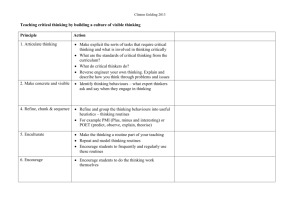
NAG Library for SMP & Multicore
advertisement

NAG Library for SMP & Multicore Make better use of multicore processors for numerical work Easy access to NAG routines for programmers from a variety of environments Library has over 1,700 routines helps users build applications in many different fields 2 2 Symmetric Multiprocessing on multicore CPUs Single, cachecoherent memory visible to all cores on all processors Core Core Core Core Core Core Core Core Memory Cache Cache Memory can be Cache Cache physically partitioned (NUMA systems) Interconnect Subsystem 3 SMP for multicore CPU Every PC is an SMP machine Two or more independent cores on one chip e.g. Intel Core Duo, AMD Athlon X2 as solution to physical limitations in microprocessor design increased performance without heat dissipation Work best for multithreaded applications e.g. SMP-enabled applications, NAG Library for SMP & Multicore 4 SMP Parallelism Multi-threaded Parallelism (Parallelism-on-demand) •Parallel execution •Serial Interfaces •Details of parallelism are hidden outside the parallel region Spawn threads Multi-threading Parallel Region Destroy threads Serial execution Serial execution Parallelism carried out in distinct parallel regions 5 5 Parallelization in NAG Library Parallelism via OpenMP directives shields user from details of parallelism assists rapid migration from serial code Growing number of routines explicitly parallelized more routines benefit by using these internally 6 6 Development of NAG Library NAG leads with SMP libraries on multiple platforms Release 1 (1997) used proprietary directives Release 2 - OpenMP, the portable SMP standard Mark 21 a few more are tuned Mark 22 more routines tuned Mark 23 many more routines tuned About 1/3 of today’s routines benefit from multicore 7 7 Interface to NAG Library Based on standard Fortran Library designed to exploit SMP architecture Identical interfaces to standard Fortran Library identical functionality and documentation as well just re-link the application assists rapid migration from serial code and between platforms Interoperable can call SMP library routines from other languages Easy access to HPC for non-specialists 8 8 Target systems Multi-socket and/or multicore SMP systems: AMD, Intel, IBM, SPARC processors Linux, Unix, Windows operating systems Standalone systems or within nodes of larger clusters or MPPs Others : Traditional vector (Cray X2, NEC SX8, etc) Virtual Shared Memory over clusters in theory, but efficiency may be poor on many algorithms due to the non-Uniform memory access (NUMA) design of such configurations Notable exceptions: GPUs (graphical processing units) FPGAs (field-programmable gate arrays) (future versions of OpenMP may help with these architectures) 9 Contents of Library Root Finding Summation of Series (e.g. FFT) Quadrature Ordinary Differential Equations Partial Differential Equations Numerical Differentiation Integral Equations Mesh Generation Interpolation Curve and Surface Fitting Optimisation Approximations of Special Functions • Wavelet Transforms • • • • • • • • • • • • • Dense Linear Algebra • Sparse Linear Algebra • Correlation and Regression Analysis • Multivariate Analysis of Variance • Random Number Generators • Univariate Estimation • Nonparametric Statistics • Smoothing in Statistics • Contingency Table Analysis • Survival Analysis • Time Series Analysis • Operations Research Note:Not all routines in these areas parallelised 10 Areas with parallelism (Mark 23) Root Finding Summation of Series (e.g. FFT) Quadrature Ordinary Differential Equations Partial Differential Equations Numerical Differentiation Integral Equations Mesh Generation Interpolation Curve and Surface Fitting Optimisation Approximations of Special Functions • Wavelet Transforms • • • • • • • • • • • • • Dense Linear Algebra • Sparse Linear Algebra • Correlation and Regression Analysis • Multivariate Analysis of Variance • Random Number Generators • Univariate Estimation • Nonparametric Statistics • Smoothing in Statistics • Contingency Table Analysis • Survival Analysis • Time Series Analysis • Operations Research Note:Not all routines in these areas parallelised 11 NAG Library contents: new at Mark 23 Mark 23 has new routines in the areas of Local and Global Optimization Wavelets Transforms Linear Algebra Routines Roots of Nonlinear Functions Quadrature ODEs Matrix Operations Eigenvalues Determinants LAPACK Linear Systems Correlation and Regression Analysis Random Number Generators Univariate Estimation Nonparametric Statistics Option Pricing Formulae 12 NAG Library Mark 23 documentation Library has complete documentation distributed as PDF and XHTML part of the installation, and on the NAG website Chapter introductions technical background to the area clear direction for choosing the appropriate routine based on the problem characteristics using decision trees, tables and indexes 13 NAG Library Mark 23 documentation (1) Each routine has a self-contained document description of method specification of each parameter explanation of error exit remarks on accuracy Document contains example programs to illustrate use of routine source, input data, output used in implementation testing Examples are also part of installation 14 NAG Library Mark 23 documentation (2) 15 NAG includes example code and data 16 SMP & Multicore contents at Mark 23 The enhancements of NAG Library Mark 23 Same functionality as serial Library (1,700+ algorithms) 200+ explicitly-parallelized, 340+ enhanced routines Fast Fourier Transforms (FFTs) Quadrature Partial differential equations Interpolation Global optimization of a function Particle Swarm Optimization Dense linear algebra (LAPACK) 17 The parallel routines In Mark 23: Over 120 NAG-specific routines are parallelized, (including: Optimization, Interpolation, Fourier transform, Quadrature, Correlation, Regression, Random number generation and Option pricing) 150 routines are enhanced by calling tuned NAG routines. (including: ODE’s PDE’s and time series analysis) Over 70 are tuned LAPACK routines (for Linear equations); and Over 250 routines are enhanced through calling tuned LAPACK routines (including: nonlinear equations, matrix calculations, eigenproblems, Cholesky factorization) 18 NAG Library Mark 23: Further Statistical Facilities Random number generation Simple calculations on statistical data Correlation and regression analysis Multivariate methods Analysis of variance and contingency table analysis Time series analysis Nonparametric statistics 19 NAG Library Mark 23: More Numerical facilities Optimization, including linear, quadratic, integer and nonlinear programming and least squares problems Ordinary and partial differential equations, and mesh generation Numerical integration and integral equations Roots of nonlinear equations (including polynomials) Solution of dense, banded and sparse linear equations and eigenvalue problems Solution of linear and nonlinear least squares problems Special functions Curve and surface fitting and interpolation 20 SMP & Multicore Library – Performance Some performance results for a few routines from Mark 23 of NAG Library for SMP & Multicore Platform details 2 AMD Opteron 6174 processors each processor has 12 cores, running at 2.2 GHz 21 Matrix properties Order 38,744 nonzeros 1,771,722 type real structure unsymmetric Note: run times level out beyond 16 for this problem type Matrix properties Order 38,744 nonzeros 1,771,722 type real structure unsymmetric 24 Core comprising: 2AMD Opteron 6174 processors. 2.2 GHz.. Note: run times level out beyond 16 for this problem type Matrix properties Order 21,200 nonzeros 1,488,768 type real structure unsymmetric 24 Core comprising: 2AMD Opteron 6174 processors. 2.2 GHz.. Note: run times level out beyond 16 for this problem type Matrix properties Order 41,092 nonzeros 1,683,902 type real structure unsymmetric 24 Core comprising: 2AMD Opteron 6174 processors. 2.2 GHz.. Note: run times level out beyond 16 for this problem type 24 Core comprising: 2AMD Opteron 6174 processors. 2.2 GHz.. 24 Core comprising: 2AMD Opteron 6174 processors. 2.2 GHz.. Conclusions Multicore systems are the standard now NAG Library for SMP & Multicore provides scalable parallel code easy migration from serial routines interfaces that match the standard NAG Fortran Library Reliability all routines vigorously tested from extensive experience implementing numerical code Portability made accessible from different software environments constantly being implemented on new architectures 30 Additional slides 1 Mark 23 full contents summary slide 1 slide on top new items NAG Mark 23 (FS & FL) 4 slides listing NAG Library Mark 23 new functions (SMP & multicore Library & Fortran Library ) 5 slides to describe the SMP parallel approach 5 performance slides 2 slides on performance advice 31 NAG Library Contents Root Finding Summation of Series Quadrature Ordinary Differential Equations Partial Differential Equations Numerical Differentiation Integral Equations Mesh Generation Interpolation Curve and Surface Fitting Optimization Approximations of Special Functions Dense Linear Algebra Sparse Linear Algebra Correlation & Regression Analysis Multivariate Methods Analysis of Variance Random Number Generators Univariate Estimation Nonparametric Statistics Smoothing in Statistics Contingency Table Analysis Survival Analysis Time Series Analysis Operations Research 32 Top new items at Mark 23 2D wavelets – further extension to an important tool for determining the structure of time series such as those arising in finance Sparse Matrix functions – the quality of the NAG implementations Optimisation - BOBYQA - of particular use with noisy functions Optimisation – Muti-start – a robust approach Optimization - PSO – Stochastic Optimization is still somewhat experimental. Particle Swarm Optimization is one of the best of the stochastic approaches. This NAG implementation is probably the most robust available since it also calls local optimization routines as part of the approach. PSO is only relevant to very high dimension problems with lots of noise Quantile regression - One advantage of quantile regression, vrs least squares regression (is in NAG) quantile regression is more robust against outliers in the response measurements L’Ecuyer MRG32K3a generator – a very efficient random number generator (note those who already use Mersenne Twister may be unlike to change – they benefit from the new ‘skip ahead’ approach.) NCM – performance improvements for Nearest Correlation Matrix and two new functions (use of a weighted norm & matrices with factor structure) 33 New in Mark 23 (1 of 4) Chapter C05 (Roots of One or More Transcendental Equations) has a new routine for solving sparse nonlinear systems and a new routine for determining values of the complex Lambert–W function. Chapter C06 (Summation of Series) has a routine for summing a Chebyshev series at a vector of points. Chapter C09 (Wavelet Transforms) has added one-dimensional continuous and two-dimensional discrete wavelet transform routines. Chapter D02 (Ordinary Differential Equations) has a new suite of routines for solving boundary-value problems by an implementation of the Chebyshev pseudospectral method. Chapter D04 (Numerical Differentiation) has added an alternative interface to its numerical differentiation routine. 34 New in Mark 23 (2 of 4) Chapter E01 (Interpolation) has added routines for interpolation of four and five-dimensional data. Chapter E02 (Curve and Surface Fitting) has an additional routine for evaluating derivatives of a bicubic spline fit. Chapter E04 (Minimizing or Maximizing a Function) has a new minimization by quadratic approximation routine (aka BOBYQA). Chapter E05 (Global Optimization of a Function) has new routines implementing Particle Swarm Optimization. Chapter F01 (Matrix Operations, Including Inversion) has new routines for matrix exponentials and functions of symmetric/Hermitian matrices; there is also a suite of routines for converting storage formats of triangular and symmetric matrices. Chapter F06 (Linear Algebra Support Routines) has new support routines for matrices stored in Rectangular Full Packed format. 35 New in Mark 23 (3 of 4) Chapter F07 (Linear Equations (LAPACK)) has LAPACK 3.2 mixed-precision Cholesky solvers, pivoted Cholesky factorizations, and routines that perform operations on matrices in Rectangular Full Packed format. Chapter F08 (Least Squares and Eigenvalue Problems (LAPACK)) has LAPACK 3.2 routines for computing the singular value decomposition by the fast Jacobi method. Chapter F16 (Further Linear Algebra Support Routines) has new routines for evaluating norms of banded matrices. Chapter G01 (Simple Calculations on Statistical Data) has new routines for quantiles of streamed data, bivariate Student's t-distribution and two probability density functions. Chapter G02 (Correlation and Regression Analysis) has new routines for nearest correlation matrices, hierarchical mixed effects regression, and quantile regression. 36 New in Mark 23 (4 of 4) Chapter G05 (Random Number Generators) has new generators of bivariate and multivariate copulas, skip-ahead for the Mersenne Twister base generator, skip-ahead by powers of 2 and weighted sampling without replacement. In addition, the suite of base generators has been extended with the inclusion of the L'Ecuyer MRG32K3a generator. Chapter G07 (Univariate Estimation) has new routines for Pareto distribution parameter estimation and outlier detection by the method of Peirce. Chapter G08 (Nonparametric Statistics) has routines for the Anderson– Darling goodness-of-fit test. Chapter G12 (Survival Analysis) has a new routine for computing rank statistics when comparing survival curves. Chapter S (Approximations of Special Functions) has a new routine for the scaled log gamma function and the S30 sub-chapter has a new routine for computing Greeks for Heston's model option pricing formula 37 Additional slides – tech summary Five slides follow to help describe SMP parallel systems 38 SMP for HPC HPC Clusters are also built with multi-core. Memory per node is decreasing and there is contention for the communication network with allto-all calls. No longer always appropriate to have an MPI process on each core. Hybrid programming is now often required. This can be easy - you replace the serial NAG Library with the NAG Library for SMP & Multicore. 39 SMP Parallelism: Strong Points Dynamic Load balancing Amounts of work to be done on each processor can be adjusted during execution Closely linked to a dynamic view of data Dynamic Data view Data can be ‘redistributed’ on-the-fly Redistribution through different patterns of data access Portability Modularity Good programming model and wide useage 40 Additional slides – Performance graphs 3 slide – different problem sizes 2 slide – compare to serial (NAG FL) 41 Additional slides – Performance advice 1 slide – help in choosing routine 1 slide – example: global optimization routines 42 Performance advice Routines from NAG Library for SMP & Multicore Consult documentation to see which routines have been parallelised Also which routines may get some benefit because they internally call one or more of the parallelised routines Library introduction document gives some extra advice on using some of the parallelised routines Consult NAG for advice if required 43 Example: Numerical Optimization Parallel Global Optimization: Multilevel Coordinate Search (MCS) algorithm (Mark 22 and 23) is also tuned for serial performance Works well in parallel environments but not ideal for parallel gains Particle Swarm Optimization algorithm (Mark 23) Stochastic method Scales well on parallel hardware (less performance in serial mode), thus PSO is a complement, not a replacement, for existing routines 44