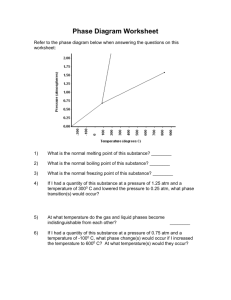
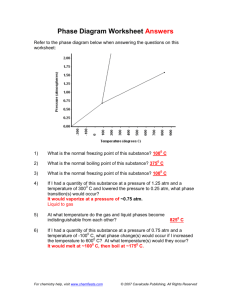
DIGITAL TRANSMISSION David Byers 1 HISTORY – PDH – SONET/SDH
advertisement

DIGITAL TRANSMISSION HISTORY – PDH – SONET/SDH (MINI-LECTURE) davby@ida.liu.se IDA/ADIT/IISLAB ©2003–2004 David Byers David Byers 1 Digital Transmission Systems § Asynchronous „ Signals run at different rates, independently of each other Ethernet, modems § Plesiochronous „ Signals are close to each other in timing, but not sourced from the same clock PDH (Tn, En, Jn) § Synchronous Signals run at the same rate; timing is usually sourced from the same clock SDH (SONET) ©2003–2004 David Byers „ Digital transmission systems can be subdivided into four basic types. Asynchronous, plesiochronous and synchronous, based on their timing characteristics. In asynchronous systems, signals in the system, as well as clocks, run at different rates, and may run entirely out of phase. Timing is entirely in the signals themselves. In plesiochronous systems, clocks run close to each other, within a welldefined tolerance. In practice, many systems that are considered asynchronous are actually plesiochronous. In synchronous systems all signals run at the same rate and all clocks are sourced off the same clock. In theory, all clocks should be exactly the same, but in practice, they will be slightly different, although not so different as to affect the signals. 2 Voice 65 60 55 50 45 40 35 30 25 100 Hz 1000 Hz 10000 Hz ©2003–2004 David Byers Idealised voice spectrum Before data communication came voice, and the development of digital communications was driven by the need to pack more voice channels into the same digital telephone trunk. This has subsequently influenced many communication protocols. In particular, we often see multiples of 64000 bps and 56000bps. Here’s why. The frequency spectrum of voice looks something like this. Most of the energy is in a fairly narrow frequency band from 100 to 5000 Hz. The information content is even more concentrated; low frequencies don’t carry a lot of information. Because of this, and because of the properties of telephone wires, telephone signals are filtered. 3 Voice Filtering 0 65 60 -10 55 -20 50 -30 45 40 -40 35 -50 30 -60 10 Hz 25 Filter Attenuation Voice Spectrum ©2003–2004 David Byers 1000 Hz This diagram shows the voice spectrum on the right and the frequency response of a filter designed for the telephone system. In practice one can say that the voice signal is filtered using a bandpass filter that passes frequencies from 300Hz to 3400Hz, leaving a signal with approximately a 3100Hz bandwidth. In reality, of course, both higher and lower frequencies are passed, but they are severely attenuated. Therefore we might consider the signal to be from 0 to 4kHz. This gives us a comfortable margin to work with. Furthermore, digitalisation of the voice signal quantifies it in 255 levels. 4 Voice Digitalisation § § § § Frequencies: 0-4kHz Levels: 0-255 Sample at 8kHz Encode using PCM ©2003–2004 David Byers § 8000 Hz times 8 bits gives 64000 bits per second § One sample every 125µs Nyquist-Shannon Sampling Theorem If a function s(x) has a Fourier transform F[s(x)] = S(f) = 0 for |f| > W, then it is completely determined by giving the value of the function at a series of points spaced 1/(2W) apart. The values sn = s(n/(2W)) are called the samples of s(x). Digitizing an analog signal is called sampling, and the Nyquist sampling theorem tells us that to reconstruct a signal with a frequency of W Hz, we need to sample it at 2W Hz (and those Ws should have been omegas). So for digital telephone we have 8000 eight-bit samples per second, giving us a total bitrate of 64000 bits per second. That is the source of the ubiquitous 64kbps. 5 DS-x Designaton Data rate DS0 multiple DS0 64 kbps 1 DS1 1.544 Mbps 24 T1 Carrier DS2 6.312 Mbps 96 4 DS1 DS3 44.736 Mbps 672 T3 Carrier § Basic DS0 rate is bundled to form higher signals § Bundling is different in Europe and the USA DS-x signals and T carrier in the USA E carrier in Europe DS1 F 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 (24 * 8bit + 1bit) * 8000Hz = 1544000 bits/s ©2003–2004 David Byers „ „ The basic unit in digital transmission systems is the DS0 signal, which is a 65kbps signal, equivalent to one voice channel. Higher-level signals can be formed by multiplexing the basic DS0. In the USA, the basic bundle is called a DS1, and consists of 24 DS0 channels. This was the basic building block for digital telephone systems. In europe, bundling starts at 30 channels. The most common DS signals are DS0, DS1 and DS3, although there are a number of others, with different multiplexing and data rates. A DS0 transmits eight bits every 125us, but nothing says that it takes 125us to transmit those bits. A DS1 consists of a single framing bit followed by 24 DS0 channels, eight bits at a time, giving a data rate of about 1544000 bits per second. 6 DS1 Superframe Framing F 1 2 3 4 5 6 7 8 F Frame 1 F Superframe Aligns frames Frame Channel 24 (DS0) 1 2 3 4 5 6 7 8 Frame 2 F Frame 12 1 0 0 0 1 1 0 1 1 1 0 0 1 0 1 0 1 0 0 0 1 1 1 0 Terminal framing bits Signaling framing bits Shaded bits indicate frames with robbed bits for signalling Aligns superframes ©2003–2004 David Byers Channel 1 (DS0) The T1 carrier uses framing bits in a repeating pattern to identify where frames start. The recevicer searches the bit stream for a position where every 193 bit results in the repeating pattern. Originally the repeating pattern was 1010, but the PCM created by certain tones (e.g. 1000Hz) also resulted in the same pattern, which could cause the receiver to lock on to the wrong positions in the stream. In 1969 the superframe was introduced. Now the framing bits were divided into two parts – the terminal framing bits, which correspond to the old framing bits, and signaling framing bits. The new pattern was less likely to appear naturally in the data stream, reducing the risk of mis-synchronization. One thing that is missing from this framing format is a suitable channel for OAM signaling. One mechanism that was used was to set data bits to specific values across the entire frame to signal e.g. error conditions. The obvious problem with this mechanism is that an entire 125us frame is lost, and that the error pattern might appear naturally in the data (e.g. if all channels were silent). An alternative method is commonly used is called robbe-bit signaling. Here one data bit is stolen and used for signalling instead of data. In the precursor to DS1, one data bit was taken from each frame, providing an 8kbps signalling channel, while also reducing the data channel to 56kbps, since only seven bits per DS0 were used for data. When superframing was introduced, the signalling scheme could be changed. Instead of robbing a bit in every frame, a bit was now robbed from every sixth frame. This wastes far less bandwidth. Bit robbing is fine for voice, where the robbed bit just results in a degradation of the voice signal. The human receiver adapts. For data communication, however, the robbed bit results in a bit error. 7 DS1 Extended Superframe Extended Superframe Format Frame 1 2 3 Fe F 5 6 7 0 FDL M CRC Frame LSB 4 M P C M 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 0 M C1 P C M 8 M 1 M C2 P C M P C M P C M a 0 M M P C M P C M C3 P C M P C M P C M P C M M 1 M C4 b M 1 M C5 P C M P C M P C M P C M 2 3 4 5 M C6 P C M P C M c P C M P C M P C M 6 7 8 9 10 11 12 d Superframe Format Frame 1 Ft 1 F Fs 3 0 0 P C M 4 P C M 5 1 0 P C M 6 P C M 7 0 1 P C M 8 a 9 10 11 12 1 1 1 P C M P C M 0 1 P C M P C M 1 0 P C M b 0 0 P C M P C M 1 0 P C M P C M 0 1 P C M a 1 1 P C M P C M 0 1 P C M P C M 0 P C M b ©2003–2004 David Byers Frame LSB 2 The superframe concept was further improved, and a new scheme, called Extended Superframe (ESF) was introduced. In this scheme, 24 frames form an extended superframe. The framing bit is used for three purposes: framing, signalling information about the link and a CRC to monitor the performance of the link. The ESF still uses robbed bit signalling in every sixth frame. The framing pattern is now only six bits again, but designed to avoid patterns that appear naturally in voice communicaitons. Reducing the number of framing bits makes it possible to introduce new features, as does the extension to 24 frames. The Facility Data Link (FDL) is used for transmitting information related to error conditions and performance monitoring, and is available for transmission to the customer since it is an out-of-band channel. Every other F bit is used for the FDL. The CRC is a six-bit CRC over the previous DS1 frame. The CRC is used to monitor the performance of the link. It cannot be used to correct errors, just to see how many are transmitted. Finally, the LSB of every sixth frame is still robbed for signalling. There are now four bits, termed a b c and d, giving the same overall bit rate for signalling as in the older superframe format. 8 DS2 and DS3 Framing 4xDS1 Overhead 4xDS1 Overhead M0 M1 M2 MX [48] [48] [48] [48] C11 C21 C31 C41 [48] [48] [48] [48] F0 F0 F0 F0 [48] [48] [48] [48] C12 C22 C32 C42 [48] [48] [48] [48] C43 C43 C43 C43 [48] [48] [48] [48] F1 F1 F1 F1 [48] [48] [48] [48] 4xDS1 Overhead 4xDS1 Overhead 4xDS1 Overhead 4xDS1 Overhead DS3 Overhead 526306 bps X X P P M0 M1 M0 [84] [84] [84] [84] [84] [84] [84] F1 F1 F1 F1 F1 F1 F1 C11 C21 C31 C41 C51 C61 C71 [84] F0 [84] F0 [84] F0 [84] F0 [84] F0 [84] F0 [84] F0 [84] [84] [84] [84] [84] [84] [84] C12 C22 C32 C42 C52 C62 C72 [84] [84] [84] [84] [84] [84] [84] F0 F0 F0 F0 F0 F0 F0 [84] C13 [84] C23 [84] C33 [84] C43 [84] C53 [84] C63 [84] C73 [84] F1 [84] F1 [84] F1 [84] F1 [84] F1 [84] F1 [84] F1 [84] [84] [84] [84] [84] [84] [84] ©2003–2004 David Byers 4xDS1 Overhead The DS3 was, and still is, a very important carrier in backbones in the USA. It provides about 45Mbps capacity, carrying 28DS1 signals. The way the DS3 is formed follows the same principles as other plesiochronous signals. Since the DS3 is so well documented, I prefer talking about it rather than the european E3, which has more practical relevance here. The DS3 is formed by multiplexing four DS2 signals, which in turn are formed by multiplexing seven DS1 signals. At each stage overhead is added and bit stuffing takes place. The DS2 signal format is shown in the top box. The M bits are used to find the start of each multiframe (each row is a multiframe); the C bits are used to control bit stuffing and the F bits are used to align frames. The [48] parts indicate 48 DS1 information bits. Bit stuffing is a technique used by multiplexters in asynchronous networks. Bit stuffing may also be used when embedding a signal from an asynchronous network in a synchronous link, such as when transmitting a DS3 over SONET. In asynchronous communication, clocks may run at slightly different rates, so the signals being multiplexed my have slightly different bit rates. To accommodate this, the multiplexer has an output with capacity enough to handle all inputs plus extra bits used to bring all inputs up to the same bit rate. In DS2, the four DS1s are brought to 1545796 bps from 1544000 bps by adding bits. This compensates for slow clocks in the network. These signals are then multiplexted together with indicators that allow the receiving end to reverse the bit stuffing. In DS3, the four DS2 signals may also be asynchronous relative to one another, so bit stuffing also takes place at the DS3 level. 9 DS0's North America Europe Japan 64 Kbps 1 - - - 1.544 Mbit/s 24 T-1 - J-1 2.048 Mbit/s 32 - E-1 - 6.312 Mbit/s 96 T-2 - J-2 7.786 Mbit/s 120 - - J-2 (alt) 8.448 Mbit/s 128 - E-2 - 32.064 Mbit/s 480 - - J-3 34.368 Mbit/s 512 - E-3 - 44.736 Mbit/s 672 T-3 - - 97.728 Mbit/s 1440 - - J-4 139.264 Mbit/s 2016 DS4NA - - 139.268 Mbit/s 2048 - E4 - 274.176 Mbit/s 4032 T-4 - - 400.352 Mbit/s 5760 T-5 - - 565.148 Mbit/s 8192 - E-5 J-5 ©2003–2004 David Byers Speed This table summarizes the various PDH data rates in the USA (T-carrier), Europe (E-carrier) and Japan (J-carrier). All are based on the DS0 data rate, but bundling is slightly different from region to region. Framing also differs, although the basic principles are the same in all carriers. Rates above T3/E3/J3 are usually carried optically. 10 SONET/SDH/OC SONET OC § Synchronous Optical Network § Standard in the USA § STS framing § Optical carrier hierarchy § OC-x is x times 51.84 Mbps SDH Synchronous Digital Hierarchy SONET-compatible ITU standard Used in Europé STM framing 51.84 Mbps 155.52 Mbps 622.08 Mbps 2488.32 Mbps 9953.28 Mbps ©2003–2004 David Byers § § § § § OC-1 OC-3 OC-12 OC-48 OC-192 SONET is a standard for a synchronous optical network, designed to replace the earlier electrical digital networks known as the plesiochronous digital hierarchy (PDH). SDH is an ITU standard with the same goals, slightly different yet compatible with SONET. SONET is primarily used in the USA, whereas in Europe, SDH is used. SONET/SDH equipment tends to be very expensive, but the technology is probably still the best choice for highperformance, high-reliability links. Unlike cheaper link-layer protocols, SONET/SDH is designed from the ground up to be fast, scalable, manageable and reliable. SONET signals are called STS-N signals. STS stands for Synchronous Transport Signal. STS-1 is a 51.84Mbps signal, which essentially means that each byte is a 64kbps signal. The reason for 64kbps is quite simple – a DS 11 SONET/SDH/OC Data Rates Optical Carrier Data Rate Payload-SONET SONET OC-1 51.84 Mbit/s 50.112 Mbit/s STS-1 OC-3 155.52 Mbit/s 150.334 Mbit/s STS-3 SDH STM-1 466.56 Mbit/s 451.044 Mbit/s STS-9 STM-3 622.08 Mbit/s 601.344 Mbit/s STS-12 STM-4 OC-18 933.12 Mbit/s 902.088 Mbit/s STS-18 STM-6 OC-24 1244.16 Mbit/s 1202.784 Mbit/s STS-24 STM-8 OC-36 1866.24 Mbit/s 1804.176 Mbit/s STS-36 STM-12 OC-48 2488.32 Mbit/s 2.4 Gbps STS-48 STM-16 OC-192 9953.28 Mbit/s 9.6 Gbps STS-192 STM-64 ©2003–2004 David Byers OC-9 OC-12 This table summarises various OC levels, the corresponding data rates, SONET payload data rates, SONET carriers and SDH carriers. 12 SONET/SDH Concepts Path Line Repeater Repeater Section Section Section Section Section PTE Line ADM Repeater PTE STS-1 Frame SOH 9 rows LOH POH 90 columns ©2003–2004 David Byers SPE SONET/SDH is a complex standard, and beyond what we’re covering here. Each STS-1 frame, which is the basic signal, contains four parts: section overhead, line overhead, path overhead and a payload. The overhead sections carry OAM and signaling information for various parts of the network. The SOH contains information pertinent to each section, and is regenerated by section-terminating equipment. LOH contains information pertinent to lines, and POH contains information pertinent to the entire path. The payload is also structured, can start anywhere in the frame and may span two frames. This makes it possible to stuff an asynchronous source, such as a DS3, into STS-1 frames; the start of the DS3 frames may not coincide with the STS frames, but the frame structure is retained anyway. Higher-level STS signals are constructed by interleaving STS-1 signals. The same nine-row structure is retained, transport overheat (SOH and LOH) go at the front of the frame, and more than 90 columns are used. 13 SONET/SDH Framing Frame n Pointer SPE Frame n+1 SPE ©2003–2004 David Byers Pointer This picture shows how the payload of a SDH frame (the SPE) can span more than one frame. This is a common occurrance when an asynchronous signal needs to be stuffed into a SONET signal. Since the asynchronous signal is not locked to the SONET clock, frames will not appear at the same rate as SONET frames do. 14 ATM PRINCIPLES – ATM PROTOCOLS – IP OVER ATM TRAFFIC ENGINEERING – SIGNALLING davby@ida.liu.se IDA/ADIT/IISLAB ©2003–2004 David Byers David Byers 15 Standards Organisations and ATM ITU-T § United Nations agency § Standards for international telecommunications § Created in 1993 § Replaced CCITT ATM Forum § Created in 1991 § Objective to accelerate use of ATM products and services § Three committees „ „ ©2003–2004 David Byers „ Technical Committee Market Awareness Committee User Committee There are two primary players in the ATM standardisation effort. The ITU-T is a united nations special agency tasked with the standardisation of international telecommunications. This agency was formed in 1993 and replaced the CCITT, which up to that point had been the main driving force in international telecommunications standardisation. The ATM forum is a non-profit international organisation formed to accelerate the use of ATM products and services, and to accelerate development of ATM. Its technical committee is tasked with working with other standards bodies to standardise aspects of ATM. It consists of a number of working groups, each focused on a different area of ATM. There are working groups for ATM architecture, control signaling, network management, physical layer issues, wireless and more. For the most part it appears that the ATM forum standards are further along than the ITU standards, and that they are more responsive to market needs. This is perhaps natural, given that the ATM forum is built for and by stakeholders in the ATM business. 16 Why ATM § One International Standard „ „ ITU-T standard ATM Forum standard § Scalable in Distance „ „ „ § Multiple Traffic Types „ „ § Scalable in Speed „ Operates on many different physical layers ©2003–2004 David Byers „ Voice (delay sensitive) Data (loss sensitive) Video (high bandwidth) Local Area Networks Metropolitan Area Networks Wide Area Networks ATM was introduced at a time when there were no wide and metropolitan area networking technologies worth using. Ethernet was limited to 10Mbps, and is not suitable for wide-area networking, and other technologies were basically point-to-point links. Technology such as X.25 and Frame Relay existed, but were limited in their usefulness as they were not easily scalable and interoperable. ATM was designed from the ground up to be an international standard, allowing interoperability between vendors. It was to be scalable in distance and speed, allowing local to wide area networking over whatever speed the user was willing to pay for. It was also designed from the start to support multiple traffic types, including high-quality voice and video. ATM started out as a CCITT (later ITU) standard. A consequence of this is that it is a committee product. In the ITU all representatives must be in agreement for a particular document to be accepted, which slows down progress considerably. It also implies that ATM has a number of compromises. Still, ATM represented a significant step forward, and even today ATM provides features that other standards do not. 17 ATM Basics § Negotiated Service Connection „ „ End-to-end connections, called virtual circuits Traffic contract § Switched Based „ Dedicated capacity § Cell Based Small, fixed length ©2003–2004 David Byers „ There are three basic concepts in ATM that the ATM forum like to push. ATM supports a negotiated service connection, which means that users can receive the service they are willing to pay for, and they are guaranteed to receive that service. This enables running real-time delay-sensitive traffic over an ATM network, something that cannot easily be done on e.g. an Ethernet. ATM is switch-based, not router based. Switches perform far better than routers, as most of the decisions can be made in hardware. Switches minimise delay. Switches can also provide dedicated capacity to single connections. Finally, switches, at least historically, are cheaper than routers. ATM is cell-based. Unlike some other circuit-switched technology, ATM does not provide for an end-to-end bit stream (although that can be emulated). It provides packet switching with small, fixed-size packets. 18 ATM Characteristics § Connection-oriented „ No adresses (sometimes) § Circuit-based „ Fast switching § Unreliable transport „ „ Cells can be lost or created But they are deliverd in-order § Minimal error detection Most error detection left to end stations „ Runs on a multitude of physical media § Complete protocol stack „ From transport protocols to physical layer protocols § Internetworking ready „ Protocols for internetworking between organizations and network types ready ©2003–2004 David Byers „ § Medium independent ATM leaves error detection and correction to the endpoints. The only thing ATM does is error detection on the header of each cell. This is to simplify ATM and make the switches cheaper. ATM is connection-oriented. Prior to communication, a connection must be negotiated. Although ATM is packet switched, it is still circuit based. Unlike some circuitswitched technology, ATM does not provide and and-to-end transparent circuit; it still splits data into cells and switches the cells. It is, however, circuit based in that prior to communiction, a path through the network must be negotiated, and all packets beloning to a particular connection will traverse the same path. Paths may be permanent or set up on demand (or, in part, both). Fundamentally, ATM is an unreliable transport in that it can drop cells. However, a great deal of effort has gone in to ensuring that this does not happen during normal operation. ATM does, however, guarantee in-order delivery of cells. It is worth noting that with certain service types, ATM may actually insert cells into the stream to ensure a steady rate of cell delivery. 19 Negotiated Service Connection § Parameters „ „ „ Traffic characteristics Peak cell rate Sustainable cell rate § Quality of service „ QOS B QOS C ©2003–2004 David Byers „ Delay characteristics Cell loss QOS A No notes for this page. 20 ATM Protocol Stack Higher layers ATM Adaption Layer (AAL) ATM Layer Physical Layer Application Application AAL AAL Physical Layer ATM ATM Physical Layer ATM Physical Layer ©2003–2004 David Byers ATM Getting in to the technology of ATM, we’ll start with a look at the ATM protocol stack. ATM consists of three layers: the physical layer (PHY), the ATM layer (ATM) and the ATM Adaptation Layer (AAL). The PHY and ATM layers exist on all ATM devices, but the AAL only exists on endpoints, not on switches. ATM diverges from the OSI model; the physical layer performs functions of the physical and data link layers in ths OSI model. The ATM layer performs functions of the data link and network layers. The ATM adaptation layer performs functions of the network and transport layers. 21 ATM Protocol Stack Q.2931 AAL Layer SAAL Layer Q.2931 SAAL Layer ATM Layer ATM Layer Physical Layer Physical Layer TE ATM Stack Switch ATM Stack ©2003–2004 David Byers Higher Layers Control Plane User Plane Management Plane A more detailed look at the protocol stack shows not only layers, but planes. In addition to the protocol layers, there is a management plane, concerned with management of the entire protocol stack. There are also control functions, located in a control plane, concerned with issues such as signalling. The management and control planes (at least part of them) are present even on switches in the network, whereas the user plane is generally not. 22 ATM Cell Structure § Small Size „ „ 5 Byte Header 48 Byte Payload 5 bytes header 48 bytes payload ©2003–2004 David Byers § Fixed Size § Header contains virtual circuit information § Payload can be voice, video or other data types No notes for this page. 23 ATM Cell Structure § Why small cells? „ „ Small cells reduce packetization effects for continuous traffic Small cells and small buffers reduce forwarding delay § Why fixed cell size? „ „ Variable cell size reduces percell overhead Fixed cell size simplifies equipment § Why 53 bytes? „ ©2003–2004 David Byers „ USA wanted 64 byte payload for efficiency Europe wanted 32 byte payload to eliminate need for echo cancellation No notes for this page. 24 ATM Terminology DTE Generic term for equipment connected to the network, e.g. a modem DTE Data General Data General DSU Data Service Unit Equipment that attaches customer equipment to a public network NNI DTE Data Terminal Equipment UNI DSU NNI Network-Network Interface Interface between ATM switches UNI User-Network Interface Interface between user equipment and an ATM switch ©2003–2004 David Byers Switch Before we move on, lets go one round of the acronym derby. ATM is full of acronyms, and you need to know them, because ATM people use them all the time. Here are some that show up a lot in ATM and ISDNrelated stuff. The UNI is an important function. This is the bit that connects an end user with the ATM network. A lot of functions, including traffic policing, take place in the UNI. In many cases UNI is used to refer to the actual piece of equipment that connects the user to the network; this is more properly called a DSU. 25 ATM Concepts § Virtual Path (VP) „ „ „ Semi-permanent circuit Contains up to 65000 VCs Switched as a whole § Virtual Channel (VC) „ „ On-demand connection Contained within a VP VC ©2003–2004 David Byers § Switched Virtual Circuit (SVC) § Permanent Virtual Circuit (PVC) VP In ATM, all cells belong to a connection. These connections are identified by a tuple <VP,VC>, where VC is the virtual channel a cell belongs to and VP is the virtual path that the virtual channel belongs to. In other words, circuits in ATM form a two-level hierarchy, with virtual paths containing virtual channels. The reason for this construction is that a virtual path containing a large number of virtual channels can be switched as one. Switches along the path do not need to keep track of every individual channel, but can simply keep track of a more limited number of paths. This improves efficiency. Furthermore, it is possible to set up virtual channels within the parameters of an existing virtual path without involving the entire network. Virtual paths were originally concieved to be semi-permanent connections, such as the connection between a branch office and headquarters, or a telecommuting worker and his workplace. Virtual channels would then be set up dynamically within the preexisting virtual path. There are two other basic concepts that tie in to the VP and VC concepts. A Switched Virtual Circuit (SVC) is a circuit that is set up on demand by the netowork, using some signalling protocol. A Permanent Virtual Circuit on the other hand is a circuit that is set up manually and exists over a longer period of time. SVCs offer the highest degree of flexibility, but PVCs are appropriate when a customer buys a permanent link through a provider’s ATM network. 26 ATM Cell Header Structure UNI cell format GFC CLP VPI VCI PTI NNI cell format VPI Generic Flow Control Virtual Path Identifier Virtual Channel Identifier CLP VCI PTI CLP HEC PTI HEC Payload Type Indicator Cell Loss Priority Header Error Control ©2003–2004 David Byers GFC VPI VCI HEC ATM cells exist in two variants. One variant is used between the end user and the network, and the other is used within the network itself. The former are called UNI cells and the latter NNI cells. The format of the NNI cell header is simple. It starts with the circuit identifier – the virtual path and channel ID, with 12 bits allocated to the VPI and 16 to the VCI. This implies that two ATM switches can have 4096 virtual paths between each other, each containing up to 65535 virtual channels. The VCI is followed by a three-bit payload type indicator field, which indicates what kind of data is in the cell. The CLP is a single-bit field. When set to 1, it indicates that the cell is a candidate for dropping when a switch must drop cells. When set to 0, the cell should only be dropped as a last resort. Finally, the HEC is a checksum over the header, used to detect errors in the header. This is the only form of error control in the ATM layer (higher layers may add additional error control). The UNI cell format is identical to the NNI cell format with the exception that the VPI is only eight bits, and the first four bits of the header are used for generalized flow control instead. This implies that an end user can have at most 256 virtual paths to the network. The difference in size of the VPI in the two cell formats is reasonable. A switch may be connected to several customers, so it may have to aggregate all VPIs from these customers on the link to another switch. By providing an additional four bits for the VPI in the NNI cell format allows a switch to aggregate VPIs from 16 UNIs without running out of VPIs. 27 ATM GFC and PTI § GFC „ „ „ Used to control flow of data from user equipment Only exists at UNI Undefined § PTI „ „ „ „ Indicates type of payload 0xx – User data cell 10x – OAM cell 110 – RM cell 000 User data cell, congestion not experienced, SDU type=0 001 User data cell, congestion not experienced, SDU type=0 010 User data cell, congestion experienced, SDU type=1 011 User data cell, congestion experienced, SDU type=1 100 Segment OAM flow-related cell 101 End-to-end OAM flow-related cell 110 RM cell ©2003–2004 David Byers 111 Reserved The GFC and PTI fields deserve an extra look. The GFC field deserves a look, because here are four bits that haven’t been standardised. When the UNI cell structure was defined, provision was made for flow control, but standardisation of how flow control would work was left for later. As a result, the GFC field exists, but interoperable standards for how to use it do not. The PTI field indicates the type of data in the cell. Note that it is possible to indicate congestion in the network by setting the appropriate PTI value. 28 ATM Protocol Stack Higher layers ATM Adaption Layer (AAL) ATM Layer Physical Layer Application Application AAL AAL Physical Layer ATM ATM Physical Layer ATM Physical Layer ©2003–2004 David Byers ATM Just a picture. 29 ©2003–2004 David Byers Physical Layer 30 Physical Layer PMD Sublayer § Timing Function § Encoding/Decoding TC Sublayer § HEC Cell Generation and Verification § Decoupling of Cell Rate § Cell Delineation § Transmission Frame Generation and Recovery Physical Layer Physical Medium-Dependent (PMD) Sublayer ©2003–2004 David Byers Transmission Convergence (TC) Sublayer The physical layer is divided into two sublayers: the physical medium-dependent sublayer and the transmission convergence sublayer. The PMD deals with low-level issues such as timing and encoding/decoding for transmission, and is probably, at least in part, implemented in hardware. The TC sublayer, on the other hand, is concerned with more high-level aspects of transmission. It deals with generating and verifying the HEC, decoupling cell rate, delineating cells and generating and recovering transmission frames. The PMD sublayer has two functions: timing and encoding/decoding. The timing function is responsible for synchronizing the transmitting and receiving PMD sublayers. This may involve extracting timing information from received signals and tuning the timing of transmitted signals. The encoding/decoding function generates transmission codes. Although some physical media operate on a bit-by-bit basis, others encode several bits at once. For example, FDDI, and other media, use a 4B/5B code, where four data bits are encoded as a five-bit codeword. The TC sublayer receives complete ATM cells from the ATM layer, but is responsible for filling in the HEC field. On the receiving end it is also responsible for checking the HEC field and discarding cells that do not pass the HEC test. The TC sublayer is also responsible for decoupling the ATM layer from the cell rate required by the PMD. The PMD may require a continuous stream of cells at a fixed rate, and the TC sublayer is responsible for generating this stream. That may entail inserting idle frames into the stream when the ATM layer isn’t producing enough traffic. It is worth noting that the ATM forum recommends that cell rate decoupling be implemented in the ATM layer; if it is, then the TC sublayer does not have to perform this task. Cell delination is the process of extracting cells from the transmission stream. There are two fundamental ways of doing this. One is to exploit framing information in the physical layer protocol; for example, it is possible to map ATM cells onto an E1 stream using PLCP (documented in IEEE 802.6c and h), and in theory it would be possible to place ATM cells at specific positions in an E3 or SONET frame (in practice this is not done). The other method is called HEC cell generation, and is described on the next slide. Finally, the TC sublayer is responsible for generating transmission frames for framed media, such as SONET. On the receiving side, the TC sublayer extracts frames from the data stream received from the PMD. 31 Physical Layer Interfaces SONET/SDH PDH Nx64kbps IMA TAXI (FDDI) ATM 25 Fiber Channel Cell-Based Clear Channel ... § ATM can operate over many physical media § At low speeds overhead is significant § Originally defined for highspeed optical links § Lower speeds defined to speed deployment and to satisfy customer needs § Special protocols used at low speeds ©2003–2004 David Byers § § § § § § § § § No notes for this page. 32 TC Sublayer § HEC Cell Generation and Verification „ „ Compute the HEC byte into ATM cells passed from the ATM layer Check HEC byte of received cells § Decoupling of Cell Rate Pass a continuous stream of cells to PMD, inserting idle cells when needed „ Generate transmission frames for framed physical layers (e.g. SONET) § Cell Deliniation „ Decide where cells start and end in the data stream from the PMD ©2003–2004 David Byers „ § Transmission Frame Generation and Recovery The TC sublayer of the PHY has a number of jobs. The first job is generating and verifying the HEC. The TC sublayer is responsible to ensure that headers of received cells are correct before further processing them. It is also responsible for computing the HEC of all outgoing cells. The second job is cell rate decoupling (this also takes place at the ATM layer). In ATM, the PHY must generate a continuous stream of cells at the appropriate speed for the physical medium. The TC sublayer is responsible for ensuring that this happens. It may have to insert idle cells in the network if there aren’t enough data cells. The TC also deals with transmission frame generation and recovery. Some physical layers used framed transport, and TC is responsible to dealing with these frames, including recovering them from the bit stream received from the PMD and computing appropriate framing for transmission to the PMD. Finally, TC finds cells. It receives a continuous bit stream and must find out where cells start. There are several ways to do this, including placing cells at well-defined positions within the frames of a framed transport (such as SONET) and actually searching for the cells. 33 TC Sublayer: Cell Rate Decoupling Why? § PHY data rate and ATM data rate may differ § PHY data rate must be maintained Cells at 100Mbps (from user) How? Cell rate decoupling § Insert idle cells in cell stream ©2003–2004 David Byers Cells at 155Mbps (e.g. STS-3c) An example where cell rate decoupling might take place is when a customer has paid for 100Mbps of capacity, but the actual link supports 155Mbps (e.g. STS-3c). Here the TC sublayer must insert about 30% worth of idle cells to make up the slack. Also note that this results in the inter-cell timings to be somewhat off, which may have to be compensated for at the receiver. 34 TC Sublayer: HEC Cell Delineation Extract cells from the bit stream received from PMD § Hunt for cell start „ Correct HEC for Y cells Hunt If a cell starts at bit bi, then CRC(bi … bi+39) = 0 § Wait X cells to ensure no false alarm Sync Incorrect HEC Correct HEC for X cells Correct HEC Presync ©2003–2004 David Byers § Assume synchronization lost on consecutive HEC failures One of the jobs of the traffic convergence sublayer is to detect where cells start. For some physical media, cells start at predefined positions. This can be the case in e.g. DS3, where the physical medium includes framing information. Here ATM cells can start at known positions. In other media, such as DS1 streams and SONET, the TC sublayer only sees a stream of bits from the PMD sublayer, and must extract the position of cells using some other mechanism. It starts in a hunt state, where it is looking for the start of a cell. The observation is that if a cell starts on a particular bit, then the CRC of that bit and the following 39 bits will be zero (the HEC cancels out). If the CRC of those bits is non-zero, then the TC tries to start a cell at the next bit. If all goes well, and there are no transmission errors, the TC will quickly find a potential start of a cell. Once the CRC is correct, the TC waits to see that several cells in a row arrive correctly. If they do not, then the start it found may have been a false alarm, so it goes back to hunting. Once several cells arrive OK in a row, the TC moves to the sync state. Once in the sync state, the HEC state machine is used to detect and correct errors in cells. If a number of consecutive errors occur in the sync state, the cell delination state machine moves back to the hunt state, under the assumption that synchronization has been lost. 35 ©2003–2004 David Byers ATM Layer 36 The ATM Layer § Forwarding tables § Cell switching § Multiplexing/demultiplexing Multiplexing AAL AAL Switching Input port Input port Input port Input port Switch table Switch table Switch table Switch table AAL Switch Fabric ATM Layer Pysical Layer Output port Output port Output port Output port ©2003–2004 David Byers Continuous cell stream The ATM layer is fundamentally responsible for two tasks: switching and multiplexing. Switching takes place mostly on NNIs, and is simply the process of moving cells between VCCs and taking them from input ports and sending them to output ports. Multiplexing is the process of accepting cells from various sources, mainly the AAL, and multiplexing them onto a continuous stream of cells. The ATM layer is responsible for creating a continuous stream of cells, and may insert empty cells when no real cells are being produced. Multiplexing several sources of cells can introduce timing variations that are not desirable. Assume one source generates a single cell every 125us. Assume also that there are lots of other sources, all competing for the same physical layer. After multiplexing, the cells from the first source may not be spaced out at exactly 125us; variations may be introduced by the multiplexing process. This is particularly important for real-time sources and when such variations cause cells to be sent at a higher rate than the negotiated rate. More on this later. 37 Switching: Label Translation § 4096 VPs, 65535 VCs § Not enough for networkwide VP/VC assignment! § Therefore VP/VC has significance only on a single link 44/214 VPin VPout 44 68 § Switches translate labels! ©2003–2004 David Byers 68/214 This demonstrates something very, very basic, which occurs in most label switching protocols. Cells are associated with virtual paths and channels, but nothing says that a particular path is identified by the same VPI throughout the network. This would, in fact, not scale at all since there are only 4096 VPIs, and coordinating VPI assignments throughout a large network would be prohibitively difficult. Therefore VPIs and VCIs only have local significance. When an ATM cell is switched from input to output interface, the VPI and VIC may be changes. The cell is still in the same VCC, but that VCC has a different identity on the new link. 38 Path or Circuit Switching Forwarding table translates only VPI Cells stay in the same VC bundle ©2003–2004 David Byers Forwarding table translates both VPI and VCI Cells can be switched from VP to VP and VC to VC At the ATM layer, switching takes place in two basic forms. In one, virtual paths are effectively terminated at the switch, and switching freely takes place among all VCCs. This allows a channel to move from one path to another. The other basic form is switching VPs as a bundle, ignoring their internals. 39 ©2003–2004 David Byers ATM Adaptation Layer 40 ATM Adaptation Layer Attributes Class A Class B Class C Class D Timing between src and dest Yes Yes No No Bit rate Constant Variable Variable Variable Connection mode CO CO CO CL Example Circuit Video emulation Audio service Frame relay LAN emulation ATM Adaption Layer AAL1 AAL3/4 AAL3/4 AAL5 ©2003–2004 David Byers AAL2 The ATM adaptation layer is where things start getting real. ATM defines several classes of service. The four original classes, A, B, C and D are shown in the table above. Each class corresponds to one AAL, which contains features to support the needs of that particular class. 41 AAL 1 SAP AAL1 Convergence Sublayer (CS) Segmentation and Reassembly (SAR) Sublayer SAP Target Networks § Constant bit rate § Timing information transferred § Connection oriented § High-rate audio/video § Circuit Emulation Service (CES) ©2003–2004 David Byers Class A Service AAL1 is used for class A service. Constant bit rate with timing information transferred. The protocol is connection oriented. The target applications for this AAL are circuit emulation, where e.g. a T1 is emulated over an ATM network, and high-rate audio and video. AAL1 is divided into two sublayers, the convergence sublayer and the SAR sublayer. It is accessed through service access points. 42 AAL1 SAR Sublayer 47 byes § Manages segmentation and reassembly of AAL1 PDUs § Adds one-byte SAR header to 47-byte CS payload § Receiver manages reassembly using sequence count § CRC over CSI and SC § Parity over CIS, SC and CRC CS SAR SN SNP Sequence count CRC Parity ©2003–2004 David Byers CSI 47 byes The SAR sublayer is responsible to segmentation and reassembly of AAL1 PDUs. It receives 47-byte PDUs from the CS and adds a header consisting of a sequence number and a checksum. It computes the CRC and assigns the sequence number. 43 AAL1 CS Sublayer § § § § § Handling of cell delay variation Processing sequence count Forward error correction Performance monitoring Data transfer modes „ „ P-Mode SP Structured Unstructured Data 46 bytes § Transfer of timing information „ „ SRTS Adaptive method Non-P-Mode ©2003–2004 David Byers 47 bytes The AAL1 convergence sublayer is responsible for a number of things. It is responsible to managing cell delay variations, to ensure that data is sent to the application layer at a constant rate, even if cells to not arrive at a constant rate. Depending on the application, the CS sublayer may insert extra bits in the stream when a buffer underrun occurs. The CS sublayer is responsible for handling the sequence count. It receives the sequence count from the SAR, and detects misinserted or lost cells. Misinserted cells are discarded, and lost cells may be compensated for by inserting dummy PDUs. The CS also provides forward error correction on the data, if required by the application. This feature may be used by high quality video or audio applications, but may not be required by all applications. Some applications need to measure performance, such as bit error rate, lost cells, misinserted cells, buffer overflow and underflows and so forth. The AAL CS is responsible for providing this service. AAL1 defines two modes of data transfer. In structured mode, the PDU starts with a one-byte pointer that indicates where in a cell data starts. This field is actually a parity bit and a seven bit pointer. The SP can be set in cells with an even sequence number. In unstructured mode, each PDU contains 47 bytes of data. The final function performed by AAL1 is transfer of timing information. For some applications, sender and receiver need to synchronize their clock frequencies. SRTS is one mechanism for clock synchronization between senter and receiver. It can be used when both can be slaved to the same clock. A four-but residual time stamp is transmitted using the CSI bit in the AAL1 header. The common reference clock must be derived from the network, so this method does not work on e.g. plesiochronous networks. In some cases, the AAL may be phase-locked to the network clock, in which case there needs to be no transfer of information at all. When no common reference is available, AAL1 uses the adaptive method. Here the buffer fill rate at the receiver is monitored, and if it is above median, the AAL assumes that it is delivering data too slowly and speeds up. If it is under median, the AAL slows down. 44 AAL2 SAP Convergence Sublayer AAL2 Service-Specific Convergence Sublayer (SSCS) Common Part Sublayer (CPS) SAP Target Networks § Variable bit rate § Timing information transferred § Connection oriented § Cellular networks § Private branch exchanges (PBX) ©2003–2004 David Byers Class B Service AAL2 is designed for class B service: variable bit rate with timing information. It is connection oriented. Target networks of this service include distribution networks for cellular networks and PBXs. AAL2 consists of a convergence sublayer, which in turn is split into a service-specific convergence sublayer and a common part sublayer. 45 AAL2 Multiplexing SAP SSCS SSCS SSCS CID A CID B CID C CPS Packets CPS CPS PDUs ©2003–2004 David Byers SAP One of the features of AAL2 that is not present in e.g. AAL1 is multiplexing. A single AAL2 session can multiplex data from several sources. Each source is identified by its own SSCS, but these all communicate with the same CPS. The SSCS transmits CPS packets to the CPS. The CPS interleaves these into CPS PDUs, which are sent to the ATM layer. 46 AAL2 Multiplexing CPS Packet CID PPT CPS Packets LI HEC UUI CPS PDUs CPS PDU P S N OSF ATM Cells ©2003–2004 David Byers PAD This slide shows how CPS packets from several sources, each with a CPS packet header, are placed into a single AAL2 cell stream. A single CPS packet may even be split across several CPS PDUs. CPS Packet CID – Channel identifier. Used to multiplex streams. Channels are bidirectional. Channels up to 7 have special meanings or are reserved. PPT – Packet payload type. PPT other than 3 indicate application data. PPT 3 indicates AAL network management function. LI – the total number of bytes in the payload of the CPS packet. It is actually one less than the length, so the maximum length of a CPS packet is 64 bytes. HEC – Header error control. Used to detect errors in the header. UUI – User-to-user indicator. Transported transparently by CPS. The CPS PDU header is called STF (Start field) P – Parity. Used to detect errors in the STF SN – Sequence numbers alternates 1-0-1-0 for successive PDUs. OSF – Offset field. Number of bytes between STF and start of the first packet in the PDU 47 AAL3/4 Convergence Sublayer AAL3/4 SAP Service-Specific Convergence Sublayer (SSCS) Common Part Sublayer (CPS) Segmentation and Reassembly (SAR) Sublayer Class C/D Service Features § Variable bit rate § No timing information § Connection oriented § Assured/non-assured transfer § Message or stream oriented § Supports several SSCS variants ©2003–2004 David Byers SAP AAL3/4 was origially defined for SMDS (Switched Multi-Megabit Data Service), but was adapted to ATM. Originally it provided class C service, but it was found to support class D as well. AAL3/4 is complex with a lot of overhead, and feels typical of a telecommunications committee product (if you thought ATM was complext up to now, you’ve got no idea). We won’t cover AAL3/4 here, because we don’t have enough time. Instead, we’ll look at AAL5, which is a simpler AAL suitable for e.g. packet switching. Suffice to say that AAL3/4 provides both packet-oriented and streamoriented service, with both assured and non-assured transfer. In assured mode, AAL3/4 manages retransmission of lost PDUs. AAL3/4 supports multiplexing like AAL2. 48 AAL5 SAP Convergence Sublayer AAL5 Service-Specific Convergence Sublayer (SSCS) Common Part Convergence Sublayer (CPCS) Segmentation and Reassembly (SAR) Sublayer Class D Service Features § Variable bit rate § No timing information § Connectionless § Non-assured transfer § Message or stream oriented § Error detection ©2003–2004 David Byers SAP AAL5 is an AAL for class D service. It is simpler than AAL3/4 and suitable for e.g. IP traffic and other connectionless services. If provides non-assured transfer of user PDUs, which means that higher-layer protocols must manage retransmission. Like AAL3/4 it consists of a convergence sublayer, which is further subdivided into a SSCS and CPCS, and a SAR sublayer. AAL5 does not provide multiplexing or assured forwarding since these can be left to higher layers. Therefore, AAL5 is a suitable choice only when these features can be provided by higher levels. Otherwise AAL3/4 is a better choice. 49 AAL5 PDU 0-65535 0-47 User PDU PAD CPS-UU CPI Padding so the entire PDU becomes a multiple of 48 bits User-to-user indication transferred transparently Common Part Indicator for future use Length of PDU in bytes Error control field CPS-UU 1 2 CPI 4 LI CRC-32 Notes § SAR segments PDUs into 48byte segments § No encapsulation at SAR level § SDU part of PTI set to zero for all segments but the last ©2003–2004 David Byers LI CRC-32 PAD 1 AAL5 places user data before a trailer containing fields more commonly placed in a header. 50 ©2003–2004 David Byers IP Over ATM 51 IP Over ATM § LAN Emulation (LANE) „ „ ATM Network emulates LAN Allows applications to operate with no changes § IP Switching „ „ Switch IP packets directly Proprietary solutions § MPLS „ „ Find next hop towards destination § Classical IP over ATM „ Treat ATM network as a point-to-point link § Multiprotocol over ATM „ „ Unified approach for all layer 3 protocols over ATM Uses NHRP and LANE ©2003–2004 David Byers „ Successor to IP switching Independent of ATM § Next-Hop Resolution Protocol IP and ATM are not a particularly good match. IP has large frames of up to 65k data, with low overhead, whereas ATM has tiny cells with high overhead. IP does not require QoS. ATM expends considerable effort to provide QoS. Loss of an ATM cell results in loss of an IP frame, but it may not be detected by the ATM layer, resulting in unnecessary switchin. ATM has its own signalling protocols. The ATM philosophy is completely different from the IP philosophy. And so in. Still, ATM was the first transport defined for high-performance networks, so IP over ATM is unavoidable, and there are several methods to run IP over ATM. LAN Emulation, which exists in several variants, emulates the characteristics of a LAN, typically an Ethernet, over ATM. Applications that normally run over LAN can run without modification on top of LAN emulation. This implies that ATM needs to support features of the LAN such as broadcasting, multicasting and address resolution. IP Switching is another option, where IP packets are switched directly. It is possible here to exploit native ATM switching by assigning related IP packets to the same VC. Another obvious method, perhaps most useful when a permanent or semi-permanent connection is desired, is to use tunneling. This is probably used more than many people realize. When purchasing a T3 in the USA or an E3 in Europe, the electrical network may reach only reach a short distance, before being fed into an ATM network, using CES. When running PPP over the T3, which is fairly common, this essentially results in tunneling IP over ATM. It is also possible to run PPP directly on top of ATM. Finally, MPLS can be integrated into an ATM network. Essentially the signalling plane of ATM is replaced with IP protocols. The VPI/VCI field in the ATM cells is used to provide switching of MPLS labels. Then IP can be run on top of MPLS. 52 LAN Emulation LLC AAL5 ATM PHY Bridge Bridge LLC LLC IP LLC MAC MAC LANE Emulates 802.3 and 802.5 MAC/LLC Can operate as part of the protocol stack Can operate as part of an Ethernet/ATM bridge Allows multipls virtual LANs on one ATM network Preserves contents of 802.3 or 802.5 frames § § § § § LANE LANE LANE AAL5 AAL5 ATM PHY MAC LLC ATM ATM PHY IP PHY MAC PHY ©2003–2004 David Byers IP LANE emulates a 802.3 or 802.5 MAC, allowing higher layers to be unchanged. There are two important configurations for LANE – one which allows devices to be directly connected to an ATM network by replacing the low-level network drivers with LANE, and another which bridges between legacy networks and an ATM network. We won’t cover LANE framing in any detail, but it is worth noting that it in no way alters the original LLC frames; it just adds a header. 53 LAN Emulation LANE Components LEC LECS LES BUS LAN Emulation Client LAN Emulation Configuration Server Lan Emulation Server Broadcast and Unknown Server § LEC „ § LECS „ Controls which clients belong to which LAN; handles clients joining and leaving the LAN; address resolution § LES „ Handles multicast, some data forwarding § BUS „ Manages broadcast and multicast ©2003–2004 David Byers LUNI LAN emulation User to Network Interface defines interaction between LE clients and servers Client software in ATM node LANE is quite complex and requires a number of components. The LEC is simply the client device. It could be a computer or Ethernet switch. LEC is really the software in this device, but the distinction isn’t really that important. The LECS is a server on the ELAN (emulated LAN), which provides configuration information. We’ll show the role of the LECS shortly. The LES is a LAN emulation server, which provides for key functions such as multicasting. The BUS is a server that supports broadcasting and communication with unknown clients (which is done by broadcasting). Since ATM is a nonbroadcast network, the BUS must maintain a point-to-multipoint connection with all LEC’s. Finally the acronym LUNI is often seen. It is the protocol between LEC and servers. 54 LAN Emulation Configuration direct VCC Control direct VCC LEC LECS LES Configuration direct VCC Control direct VCC Control Distribute VCC Multicast send BUS Multicast send LEC Multicast Forward VCC ©2003–2004 David Byers Data Direct VCC This diagram shows what communication channels typically exist in an ELAN with two clients. The control distribute and multicast forward VCCs are point-to-multipont connections used for broadcasting and multicasting. 55 LANE Operation § Initialisation „ Get address of LES and LECS § Configuration „ Send ATM and MAC address and frame size to LECS § Joining „ „ Create VCC with LES Send join request to LES § Registration „ „ Send MAC to LES Declare if LEC wants ARPs § Register with BUS „ „ Find BUS (ARP for ff:ff:ff:ff:ff:ff) Register to join multicast VCC § Address Resolution „ „ Send LE-ARP to LES LES may forward to LECs § Broadcast/multicast „ „ Send frames to BUS BUS forwards to all LECs § Data transfer „ Get ATM address from LES Set up SVC for data traffic ©2003–2004 David Byers „ No notes with this slide. 56 LANE Operation Address Resolution Broadcast and multicast § Translate MAC address to ATM address § LE-ARP sent to LES § LES may forward to LEC (e.g. in case of bridged LAN, LEC may need to ARP for the MAC address) § Broadcast and multicast frames sent to BUS § BUS forwards frames over multicast ATM channel LE-ARP LEC Forward to all LECs Send REPLY LEC LEC LEC LEC LEC ©2003–2004 David Byers New SVC LES BUS No notes with this slide. 57 Classical IP Over ATM (CIOA) Operation § Subdivision of the network § Contains hosts and routers § Served by LIS server ARMARP for address resolution Routers between LISes ©2003–2004 David Byers Logical Independent Subnet Classical IP over ATM is one of the simplest methods of transporting IP over an ATM network. Here, IP hosts are classified into logical independent subnetworks, which roughly correspond to LANs in an Ethernet/IP environment. The main problem is address resolution – how does an IP host know how to reach another IP host? This is handled through the use of ATMARP. ATMARP is a query, sent to a LIS server, asking for the ATM address corresponding to an IP address. The LIS server, which keeps track of membership in the LIS much like a LES server does in LANE, responds, and the IP host can then set up a SVC to the destination. To communicate from LIS to LIS, regular routers are needed, even if all LISes are on the same ATM network. These routers belong to both LISes, and must reassenble IP packets and perform IP processing to forward them. This is perhaps the most serious drawback of CIOA. 58 Next-Hop Resolution Protocol Operation § Resolve layer 3 address to ATM address of destination or next hop towards destination § Direct connection set up across multiple LISes ©2003–2004 David Byers Operation NHRP is a protocol for routing layer 3 packets over an ATM network, without involving intermediary routers. The concept of a LIS is still in NHRP, but the role of the servers, not called NHRP servers, is different. When a device wants to send an IP packet to another device, it queries the NHRP server for the next hop towards the destination. If the destination is on the same LIS as the source, the NHRP server will respond with the ATM address of the destination, much like an ATMARP reply. If the destination is not on the same LIS, the NHRP server forwards the query to another device that is closer to the destination. This process may be repeated several times until the NHRP server serving the LIS on which the destination is located can reply with the ATM address of the destination. This allows the source to set up a connection directly to the destination, without involving intermediary routers. If the destination is on a different ATM network, IP packets will be forwarded to an egress router, which will have to perform IP processing to forward the packet to the destination. While waiting for the NHRP answer, packets may be forwarded along the routed path. This reduces overall latency as communication can take place even before a direct connection can be set up. A nice feature of NHRP is that is is possible to indicate desired QoS for the connection. I don’t know if this has been standardised, but it is something that has been under consideration. 59 MPOA Very simplified Principles § LANE + NHRP § Separate route calculation from packet forwarding § Routers become route servers Components § LANE provides backward compatibility § NHRP extensions provide better performance for MPOA-aware clients ©2003–2004 David Byers § MPS: MPOA Server § MPC: MPOA client Multiprotocol over ATM is an improvement over LANE, CIOA and NHRP. The goal is to provide a protocol-agnostic layer 3 transport over ATM, while still maintaining compatibility with legacy equipment. MPOA basically accomplishes this by combining NHRP and LANE. It uses LANE for layer 2 forwarding and NHRP to set up direct layer 3 connections. 60 ©2003–2004 David Byers QoS 61 Traffic Characterisation Additional parameters: CDVT Cell Delay Variation Tolerance Characterisation of randomness in the source that may result in exceeding the PCR BT Burst Tolerance Computed from MBS to specify how large bursts an ATM switch accepts ©2003–2004 David Byers PCR Peak Cell Rate The maximum amount of traffic that can be sent SCR Sustained Cell Rate Upper bound on average cell rate MBS Maximum Burst Size Maximum number of cells submitted at PCR In ATM, traffic is characterised by a number of parameters, most of which are listed on this page. Note that CDVT and BT are not really characteristics of the traffic, but parameters used to determine if actual traffic conforms to a negotiated level of service. PCR is the maximum rate at which cells are ever sent. SCR is an upper bound of the average cell rate over a specific interval. It is not an average of the cell rate over the lifetime of a connection. MBS is tha maximum burst size, or the maximum number of cells that will ever be transmitted back-toback at the peak cell rate. The CDVT and BT parameters are used in traffic policing. We’ll look at exactly how they’re used later. 62 QoS Parameters Cell loss rate Ratio of lost cells to delivered cells CTD Cell transfer delay Sum of fixed delays a cell encounters along a path CDV Cell delay variation Sum of variable delays a cell encounters along a path MCR Minimum cell rate Minimum cell rate guarantee for ABR connections ©2003–2004 David Byers CLR ATM also specifies a number of QoS parameters. These are signalled during call setup, and the set is not fixed. The ATM forum and the ITU specify a different set of parameters, and others may be added later. Popular parameters include the ones above. Note that the MCR parameter is only used in available bit rate connections; a concept we haven’t talked about yet. 63 Service Categories CBR rt-VBR nrt-VBR Constant bit rate Real-time variable bitrate Non-real-time variable bitrate ABR UBR Available bitrate Unspecified bitrate ATM Service Category CBR CLR rt-VBR nrt-VBR Specified MCR Feedback Unspecified Unspecified Specified PCR & CDVT SCR & MBS UBR Network specific Specified CTD & CDV ABR N/A Specified N/A N/A Specified N/A Unspecified Specified N/A ©2003–2004 David Byers Attribute This table, which I nicked from somewhere, does a good job of summarising traffic characterisation and QoS parameters with respect to various service categories. ATM supports constand and variable bitrates, which we’ve already talked a little about. It also supports available bitrate, which is a service category that requires the sender to adapt to congestion in the network. ABR is a lot like best-effort with the exception that it is possible to specify a minimum cell rate. UBR is a special category. It gives not guarantees at all and has the lowest precedence of all. 64 Examples DS1 Circuit Emulation § § § § § CBR CTD < 100ms CDV < 5ms PCR = 8000 cps CDVT depends . . . 100 Mbps data traffic § ABR § PCR = 284940 cps § MCR = 2850 cps GSM Voice Connection rt-VBR CTD < 100ms CDV < 10ms PCR = 1875 CDVT depends . . . ©2003–2004 David Byers § § § § § Here are some purely hypothetical examples of different applications of the service types. The parameters are probably not currect. The service categories probably are. 65 The ABR Service § Peak and minimum cell rate § Feedback-based reactive congestion control § ABR cell rate varies between MCR and PCR depending on network load CBR Fixed at 1000 ©2003–2004 David Byers ABR Varies between 2000 and 3000 The ABR service type is likely to be the most popular in the long run as it provides the highest level of network utilisation. ABR and even VBR services leave much capacity unused. With minimum cell rate guarantees, ABR services can even be used for applications that previously would have used VBR. In ABR the sender is allowed to increase sending rate up to the PCR when there is slack in the network, but is also required (or requested) to decrease the rate when the network is congested. The sender may always send at the minimum guaranteed rate, the MCR. Note, however, that ABR is not intended for real-time applications. There are no guarantees of loss or delay. ABR is implemented using feedback. When the network starts to become congested, the network informs the sender of this, and the sender is required to reduce the rate of transmission. The feedback mechanism is implemented using resource management cells, which are ATM cells with the PTI set to 110. The transmitting end device generates RM cells which are sent through the network to the receiver, who then returns them to the sender. Along the way, the network has the opportunity to alter the cells. 66 ABR Congestion Control Control path Explicit rate mode § Destination returns RM cells § Switches set ER in return cells § Source adjusts rate accordingly ©2003–2004 David Byers Binary Mode § Switch sets EFCI in forward cells § Destination sets CI or NI in return cells § Source adjusts rate accordingly ABR provides two mechanisms for congestion control. In binary mode, the sender is told to speed up, hold or slow down (so it’s really ternary). In explicit rate mode the sending rate is specified by the network. This is all accomplished by making every 32nd cell a resource management (RM) cell. When a switch receives an RM cell, it computes how much bandwidth is available for the ABR connection, and writes that into the cell. If may also set a bit called EFCI in the cell header to indicate congestion or no congestion. The receiver, upon receiving the RM cell, removes the EFCI bit and sets either ”congestion indication” or ”no increase” in the RM cell and returns it to the sender. Along the way, switches may further modify the cell. The sender, upon receiving an RM cell, must obey the indications in the cell. It is possible for a switch to generate RM cells and send them to the sender. This may be done if conditions change rapidly and the switch wants to notify the sender without waiting for the RM cell to traverse the network all the way to the receiver. 67 ABR Congestion Control § Every 32nd cell is a RM cell „ „ „ „ „ ER set to desired rate CCR set to current rate MCR set to minimum rate ID = 1, DIR = 0, BN = 0, CI = 0, NI = 0, RA = 0 RM cells are sent through the network RM Cell ID B C N R N I I A ER CCR MCR QL QL (cont.) SN SN (cont.) ©2003–2004 David Byers § Switches modify EFCN or ER in response to network load § Destination sets NI or CI and returns RM cell D I R The RM cell has several fields. ER is the rate that the sender may use. It is set by switches along the path. A switch will never write a higher rate into the ER field than the one already there. By the time the cell gets to the receiver, the ER field will contain a rate acceptable to all switches along the path. CCR is the current sending rate, set by the sender. MCR is the minimum rate that the sender is willing to accept. This should have been negotiated when the connection was admitted to the network. The sender is guaranteed this rate. ID is fixed to one. DIR indicates the direction of the RM cell. BN indicates if the cell is a backward notification. CI indicates if there is congestion. NI indicates that the sender may not increase the transmission rate. I forget what RA was. 68 ABR Congestion Control § Propagation delay issues „ „ „ 125 miles at 622Mbps means 1462 cells may be in transit at once Response to RM cells may require another 1462 cells May cause instability § Segmented control loops RM cells to not travel endto-end but are returned by switches ©2003–2004 David Byers „ A problem with the RM-based scheme arises when the bandwidth-delay product is high. Take a network with 125 miles of fiber running at 622Mbps. In this network, there can be 1462 cells (don’t ask me to re-do the calculations) sitting in the network at one time. By the time an RM cell has traversed the network, nearly 3000 cells have been transmitted. Thus, reaction to changing conditions, although fast in terms of real time, are slow in terms of the cell rate. This can lead to instabilities, congestion and other problems. To counter this, it is possible to create segmented control loops, where RM cells do not travel all the way to the destination, but are returned by intermediary switches. A detailed discussion about segmented control loops is beyond the scope of this lecture. 69 Preventive Congestion Control Bandwidth Enforcement § Strictly enforce negotiated traffic characteristics ©2003–2004 David Byers Call Admission Control § Only allow connections whose requirements can be guaranteed ABR uses reactive congestion control, but ATM traditionally was based on preventive congestion control. This is based on two principles: call admission control (CAC) and bandwidth enforcement. 70 Call Admission Control (CAC) Statistical allocation § Less than PCR is reserved § If all sources send at PCR, requirements will exceed available resources § Difficult to tune correctly § Better utilisation of resources than nonstatistical allocation ©2003–2004 David Byers Non-statistical allocation § Entire PCR is reserved § If senders to not send at PCR continuously, wastes resources Call Admission Control (CAC) is the process of admitting a connection to the network. The principle is that a connection is only admitted if its QoS requirements can be met (and other QoS commitments can be kept). A call begins with a signal from the caller that contains specifications of the QoS requirements and traffic characteristics. Each switch along the path from sender to receiver must allocate resources to meet the QoS requirements; if a switch is unable to do so, an alternate path is attempted until there are not more paths. There are two basic principles for resource allocation: statistical and nonstatistical. Non-statistical allocation is appropriate for constant bit rate applications, but leads to resource waste for VBR connections. Statistical allocation, on the other hand, can lead to overcommitment. Here a model of the traffic is used, and enough resources are allocated that statistically, all QoS commitments can be met. If, for example, all VBR connections would peak at the same time, however, enough resources to handle the peak would not be available. 71 Bandwidth Enforcement Policing Mechanisms § Ensuring that a source does not exceed the negotiated service contract § Specifically, limit PCR and SCR to negotiated values § Leaky bucket § Double leaky bucket § GCRA Tokens Tokens K K Unbuffered leaky bucket Buffered leaky bucket ©2003–2004 David Byers Buffer Traffic policing involves ensuring that a source does not send outside the bounds of the traffic contract. The terms that a source must adhere to typically involve PCR, SCR and MBS. A simple mechanism for policing is the leaky bucket, which has been covered in the basic course. The problem with this mechanism is that it is difficult to tune the parameters so that all nonconforming cells are detected and all conforming cells are passed transparently. Therefore, this is not the mechanism preferred in ATM networks. Instead, the generic cell rate algorithm is commonly used, and it can be modeled as a double leaky bucket. 72 GCRA Virtual Scheduling Start yes no Cell not compliant yes § § § § TAT = ts TAT > ts + τ T = 1/PCR τ = CDVT ts – Actual arrival time of cell TAT – Theoretical arrival time of the next cell T no Transmission time TAT = TAT + T Arrival time at the UNI ts ts ts ts ©2003–2004 David Byers TAT <= ts Parameters Consider an example T=10 tau=15 Arrival times are 0, 12 18 20, 25, 30, 36 Cell 1: TAT=0, ts = 0, so the cell is conformant. TAT = 10 Cell 2: TAT=10, ts = 12, so the cell is conformant. TAT = 20 Cell 3: TAT=20, ts = 18, so the cell is early, but tau+ts=33, so the cell is conformant Cell 4: TAT=30, ts = 20, so the cell is early, but tau+ts=35, so the cell is conformant Cell 5: TAT=40, ts = 25, so the cell is early, and tau+ts=40, so the cell is not conformant Cell 6: TAT=40, ts = 30, so the cell is early, but tau+ts=45, so the cell is conformant Cell 7: TAT=50, ts = 36, so the cell is early, but tau+ts=51, so the cell is conformant The next cell will have to arrive at 46 or later to be conformant Note how the value of tau is ”eaten up” by successive early cells. 73 GCRA Continuous Leaky Bucket Start Parameters § § § § § X’ = X – (ts – LCT) yes X’ <= 0 T = 1/PCR τ = CDVT ts – Actual arrival time of cell X – State of leaky bucket LCT – Last Compliance Time no X’ = 0 Cell not compliant yes X’ > τ Notes § X’ <= 0 – Cell is late § X’ > 0 – Cell is early X = X’ + T LCT = ts ©2003–2004 David Byers no Consider an example T=10 tau=15 Arrival times are 0, 12 18 20, 25, 30, 36 Cell 1: X=0, LCT=0 ts=0 à X’ = 0: The cell is compliant; LCT=0, X=10 Cell 2: X=10, LCT=0, ts=12 à X’ = -2: The cell is compliant; LCT=12, X=8 Cell 3: X=8, LCT=12, ts=18 à X’ = 2: The cell is early, but X’ is less than tau so it is compliant; LCT=18, X=12 Cell 4: X=12, LCT=18, ts=20 à X’ = 10: The cell is early but compliant; LCT=20, X=20 Cell 5: X=20, LCT=20, ts=20 à X’ = 20: The cell is not compliant; Cell 6: X=20, LCT=20, ts=25 à X’ = 15: The cell is compliant; LCT=25, X=25 And so on. 74 Policing Both PCR and SCR § One GCRA for PCR „ T = 1/PCR τ = CDVT GCRA(1/PCR, CDVT) § One GCRA for SCR „ „ Ts = 1/SCR τ = Burst tolerance = (MBS – 1)(Ts – T) GCRA(1/SCR, BT) Non-compliant cells Dropped or marked CLP=1 „ ©2003–2004 David Byers Compliant cells queued for output Bandwidth policing is a combination of policing the PCR and the SCR. This is accmomplished by combining a GCRA for the PCR with a GCRA for the SCR. First cells are tested for compliance with the PCR, then with the SCR. So what about cells that are found to be non-compliant? What happens? The simplistic thing to do would be to just drop them, but if there is slack in the network, there is no reason not to send them. An option, therefore, is to simply mark them with CLP=1, so that they can be dropped quickly later in the network, if need be. 75 ©2003–2004 David Byers ATM Signalling Signalling is a function mainly needed to manage SVCs. Setting up a PVC can be a matter of manual configuration, but a SVC needs to be created and torn down in real time. Therefore, signalling is a crucial part of ATM. 76 Signalling Protocol Stack Signalling Protocols Signalling ATM Adaptation Layer (SAAL) ATM Layer Physical Layer § VPI/VCI = 0/5 – Unassociated signalling for signalling regarding all VCCs; default circuit § VPI/VCI = x/5 – Nonassociated signalling; signalling regarding VCs within a specific VP ©2003–2004 David Byers Signalling channel Signalling protocols are nothing special in ATM. They are just protocols that run on top of an AAL, as does everything else. The SAAL, the AAL for signalling, is further subdivided into sublayers 77 SAAL SAP Service-Specific Coordination Function (SSCF) Service-Specific Connection-Oriented Protocol (SSCOP) Common Part Convergence Sublayer (CPCS) Service-Specific Convergence Sublayer (SSCS) SAAL AAL5 ©2003–2004 David Byers SAP The SAAL consists of two sublayers, much like other AALs. Its CPCS is simply AAL5, which provides most of the transport functionality. The SSCS is further subdivided into the Service-Specific Coordination Function and Service-Specific Connection-Oriented Protocol. The SSCOP provides assured transfer of frames across a network with a high bandwidth-delay product. It was designed for ATM as earlier protocols, such as LAP-D in ISDN use a simple ARQ scheme, which is not effective in ATM networks. The SSCF maps the services provided by the SSCOP to services required by the user of the SAAL. 78 Metasignalling § Establish „ „ Establish a signalling channel Point-to-point, broadcast or selective broadcast ASSIGN REQUEST ASSIGNED/DENIED REMOVE REQUEST § Release „ Remove a signalling channel REMOVE ASSIGNED/DENIED § Verify Verify status of signalling channel CHECK REQUEST CHECK RESPONSE ©2003–2004 David Byers „ Beyond the normal signalling, there is need for metasignalling, for establishing and tearing down signalling channels. Metasignalling, since it deals with only one thing, can be very simple. Metasignalling is not needed if there is a default signalling channel, which there currently is in ATM. There are three functions: establish a signalling channel, tear down a signalling channel and check the status of a signalling channel. 79 Signalling Protocols Q.2931 Sidebar: SS7 § User-to-UNI protocol for pointto-point curcuits SS7, SS7, Signalling Signalling System System 7, 7, also also known known as as C7 C7 and and CCIS7, CCIS7, is is an an ITU ITU standard standard for for out-of-band out-of-band signalling signalling protocol protocol in in the the telephone telephone network. network. It is designed to It is designed to replace replace earlier earlier ininband band signalling signalling systems. systems. Q.2971 § User-to-UNI protocol for pointto-multipoint circuits B-ICI § Signalling between networks § Based on B-ISUP which is based on SS7 SS7 SS7 deals deals with with issues issues such such as as call call setup, setup, call call routing, routing, caller caller ID, ID, multimultipart part calls, calls, toll-free toll-free calls, calls, as as well well as as OAM OAM issues. issues. PNNI ©2003–2004 David Byers § Private NNI-NNI signalling For communication between the UNI and network, there are two protocols in use today, although since signalling is noting special in ATM, other protocols may be used. Q.2931 is used to set up point-to-point connections. Q.2971, which uses Q.2931, is used for point-to-multipoint connections. These are both ITU standards and they are endorsed by the ATM forum (which, in fact, was instrumental in designing them). For signalling between network elements, ATM differentiates between private and public signalling. Private signalling takes place between NNIs that are under common control, e.g. the network belonging to a particular carrier. Public signalling takes place between carriers. ATM uses PNNI for private signalling and B-ICI for public signalling. PNNI includes all the features necessary to perform routing and set QoS parameters. B-ICI is more limited. It does not support routing (inter-carrier links are set up statically) and only supports a subset of the services that ATM can provide. B-ICI is based on SS7, the signalling system used in the telephone network. In addition to these there is AINI and public UNI, both used for public signalling. AINI may take the place of B-ICI as the design allows better 80 ATM Signalling Protocols Public UNI or AINI or B-ICI Q.2931 AT&T Q.2931 MCI ©2003–2004 David Byers PNNI 81 Q.2931 Notes Call Establishment § Used to establish point-to-point connection § Three groups of message types § Each message contains information elements that can convey e.g. QoS requirements § ALERTING, CALL PROCEEDING, CONNECT, CONNECT ACKNOWLEDGMENT, SETUP Call Clearing § RELEASE, RELEASE COMPLETE Miscellaneous ©2003–2004 David Byers § NOTIFY, STATUS, STATUS ENQUIRY Q.2931 is the protocol used to communicate with the UNI. It handles establishment of point-to-point connections. The protocol is very flexible in that the message format is extensible. Each message consists of a message type, fixed message parameters and a set of information elements. These elements can express such things as QoS requirements or client capabilities. There are three groups of message types: messages for call establishment, messages for call clearing and messages for various other things. Call establishment messages deal with setting up connections. Call clearing messages deal with tearing them down. The rest deal with getting information from the network, such as querying the status of a connection. 82 Q.2931 ALERTING § Sent by called party to notify network that it is alerting a human CALL PROCEEDING § Sent by called user to indicate that the call is being initiated CONNECT § Sent by the called user to indicate that call is accepted RELEASE § Sent by user to request clear a connection RELEASE COMPLETE § Sent by user to indicate that clearing is complete SETUP § Sent by user to initiate establishment of new call CONNECT ACKNOWLEDGMENT Send by network to called user to indicate that connect is OK ©2003–2004 David Byers § This slide lists some of the specifi messages in Q.2931. 83 Adressing in ATM DCC ATM AFI DCC High Order-DSP ESI SEL High Order-DSP ESI SEL ESI SEL ICD ATM AFI ICD E.164 ATM AFI DCC IDC ESI SEL E.164 Authority and Format Identifier Data Country Code International Code Designator End System Identifier Intra-Endpoint Selector HO-DSP Initial Domain Part (IDP) Initial Domain Identifier (IDI) underlined Domain-Specific Part Administered by authority identified by IDI ©2003–2004 David Byers AFI ATM devices all have unique ATM adresses. Depending on whether the device is on a public or private network, it will use different adresses. Devicec on a public network use E.164 adresses, whereas devices on private networks use OSI NSAP adresses. E.164 adresses consist of 16 digits, each encoded in BCD format, using four bits. The first digit determines if the adress is unicast or multicast; the next three indicate a country code and the remaining digits indicate a city codde, exchange code and end device identifier. E.164 addresses are more popularly known as ”telephone numbers”. Or almost so anyway. Private adresses consist of two parts, the Initial Domain Part (IDP) and the Domain-Specific Part (DSP). The IDP specifies the authority who assigns values for the DSP. It is further subdivided into Authority and Format Identifier (AFI) and Initial Domain Identidier (IDI). The AFI indicates the format of the IDI. The ATM forum has defined three IDIs: 1. DCC (Data Country Code); the DCC consists of a two-byte country code according to ISO3166 and adresses are adminisered by the ISO’s national member body in each country. 2. ICD (International Code Designator); The ICD identifies an authority which administers a coding scheme; the registration authority for the ICD is maintained by the British standards institute. 3. E.164 Adresses The AFI identifies what kind of adress it is The IDI identifies the specific authority within the adressing scheme The high-order DSP is an adress administered by the coding scheme authority The ESI is an end-system identifier, within the particular adress identified by the HO-DSP and IDP The SEL is to select an endpoint within an end system. The HO-DSP field may be further subdivided into fields, depending on the coding scheme. For example, it may include topological information. 84 Q.2931 Call Example ATM Network User User SETU P PROC CALL SETU P PROC CALL NECT CON CON N AC K NECT CON Q.2931 PNNI Q.2931 ©2003–2004 David Byers CON N AC K This shows how a call is set up using Q.2931. Note that Q.2931 is only used between the user and the UNI. Within the ATM network other protocols, typically PNNI are used. 85 Q.2931 Release Example ATM Network User User RELE ASE OMP REL C RELE ASE OMP REL C PNNI Q.2931 ©2003–2004 David Byers Q.2931 This demonstrates how a call is torn down. Again, Q.2931 is only used between the user and the UNI. PNNI is used elsewhere. 86 Q.2971 Notes Message types § Use to establish point-tomultipoint connections § Starts with point-to-point § Can add and drop parties § Root: Sender § Leaf: Receiver § ADD PARTY, ADD PARTY ACK, PARTY ALERTING, ADD PARTY REJECT, DROP PARTY, DROP PARTY ACK Leaf-Initiated Join ©2003–2004 David Byers § A leaf can request to be added to a multicast tree ATM supports more features than Q.2931. In particular, Q.2931 only deals with point-to-point connections. While these are the most common, ATM supports point-to-multipoint, multipoint-to-point and multipoint-to-multipoint connections as well. Q.2971 can be seen as an extension to Q.2931, which supports point-to-multipoint connections. An interesting point of this protocol is that it not only permits the point to add nodes to a call, but it also permits leaves to add themselves to an existing point-to-multipoint connection. This is particularly useful in systems such as MPOA, where a new node might want to join the existing multicast connection used to simulate LAN broadcast. 87 PNNI PNNI Signalling Protocol § Discovery of neighbors and link status § Synchronization of topology databases § Summarization of topology state information § Construction of routing hierarchy § Call clearing § Call establishment § Dynamic call setup ©2003–2004 David Byers PNNI Routing Protocol Q.2931 and Q.2971 deal with signalling between the user and the UNI. Within a private network, other protocols are used. The predominant protocol is PNNI version 2.0. I will describe some of the features of PNNI, but mainly stick to features that were already in version 1.0. Version 2.0 offers such features as leaf-initiated join, security and call coordination (allowing the network to re-establish a failed connection). PNNI is similar to the user-UNI protocol, but also includes features to deal with issues such as routing. The PNNI is divided into a routing part and a signalling part. The routing part is concerned with computing topology and reachability information, whereas the signalling part is concerned with establishing and clearing connections, and uses the topology and reachability information created by the PNNI routing. The protocols are quite complex, so we will only cover them from a high altitude. There will be hand-waving. There will be proof by obfuscation. If you want the details, the specifications are available on-line from the ATM forum. They’re actually quite readable. 88 ©2003–2004 David Byers Physical Network PNNI routing is a departure from the routing protocols used in IP. In some ways it is similar to link-state protocols such as OSPF and IS-IS, but it takes the concepts much further. PNNI is a link-state protocol, and as all link-state protocols this implies that every node has full information about the network topology. In reality, this is not the case since such a system would not scale very well. A network with 30 nodes would be no problem. One with 300 might work. With 3000 nodes, forcing every node to have full information (and flooding all changes to all nodes) would be disasterous. To counter this problem, link-state protocols create hierarchies. In OSPF, networks are organized in two-level hierarchies. Specifically, the network is divided into areas, one of which is designated a backbone area and carries all inter-area communication (well, not really, since it is possible to fudge direct inter-area links). This improves scalability, but only to a certain point, since areas cannot be further subdivided. PNNI takes the idea to its conclusion. It allows the network administrator to create arbitrary hierarchies, resulting in a highly scalable protocol. Nodes in the network end up having complete information about their immediate surroundings, and summarized information about everything else. The level of detail decreases with logical distance from a node. The hierarchy starts with the physical network. Nodes all have addresses (AESA – ATM End-System Address) and are configured to belong to socalled peer groups. 89 Lowest Hierarchy Level PG(B.2) B.2.1 PG(A.2) B.2.2 A.2.3 B.2.3 PG(B.1) PG(A.1) A.2.2 PG(A.3) A.2.1 A.1.3 B.1.1 B.2.5 B.2.4 B.1.2 A.3.1 A.4.1 A.1.2 A.3.4 A.3.2 A.4.2 A.3.3 A.4.3 A.1.1 A.4.4 A.4.5 B.1.3 C.1 C.2 A.4.6 Peer group Logical Link PG(A.4) Border node Peer group leader ©2003–2004 David Byers PG(C) In a large network, maintaining complete information about the topology is neither practical or desirable. It requires a large amount of memory, and changes to the topology, regardless of what parts of the network they affect, will be flooded throughout the network, wasting capacity. To counter this, many routing protocols, including OSPF, IS-IS and PNNI create a hierarchical abstraction of the network. In PNNI, nodes are grouped into peer groups. The peer group a particular node belongs to is configured in the node itself – it is not derived from the network topology. At startup, nodes exchange HELLO messages to determine their immediate neighbors, and then construct PNNI Topology State Elements, which describe the immediate surroundings, and flood these to all nodes in the peer group. By doing this, all nodes will have complete topology information for their own peer group, and will be able to route traffic within the peer group. Nodes also flood reachability information (the addresses each node knows how to reach) through PTSEs. Within each peer group a peer group leader is elected. This node is responsible for coordinating actions that involve the entire peer group, such as information exchange with other peer groups. Border nodes exchange information with border nodes in other peer groups regarding the peer group they belong to. This allows neighboring peer groups to determine if they belong to the same higher-level peer group, which is necessary to construct the next level of the hierarchy. 90 Second Hierarchy level PG(A) B.1 A.1 B.2 PG(B) A.4 A.2 ©2003–2004 David Byers A.3 Peer groups are represented by logical peer group nodes, implemented by the peer group leader. Each such node has an end system address, just like a physical node, so connections can be set up between it and other nodes. Logical peer group nodes are organized into higher-level peer groups. As higher level peer groups are performed, three kinds of summarization takes place. Address summarization abstracts the addresses reachable within a peer group, decreasing the level of detail in the reachability information passed to other peer groups. Topology summarization summarizes the internal topology of peer groups, essentially reducing them to multi-port nodes. Link summarization summarizes the logical links between peer groups. Various information is passed up and down the hierarchy. Higher-level nodes pass topology information about the higher level down to the peer groups, allowing them to deduce reachability to other peer groups. Peer groups, in turn, pass information about local reachability and topology up to the peer group nodes, giving them information that is passed to other peer groups. 91 Uplinks A.2 A.1 A.3 PG(A) A.4 A.4.1 A.4.2 A.3.1 A.4.3 A.3.2 A.3.4 A.4.4 A.3.3 A.4.5 A.4.6 PG(A.4) ©2003–2004 David Byers PG(A.3) Border nodes need to advertise connectivity to other peer groups. This is accomplished by advertising an uplink; a link connecting the border node to the peer group node for the neighboring peer group. The uplinks are used by peer group leaders to construct the higher-level hierarchy – the connections between peer groups. 92 ©2003–2004 David Byers Complete PNNI Hierarchy This picture shows the entire PNNI hierarchy for the example network. 93 Single Node Perspective A B C A.2 A.1 A.3 A.4 A.3.1 A.3.3 ©2003–2004 David Byers A.3.2 A.3.4 As mentioned earlier, nodes have increasingly less detailed information about the network, the farther away from the node the network is. Viewing the information held by a single node, this is evident. Nodes know everything about their peer group as topology and reachability information is flooded through the peer group. This is the most detailed level. Nodes know about their parent peer group, but only have summary information about the other peer groups within the parent peer group. This information is flooded from the parent peer group (the peer group leader) into the network. Similarly, nodes know about higher-level ancestor peer groups, but only have summary information about nodes in these peer groups. 94 PNNI Signalling Source routed Designated Transfer List (DTL) § Allows different path selection algorithms on different nodes § Works even if topology information is inconsistent § List of nodes to pass on the way to the destination § A stack of paths Why not hop-by-hop Crankback § Rolling back a call partway to try a different route ©2003–2004 David Byers § Sensitive to inconsistencies in topology databases § Sensitive to inconsistencies in routing algorithms Call Admission Control (CAC) § Procedure for deciding whether to admit a requested call PNNI, unlike IP, uses source routing. Although it would have been possible to use hop-byhop routing, the ATM forum has identified problems with hop-by-hop routing that make it unsuitable to ATM. Hop-by-hop routing may result in loops since routers do not have complete information about the entire path taken by a connection. Loop prevention is a huge part of routing protocols for hop-by-hop routing. Loops are generally caused by one of two things: inconsistency in routing decisions caused by the use of different routing algorithms; or inconsistency in routing databases (mainly due to changes in topology information that have not propagated fully). This implies that hop-by-hop routing requires the path selection mechanism to be fully specified and implemented identically on all nodes. Evolution in the path selection mechanism is not possible. Furthermore, due to inconsistencies it is possible to construct far-from-optimal paths that are loop free. In a non-connection oriented network this is not a major problem since the situation will resolve itself. In a connection-oriented network, however, the cost of bad routing decisions will be paid through the lifetime of the connection. Source routing requires nodes to have complete topology information. PNNI accomplishes this by using a hierarchical model which relieves nodes of knowing the details of the entire network. Inconsistencies in topology databases are rarely fatal since loops will never be formed. Similarly, since only one node is involved in the computation of the route, different nodes can use different path selection algorithms. PNNI uses source routing with crankback. Nodes create something called a DTL, which is essentially a stack of paths describing how a connection could be routed. Crankback is the process of undoing a connection part of the way and trying a new path if it is discovered that the selected path will not admit the connection. The algorithms for path selection (construction of the DTL) and call admission are not specified in the PNNI specification as they do not have to be standardized. 95 PNNI Routing Example B A C A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 In this example, the green box on the left wants to set up a SVC to the green box on the right. The PNNI hierarchy is illustrated in the slide. Here, A.1.2 has to decide a route to the destination. Recall that A.1.2 has complete information about its own peer group and its ancestors. This implies that as far as A.1.2 is concerned, the destination is B, the top-level group node containing the destination. Reachability information will have been summarized to indicate that the destination can be reached through B. There are a number of different options for A.1.2. One would be A.1.2 to A.1.1 to A.2 to B. Another is A.1.2 to A.3 to B. A third is A.1.2 to A.1.1 to A.2 to A.3 to B. Which is most appropriate depends on the current conditions in the network. The shortest path is not always the best path. Looking at the last of these four paths, note that the actual path through the network will be far more complex. Again, there are several options. The exact path will be determined by other nodes along the path – for example, A.1.2 does not specify routing through peer group B – nodes in B will have to amend the route to contain these details. Let’s walk through an example of how path selection works. It all starts with a SETUP message being sent over the UNI. A.1.2 will then construct a DTL and issue a SETUP message of its own to the next node in the DTL. This will then progress until the SETUP message reaches the destination. 96 SETUP Rules (Simplified) Advance current elem X = Current DTL element Create DTL to X X = Me? Is X a neighbor? Top DTL Empty? CAC Pop top-level DTL Create DTL to destination Allocate SVC Send SETUP CAC OK? RELEASE DTL Stack Empty? ©2003–2004 David Byers START Once the source route has been set up, the calling NNI issues a SETUP call containing a DTL stack. The DTL stack contains one DTL per level in the PNNI hierarchy. For the path A.1.2 A.1.1 A.2 A.3 B, three DTLs would be required. One containing A.1.1 A.1.2, one with A.1 A.2 A.3 and one with A B. Note that the starting node is part of the DTL. Each DTL also has a pointer. In the top-level DTL it indicates the next node in the list. In the other levels it indicates the current element of the DTL. When a node receives a SETUP containing a DTL and is not the destination, it checks the top-level DTL. If its address is at the top, it moves to the next element, if there is one, performs CAC to allocate a channel to the node represented by the new current element and forwards the SETUP call to the node indicated by the new current element. If the top-level DTL is exhausted, the node pops it from the stack and essentially starts over. At this point, the current element may not be the node itself, but is likely to be a node in a higher level of the PNNI hierarchy. The node searches for a way to reach the new current node. If there is a direct connection, it can proceed as before. If there is no direct connection it has to construct a new DTL and place on the top of the stack, indicating the path to the new current node. If the entire DTL stack is exhausted, the current node will have to construct a DTL (possibly a stack) to the destination. If the node adds a DTL to the stack it is part of the routing process and may have to participate in crankback. If this is the case, it saves sufficient information to compute an alternate DTL, should crankback take place. If the node cannot allocate the required resources for the next step, it will respond with a RELEASE message, indicating that crankback is taking place. This message is propagated backwards along the path that has been set up until it reaches a node that has taken part in creating the path. At this point, that node may attempt to create an alternate path for the DTLs that it added. If it cannot construct an alternate path, it forwards the RELEASE message back along the path. 97 Now for a real example. The green box on the left wants a SVC to the green box on the right. The link A.3.1 to B.2.3 cannot support the PCR that is requested. The link from A.3.3 to B.1.2 is down, but A.1.2 doesn’t know that. A.1.2 selects the following path: A.1.2 A.1.1 A.2 A.3 B resulting in a three-level stack of DTLs. Each DTL is marked with a level indicating the level in the PNNI hierarchy that the DTL corresponds to. The top of the stack is the DTL for the path within A.1. It consists of A.1.2 A.1.1 and is at level 96. The next element is the path through peer group A, and consists of A.1 A.2 A.3, and it at level 72. The final element is the path within the top-level peer group, A B, and is at level 64. A.1.2 sends the SETUP message to A.1.1. This node will pop the top DTL since the target of that DTL has been reached and send the SETUP message to A.2, which is the current destination in the next DTL. In this case, A.1.1 knows that its neighbor A.2.2 is in A.2, so it forwards the message to A.2.2 without altering the DTLs. A.2.2 sees that the current destination is A.2. Since it is in A.2, it looks at the next element, A.3. To reach A.3 it adds the DTL A.2.2 A.2.3 with level 96 to the top of the stack and forwards the SETUP to A.2.3. Since A.2.2 added a DTL, it may be involved in alternate routing later, so it saves information for this eventuality. A.2.3 determines that the top DTL is exhausted, pops it and examines the new current destination, A.3. A.2.3 has a neighbor, A.3.4, that is in A.3, so it forwards the SETUP there. A.3.4 notes that the target of the top DTL is reached, pops it from the stack and examines the new current destination, which is B. A.3.4 builds a route to B and places the DTL A.3.4 A.3.2 A.3.3 with level 96 on the top of the stack. Since it added a DTL to the stack, it saves information so it can participate in alternate routing later. A.3.2 receives the SETUP and forwards it to A.3.3. A.3.3 removes the top DTLs, noting that the new current destination is B. At this point setup blocks since A.3.3 cannot create the connection to B.1.2, and must initiate crankback. It constructs a RELEASE message indicating the link that could not be used and the reason for failure, and sends the message back to A.3.2. The release message has crankback level 96 since that is the level of the current DTL. Since A.3.2 did not add any DTLs it simply tears down SVCs that have been allocated for the call and forwards the message to A.3.4. A.3.4 did create DTLs and so attempts alternate routing. After removing the failed link from consideration, it determines that there are to paths across A3 to B. One is A.3.2 A.3.3 A.3.1 and the other is directly to A.3.1. However, the link from A.3.1 to B cannot support the PCR requested, so A.3.4 refrains from attempting to allocate this path, and sends the RELEASE message back to A.2.2. The crankback level is set to 72, since that corresponds to the level of the higher-level DTL, generated by A.1.2. A.2.2 did create an DTL, but will not attempt alternate routing since the crankback level indicated by the release message is higher than the level of the DTL it created. Eventually the RELEASE message is received at A.1.2, which constructs an alternate route to the destination, this time selecting A.1.2 A.1.1 A.2 B. The troublesome links in A.3 are eliminated from consideration. The new DTL stack is A.1.2 A.1.1, A.1 A.2 and A B. The new SETUP is forwarded to A.1.1, which removes the top DTL and forwards the SETUP to A.2.2. A.2.2 pushes a new DTL A.2.2 A.2.1 onto the stack and forwards to A.2.1. A.2.1 removes the top DTL and forwards to B.1.1. B.1.1 notes that the destination of the current DTL has been reached. The current DTL in this case is the DTL A B. Now B.1.1 needs to construct a new source route to reach the destination. It computes the path B.1.1 B.1.3 B.2 B.3, pushing two DTLs onto the stack: B.1.1 B.1.3 and B.1 B.2 B.3. It forwards the call to B.1.3, which pops the top DTL and forwards to B.2.2. B.2.2 finds a path to B.3 and pushes B.2.2 B.2.3 onto the DTL stack. The call is forwarded to B.2.3, which pops the top level and forwards to B.3.4. B.3.4 in turn computes a path to B.3.3: B.3.4 B.3.1 B.3.4. The call is forwarded to B.3.4, which notes that the destination has been reached. The overall path is thus A.1.2 A.1.1 A.2.2 A.2.1 B.1.1 B.1.3 B.2.2 B.2.3 B.3.4 B.3.1 B.3.3. 98 PNNI Routing Example B A C A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 99 PNNI Routing Example DTL Stack A.1.2 A.1.1 B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 100 PNNI Routing Example DTL Stack A.1.2 A.1.1 B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 101 PNNI Routing Example DTL Stack A.2.2 A.2.3 B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 102 PNNI Routing Example DTL Stack A.2.2 A.2.3 B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 103 PNNI Routing Example DTL Stack A.3.4 A.3.2 A.3.3 B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 104 PNNI Routing Example DTL Stack A.3.4 A.3.2 A.3.3 B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 105 PNNI Routing Example DTL Stack A.3.4 A.3.2 A.3.3 B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 106 PNNI Routing Example DTL Stack No alternate! B A A.1 A.2 A.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 107 PNNI Routing Example Wrong crankback level! B A DTL Stack C A.1 A.2 A.3 AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 108 PNNI Routing Example DTL Stack A.1.2 A.1.1 B A A.1 A.2 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 109 PNNI Routing Example DTL Stack A.1.2 A.1.1 B A A.1 A.2 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 110 PNNI Routing Example DTL Stack A.2.2 A.2.1 B A A.1 A.2 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 111 PNNI Routing Example DTL Stack A.2.2 A.2.1 B A A.1 A.2 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 112 PNNI Routing Example DTL Stack B.1.1 B.1.3 B A B.1 B.2 B.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 113 PNNI Routing Example DTL Stack B.1.1 B.1.3 B A B.1 B.2 B.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 114 PNNI Routing Example DTL Stack B.2.2 B.2.3 B A B.1 B.2 B.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 115 PNNI Routing Example DTL Stack B.2.2 B.2.3 B A B.1 B.2 B.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 116 PNNI Routing Example DTL Stack B.3.4 B.3.1 B.3.3 B A B.1 B.2 B.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 117 PNNI Routing Example DTL Stack B.3.4 B.3.1 B.3.3 B A B.1 B.2 B.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 118 PNNI Routing Example DTL Stack B.3.4 B.3.1 B.3.3 B A B.1 B.2 B.3 C AB A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 119 PNNI Routing Example B A C A.2 B.1 A.1 B.2 B.3 A.3 C.1 C.2 B.3.2 A.2.1 B.1.1 A.2.2 B.1.2 B.2.1 B.2.2 B.3.4 B.3.1 B.3.3 A.3.2 A.1.2 B.1.3 A.2.3 B.2.3 B.3.5 A.3.3 A.3.4 A.3.1 ©2003–2004 David Byers A.1.1 120 ©2003–2004 David Byers THE BEGINNING IS THE END THE END IS THE BEGINNING 121