying
distribution of the data; the similarity estimates assume a uniform distribution of each
attribute across the domain.
The t-test comparisonof classes is very
imprecise. It imparts very little information aboutthe quality of a classification compared with the clinical classification. AClass
is indicated as a similar classification, since
the meansof all the variables for each class
are equivalent. AClass3obviously compares
poorly to the clinical classification since the
meansare significantly different in all three
classes--two out of three meansare different
¯ in both the Normaland Chemicalclasses. The
t-test results wouldindicate that AClass1 and
AClass2are comparableclassifications. This
is an obvious disagreementwith the analysis
of the geometric correlation matrices. The
similarity metrics for AClassl and AClass2
alone differ by 14.82%. 37.2%of Overt diabetics are classified as Normalby AClass2,
compared with 1.64% by AClassl.
Thetable of instance misclassifications can
be used in the same way as the correlation
6. Conclusions
matrix. Theclassification error for each type
This paper has presented a newmethodfor
of misclassification corresponds roughly to
evaluating
the quality of classifications, based
those inthe correlation matrix. For example,
on
a
geometric
representation of class descripthere are 19 misclassifications from Chemical
tions.
Rule
sets
are producedthat describe the
to Normalfor the AClass3e!assification, giv’i
difference
between
pairs of classes. Correlaing an error rate of 13,1%(one of the highest
tion
matrices
are
used
to determinethe relative
rates in Table 2). Thesamemisc!assification:
degree
of
similarity
between
classifications.
in Table 7 gives an error rate of 37.2%----also
one of the highest. Webelieve the similarity ¯ i Themethodhas beenapplied to classifications
in a medical domain,
statistics in the correlation matricesare more generated by AUTOCLASS
and
its
evaluation
compared
to those of simple
indicative of potential misclassification error
instance
comparison
and
statistical
methods.
than the estimates of Table 2. The instance
misclassification errors are only representaTheresults obtained so far are encouraging.
tive of the current data set. For large data
The¯evaluations produced by the geometric
sets this error maybe close to the populaalgorithm appear to¯correlate reasonably well
tion errormhowever,small data sets are not
with the simple instance comparison. Weberepresentative of the population. The gee,
lieve that the geometric evaluation is more
metric rules are ¯moreindicative of classifiuseful because it reflects the performanceof
cation errors because the rules are represem the classification in the real world, on unseen
tative of the population domainDthatis, it
data. Instance based or statistical methods
is assumedthe rules will be used to classify ¯ cannot ¯reproduce this. However,several asunseencases. Misclassifications indicated in
pects of the techniquerequire further experiTable 2 are not always accounted for by the
mentation and development.
rules. C4.5 reclassifies someinstances when
the rules are constructed. Thesingle misclasThe algorithm currently assumesa uniform
sification from the Overt class to the Normal distribution for all attributes, whichin general is not valid. Weplan to incorporate a
class by EClass for example, is not repre:
¯
mechanism
for specifying the distribution of
sented in Table 4.
KDD-94
AAA1-94 Workshop on Knowledge Discovery in Databases
Page 405
attributes to the algorithm,or at least use ’standard’ configurations such as a normaldistribution.
Kononenko, I. & Bratko, I., 1991.
"Information-Based Evaluation Criterion
for Classifier’s Performance". Machine
Learning 6, 67-80.
Thesystem is at present limited to compar- Lebowitz, M., 1987, "Experiments with Ining ripple-down rule sets. Ideally it would
cremental Concept Formation: UNIMEM".
also be able to handle rule sets in whichevery
MachineLearning 2, 103-138.
rul.e has equalpriority. Thereis a difficulty in
this case with overlappingrules fromdifferent
McQueen,R., Neal, D., DeWar,R. & Garner, S., 1994. ,’Preparing and processing
classes--unlike ripple-downrules there is no
relational data through the WEKA
machine
easy wayto decide whichrule, if any, should
learning workbench".Internal report, De,
take priority.
partment of ComputerScience, University
Finally we plan to extend the system to
of Waikato, Hamilton, NewZealand.
handle enumeratedas well as continuous attributes, and integrate it fully with the WEKA Michalski, R. & Stepp, R., 1983. "Learning from Observation: Conceptual Clusworkbench.
tering". In Michalski, R., Carbonell, J. &
Mitchell, T. (eds.), MachineLearning: An
Artificial Intelligence Approach,331-363.
Acknowledgements
Tioga Publishing Company,Palo Alto, California.
Wewish to thank RayLittler and Ian Witten
Mingers, J., 1989. "An Empirical Comparifor their inspiration, commentsand suggestions. Credit goes to Craig Nevill-Manning
son Of Pruning Methodsfor Decision Tree
Induction". MachineLearning 4, 227-243.
for his last minuteediting. Special thanks to
AndrewDonkinfor his excellent work on the
Nie, N., Hull, H., Jenkins, J., Steinbrenner,
WEKAWorkbench.
K: & Bent, D., 1975. SPSS: Statistical
Packagefor the Social Sciences, 2nd ed.
MCGraw-HillBook Company, NewYork.
References
Ousterhout, J., 1993. An Introduction to TCL
Cendrowska,J., 1987. "PRISM:Analgorithm
and TK. Addison-Wesley Publishing Comfor inducing modularrules". International
pany, Inc., Reading, Massachusetts.
Journal of Man-MachineStudies. 27,349Quinlan, J., 1986. "Induction of Decision
270.
Trees". MachineLearning 1, 81-106.
Cheeseman,E, Kelly, J., Self, M., Stutz, J.,
Quinlan, J., 1992. c4.5: Programsfor MaTaylor, W, & Freeman, D., 1988. "AuTochine Learning. Morgan KaufmannPubCLASS:A Bayesian Classification System".
lishers, San Mateo,California.
In Proceedingsof the Fifth International
Reaven, G., Berstein, R., Davis, B. & OlefConference on Machine Learning, 54-64.
sky, J., 1976. "Non-ketoic diabetes melMorgan KaufmannPublishers, San Mateo,
litus: insulin deficiency or insulin resisCalifornia.
tance?". AmericanJournal of Medicine60,
Compton,E, Edwards, G., Srinivasan, A.,
80-88.
Malor, R., Preston, E, Kang, B. & Lazarus,
Reaven, G. & Miller, R., 1979. "An Attempt
L., 1992. "Ripple down rules: turnto Define the Nature of ChemicalDiabetes
ing knowledgeaquisition into knowledge
Using a Multidimensional Analysis". Diamaintenance". Artificial Intelligence in
betologia 16, 17-24.
Medicine 4, 47-59.
Tierney, L., 1990. LIsP-S’rA’r: An ObjectFisher, D., 1987. "KnowledgeAcquisition
Oriented Environmentfor Statistical ComVia Incremental Concept Clustering". Maputing
and DynamicGraphics. John Wiley
chine Learning 2, 139-172.
& Sons, NewYork.
Friedman, H. & Rubin, J., 1967. "On some
Utgoff, E, 1989. "Incremental Induction
invariant criteria for groupingdata". Jourof Decision Trees". MachineLearning 4,
nal of the AmericanStatistical Association
161-186.
62, 1159-1178.
Hanson, S. & Bauer, M., 1989. "Conceptual
Clustering, Categorization, and Polymorphy". Machine Learning 3, 343-372.
Page 406
AAA/-94 Workshop on Knowledge Discovery in Databases
KDD-94