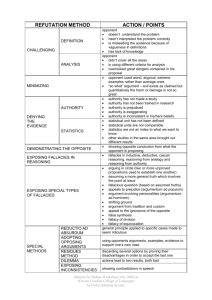
Multi Level Reasoning In A Cheat Agent Deception
advertisement

Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover
Deception
Rina Blomberg
rinbl907@student.liu.se
729G11: Artificial Intelligence II
Linköping University
September 19, 2011.
One goal in Artificial Intelligence is to design cognitive systems that can perform multi level
reasoning typical of humans. The aim of this paper is to theoretically demonstrate how human
multi-level reasoning within a competitive environment can be modelled in an intelligent agent.
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
“...it is the means by which rational beings understand
themselves to think about cause and effect, truth and falsehood,
and what is good or bad.”
Reason - From Wikipedia 09-09-2011
Introduction
Human intelligence can be observed through their rational reasoning in the face of the
unknown: hypotheses are made, tested and evaluated and new beliefs replace old.
When presented with problems that require uninformed/sub-informed decisions,
humans typically perform strategic actions in order to gain more information about the
problem. With problems that involve two or more persons, humans engage in multilevel reasoning: reasoning about other‟s beliefs and predicting their plans of action.
One goal in Artificial Intelligence is to design cognitive systems that can perform this
kind of human-level reasoning and the aim of this paper is to theoretically demonstrate
how human multi-level reasoning in a competitive environment can be modelled in an
intelligent agent.
Background
Games have been a key element for studies in Artificial Intelligence (AI). They provide
researchers with a structured environment for which human cognition can be observed,
monitored and tested. One of the most popular games since the late 20th Century that
involves making rational, sub-informed decisions with multi-level reasoning is poker.
Poker is described as a game of simple rules but with complex strategies, and one
challenge within AI is to create a poker agent capable of playing on par with a human
expert.
Despite increasing progress in pokerbot design, the reason why agents are still unable to
compete at an expert level is not due to the complexity of the game space but due to the
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
fact that poker is a nontransitive zero-sum game.
To tackle this challenge, AI
researchers have taken a Bayesian Network-driven approach, (Korb, Nicholson, &
Jitnah, 1999), (Mihok & Terry, 2005), (Tretyakov & Kamm, 2009).
Bayesian Networks are used in AI to reason about uncertainty and provide agents with
the means to make inferences about complex causal relationships between variables via
a directed acyclic graph.
Bayesian inference is an iterative process.
Beliefs are
modelled as a probability distribution over uncertain data and as new evidence is
observed the belief system is updated. The initial belief is termed prior probability and
the modified belief is termed posterior probability.
Pokerbot researchers, Brian Mihok and Michael Terry (M&T) defined the different
levels of human reasoning in poker so as to create a solid framework for their model
(see Definition 1). A key element in M&T‟s system-design was the use of Bayesian
Nets for lower-level inferences about the opponent‟s hand and strategy as a basis for
higher-level strategic reasoning (Mihok & Terry, 2005).
Definition 1. Mihok and Terry define different levels of human reasoning in poker as:
Level 0: Reasoning about your hand
Level 1: Reasoning about your opponents hand
Level 2: Reasoning about what your opponent thinks about his and your
hand
Level 3: What to do about what your opponent thinks
…
Professional players are often thinking on level 4 or 5.
Influenced by M&T‟s framework, this project will explain the design of a theoretical
model for a Cheat1 agent capable of competing on par with an experienced human
player. The card game Cheat is not as complex as poker, betting and suiting (clubs,
diamonds, hearts, spades), for example, are not elements of the game. Deception
though, plays a major role in game strategy and so like poker, multi-level reasoning is
required for optimal play. For simplicity, the game space in this model will be confined
1
Also known as „Bullshit‟ and „I doubt it‟.
3
to the two player game version, but with a few modifications the model may be usable
for versions with 3+ players.
2 Player Cheat
Set Up
A standard pack of shuffled 52 playing cards is used. The chosen dealer deals 8 cards
face down to both players (the player‟s hand) and one card face up in the middle of the
board (the tabled card). The remaining cards (the pack) are piled face down beside the
table card (see Figure 1). A player may look at the cards in his own hand. The player
who did not deal is the first to move.
Figure 1. Initial board setup.
Object
The object of the game is to be the first player to get rid of all the cards in his hand.
Game Play
Turns: The player whose turn it is, (Player) can choose to discard one to four cards
face down onto the tabled pile and call out their rank or pick up one card from the pack
and add it to his hand.
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
Picking Up: If Player chooses to pick up a card from the pack then Player‟s turn is
over.
Discarding: Should Player choose to table a number of cards, the chosen rank must
either be one rank higher or one rank lower than the previously tabled card(s) (see
Definition 2).
Player must be truthful about the quantity of cards he discards but is
allowed to bluff about the actual cards he tables. For example, Player may claim to
table three 7s but in actual fact placed face down two Js and one 9. Opponent must
decide whether or not Player made an honest claim.
Accepting A Play: If Opponent accepts Player‟s claim as honest, then Player‟s turn is
over and Opponent‟s turn consists of choosing between picking up a card from the pack
or discarding a number of cards with either one rank higher or lower than the (claimed)
rank of the tabled card(s).
Calling A Bluff:
If Opponent thinks Player was dishonest, he calls out „Cheat!‟
Player‟s tabled cards are exposed and one of two things happens:
1. If all of the exposed cards are shown to be of the rank that Player claimed, then
Opponent must pick up and add to his hand the entire tabled pile. Player starts
the next round.
2. If any of the exposed cards are different from the claimed rank, then Player must
pick up and add to his hand the entire tabled pile. Opponent starts the next
round.
Next Round: Then next round starts with the player whose turn it is which is dependent
upon the outcome of the called bluff. The player tables face up any card he chooses
from his hand and it then becomes Opponents turn to move and play continues as usual.
Ending the Game: The player who has just one card left in his hand and is able to
discard that card without cheating, wins the game. Alternatively, a player who collects
30+ cards in his hand, automatically loses.
5
Definition 2. Ranking of cards from lowest to highest.
When a King is tabled the choice of ranks are Queen or Ace.
When an Ace is tabled the choice of ranks are King or Two.
Cheat Strategy
The key to winning is being the player with the least number of cards in hand and
having increasing opportunities to set the tabled rank to one‟s own preference. This is
done by successfully calling the opponent‟s bluff and fooling the opponent into calling
cheat for an honest play.
Holding all four cards of a rank in hand is the easiest way to gain the lead because the
opponent is either forced to pick up or cheat if made to play this rank.
Card memory is a necessity. Remembering which cards one has discarded that have
ended up in the opponent‟s hand, assists in reasoning whether or not to play honestly
and whether or not to call the opponent a cheat.
Cheat becomes a game of pattern recognition. The player who wins exploits patterns in
his opponent's play before the opponent can adjust. Thus, an inexperienced player will
repeatedly call cheat for honest plays.
With every turn, an experienced player will reason on various levels:
Which rank should I play? What will most likely lead to strong sequential play
and discards to my advantage? (Level 0)
What is the likelihood that my opponent holds one or more cards of this rank in
his hand? (Level 1)
What is the likelihood that my opponent will call cheat, what is the likelihood
that my opponent cheated? (Level 2)
Is my opponent aware of my bluffing strategy and what should I do about my
opponent‟s bluffing strategy? (Level 3)
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
As M&T have demonstrated in their research, these multi reasoning levels provide a
framework from which to generate a winning strategy for the agent and aid in
classifying inference tasks. For this theoretical model, Levels 0 to 2 will be formulated.
The advanced Level 3 will remain outside the scope of the project but will be included
in the discussion at the end of this report.
Achieving Level 0:
In Cheat a strong hand is one that allows for sequential play with many discards or
controls whether the opponent will be forced to pick up or cheat. Sequential play
involves playing a series of successive ranks. In most cases the entire hand does not
need to be evaluated in order to determine sequential play, it is enough to reason over
±3 ranks from the rank of the tabled. Because the outcome of each turn is uncertain, it
is necessary for the agent to calculate hand strength with each turn.
Reasoning about own hand
Let:
q = the quantity with the domain: {1, 2, 3, 4}
r = a rank with the domain: {A, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, J, Q, K}
t = the rank of the tabled card.
Represent sequential play in the hand as: H = [qt, q(t+1), q(t+2), q(t+3)]
and: L = [q(t-3), q(t-2), q(t-1), qt]
Create a heuristic algorithm to compare the strength of L to H (see Algorithm 1).
Algorithm 1 helps the agent to decide whether to play one rank higher or one rank lower
than the tabled card, even when the agent‟s hand doesn‟t actually have that rank. This is
because the algorithm puts a value on the sequence of ranks and their quantities rather
than just valuing a rank per se.
When the outcome of the opponent‟s turn falls in favour of the agent‟s direction of
preference – H(igher) vs. L(ower); the agent can reason at this level, together with
7
condition action rules, to not risk calling cheat and instead continue to discard cards in
the direction of the preferred sequence.
Algorithm 1. Algorithm to compare the strength of L to H.
Achieving Level 1
As the game evolves, a player gains increasing information over what cards the
opponent may be holding. The player gets this information in two ways:
1. Estimating the likelihood that the opponent will have qi ri in his hand based upon
the total number of unknown cards on the board.
2. By remembering which cards he has discarded that have ended up in the
opponent‟s hand and by estimating the likelihood that those cards are still in the
opponent‟s hand (Level 2).
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
Reasoning about opponent’s hand
Let:
U = the total number of unknown cards on the board (includes unknown cards in
opponent hand, tabled pile and pack).
N = the number of ri contained in the set of U.
C = the total number unknown cards in opponent‟s hand.
Create an algorithm for calculating P(qj ri) (see Algorithm 2).
Algorithm 2. Calculating the probability that a certain quantity of a certain rank is
contained in the hand of the opponent.
Algorithm 2 gives the agent necessary insight into the opponent‟s hand, which together
with condition action rules, at this level of reasoning, can be used to decide whether or
not to call the opponent a cheat. This level of reasoning however, is not a optimal
strategy because an experienced human player will take into account a number of other
stochastic variables that influence whether or not an opponent has decided to cheat.
Achieving Level 2
Reasoning about what opponent thinks about his and your hand
Estimating whether or not a known card is still in the opponent‟s hand after several
turns (within a single round), involves taking into consideration the likelihood that the
opponent has cheated with each turn. Calculating this likelihood requires Level 2
9
reasoning and the agent achieves this through Bayesian inference. This project now
turns to the design of the Bayesian Net, and does so node by node with reference to the
agent‟s reasoning needs.
Engineering the Bayesian Net
A Bayesian Net is a directed acyclic graph in which each node in the graph corresponds
to a random variable, which may be discrete or continuous. A probability function
associated with each node takes as input a particular set of values and returns the
probability for a particular value of the variable represented by the node. The edges are
directed links between pairs of nodes and represent conditional dependencies. Each
node Xi has a conditional probability distribution P(Xi | Parents(Xi)) that quantifies the
effect of the parents on the node (Russell & Norvig, 2010). Nodes which are not
connected represent conditionally independent variables.
Algorithm 2 is used to calculate the probability that a certain quantity, qj of a certain
rank, ri exists in the Opponent’s hand - P(O). So the first node, X1 in the Bayesian Net
will contain thirteen different probability tables for P(O) one for each card rank.
Algorithm 2 can also be used for calculating the conditional probability distribution:
P(A | O), which represents the opponent‟s belief about the quantity ri in the Agent’s
hand given the quantity ri contained in his own hand. A conditional probability table
for P(A | O) forms the second node, X2 = A in the Bayesian Net (see Figure 2).
Figure 2. Connected nodes: X1 and X2, with probability tables.
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
So far, the agent is able to form knowledge about the cards in the opponent‟s hand and
what the opponent believes about the agent‟s hand based only upon the information
contained in his own hand.
But this information is not enough to reason about
deception, thus the Bayesian Net will need additional nodes.
Experienced players regularly weigh how certain they are that the opponent is bluffing
against the cost of picking up the tabled pile should they be wrong. This is a crucial
decision making process and must therefore be represented in the Bayesian Net.
Let:
H be a random variable with a Bernouilli distribution (see Formula 1).
H = 1 means that picking up the pack will Hurt.
H = 0 means that picking up the pack will not Hurt.
X3 = H
Forumla 1. The probability formula for the random variable H where p = P(H =1) and
h ∈ {0,1}.
P(H = h) = ph(1-p)1-h
Create an algorithm for determining the value of H for player B (see Algorithm 3)
where:
A = number of cards in A‟s hand
B = number of cards B‟s hand
T = number of cards in tabled pile
True = 1
False = 0
Algorithm 3 allows for the agent to take into account the likelihood that picking up the
tabled pile will hurt either its chances of winning or the opponent‟s chances of winning.
This is determined by calculating the ratio for A:(B+T). If
> 2.3 for A < B+T, then
picking up the tabled piled is considered detrimental to B‟s hand because for every one
card A discards, B must discard more than 2.3 cards in order to win. Such a scenario
will increase B‟s need to cheat with large quantities of cards at a time and thus increase
the risk of being caught again.
11
Algorithm 3. Algorithm for determining the value of H for player B.
The choice of how many cards to table can greatly affect the outcome of being called a
cheat, so the fourth node, X4 in the network will represent the Choice of tabling 1-4
cards. Let C be a random variable with a categorical distribution for the domain {1, 2,
3, 4}.
The probability law of C is given in Formula 2 where pi represents the
probability of seeing element i and
.
Formula 2. The probability formula of C where pi represents the probability of seeing
element i and
.
P(C = ci) = pi
The final node, X5 in the Bayesian Net represents the probability that the player in
question has Bluffed. The random variable B in X5 has the domain: {True, False}.
The initial data contained within the conditional probability table P(B | A, C, H) will
only be an estimate. It is intended, that as the Bayesian net is learned through new data
observations, each parameter in the conditional probability table will come to represent
the actual probability for the sample‟s value (this is discussed more in the next section:
Learning the Bayesian Net).
The final topography of the Bayesian Net can be seen in Figure 3 which shows the
conditional dependencies for X5.
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
Figure 3. Bayesian inference net for Cheat agent.
Bayesian Net for Level 2 reasoning
The semantics of this Bayesian Net allow the agent to use the same data and inference
methods for two different reasoning perspectives:
1. The first perspective is reasoning about the opponent‟s cards and actions – the
agent reasoning when it is the opponent‟s turn.
2. The second perspective is reasoning about the opponent‟s beliefs about the
agent‟s cards and actions – the agent reasoning when it is its own turn.
By learning the Bayesian Net after each player‟s turn, the posterior probability of
perspective one forms the hypothesis (prior probability) for perspective two. This
makes the Bayesian Net a powerful tool for Level 2 reasoning and is not so different
from the reasoning methods that humans employ at this level. The next section of this
project will explain how the Bayesian Net is learned.
13
Learning The Bayesian Net
In order for this multi level reasoning model to be effective, it must learn from its
observations. This process involves maintaining an observation table for each variable
to be updated in the network, and then updating the variable‟s conditional probability
table under the assertion that the actual probabilities for the parameters are
proportionally equal to the observed data for that variable.
The chosen learning
approach is therefore Maximum-likelihood Parameter Learning (Russell & Norvig,
2010).
In a report from 2002, titled “Sensitivity Analysis for Selective Parameter Update in
Bayesian Network Learning” by Wang, Rish & Ma; a formula for the maximum
likelihood of a specific parameter θ was discussed (Wang, Rish, & Ma, 2002). Because
learning the network involves the process of actively updating specific parameters, this
formula will be applied to the model (see Formula 1).
Formula 1. Maxiumum likelihood parameter learning formula (Wang, Rish, & Ma,
2002). θ is a parameter from row x, column y in a conditional probability table τ. N
is the number of observations made for a particular instance of a variable, with k
possible values, in an observation table τ´.
Each variable in the Bayesian Net that requires active evidence updating will have a
corresponding observation table (see Figure 4), which is a total of 15 tables.
Figure 4. Observation tables for the variables B´, A´ and O´i.
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
An observation value entered into a table representing the quantity of a rank in the
opponent's hand does, not have to be exactly 1 if the agent is uncertain. Instead the
agent can use Algorithm 2 and add the value for each P(
in the table.
) to the corresponding value
The total observations for the table will still however be a whole
number because
.
The reason why observations for the agent‟s hand are represented in only one table,
rather than 13 different tables for each rank is because it is assumed that the actual rank
of the cards have no varying effect on the behaviour of the opponent. It is only the
quantity of cards in relation to the opponent‟s cards that need to be statistically
observed.
Inference And Action
At node X5 the agent is able to use the same inference method to determine two
different questions:
1. Given that my opponent has tabled qj ri what is the probability that he is
bluffing?
2. If I table qj ri what is the probability that the opponent will call cheat?
Using inference by enumeration together with relevant variable selection, the agent is
able to calculate (see Formula 3), the probability of B = True given the value for H as
determined by Algorithm 3 and the value of C as either an observed value (question 1)
or a hypothesis (question 2).
Formula 2. Bayesian inference formula for P(B | H, C)
This method of inference can be used to calculate all Level 2 queries such as whether or
not a known quantity of card rank is still in the opponent‟s hand after several turns
(within a single round): P(o | b) in which o = qj ri and b = True.
15
The information derived from Bayesian inference combined with the information
regarding hand strength in Algorithm 1 provides the agent with a solid foundation for
the condition action rules. Algorithm 4 is a simple example of how the condition action
rules could be formulated.
Algorithm 4. A simple example of condition action rules for a Cheat agent.
Discussion
The inference method used in this project was one of exact inference. The complexity
of exact inference is dependent upon the structure of the network. This network‟s
structure is known as a polytree in which there is at most one undirected path between
any two nodes. The time and space complexity of exact inference in polytrees is linear
in the size of the network. (Russell & Norvig, 2010) The size of this network can be
defined as the total number parameters from all of the conditional probability tables. If
adapting this network to a 3+ player game involves a structural change such that the
network becomes multiply connected rather than singly connected (polytree), other
inference methods will be needed in order to avoid exponential time and space
complexity.
This project has shown that human multi-level reasoning as high as Level 2
theoretically can be modelled in an agent using Bayesian inference.
As previous
pokerbot researchers have shown, a purely Bayesian driven model will not succeed in
solving higher level reasoning problems, such as reasoning about an opponent‟s strategy
and adapting to that strategy.
This is because Bayesian Nets are meant for the
Multi Level Reasoning In A Cheat Agent
Using Bayesian Inference to Cover and Uncover Deception
Rina Blomberg
construction of adaptive algorithms and so model engineers must turn to hybrid
Bayesian networks such as a Dynamic Bayesian Net (Tretyakov & Kamm, 2009).
Mihok‟s and Terry‟s pokerbot research, theoretically incorporated Bayesian nets into a
Hidden Markov Model (HMM) for the purpose of creating a multivariable inference
system (Mihok & Terry, 2005).
A HMM can be considered as a simple Dynamic
Bayesian Net (Wikipedia, 2011) and consists of a finite set of states, each of which is
associated with a probability distribution.
M&T argue that humans attempt high levels of reasoning through hypothesis testing
and an important goal in their research was to demonstrate how a HMM is an applicable
model for this human process. Their approach starts by estimating the range of hands
an opponent in poker may have and as more information becomes available, the
distribution of initial states is updated.
The HMM keeps track of the transitions
between various hand states and the embedded Bayesian Nets in the HMM are used to
make inferences about observations regarding the opponent‟s hand and strategy.
Future work for this project will continue using M&T‟s research and influence and
attempt to design a Cheat agent capable of reasoning on Level 3 by introducing a
Dynamic Bayesian Net to the model.
17
References
Korb, K. B., Nicholson, A. E., & Jitnah, N. (1999). Bayesian Poker. Proceedings of the
15th International Conference on Uncertainty in Artificial Intelligence (pp. 343-350).
Stockholm: UAI.
Mihok, B. E., & Terry, M. A. (2005). A Bayesian Net Inference Tool for Hidden State in
Texas Hold'em Poker. Cambridge: Massachusetts Institute of Technology .
Mihok, B., & Terry, M. (2005). Statistical Learning and Inference Methods for
Reasoning in Games. Cognitive Robotics 2005 Advance Lectures. Cambridge: MIT
Open Courseware.
Nicholson, A. E., Korb, K. B., & Boulton, D. Using Bayesian Decision Networks to
Play Texas Hold'Em Poker. Australia: Faculty of Information Technology, Monash
University.
Russell, S., & Norvig, P. (2010). Artificial Intelligence, A Modern Approach -Third
Edition. New Jersey: Pearson.
Tretyakov, K., & Kamm, L. (2009). Modeling Texas Hold'em Poker Strategies with
Bayesian Networks. Tartu: University of Tartu.
Wang, H., Rish, I., & Ma, S. (2002). Using Sensitivity Analysis for Selective Parameter
Update in Bayesian Network Learning. Menlo Park, CA: AAAI Press.
Wikipedia. (2011). Wikipedia. Retrieved 9 19, 2011, from Dynamic Bayesian Network:
http://en.wikipedia.org/wiki/Dynamic_Bayesian_network