Information Theory Huffman Coding
advertisement

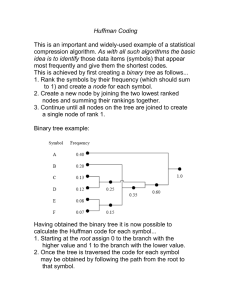
College of Information Technology 1 Information Theory Huffman Coding Huffman (1952) devised a variable-length encoding algorithm, based on the source letter probabilities. This algorithm is optimum in the sense that the average number of binary digits required to represent the source symbols is a minimum, subject to the constraint that the code words satisfy the Prefix condition. The steps of the Huffman coding algorithm are given below: 1- Arrange the source symbols in decreasing order of their probabilities. 2- Take the bottom two symbols and tie them together as shown below. Add the probabilities of the two symbols and write it on the combined node. Label the two branches with 1 and 0. 3- Treat this sum of probabilities as a new probability associated with new symbol. Again pick the two smallest Probabilities. Tie them together to form a new probability. Whenever we tie together two probabilities (nodes) we label the two branches with 1 and 0. 4- Continue the procedure unit only one probability is left (and it should be 1).This completes the construction of the Huffman tree. 5- To find out the prefix codeword for any symbol, follow the branches from the final node back to the symbol. While tracing back the route read out the labels on the branches. This is the code word for the symbol. Ex: Consider a DMS with seven possible symbols having the probabilities of occurrence illustrated in table. symbol 𝑥1 probability 0.35 Self-information 1.5146 0.30 1.7370 0.20 2.3219 Codeword College of Information Technology 2 Information Theory 0.10 𝑥5 3.3219 0.04 4.6439 0.005 7.6439 0.005 7.6439 College of Information Technology 3 Information Theory Ex: Determine the Huffman code for the output of a DMS given in table symbol 𝑥1 probability 0.36 0.14 0.13 0.12 𝑥5 0.10 0.09 0.04 0.02 Self-informatio n Codeword College of Information Technology 4 Information Theory #-Instead of encoding on symbol-by-symbol basis, a more efficient procedure is to encode blocks of J symbols at a time. In such a case, since the entropy of a J-symbol block from a DMS is , College of Information Technology 5 Information Theory The average number of bits per J-symbol blocks. If we divide Eq. by J we obtain Ex: The output of a DMS consists of letters with probabilities 0.45, 0.35 and 0.20 respectively. The Huffman code for this source is: Symbol 𝑥1 Probability 0.45 Self-information 1.156 0.35 1.520 0.20 2.330 Codeword If Pairs of symbols are encoded by Huffman algorithm. The results is College of Information Technology 6 Information Theory symbol probability 0.2025 0.1575 0.1575 0.1225 0.09 0.09 0.07 0.07 0.04 Self-informatio n Codeword College of Information Technology 7 Information Theory