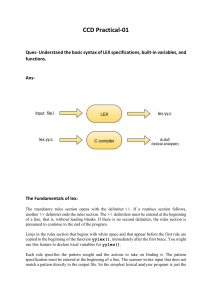
• Review: Regular expression: – How do we define it?
advertisement

• Review: Regular expression:
– How do we define it?
• Given an alphabet ,
• Base case:
–
is a regular expression that denote { }, the set that
contains the empty string.
– For each a
, a is a regular expression denote {a}, the
set containing the string a.
• Induction case:
– r and s are regular expressions denoting the language (set)
L(r ) and L(s ). Then
» ( r ) | ( s ) is a regular expression denoting L( r ) U L(
s)
» ( r ) ( s ) is a regular expression denoting L( r ) L ( s )
» ( r )* is a regular expression denoting (L ( r )) *
• Lex -- a Lexical Analyzer Generator (by M.E.
Lesk and Eric. Schmidt)
• Lex source program
{definition}
%%
{rules}
%%
{user subroutines}
Rules: <regular expression>
<action>
Each regular expression specifies a token.
Default action for anything that is not matched: copy to the
output
Action: C source fragments specifying what to do when a
token is recognized.
• lex program examples: ex1.l and ex2.l
– ‘lex ex1.l’ produces the lex.yy.c file.
– The int yylex() routine is the scanner that finds
all the regular expressions specified.
• yylex() returns a non-zero value (usually token id)
normally.
• yylex() returns 0 when end of file is reached.
• Need a drive to test the routine.
– You need to have a yywrap() function in the lex
file (return 1).
• Something to do with compiling multiple files.
• Lex regular expression: contains text
characters and operators.
– Letters of alphabet and digits are always text
characters.
• Regular expression integer matches the string
“integer”
– Operators: “\[]^-?.*+|()$/{}%<>
• When these characters happen in a regular
expression, they have special meanings
– operators (characters that have special meanings):
“\[]^-?.*+|()$/{}%<>
• ‘*’, ‘+’, ‘|’, ‘(‘,’)’ -- used in regular expression
• ‘ “ ‘ -- any character in between quote is a text character.
– E.g.: “xyz++” == xyz”++”
• ‘\’ -- escape character,
– To get the operators back: “xyz++” == ??
– To specify special characters: \40 == “ “
• ‘[‘ and ‘]’ -- used to specify a set of characters
– e.g: [a-z], [a-zA-Z],
– Every character in it except ^, - and \ is a text character
– [-+0-9], [\40-\176]
• ‘^’ -- not, used as the first character after the left bracket
– E.g [^abc] -- everything except a, b or c.
– [^a-zA-Z] -- ??
– operators (characters that have special
meanings):
“\[]^-?.*+|()$/{}%<>
• ‘.’ -- every character
• ‘?’ -- optional ab?c matches ‘ac’ or ‘abc’
• ‘/’ -- used in character lookahead:
– e.g. ab/cd -- matches ab only if it is followed by cd
• ‘{‘’}’ -- enclose a regular definition
• ‘%’ -- has special meaning in lex
• ‘$’ -- match the end of a line, ‘^’ -- match the
beginning of a line
– ab$ == ab/\n
• ‘<‘ ‘>’: start condidtion (more context sensitivity
support, see the paper for details).
– Order of pattern matching:
• Always matches the longest pattern.
• When multiple patterns matches, use the first pattern.
– To override, add “REJECT” in the action.
...
%%
Ab
Abc
{letter}{letter|digit}*
{printf(“rule 1\n”);}
{printf(“rule 2\n”);}
{printf(“rule 3\n”);}
%%
Input: Abc
What happened when at ‘.*’ as a pattern?
– Manipulate the lexeme and/or the input stream:
• yytext -- a char pointer pointing to the matched string
• yyleng -- the length of the matched string
• I/O routines to manipulate the input stream:
– input() -- get a character from the input character, return <=0
when reaching the end of the input stream, the character
otherwise
– unput( c ) -- put c back onto the input stream
– Deal with comments: (/* ….. */
» “/*”.*”*/” ???
%%
…
“/*”
{char c1;
c2 = input();
if (c2 <=0) {lex_error(“unfinished comment” …}
else { c1 = c2; c2 = input();
while (((c1!=‘*’) || (c2 != ‘/’)) && (c2 > 0)) {c1 = c2; c2 = input();}
if (c2 <= 0) {lex_error( ….)
}
– Reporting errors:
• What kind of errors? Not too many.
– Characters that cannot lead to a token
– unended comments (can we do it in later phases?)
– unended string constants.
• How to keep track of current position (which line, which
column)?
– Use to global variable for this: yyline, yycolumn
%{
int yyline = 1, yycolumn = 1;
%}
...
%%
[ \t\n]+
If
“+”
{letter}{letter|digit}*
...
%%
{/* do nothing*/}
{return (IFNumber);}
{return (PLUSNumber);}
{yylval = idtable_insert(yytext); return(IDNumber);}
– Reporting errors:
• How to report an error character that cannot lead to a token?
• How to deal with unended commend?
• How to deal with unended string?
• Dealing with identifiers, string constants.
– Data structures:
• A string table that stores the lexeme value.
• To avoid inserting the same lexeme multiple times, we will
maintain an id table that records all identifiers found. Id table
will have pointer pointing to the string table.
– Implementation of the id table: hash_table, link list, tree, …
– The hash_table implementation in page 433-436.
cp
n
match
last
i
c p ‘\0’ n ‘\0’ m a t c h ‘\0’ l a s t ‘\0’ I ‘\0’ j ‘\0’
j
• Some code piece for the id table:
#define STRINGTABLELENGTH 20000
#define PRIME 997
struct HashItem {
int index;
struct HashItem *next;
}
struct HashItem *HashTable[PRIME];
char StringTable[STRINGTABLELENGTH];
int StringTableIndex=0;
int HashFunction(char *s);
/* copy from page 436 */
int HashInsert(char *s);
– Internal representation of String constants:
• Needs conversion for the special characters.
• “abc” ==> ‘a’’b’’c’’\0’
• “abc\”def” ==> ‘a’’b’’c’”’d’’e’’f’’\0’
• “abc\n” ==> ‘a’’b’’c’’\n’
– Recognizing constant strings with special
characters
• Assuming string cannot pass line boundary.
• Use yymore()
“[^”\n]*
{char c;
c = input();
if (c != ‘”’) error
else if (yytext[yyleng-1] == ‘\\’) {
unput( c ); yymore();
} else {/* find the whole string, normal process*/}
Put it all together
• Checkout token.l program.