Descriptive statistics and frequency tables, although of great value to... only allow us to consider one variable at a time.... Cross Tabulation: Part 1 Slide 1
advertisement

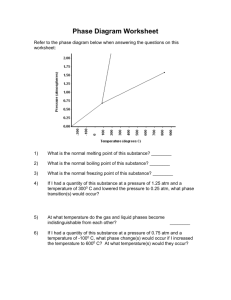
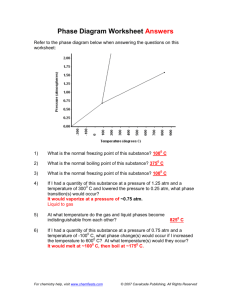
Cross Tabulation: Part 1 Slide 1 Descriptive statistics and frequency tables, although of great value to marketing researchers, only allow us to consider one variable at a time. Often the real story emerges when we consider more than one variable at a time. Hence the theme of this lecture, which is on cross tabulations and banners, which allow us to consider two or more variables at a time. Slide 2 Here’s an example of a crosstabulation (or crosstab) table generated by SPSS. We can see that there’s an effort to relate the country of origin of households or a driver’s car against the education level of that driver. Education is in five different categories, but we can’t tell from the coding what ranges correspond with each category. With the car country of origin, the researcher has provided value labels to the SPSS software, so we know that Category 1 is American, Category 2 is European, and Category 3 is Japanese. Slide 3 What is cross tabulation? It’s a way to organize data by groups or categories, thus facilitating comparisons. It provides joint frequency distributions for observations on two or more sets of variables. For example, if we want to understand the relationship between sex and car ownership, sex would be ‘male’ or ‘female’ and car ownership would be ‘yes’ or ‘no’. There will be a percent of people who are male, a percent who are female, a percent who are car owners, and a percent who are not car owners. By running cross tabulation analyses, we can look at males who are and aren’t car owners, as well as females who are and aren’t car owners. This allows us to look simultaneously at responses to at least two, sometimes more than two, variables. A contingency table is produced by running a crosstab analysis for two variables, such as two questionnaire items. Univariate analyses look at a single variable and generating things like mean, mode, median, measures of dispersion, counts, and frequencies. Relative to that type of analyses, bivariate analyses can provide greater insights because it allows us to consider more than one variable simultaneously. Slide 4 This lecture on cross tabulation and banners contains several examples that clearly show why considering more than one variable at a time provides additional insights into underlying marketing phenomenon. The first example shows a fictitious car ownership study. Looking at the frequency data, relative to household income, we see that about half the participants earned less than $17,500 and the other half earned more. Slide 5 The cumulative frequency curve makes the same point about income as the last slide. We can see that $17,500 is the midpoint of a ranking of incomes for this group. Page | 1 Slide 6 Here are three crosstab tables with different information in each table. SPSS output combines these tables into one table, or at least gives you the option to do so. We’ll consider them individually. The first table (at the top), which relates household income to number of cars owned, shows that 54 of 100 households have incomes less than $17,500 and 46 of 100 households have incomes more than $17,500. Of those 54 households in the lower income category, 48 owned ‘one or no car’ and 6 owned ‘two or more’ cars. The 46 higher-income households shows a 60/40 split, with 27 of the 46 owning ‘one or no car’ and 19 owning ‘two or more’ cars. We can sum across rows, look at the marginal figures, and consider just the 54 cases. We can also sum down columns and look at the 75 households with ‘one or no’ car; of those households, roughly 64% had incomes less than $17,500 and 36% had incomes more than $17.500. Now looking at households with ‘two or more’ cars, we see a reversal, with a roughly 3-to-1 (6 to 19) split the other way. Only 24% of households with ‘two or more’ cars earn less than $17,500, but 76% of ‘two or more’ car households earned more than $17,500. The point: you can look at these crosstab tables in toto, or you can look across the rows or down the columns. The way you extract information from a crosstab table depends on your needs. Slide 7 This slide shows two tables in which number of cars is unrelated to income but is related to family size. We can see that households are divided into ‘four or fewer’ members or ‘five or more’ members. In this sample of 100 households, 78 of them have ‘four or fewer’ members and 22 of them have ‘five or more’ members. A quick eyeballing of the table suggests there’s a relationship between car ownership and family size. The bottom half of the table shows that for families with ‘four or fewer’ members, 90% own ‘one or no’ car and only 10% own ‘two or more’ cars. In contrast, for households with ‘five or more’ members, 23% own ‘one or no’ car and 77% own ‘two or more’ cars. Thus, there seems to be relationships between (1) household income and number of cars owned, and (2) family size and number of cars owned. If we owned a car dealership interested in direct marketing, then these results would suggest that we target our direct marketing efforts at larger households with higher incomes. Slide 8 The last table associated with the first example tells a more complete story. Now we’re looking at three variables simultaneously; income, family size, and car ownership. This view will give us a fuller perspective. Seemingly, income is related to car ownership and size of family is related to car ownership; looking at the three variables simultaneously suggests a different interpretation. Divide the sample into the 78 smaller households and the 22 larger households. It seems that none of the smaller households with incomes less than $17,500 own ‘two or more’ cars but only 19% of these smaller households own ‘two or more’ cars. Of the 22 larger households (with five or more members), only 50% (4 of 8) of the households earning less than $17,500 own ‘two or more’ cars but 93% (13 of 14) of households earning more than $17,500 own two or more cars. Thus, it seems that family size is the primary determinant of whether or not a household owns ‘two or more’ cars because larger households need multiple cars. However, income is a constraint, so households earning less than $17,500 may scramble to purchase that second car but often can’t afford it. Page | 2 Slide 9 Example #2 summarizes the data for a survey about ATM usage in the past six months. Let’s look at the frequency distribution for two of the variables in this study. The question is, have you used an ATM in the last 6 months, yes or no? Out of 100 respondents, 61 said ‘yes’ and 39 said ‘no’. The respondents’ answers about their age ran as follows: 22 were between the ages of 1834, 33 between 35-54, and 45 were at least 55 years old. Slide 10 The research question relating to these two survey questions is ‘Is there a relationship between age and ATM usage?’ Some people might believe this to be true, as older people are less adept at and inclined to use technology. Thus, there’s good reason to believe there’s a correlation between age and ATM usage. Knowing this relationship exists might encourage banks to instruct their older clients about ATM usage, as ATMs cost banks less than tellers. The crosstab table for verifying this relationship includes a key in the upper left hand corner that identifies the four numbers in each cell: (1) the count of people who answered both questions a certain way, (2) the row percent, which is the percent of people who answered the ATM question a certain way in each age category, (3) the column percent, which is the percent of people who answered the age question a certain way for each ATM usage category, and (4) the total percent of people who answered both questions a certain way. How many people are between the ages of 18-34 and had not used an ATM in the last six months? The answer is ‘2’; 2 of 22 for that column is 9.1%, and 2 of 100 (for the total sample) is 2%. From the pattern of row and column percents, we see there’s a pattern. If we look at respondents who hadn’t used ATMs and then look at the percentages, we see less ATM usage as respondent age increases. In other words, respondents in the 18-34 category are almost all ATM users; in contrast, more than half of respondents age 55 or older have not used an ATM. Slide 11 Here’s a banner, which is a batch of crosstab tables smashed together. Although banners make more efficient use of paper and easier to read, I don’t recommend them for two reasons. 1. Most banner software doesn’t include statistical tests. As a result, percentages and totals may seem to reflect meaningful differences that in fact do not exist. With statistical tests, you’ll know whether or not there’s a statistical relationship between the variables in question; if so, then you can eyeball the table to discern the nature of that relationship. 2. Banners include totals, counts for individual responses, and column percentages, but do not include row percentages and the total percentages, which provide useful information about the nature of a relationship between variables. Slide 12 This slide shows a table on which we might like to run a chi-square (χ2) test. In this example, we have responses from men and women regarding whether they never, sometimes, or always use something. The questions that you can answer using a chi-square test is ‘Is the difference between the distributions statistically significant?’ Page | 3 Is the nature of any difference in the distributions of managerial value? Although a χ2 test can determine if there’s a statistically meaningful relationship between the two variables in question, a statistically significant finding may not be a managerially relevant finding. Hence, once you find a statistically significant difference, you must ask ‘Does that difference make a difference?’ As one of my marketing professors used to say, “a difference that makes no difference is no difference.” Slide 13 Typically a χ2 test is used on nominal data when we’re trying to determine differences between two independent groups. You may want to use a chi-square test for ordinal data. That’s OK, but you’ll lose a bit of information because the χ2 test is designed for nominal data, and you lose information when you treat ordinal data as nominal data. Slide 14 The crosstab table in this slide illustrates how one could use a χ2 test. In this case, the tire manufacturer wants the answer to the following question: ‘Do men differ from women in their awareness of the brand?’ Of 100 respondents, 65 were men and 35 were women. Of the men, 50 were and 15 weren’t aware; for the women, only 10 were and 25 weren’t aware. There’s more than a 3-to-1 ratio of aware to unaware men, but a 2-to-5 ratio of aware to unaware women. We can’t know if this ratio differs significantly until we run a χ2 test. Slide 15 This slide shows the formula for the χ2 test. It’s important that you understand the logic of this test. The χ2 test makes a cell-by-cell comparison between what we observed versus what we would expect to observe if there was no relationship between the two variables. What number would we expect to find in either the aware men or aware women cells if there’s no relationship between sex and tire brand awareness? A χ2 test assesses cell by cell the difference between what the table we observe (in this case, numbers based on survey results) and the table we’d expect if there’s no relationship between the two variables. There are two reasons—similar to reasons I mentioned in the univariate statistics lecture—why the ‘observed minus expected’ difference is squared: 1. The absolute mean differences sum to zero (0) if they’re not squared; hence, squaring eliminates the ‘they sum to 0’ problem. 2. From a practical perspective, we’d like bigger differences to count more and smaller differences to count less; squaring differences is one way to weight them. The square of a small number is a smaller number, but the square of large number is a huge number. Therefore, we square the differences to eliminate the zero (0) sum problem and to ensure that larger differences count more. Finally, notice a denominator, which is the expected frequency. Think about taking differences for a small sample. Even if those differences are meaningful percentage-wise, the absolute differences are relatively small, which yields a small squared number. In contrast, differences for large samples will be much larger in an absolute sense, so the square of that large Page | 4 difference will be a huge number. To adjust for sample size, the χ2 test divides the sum of squared differences by sample size. Slide 16 This slide shows how we would calculate a table with two unrelated variables. We’d take the observed frequency in the row, multiply it by the observed frequency in the relevant column, and then divide by the sample size. That gives us the expected value if there’s no relationship. Think about flipping a coin. The odds it comes up heads is ½. If you flip it twice, the odds it comes up heads both times is ¼, which you calculated by multiplying ½ by ½. The first flip is independent of the second flip and unrelated means independent. If two variables are unrelated, then the probability of giving a certain answer to one question and the probability of giving a certain answer to a different question are unrelated to one another. If probabilities are unrelated, then we multiply them to calculate a joint probability. Slide 17 Think again about summing the differences between the observed and the expected for each cell. Even if you’re controlling for overall sample size, you’ll also need to control for the number of cells. If you’re trying to relate a variable with five categories to another variable with five categories, then you’re crosstab table will contain 25 cells. Squaring 25 differences is likely to produce a large number. How do you control for the number of categories in each cell? You can calculate the degrees of freedom, which is the ‘number of rows – 1’ times the ‘number of columns – 1’. Assume we have three numbers that must sum to 100, and you pick 10 as the first number and 40 for the second number. You must choose 50 for the third number if the sum of the three numbers must be 100. In other words, the last number is not free to vary. In this example, there are ‘2’ degrees of freedom. The crosstab table in the slide shows the totals in each row and column; the first number in a row can be anything, but the last number in each row or column must allow the sum to equal the number indicated in the margin. This is true of all the rows and all the columns. Hence, the degrees of freedom equal the ‘number of rows – 1’ times the ‘number of columns – 1’. Slide 18 Here’s the calculation you’ve all been waiting for. It seems that the expected for the males who are aware is 39 and the females are 21. The expected for males who are unaware is 26 and females is 14. Computing this χ2, we would expect, if there’s no relationship between sex and awareness of tire brand, that 39 of respondents were male and aware. By subtracting the counts of respondents in each cell from the expected number of respondents we’d expect in each cell, squaring that difference, and dividing by the total number of respondents, produces a χ2 value of 22.16. The degrees of freedom are ‘2 – 1’ times ‘2 – 1’, which is 1 degree of freedom. I’m sure that this χ2 value is significant at the 0.5 level. Therefore, we’d conclude that there’s a relationship between sex and awareness of this tire brand. Slide 19 In returning to example #2, we’ve established there’s a relationship between ATM usage and age, so younger customers are more likely and older customers are less likely to use ATMs, so let’s run a χ2 test on this data. Page | 5 Slide 20 Looking at ATM usage versus age, the observed counts are 2, 10, and 27 for no usage, and 20, 23, 18 for usage. If there was no relationship between ATM usage and age, we’d expect 8.58 people in the first cell. For the cell below—18-34 year olds who said ‘yes’ to ATM usage—we’d expect 13.42 if there was no relationship between ATM usage and age. Using the same calculations discussed previously—taking the differences between what we observed and what we expect if there’s no relationship, squaring those differences for each cell (so bigger differences count more and little differences count less), and adjust for sample size—the χ2 value is 17.66. The degrees of freedom, which control for the number of differences squared and summed, is ‘2’. The χ2 table of values indicates that at χ2 value of 17.66 with two degrees of freedom is significant at the 0.05 level. Thus, there’s a statistically significant relationship between ATM usage and age. Page | 6