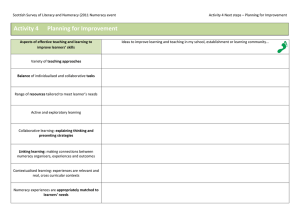
Numeracy Outcome 3
advertisement

Numeracy Outcome 3 [HIGHER] Introduction Section 1: Mean and Standard Deviation Section 2: Median and Quartiles Section 3: Transposition of Formulae Section 4: Correlation and Regression Section 5: Recurrence Relations Tutor Assignments 3 5 25 49 87 113 139 In Outcome 3, answers for each section are at the end of that section. INTRODUCTION The following is an extract from the National Unit Specification of standards. Outcome 3 Apply in combination a wide range of numerical and statistical skills. Performance criteria (a) Work with a mathematical concept. (b) Decide the steps to be carried out. (c) Carry out a number of sustained complex calculations. This pack contains five sections. Each section deals with a topic that contains work at the level required for Numeracy (Higher). The Tutor Assignments for each section are all at the end of the pack. You will have received guidance from your tutor as to which topics you should study; it is doubtful if you will have to do them all. Equally, your tutor may well give you topics which are not included in this pack. Whichever topics you do, I hope you find them interesting. Resources You will need a scientific calculator. Assessment The assessment paper is likely to contain questions on a variety of topics. You will have to answer a selection of these. Your tutor will give you guidance on this. Good luck with the Outcome. OUTCOME 3: NUMERACY/HIGHER 3 4 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION SECTION 1 Measures of Central Location and Measures of Dispersion When analysing data, we frequently have more numbers than we can comfortably cope with, and very often the first job is to try to cut down the amount of information that we have. There are many ways of doing this, but one way is to try to summarise the entire data set by using just a few numbers to represent it, so that these numbers can be used in further calculations or quoted by people, such as politicians. Needless to say, any old numbers won’t do, and over the years several different methods have evolved. These fall into two main categories: measures of central location (or tendency) and measures of dispersion. Measure of central location: the mode This is a very grandiose title for a very simple idea. If you could represent a whole set of numbers by just one, what would it be? Since it’s difficult to talk hypothetically, it will help if we have some actual numbers to play with. Suppose I stand outside the gates of a factory and ask the first 15 people who come out what they earned for the their day’s work. Here is a possible set of answers, the figures all rounded off to the nearest whole £: 45 52 39 52 63 60 52 58 54 47 41 52 55 58 52 What one number would you pick to represent this set? Because they’re all jumbled up it’s difficult to make any sense of them at all. So we’ll start by putting them in order of size, smallest to largest. 39 41 45 47 52 52 52 52 52 54 55 58 58 60 63 Let’s call this set A. If we take the path of least resistance, and wish to make no calculations at all, the representative number that jumps out is 52. This is because there are more 52s than there are of any other number. OUTCOME 3: NUMERACY/HIGHER 5 MEAN AND STANDARD DEVIATION In this case we say that £52 is the mode of the distribution. • The mode is the member of the data set which occurs more often than any other number. The mode is by far the simplest measure of central location, which can be thought of as a value around which the set of data is located. Associated with measures of central location are the so-called measures of dispersion. Measure of dispersion: the range Measures of dispersion tell us how dispersed, or spread out, the data set is. Here is another set of figures, giving daily earnings for a different sample of workers at the same factory, already lined up in order of size: 25 28 35 38 42 47 52 52 52 59 64 67 We’ll call this set B. Although there are only 12 numbers in this data set, that doesn’t stop us comparing them. The mode is still 52, but the numbers are spread out more. This leads us to the simplest measure of spread – the range. • The range of a set of data is the difference between the largest and smallest member of the data set. The range of set A is £63 – £39 = £24 The range of set B is £67 – £25 = £42 Set B is thus more spread out than set A, which you presumably had realised already, but at least we now have a figure to represent the amount of spread. These two measures, the mode and the range, are very rudimentary and unsophisticated. But at least statisticians the world over know exactly what they are talking about when they use these two words – mode and range – and so long as they are aware of the limitations of these two measures, they can use them to good effect. And the mode and range don’t need much effort to be found! When teaching this topic in class, it is at this stage that I can usually sense a feeling of unrest among my students, with elbow nudging and whispering. ‘What about the average?’ I hear them say. ‘We did that in primary school.’ So let’s have a quick look at average next. 6 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION Measure of central location: the mean First of all, the word ‘average’ is such a commonly used expression, covering such a multitude of sins, that statisticians have coined a more specific word to be used in its place. That word is mean. The mean, like the mode, is a measure of central location. • The mean of a data set is the total of all the values of the data set divided by the number of members of the data set. When the credits roll at the end of an episode of Taggart on TV, the singer is enthusing about Glasgow being ‘no mean city’, in the sense of ‘no average city’ or ‘no ordinary city’ (but those words wouldn’t fit with the music). The mean is the average which you did, in fact, learn about in primary school. The mean of set A is (39 + 41 + ... + 60 + 63) ÷ 15 = 780 ÷ 15 = £52. That this is exactly the same as the mode is coincidence, and as much a surprise to you as it was to me when I worked it out. Coincidences do occur. Sometimes they mean something, at other times they don’t. This one doesn’t. Activity 1a What is the mean of set B? Note that all our measures have a unit attached. In this case it is £s. It could have been $, people, cm, seconds, elephants or whatever. But there is always a unit attached, so try to get into the habit of using units. The measure of dispersion usually associated with the mean is called the standard deviation, and we will be looking at that in detail later in this section. Measure of central location: the median The third commonly used measure of central location is the median, and this is actually gaining in popularity, mainly thanks to an eminent American statistician called Tukey (pronounced Chookie) who died as recently as 2000. We’ll look at the median in more detail later but, briefly, the median is the middle number of a data set when the data is arranged in order of size. If we look back at set A, the middle number is 39 41 45 47 52 52 52 52 52 54 55 58 58 60 63 There are seven numbers to the left of the circled £52 and seven to the right of it, so the median is £52. We have £52 again – and this is not so much of a coincidence this time. It certainly looks as if £52 could represent set A quite happily. OUTCOME 3: NUMERACY/HIGHER 7 MEAN AND STANDARD DEVIATION Activity 1b What is the median of set B? Are you having difficulty working this out? What’s the problem? What’s a good compromise? So which measure is better, the mean or the median? Let’s go back to our original example of the workers at the factory gate. Suppose you ask one extra person what their earnings were for that day, and you just happen to pick the Boss, whose Rolls Royce is quietly purring its 6-litre supercharged engine round the corner. ‘Actually, I reckon I earned £350 for today’s efforts.’ Let’s look at our two sets now: Set A: 39 41 45 47 52 52 52 52 52 54 55 58 58 60 63 350 Set B: 25 28 35 38 42 47 52 52 52 59 64 67 350 Activity 1c Calculate the mean and the median of the new Set A and the new Set B. Comment on the changes between the values you have just obtained and the old ones. You have just met one of the main disadvantages of the mean – that one very extreme value can pull it out of its more natural, representative position. Some statisticians get round this problem by using a so-called truncated mean, which is the mean of all the numbers except a percentage of them from the top and bottom, i.e. it allows you to ignore outliers (extreme values at the top or bottom of the range). The measure of dispersion associated with the median is called the semi-interquartile range (or quartile deviation in some older textbooks). We’ll study this more closely in Section 2. To end this introduction, here is a summary of the advantages and disadvantages of the three measures of central location. The mean Advantages • It is the best-known measure of average. • It can be calculated easily. • It uses all the data. • It is used in more complicated mathematical formulae, probably its most important feature. 8 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION Disadvantages • It is affected by extreme values (as in the example above). • It can give impossible values (e.g. 1.8 children). • It need not be a member of the data set. The median Advantages • It is not influenced by extreme values. • It can be obtained even if some values are missing. • It is usually represented by an actual data value. Disadvantages • It does not reflect the full range of values. • It might not be typical of the data set if the set is very small or irregularly distributed. • In grouped distributions it can only be estimated. • It cannot be used in further statistical formulae. The mode Advantages • It is not affected by extreme values. • It is very easily found from a table or graph. • The whole distribution is not necessarily required. Disadvantages • In grouped distributions it cannot be found exactly. • There may be more than one mode. • It ignores dispersion around the modal value. • It cannot be used in further statistical work. In classical statistics, i.e. statistics as developed since the middle of the nineteenth century, the mean is probably the single most important statistic which is calculated and, when used in conjunction with the standard deviation, it forms the basis of much statistical analysis and testing. Since the 1970s, however, a modern approach to statistics known as exploratory data analysis has emerged. It puts great emphasis on the median, and there is much research currently being undertaken into its applications. OUTCOME 3: NUMERACY/HIGHER 9 MEAN AND STANDARD DEVIATION Using the Mean and Standard Deviation We now look in more detail at the calculations which are required to find the mean and the standard deviation. You will fully understand what’s going on after you have read through Example 1a on pages 11–12. As we have seen, the mean of a set of data values is the arithmetic average of those values, i.e. the total of the values divided by the number of values there are. The standard deviation measures how much the data is spread about. It tells you how far away, on average, each member of the data set is from the mean. The mean and standard deviation, used on their own just for one data set, give us a limited summary of what is going on. However, we often have several data sets which we want to compare, and there are various recognised procedures for making comparisons. The means and standard deviations of the data sets play a crucial part in the calculations. Notation If the data set is a sample, which more often than not it is, we use the following notation in the Latin alphabet (x is usually read as ‘x bar’): Mean: x Standard Deviation: s If the data is a population, i.e. if it is all the data which exists about a certain situation, then we use the Greek alphabet. This is an internationally recognised convention: Mean: µ Standard Deviation: σ µ is pronounced ‘myoo’ and is simply the Greek letter m; σ is pronounced ‘sigma’ and is the lower case Greek letter s. (The capital Greek s, Σ (also pronounced ‘sigma’), is used to mean ‘the sum of’ and you will meet it very soon – almost immediately in fact.) Suppose you are analysing the wages paid to building trades people in a particular company. If you use the wages of everyone in the company in your calculation then you are dealing with a population and you use the Greek letters. On the other hand if all the data is unavailable and you use only the wages of the workers on one particular site, then you are dealing with a sample and you use the Latin letters. (There is actually more to it than that – some of the formulae change depending on whether it’s a sample or population, and also on what kind of comparisons we want to make, but you don’t need to worry about this yet.) 10 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION However, I will use x and s for the mean and standard deviation in all the answers from now on, for simplicity. Data in the form of a short set of (individual) raw scores The formulae we use are: Σx Mean: n Standard Deviation: Σ(x – x ) 2 n The formula for the mean tells you to add up all the data values (that’s the top line) and divide by n which is the letter that represents the total number of values that there are. The standard deviation formula is a bit harder to explain. We start off by subtracting the mean (x) from each member of the data set (x). But this will give us some positive numbers and some negative which will then add up to give us zero. So to get round this problem we square the results of all our subtractions (i.e. we square all these ‘deviations from the mean’), add up all these now positive numbers, then find their average by dividing by n. However, our units are all wrong! Suppose we are analysing wages. The wages are in ‘pounds’ and we are at the moment calculating an average of ‘square pounds’ (?). So we take the square root of the answer to bring our units back to the original. The alternative definition of standard deviation is the root mean square deviation from the mean, which is precisely what the formula is calculating. Example 1a Find the mean and standard deviation of the numbers 3, 7, 2, 7, 4 Solution: First find the mean: x= Σx 3+7+2+7+4 23 = = = 4.6 n 5 5 OUTCOME 3: NUMERACY/HIGHER 11 MEAN AND STANDARD DEVIATION Next, make up a table like this: In this column we square each number in the previous column (i.e. multiply it by itself) In this column we are subtracting the mean (4.6) from each number in the first column. V V 3 7 2 7 4 TOTAL –1.6 2.4 –2.6 2.4 –0.6 0 (x – x) 2 2.56 5.76 6.76 5.76 0.36 21.20 V x – x = x – 4.6 x Notice there are no negative numbers in column 3. Squaring any number always gives us a positive answer. Now perform the calculation: s = Σ(x – x )2 n = 21.20 = 5 4.24 = 2.06 (to 2 d. p.) This means that, on average, each number is 2.06 away from the mean of 4.6. (The 0 total in the table just helps to check that the column entries are correct.) Data in the form of a simple frequency table We use a frequency table in situations where each member of the data set occurs more than once. The data of the previous example could have been arranged as a frequency table like this, although for such a simple example it would have been a bit of a waste of time. The column of xs shows the values of the variable x. x 2 3 4 7 Total The frequency (f) column shows the number of times each value occurs. We have to amend our formulae slightly x or µ = 12 Σfx Σf OUTCOME 3: NUMERACY/HIGHER s or σ = Σfx 2 Σfx – Σf Σf 2 f 1 1 1 2 5 MEAN AND STANDARD DEVIATION Note that fx means f × x and that fx2 means either fx × x or f × x 2 but emphatically NOT fx × fx. You need some fairly complicated maths to see that the formula for the standard deviation calculates the same thing as the first formula did on page 11, but please take my word for it that it does. Example 1b The table below shows the number of strokes required by golfers to get round a particular course during the first round of a competition. (It must have been an easy course!) No. of strokes (x) No. of golfers (f) 67 15 68 23 69 38 70 27 71 25 72 19 73 16 74 10 75 4 Find the mean and standard deviation. Solution How do you apply the formulae to this table? Start by writing the data in a column, not a row, and adding a column for fx and another column for fx2. Thus the formula for the mean gives (total number of strokes) ÷ (total number of golfers) giving the average number of strokes per golfer. Before you do the calculations, look at the data and see if you have some sort of idea as to the answers to expect. You see there is a quick build-up of numbers to 69, then a long tail to 75. You could make a rough guess that the mean will be about 70. The standard deviation is also easy to estimate. Take the range of your data (= the largest minus the smallest member of the data set, in this case 75 – 67 = 8). In many situations the standard deviation is, very roughly, between one third and one quarter of the range. 1/ 3 of 8 is 2.7 and ¼ of 8 is 2. So we would expect the standard deviation to be somewhere between 2 and 2.7. And, if not, then not too far away. OUTCOME 3: NUMERACY/HIGHER 13 MEAN AND STANDARD DEVIATION Now for the actual calculations: Here we multiply each number of the x column by its partner in the f column. The first line means 15 golfers each scored 67. This makes a total of 15 × 67 = 1005 strokes. V f 15 23 38 27 25 19 16 10 4 177 V This is the total number of golfers in the first round. x= Σfx 12,432 = = 70.24 Σf 177 fx 1,005 1,564 2,622 1,890 1,775 1,368 1,168 740 300 12,432 fx 2 67,335 106,352 180,918 132,300 126,025 98,496 85,264 54,760 22,500 873,950 V V V x 67 68 69 70 71 72 73 74 75 TOTALS This is the total number of strokes played by everyone in the entire first round. 2 s= The last column required by the formula. The 67335 we get by multiplying 1005 by 67, alternatively, 15 × 67 × 67 or 15 × 67 2 . V This column shows how many people score how many strokes. E.g. 15 people each score 67, then 23 people each score 68 etc. V This column shows that the lowest number of strokes for a round in the competition is 67 and the highest number is 75. Σfx 2 Σfx – = Σf Σf This total doesn’t actually mean very much but you need it for the formula. 2 873,950 12,432 – = 2.07 177 177 As you see, both tie in with our initial estimates. Estimates won’t help if you make a small error in the calculations, but they do tell you if you are miles out. 14 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION ? 1A NOTE: It can help considerably if you are familiar with your calculator and are able to use the memory keys efficiently. You can then add each of your multiplications into the memory and get the final column total without having to key all the numbers back in again. Check your manual. 1. Find the mode and the range of each set of numbers. Next, have a guess at what you think the mean and standard deviation of each set is. Finally, calculate the mean and standard deviation as shown in Example 1a. (a) (b) 2. 2, 5, 6, 6, 7, 10 1, 3, 5, 7, 7, 8, 8, 8, 9, 11 Below is a table which gives the breaking stress of each of 9 test cubes of concrete, the units of measurement being N/mm2. Calculate the mean breaking stress and the standard deviation. (This is also done as Example 1a; it just looks a bit different.) Cube Breaking stress 3. B 25.2 C 21.7 D 23.8 E 25.9 F 20.3 G 21 H 26.6 I 22.4 In absorption tests on 200 bricks the following figures were obtained. Calculate the mean absorption rate and the standard deviation. (Follow the procedure of Example 1b.) % absorption Frequency 4. A 19 6 1 7 5 8 13 9 31 10 51 11 47 12 33 13 14 14 4 15 1 The number of hours worked each week by each of 100 workers in a construction company was recorded as follows. Calculate the mean number of hours worked and the standard deviation. Hours per worker Number of workers 40 3 41 4 42 8 43 12 44 17 45 21 46 19 47 11 OUTCOME 3: NUMERACY/HIGHER 48 5 15 MEAN AND STANDARD DEVIATION Data in the form of a grouped frequency table We use a grouped frequency table if the range of values in the data set is far too large to have each number shown individually in the frequency table. We have to group the values in bundles, or class intervals (to use the correct terminology). Example 1c Here we see the wages of a bunch of employees, grouped in intervals of £50: Wages (£) Frequency (f) 100-150 150-200 200-250 250-300 300-350 350-400 400-500 17 25 34 47 26 15 3 The first interval is defined as £100–150. The £100 is called the lower limit and the £150 is called the upper limit. But look at the first two intervals. The first is £100–£150 and the second is £150-£200. Thus the lower limit of the second is exactly the same (£150) as the upper limit of the first. So suppose an employee earns exactly £150. Which interval is that person in? Is he or she one of the 17 in the first group, or one of the 25 in the second group? The convention in such a situation is that the first interval includes everyone earning from £100.00 to £149.99 inclusive, and the second interval from £150.00 to £199.99 inclusive and so on. In other words, the upper limit of an interval is exclusive and the lower limit of an interval is inclusive. This convention only applies where the intervals are defined in such a way that each one starts on exactly the same number as the previous one finished on. Consider the first interval again. The 17 employees could all be earning as much as £149.99 each or as little as £100.00 each, we have no way of knowing. So, in order to make any calculations at all, we have to make a fairly big assumption – that they all earn an amount that is in the middle of the interval. The £149.99 is so close to £150 as makes no odds, so pretend they all earn £(100+150) ÷ 2 = £125. We make the same assumption for all the other intervals, and all these mid-values become the x of our formula. The mean and standard deviation thus found aren’t absolutely exact, but (unless we are very unlucky) they are close enough to the real values to be usable. In statistics, ‘near enough is good enough’! We can only do the best we can with the information we have. 16 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION Note that the last interval is slightly different (actually twice the width of the others), and our last mid-value will thus be slightly different in appearance from the rest as well. Before launching into calculations step back a bit and really LOOK at the data. Try to get a feel for it. What is it trying to tell you? Roughly what do you think the mean is? Off the top of my head I’d say it was about £250. What about the standard deviation? Again we’re going to be operating with the mid-values of the intervals. The mid-value of the first interval is half of (100 + 150) = 125. The mid-value of the last interval is half of (400 + 500) = 450. So the range of these is 450 – 125 = 325. Divide this range by 3 (approx 108) and divide the range again by 4 (approx 80). So a standard deviation should be somewhere around 80 to 108. Let’s see! The x of our formula is the mid-value of each interval. Add together the lower and upper limit, then halve the answer. These three columns are exactly as before. 17 × 125 = 2,125 then 2,125 × 125 or 17 × 1,252 (either of them) equal 265,625. V V V There is no point in adding this column. f 17 25 34 47 26 15 3 167 V Mid-val x 125 175 225 275 325 375 450 V Wages 100-150 150-200 200-250 250-300 300-350 350-400 400-500 TOTALS fx fx 2 2,125.0 265,625.00 4,375.0 765,625.00 7,650.0 1,721,250.00 12,925.0 3,554,375.00 8,450.0 2,746,250.00 5,625.0 2,109,375.00 1350.0 607,500.00 42,500.0 11,770,000.00 V V V Find these column totals as usual. OUTCOME 3: NUMERACY/HIGHER 17 MEAN AND STANDARD DEVIATION Now for the formulae: x= 42,500 Σfx = = £254.49 167 Σf 2 2 11,770,000 42,500 Σfx 2 Σfx – – = = £75.59 167 f Σf Σ 167 s= The mean we have calculated is close to our estimate. The standard deviation is lower than we estimated but not miles away, so we are happy with the answers. ? 1B Read the important note on page 20 before looking up the answers. 1. The table below represents the weights of a sample of 100 male students at a college. Find the mean weight and the standard deviation. Weight (kg) Frequency 2. 60-64 5 76-80 8 20-25 5 25-30 17 30-35 52 35-40 18 40-45 7 45-50 1 470-480 480-490 490-500 500-510 510-520 520-530 530-540 17 28 63 105 87 35 30 The table below shows the ages of passengers on a cruise ship. Find the mean age and the standard deviation. Note: the last interval is ‘open-ended’ and theoretically could go all the way up to 100 or more. But we use the convention that it is the same width as the one next to it. Age, x Number, f 18 72-76 27 The daily output of components produced by a machine was logged over a period of a year. The table below gives the results. Find the mean daily output and the standard deviation. Daily output, x No. of days, f 4. 68-72 42 The following table gives the moisture content in 100 test samples of a particular cement mix after a certain time interval. Calculate the mean moisture content and the standard deviation: % Moisture content Number of samples 3. 64-68 18 18-25 46 25-35 157 OUTCOME 3: NUMERACY/HIGHER 35-50 218 50-65 308 65-75 146 75 & over 23 MEAN AND STANDARD DEVIATION The best uses of the mean and standard deviation are in an area of statistics called inferential statistics or hypothesis testing, which is not covered in this section. However, it is worth mentioning a few relevant points about this. Most people intuitively understand what the mean is. Standard deviation is another matter. The standard deviation of one frequency distribution is fairly meaningless on its own. The meaning only becomes apparent if we have more than one distribution to look at. Here are three distributions, each presented in the form of a histogram, with their means and standard deviations calculated. (A histogram is a special type of bar chart. The class limits (as you have studied them so far) appear at the boundaries of the bars. There are no spaces between the bars. Ask your tutor if you want to know more.) Each histogram is for 176 people arranged by age in 5-year class intervals. In this histogram the data is well spread out, with almost equal numbers in each interval. 70 60 50 40 Mean = 28.01 years 30 20 St. Dev. = 9.48 years 10 0 In this histogram, the data is more ‘normal’ with fewer people at the ends and more people bunched in the middle intervals. Mean = 26.79 years 10 15 20 25 30 35 10 15 20 25 30 35 40 45 70 60 50 40 30 20 St. Dev. = 6.65 years 10 0 40 45 The means are approximately the same but the standard deviation of the second distribution is smaller than that of the first one, showing less spread (or dispersion, to use the technical jargon). OUTCOME 3: NUMERACY/HIGHER 19 MEAN AND STANDARD DEVIATION In this histogram the spread of the data is very small, with well over 90% of the people in two class intervals. The range of the data is only 20 years (35 – 15 = 20). 90 80 70 60 50 40 30 Mean = 24.97 years 20 10 St. Dev. = 3.11 years 0 15 20 25 30 35 As you see, the standard deviation is considerably smaller now. The larger the standard deviation, the more spread out the data set is, the further away each one is, on average, from the mean. The smaller the standard deviation, the less spread out the data is, the closer each number is, on average, to the mean. * Important note If you have already seen the calculation of standard deviation in, say, a Higher Mathematics course you may well have seen a slightly different formula for it. This is because there is a very slight technical problem which I will explain but which will not really concern you unless your job happens to depend on your knowledge of statistics. One important use of the science of statistics is to collect samples, which are small but hopefully representative pieces of data about a much larger population, and then come to some conclusion about the population from calculations made on the sample. For instance, an opinion poll shows that 60% of a sample of 1,028 people in a constituency plan to vote for party X in a local by-election, and so the conclusion is made that about 60% of the entire electorate will vote that way too. Various mathematical formulae are used in this branch of statistics called inferential statistics. Many of them depend on using the standard deviation of a sample as an estimate for the standard deviation of the population. But the standard deviation of the sample is usually slightly smaller than the standard deviation of the population and this knocks the sums out. And the smaller the sample, the worse it gets. So the sample standard deviation is adjusted to make it slightly higher to alter the calculations to make the predictions more reliable. 20 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION This can be done in two ways. One way is to calculate the true standard deviation (which is what we have been doing) and then adjust it if necessary by using a measure called Bessel’s correction factor. (You don’t need to know what this is about.) The other way is to adjust the standard deviation at source by using a slightly different formula, the reasoning being that, since the majority of data are, in fact, samples, many of which are going to be used for inferential purposes anyway, you might as well adjust the standard deviation before you start. This is not an argument which is relevant here. I have to point this different formula out, though, in case you have come across it in other textbooks and are confused. Here are the two sets of formulae for reference. Decide yourself which set looks easier to use. Σ(x - x ) 2 True standard deviation: n Σ(x - x ) 2 or 2 Adjusted version: n –1 Σx 2 Σx – or n n 1 2 ( Σx ) Σx – n –1 n 2 or Σfx 2 Σfx – Σf Σf or 2 1 2 ( Σfx ) Σfx – Σf –1 Σf 2 All answers in this section have been calculated using the true standard deviation formulae, which are the ones in the top row. OUTCOME 3: NUMERACY/HIGHER 21 MEAN AND STANDARD DEVIATION Answers Activity 1a Mean of set B = £(25 + 28 + 35 + ... + 67)/12 = £561/12 = £46.75 Activity 1b Median of set B: 25 28 35 38 42 47 V 52 52 52 59 64 67 Because there are 12 numbers (i.e. an even number as opposed to odd) there is no middle term. By convention we take the average of the two middle numbers, in this case (47 + 52)/2 = 99/2, so the median is £49.50. Activity 1c Mean of new set A = £1130/16 = £70.63 Median of the new set A is the average of the last two 52s, i.e. £(52 + 52)/2 = £52 Mean of new set B = £910/13 = £70 Median of new set B is the first of the 52s = £52 To summarise: Mean Median Old A £52 £52 New A £70.63 £52 Old B £46.75 £49.50 New B £70 £52 As you see, the mean is considerably increased by the inclusion of an extra large number, whereas the median only moves along ‘half a space’ and thus changes either only a little bit or not at all. There is more about the median in another section of the study pack. 22 OUTCOME 3: NUMERACY/HIGHER MEAN AND STANDARD DEVIATION ?1A: Answers 1. (a) Mode = 6 Range = 10 – 2 = 8 Mean = 36/6 = 6 Σ(x – x ) 2 s= n 34 6 = 2.38 = (b) Mode = 8 Range = 11 – 1 = 10 Mean = 67/10 = 6.7 Σ(x – x ) 2 s= 78 10 = 2.79 = 2. 205.9 9 = 22.9 N/mm2 x= 56.06 9 = 2.5 N/mm2 s= n x 2 5 6 6 7 10 Total x–x= x–6 –4 –1 0 0 1 4 check = 0 (x – x)2 16 1 0 0 1 16 34 x 1 3 5 7 7 8 8 8 9 11 Total x–x= x – 6.7 –5.7 –3.7 –1.7 0.3 0.3 1.3 1.3 1.3 2.3 4.3 check = 0 (x – x)2 32.49 13.69 2.89 0.09 0.09 1.69 1.69 1.69 5.29 18.49 78.10 x 19.0 25.2 21.7 23.8 25.9 20.3 21.0 26.6 22.4 205.9 x–x= x – 22.9 –3.9 2.3 –1.2 0.9 3 –2.6 –1.9 3.7 –0.5 (x – x)2 15.21 5.29 1.44 0.81 9 6.76 3.61 13.69 0.25 56.06 OUTCOME 3: NUMERACY/HIGHER 23 MEAN AND STANDARD DEVIATION 3. 4. x 6 7 8 9 10 11 12 13 14 15 Totals f fx 1 5 13 31 51 47 33 14 4 1 200 6 35 104 279 510 517 396 182 56 15 2,100 fx2 36 245 832 2,511 5,100 5,687 4,752 2,366 784 225 22,538 x= 2,100 = 10.5% 200 22,538 2,100 – 200 200 = 1.56% 2 s= ∑f = 100; ∑fx = 4,460; ∑fx2 = 199,284 x = 44.6 hours; s = 1.92 hours ?1B: Answers As you will have seen by now, the calculations can get tortuous, with numbers running to 6 or more digits. The best advice for someone doing these on a hand-held calculator is to learn how to use the memory function. This will allow you to find a column total without having to key in all the numbers in the column all over again: well worth the effort. 1. Using 62, 66, 70, 74, 78 as mid-values we get ∑f = 100; x = 70.6 kg; 2. ∑fx2 = 499,952 Using 22.5, 27.5, 32.5, etc. as mid-values we get ∑f = 100; x = 32.9%; 3. ∑fx = 7,060; s = 3.89 kg ∑fx = 3,290; s = 4.78% ∑fx2 = 110,525 Using 475, 485, 495, etc. as mid-values we get ∑f = 365; ∑fx = 185,095; ∑fx2 = 93,944,325 x = 507.11 components; s = 14.89 components 4. Using 21.5, 30.0, 42.5, 57.5, 70.0, and 80.0 as mid-values we get ∑f = 898; ∑fx = 44,734; x = 49.82 years; 24 ∑fx2 = 2,437,251 s = 15.25 years OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES SECTION 2 Another common measure of central tendency is the median. The median is the middle member of a data set when the values are all arranged in order of size, smallest to largest. It is fairly obvious why the data must be arranged in order of size. Suppose we have seven people of different ages: 23, 42, 35, 18, 50, 27, 62. The age of the person in the middle is 18. Suppose we now arrange them in a different way: 35, 50, 18, 62, 27, 23, 42. The middle age is now 62, different from last time. So we MUST put the ages in order of size first, before saying which is the middle one: 18 23 27 35 42 50 62 and then we isolate the median: Median is 35 years V 18 V 23 V 27 We have the same number of values on this side of the median... 35 42 50 V 62 V ...as we have on this side Notice that the term median applies to the variable. Thus it’s not the person who is 35 that is the median, it’s the age of 35 years that is the median. If there is more than one value which is the same, line them all up as before. The median may well not be an individual, but it’s a compromise we just have to make. For instance, here is a list of the numbers of passengers in cars passing a traffic control point: 1, 3, 2, 0, 2, 1, 2, 0, 1, 3, 4, 1, 0, 2, 0, 1, 1, 0, 3, 4, 1, 2, 1 OUTCOME 3: NUMERACY/HIGHER 25 MEDIAN AND QUARTILES There are 23 numbers in that list, so line them up and the median will be in the 12th position so that there are 11 on either side of it, even though some of the 11 may well be the same as the median: 0 0 0 0 0 1 1 1 1 1 1 1 1 2 2 2 2 2 3 3 3 4 4 The median number of passengers is 1, or 1 passenger is the median number of passengers. What happens if we have an even number of numbers? In the spirit of compromise we average the two numbers on either side of the median position, like this: Here someone has counted the number of matches in 10 boxes which are supposed to have ‘average contents 40’: 42, 40, 38, 39, 40, 42, 41, 39, 38, 40 First line them up in order: 38 38 39 39 40 40 40 41 42 42 Then find the median: Median is the average of these two ½(40 + 40) = ½ × 80 = 40 so median is 40 V 38 V 38 39 39 V 40 40 40 41 V The same number on this side... 42 42 V ...as on this side Some textbooks give you a formula which can use to find the position in line (or rank) of the median: The rank of the median is 1 2 ( n +1) Thus if there are 11 numbers in line, the median rank is 1 2 (11+1) = 12 ×12 = 6 i.e. the median is the sixth number in line (from either end, though we do usually count from the bottom up). And if there are 12 numbers in line, the median rank is 1 2 26 (12 +1) = 12 ×13 = 6.5 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES Now, you may well say there is no such number as the ‘6.5th’ number, but what this means is ‘the average of the 6th and 7th numbers’. In the same way, a rank of 8.5 means ‘the average of the 8th and 9th numbers’, and a rank of 19.5 means ‘the average of the 19th and 20th numbers’. In the list above, the numbers on either side of the median position were both the same (i.e. both 40) but if they were different you would still follow the procedure. So if we have the numbers 17 19 12 24 22 26 30 18 as being the number of cars passing a checkpoint on the road within a fixed interval of time, the median would be: 12 17 18 19 22 24 26 30 V Median is the average of these two numbers and so the median is 20.5. Thus the median is not itself a member of the data set. This is not a problem. The mean (arithmetic average) is almost never in the data set either. Now we know that there is no such thing as 20.5 cars passing a point, but we can use this number as a measure and compare it with the median derived from other checkpoints, or from the same checkpoint at other times. What it means is during half of the time intervals there were less than 20.5 cars passing the checkpoint and during the other half of the intervals there were more than 20.5 cars passing the checkpoint. Why do we need a median anyway? This has already been discussed in the mean and standard deviation section but a quick second look will do no harm. The mean (or arithmetic average) of a set of numbers is all very well if there are no ‘rogues’ which are abnormally different from the rest. But where this does happen, the mean gets pulled out of its natural position and gives a false impression. Suppose you have the set of numbers, written in order: 10 10 13 14 18. The mean (average) is (10 + 10 + 13 + 14 + 18) ÷ 5 = 13. The median is the middle one of these numbers: 13 is in the middle of the five of them. By sheer coincidence it has turned out to be the same as the mean. OUTCOME 3: NUMERACY/HIGHER 27 MEDIAN AND QUARTILES Now let’s add another number which is much bigger than the others: 10 18 95. 10 13 14 The mean is now (10 + 10 + 13 + 14 + 18 + 95) ÷ 6 = 26.7. As you see, it has moved quite dramatically upwards. Is it now a good representative of the data set? No. What about the median? Well, we have an even number of values so we average out the two middle ones: (13 + 14) ÷ 2 = 13.5. This is much closer to the spirit of the data set than the mean’s 26.7, and so is a better measure of ‘average’. 2.1 Quartiles from a Simple Data Set As with the mean, there is a measure of dispersion associated with the median, but before we can find this we have to know about quartiles. Quartiles are those members of the data set which split the data (when taken in order of size) into quarters. Thus we have: Smallest number in the data set Lower Quartile Q1 Q2 25% of the data Upper Quartile 25% of the data Q3 Largest number in the data set 25% of the data } } } } 25% of the data Middle Quartile = MEDIAN The procedure is to find and isolate the median, and then to find the median of each half of the remaining data. This ensures that the same number of data values lie within each ‘quarter’ of the data set. A few examples will help. Each X represents a member of the data set. the positions of the quartiles are marked. The median is, of course, the same as the middle, or second, quartile. X X 28 X X X X X X X X X V V V Q1 Q2 Q3 X X X X X X X X V V V Q1 Q2 Q3 OUTCOME 3: NUMERACY/HIGHER X X X X MEDIAN AND QUARTILES X X X X X X X X X X X V V V Q1 Q2 Q3 X X Example 2.1a Find the three quartiles of 1.82 1.57 1.64 1.85 1.70 1.75 1.83 where these numbers represent the heights in metres of nine students. 1.80 1.81 Solution: Start by lining the numbers up in order. Since there are nine numbers, the median will be the 5th number. 1.57 1.64 1.70 1.75 1.80 1.81 1.82 1.83 1.85 Q2 We now take the numbers on either side of the median, not including the median, and find the middle of each. Left side 1.64 1.70 1.57 1.75 1.81 Right side 1.82 1.83 1.85 V V Q1 = ½(1.64 + 1.70) = 1.66 Q3 = ½(1.82 + 1.83) = 1.825 The lower quartile is 1.66m, the middle quartile is 1.80m, the upper quartile is 1.825m. Once we have found the actual quartiles we calculate the quartile deviation (or the semiinterquartile range: SIQR for short) using the formula 1 2 (Q3 – Q1) This is because it shows how much, on average, each quartile differs from the median: Distance of lower quartile from median V V Distance of upper quartile from median (Q3 – Q 2 ) + (Q2 – Q1 ) Q – Q 2 + Q 2 – Q1 Q – Q1 = 3 = 3 2 V 2 2 Add up and divide by 2 to find the average OUTCOME 3: NUMERACY/HIGHER 29 MEDIAN AND QUARTILES The semi interquartile range is 1 2 (1.825 – 1.66) = 1 2 × 0.165 = 0.0825m This means that the upper and lower quartiles are, on average, 0.0825 metres away from the median. You will realise that (Q3 – Q1 ) 1 = is the same as (Q3 – Q1 ) 2 2 Here’s another example. Example 2.1b Find the quartile deviation of the weights of this sample of parcels (units are kilograms). 18 25 22 17 21 19 21 19 20 13 17 25 20 19 Solution: Line up in order of size, then find the positions of the quartiles (always find the median first). 13 17 17 18 19 19 19 V 20 20 21 21 V 22 25 25 } } } } V V Q1 V V Q2 V Q3 As you see there are the same number of values (in this case 3) between each quartile position and also from the ends. The median is mid-way between 19 and 20, so it is 19.5kg. The lower quartile is 18kg and the upper quartile is 21kg. The semi-interquartile range (or quartile deviation) is half of (21 – 18)kg, i.e. it is 1.5kg. This means that the upper and lower quartiles are, on average, 1.5kg away from the median. 30 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES ? 2.1 Find the median and the semi-interquartile range of each set of numbers. 1. These are hourly rates of pay in £s, to the nearest whole £, paid to employees of a building firm. 16 2. 15 11 16 17 18 16 13 20 16 19 15 16 11 16 These are times taken in minutes for samples of paint to dry. 120 125 130 126 127 122 131 125 128 129 123 125 3. These are lengths of bits of wire (in cm) cut by an erratic machine. 2.1 2.0 2.5 2.3 2.7 2.5 2.4 1.9 1.8 2.5 2.7 2.3 2.5 2.2 Quartiles from a Simple Frequency Table If your data set is very small, it’s easy enough to line them up in order and count out the positions of the quartiles. But what happens if there are 50 or 100 numbers and not just a dozen or so? Example 2.2a Shoe size x No. of pairs f 5 2 5½ 5 6 8 6½ 13 7 10 7½ 4 8 1 The table above shows how many pairs of shoes of different sizes a shop has. Find the median, quartiles and semi-interquartile range. Solution: There are 43 pairs altogether. The median is therefore the size of the 22nd pair when they are all lined up in order of size. And the table does actually line them up like this. There are 21 pairs of shoes on either side. The middle one of each is the 11th. So we have the following positions for the quartiles: 1st 2nd ... 10th 11th 12th ... 21st 22nd 23rd ... 32nd 33rd 34th ... 43rd TEN NUMBERS Q1 TEN NUMBERS Q2 TEN NUMBERS Q3 TEN NUMBERS To save us doing a lot of counting, we incorporate a cumulative frequency (c.f.) column in our table (conventionally written as a column, but it could just as well be in a row). The cumulative frequency is just a running total. It tells us how many numbers we have passed as we count along the line. OUTCOME 3: NUMERACY/HIGHER 31 MEDIAN AND QUARTILES Shoe size x 5 5½ 6 6½ 7 7½ 8 Total Pairs f 2 5 8 13 10 4 1 ∑f = 43 c.f. 2 7 15 28 38 42 43 2 + 5 = 7. This means 7 pairs were size 5.5 or less. 7 + 8 = 15. This means 15 pairs were size 6 or less. 15 + 13 = 28. This means 28 pairs were size 6.5 or less. 28 + 10 = 38. This means 38 pairs were size 7 or less. 38 + 4 = 42. This means 42 pairs were size 7.5 or less. 42 + 1 = 43. This means 43 pairs were size 8 or less. Now look down the cumulative frequency (c.f.) column. Where a c.f. number is just larger than a quartile position, the variable number (x) it refers to is the quartile. Shoe size x 5 5½ 6 6½ 7 7½ 8 Total Pairs f 2 5 8 13 10 4 1 ∑f = 43 The lower quartile is the 11th number. We c.f. 2 7 15 28 38 42 43 pass 11 in this line. Thus Q1 = shoe size 6. The middle quartile (median) is the 22nd number. We pass 22 in this line. Thus Q 2 = shoe size 6½. The upper quartile is the 33rd number. We pass 33 in this line. Thus Q3 = shoe size 7. We can now find the quartile deviation (semi-interquartile range, SIQR for short) SIQR = 1 2 (7 – 6) = 0.5 That perhaps took a long time to explain, but it’s actually done very quickly. Finding the exact positions of the quartiles like this is a palaver. But there is a formula for it! And you can use the formula to find the positions of pentiles (where the data set is split into fifths) and deciles (split into tenths) and percentiles (split into hundredths) so it’s worth a mention. The exact position (or rank) of the pth q-tile of n observations is given by pn pn INT + 1 but this formula is ONLY used if is NOT a whole number q q where INT means the integral, or whole number part. In this example we have 43 observations (so n = 43) and we want quartiles (so q = 4) and p takes the values 1 (for Q1), 2 (for Q2) and 3 (for Q3) in turn. 32 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES 1× 43 Q1: = INT = INT(10.75) = 10, so rank of Q1 is 10 + 1 = 11 4 2 × 43 Q2 : = INT = INT(21.5) = 21, so rank of Q2 is 21 + 1 = 22 4 3 × 43 Q3 : = INT = INT(32.25) = 32, so rank of Q3 is 32 + 1 = 33 4 and then the exact values of the quartiles can be found as before. (If we want pentiles, q = 5; if we want deciles, q = 10 and so on.) Example 2.2b The table below gives the ages of members of a youth club. I’ve put the cumulative frequency column in right away. Find the quartiles. Age x 13 14 15 16 17 18 19 Total f 23 26 28 22 10 9 2 ∑f = 120 c.f. 23 49 77 99 109 118 120 Reminder: 23 + 26 = 49 49 + 28 = 77 77 + 22 = 99 and so on The last number (120) should be the same as the total of the f column. Solution: Calculate the ranks of the quartiles: 1×120 = 30 (a whole number) so rank of Q1 is average of 30th and 31st numbers, i.e. 30.5 4 2 ×120 = 60 (a whole number) so rank of Q2 is average of 60th and 61st numbers, i.e. 60.5 4 3 ×120 = 90 (a whole number) so rank of Q3 is average of 90th and 91st numbers, i.e. 90.5 4 Now check when we pass each of these rankings as we move down the c.f. column; Age x 13 14 15 16 17 18 19 Total f 23 26 28 22 10 9 2 ∑f = 120 c.f. 23 49 77 99 109 118 120 Pass 30.5 here, so Q1 = 14 years Pass 60.5 here, so Q2 = 15 years Pass 90.5 here, so Q3 = 16 years OUTCOME 3: NUMERACY/HIGHER 33 MEDIAN AND QUARTILES The median age is thus 15 years. The SIQR is half of (16 – 14) i.e. 1 year. This means that, on average, the upper and lower quartiles are 1 year away from the median. One quarter of the members are below 14 years old; a quarter are between 14 and 15; a quarter are between 15 and 16; and the oldest quarter are between 16 and 19. It is just coincidence that the three quartiles all find themselves next to each other like this. Two of them could easily be the same, it just depends on how the numbers are spread out. Just in case you think I’m being too finicky about the ranks of the quartiles, here’s a manufactured example to show you why this is necessary. I’ll also stop using the expression ‘whole number’ and use the more correct ‘integer’. The difference is imortant to mathematicians but not so much so to normal people (!). A whole number is, technically, 0, 1, 2, 3, 4, and so on. Integers include all of these plus negative whole numbers, i.e. -1, -2, -3 and so on. Example 2.2c The table below shows the final golf scores in a tournament of 214 players. Find the quartiles and the semi-interquartile range. Solution: We can calculate the rankings of the quartiles before going to the table, given that we know the value of n. V 1× 214 = 53.5, not an integer, so rank of Q1 is 53 + 1 = 54 4 2 × 214 = 107, an integer, so rank of Q2 is 107.5 4 (rank Q2 is average of 107 and 108) 3 × 214 = 160.5, not an integer, so rank of Q3 is 160 + 1 = 161 4 Strokes 274 275 276 277 278 279 280 281 282 Total f 1 9 15 32 50 25 20 47 15 214 c.f. 1 10 25 57 107 132 152 199 214 We pass 54 here, so Q1 = 277 strokes. Aha! The rank of Q2 is 107.5 but the table clearly shows that the 107th person is the last one to score 278. So the 108th person is the first to score 279. The median is the average of 278 and 279, i.e. 278.5 strokes. We pass 161 here, so Q3 is 281 strokes. The semi-interquartile range is thus (281 – 277)/2 = 2 strokes. 34 OUTCOME 3: NUMERACY/HIGHER pq is exactly n an integer we add 0.5 to it to get the rank, instead of 1. If MEDIAN AND QUARTILES ? 2.2 In each question find the median, the lower and upper quartiles, and the semi-interquartile range. 1. The number of faulty items made per day over a period of 30 days is catalogued as follows. Faults x Frequency f 2. 2 3 3 7 4 4 7 3 9 2 10 1 11 3 0 10 1 21 2 15 3 13 4 8 5 5 6 2 7 0 8 1 For a statistics project, school pupils noted how many people there were in cars passing the school gates during a certain time interval in the morning. People in car x No. of cars f 4. 1 2 During a 75 day period a Fire Brigade attended incidents per day as follows: Incidents x Frequency f 3. 0 5 1 28 2 35 3 20 4 8 5 5 6 1 This table shows the lengths of components produced by a machine, Length of component x (mm) Number of components f 73.0 73.1 73.2 73.3 73.4 73.5 73.6 73.7 25 34 67 100 178 213 104 35 We now look at grouped frequency tables and compare the SIQRs of various related distributions. 2.3 Grouped Frequency Tables If the range of data is so great that we cannot conveniently or sensibly make up a simple frequency table, where each and every data value is represented, we need to group the data to be able to illustrate and analyse it meaningfully. This applies particularly in situations where the variable is a continuous variable, i.e. it can take any value within a given range, to umpteen decimal places if necessary. In particular, measurements fall into this category. OUTCOME 3: NUMERACY/HIGHER 35 MEDIAN AND QUARTILES Example 2.3a Wages (£) 150-200 200-250 250-300 300-350 350-400 400-450 Total No. of Employees 10 25 39 18 9 5 106 Here we have the wages of 106 people in a place of work. Each of the 106 could be earning a different amount. We can’t have a table with 106 entries! So we group the data in class intervals. You’ll notice that the number 200 is represented in both the first and second intervals. By convention, a wage of exactly 200 will be placed in the second interval. So the first interval contains £150.00 to £199.99 inclusive, the second interval contains £200.00 to £249.99 inclusive and so on. Find the quartiles and the semi-interquartile range. (We have to make a rather large assumption: that the wages are spread evenly within each interval. This assumption could be totally wrong, of course, but the numbers may be squashed at the end of one interval in some places and spread out in others. It’s a matter of swings and roundabouts. In the grand scheme of things everything evens out at the end. Any answers we get will be close enough to be used in further analysis. They will only be approximate, but they’ll be the best we can do. As the great (recently deceased) statistician John W. Tukey said, ‘It is better to have the approximate answer to the right question than the accurate answer to the wrong question.’) Solution: As usual, we start by making a column of cumulative frequencies, then calculate the ranks of the quartiles to find where they lie. But since we know that any answers we get will be approximate, we don’t bother with trying to pin down the quartiles exactly. An approximate position will do. We simply find a quarter, a half, and three quarters, of the total number 106. Rank of Q 1 = ¼ of 106 = 26.5 Rank of Q2 = ½ of 106 = 53 Rank of Q 3 = ¾ of 106 = 79.5 36 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES Wages (£) 150-200 200-250 250-300 300-350 350-400 400-450 Total No. of Employees 10 25 39 18 9 5 106 Scanning down the cumulative frequency column as before, Cumulative Frequency 10 35 74 92 101 106 We pass 26.5 here, so Q 1 is in the 200250 group We pass 53 here so Q 2 is in the 250-300 group We pass 79.5 here so Q3 is in the 300350 group Let’s now find the approximate value of the lower quartile. It lies in the 200-250 interval. The numbers 200 and 250 are called the boundaries of that interval, 200 being the lower boundary and 250 being the upper boundary. The upper boundary of the 150-200 group is the same as the lower boundary of the 200-250 group. Imagine that all the employees are strung out in a line according to their wages and we walk along the line. By the time we pass the last of the 150-200 group we have walked past 10 people. The lower quartile is the wage earned by the ‘26.5th’ person in the line so we have 16.5 people still to go before we reach that person. There are 25 people in the 200-250 interval. So, assuming they are nicely spread out, we have to walk past the fraction 16.5/25 of that interval. So we take the same fraction of the width of that interval, which is £50. But the interval’s lower boundary is £200, so we add the fraction onto this lower boundary. Here’s the calculation: 16.5 of £50 = £33, then add this on to £200, so Q1 = £233 25 We repeat this procedure for the other two quartiles. Below is a formula which allows you to slot numbers in and get an answer without much thought, but if you compare the formula for the first quartile with what you’ve just read you will see exactly where each number comes from. First you must identify the interval in which the lower quartile lies. The formula for Q1 is then Lower Class Boundary of the class that Q1 is in + 1 Total – cumulative frequency of the previous interval 4 × the class width frequency of the class that Q1 is in OUTCOME 3: NUMERACY/HIGHER 37 MEDIAN AND QUARTILES This is quite a mouthful, so I’ll do it in shortcuts: LCB Q1 + 1 4 Total – cfint before × width fQ1int Substituting the data we get £200 + 26.5 – 10 × £50 = £233 as before 25 (When using a calculator put brackets round the (26.5 – 10) otherwise you’ll get a different (wrong) answer.) The beauty of this formula is that, with a minor adjustment, you can calculate the values of all the quartiles: Lower quartile Q1 = LCB Q1 + Median Q2 = LCBQ2 + Upper quartile Q3 = LCB Q3 + 1 4 Total – cfbefore × width fQ1interval 1 2 Total – cfbefore × width fQ2interval 3 4 Total – cfbefore × width fQ3interval So we calculate the values as follows: 26.5 –10 × £50 = £233 25 53 – 35 Median Q 2 = £250 + × £50 = £273.08 39 79.5 – 74 Upper quartile Q3 = £300 + × £50 = £315.28 18 Lower quartile Q1 = £200 + and the quartile deviation, or semi-interquartile range, becomes 1 1 (Q3 – Q1 ) = (£315.28 – £233) = £41.14 2 2 This last number won’t mean much to you yet, but it will soon. 38 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES Example 2.3b Two different machines are producing components, supposedly of the same size. Compare the two using medians and quartiles. Machine A Component size (mm) 1200-1205 1205-1210 1210-1215 1215-1220 1220-1225 1225-1240 Total Machine B No. of components 143 217 83 21 17 2 483 Component size (mm) 1200-1205 1205-1210 1210-1215 1215-1220 1220-1225 1225-1240 Total No. of components 25 174 193 32 15 0 439 Solution: Add a cumulative frequency column to each table, then identify the interval in which each required quartile lies. But find the quartile ranks first. Machine A: Q1 ranking 1/4 of 483 = 120.75 Q2 ranking 1/2 of 483 = 241.5 Q3 ranking 3/4 of 483 = 362.25 Q1 in this interval Q2 in this interval Q3 in this interval Component No. of Cumulative size (mm) components frequency 1200-1205 143 143 1205-1210 217 360 1210-1215 83 443 1215-1220 21 464 1220-1225 17 481 1225-1240 2 483 Total 483 Tracking down the c.f. column we pass 120.75 here we pass 241.5 here we pass 362.5 here As you see, each quartile is in a different interval. This often happens, but it need not be so. All the quartiles could be in the same interval, if the data was sufficiently squashed up. OUTCOME 3: NUMERACY/HIGHER 39 MEDIAN AND QUARTILES Now for the calculations: 120.75 – 0 × 5mm = 1204.2mm 143 241.5 –143 Median Q2 = 1205mm + × 5mm = 1207.3mm 217 362.25 – 360 Upper quartile Q3 = 1210mm + × 5mm = 1210.1mm 83 1 1 Quartile deviation (SIQR) = (Q3 –Q1 ) = (1210.1–1204.2) = 2.95mm 2 2 Lower quartile Q1 = 1200mm + Machine B: Q1 ranking 1/4 of 439 = 109.75 Q2 ranking 1/2 of 439 = 219.5 Q3 ranking 3/4 of 439 = 329.25 Q1 in here Q2 in here Q3 in here Component No. of Cumulative size (mm) components frequency 1200-1205 25 25 1205-1210 174 199 1210-1215 193 392 1215-1220 32 424 1220-1225 15 439 1225-1240 0 439 Total 483 Pass 109.75 here Pass 219.5 here Pass 329.25 here As you see here, two of the quartiles are in the same interval. Now for the calculations: 109.75 – 25 × 5mm = 1207.4mm 174 219.5 –199 Median Q2 = 1210mm + × 5mm = 1210.5mm 193 329.25 –199 Upper quartile Q3 = 1210mm + × 5mm = 1213.4mm 193 1 1 Quartile deviation (SIQR) = (Q3 –Q1 ) = (1213.4–1207.4) = 3mm 2 2 Lower quartile Q1 = 1205mm + As you see, the quartile deviations (or semi-interquartile ranges) are virtually the same (B’s being only marginally larger), showing that the two distributions have a similar spread. But A’s median is lower than B’s median. Another point to note is that the two sets of figures are of different sizes. 40 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES Box plots A box plot (or box-whisker chart) is an extremely good way to show median and quartiles for comparison purposes. Many graphic calculators include box plots in their library of statistical charts. A box plot has two components. The first is a line showing the scale of numbers required: 1200 1205 1210 1215 1220 1225 1230 The second is the ‘box’ with its two ‘whiskers’. ¼ of the data values lie in here V V V V V ¼ of the data values lie in here V V V ¼ of the data ¼ of the data values lie in values lie in here here V V V This point marks the position of the smallest number This point marks the position of the lower quartile Q1 V V This point marks the position of the upper quartile Q3 This point marks the position of the middle quartile, Q2 , the median This point marks the position of the largest number Now you marry the two together, lining up the various parts of the boxes with the scale. As an example, here is the data for Example 2.3b. 1200 1205 1210 1215 1220 1225 1230 Machine A Machine B We have to take the two whiskers out as far as they theoretically can go; if you know the actual maximum and minimum values of the data set you would stop the whiskers at those points. (Note that sometimes box plots are drawn vertically instead of horizontally.) OUTCOME 3: NUMERACY/HIGHER 41 MEDIAN AND QUARTILES The actual range of A (1230 – 1200 = 30 mm) is larger than the range of B (1225 – 1200 = 25mm) but the SIQR of B is, as we saw earlier, marginally larger than that of A. Those very few values of A which stretch out to 1230 aren’t enough to counteract the dispersion of B in the most vital area, that of the middle 50%. We can see that B has larger components, with more bunching for the third 25% (between Q2 and Q3) than in A. The smallest 25% of B are dispersed more than the corresponding values of A, since the leading whisker of B is longer. If we added two more machines C and D, without actually showing the class intervals and so on, you can tell even more: 1200 1205 1210 1215 1220 1225 1230 Machine A Machine B Machine C Machine D Which machine do you think is performing best? Which is the worst? Note that there are conventions about what constitutes an outlier (i.e. a rogue value which is substantially higher or lower than all the other values) and how the presence of an outlier can affect the construction of the box plot, but this topic has been deliberately omitted here. Here is a final example about boundaries before you do the last exercise of this section. 42 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES Example 2.3c This table shows the life spans of Christmas tree bulbs. Find the quartiles. Life (hrs) 200-249 250-299 300-349 350-399 400-449 450-499 500-549 550-599 No. of bulbs 4 15 27 45 73 51 19 6 c.f. 4 19 46 91 164 215 234 240 Rank of Q1 is 240/4 = 60. We pass 60 here. Rank of Q2 is 240/2 = 120. We pass 120 here. Rank of Q3 is 3 × 240/4 = 180. We pass 180 here. You’ll notice that the second interval starts at 250, but the first interval ended at 249. This is not what you’ve been seeing so far. But it is very common. The upper limit of the first interval is 249. The lower limit of the second interval is 250. The boundary between them is 249.5 (you split the difference between the limits). The second class has lower boundary 249.5 and upper bounday 299.5. The third class has lower boundary 299.5 and upper boundary 349.5 and so on. This complication only arises if the intervals are so defined that each one starts at a slightly higher number (usually 1 unit more) than the one on which the previous one ended. The quartile formulae use the lower class boundary as the kick-off. Note also that the width of each interval is 50 hours and NOT 49 hours as you might think. The width of an interval is defined as the difference between upper and lower boundaries. (60 – 46) Q1 = 349.5 + × 50 hours = 365.06 hours 45 (120 – 91) Q2 = 399.5 + × 50 hours = 419.36 hours 73 (180 –164) Q3 = 449.5 + × 50 hours = 465.19 hours 51 I’ve given more complete answers here so you can check them on your calculator. But remember these are just approximate. So 2 decimal places aren’t really justified. The nearest whole number may well be appropriate. OUTCOME 3: NUMERACY/HIGHER 43 MEDIAN AND QUARTILES ? 2.3 For each question find the median, the quartiles, and the SIQR. You should also practise drawing box plots. 1. The table represents the weights of a sample of 100 male students at a college. Weight (kg) Frequency 2. 60-62 5 64-66 42 66-68 27 68-70 8 The following table gives the moisture content in 100 test samples of a particular cement mix after a certain time interval. % moisture content Number of samples 3. 62-64 18 20-25 5 25-30 17 30-35 52 35-40 18 40-45 7 45-50 1 This table gives the diameters (in mm) of a sample of washers produced by a machine. Diameter x 10.0-10.4 10.5-10.9 11.0-11.4 11.5-11.9 12.0-12.4 12.5-12.9 No. of items f 4 15 27 56 75 53 4. Here is the data for the daily output of three machines over a period of one year. Illustrate each with a box plot and make some relevant comments about the machines’ performance. Each machine is supposed to produce 500 components per day. Machine A Daily output (units) 480-490 490-500 500-510 510-520 520-530 Total days 44 No. of days (f) 15 28 142 97 83 365 Machine B Daily output (units) 470-480 480-490 490-500 500-510 510-520 520-530 530-540 Total days OUTCOME 3: NUMERACY/HIGHER No. of days (f) 17 28 63 105 87 35 30 365 Machine C Daily output (units) 490-495 495-500 500-505 505-510 Total days No. of days (f) 30 203 126 6 365 MEDIAN AND QUARTILES Answers ?2.1: Answers 1. 11 11 13 15 15 16 16 16 16 16 16 17 18 19 20 V V V Q1 = £15 per hour, Q2 = £16 per hour, Q 3 = £17 per hour, SIQR = £1 per hour 2. 120 122 123 125 125 125 126 127 128 129 130 131 V V V Q1 = 124 minutes, Q 2 = 125.5 minutes, Q3 = 128.5 minutes, SIQR = 2.25 minutes 3. 1.8 1.9 2.0 2.1 2.3 2.3 2.4 2.5 2.5 2.5 2.5 2.7 2.7 V V V Q1 = 2.05 cm, Q2 = 2.4 cm , Q3 = 2.5 cm , SIQR = 0.225 cm ?2.2: Answers 1. 1× 30 = 7.5, Rank = 7 + 1 = 8 4 2 × 30 Q2 : = 15, Rank is 15.5 4 3 × 30 Q3 : = 22.5, Rank = 22 + 1 = 23 4 Ranks: Q1: x 0 1 2 3 4 7 9 10 11 f 5 2 3 7 4 3 2 1 3 c.f. 5 7 10 17 21 24 26 27 30 pass 8 here pass 15.5 here pass 23 here Q1 = 2 faulty items, Q 2 = 3 faulty, Q3 = 7 faulty, SIQR = 2.5 faulty items OUTCOME 3: NUMERACY/HIGHER 45 MEDIAN AND QUARTILES 2. Ranks are Q1: 19, Q2: 38, Q3: 57 Q1 = 1 incident, Q2 = 2 incidents, Q3 = 3 incidents, SIQR = 1 incident 3. Ranks are Q1: 25, Q 2: 49, Q3: 73 Q1 = 1 person in car, Q2 = 2 people, Q3 = 3 people, SIQR = 1 person 4. Ranks are Q1: 189.5, Q2: 378.5, Q3: 567.5 Q1 = 73.3 mm, Q 2 = 73.4 mm, Q 3 = 73.5 mm, SIQR = 0.1 mm (Note: In question 4, all the ‘point 5s’ in the ranks made no difference, but they might have.) ?2.3: Answers 1. 1×100 = 25 4 2 ×100 Q2 : = 50 4 3 ×100 Q3 : = 75 4 Q1: Q1 Q2 Q3 x 60-62 62-64 64-66 66-68 68-70 f 5 18 42 27 8 c.f. 5 23 65 92 100 pass 25 here pass 50 here pass 75 here 25 – 23 × 2 = 64.10kg 42 50 – 23 Q2 = 64 + × 2 = 65.29kg = median 42 75 – 65 Q3 = 66 + × 2 = 66.74kg 27 1 SIQR = (66.74 – 64.10) = 1.32kg 2 Q1 = 64 + 60 61 62 63 64 65 66 67 68 69 70 The whiskers have to go out to 60 and 70 (strictly 69.99999) because, for all you know, 60kg could be the lowest weight and 70kg could be the highest. If you actually know what the lowest and highest weights are, you only take the whiskers out that far. 46 OUTCOME 3: NUMERACY/HIGHER MEDIAN AND QUARTILES 2. 3. 4. 25 – 22 × 5 = 30.3% 52 50 – 22 × 5 = 32.7% Q 2 = 30 + 52 75 – 74 × 5 = 35.3% Q3 = 35 + 18 1 SIQR = (35.3 – 30.3) = 2.5% 2 Q1 = 30 + 57.5 – 46 × 0.5 = 11.55mm 56 115 –102 Q2 = 11.95 + × 0.5 = 12.04mm 75 172.5 –102 Q3 = 11.95 + × 0.5 = 12.42mm 75 1 SIQR = (12.42 – 11.55) = 0.44mm 2 Q1 = 11.45 + Machine A: Q1 = 503.4 units, Q2 = 509.8 units, Q3 = 519.1 units Machine B: Q1 = 498.9 units, Q2 = 508.0 units, Q3 = 517.0 units Machine C: Q1 = 496.5 units, Q2 = 498.8 units, Q3 = 501.6 units the numbers don’t mean much until you see the box plot: 470 480 490 500 510 520 530 540 A B C OUTCOME 3: NUMERACY/HIGHER 47 48 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE SECTION 3 A formula is a rule, usually written using mathematical symbols, which shows how two or more variables are related. Some formulae are explicit, i.e. they spell the relation out with no ambiguity. For example, A = lb is the formula for the area of a rectangle. It tells you clearly that if you know the length (l) and the breadth (b) you have to multiply them together to get the area. Other formulae are implicit, i.e. they imply the relationship without spelling it out. For example NA n = B NB nA is a formula which relates the rotational speed (N) and the number of teeth (n) for two interlocked gear wheels A and B. When we transpose (or change the subject of) a formula we rearrange it so that a different variable is on its own on one side of the formula. That variable becomes the subject of the formula. So if we know the area and the length of a rectangle, the formula which gives us the breadth is b= A l and if we want to know the number of teeth for gear wheel B, given that we know everything else, the formula for that is nA = NB nB NA Transposition as a technique is one of the most important skills used in mathematics (and also physics, electronics and engineering and …). It may look complicated, but is helped by the fact that, in mathematics, the rules are always consistent. Two things to remember: • You can frequently think of the letters in the formula as numbers. What is normally true for ordinary numbers will be true for letters as well. • When you are transposing a formula you follow the rules of equations: whatever you do to one side of the equation you do at the same time to the other side. OUTCOME 3: NUMERACY/HIGHER 49 TRANSPOSITION OF FORMULAE 3.1 Writing Formulae Using Numbers Multiplication and division are inverse operations. This means that each one is the opposite of the other. Whatever one does, the other undoes. This means that any multiplication can be rewritten as a division and vice versa. Thus the multiplication 5 × 2 = 10 can be rewritten as 5 = 10 10 and also as 2 = 2 5 Similarly, the multiplication 3 × 4 = 12 can be rearranged as 3 = 12 12 or 4 = . 4 3 48 6 can be rewritten as the product (multiplication) 6 × 8 = 48. We don’t bother offering an alternative 8 × 6 = 48 because everyone knows that it doesn’t matter which number goes first with multiplication , the answers will be the same. If we start off with a division, we can rearrange it to form a multiplication. Thus 8 = In the language of mathematics we say that multiplication is commutative. Do you think division is commutative? (Answer is on page 80.) In the same way, addition and subtraction are inverse operations. Each one can be rearranged as the other. Whatever one does, the other does the opposite. Thus we can rearrange the sum 5 + 2 = 7 as the difference 7 – 2 = 5 or as 7 – 5 = 2. Similarly the difference 10 – 6 = 4 can be rewritten as the sum 10 = 6 + 4. Again, we wouldn’t offer 4 + 6 = 10 as an alternative because addition is also commutative, i.e. it doesn’t matter in what order you add two numbers, the answer will be the same. Do you think subtraction is commutative? ? 3.1 Rewrite each product as a quotient (division) and vice versa. Rewrite each sum as a difference and vice versa. 1. 4. 7. 2+3=5 15 3 8 = 12 – 4 5= 2. 5 × 7 = 35 3. 5. 12 = 10 + 2 6. 8. 18 = 3 × 6 9. 8–7=1 21 =3 7 5=7–2 It should be clear that adding and subtracting form one pair of inverse operations, and multiplying and dividing form another pair. You can’t jump between pairs. For example, subtraction won’t undo a division, and multiplication is not the opposite of addition. 50 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE This is most important in what follows. 3.2 Relating Letters to Numbers – Adding and Subtracting Here is a true statement, 2 + 5 = 7, which we can rewrite either as 5 = 7 – 2 or as 2 = 7 – 5. Now we do the same with letters: a + b = c which we can rewrite either as b = c – a or as a = c – b. Can you see how the equations with the letters are exactly the same as the ones written above with numbers, if you replace 2 by a, 5 by b and 7 by c each time? Here we have a similar situation, first with numbers and then with letters replacing the numbers: 7–3=4 7=4+3 with the alternative p–q=r where p replaces 7, q replaces 3 and r replaces 4. p=r+q ? 3.2 Fill in the blanks in these equations, using the example on the left to help you. 1. 8 + 2 = 10 k+t=s (a) 8 = 10 – 2 k = .... – .... (b) 2 = 10 – 8 .... = .... – .... 2. 4–3=1 m–r=u (a) 4 = .... + .... .... = .... + .... (b) 3 = .... – .... .... = .... – .... 3. 8–5=3 t–k=w (a) 8 = ............ t = ............ (b) 5 = ............ k = ............ See if you can do the next questions using only letters or a mixture of numbers and letters. (Having a mixture does not affect what you do in any way.) By all means imagine numbers to be there if you need them, but don’t write any numbers down. 4. (a) t+u=h t = .... – .... (b) m–v=k m = .... + .... (c) f–x=w f = .... + .... 5. (a) q–r=p q = .... + .... (b) s+t=8 t = .... – .... (c) x+4=y x = .... – .... OUTCOME 3: NUMERACY/HIGHER 51 TRANSPOSITION OF FORMULAE 3.3 Solving Equations Involving only Addition and Subtraction We will now apply what we have learned so far to solve some very simple equations, ones in which you can spot the answer. We will use special techniques which will seem unnecessary for such simple problems. However, you have to learn the techniques, because you won’t be able to spot the answer to the more difficult equations you’ll meet later. Suppose we want to solve the equation x + 2 = 5. This means we want to find the value of x which makes the statement true. Obviously the solution is x = 3 because when you replace the letter x by the number 3 you get 3 + 2 = 5, which is true. Now we will use a procedure to do this. The aim in the solution of any equation (or the transposition of any formula) is to isolate the variable in which you are interested. As far as our equation is concerned, we have to get x on its own on one side of the equation. This means getting rid of the 2 on the left. But the 2 is being added to the x, so we get rid of it by using the inverse operation to addition. We subtract 2 from the left-hand side (LHS) of the equation. But for the equals sign to mean what it says (‘is the same as’) we have to do the same to the other side, the right-hand side (RHS) of the equation. This is to satisfy the rule: whatever you do to one side of the equation you must do to the other. The working looks like this: x+2 = 5 x+2–2 = 5–2 x = 3 V x is left on its own because +2–2=0 Now let’s have a look at another simple example: x – 4 = 8, the solution to which is x = 12 because 12 is the number which, when it replaces x in the equation, makes it true: 12 – 4 = 8. Again, we want to isolate x, which involves getting rid of the 4 on the LHS. Since the 4 is being subtracted, we eliminate it by adding 4 to the LHS, which means we have to add 4 to the RHS. The working looks like this: 52 x–4 =8 x–4+4 =8+4 x = 12 V x is left on its own because – –4 + 4 = 0 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE Let’s try one more easy example where you can spot the answer: 12 – a = 7 to which the answer is a = 5 because 12 – 5 = 7. There is a slight problem here because of the ‘minus’ sign in front of the a. Although this may seem complicated to you, the easiest way (in the long run) to deal with this is to add a to each side, and subtract 7 from each side (do these two operations in the same line of the solution). Watch what happens: –a + a gives 0 =7 =7+a–7 =a =a V V 12 – a 12 – a + a – 7 12 – 7 5 7–7 gives 0 the last line of which can be reversed to read a=5 Remember that the aim is to get the variable on its own, on one side of the equation (and it doesn’t matter which side), and positive. ? 3.3 Try to solve these equations in the same way. 1. 4. x+7=8 9–k=4 2. 5. y –4=9 7 + t = 10 3. 6. z+2=6 m – 12 = 17 3.4 The ‘Change Side, Change Sign’ Rule This adding or subtracting from each side is all very well, but it can be tedious if there is a lot of it to be done. So let’s see if there is a short cut which we can apply. Look at one of the previous examples: x+2 =5 x+2–2 =5–2 x =3 If we take away the bit which gives us zero we are left with x+2 =5 x =5–2 x =3 It looks as if the +2 has disappeared from the LHS and reappeared as a –2 on the RHS. OUTCOME 3: NUMERACY/HIGHER 53 TRANSPOSITION OF FORMULAE Let’s look at another one from before x–4 =8 x–4+4 =8+4 x = 12 Again, remove the bit which gives zero: x–4 =8 x =8+4 x = 12 It looks as if the –4 has moved across from the LHS and appeared as a +4 on the RHS. This rule, whereby it appears that if you move something from one side to the other you change its sign as you go, is incredibly useful and we will apply it from now on. It works only because we are adding equal quantities to, or subtracting equal quantities from, each side of the equation, as you have already seen. It’s not magic. More important, it applies ONLY to + and – signs. Here’s a more complicated example: 3x – 5 = 2x + 4 To achieve our aim, we subtract 2x from each side and add 5 to each side: 3x – 5 – 2x + 5 = 2x + 4 – 2x + 5 Remember the Aim To get the variable x on one side of the equation, and positive; and to get the numbers on the other side. If we now do away with all the stuff that becomes zero on each side of the equation we get 3x – 2x = 4 + 5 and this finally resolves itself x=9 Here’s a fully worked example: 54 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE Example 3.4 Solve the equation 5x – 7 = 6x – 3 Solution: We notice first that if we move the 6x to the left we will have 5x – 6x which will be negative. – 7 + 3 = 6x – 5x V This 7 has a – sign glued to the front of it. V V V So move the x terms to the right, and the numbers to the left: It is staying on the LHS. So the – sign stays with it! This +3 has flown in from the RHS. So its sign has changed from –3 on the right to +3 on the left. This 6x was on the RHS and is staying on the RHS so its sign does not change. This 5x had been at the start of the LHS, so it was assumed positive. It has flown over to the RHS, so has changed its sign and appeared as a –5x We end up with – 4 = x or, reversed, x = – 4 You could not have guessed that one from the start! For practice, you can try some straightforward numerical examples. For instance, here is a true statement: 5 + 2 – 7 + 3 = 6 – 8 + 9 – 4 (each side is worth 3) Rearrange so that the even numbers are on the left and the odd numbers are on the right: 2 – 6 + 8 + 4 = 9 + 7 – 5 – 3 (each side is now worth 8, so the equals sign still works!) And the same thing can be done with letters: a – x + y – b = c + z – d – w. Rearrange this so that the a, b, c, d are on the left and the w, x, y, z are on the right. A possible answer is a – b – c + d = z – w – y + x. There are dozens of variations, such as a + d – c – b = x – w + z – y for instance. OUTCOME 3: NUMERACY/HIGHER 55 TRANSPOSITION OF FORMULAE This will happen throughout this section. So long as each variable or number has its correct symbol stuck in front of it, it can take up any position in the line-up and still be correct. So please expect legitimate variations in the answers at the back. ? 3.4 1. Rearrange these as required: (a) (b) (c) (d) 2. Solve these equations. (a) (c) (e) 3. 2 + 3 – 4 = 7 – 12 + 6 so that the even numbers are on the left, odd on the right 2 + 6 – 8 = – 4 + 7 – 3 so the odds are to the left, evens to the right A – b + c = P + Q – r so that the capital letters are to the left, lower case to the right – X + y – z = W – T + t as for (c) above 5x + 4 = 4x + 7 7k + 2 = 6k – 4 7 – 3m = 2 – 4m (b) (d) (f) 3y – 7 = 2y + 4 9 + 2t = t – 7 9w + 3 = 8w –11 Rearrange each of these so that the x is positive on one side of the equation, and everything else, numbers or letters – it doesn’t matter, is on the other side. (a) (c) (e) x+a=5–p w=y–2–x 2x – a = x + b (b) (c) (d) x+3–a=w+p y = 10 + x k=2+x–a CONGRATULATIONS! You’ve just transposed your first formulae without even realising it! 56 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE 3.5 Transposing Formulae with only + and – Signs In a simple formula such as a = b – c we say that a is the subject of the formula, because it is isolated (on its own) on one side of the equation, with everything else on the other side. To change the subject of the formula, or transpose the formula, we rearrange the equation so that a different letter is on its own. Suppose we want to change the subject of the formula above to b. This means we want b on its own. Since b is positive on the RHS we keep it there and move the c over to the left. Like this: The b stays on the RHS because it is positive here. V a=b–c a+c=b b=a+c V The –c has moved from RHS to LHS so it has changed its sign to +. V V This line is really optional – it tidies the solution up so that the new subject is on the left. When you completely swap sides like this there are no sign changes. Signs only change when some things move and other things stay. Notice how the equals signs are all lined up neatly one under the other. This is very important. It is much easier to clearly see which side is the left and which side is the right. Suppose now we want to take the original formula and transpose it to c. This means making c the new subject. Here is the solution: V When c was on the RHS it had a – sign in front of it. Moving it to the LHS changes its sign to a +. Because it is at the start of the line we don’t write the + sign in, we understand it to be there. V a=b–c c=b–a The a was positive on the LHS. There was no + sign in front of it but we understood it to be there. We have to move it right so that c can be isolated on the left. Moving a to the RHS changed its sign to a –. Here are three more examples. Try to follow them without any explanations: p = q + r, change to r p–q =r r =p–q s = u – v, change to u s+v =u u =s+v w = a – k, change to k k=a–w OUTCOME 3: NUMERACY/HIGHER 57 TRANSPOSITION OF FORMULAE ? 3.5 Transpose each of these formulae as required: 1. 3. 5. p=q+r m=q–t s=x–r–8 to q to q to r 2. 4. 6. p=q+r m=q–t s=x–r–8 to r to t to x 3.6 Relating Letters to Numbers – Multiplying and Dividing We will now repeat for × and ÷ what we did for + and – on page 51. Here is a true statement, 5 × 2 = 10, which can be rewritten as a division 5 = 10 10 or 2 = . 2 5 c c or b = . b a As you see, the pattern is the same, where a replaces 5, b replaces 2 and c replaces 10. Using letters: a × b = c, which can be rewritten as a division a = Here’s another example. We start with a division, which can be rewritten as a multiplication and then a different division: 12 12 which rearranges to 12 = 4 × 3 and then 3 = . 3 4 Replacing 4 by p, 12 by r and 3 by s we get 4= p= r r which rearranges to r = p × s and then s = . s p ? 3.6 Fill in the blanks in these equations, using the example to help you. 1. 5 × 3 = 15 (a) a×b=c 2. 6 × 2 = 12 (a) r×w=k 3. 58 7= 21 3 h= x t (a) 5= 15 3 a= ⋅⋅⋅⋅ ⋅⋅⋅⋅ 6= 12 2 r= ⋅⋅⋅⋅ ⋅⋅⋅⋅ 21 = 7 × 3 x = .... × .... OUTCOME 3: NUMERACY/HIGHER (b) (b) (b) 3= 15 5 b= ⋅⋅⋅⋅ ⋅⋅⋅⋅ 2= 12 6 w= ⋅⋅⋅⋅ ⋅⋅⋅⋅ 3= 21 7 t= ⋅⋅⋅⋅ ⋅⋅⋅⋅ TRANSPOSITION OF FORMULAE See if you can do these without any help. 4. (a) p×q=b (b) p= 5. j= (a) t= m f (c) m= t 8 (b) t= b=r×q q= g=y×a a= (c) 7= r x r= 3.7 Solving Equations Involving only Multiplication and Division In the previous section you saw how subtracting undid an addition and vice versa, because adding and subtracting are inverse operations. This next section involves only multiplication and division. I hope you remember that each is the inverse operation of the other. So to undo a multiplication we will be dividing. And vice versa. First of all, some algebraic conventions. Convention 1: Unless it will lead to confusion, all multiplication signs will be omitted. Thus ab means a × b and pqr means p × q × r. Convention 2: Since multiplication is commutative, the order of variables does not matter, although alphabetical order is preferable. Thus bca is the same as cab but abc is best of all. Convention 3: If a number is involved in multiplying, it always comes first. Thus you write 4x and not x4 to mean ‘4 times x’. Convention 4: In addition/subtraction, you can only simplify like terms, or terms which look alike. For instance, 3x + 2x = 5x because 3x and 2x are both the same sort of term, but terms like 3x + 2y or 3x – 2 cannot be simplified any further. With multiplying, however, you can simplify virtually anything. Thus 3x × 2y = 6xy and 3x × 2 × 5z = 30xz and so on. Now let’s solve some equations. 2x = 8 The x is being multiplied by 2. We want to isolate x, i.e. make it on its own. To do this we have to separate the 2 from the × x. The only way to do this is to use the inverse operation, i.e. division. OUTCOME 3: NUMERACY/HIGHER 59 TRANSPOSITION OF FORMULAE So we divide each side by 2: 2x 8 = 2 2 On the LHS the 2s cancel out top and bottom, leaving x. On the RHS we divide 8 by 2 to give the answer 4. When we say that we CANCEL a number top and bottom, we are dividing the numerator and the denominator BOTH by the same number (in this case by 2) so that the expression looks different but is still worth the same. x=4 In practice we do the LHS of the middle line in our heads, and the solution as written out looks like this: 2x = 8 8 2 x=4 x= Quite easy, really: easier than moving terms from left to right and so on. Here’s another example: 3a = 7 To separate the 3 from the a we have to use the inverse operation which will unstick the glue which holds them together. They are stuck together with multiplication, to which the inverse operation is division. So divide each side by 3. This will isolate the a, which is what we’re after. 3a 7 = 3 3 60 OUTCOME 3: NUMERACY/HIGHER 7 3 V a= V V The 3s cancel out top and bottom, leaving you with the a only. In practice we do this line mentally, and go straight on to the last line. We could turn this into a decimal if we want, but mathematical convention is to leave it as an exact fraction. TRANSPOSITION OF FORMULAE Example 3.7a Transpose the formula A = BC to B. Numerical equivalent Solution: We could start by reversing the entire formula so that the BC is on the left. BC = A 12 = 3 × 4 3 × 4 = 12 4= We want to isolate B. B is being multiplied by C. So divide each side by C: B= 12 3 A C Example 3.7b Transpose the formula P = 3QRS to R. Solution: Don’t be put off by the extra number and letters. The method is exactly the same as before. We want to isolate Q. Q is being multiplied by 3RS (it doesn’t matter that the Q is in the middle. It could have been at the start or at the end). So divide each side by the 3RS. We can reverse the equation either at the start or at the end. P = 3QRS P = 3QRS 3QRS = P R= or P 3QS Numerical equivalent P =R 3QS R= 120 = 3 × 2 × 4 × 5 120 4= 3 × 2 ×5 P 3QS ? 3.7 Transpose these formulae as required: 1. 4. s = 7k t = km to k to m 2. 5. m = 9t B = 4hg to t to g 3. 6. C = πd A = 5bmx to d to m OUTCOME 3: NUMERACY/HIGHER 61 TRANSPOSITION OF FORMULAE 3.8 Equations with Fractions The first, and only, rule about fractions is get rid of them. Fast. This is so that your equation is a ‘one liner’, i.e. all written on one line, because it is then more easily dealt with. Let’s go back to a numerical example 5= 20 4 Although this means ‘5 equals 20 divided by 4’ it can also mean ‘a fraction equivalent of 5 is 20 over 4’. Since the 20 and the 4 are glued together by division, we can unglue them by using the inverse operation of division. We can multiply both sides by the denominator of the fraction (the number on the bottom). 4 × 5=4 × 20 4 On the right-hand side of this the 4s cancel out top and bottom, and we are left with 4 × 5 = 20 which I’m sure you knew anyway (as far back as page 50). But it’s the technique that’s important. Example 3.8a Transpose the formula P = m to m. 8 Solution: You multiply both sides by 8. 62 V This reversal is optional, but it does make the solution look a lot better! V V m 8 × P=8 × 8 V 8P = m m = 8P OUTCOME 3: NUMERACY/HIGHER In practice you can do this line mentally, without actually writing it down, although it might help to write it for now. 8 cancels out top and bottom on the RHS. TRANSPOSITION OF FORMULAE Example 3.8b From here on, read comments in boxes in their numerical order. 3y Transpose the formula X = to y. 2wz Solution: This looks difficult, but it is only one step longer than the last example. 2. The 2wz cancels top and bottom on the RHS. V 2wzX = 3y 3y = 2wzx 2wzX y= 3 V 3. Reverse equation (i.e. swap sides about) to make it look good. 3y 2wz 2wz × X = 2wz × V V 4. Divide each side by 3 to isolate the y. Transposition complete. V 1. Multiply each side by the denominator. For the last example in this section we’ll take the same formula as before, but change the new subject. Example 3.8c Transpose the formula X = 3y to w. 2wz Solution: The first step is to get rid of the fraction as before. In (almost) every formula which has fractions in it, the very first step is always to get rid of the fraction. It doesn’t matter what the subject of the formula is to be. 2wz × X = 2wz × w= V 2wzX = 3y 3y 2wz 3y 2Xz V 1. The first two lines are EXACTLY the same as before. It doesn’t matter if we write 2Xz or 2zX on the bottom line. 2. Note that we don’t need to reverse the equation because the required w is on the left already. 3. To isolate w we divide each side by whatever is multiplying w. We divide each side by 2zX. It does matter, however, if you write a lower case x instead of the capital X which is in the formula. In a particular context, lower case and capital letters may represent different variables, so you have to write the letters as they are. ? 3.8 Transpose these as required: 1. w= P 4 to p 2. X= 2r S to r 3. m= ab cd 4. T= 2π to t 5t 5. k= 3abc 4pqr to a 6. k= 3abc 4pqr to q to a OUTCOME 3: NUMERACY/HIGHER 63 TRANSPOSITION OF FORMULAE 3.9 Cross Multiplication Cross multiplication is an incredibly useful component of your transposition toolkit, used in situations where the formula or equation is in the form FRACTION = FRACTION In fact, we have been sort of cross multiplying in the last section. How does it work? Let’s first look at a numerical example. If you multiply both the numerator AND the denominator of a fraction by the SAME number, you get an equivalent fraction; the two fractions look different but they are both worth the same. For example, if you multiply the numerator and denominator of the fraction ½ by 3, you get 1 3 = 2 6 Now watch this: 1×6=2×3 which is perfectly true: both sides are equal to 6. Here are a few more examples for you to think about: 3 6 = 4 8 3 × 8=6 × 4 5 20 = 4 16 5 × 16 = 20 × 4 2 20 = 7 70 70 × 2 = 7 × 20 If an equation is written in the form A C = B D then we can cross multiply and arrive at the one liner A×D=B×C Of course we would write this without the times signs, AD=BC, and it could be written in many other ways, depending on convenience: DA = CB or BC = DA and a few others. Cross multiplication is just a convenient shortcut. You could transpose this formula by multiplying both sides; it would just take longer: 64 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE V LHS: B cancels out top and bottom. A C = B D A C = BD × BD × B D DA = BC V Multiply both sides by the product of the denominators, i.e. by B times D RHS: D cancels out top and bottom. Any of the four variables can now become the new subject with one quick division. Example 3.9a Solve the equation Have you figured out why it’s called ‘cross multiplication’? 5 2 = x 3 V x= Solve for x: V 15 = 7 12 or 7.5 2 V 2x = 5 × 3 V Solution: Cross multiply: A C = B D A C = B D A × D=B × C Example 3.9b Transpose the formula p 2π = to make t the subject. q t Solution: Cross multiply: pt = 2πq t = Solve for t: 2πq p Example 3.9c Transpose the formula X = 3Y to make Z the subject. 5wZ Solution: Put the X ‘over 1’ to make the LHS look like a fraction. You can do this with any letter or 3 12 a 5t ; 12 = ; a = ; 5t = ; and so on. 1 1 1 1 V You would do this first step no matter what transposition you intended to make. X 3Y = 1 5wZ 5wZX = 3Y × 1 Z= 3Y 5wX V number: 3 = You wouldn’t actually write 3Y × 1 because you know that the answer will be 3Y, since anything times 1 is itself. I’ve written it here so you can see what’s happening. OUTCOME 3: NUMERACY/HIGHER 65 TRANSPOSITION OF FORMULAE ? 3.9 Transpose these formulae as required. aC 360 1. A= 4. NA n = B NB nA to a 2. A 7 = w p to w 3. A 7 = w p to p to nA 5. A= BC D to B 6. A= q pr to r 3.10 Formulae Involving all Operations This is crunch time: time to put everything together. If you’ve managed up until now, one more small step and you’re there. It’s sometimes difficult to give rules which will cover every eventuality, but as a rule of thumb, for the formulae you can cope with so far: 1. Get rid of fractions either by multiplying both sides by the denominator (if there is only one), or by multiplying both sides by the lowest common multiple of the denominators, often the product (if there is more than one). 2. Move terms around from side to side so as to isolate on one side the term involving the variable you want (where it is positive) and have all the other terms on the other side. This involves changing side/sign if there are + and – signs involved. 3. Finally, isolate the variable you want, probably by division. Example 3.10a Transpose a = bc – d to d. Solution: V 3. d was negative on the RHS, has moved left, so has become positive. a = bc – d 1. The proposed subject, d, is negative on the RHS, so move it to the other, changing sign as you go. d = bc – a 4. a was positive on the LHS, has moved right, so has become negative. V 2. If d comes over from the left, it will join the a, but you want d isolated. So move the a over to the right, changing sign as you go. V 5. bc has stayed on the RHS, it has NOT moved, so does NOT change. 66 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE The transposition is complete. Without all the comments, the problem looks like this: a = bc – d d = bc – a Example 3.10b Transpose a = bc + d to d. Solution: 2. But if you leave d on the RHS it will not be isolated, so move the bc to the left, changing its sign as you do so. a = bc + d 1. The proposed new subject, d, is positive on the RHS so LEAVE IT HERE, do not move it. Leaving it thus will NOT change its sign. (Signs only change when things move.) a – bc = d Finally, reverse the formula: d = a – bc The completed problem, without comments, but with all the = signs neatly one under the other: a = bc + d a – bc = d d = a – bc Example 3.10c Transpose a = bc + d to b. Solution: V 2. If you have decided to isolated bc on the RHS, then the d must come over to the LHS. Because it has moved, it has changed sign. a = bc + d V V 3. a has not moved, so its sign does not change. a – d = bc V a–d =b c V 5. Finally, reverse the fomula to make it look good. 1. You want b, which is glued together with c by multiplication. You MUST unglue + and – BEFORE ungluing x. Since bc is positive on the RHS leave it here, without changing its sign. You are thus isolating the term which involves the variable you want. b= a–d c 4. Having isolated bc, you now isolate b. Unglue it from c by dividing both sides by c. Transposition complete. OUTCOME 3: NUMERACY/HIGHER 67 TRANSPOSITION OF FORMULAE Example 3.10d Transpose a = b – cd to d. Solution: a = b – cd ○ V ○ V ○ 1. As usual, isolate the term involving the variable you want. This means get the cd term on its own to the side which makes it positive. Since it is negative on the RHS move it left to make it positive. V ○ ○ V ○ ○ cd = b – a ○ 2. As cd moves left it joins a which is already there. But you don’t want it there because you want the cd to be alone. So move the a to the RHS, changing its sign from + to – as you go. d= b–a c V 3. Finally, divide both sides by c to isolate d. The c’s cancel out top and bottom on the LHS so don’t write them there. But do write c on the RHS. Transposition complete. ? 3.10 Transpose the following as required. 1. 4. p = q – rs s = ap – 3nq to q to a 2. 5. k = 3t + ah T = 4r – abcd to h to c 3. 6. x = 2y + 3bc K = π – pqr to b to q 3.11 Coping with Brackets A bracket is yet another layer of ‘glue’ to be unstuck when solving an equation or transposing a formula. The general rule is: • get rid of any fractions outside the brackets first then • multiply out the brackets then • get rid of any fractions which are inside the brackets then • do any moving terms about from one side to the other. If various terms are inside a bracket, you cannot get at them individually until after you have multiplied the bracket out. Using another analogy: Stuff inside a bracket is like money in your pocket. You can’t see how much you’ve got until it’s out of the pocket and on the table. When multiplying out brackets, remember that everything inside the bracket gets multiplied by whatever is immediately outside. If it is a negative number that’s outside, then the signs inside will change as you go. 68 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE Reminders: Watch the sign changes in the last two examples. 2(x + 3) 3(a – 2b + 5) x(x + y) 3m(2m + 5n – 3) –4(2x – 3z + 1) –3a(1 – 2a + 3a2 – 4b) = = = = = = 2x + 6 3a – 6b + 15 x2 + xy 6m 2 + 15mn –9m –8x + 12z – 4 –3a + 6a2 – 9a3 + 12ab Multiplying by a negative number always changes the sign, because Negative × Positive = Negative and Negative × Negative = Positive Example 3.11a Transpose x = y(a + b) to y. Solution: Just to confuse you, we’ll start off this section without multiplying out brackets! Since we want y isolated, and y is being multiplied by the single term (a + b), simply divide both sides by the bracket (a + b) like this: x y(a + b) = and the (a + b) will cancel out top and bottom on the RHS leaving you (a + b) (a + b) with x x = y which can be reversed to give you y = (a + b) (a + b) Example 3.11b Transpose x = y(a + b) to a. The a we want is inside the bracket. A rule of thumb (which you can break when you become proficient at all of this, but not yet) is that you must multiply out any bracket to be able to access individually the terms inside it. x = y (a + b) x – yb = ya V 3. Reverse V x = ya + yb 2. Move yb to the LHS to isolate the positive ya on the right. V V 1. Multiply out the bracket. 4. Divide both sides by y to isolate a as required. ya = x – yb a= x – yb y OUTCOME 3: NUMERACY/HIGHER 69 TRANSPOSITION OF FORMULAE Example 3.11c Transpose a = b(3x – 5y) to y. Solution: See if you can follow this without any further explanation. a = b(3x – 5y ) a = 3bx – 5by 5by = 3bx – a 3bx – a y= 5b Example 3.11d Transpose a = x to b. a–b Solution: a x = 1 (a – b) a(a – b) = x 1. Note that I have added a pair of brackets round the a – b. This is MOST IMPORTANT and will avoid mistakes later. 2. Cross multiply as usual. Remember that x times 1 equals x. a2 – x = ab b= a2 – x a V a2 – ab = x 4. Isolate the term involving b. V V 3. Multiply out the bracket. Having put the bracket in ensures that this step is done correctly. (A very common mistake is to get the a 2 correct but then write –b, having forgotton to multiply it by a as well.) V a to achieve ‘fraction = fraction’ format 1 V The easiest way is to rewrite the LHS as 5. Continue as usual. I have combined the ‘isolating’ step and the ‘reversing’ step into one line. Example 3.11e Change the subject of the formula x = p+q to p. p–q Solution: Start as before: put brackets round the p + q and also the p – q , write the x as ‘x over 1’, then cross multiply: x (p + q ) = 1 (p – q ) x (p – q ) = 1(p + q ) 70 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE Since the required p is inside a bracket and, what’s worse, on both sides of the equation as well, we have no choice but to multiply out both brackets: 1. Move the terms involving the required p to one side of the equation... 2. ...and the other terms to the other side V xp – p = q + xq V xp – xq = p + q We now have two terms involving the required p but we only want to have one term. If x was a number it would have been easy: 5p – p = 4p; 9p – p = 8p and so on. But we don’t have that, we have xp – p. We cope with the problem by taking out p as a common factor: q(1 + x ) p= (x – 1) p= V q + xq (x – 1) q(x + 1) (x – 1) V V V 4. To isolate p, divide both sides by whatever is multiplying it, in this case the entire (x – 1) bracket. p= V p(x – 1) = q + xq 3. Remember that px is exactly the same as xp. 5. This line is actually OK as an answer... 6. ...but it looks better if you notice that taking out q as a factor on the top line is a possibility... 7. ...and changing the order of the top bracket to make it look similar to the bottom one is the icing on the cake! To be fair, that was quite a stinker of a transposition. Here is another one but, if you followed the last one without difficulty, omit this next one and move on. Example 3.11f Make r the subject of the formula E = R + nr . R – nr 2. Put the numerator and the denominator of the fraction each into a bracket as a safety precaution. E(R – nr ) = 1(R + nr ) ER – Enr = R + nr V ER – R = nr + Enr ER – R = r (n + En) V V 4. Now a slight problem. If you put the terms involving the required r to the left, you get too many minus signs, which make handling the equation difficult... E (R + nr ) = 1 (R – nr ) 5. ...so move the terms involving r to the RHS instead... V V 3. Cross multiply, then multiply out the brackets as before. V 1. Write ‘E over 1’ to put the equation into ‘fraction = fraction’ form to make cross multiplication possible. V V Solution: 6. ...then take out r as a common factor. OUTCOME 3: NUMERACY/HIGHER 71 TRANSPOSITION OF FORMULAE Now divide both sides by the bracket which is multiplying r to get r on its own, and reverse the entire equation: r= r= (ER – R ) (n + En) R(E – 1) n(E + 1) 8. And a final cosmetic embellishment to make it look as if you really know what you’re doing! V V 7. Put a bracket round the numerator. This stops you making silly mistakes like cancelling out the Es, for example. But what happens if you can’t just put one side ‘over 1’ and cross multiply? Well, you just go back to multiplying each side by something which will get rid of all the fractions at one go: Example 3.11g Rearrange the formula R = k 3k + to make k the subject. 2x x +1 Solution: The trick is to multiply both sides by the lowest common denominator of all the fractions. In this case, it’s 2x times (x + 1). To avoid possible mistakes, put a bracket round the entire RHS. 3k k 2x ( x + 1) R = 2x ( x + 1) + 2x x +1 Now multiply out the RHS. You can leave the LHS as it is. 2x ( x + 1) R = 2x ( x + 1) V k 3k + 2x ( x + 1) 2x x +1 V V V Cancel out the entire (x + 1) bracket top and bottom. Cancel out the 2x top and bottom. and you are left with V V 2x ( x + 1) R = 2xk + ( x + 1) 3k 2x (x + 1)R = k (2x + 3x + 3) V 2x (x + 1)R = k (5x + 3) 72 OUTCOME 3: NUMERACY/HIGHER 2x (x + 1)R (5x + 3) V k= 1. Take out k as a common factor. You get k(2x + (x + 1)3) = k(2x + 3x + 3) 2. Divide each side by (5x + 3). Keeping it in a bracket means you avoid mistakes such as cancelling out x top and bottom, for instance. TRANSPOSITION OF FORMULAE And now, an exercise to practise on. ? 3.11 A quick word about cancelling. You can only cancel entire factors. The only reason that the fraction 6/8 cancels down to be ¾ is that you are dividing the top and the bottom by a factor of 2: Change the subject of each formula as required: 1. 2. T = 3(x –2y) P = t(3 + 5m) to (a) x to (a) t 3. a Y= + bc 2 4. t 2m X= – 3 5 5. 2w + 3 K= 7 6. H= 3(x – y ) x to (a) y (b) x 7. P= a + 2b a–b to (a) a (b) b 8. T= 3(x – 2y ) 2(x + 3y ) to (a) x (b) y to (a) a to (a) t (b) y (b) m 6 8 (b) b = 2×3 2×4 3 = 4 If we write the fraction as (b) m 6 8 = can’t cancel out the 5s and get to w 5 +1 5+3 1 3 you or anything else. Similarly, if you have a fraction like x + 3y 3 the 3 of the denominator is dividing into the WHOLE of the top line, not just a selected bit of it. So you can’t cancel out the 3s and get x + y or anything else. 2x + 6 can be simplified 2 ONLY because the top can be written as a product of two factors, one of which is 2, and we can then cancel out the 2’s like this: A fraction like We’re nearly at the end now: one last topic to look at. 2x + 6 2 = 2 × (x + 3) 2 = x +3 1 =x +3 3.12 Powers and Roots First of all, a power and the appropriate root are inverses of each other. This means that we can use one to unravel the other. For example, 3 to the power 2 (or 3 squared) is equal to 9. This means that 3 times 3 is 9. The power tells you how many times a number multiplies itself. The inverse of this is that the square root of 9 is 3. Written using symbols, we have 32 = 9 so 9 = 3 In the olden days, the square root was written like this: 2 9 = 3 but since the square root is the one most often used, we have become lazy and the 2 has been dropped. Here are some more examples: OUTCOME 3: NUMERACY/HIGHER 73 TRANSPOSITION OF FORMULAE 52 = 25 so 25 = 5 7 2 = 49 so 100 = 10 because 10 2 = 100 49 = 7 2.25 = 1.5 because 1.52 = 2.25 and we can do the same with symbols a 2 = b so a = b x 2 = y so x = t = w so t = w 2 y bc = d so bc = d 2 Believe it or not, we’re actually ‘doing the same to each side of the equation’ in these examples; in this case we are squaring each side. x= a Square each side (x) 2 = ( a) 2 x2 = a If you ‘square a square root’ like this, you effectively get access to whatever is under the root sign. Thus: ( t) = t ( 5b ) = 5b 2 2 ( 3x 2 y ) 2 = 3x 2 y and so on. There’s actually more to it than this, but that’s all you need to know here. The same applies to higher powers, for example: 23 = 8 (meaning 2 × 2 × 2 = 8) so 3 8 = 2 (read ‘the cube root of 8 is 2’) 54 = 625 (meaning 5 × 5 × 5 × 5 = 625) so 4 625 = 5 (read ‘the fourth root of 625 is 5’) But we will be sticking mainly to squares and square roots, with the occasional cube and cube root thrown in. Now for some more worked examples. 74 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE Example 3.12a Transpose a = x to t. 3t Solution: Start by squaring both sides. This will gain you access to everything under the root sign: x ( a ) = 3t x a2 = 3t 2 2 From now on it’s plain sailing, I hope: a2 x = 1 3t 3ta 2 = x t= x 3a 2 Example 3.12b Transpose p = 2π x – 3y to y. Solution: There’s often more than one way to solve this kind of problem, but I'll just stick to the one. As a rule of thumb, you should start by isolating the entire rooted term: V p = 2π x – 3y 2. Square both sides to be able to access what’s under the root sign. p = 2π V 3. Note the bottom line here: 2π × 2π = 4π 2 and NOT 2π 2. ( x – 3y ) 2 V 2 V 1. Divide both sides by 2π. p2 = x – 3y 4π 2 3y = x – y= V 5. To get one y divide both sides by 3. This would look cumbersome, but multiplying by one third does the same job. p 4π 2 V 2 4. Since the 3y term is clear of interference, move it to the LHS to make it positive. This involves moving other stuff to the RHS. 1 p2 x – 3 4π2 OUTCOME 3: NUMERACY/HIGHER 75 TRANSPOSITION OF FORMULAE Example 3.12c Rewrite the formula a = b 3w – π to make w the subject. w Solution: See if you can follow this without a commentary. 2 3w – π a = w b (3w – π ) a2 = 2 b w 2 2 a w = b (3w – π ) 2 a 2 w = 3b 2 w – b 2 π b2 π = 3b2 w – a 2 w (*) 2 2 2 πb2 (3b – a 2 ) w= 2 V b π = w (3b – a ) Since π is a number (3.14159 etc) it technically should go in front, just as when we write 3x instead of x3. Notice how in the line marked (*) I've moved the w terms to the right. This is because the alternative, moving them left, would give us a 2 w – 3b 2 w = – b 2 π w (a 2 – 3b 2 ) = – b 2 π w= –b 2 π (a 2 – 3b 2 ) Technically speaking this is OK, but it looks cumbersome because of the negative sign on the top line. We can counter this by multiplying numerator and denominator both by –1. This has the effect of changing signs but nothing else, so the result would be w= b2 π – a 2 + 3b2 and we would then rewrite the bottom line with the positive term first w= b2 π 3b 2 – a 2 So it’s a lot easier doing it the first way from scratch. 76 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE Example 3.12d Transpose the formula y = 3x2 + 5 to make x the subject. Solution: x= y –5 3 V y –5 = x2 3 1. Do whatever you have to do to isolate the term involving x2. V y – 5 = 3x 2 2. Do whatever you have to do to isolate the x2 itself. V y = 3x 2 + 5 3. Now that you have x 2 isolated, you square root each side to get x. Notice that it is important to write the square root sign so that it encompasses the entire relevant part of the equation. Some people are careless, and would write the answer with a smaller sign, making it look like this: x= y –5 3 This is completely wrong, as it has a totally different meaning. In the first (correct) expression, you subtract 5 from y, divide the answer by 3, then take the square root of the final answer. In the second (wrong) expression, you are subtracting 5 from y, square rooting the answer, then dividing that answer by 3. Example 3.12e Change the subject of the formula 3t = 5 to X. X –2 3 Solution: Start as usual 3t 5 = 3 1 (X – 2) 3t(X 3 – 2) = 5 3tX 3 – 6t = 5 OUTCOME 3: NUMERACY/HIGHER 77 TRANSPOSITION OF FORMULAE Now treat the cube in the same way as you would a square – isolate first the term involving it, then the X3 itself: NB You canNOT cancel the 6 with the 3, or the t with the t. To avoid this mistake, put brackets round the top line (effectively gluing it together). 3tX 3 = 5 + 6t (5 + 6t ) X3 = 3t Now, instead of taking a square root of each side, you take a cube root. X= 3 5 + 6t 3t Now for an exercise on roots and powers. ? 3.12 A few more things you need to know about roots: Transpose these formulae as required: 36 = 6 1. Q = 3p2 2. y= 3. k =3 t 4. m= 5. y = 3x2 + ab to 6. z= x +y to y 7. t= x x +y to 8. m = 5x 2 + 25 x2 to p but we can also write 36 = to x 2 5 x 4×9 = 4 × 9 = 2×3 = 6 This illustrates the rule that to t ab = a × b We can similarly show that to x (a) a (b) x a b = a b This does NOT work for adding and subtracting! (a) y (b) x 2y to y a + b is NOT the same as a + b A simple illustration: 9 + 16 = 25 = 5 we know is true BUT if we try two separate ones And that’s all there is to it (!) If you have managed to survive this long, you have actually achieved a great deal. 9 + 16 = 3 + 4 = 7 is different. The same applies to subtraction. In my mind, transposition of formulae is probably the single most difficult technique to master, and we’ve done it all with the exception of exponentials and logarithms, which is a complete topic all to itself. Here is a final exercise, a complete mixture of everything you’ve covered so far, using ‘real’ formulae, in other words, formulae which are actually used in the real world. 78 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE ? 3.13 Hope it’s lucky for you. Transpose these formulae as required. In many cases you are asked for more than one transposition, but remember that in most cases your initial steps are always the same, you don’t have to go back to the very beginning each time. Take care to copy down formulae correctly using capital letters and lower case letters as shown, especially in questions 13 and 14. 1. 2. C = πd V = πr2h to d to (a) h (b) r 3. F= 1 2 mv2 to (a) m (b) v 4. V= 3 4 πr3 to r 5. f = (b) m1 (b) d 6. T = 2π 7. 8. v = u + at to v2 = u2 + 2as to (a) (a) u s (b) (b) a u (u + v)t to (a) t (b) u 1 2 Gm1m2 d2 1 2 to l g to l 9. s= 10. s = ut + at2 to (a) u (b) a 11. to (a) b (b) c 12. a = b2 – c2 A = 2πr(r + h) 13. I= iR R +r to (a) i (b) r (c) R 14. I= nE R + nr to (a) E (b) R (c) r to h (d) n OUTCOME 3: NUMERACY/HIGHER 79 TRANSPOSITION OF FORMULAE Answers Page 50 Division is not commutative because the order of division does matter. For example, 6 ÷ 3 is not the same as 3 ÷ 6. The answer to the first one is 2, the answer to the second is ½. Similarly, subtraction is not commutative either. For instance, 5 – 2 = 3 but 2 – 5 = –3 which is a totally different answer. ?3.1: Answers 1. 2. 3. 4. 5. 6. 7. 8. 9. 2 = 5 – 3 or 3 = 5 – 2 35 35 or 7 = 7 5 8 = 7 + 1 (or 1 + 7 but this is the last time a variation like this will be given here) 15 = 5 x 3 (or 3 × 5 but this is the last time a variation like this will be given here) 10 = 12 – 2 or 2 = 12 – 10 21 = 7 × 3 12 = 8 + 4 5= 18 18 or 3 = 3 6 7=5+2 6= ?3.2: Answers 1. 2. (a) (a) 3. (a) 4. 5. (a) (a) k=s–t 4=1+3 m=u+r 8=3+5 t=w+k t=h–u q=p+r (b) (b) (b) (b) (b) t=s–k 3=4–1 r=m–u 5=8–3 k=t–w m=k+v t=8–s (c) (c) f=w+x x=y–4 ?3.3: Answers 1. 4. 80 x=1 k=5 2. 5. y = 13 t=3 3. 6. OUTCOME 3: NUMERACY/HIGHER z=4 m = 29 TRANSPOSITION OF FORMULAE ?3.4: Answers 1. (a) (b) (c) (d) 2 – 4 + 12 – 6 = 7 – 3 (each side equals 4) – 7 + 3 = – 4 + 8 – 6 – 2 (each side equals -4) A–P–Q = b–c–r T – X – W = t + z – y (try to start each line or side with a positive, unless you have no choice) (2) (a) 5x – 4x = 7 – 4 x=3 (b) 3y – 2y = 4 + 7 y = 11 (c) 7k – 6k = –4 – 2 k = –6 (d) 2t – t = – 7 – 9 t = –16 (e) –3m + 4m = 2 – 7 m = –5 (f) 9w – 8w = –11 – 3 w = – 14 (a) (c) (e) x=5–p–a x=y–2–w x=a+b (b) (d) (f) x=w+p–3+a y – 10 = x k–2+a=x 3. ?3.5: Answers 1. 3. 5. q=p–r q=m+t r=x–8–s 2. 4. 6. r=p–q t=q–m x=s+r+8 ?3.6: Answers 1. (a) a= c b (b) b= c a 2. (a) r= k w (b) w= k r 3. (a) x=h×t (b) t= 4. (a) p= (b) m=t×f 5. (a) t=8×j (b) a= b q x h g y b r (c) q= (c) r=7×x OUTCOME 3: NUMERACY/HIGHER 81 TRANSPOSITION OF FORMULAE ?3.7: Answers 1. 4. s 7 t m= k k= 2. 5. m 9 B g= 4h t= 3. d= 6. m= 3. a= C π A 5bx ?3.8: Answers 1. p = 4w 2. 4. t= 2π 5T 5. XS 2 4kpqr a= 3bc r= 6. cdm b 3abc q= 4kpr ?3.9: Answers 1. 4. 360A C NB nB nA = NA a= 2. 5. Ap 7 AD B= C w= 3. 6. 7w A q r= Ap p= ?3.10: Answers 1. q = p + rs 4. a= s + 3nq p 2. 5. k – 3t a 4r – T c= abd h= 3. 6. x – 2y 3c π–K q= pr b= ?3.11: Answers 1. x= T + 6y 3x – T ; y= and you can’t cancel the 6 and the 3! 3 6 2. t= P P – 3t ; m= 3 + 5m 5t 3. Multiply each side by 2 first, giving 2Y = a + 2bc after which a = 2Y – 2bc or 2(Y – bc); b = 4. Multiply each side by 15 (= 3 × 5) first, giving 15X = 5t – 6m after which t= 82 2Y – a and you can’t cancel the 2s. 2c 15X + 6m 5t – 15X ; m= . 5 6 OUTCOME 3: NUMERACY/HIGHER TRANSPOSITION OF FORMULAE 5. 6. 7k – 3 but remember it could be written ½(7k – 3). This applies to lots of 2 other answers as well. w= Whether it’s x or y you’re trying for, the first steps for both are Hx = 3x – 3y 3y = 3x – Hx after which, obtaining y requires one compulsory and one optional move: 3x – Hx (compulsory) 3 (3 – H )x (optional) y= 3 y= and to get x we must do this: 3y = (3 – H )x 3y x= (3 – H ) 7. Put P over 1 and cross multiply, multiply out the bracket you get, then shift the a terms to one side and the b terms to the other. You do all that whether it’s a you want or b. P(a – b) = a + 2b Pa – Pb = a + 2b Pa – a = Pb + 2b a(P – 1) = b(P + 2) Now we can get either a or b: a= 8. b(P + 2) a(P – 1) ; b= (P – 1) (P + 2) Same idea as in Question 7 x= 6y (t + 1) (3 – 2t ) ; y= (3 – 2t ) 6(t + 1) In both cases, the brackets round the 3 – 2t are optional, although the brackets round the t + 1 obviously aren’t. OUTCOME 3: NUMERACY/HIGHER 83 TRANSPOSITION OF FORMULAE ?3.12: Answers Q 3 1. P= 3. k2 k t = or 9 3 5. a= 25 5 or y y 2. x= 4. 4 2 x= or 25m 5m 2 2 6. y – 3x 2 ; x= b y = z2 – x 7. y= 8. Start with m – 5x 2 = y – ab 3 x (1 – t 2 ) t2 y ; x = t2 1 – t2 2y to isolate the rooted term, then square both sides: (m – 5x2)2 = 2y and finally isolate y and reverse: y = ½(m – 5x2)2 or prefer. ?3.13: Answers 1. d= C π 2. h= V ; r= πr 2 3. Multiply both sides by 2 first 2F ; v= v2 m= V πh 2F m 3V 4π 4. r= 5. m= 6. Remember to isolate the rooted term first: l = 84 3 fd 2 ; d= Gm2 Gm1m 2 f OUTCOME 3: NUMERACY/HIGHER gT 2 4π2 (m – 5x 2 )2 if you 2 TRANSPOSITION OF FORMULAE v –u t 7. u = v – at; a = 8. s= v 2 – u2 ; u = v 2 – 2as 2a 9. t= 2s 2s – vt 2s or u = or –v (u + v ) t t 10. u= 2s – at2 2s – 2ut 2(s – ut) or a = or 2t t2 t2 11. b = a2 + c2 ; c = b2 – a2 12. h= A A – 2πr 2 –r or 2πr 2πr 13. i= R(i – I ) I (R + r ) Ir iR iR – I R ; r= – R or or ; R= I I I R i–I 14. E= I (R + nr ) nE nE – nr I n(E – r I ) ; R= – nr or or I I I n r= I nE IR E R nE – I R – R or – or ; n= I In E – Ir n I n OUTCOME 3: NUMERACY/HIGHER 85 86 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION SECTION 4 Introduction – Bivariate Data This title does look forbidding, but believe me it’s not really that difficult. Bivariate data simply means data where the information comes in pairs of mumbers, each from a different source, in other words, each number is a different variable. It could be that one number is the amount of money spent on advertising a particular product and the other is the value of the sales made as a result. As usual, a first step to analysing this sort of information is often to draw a graph. The kind of graph most usually associated with the analysis of bivariate data is the scattergraph or scatter diagram. 4.1 Scattergraph or Scatter Diagram A scatter diagram is a method of plotting the values of two variables, using axes and plotting points just as you did for line graphs, but without trying to join any of the points together (this is because usually there are too many dots for any obvious line to be drawn). The resulting distribution of dots or crosses can then give us an idea of whether the relationship between the two variables is weak or strong. The technical word for this relationship is correlation, and the calculations and study of correlation form a significant part of many maths and statistics courses. You’ll learn more about this very soon. Here is a very simple scatter diagram which plots four models of aeroplane. One axis shows the number of passengers the plane can carry, the other axis shows the hourly cost of operating the plane. Carrying Capacity Example 4.1a •B •D •C A shows a plane which costs little to operate and carries •A few passengers. O Operating Costs Operating Costs B shows a plane which costs little to operate (but a bit more than A) and carries many passengers. C shows a plane which costs a lot to operate and carries few passengers (but a few more than A). The diagram does not show any relationship whatever between the two variables (i.e. between operating costs and carrying capacity). OUTCOME 3: NUMERACY/HIGHER 87 CORRELATION AND REGRESSION Activity 4.1a What do you think the scatter diagram shows about aeroplane D? Example 4.1b Each dot represents an aeroplane in an airline’s fleet. The diagram shows that there is a fairly high correlation (i.e. a strong relationship) between the number of passengers a plane can carry and the profit which that plane generates for the airline’s coffers. The correlation is positive, i.e. the higher the value of one variable, the higher the value of the other. Profit Here is another scatter diagram. • • • • • • • • • • • • • •A Carrying CarryingCapacity Capacity 0 Activity 4.1b What does the diagram tell you about the aeroplane marked A? Can you suggest any reasons for this? Here, a factory manager has plotted the age of each machine in the factory against the efficiency of that machine. Again, as with the aeroplanes in Example 4.1b, the correlation is high. In fact it is higher here than in Example 4.1b. How do we know? Because the dots lie closer to a straight line here. In fact, if the dots actually all lie on a straight line then we have perfect correlation: you can’t get better than that. Efficiency Index Example 4.1c • • • • • •A 0 • • • • • • • Age Ageofof Machine Machine In this case our correlation is negative. The higher the age of the machine, the lower the efficiency index. (In other words, the older it is, the worse it works.) Activity 4.1c The machine marked A sticks out like a sore thumb on the diagram, whereas it might have been buried in a page of figures. What does the diagram say about machine A? Suggest a reason. 88 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION Example 4.1d Here, someone has plotted the relationship between the wages paid to employees of a company and the physical height of those employees. • • • • Clearly, we would expect there to be no relationship at all, and the scatter diagram shows this with a ‘plum pudding’ effect. • • 0 • • • • • • • • • Wage paid by Firm There is no correlation at all, either positive or negative. We say that the correlation is zero. If the dots had happened to lie reasonably close to a straight line, we would hope that the correlation was spurious, i.e. completely coincidental, and that the firm did not have any policy of paying by height! OUTCOME 3: NUMERACY/HIGHER 89 CORRELATION AND REGRESSION ? 4.1 For each diagram say whether it displays positive correlation, negative correlation, or zero correlation. Write a sentence or two about each one. Try to put the strengths of the correlations in order of size. (2) Volume of Production Company Profits (£) (1) 0 Company Sales (£) Examination Marks 0 Rainfall (mm) 0 Age of Student (6) Traffic Speed (mph) Production Costs (£) (5) 0 90 Absenteeism by Employees (4) Crop Yield (tonnes) (3) 0 Production Level (units) OUTCOME 3: NUMERACY/HIGHER 0 Volume of Traffic (000s) CORRELATION AND REGRESSION Important Note It is important to remember, and this will be repeated several times, that the existence of correlation does not, repeat NOT, imply that one effect is CAUSED by the other. It simply shows that the two variables are related. Both of them could, of course, be caused by a third variable you don’t even know about. So when we talk about graphing the independent variable horizontally and the dependent variable vertically, these are expressions we use to denote a notional dependence – ‘if there is a dependence, this is how it would be’ – but the existence of correlation does NOT imply causation. 4.2 Drawing Scatter Diagrams When drawing a scatter diagram, plot the variables along a pair of axes in the same way as you would for a line graph, the only difference being that you don’t (in fact can’t) join them up with a line. As usual, the variable which, it is suspected, is dependent on the other is plotted vertically and the independent variable is plotted horizontally. Example 4.2a This table shows the diameters (in inches) of a variety of cylindrical components produced on a lathe and the time taken (in seconds) by the machinist to make them. Draw a scatter diagram to illustrate this. Solution: If anything, the time taken to make the component will depend on the diameter of the component (although they might both depend on something else), so we plot time vertically and diameter horizontally. Component A B C D E F G H I J K L Diameter 3.006 3.012 3.001 2.998 3.015 3.009 3.013 3.000 2.997 3.005 3.010 3.016 Time 195 205 200 185 210 215 200 190 195 205 200 220 The lowest diameter is 2.997 and the highest is 3.016, so a horizontal scale from 2.990 to 3.020 will suffice. The lowest time is 185 and the highest is 220 so a vertical scale from 180 to 220 will do. Each point is plotted in its correct position relative to the axes. I have also typed the reference letter beside each one, though this is not usually done. As you see, joining the points up with a line is just nonsense. OUTCOME 3: NUMERACY/HIGHER 91 CORRELATION AND REGRESSION Scatter Diagram showing Diameters and Production Times 220 L 215 F 210 E Time 205 B J 200 C 195 K 190 G A I H 185 D 180 2.990 2.995 3.000 3.005 3.010 Diameter (inches) 3.015 3.020 The scattergraph shows a reasonably strong positive (sloping up from left to right) linear (i.e. straight line) relationship between the two variables. In general, the larger the diameter of the component, the longer it takes to make. Activity 4.2a On the diagram above, plot the following: Component M, diameter 3.007 inches, taking 208 seconds Component N, diameter 3.003 inches, taking 210 seconds and make a comment about each one. You can try to draw a best-fitting straight line (or line of best fit) through these points which would help you to decide, for example, how long it would take to produce a component of diameter 3.008 inches (i.e. within the known range of data) or of diameter 3.03 inches (outwith the known range of data). Such a line is called the line of regression of y on x. Drawing one by eye is very difficult and not at all reliable, as the graph below shows. You may well disagree with the one shown. Better ways of doing this will follow. Scatter Diagram showing Diameters and Production Times 220 L 215 F 210 E Time 205 200 C 195 G H 185 92 K A I 190 180 2.990 B J D 2.995 3.000 3.005 3.010 Diameter (inches) OUTCOME 3: NUMERACY/HIGHER 3.015 3.020 CORRELATION AND REGRESSION Example 4.2b School This table shows the pupil:staff ratio at fourteen secondary schools and also the percentage of pupils who passed 5 or more Highers. Draw a scatter diagram to illustrate the data. Percentage A B C D E F G H I J K L M Pupils per teacher 17 19 12 10 16 13 18 20 22 13 19 8 19 N 17 20 10 12 16 15 10 14 9 8 10 17 7 23 19 Solution: The resulting scatter diagram is shown below. Scatter Diagram of Teaching Ratio and Pass Rate 25 Percentage 20 15 10 5 0 0 5 10 15 Pupil : Teacher Ratio 20 25 Here we see a relatively strong negative (because the general slope of the ‘line’ is down, left to right) correlation between the two variables. In general, the more pupils there are per teacher, the fewer of the pupils do well in their exams. The strength of the relationship is clearly not as high as it was in Example 4.2a, so drawing the line of regression by eye is even more problematic. OUTCOME 3: NUMERACY/HIGHER 93 CORRELATION AND REGRESSION Drawing a line of best fit by eye Drawing a line of best fit is not actually as hit and miss as you might think. There is a point through which the best line will go. Find the average of the values of each variable (separately) and you will have a point on which to anchor your ruler. How the line will slope is then a matter of conjecture. In the example above, the average of the pupil:teacher ratio column is (17 + 19 + ... + 19 + 17)/14 = 15.9 the average of the percentage column is (10 + 12 + ... + 19 + 20)/14 = 13.6 Plot that point on the graph, then use your skill and judgment to draw the line. A possible example is: Scatter Diagram of Teaching Ratio and Pass Rate Point (15.9 , 13.6) 25 20 15 10 5 0 0 5 10 15 Pupil : Teacher Ratio In some textbooks this point is called the mean centre. 94 OUTCOME 3: NUMERACY/HIGHER 20 25 CORRELATION AND REGRESSION ? 4.2 Draw a scatter diagram to illustrate each of the following tables. Once you have drawn the graph, draw on it what you think is the best fitting straight line. You are looking for a straight line which passes through as many points as possible, with as many points above it as below it, but also passing through the mean centre as calculated on the previous page. Keep your answers; you’ll need them later. 1. An advertising executive is investigating the relationship between the size of the budget for certain advertising campaigns (horizontal scale) and the resulting sales (vertical scale). Use your line to predict the sales for an advertising expenditure of £7 million. 2. A town planner is looking at the population density of certain areas of the town (horizontal scale) and their distance from the town centre (vertical scale). Use your line to predict how far away from the town centre you would find a population density of 40 persons per hectare. 3. An economist from an energy company is looking at the demand from a power station (vertical scale) and how it is affected by the average daily temperature (horizontal scale). Use your line to predict the demand if the temperature is 5.5°C. Advertising Expenditure (£m) 3.4 4.0 5.2 6.5 7.9 8.3 9.2 10.0 Sales (£m) Persons per Hectare 65 21 78 48 56 53 31 34 Distance from Centre (km) 0.8 3.7 1.6 2.7 1.5 2.6 3.4 1.9 Temperature (°C) -2.0 1.0 2.3 4.1 4.9 8.3 6.5 3.8 12.0 15.8 19.7 19.2 26.0 24.7 29.2 29.7 Demand (MWh) 60.5 58.9 56.4 51.3 48.0 42.6 43.2 53.1 OUTCOME 3: NUMERACY/HIGHER 95 CORRELATION AND REGRESSION 4.3 Correlation and Regression We can have different types of correlation and we try to draw a line of best fit, if we can, through the points plotted on the scatter diagram, which will allow us to make point estimates of values of y for any given x. The line we draw is called the line of regression of y on x. It allows us to predict a value of y for a given value of x, but not the other way round. We will be looking at linear regression, where the line of best fit is a straight line. But other forms of regression exist, and many scientific calculators with statistical functions can apply more than one form of regression to given data so that you can choose the best one (note – so that you can choose, the calculator won’t make the choice for you!) Here we have positive linear correlation. y The line of points is best approximated by a straight line whose form is y = a + bx x where b will have a positive value because the line is sloping up from left to right. Here we have negative linear correlation. y The line of points is best approximated by a straight line whose form is y = a + bx x where b will have a negative value because the line is sloping down from left to right. Here we have quadratic correlation. y The shape of the points is best approximated by a parabola, whose equation is of the form y = ax2 + bx + c 96 OUTCOME 3: NUMERACY/HIGHER x CORRELATION AND REGRESSION Here we have exponential correlation. y The shape of the points is best approximated by a curved line whose equation is of the form y = ab x or y = axb x Here we have logarithmic correlation. y The shape of the points is best approximated by a curve whose equation is of the form y = a + b logex x We will be looking only at linear correlation. Associated with the regression line is the coefficient of correlation. There are several of these measures used; the one we will be looking at was invented by someone called Pearson, and its full title is Pearson’s Product Moment Correlation Coefficient. Its calculation involves means and standard deviations, and a few other things besides, but the formula he devised essentially boils down to this: The closer the points all lie to the line of regression, the nearer the coefficient is to either +1 (if the the line has a positive slope) or –1 (if the line has a negative slope). The further away from the line that the points lie, the closer the coefficient (which is given the letter r as an identifier) is to 0. All values of r thus lie between +1 and –1, which both show perfect correlation, i.e. the strongest possible relationship between the two variables. The value of 0 for r shows no correlation at all, i.e. no relationship whatever between the two variables. OUTCOME 3: NUMERACY/HIGHER 97 CORRELATION AND REGRESSION For example: y r = 0.82 x y r = -0.95 x y r = -0.15 x I will now give you the formulae required. But first, a little disagreement with our American partners. For reasons I won’t go into here, American textbooks often give the regression equation in the form y = ax + b whereas British textbooks give the equation as y = a + bx There is thus confusion between the values of a and b as shown in various formulae. (Thankfully, the formula for r is the same no matter which convention you use.) So make sure you know what’s what! Even calculators are not consistent. At college I tend to use two calculators both made by the same manufacturer and both able to calculate correlation. One model uses ax + b and the other uses a + bx. And to confuse things just a little bit more, mathematics textbooks use y = mx + c! 98 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION Here is the convention and the formulae I will be using in this section: For the line of regression of y on x of the form y = a + bx: b= r= nΣxy – ( Σx )(Σy ) nΣx – (Σx ) 2 2 ; a= Σy – bΣx n nΣxy – (Σx )(Σy ) nΣx 2 – (Σx )2 nΣy 2 – (Σy )2 These look complex, but the formulae actually tell you what columns of figures you have to add up. We need an x column, a y column, an xy column, an x 2 column and a y2 column. The n of the formula is the number of points we have as data. In case you haven’t met it before, the Σ sign is a Greek symbol (read ‘sigma’) which means ‘the total of’. Where do these formulae come from? There is a method known as least squares. It takes the distance each point is from the regression line, squares it (to get rid of the problem of some of these distances being positive and some negative, due to their position above or below the line) and then uses calculus to minimise the total of these squared distances. The best fit line is thus sometimes called the least squares line. Don’t worry, the vast majority of people who use these formulae don’t know (or care) where they come from, they just use the results. You won’t at any point be expected to know calculus! Example 4.3a We’ll start with an example where we can find the answer just by looking. It costs £40 to set up a computer to print a logo on a T-shirt, then it costs a further £5 per shirt. So there is a start-up cost of £40, then you have to multiply the number of shirts (= x) by £5 to get the cost of the actual shirts, and add it on to the 40. So the formula will be y = 40 + 5x where y is the total cost. If you’ve done any accountancy or economics you’ll recognise the format as ‘fixed cost + variable cost’. OUTCOME 3: NUMERACY/HIGHER 99 CORRELATION AND REGRESSION Make up a table of values (the x and y will be given to you in a normal situation) then add columns for x2, y2 and xy. Multiply each number of the x column by itself. 0 ×0 = 0 3 ×3 = 9 5 × 5 = 25 and so on V V 0 3 5 8 10 26 y 40 55 65 80 90 330 x2 0 9 25 64 100 198 y2 1,600 3,025 4,225 6,400 8,100 23,350 V V V The numbers in this row are the totals of each column. x xy V The x and y values are normally given to you to start with Multiply each x by its partner y. Thus: 0 × 40 = 0 3 × 55 = 165 5 × 65 = 325 and so on Multiply each number of the y column by itself. 40 × 40 = 1,600 55 × 55 = 3,025 65 × 65 = 4,225 and so on 0 165 325 640 900 2,030 The calculations are now as follows: 5 × 2,030 – 26 × 330 1,570 = =5 2 5 × 198 – 26 314 330 – 5 × 26 200 a= = = 40 5 5 1,570 (= same numerator as for b) r= = [314 = same denominator as for b]× 5 × 23,350 – 3302 b= 1,570 314 × 7,850 = 1,570 1,570 Here is the graph with points plotted and the line of regression drawn on. 90 80 70 60 yy 50 40 30 20 10 0 0 1 2 3 4 5 xx 6 7 8 9 10 The values of b = 5 and a = 40 confirm what we already knew, that y = a + bx is, in fact, y = 40 + 5x. Furthermore, we get a value of 1 for our correlation coefficient, which comes as no surprise since the points all exactly fit the formula. 100 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION Just to confirm what I said earlier about drawing by eye: the average of the xs is (0 + 3 + 5 + 8 + 10)/5 = 5.2 the average of the ys is (40 + 55 + 65 + 80 + 90)/5 = 66 Looking at the graph you can vaguely see that the line passes through that point. But, more importantly, if we take x as being 5.2 and substitute into the formula 40 + 5x = 40 + 5 × 5.2, we get 40 + 26 = 66 as expected. Example 4.3b Now let’s take three of our points and change them a bit, and see how that affects the graph and the calculations. x y 30 55 40 80 80 285 0 3 5 8 10 26 Changing the y values of three of the points changes some of the table entries and also some of the column totals. x2 0 9 25 64 100 198 y2 900 3,025 1,600 6,400 6,400 18,325 xy 0 165 200 640 800 1,805 The calculations change as well: 5 × 1,805 – 26 × 285 1,615 = = 5.143 5 × 198 – 262 314 285 – 5.143 × 26 151.282 a= = = 30.256 5 5 1,615 (= same numerator as for b ) r= [314 = same denominator as for b]× 5 × 18,325 – 2852 1615 1615 = = 0.894 = 1807.097 314 × 10400 b= 90 80 70 60 yy 50 40 30 20 10 0 0 1 2 3 4 5 6 7 8 9 10 xx OUTCOME 3: NUMERACY/HIGHER 101 CORRELATION AND REGRESSION The best fitting line no longer goes through all the points, so we expect the value of r to be less than 1. In fact, r is now 0.894, still showing a strong positive relationship between the two variables but not as strong as before. The equation of the line of regression is now y = 30.256 + 5.143x thus reflecting its altered position on the diagram. How do we draw the line? The technique is to pick two values of x, as far apart as is practical, and substitute them in the formula to calculate y. Choose, say, x = 0. Then y = 30.256 + 5.153 × 0 = 30.256 so we could plot (0, 30) on the diagram because any greater degree of precision isn’t possible. Now pick another x, say 8. Then y = 30.256 + 5.153 × 8 = 71.480 so plot the point (8, 71). Then draw the line connecting these two points. What do we use the line for? The line of regression will now give us a point estimate of the cost for any number of shirts. In reality, we would have to qualify our answer with a ‘plus or minus ...’ but the calculation of this is extremely complicated (it involves things called confidence intervals) so I’ll give you a simplified version. What is the cost for 7 shirts? Looking at the graph, you see that the cost will be round about £68. If we replace x by 7 in the equation, we get y = 30.256 + 5.143 × 7 = £66.257. But remember that this is just an estimate, so ‘round about £66’ will be a good answer. This answer is fairly reliable, because the value of r is close to 1. In addition, our estimate was for a value within the known range of data (the values of x we were given lay between 0 and 10) thus adding to its reliability. What is the cost of 20 shirts? This can be calculated as 30.256 + 5.143 × 20 = £133.116. But here we are forecasting beyond the known range of data (i.e. outside the limits of the graph as we can see it) and quite far beyond. We would expect the answer of ‘around £133’ to be a bit less reliable than our previous answer. The further we go beyond the range of data that we know about, the less reliable any point estimates will be, since there may be factors ‘out there’ affecting results in a manner that we don’t know. Further study of the range of values that a point estimate can represent is not covered in this study pack. 102 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION Example 4.3c Here is now a full worked example, from start to finish. A factory produces batches of items. The table shows the number of items produced (in hundreds) and the corresponding cost of producing that batch (in thousands of £s). No. of items produced (00) 10 24 30 33 Cost of production (£000) 380 400 510 500 45 45 485 500 54 58 60 69 590 523 600 618 Draw a scatter diagram, calculate the coefficient of correlation and the equation of the regression line of y on x, and draw the line on your diagram. Then estimate the cost of a batch of (a) 4,320 items and (b) 7,540 items and comment on the reliability of these estimates. Solution: The first and most important matter to sort out is which variable is x and which is y? The clue is in the last line of the question ‘...estimate the cost of a batch of 4,320 items...’ The regression line is the line of regression of y on x and allows us to estimate y for a given x. We are given 4,320 items. It follows that Number of items is x and Production cost is y. We have to write the data in two columns, and also draw the graph. Here’s the graph. y = cost (£000) 700 600 500 400 300 0 10 20 30 40 50 60 70 = no. xx= no.ofofitems items(00) (00) Next, put in the extra columns and evaluate the formulae: OUTCOME 3: NUMERACY/HIGHER 103 CORRELATION AND REGRESSION x (00 Items) b= x2 y (£000 cost) y2 Reminder: xy 10 380 100 144,400 3,800 24 400 576 160,000 9,600 30 510 900 260,100 15,300 33 500 1,089 250,000 16,500 45 485 2,025 235,225 21,825 45 500 2,025 250,000 22,500 54 590 2,916 348,100 31,860 58 523 3,364 273,529 30,334 60 600 3,600 360,000 36,000 69 618 4,761 381,924 42,642 428 5,106 21,356 2,663,278 230,361 nΣxy – (Σx )(Σy ) nΣx – ( Σx ) 2 2 = First Line: 100 comes from 102 144,400 comes from 380 2 3,800 comes from 10 × 380 10 × 230,261 – 428 × 5,106 118,242 = = 3.893 2 10 × 21,356 – 428 30,376 Σy – bΣx 5,106 – 3.893 × 428 = = 344.0 10 n 118,242 118,242 = 0.905 = r= 2 30,376 × 561,544 [30,376]× 10 × 2,663, 278 – 5,106 a= The line of regression of y on x has equation y = 344.0 +3.893x This shows two things: (a) it costs 344.0 (£000), in other words £344,000, to produce no items at all. We get this by setting x equal to 0 in the equation. Note the units: each unit of y is actually £1,000. (b) 3.893 is the gradient of the line (compare with y = mx + c). In other words it is the rate of y for each x. Each x costs 3.893 (y) to produce. But since x is in hundreds of items and y is in £000, this means that every 100 items cost £3,893 to produce. We can easily draw the line of regression on the graph – simply choose two easy values of x quite far apart, calculate y, plot the points then join them up: x = 0 , y = 344.0 + 3.893 × 0 = 344 (we already knew that) x = 70, y = 344.0 + 3.893 × 70 = 616.51 The line is plotted on the next page. Since the value of the correlation coefficient is very high (0.905 is very close to 1) this means that there is a very strong relationship between the number of items produced (in hundreds) and the production cost (in £000). The points on the graph all lie close to the line of regression. 104 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION y = cost (£000) 700 600 500 y= 400 .0 344 .89 +3 3x 300 0 10 20 30 40 50 60 70 = no. (00) xx = no.ofofitems items (00) Now for the forecasts: (a) For 4,320 items, we have to put x = 43.20 into the regression equation (which has x in hundreds of items) and we get y = 344.0 + 3.893 × 43.20 = 512.178. This means a cost of £512,178 although it would make more sense to round it off to, say, £512,000 since it is a point estimate after all. This is roughly the answer which the graph would give you. We would expect this estimate to be quite reliable because (i) the value of r is close to 1 (ii) our value of x is within the range of known data (i.e. 43.20 is between 10 and 69). (b) For 7,540 items, we have to put x = 75.40 into the regression equation and we get y = 344.0 + 3.893 × 75.40 = 637.532 meaning £637,532 which can be rounded off to perhaps £638,000. This estimate is not as reliable as the previous one because, despite the high value of r, we are forecasting beyond the known range of data (75.40 is beyond 69). OUTCOME 3: NUMERACY/HIGHER 105 CORRELATION AND REGRESSION ? 4.3 1. Dunedin Chemicals Ltd plan to use data from the previous six months to obtain a formula for estimating the total power costs for a given output. The relevant data are shown. Output (units) Power costs (£000) 12 6.2 18 8 19 8.6 20 24 30 10.4 10.2 12.4 Draw a scatter diagram, calculate the equation of the line of regression and the value of the correlation coefficient, then draw the line of regression on your diagram. Estimate the total power costs for an output of (a) 22 units (b) 35 units and comment on the reliability of your estimates. 2. A hire purchase company predicts the level of business it expects by considering current rates of interest. Graph the given data on a scatter diagram, calculate the coefficient of correlation, and comment on the strength of the relationship between the two variables. Value of contracts (£million) 5.0 5.5 4.8 4.0 Rates of interest (%) 10.0 10.5 11.0 11.0 6.0 9.0 5.5 6.2 10.5 9.5 7.0 8.5 Calculate the equation of the line of regression and draw it on the diagram. Use it to estimate the value of contracts if the interest rate is 8%. Comment on the reliability of your estimate. 3. A consumers’ organisation awarded marks out of 20 for each of nine washing machines tested, and these marks are shown below together with the recommended retail price (RRP) of each machine. Machine Mark/20 RRP (£) A 16 300 B 10 220 C 13 250 D 7 175 E 19 295 F 8 210 G 13 245 H 11 255 I 14 260 Calculate the correlation coefficient and also the equation of the line of regression. How much would you expect to pay for a machine which scored full marks in the survey ? 106 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION 4. The following table shows the labour cost (£) and the corresponding output (tonnes) of a manufacturing plant. Output Labour costs 7,600 8,400 8,800 8,000 9,100 10,000 9,700 60,000 63,000 69,000 62,000 74,000 95,000 87,000 As you see, the numbers are all on the large side, so you may wish to alter their size before proceeding further. Draw the scatter diagram, estimate what the labour cost would be for an output of 12,400 tonnes, and say how reliable you think this estimate will be. 5. 6. A company has a new management accountant who is attempting to install a new budgetary control system into one of the company’s operating plants. The following historical data has been established for plant overheads for the last 12 months. Help him decide whether the overhead costs vary more with the output or the overhead costs vary more with the number of employees, and find the equation of the appropriate regression line. Month (1998) No. of Employees January February March April May June July August September October November December 200 180 220 200 250 220 190 150 160 240 240 180 Output (standard hours) 16,000 14,400 18,200 18,000 20,100 18,600 17,500 12,500 16,600 20,400 19,700 14,000 Overhead Costs (£) 52,400 48,500 56,400 55,700 60,300 57,000 55,000 46,500 53,000 61,000 59,500 47,900 Look back at the three questions in Exercise 4.2. For each one calculate the correlation coefficient and the equation of the line of regression. Then calculate the same estimate as you did last time by eye. How close were you? OUTCOME 3: NUMERACY/HIGHER 107 CORRELATION AND REGRESSION Answers Activity 4.1a D’s operating costs are a bit lower than C’s but considerably higher than A’s or B’s. D’s carrying capacity is a bit lower than B’s but considerably higher than A’s or C’s. Activity 4.1b Its carrying capacity is the highest of all the planes but the profits generated by it are almost the worst. Perhaps the route is not popular and so the plane flies aound half empty, a smaller plane should be assigned to that route. Note: if you are asked for a reason, it’s bound to be one which requires no specialist knowledge but just a bit of common sense. Activity 4.1c It’s the third youngest machine but has almost the worst efficiency. Perhaps there are unexpected teething troubles, or the operators have not been properly trained. ?4.1: Answers 1. 2. 3. 4. 5. 6. Positive Negative Negative None Positive Negative Strongest to weakest: 5, 1, 6, 2, 3, 4 The stronger the relationship between the two variables, the closer the dots lie to a straight line. You will have noticed that in question 6 a curve fits the dots better than a straight line. Not all correlation is linear; more about this later. 108 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION Activity 4.2a Scatter Diagram showing Diameters and Production Times 220 215 N 210 Time T 205 i 200 m e 195 190 . . M L F E B J C K G A I H 185 180 2.990 D 2.995 3.000 3.005 3.010 Diameter (inches) 3.015 3.020 ?4.2: Answers 1. Your regession line will go through the point (Advertising 6.8, Sales 22.0). Relation of Sales to Adv ertising Expenditure 30.0 Sales (£m) 25.0 20.0 15.0 10.0 3.0 4.0 5.0 6.0 7.0 8.0 Adv ertising Expenditure (£m) 9.0 10.0 Estimated sales will be around £23–24 million. Your regression line will go through the point (Density 48.2, Distance 2.3). Relationship of Population Density and Distance f rom Town Centre Kilometres from Town Centre 2. 4 3.5 3 2.5 2 1.5 1 0.5 0 20 30 40 50 60 Persons per Hectare 70 80 Estimated distance is about 2.6km. OUTCOME 3: NUMERACY/HIGHER 109 CORRELATION AND REGRESSION 3. Your regression line will go through the point (Temperature 3.6, Demand 51.8). Relationship of Power Demand to Temperature 65.0 60.0 55.0 50.0 45.0 40.0 -2.0 0.0 2.0 4.0 Temperature ( 6.0 8.0 10.0 ° C) Estimated demand is approximately 48 MWh. ?4.3: Answers 1. x is Output (horizontal axis), y is Power Costs (vertical axis). They MUST be that way round. x 12 18 19 20 24 30 123 y x2 6.2 144 8 324 8.6 361 10.4 400 10.2 576 12.4 900 55.8 2,705 y2 xy 38.44 74.4 64 144 73.96 163.4 108.16 208 104.04 244.8 153.76 372 542.36 1,206.6 6 × 1,206.6 – 123 × 55.8 = 0.341689 6 × 2,705 – 1232 55.8 – 0.341689 × 123 a= = 2.29537 6 6 × 1,206.6 – 123 × 55.8 r= 6 × 2,705 – 1232 × 6 × 542.36 – 55.8 2 = 0.956436 b= Correlation coefficient is 0.96 (rounded off to 2 d. p.) This is very close to 1 and thus shows a very strong relationship between the two variables. The equation of the regression line is y = 2.30 + 0.34x. To draw the line on your diagram, pick any two points reasonably far apart. (The further apart these are, the less significant any errors you make will be, by having too thick a pencil, say, or by missing your point altogether.) Say x = 10, then y = 2.30 + 0.34 × 10 = 5.7. Say x = 22, then y = 2.30 + 0.34 × 22 = 9.78. (As you see, once you get to the regression line you can drop all the decimal places your calculator gave you, and just stick to 2.) Join up the two points just found and there’s your line. 110 OUTCOME 3: NUMERACY/HIGHER CORRELATION AND REGRESSION Required estimates: (a) For 22 units we get y = 9.78 but remember that this is in £000 so the estimate is £9,780. This should be reliable because (i) r is very high and (ii) we are estimating within the known range of data. (b) For 35 units we get y = 14.2 meaning £14,200. The 35, however, is beyond the range of known data (remember x only went from 12 to 30) so the estimate won’t be as reliable as for (a) although the high value of r would still make it reasonable. NB if you plot your x and y the wrong way round you get the regression line of x on y and you would end up estimating the output for a given power cost. This is a complication you do not need. So get them the right way round to start with! 2. The interest rate is x (plotted horizontally) and the contract value is y (plotted vertically). The column totals are: Σx = 80; Σy = 44; Σx2 = 806; Σy2 = 247.98; Σxy = 434.7 b= –0.88333 and a = 14.3333 so the regression line has equation y = 14.33 – 0.88x. r = –0.88481 ..., showing a very high correlation. The line will slope down from left to right. For an interest rate of 8% we get y = 7.269 i.e. the value of the contracts will be approximately £7.3 million, or £7,269,000. The points I picked when drawing the graph are (8, 7.3) and (11, 4.7). 3. x is the mark out of 20, y is the RRP. The column totals are Σx = 111; Σy = 2,210; Σx 2 = 1,485; Σy2 = 555,300; Σxy = 28,390 The equation is y = 125.06 + 9.77x. The value of r is 0.937, showing a very strong relationship. Points which could be used to draw the line are (0,125) and (20, 320). Full marks is 20 out of 20, so x = 20 and y = 320.46, meaning £320.46, but ‘about £320’ is much better. It is a less precise answer but shows that you understand that an estimate is not expected to be accurate. OUTCOME 3: NUMERACY/HIGHER 111 CORRELATION AND REGRESSION This figure of £320 should be reliable, as the value of r is high and we are going only a little way beyond the range of known data. 4. It is easier on the calculator finger if you change the scale of your figures. Make your x column (output) in thousands (7.6, 8.4, 8.8, etc.) and make your y column (labour cost) also in thousands (60, 63, 63, etc.). It is coincidental that the scale change is the same for each variable. You could make the labour cost in hundreds (600, 630, 690, etc.) but it’s not as convenient. Σx = 61.6; Σy = 510; Σx2 = 546.66; Σy2 = 38,244; Σxy = 4,555 y = –57.22 + 14.78x is the equation, r = 0.960 is very high. For an output of 12,400 tonnes you have to make x = 12.4 (because the scale was changed) and substitute this into the equation, giving y = 126.052. But this is in thousands as well, so the estimate is £126,052 which looks more like an exact figure. Therefore quote the estimate as ‘around £126,000’. However, this estimate is being made for a value of x well beyond the data range, so despite the high value of r and the strong relationship this implies, I wouldn’t bet my life on it! 5. This is really two questions in one. (a) Output = x (changed to thousands), overhead costs = y (thousands) Σx = 206; Σy = 653.2; Σx2 = 3,606.88; Σy2 = 35,818.46; Σxy = 11,348.81 r = 0.9958 (b) Employees = x (changed to hundreds), overhead costs = y (thousands) Σx = 24.3; Σy = 653.2; Σx2 = 50.35; Σy2 = 35,818.46; Σxy = 1,338.2 r = 0.8931 Since the value of r is higher in (a) than it is in (b) the relationship is stronger there and so we’ll find the regression equation for part (a): y = 21.45 + 1.92x. 6. y = 4.60 + 2.56x; r = 0.98; estimate is £22.52 million. 7. y = 4.26 – 0.041x; r = –0.78; estimate is 2.62 km. This would not be as reliable as the answer to question 6 because r is not so high. 8. y = 59.06 – 2.02x; r = -0.96; estimate is 47.95 MWh. 112 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS SECTION 5 A sequence is a list of numbers which are related to each other. Each item of the sequence is called a term. Invariably, this being Mathematics, there is a formula which generates each term of the sequence. Notation We use the notation Un to denote the nth term of a sequence. The subscript of the letter U tells you which term you are finding. Thus U1 is the first term, U 2 is the second term, U 3 is the third and so on. Just as the term before U8 is U7 , and the term after U8 is U9, so the term before Un is Un–1 and the term after Un is Un+1. 5.1 Generating by Formula Example 5.1a Suppose we have a formula Un = 3n – 1. We can find any term of the sequence by replacing n by the number of the required term. So we can get the first three terms thus: U1 = 3 × 1 – 1 = 2 U2 = 3 × 2 – 1 = 5 U3 = 3 × 3 – 1 = 8 Note that only the n changes value as required, all the other bits of the formula stay as they are. But the beauty of this is that, suppose we want to find, say, the 15th term. We don’t have to find each and every term preceding the 15th. We can home in on it: U15 = 3 × 15 – 1 = 44 Example 5.1b Find the 8th term of each of these sequences: (a) Un = 3(n –1) 2 Solution: U8 = 3 × (8 –1)2 = 3 × 72 = 3 × 49 = 147 OUTCOME 3: NUMERACY/HIGHER 113 RECURRENCE RELATIONS (b) Un = (–1)n+1n Solution: U 8 = (–1) 8+1 × 8 = (–1)9 × 8 = – 8 (c) Un = 2n n+5 Solution: U8 = 2×8 16 = 8+5 13 ? 5.1 1. Find the first three terms of each of these sequences: (a) 2. (b) Un = n2 + 1 (c) U n = 5 – 2n Find the required term in each of these: (a) (b) (c) (d) (e) 3. Un = 2n + 7 Un = 5n2; U4 Un = n2 + 3n – 2; U5 Un = (–1)n × 3n; U 8 Un = (–1)n+1 × (2n + 1); U8 Un = (n – 3)2; U7 Sometimes we can jump to premature conclusions. Calculate the first four terms of each of these sequences, then make a rather obvious comment. (a) (b) Un = 2n Un = n2 – n + 2 5.2 Recurrence Relations Sometimes it is extremely difficult to define a sequence by using a formula as above. Sometimes we can only define it by relating each term to the previous one(s). This means we also require to know what the first term is so that we have something to start with. In these cases, U1 is the first term as before, but it is often easier to make U0 the term which you are actually given, and U1 then becomes the first term which you have actually calculated (i.e. the second term of the sequence). 114 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS I know that this seems complicated, but it can make life much simpler as you will see later on. At the end of the day, it doesn’t actually matter which way you do it, so long as you clearly state what your U0 and U 1 are, and get the correct answer. The name given to the type of formula which relates a particular term to whatever went before is recurrence relation. Example 5.2a A sequence is generated by the recurrence relation Un = Un–1 + 2 where U 1 = 5. Write down the next four terms. V Solution: The relation means ‘each term is equal to the previous term plus 2’ U1 =5 V U2 = U1 + 2 = 5 + 2 = 7 V U3 = U2 + 2 = 7 + 2 = 9 V U4 = U3 + 2 = 9 + 2 = 11 U5 = U4 + 2 = 11 + 2 = 13 In the above example, we made U1 = 5 because making the subscript equal to 0 would cause problems with the part of the formula which reads Un–1, because making n = 0 would give us U–1 which, by convention, we cannot have (there is no such thing as a (–1)th term). Here is another example where we define the relation slightly differently. Example 5.2b Write down the next four terms of the sequence generated by the recurrence relation Un+1 = 3U n – 5 where U0 = 2. Each term is ‘3 times the previous term, then subtract 5’. Solution: U0 V =2 V U1 = 3 × U0 – 5 = 3 × 2 – 5 = 1 V U2 = 3 × U1 – 5 = 3 × 1 – 5 = –2 V U3 = 3 × U2 – 5 = 3 × (–2) – 5 = –11 U4 = 3 × U3 – 5 = 3 × (–11) – 5 = –38 You can do the calculations either mentally or using a calculator. OUTCOME 3: NUMERACY/HIGHER 115 RECURRENCE RELATIONS If you had made U1 = 2, the calculations would have been exactly the same, but the final answer of –38 would have been called U5 and not U4. Example 5.2c Calculate the next four terms of this sequence: Un+1 = 0.3U n + 5 where U1 = 20. Solution: U n+1 = 0.3Un + 5 = 20 V U1 V U 2 = 0.3 × U1 + 5 = 0.3 × 20 + 5 = 11 V U 3 = 0.3 × U2 + 5 = 0.3 × 11 + 5 = 8.3 V U 4 = 0.3 × U3 + 5 = 0.3 × 8.3 + 5 = 7.49 U 5 = 0.3 × U 4 + 5 = 0.3 × 7.49 + 5 = 7.247 If you have a modern calculator with an ANS key, the calculations can be simplified dramatically as follows: Type in the first term, i.e. 20, then press the = (or EXE) key. Next, type the whole formula, but press ANS instead of U, thus: 0.3 × ANS + 5 = and the calculator will reward you with 11. Now the good bit: JUST KEEP PRESSING THE = KEY. The calculator sequence loops round, putting each successive answer back into the formula and generating the entire sequence of numbers. You don’t have to worry about rounding off or anything. 116 OUTCOME 3: NUMERACY/HIGHER V V By this line the third decimal place looks like it has settled on 3... V By this line the first decimal place has settled on 1. 20 11 8.3 7.49 7.247 7.1741 7.15223 7.145669 7.1437007 7.14311021 7.142933063 7.142879919 V Try it. You should end up with this sequence of numbers: By this line the second decimal place has settled on 4. ...but in actual fact the third place is 2. RECURRENCE RELATIONS The sequence is heading for a number called a limit. Such a sequence is called convergent. If I keep pressing the = key my calculator display eventually stops changing at 7.142857143, but a calculator with a longer display will just keep on going. Theoretically you cannot get an ‘exact’ limit. The limit is really the number which the sequence would reach if you kept pressing that key forever, which is obviously impossible. But we don’t split hairs about that so we simply say that the limit is 5, or 12.4, or whatever it is. In the last example we can round off the limit, and say it is 7.14 to two decimal places, or 7.1429 to four decimal places, whatever is required (or sensible). ? 5.2 1. Calculate the first four terms of each sequence. (a) (b) (c) (d) 2. Un = 2U n–1 + 3 Un = 0.5Un–1 Un+1 = 3U n Un+1 = ¼U n – 2 where where where where U1 = 4 U1 = 100 U1 = 1 U0 = 60 Sometimes a recurrence relation depends on two (or more) previous terms, in which case we are given two numbers with which to start. The famous Fibonacci Sequence is one of these. Find the first eight terms of this sequence: Un+2 = Un+1 + Un where U 1 = 1and U2 = 1. (This means ‘add the previous two terms to get the next one’, so U3 = U2 + U1, and then U 4 = U3 + U2 and so on.) 3. Use the ANS key as shown above to determine quickly what the following sequences do. If they converge, i.e. tend to a limit, say what this limit is (round off to three decimal places if you have to). A sequence which does not converge is said to diverge or be divergent. When you try to find the limit you get numbers which go off the scale or which wobble about and can’t decide what they want to do. Divergent sequences do not have a limit. (a) (c) (e) Un = 2Un–1; U 1 = 1 Un+1 = 1.5Un + 2; U0 = 1 Un+1 = 0.75U n – 4; U0 = 6 (b) (d) (f) Un+1 = 0.8U n; U 1 = 10 Un = 2Un–1 – 4; U1 = 3 Un+1 = –0.5Un + 3; U 1 = 8 OUTCOME 3: NUMERACY/HIGHER 117 RECURRENCE RELATIONS I hope you weren’t put off by my apparently almost random use of U0 and U 1 as a starting off number. I’ve done so deliberately to get you used to the idea that, in practice, it doesn’t really matter which you use, so long as you can’t get a negative subscript. So when do you know if there is a limit or not? You might have got an idea from the previous exercise. We’ll come back to this later. 5.3 Growth and Decay Factors Suppose you want to increase or decrease a quantity by a percentage. At school, you may well have done it as in the next example. Example 5.3a Jimmy used to get £4.50 a week pocket money. After his birthday he was promised a 10% rise, if he could work the new amount out correctly. What should his new weekly allowance be? Solution: Jimmy’s increase is 10% of £4.50 which is £0.45. New allowance = Old amount + increase = £4.50 + £0.45 = £4.95 Another way of calculating this is as follows. If you think of his old amount (£4.50) as 100%, an increase of 10% will now give Jimmy 110%. 110 = 1.10. 100 Multiplying the old amount £4.50 by 1.10 automatically gives you £4.95, the new, increased quantity. Now, any percentage means ‘over 100’, so 110% = We call the number 1.10 a growth factor. An obvious disadvantage is that if you specifically want the £0.45 increase for some reason, you have to subtract £4.50 from £4.95, but usually it’s the end product you want, not what went on in between. In the same way, if you want to increase a quantity by, say, 4%, you would multiply by 1.04; to increase a quantity by 8.5%, multiply by 1.085 and so on. 118 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS ? 5.3A Complete the blank spaces in this table: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. To increase by 12% 72% 5% 1% 7.5% 96.5% 2% 0.5% 0.1% 100% Multiply by Example 5.3b When Jimmy’s dad bought a new car it cost him £12,500 but, when he tried to sell it, he found it had lost 35% of its value. What was it now worth? Solution: The depreciation is 35% of £12,500 which comes to £4,375. The new value is therefore £12,500 – £4,375 = £8,125. To do this another way, if we call the original £12,500 100%, and we have lost 35%, then we have 65% of the original value left. 65% of £12,500 is, would you believe, £8,125. Again, we have homed in on the final value without calculating the intervening loss. Now 65% as a decimal is 0.65 and we call this the decay factor. Multiplying the original value £12,500 by 0.65 automatically gives you £8,125. Similarly, if you lose 20% of the value, you are left with 80%, giving you a decay factor of 0.80 and if you lose 5% you are left with 95%, a decay factor of 0.95. OUTCOME 3: NUMERACY/HIGHER 119 RECURRENCE RELATIONS ? 5.3B Fill in the blanks in this table to find the relevant decay factors: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. To decrease by 12% 72% 5% 1% 7.5% 96.5% 2% 0.5% 0.1% 100% Multiply by We will now use growth and decay factors in our study of recurrence relations. 5.4 Recurrence Relations of the form Un+1 = aUn Suppose you invested £500 in an account which paid 8% per annum (each year, shortened to p.a.), the interest being credited to the account at the end of each year. The amount is being compounded annually at a rate of 8%. What we have here is, in fact, compound interest. Since the £500 is increasing by 8%, this means that we can apply a growth factor of 1.08 to the £500. At the end of year 1 the account is worth £500 × 1.08 = £540. At the end of year 2 it is no longer £500 which is being increased, but £540. The account is now worth £540 × 1.08 = £583.20. At the end of year 3 we have £583.20 × 1.08 = £629.856 and so on. Each year we multiply what we had the year before by 1.08. A perfect recurrence relation! 120 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS U0 = 500 U1 = 1.08U0 = 1.08 × 500 = 540 U2 = 1.08U 1 = 1.08 × 540 = 583.20 U3 = 1.08U 2 = 1.08 × 583.20 = 629.856 U0 is what we start off with. U 1 is the first calculated figure. It is the amount at the end of year 1. It is very important to be very clear about the exact meaning or status of U1. and so on. The recurrence relation itself is U n+1 = 1.08Un with U 0 = 500. If you want to use the ANS key on your calculator follow the instructions in the box but make sure you keep count of how many times you pressed equals. The calculator will keep umpteen decimal places for you but you will need to round off to the nearest penny. 500 = then 1.08 × ANS then = = = So if the question is ‘How much is in the account after the 7th year?’ you press the key 7 times and round off the display to £856.91. Try it and see. If you want to know how many years it will take for the investment to reach, say £1,000, you have to keep track of how many times you press the = key. The 8th press gives £925.465 . . . The 9th press gives £999.50 . . . almost there! The 10th press takes you beyond the £1,000 to £1,079.46 so technically it takes 10 years to get beyond the £1,000 mark. Example 5.4 A piece of machinery is bought new for £350,000 and depreciates at 15% each year. (a) (b) How much is it worth after four years? It is to be scrapped when it reaches 25% of its original value. If it was bought at the start of 1996, in what year will it be scrapped? Solution: The machinery loses 15% a year, so the decay factor is 100% – 15% = 85% or 0.85. Each year it is worth 0.85 times what it was worth the year before. So the recurrence relation is Un+1 = 0.85Un where U0 = 350,000 and U1 represents the value at the end of year 1, which in this case is the end of 1996. OUTCOME 3: NUMERACY/HIGHER 121 RECURRENCE RELATIONS V V V 1996 1997 1998 1999 2000 2001 2002 2003 2004 You’ll notice that I’ve ignored the pennies here for the purposes of clarity. The calculator keeps them all, though, so the answer should be offered complete with pennies, though I can’t see you being marked wrong for rounding to the nearest £ since we are dealing with thousands of them. (a) ‘after four years’ means ‘end of 1999’, so the answer is £182,702.19. V £350,000 £297,500 £252,875 £214,943 £182,702 £155,296 £132,002 £112,201 £95,371 £81,065 V Following the usual key sequence you will get the following results – they are typed out here, you only need to keep track of where you are. Amounts refer to ‘end of year’. (b) 25% of £350,000 is £87,500, and the calculator sequence of numbers dips below this here. So the machine would be scrapped towards the end of 2004. ? 5.4 In each question you must write down the recurrence relation and clearly define what U 0 and U1 are, as well as answering the specific question(s) asked. 1. £1,000 is invested in an account which has interest compounded at the end of each year at a rate of 7%. (a) (b) 2. An antique painting is bought at the beginning of July for £1.2 million. Each month it appreciates (i.e. increases) in value by 5%. (a) (b) 3. How much is it worth at the end of December? In what month does its value pass £1.75 million? A microscope slide has 35,000 microbes on it (give or take a few) at 6 a.m. Every hour, the number increases by 12%. Assuming there’s room for them all, (a) (b) (c) 122 How much is in the account at the end of the 6th year? How many years pass before the account has doubled in value? how many microbes are there by 9 a.m. how long does it take for the number to double when will the number increase to 100,000? OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS 4. A toxic element is accidentally introduced into a water supply and the concentration is 1.4 parts per million (ppm). Measures taken to reduce this concentration are successful in making it drop by 3% per hour. The safe level of this toxic element is 0.25 ppm. (a) (b) How many hours does it take to reduce the concentration to 1 ppm? How long does it take to make the supply safe? 5. A car radiator has a leak through which 6% of the remaining water escapes every day. The radiator starts full with a capacity of 5 litres of water in it, and the engine will seize up when this drops to half. How many days does the driver have in which to notice the fault before the engine seizes up? 6. A pet shop sells hamsters, of which it initially has 8, which breed at a rate that increases the number of hamsters in the shop by 15% per week. Normally, schoolchildren buy the hamsters and thus manage to keep the numbers in the shop under control. Unfortunately, the seven-week school holidays have just started, the weather is super, children aren’t interested in the hamsters, and so the hamsters just keep on breeding. The shop has enough space for 25 hamsters. Will it run out of space by the time the holidays end? 5.5 An Alternative Formula If you look back at the example of compound interest on page 120 you might realise that there is available to us a slightly different method of solution. U0 = 500 U1 = 1.08 × U 0 U2 = 1.08 × U1 but U1 = 1.08 × U0 so U2 = 1.08 × 1.08 × U0 In other words we can write U2 = 1.082U 0 and similarly U3 = 1.083U 0 and finally the formula Un = 1.08nU 0 So after seven years the amount is 1.087 × 500 = £856.91 as before. OUTCOME 3: NUMERACY/HIGHER 123 RECURRENCE RELATIONS Annual percentage rate (APR) Suppose you borrow (or invest; it works the same way) a sum of money (call it U0) and the monthly interest rate is 2%. After 1 month the value is 1.02 × U0 which is the same as 1.02 1 × U0 After 2 months the value is 1.02 2 × U0 After 3 months the value is 1.02 3 × U0 . . . After 12 months the value is 1.02 12 × U0 The value of 1.02 12 × U0 is 1.26824..., which I will round off to 1.269, which is the same as 126.9 or 126.9%. 100 100% represents the original amount of money, whatever it was, so the 26.9% represents the increase over a period of one year. This 26.9% is the annual percentage rate (APR). The general procedure is as follows. If the monthly rate is r%, we express it as a decimal, then calculate (1+r)12 and then subtract 1. What’s left is the decimal form of the APR. ? 5.5 Find the APR if the monthly interest rate is 1. 2. 3. 4. 124 1% 1.5% 1.75% 2.38% OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS 5.6 Recurrence Relations of the Form Un+1 = aUn + b If you look back to Exercise 5.2 you will see that some of the sequences there were convergent, i.e. they tended to a limit; others were divergent, and did not have a limit. In this section we will look first at when a recurrence relation is convergent, then we’ll discuss some real-life problems and see what relevance this limit has. Activity 5.6a 1. Remind yourself of the special key sequence which generates the list of terms. 2. Check that this list of sequences is convergent, and find the limit of each. (a) (b) (c) (d) 3. Check that this list of sequences is divergent. (a) (b) (c) (d) 4. Un+1 = 0.7Un – 3; U 0 = 6 Un+1 = 0.3Un + 5; U0 = 4 Un+1 = –0.25Un +12; U0 = 10 Un+1 = –0.8Un – 1; U0 = –4 Un+1 = 1.5Un + 5; U0 = 4 Un+1 = 4Un – 3; U0 = 6 Un+1 = –2Un +12; U0 = 10 Un+1 = –2.8Un – 1; U0 = –4 See if you can come up with a conjecture (a theory, an intelligent guess, call it what you will) about what feature of the sequences above makes those for question 2 convergent and those for question 3 divergent. The numerical answers to questions 1 and 2 are on page 136. The answer to question 4 is below, but try to avoid looking at it without a bit of thought on the subject first. The answer is that a relation of the form Un+1 = aUn + b converges to a limit if the number a, i.e. the number multiplying Un in the formula, is between –1 and 1. A quick illustration: Un+1 = 0.75Un + 3; U0 = 5 OUTCOME 3: NUMERACY/HIGHER 125 RECURRENCE RELATIONS The sequence is V Difference between these two numbers is 1.3125 V V Difference between these two numbers is 1.75 Difference between these two numbers is 0.9843 V VV 5 6.75 8.0625 9.0468 ... 9.7851 ... 10.3388 ... 10.7541 ... The difference between each pair of sequence terms is getting smaller, showing that the sequence is convergent. (20 = presses later) 11.9960 ... 11.9970 ... 11.9977 ... (12 more = presses later) 11.9999296 As you can see, the limit appears to be 12, but this sequence is taking its time getting there. This is because the 0.75 is quite big, i.e. relatively close to 1. If you repeat the whole process but replace the 0.75 with 0.25, the limit will change to 4, but you can see this within 6 presses of the = key. Convergence is much faster. Activity 5.6b Now let’s investigate how the limit, when there is one, is affected by the initial value U 0. Take the relation Un+1 = 0.4U n + 5 and find its limit with these different starting values 1. 2. 3. 4. U0 = 10 U0 = 100 U0 = 2 U0 = –50 The answer is on the next page, but don’t look too soon. 126 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS The answer which I hope you got was that the limit is the same (8.3333333) no matter what the starting value is. The limit of the relation Un+1 = aUn + b depends on the values of a and b, but is independent of the value of U 0. You can start the sequence anywhere you like, the limit will (eventually) be the same. Needless to say, there is a formula for this. If you don’t understand the maths of it, don’t worry, because you can simply apply the formula. 5.7 Formula for the Limit Once we start getting close to the limit, successive terms get closer and closer to each other, and the difference between two consecutive terms becomes so small that it gradually disappears. When we ‘reach the limit’ we could thus say that two consecutive terms are both the same. In other words, both Un+1 and Un are equal to each other, and so are both equal to the limit which we can call L. So, at the limit, the equation Un+1 = aUn + b can be written instead as L = aL + b. This can be solved for L as follows: V V V 2. Reduce the two terms involving L to just one term, by taking out L as a common factor. L = aL + b L – aL = b L(1 – a ) = b b L= 1–a 1. Move both terms involving L to one side of the equation. 3. Divide both sides by the bracket (1–a) to get L on its own. The last line is an easy one to remember. Example 5.7 Find the limit of the sequence generated by U n+1 = 0.36Un + 72. b 1–a 72 = 1 – 0.36 72 = 0.64 = 112.5 L= It is most important to establish this fact. V Solution: A limit L exists because 0.36 lies between –1 and 1. So the value of this limit is Just because a formula exists does not mean to say that it makes sense. If the 0.36 was actually, say, 1.36 the formula would give the answer –200 which is nonsense in the context of the sequence. You can always check this out with your calculator, using any number you like as a starter. OUTCOME 3: NUMERACY/HIGHER 127 RECURRENCE RELATIONS ? 5.7 Practise using the formula for the limit on the following sequences to find the limit where it exists. Where there is no limit, say so. 1. 2. 3. 4. 5. 6. 7. 8. Un+1 = 0.5Un + 6 Un+1 = 0.25Un +4 Un+1 = 1.6Un +7 Un+1 = 0.92Un – 8 Un+1 = 3Un + 6 Un+1 = –0.75Un +3 Un+1 = 0.43Un +2.5 Un+1 = –0.2Un – 10 5.8 Problems involving Recurrence Relations And finally, we look at the sorts of questions which will turn up in an assessment. Example 5.8a Each evening, the school caretaker and his team manage to pick up 60% of the litter in the playground, but the next day the little recalcitrants deposit another 3 tonnes of litter. On Monday after school there are 10 tonnes of litter in the playground. (a) How much litter is there on (i) Wednesday afternoon immediately after school (ii) Friday afternoon immediately after school? (b) How much litter is likely to be in the playground long term (before and after cleanup)? Solution: The decay factor is 0.40, because if 60% of the litter is picked up there is still 40% left. If we start with U0 = 10 tonnes, then on the Tuesday immediately after school there is 0.40U0 + 3, i.e. the 40% that’s left plus the new deposit of 3 tonnes. We can thus set up the recurrence relation: Un+1 = 0.40U0 + 3 with U 0 = 10. It is important to remember that each successive value of U is the amount of litter after the pupils have dropped their day’s offering but before the caretaker cleans up. 128 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS Values on the calculator display are thus Mon Tue Wed Thu Fri 10 7 5.8 = answer (a,i) 5.32 5.128 = answer (a,ii) The difference between each successive pair of numbers is decreasing, thus suggesting convergence. The sequence is clearly converging, and this is shown by the fact that the decay factor 0.40 is between –1 and 1. To get the answer to part (b), as we approach the limit L we get L = 0.4L + 3 L – 0.40L = 3 0.60L = 3 3 0.60 =5 L= The following graph should show you what is happening: Start with 10 tonnes 60% = 6 tonnes is picked up, leaving 4 tonnes Day 3 tonnes is added during the day, making 7 tonnes 60% = 4.2 tonnes is picked up, leaving 2.8 tonnes 3 tonnes is added during the day, making 5.8 tonnes 60% = 3.48 tonnes is picked up, leaving 2.32 tonnes and so on. 0 1 2 3 4 5 6 7 8 9 10 Amount before clean-up 10 7 5.8 5.32 5.128 5.0512 5.02048 5.008192 5.0032768 5.0013107 Amount after clean-up 4 2.8 2.32 2.128 2.0512 2.02048 2.008192 2.0032768 2.0013107 2.0005243 5.0005243 2.0002097 10 The top line is the limit of the recurrence relation, showing how much there is after a deposit but before the clean-up. As you see, it levels off at 5 tonnes. 9 No. of tonnes 8 7 6 5 4 3 2 1 0 1 3 5 7 9 11 Day 13 15 17 19 21 The bottom line shows the amount after the clean-up but before the next deposit. It levels off at 2 tonnes. OUTCOME 3: NUMERACY/HIGHER 129 RECURRENCE RELATIONS What actually happens is that the decrease of 60% is larger, at the start, than the increase of 3 tonnes, but as the level of litter gets smaller, so does the amount of decrease (because it is a fixed 60% of an ever smaller number), until it is eventually exactly balanced by the 3 tonne increase. The next worked example will show how a sequence increases towards a limit. Example 5.8b A harbour has 4 metres of silt in it. A dredger is employed to dredge out a channel, and succeeds in removing 25% of the silt each day. However, heavy rains bring down a further 1.5 metres each day. For ships to use the harbour there must be no more than 5 metres of silt in it. Will the harbour be usable? Solution: 25% of the silt is removed so 75% is still there. The decay factor is therefore 0.75, which is just 75% expressed as a decimal. Now we set up the recurrence relation: U0 = 4 U 1 = 0.75U 0 + 1.5 where U 1 is thus the level of silt after the first day’s dredging and also after the first addition of silt by heavy rain. The recurrence relation is thus Un+1 = 0.75Un + 1.5 and we know a limit will exist because 0.75 is between –1 and 1. L = 0.75L + 1.5 L – 0.75L = 1.5 0.25L = 1.5 1.5 0.25 =6 L= Now this 6 metre limit is after the addition of 1½ metres of more silt, so the depth will vary between 4.5 and 6 metres. In other words, there will be times when there are less than 5 metres of silt in the harbour, but also times when there are more. So the harbour will not be safe for use. 130 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS 6.5 2. Level before dredging is above the 5m line. This is the 6m limit of the recurrence relation. 6 Depth of silt 5.5 5 4.5 1. Level after dredging is below the 5m line, which looks safe. 4 3.5 3 2.5 2 1 4 7 10 13 16 19 22 25 28 31 34 37 40 Day Sometimes we have to form one recurrence relation within another. Example 5.8c A patient is being given a new experimental drug. He is initially given a 50mg dose which is to be repeated every 4 hours. The body flushes out 10% of the drug every hour. To be effective, there must be at least 100mg of the drug continually in the body, but it is considered unsafe to give more than 50mg at a time, hence the problem. How many doses are required before there are 100mg of the drug continually in the body? Solution: The first relation: 10% lost per hour, so decay factor 0.90 V See page 123 ‘An Alternative Formula’ if unsure about this step. V V U0 = 50 U1 = 0.90 × U 0 and so on U4 = (0.90)4 × U0 = (0.90)4 × 50 = 32.805 Initial dose. Amount remaining after 1 hour. Amount remaining after 4 hours. 32.805 × 100 = 65.61% left from 50 each 50mg dose. In other words, the decay factor for each 4-hourly dose is 0.6561. So there are 32.805mg left out of 50, which represents So now we look at the recurrence relation which affects the patient every 4 hours: U0 = 50 U1 = 0.6561U0 + 50 NB The decay factor shows how much is left, not how much has gone. where U1 is the amount in the body after the second dose. (This is a situation where it might have been marginally easier to call the first dose U1 instead of U 0.) OUTCOME 3: NUMERACY/HIGHER 131 RECURRENCE RELATIONS U n+1 = 0.6561U0 + 50 is the recurrence relation, and a quick check will show that this has a limit of 145.39mg. On the face of it, this is above the required 100mg level so looks OK, but remember that it is the level after the addition of 50mg. So the amount in the body will vary between 95.39mg and 145.39mg, i.e. there are times when there is less than the required 100mg in the body, so the drug will not be wholly effective. Had the required effective level been, say, 90mg, then we would have been OK. And so would the patient. I hope this example demonstrates that you mustn’t just look at the value of the limit. You must also look at the value immediately before, in other words at the whole range of values which the limit actually represents. ? 5.8 1. A pond has an absolutely massive supply of frog spawn. Every night another 400 tadpoles are born, and every day predators eat 70% of the tadpoles in the pond at that time. If we start off with 500 tadpoles on the Monday morning, how many are there on Tuesday morning? On Tuesday night? On Wednesday morning? What is the long-term position? (In other words, is there a limit, and if there is, what is it?) 2. A large herd of deer is causing a nuisance on a Highland estate. Every spring approximately 150 new calves are born, so the owner allows a cull of 20% of the deer population each autumn. In the summer of 1995 there were 1,000 deer on the estate. How many will there be by the summer of 1996? Of 1997? Of 1998? Will the number of deer level off? 3. A fish farm stocks its ponds with 5,000 new fish. Every year the fish population increases by approximately 15%, and the owner allows 1,000 fish to be caught. If you assume the increase comes before the fish are taken out, calculate the first few terms of the sequence and decide if the sequence is convergent or divergent. Is the owner allowing too many or too few fish to be caught? 4. A forestry company has a forest with an area of approximately 750 hectares, of which only 500 hectares is actually planted. During the summer, approximately 18% of the planted area is cut, and another 75 hectares is planted out in the autumn. Does the company have spare capacity for the foreseeable future, or will it have to buy more land to keep up this rate of activity? 5. A city manager finds that every day the population dumps 15 tonnes of litter in the city centre, but squads of cleaners, who operate during the night, only manage to lift 132 OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS 60% of it. On the evening of 17 May there are 25 tonnes of litter in the city centre. How many tonnes are there (a) on the evening of 20 May (b) on the evening of 22 May? What’s going on? 6. In the same city centre as in question 5, there is a new manager. She pays her squads more and they lift 80% of the litter. How long does it take to get the amount of litter permanently below 18 tonnes, starting at 25 tonnes again? 7. The same situation as in question 5, but two years and a massive public education campaign later. The public now drop only 10 tonnes of litter per day, and squads pick up 95% of the total at night. How much litter is on the streets every morning? 8. A captured spy is given 150 units of a truth drug every hour to make him talk. Every hour the body gets rid of 30% of the drug. The drug is only effective if there are at least 300 units continuously in the body. If the spy is given the first dose at 8 a.m., at what time can questioning begin? 9. Another spy is given a different drug. This drug is given every 6 hours in 100mg doses. The body gets rid of 5% of the drug every hour. (a) (b) 10. How many doses are needed to keep the level continuously above 250mg? In the long term, what will be the range of values between which the amount of drug in the body will lie, and how will this affect the spy if a dose of over 360mg is fatal? In order to safeguard depleted fishing stocks, the appropriate ministry orders a cull of seals, of which there are 200,000. Each spring this number increases by 15%. (a) (b) How many seals must be culled each summer to keep the number of seals at its present level? In fact, 40,000 seals are killed each summer. How many culls must be made to bring the number of seals down to 100,000? 11. A car engine holds 5 litres of oil, but a leak is causing it to lose 22% of its oil each month. At the end of each month the owner adds 600ml of oil. The engine will seize up if the oil level drops at any time to less than half the capacity. Is the owner's replacement policy a safe one? 12. It is winter, and a plant is 80cm tall. Each spring it is pruned by 20%. It has been genetically modified to grow exactly 35 cm each year. The target height is a maximum of 1.8m. Will this pruning policy achieve this? OUTCOME 3: NUMERACY/HIGHER 133 RECURRENCE RELATIONS Answers ?5.1: Answers 1. (a) U1 = 2 × 1 + 7 = 9 U2 = 2 × 2 + 7 = 11 U3 = 2 × 3 + 7 = 13 (b) U1 = 12 + 1 = 2 U2 = 22 + 1 = 5 U3 = 32 + 1 = 10 2. (a) (b) (c) (d) (e) U4 = 5 × 42 = 80 U5 = 52 + 3 × 5 – 2 = 38 U8 = (–1)8 × 3 × 8 = 24 U8 = (–1)9 × (2 × 8 + 1) = –1 × 17 = –17 U7 = (7 – 3)2 = 16 3. (a) (b) 2, 4, 8, 16 2, 4, 8, 14 (c) U 1 = 5 – 21 = 3 U 2 = 5 – 22 = 1 U 3 = 5 – 23 = –3 First three terms are the same, the fourth (and subsequent) terms are different. You frequently need more than just three terms to know what’s what. ?5.2: Answers 1. (a) (b) (c) (d) 2. 1, 1, 2, 3, 5, 8, 13, 21, 33, 54 3. (a) (b) (c) (d) (e) (f) 134 4, 11, 25, 53, 109 100, 50, 25, 12.5, 6.25 1, 3, 9, 27, 81 60, 13, 1.25, –1.6875, –2.421875 1, 2, 4, 8, 16 divergent 10, 8, 6.4, 5.12, 4.096 convergent, in fact heading for 0 1, 3.5, 7.25, 12.875 divergent 3, 2, 0, –4, –12 divergent 6, 0.5, –3.625, –6.71875 convergent, limit is –16 8, –1, 3.5, 1.25, 2.375, 1.8125 convergent, limit 2. This last one wobbles about above and below the limit before settling. We say a sequence like this oscillates towards the limit. OUTCOME 3: NUMERACY/HIGHER RECURRENCE RELATIONS ?5.3A: Answers 1. 4. 7. 10. 1.12 1.01 1.02 2 2. 5. 8. 1.72 1.075 1.005 3. 6. 9. 1.05 1.965 1.001 Watch that last one. Increasing something by 100% means you are doubling it. ?5.3B: Answers 1. 4. 7. 10. 0.88 2. 0.28 3. 0.95 0.99 5. 0.925 6. 0.035 0.98 8. 0.995 9. 0.999 0 (if you decrease something by 100% you wipe it out!) ?5.4: Answers 1. U0 = £1,000 U1 = amount at end of year 1 = 1.07 × U0 Un+1 = 1.07 Un (a) (b) 2. U0 = £1.2m = beginning of July U1 = amount at end of July = 1.05 × U0 Un+1 = 1.05 Un (a) (b) 3. £1.5315 ...million = £1,531,538 Just passes £1.75m at end of March U0 = 35,000 = amount at 6 a.m. U1 = amount at 7 a.m. = 1.12 × U0 Un+1 = 1.12 Un (a) (b) (c) 4. £1,500.73 11 years (£2,104.85) 49,172 12 noon – 69,083; 1p.m. – 77,373 i.e. just over 6 hours Somewhere between 3 p.m. and 4 p.m. Un+1 = 0.97 U n ; U0 = 1.4 ppm; U 1 = amount after 1 hour (a) 12 hours OUTCOME 3: NUMERACY/HIGHER 135 RECURRENCE RELATIONS (b) 57 hours to get just below 0.25 ppm (The nearer the decay factor is to 1, the longer it takes.) 5. Un+1 = 0.94 U n; U0 = 5 litres; U1 = amount after 1 day 11 days to notice problem, 12th day level dips to 2.37 which is below 2.5 6. Un+1 = 1.15 Un; U0 = 8 hamsters; U1 = amount after 1 week At the end of the 7th week of holiday there are 21.78 hamsters, so assuming the children start buying as soon as they’re back at school there’s room for them. ?5.5: Answers 1. 2. 3. 4. (1.01)12 = 1.1268 ....; APR = 12.68% (1.015)12 = 1.1956 ...; APR = 19.56% (1.0175)12 = 1.2314 ....; APR = 23.14% (1.0238)12 = 1.3261 ....; APR = 32.61% Activity 5.6a 1. Type the first term then press the = or EXE key. Type in the equation, but replace U n with the ANS key, e.g. instead of typing 0.54 × U n + 3 you would type 0.54 × ANS + 3. Then press = as often as you need, either keeping count of the number of presses or writing the answers down. 2. (a) (b) (c) Limit –10 (exact) Limit 7.1429 (to 4 d. p. – this is optional, could be to 3 or 2 if you want) Limit 0.96 (exact) (d) Limit –0.5556 to 4 d.p. (in fact, it is the exact fraction ?5.7: Answers 1. 12 2. 5 13 3. 4. 5. 6. 7. No limit because 1.6 is outside the –1 to +1 range –100 No limit 1.7143 4.3860 8. –8 13 136 OUTCOME 3: NUMERACY/HIGHER 5 9 ). RECURRENCE RELATIONS ?5.8: Answers 1. Monday morning 500 Monday night 150 Tuesday morning 550 Tuesday night 165 Wednesday morning 565 Un+1 = 0.30U n + 400 is convergent because 0.30 is between –1 and 1. Limit 571 tadpoles 2. 1995 – 1,000; 1996 – 950; 1997 – 910; 1998 – 878 Un+1 = 0.80Un + 150 and the limit exists because 0.80 is between –1 and +1. Limit = 750 3. 5000; 4750; 4462; 4131 (omitting the decimal parts) The differences between terms are increasing so the sequence is divergent, and this is confirmed by the relation Un+1 = 1.15Un – 1,000. Eventually the sequence gets to 0 or beyond; too many fish are being taken out. 4. Un+1 = 0.82Un + 75 with U0 = 500, though, as we know, the limit is independent of the first term. The limit is 416.67 which means there is approximately 83 hectares spare capacity. 5. Un+1 = 0.40Un + 15, U0 = 25 (a) 25 tonnes (b) 25 tonnes Exactly the same amount is being picked up as is being dropped. 6. Un+1 = 0.20Un + 15, U0 = 25 Limit exists; it is 18.75 so the level settles down eventually to between 3.75 (each morning) and 18.75 (each evening). It never completely falls below 18 tonnes. 7. Un+1 = 0.05Un + 10 and the limit is 10.53, i.e. the level varies between 0.53 and 10.53. 8. Un+1 = 0.70Un + 150; U0 is 1st dose at 8 a.m., U 1 is amount in body after 2nd dose, 9 a.m. 9 a.m. 10 a.m. 11 a.m. 12 noon 1 p.m. 2 p.m. 255 328 379 415.965 441.175 458.175 The 1p.m. dose is the first one which doesn’t drop to below 300. OUTCOME 3: NUMERACY/HIGHER 137 RECURRENCE RELATIONS 9. Hourly sequence is Un+1 = (0.95)6 × Un which means that the initial 100 mg drops to 73.51 mg, a decay factor of 0.7351. The 6-hourly sequence is therefore Un+1 = 0.7351U n + 100 The 9th dose takes you to 353.84 so it must have been 253.84 immediately beforehand. The limit is 377.5 so the dose varies between 277.5 and 377.5 and, since 360 mg is fatal, the spy is in serious trouble. 10. (a) (b) 11. Un+1 = 0.78U n + 600 The limit is 2,727.27 but this is after 600 ml has been added, so the range of values is 2,127 up to 2,727. So it drops below 2,500 and the policy is unsafe. 12. Un+1 = 0.80Un + 35 for which the limit is 175 cm, but this is after the 35 cm growth, so the policy will keep the plant below 180 cm. 138 30,000 Un+1 = 1.15Un – 40,0000; U0 = 200,000 7 culls take the number down to 89,332. OUTCOME 3: NUMERACY/HIGHER TUTOR ASSIGNMENTS Mean and Standard Deviation T1 The table shows how many minutes, to the nearest tenth of a minute, it took for a task to be completed by a number of clerical staff. Calculate the mean and standard deviation of the data. Time (min) 10.0-10.4 10.5-10.9 11.0-11.4 11.5-11.9 12.0-12.4 12.5-12.9 13.0-13.4 TOTAL No. of staff 5 12 23 10 5 2 1 58 OUTCOME 3: NUMERACY/HIGHER 139 TUTOR ASSIGNMENTS Median and Quartiles T2 Calculate the median, the other two quartiles, and the semi-interquartile range, for the following: 1. 31 22 45 24 30 33 40 19 27 22 34 26 24 2. The table shows how many faulty light bulbs there are in boxes of six. No. faulty No. of boxes 3. 0 47 2 20 3 8 4 5 5 3 6 1 This table shows the value of sales made by 80 sales persons working for a company during a period of time: Value of sales (£000) No. of salespersons 140 1 53 25-30 1 OUTCOME 3: NUMERACY/HIGHER 30-35 14 35-40 23 40-45 21 45-50 15 50-55 6 TUTOR ASSIGNMENTS Transposition of Formulae T3 Transpose these formulae: ab 3c 1. W= 2. P = ab – 3. A= to (a) a (b) c c to (a) a (b) c 5 – pq q to (a) p (b) q 4. R = 3π(t – 2m) to (a) t (b) m 5. Z =4 (a) x (b) y 1 2 x –y y to OUTCOME 3: NUMERACY/HIGHER 141 TUTOR ASSIGNMENTS Correlation and Regression T4 The table shows ten mythical local authorities with the population of each and the amount spent on a certain aspect of health care. Authority A B C D E F G H I J Population 145,000 236,000 95,000 142,000 178,000 263,000 74,000 137,000 89,000 312,000 Amount spent (£m) 7.2 9.5 3.6 4.2 9.3 10.1 3.9 5.6 3.3 11.4 (a) Draw the scatter diagram on squared paper. (b) Make up a table which will allow you to estimate the amount spent for a given population (so get your x and y the right way round). (c) Calculate the equation of the line of regression and also the value of the correlation coefficient. (d) Draw the regression line on your scatter diagram. (e) Use the line of regression to make a point estimate about the amount which ‘should’ be spent by local authorities with the following populations: (i) (ii) (f) 142 153,000 406,000 Make comments about the reliability of each of these estimates, making sure you use one of your previous calculations to back up your argument. OUTCOME 3: NUMERACY/HIGHER TUTOR ASSIGNMENTS Recurrence Relations T5 1. 2. 3. A painting appreciates in value by 15% each year. It is initially worth £1 million. (a) Write down a formula which will allow you to home in on its value after any number of years. Then find its value after (i) 3 years (ii) 5 years. (b) Write down a recurrence relation which ties the value each year to the value the previous year. How many years is it before the painting trebles in value? At the beginning of November a person borrows £4,000 and agrees to pay back £500 at the beginning of each month after this (i.e. first repayment at the beginning of December). However, during every month the amount owed increases by 2% of the value at the start of the month. (a) Writing down the amount owing every month as you go, calculate during which month the loan will be eventually paid off. In other words, number crunch your way through the problem. (b) Write down the problem in the form of a recurrence relation which allows you the use of the ANS key. There are an estimated 20 million brownling fish in the sea. During the breeding season there is an estimated 8% increase in the number of fish. After this comes the fishing season and fishermen are allowed to catch 1,750,000 fish. (a) (b) (c) 4. Write down the number of fish in the sea each year in the form of a recurrence relation. How many fish will be in the sea after four years? Does the relation have a limit? If so, find it and say what it means; if not, why not? And what are the implications for the fish? In November a turkey farmer has 6,000 turkeys. Each following Christmas he sells off 20% of them and buys in 2,000 chicks which he then brings on for the next season. (a) (b) Write down a recurrence relation for the number of turkeys. Find the farmer’s long-term position if he continues this policy. OUTCOME 3: NUMERACY/HIGHER 143