Exploring the Sources of Default Clustering ∗ July 17, 2015
advertisement

Exploring the Sources of Default Clustering∗
S. Azizpour, K. Giesecke, G. Schwenkler
July 17, 2015†
Abstract
The U.S. economy has repeatedly suffered significant clusters of corporate default
events. This paper studies the sources of clustering using data on industrial and
financial default timing in the U.S. between 1970 and 2012. We find strong evidence
for the existence of several clustering channels, including firms’ joint exposure to
macroeconomic factors such as GDP growth, the influence of a common latent factor
with mean-reverting behavior, and the impact on firms of past default events. Our
results have important implications for the management of portfolio credit risk at
financial institutions as well as the risk analysis and pricing of securities exposed to
correlated default risk.
∗
This paper is a significant revision of an earlier paper by the first two authors entitled “Self-Exciting
Corporate Defaults: Contagion vs. Frailty.” Azizpour is at Apollo Global Management, Giesecke is at the
Department of Management Science & Engineering, Stanford University, Schwenkler is at the Department
of Finance, Boston University Questrom School of Business. Schwenkler is corresponding author: Phone
(617) 358-6266, email: gas@bu.edu, web: http://people.bu.edu/gas/.
†
We are grateful for grants from Moody’s Corporation and the Global Association of Risk Professionals, and for data from Moody’s. Schwenkler was supported by a Mayfield Stanford Graduate Fellowship
and a Lieberman Fellowship. We thank Richard Cantor for providing access to data, Antje Berndt, Jens
Christensen, Darrell Duffie, Andreas Eckner, Jean-David Fermanian, Lisa Goldberg, Albert Kyle, Francis
Longstaff, Michael Ohlrogge, George Papanicolaou, Bjorgvin Sigurdsson, Ken Singleton, Justin Sirignano, Ilya Strebulaev, Stefan Weber, Liuren Wu, Fan Yu, and seminar participants at the 5th Bachelier
World Congress, the 14th FDIC/JFSR Annual Bank Research Conference, the 2014 MFA Conference,
the 2015 AFA Meetings, Boston University, Columbia University, the Federal Reserve Bank of San Francisco, Georgia Institute of Technology, the International Monetary Fund, Princeton University, Stanford
University, the University of Illinois at Urbana-Champaign, and the University of Southern California
for discussions and comments, and Xiaowei Ding, Baeho Kim, Supakorn Mudchanatongsuk, and Hannan
Zheng for excellent research assistance.
1
1
Introduction
The U.S. economy has repeatedly suffered significant clusters of corporate default events.
Examples include the savings and loan crisis of the early 1990s, the burst of the dotcom
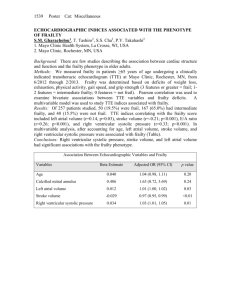
bubble in 2001, and the financial crisis of 2007-09. Figure 1, which shows the annual
number of defaults of U.S. industrial and financial firms with Moody’s rated debt between
1970 and 2012, illustrates these events. This paper analyzes the potential sources of the
clusters observed in the default timing data. An understanding of these sources is crucial
for the measurement of portfolio credit risk at financial institutions, the management of
systemic financial risk, as well as the risk analysis and valuation of securities exposed to
correlated corporate default risk, such as collateralized debt obligations.
A major source of default clustering is the joint exposure of firms to common or
correlated risk factors such as interest rates, stock returns, and GDP growth.1 The movements of these factors cause correlated changes in firms’ conditional default rates. For
example, strong economic growth often reduces the likelihood of default across the board.
In an important paper, however, Das, Duffie, Kapadia & Saita (2007) provide strong evidence that this channel on its own cannot explain the degree of clustering observed in
U.S. industrial defaults between 1979 and 2004. Their findings suggest the existence of
additional clustering channels. Using data on industrial and financial default timing in
the U.S. between 1970 and 2012, we study the empirical significance of latent variables
(frailty) and contagion for default clustering. In particular, we test whether frailty and
contagion are potential sources of the excess clustering that Das et al. (2007) found to be
unexplained by firms’ joint exposure to common systematic risk factors.
The cases for frailty and contagion as potential clustering channels are easily made.
Chava, Stefanescu & Turnbull (2011), Duffie, Eckner, Horel & Saita (2009), Koopman,
Lucas & Monteiro (2008), Koopman, Lucas & Schwaab (2011), Monfort & Renne (2013),
and other authors provide strong empirical evidence that some of the systematic risk
factors influencing firms’ conditional default rates have not been identified or are simply
unobservable. The uncertainty regarding the current values of these latent frailty factors,
and the future time variation of these factors, have an influence on the conditional default
rates of the firms that depend on the same frailty factors. This influence generates correlation between firms’ conditional default rates beyond the correlation due to the future
movements of the observable systematic factors that have already been accounted for; see
Benzoni, Collin-Dufresne, Goldstein & Helwege (2015), Giesecke (2004), and others for
theoretical models of this mechanism. The additional correlation caused by frailty might
be responsible for the excess clustering found by Das et al. (2007).
There is also strong empirical evidence of contagion effects. Financial, legal, or business relationships between firms might act as a conduit for the spread of risk. For instance,
1
Campbell, Hilscher & Szilagyi (2008), Chava & Jarrow (2004), Duffie, Saita & Wang (2007), Giesecke,
Longstaff, Schaefer & Strebulaev (2011), Lando & Nielsen (2010), Shumway (2001), and others analyze
the significance of these and other factors for U.S. default timing.
2
150
100
0
50
Defaults per year
1970
1980
1990
2000
2010
Figure 1: Annual number of defaults of U.S. firms with Moody’s rated debt. Source:
Moody’s Default Risk Service.
a default by the protection seller in a credit swap could expose the buyer of protection and
increase the default risk borne by the protection buyer’s other counterparties, see Stulz
(2010). A related example is the collapse of Lehman Brothers in 2008, which pushed some
of Lehman’s creditors, trading partners and clients into financial distress, see Aragon &
Strahan (2012), Brunnermeier (2009), Chakrabarty & Zhang (2012), Dumontaux & Pop
(2013), Fernando, May & Megginson (2012), and others. Contagion is not limited to the
financial sector. For example, the default by major parts supplier Delphi in 2005 exposed
General Motors, as indicated by a jump in GM’s stock price and credit swap spreads.
Bams, Pisa & Wolff (2014), Boone & Ivanov (2012), Jorion & Zhang (2009), and Lang
& Stulz (1992) provide evidence of default spillover effects on business partners. With
contagion, the default by one firm may have a direct impact on the conditional default
rates of other firms, as in the network models of Acemoglu, Ozdaglar & Tahbaz-Salehi
(2015), Eisenberg & Noe (2001), and Elliott, Golub & Jackson (2014). This impact causes
correlation between firms’ conditional default rates beyond the correlation due to firms’
exposure to observable and frailty factors. Thus, contagion might be another source of
the excess clustering uncovered by Das et al. (2007).
We develop tests to analyze whether frailty and contagion are potential sources of
the default clustering in the U.S. not due to firms’ exposure to observable systematic
factors. Our tests are based on a new reduced-form model of correlated default timing,
which addresses firms’ exposure to observable factors, a latent frailty factor, and failure
events. The conditional rate of defaults is allowed to depend on time-varying factors
3
that are observable throughout the sample period, a latent frailty factor with square-root
dynamics that is not observable at all, and past failures. A default event ramps up the
conditional arrival rate. The impact depends on the amount of defaulted debt and decays
with time. Our model extends the standard doubly-stochastic formulation widely used in
theoretical and empirical analyses of correlated default risk (see Chava & Jarrow (2004),
Duffie & Garleanu (2001), Duffie et al. (2007), Jarrow, Lando & Yu (2005), Mortensen
(2006), and others). In a doubly-stochastic formulation, default arrivals are assumed to be
conditionally Poisson given the paths of the observable risk factors, and the only potential
source of default clustering is firms’ joint exposure to these factors. Our model also extends
a richer formulation with observable factors and a latent frailty factor, in which arrivals are
assumed to be conditionally Poisson given the paths of all factors. The doubly-stochastic
assumption imposes strong restrictions on the conditional distribution of events since it
precludes a direct influence of past failures on the conditional default rate. Because we do
not make the doubly-stochastic assumption, we avoid such restrictions. By allowing the
conditional default rate to depend on past failures, our model of correlated default risk
generates a much richer set of event distributions.
We test a series of hypotheses regarding the roles of frailty and contagion. The results
of these tests strongly suggest that both frailty and contagion are significant sources of
clustering after controlling for the influence of the macroeconomic risk factors that prior
studies have identified as predictors of U.S. defaults. Specifically, the likelihood estimates
of our model highlight the significant dependence of conditional default rates on past
failures as well as a latent frailty with strong mean-reverting behavior. A default is found
to have a persistent impact on the default rate, with a half-life of about 3 months. Upon
a default event with $173 million of defaulted debt, the average in our data set, the
default rate increases by roughly 2.8 events per year. Likelihood ratio tests suggest that
the contagion channel takes a somewhat more prominent role than the frailty channel
for explaining the default clusters in the data. A decomposition of conditional default
rates highlights the dominant role of the contagion channel during clustering episodes,
such as the crisis of 2007-09. These findings provide empirical support for the network
models of Acemoglu et al. (2015), Eisenberg & Noe (2001), Elliott et al. (2014), and
many others, which emphasize the contagion channel. Robustness tests confirm that our
results survive after removing financial firm defaults from our analysis, indicating that
an industrial default event might cause the same contagion effects as a similarly sized
financial default event. This observation complements the current debate about contagion
and frailty effects in the financial sector; see, for example, Baur (2012), Chakrabarty &
Zhang (2012), Helwege & Zhang (2012), and Lee & Poon (2014).
Time-change tests indicate the importance of the frailty and contagion channels for
fitting the significant time-variation of the event arrival rate during the sample period
1970–2012. We find evidence that a model ignoring the contagion channel tends to overstate the significance of the frailty channel. Out-of-sample tests of forecast accuracy for
several test credit portfolios indicate that ignoring the contagion channel also leads to ex4
cessively high and volatile forecasts of portfolio credit risk. This finding is consistent with
the results of Gouriéroux, Monfort & Renne (2014), who show that a CDS pricing model
that ignores the contagion channel tends to overstate risk-neutral default probabilities.
Only when addressing all three sources of default clustering do we obtain accurate and
sensible out-of sample forecasts of correlated default risk in the United States.
Our empirical analysis yields several additional insights into the nature of correlated default risk. We find that the firm-specific risk factors the literature has identified
as significant predictors of firm-level default contain only little information about correlated default risk. For example, Duffie et al. (2007), Duffie et al. (2009), and Lando &
Nielsen (2010) find that distance-to-default, a volatility-adjusted measure of leverage, is
the most statistically and economically significant predictor of firm-level default in the
United States. However, when we aggregate the cross section of distance-to-default of
publicly traded firms between 1991 and 2012, and regress a cross-sectional average on an
extensive list of standard macroeconomic default risk factors, we find that these factors
can explain about 71% of the time-variation of the cross sectional distance-to-default average. We obtain similar results for other firm-specific default risk factors, such as leverage,
volatility, and short-term debt ratio. Further, the residuals of these regressions can only
explain a small fraction of the portion of the default rate not tied to the macroeconomic
risk factors. Thus, firm-specific risk factors are less relevant for clustered default risk, after
controlling for the influence of macroeconomic default risk factors as well as the contagion
and frailty channels. This finding complements the results of Bharath & Shumway (2008),
Campbell et al. (2008), Tian, Yu & Guo (2015), and others, who find that distance-todefault plays only a minor role for forecasting firm-level defaults. Our results also suggest
that there is extensive commonality in the cross-section of idiosyncratic risk factors influencing default timing. This observation complements recent findings by Atkeson, Eisfeldt
& Weill (2014), who show that there is strong comovement in the cross-section of a financial soundness measure known as distance-to-insolvency.
Our results have significant implications for the management of credit risk at financial institutions. Most importantly, our results indicate that the doubly-stochastic models
of correlated default risk widely used to measure portfolio credit risk in practice may
understate the risk of large losses from defaults, especially during clustering periods such
as 2001-02 and 2007-09. As a result, financial institutions may end up with capital buffers
that are inadequate to withstand the large losses typically associated with default clustering episodes. Our results suggest it is necessary to address the frailty and contagion
channels of clustering when measuring correlated default risk and estimating risk capital. Accounting for the effects of frailty and contagion will lead to more accurate risk
assessments and more adequate capital buffers. The reduced-form model of correlated
default timing we propose in this paper addresses this need. It is shown to generate accurate out-of-sample forecasts of correlated default risk, and could replace conventional
doubly-stochastic models in risk management applications.
Our results also have significant implications for the pricing of correlated corporate
5
default risk. The models commonly used in practice for the valuation and hedging of
structured securities exposed to correlated default risk, such as collateralized debt obligations (CDOs), ignore the frailty and contagion channels of default clustering. Our findings
suggest that these models may misprice clustered default risk, especially the risk of senior
tranches of CDOs, because they understate the probability of large losses in the pool of
reference credits. This conclusion is consistent with the difficulty of fitting the prices of
senior tranches using conventional doubly-stochastic models of correlated default timing,
as indicated in Feldhütter (2007). It is also supported by the findings of Coval, Jurek &
Stafford (2009), who show that between 2004 and 2007 the senior tranches of the Dow
Jones CDX Investment Grade Index were priced similarly to risk-matched single-name
credit securities that are not exposed to clustered default risk. These authors conclude
that senior CDO tranches did not fully compensate investors for bearing correlated default
risk, consistent with the notion that CDO senior tranches were mispriced. Benmelech &
Dlugosz (2009), Christoffersen, Ericsson, Jacobs & Jin (2010), and Griffin & Nickerson
(2015) provide additional evidence of the potential mispricing of senior tranches of structured securities due to an understatement of correlated default risk. Our reduced form
model of correlated default risk provides a more realistic assessment of the probability of
large credit losses. It could be applied (under a risk-neutral measure) to treat the pricing
and hedging problems associated with structured credit securities.
1.1
Related literature
Previous research has studied the issue of default clustering. Using data on industrial
defaults in the U.S. between 1980 and 2004, Duffie et al. (2007) identify a set of observable
firm-specific and macroeconomic risk factors influencing the timing of defaults in a doublystochastic model. Das et al. (2007) develop time-change tests to evaluate the doublystochastic assumption that firms’ default times are correlated only as implied by the
dependence of firms’ conditional default rates on these risk factors. They find evidence of
clustering in excess of that explained by their model, and reject the joint hypothesis of
well-specified default rates and the doubly-stochastic assumption. This important result
motivates the analysis of additional channels of default clustering, going beyond the joint
exposure of firms’ to systematic risk factors.
Using data on U.S. industrial defaults between 1979 and 2004, Duffie et al. (2009)
estimate a model in which firms’ default rates are allowed to depend on observable firmspecific and macroeconomic risk factors as well as a mean-reverting frailty.2 Their model is
doubly-stochastic with respect to observable and latent frailty risk factors. They find that
the frailty has a large impact on fitted default rates. In contrast to this study, we analyze
industrial and financial defaults between 1970 and 2012, and, importantly, we control for
the contagion channel when measuring the impact of frailty. Our results suggest that the
2
See Delloye, Fermanian & Sbai (2006), Koopman et al. (2008), Koopman et al. (2011), and others
for related frailty models.
6
role of frailty is overstated when the contagion channel is ignored. Moreover, we find that
the contagion channel is highly significant even in the presence of frailty. Both frailty and
contagion are significant sources of the clustering of U.S. defaults, after controlling for
firms’ exposure to systematic risk factors.
Using data on U.S. industrial defaults between 1982 and 2005, Lando & Nielsen
(2010) estimate a model in which firms’ default rates are influenced by observable firmspecific and macroeconomic factors as well as past defaults. They find that the influence
of past defaults is not significant. In contrast to this study, we examine industrial and
financial defaults between 1970 and 2012, and we control for the presence of frailty when
measuring the impact of past defaults. We find strong evidence that the conditional default
rate depends on past failures, regardless of whether or not frailty is present. Our findings
are corroborated by robustness tests in which we restrict our model to the subset of data
and clustering sources considered by Lando & Nielsen (2010).
The aforementioned papers examine correlated default risk using firm-by-firm models
that include firm-specific risk factors such as stock returns and distance-to-default. Our
analysis of clustered default risk is based upon the portfolio-level default rate rather than
firm-level rates, as in Bams et al. (2014), Bhansali, Gingrich & Longstaff (2008), Cont
& Minca (2013), Longstaff & Rajan (2008), Giesecke et al. (2011), Giesecke, Longstaff,
Schaefer & Strebulaev (2014), Hull & White (2008), and others. The advantages of this
approach are its relative simplicity, ease of specification, and convenience of estimation.
Robustness tests indicate that our portfolio-level model fits the event timing data at least
as well as the firm-by-firm models of Duffie et al. (2007) and Lando & Nielsen (2010).
Moreover, popular firm-specific default predictors such as distance-to-default are shown
to play only a minor role for default clustering after controlling for the impact of standard
macroeconomic variables. These observations support our approach.
Self-exciting event timing models that incorporate the dependence of the conditional
event rate on past events have been used by Aı̈t-Sahalia, Cacho-Diaz & Laeven (2015)
for analyzing the dynamics of asset returns with feedback jumps, by Bowsher (2007)
and others for studying the dynamics of order book data, and by Jarrow & Yu (2001)
and others for pricing corporate bonds and credit derivatives. In contrast to these prior
studies, we also model and estimate the dependence of the conditional event rate on a
latent, dynamically-varying frailty factor.
On the econometric front, we significantly extend the time-change tests developed
by Das et al. (2007) for doubly-stochastic models with observable risk factors. Our tests
facilitate the statistical assessment of models that are not doubly-stochastic because of the
influence of past defaults or latent frailty factors. Unlike the tests developed by Das et al.
(2007), our tests allow for the evaluation and comparison of models addressing different
sources of default clustering.
7
1.2
Structure of paper
Section 2 formulates the hypotheses we will test. Section 3 discusses the default timing data. Section 4 develops our reduced-form model of correlated default timing, and
discusses our identification strategy and estimation methodology. Section 5 contains our
empirical results. Robustness checks are carried out in Section 6. Section 7 concludes.
There are several technical appendices.
2
Clustering sources and hypotheses
This section discusses the three potential channels of default clustering we will analyze
and formulates the hypotheses we will test.
2.1
Sources of clustering
A number of papers highlight the significance of macroeconomic factors for corporate
default rates. For example, Duffie et al. (2007) find that default probabilities of U.S. industrials rise when short-term interest rates decline. Lando & Nielsen (2010) document
that U.S. industrial default probabilities also rise when the Treasury yield curve becomes
steeper and when the U.S. industrial production growth rate falls. Giesecke et al. (2011)
conclude that default rates increase during periods of GDP contraction, as well as during
stock market crashes and periods of high stock market volatility. The importance of the
macroeconomy for default timing is unsurprising: deteriorating macroeconomic conditions
negatively impact corporate earnings and the valuation of corporate assets and liabilities.
For example, Longstaff & Piazzesi (2004) document procyclicality in corporate earnings,
Covas & Den Haan (2011) show that debt and equity issuance are also procyclical, forcing
firms to reduce investments and operations in economic downturns, and Acharya, Amihuda & Bharath (2015) demonstrate that prices of speculative grade corporate bonds fall
by excessive amounts during periods of macroeconomic stress.
The joint exposure of firms to common macroeconomic risk factors is a major source of
default clustering: movements in the factors induce correlated changes in firms’ conditional
default rates. However, Das et al. (2007) provide strong evidence that this source on
its own does not explain the degree of clustering found in U.S. default timing data.
Their findings suggests that there are additional sources of default clustering. A candidate
is frailty, i.e., incomplete information regarding the systematic risk factors influencing
conditional default rates. It is possible that some of the relevant risk factors might not
have been identified or are simply unobservable. There is strong empirical evidence of
latent risk factors, see Chava et al. (2011), Duffie et al. (2009), Koopman et al. (2008),
Koopman et al. (2011), Monfort & Renne (2013), and others. The uncertainty regarding
the current values of the latent frailty factors, and the future time variation of these factors,
have an influence on the conditional default rates of the firms that depend on the same
8
frailty factors. This influence generates correlation between firms’ conditional default rates
beyond the correlation due to the future movements of the observable systematic factors
that have already been accounted for. There is theoretical support for this mechanism.
For example, Benzoni et al. (2015) develop an equilibrium model of default risk in which
investors are uncertain about the underlying economic state of the world. In this model, a
common frailty factor naturally arises as a driver of the cross section of conditional default
probabilities. Using a structural model of multi-firm default, Giesecke (2004) shows how
uncertainty regarding firms’ liabilities has an impact on conditional default probabilities
across the board.
Contagion is another potential source of default clustering. With contagion, the default by one firm may have a direct impact on the conditional default rates of other
firms. Financial, legal, or business relationships between firms might act as a conduit
for the spread of risk. A widely studied example is the downfall of Lehman Brothers
in 2008, which exposed many of the firm’s creditors, clients, and trading counterparties.
Chakrabarty & Zhang (2012) measure the impact of Lehman’s default on several measures
of stock market liquidity for Lehman’s counterparties. They find that Lehman’s counterparties experienced a more severe deterioration of liquidity following Lehman’s collapse
than comparable firms that had no counterparty relations with Lehman. In the same vein,
Aragon & Strahan (2012) find that stocks held by hedge funds that had counterparty
exposures to Lehman experienced abnormally large market liquidity deterioration after
Lehman’s downfall compared to stocks that had no exposure to Lehman. Fernando et al.
(2012) show that industrial firms that had investment banking relations with Lehman
experienced significantly negative abnormal stock returns immediately after Lehman’s
collapse. More generally, Hertzel, Li, Officer & Rodgers (2008) document that suppliers
of a defaulted firm experience negative abnormal stock performance, suggesting that financial distress can spread across industries along the supply chain of a defaulted firm.
Boone & Ivanov (2012) find that a default can have a negative impact on the financial
performance of a firm’s strategic partners because of the inability of the defaulting firm
to fulfill its partnership agreements. Mistrulli (2011) finds that the default of a firm in a
conglomerate may force the parent firm to bailout the defaulted firm, raising the parent
firm’s own default rate. Jorion & Zhang (2009) find evidence that a default may push
the trade creditors of a defaulting firm into distress. The key feature of contagion is that
a default has an impact on the default rates of other firms, as in the network models of
Acemoglu, Carvalho, Ozdaglar & Tahbaz-Salehi (2012), Eisenberg & Noe (2001), Elliott
et al. (2014) and many others.
2.2
Hypotheses to be tested
There is evidence of the presence of frailty and contagion effects in corporate credit markets. But are frailty and contagion the sources of the excess default clustering that Das
et al. (2007) found to be unexplained by firms’ exposure to common systematic risk fac9
tors? We will address this question by testing several hypotheses.
Null Hypothesis H0 . After controlling for firms’ joint exposure to common,
observable systematic risk factors, neither frailty nor contagion are significant
sources of corporate default clustering.
Alternative Hypothesis H1 . After controlling for firms’ joint exposure to
common, observable systematic risk factors, only frailty is a significant source of
corporate default clustering.
Alternative Hypothesis H2 . After controlling for firms’ joint exposure to
common, observable systematic risk factors, only contagion is a significant
source of corporate default clustering.
Alternative Hypothesis H3 . After controlling for firms’ joint exposure to
common, observable systematic risk factors, both frailty and contagion are
significant sources of corporate default clustering.
Given support for Hypothesis H3 , we will also test the following competing subhypotheses regarding the roles of the contagion and frailty channels.
Alternative Hypothesis H3(a) . After controlling for firms’ joint exposure
to common, observable systematic risk factors, both frailty and contagion
are significant sources of corporate default clustering, but contagion is more
dominant than frailty during clustering episodes.
Alternative Hypothesis H3(b) . After controlling for firms’ joint exposure
to common, observable systematic risk factors, both frailty and contagion are
significant sources of corporate default clustering, but frailty is more dominant
than contagion during clustering episodes.
3
The data
We will test the hypotheses developed in Section 2 using data on industrial and financial
default timing in the U.S. between 1/1/1970 and 12/31/2012. The data cover all defaults
of firms domiciled in the U.S. with debt rated by Moody’s, and were obtained from
Moody’s Default Risk Service.
We adopt Moody’s definition of a default event (see Hamilton (2005)). A “default” is
an event in any of the following categories: (1) a missed or delayed disbursement of interest
or principal, including delayed payments made within a grace period; (2) bankruptcy
(Section 77, Chapter 10, Chapter 11, Chapter 7, Prepackaged Chapter 11), administration,
legal receivership, or other legal blocks to the timely payment of interest or principal; or
(3) a distressed exchange occurs where: (i) the issuer offers debt holders a new security or
10
package of securities that amount to a diminished financial obligation; or (ii) the exchange
had the apparent purpose of helping the borrower avoid default. A repeated default by
the same issuer is included in the set of events if it was not within a year of the initial
event and the issuer’s rating was raised above Caa after the initial default. This treatment
of repeated defaults is consistent with that of Moody’s.
We observe a total of 2001 defaults by 1294 firms. There are 1452 days with default
events. Figure 2(a) shows the face amount of defaulted debt for each day in our sample
period. The date with the largest amount of defaulted debt is March 27, 2009, when Charter Communications Holdings LLC defaulted. April 8, 2009, the day on which Harrah’s
Operating Company collapsed, is next on the list. The third largest event is the default
of American Airlines on November 29, 2011. We observe that the face value of defaulted
debt tends to increase over the sample period. This is primarily due to the fact that the
firms in our default data set have increased both their total liabilities and their leverage
ratios over time; see Figure 2(b).
Figure 3 reports the distribution of defaulted debt. About 95% of the defaults involve
$500 million or less of defaulted debt. The average amount of defaulted debt is $173
million; the median is $100 million. Figure 4 shows the number of defaults by event
category. The vast majority of defaults is due to missed interest payments, Chapter 11
filings, or exchanges of distressed debt that resulted in losses to bond investors. Figure 4
also indicates the number of events by sector. Most defaults occur in the capital industry,
followed by the consumer industry, technology, retail and distribution, and media and
publishing sectors.
Figure 5 shows the joint distributions of the sector of a defaulting firm, the event
category, the amount of defaulted debt, and the time until the next default. Defaults
involving Chapter 11 filings, distressed exchanges, and missed principal payments tend to
be quickly followed by additional defaults. These types of defaults also tend to be large
in terms of the amount of defaulted debt. Similarly, defaults in the finance, insurance,
real estate, the consumer industry, the media and publishing, and the technology sectors
tend to be quickly followed by additional defaults. These sectors also tend to have large
amounts of defaulted debt. Figure 6 indicates that defaults with large amounts of debt
tend to be quickly followed by additional defaults. Figure 6 also suggests that the impact of
large defaults on the arrival of additional defaults tends to be persistent: there is higher
cumulated defaulted debt over the one-month period after a large default than in the
one-month period after a small default. These observations will inform the design of our
reduced-form model in Section 4.
We will study the influence on default timing of a number of explanatory variables
(risk factors). We construct time series of variables from data obtained from the Federal
Reserve Banks of New York and Saint Louis; Table 1 reports summary statistics. The
variables we consider include the quarterly growth rate of the U.S. industrial production
calculated from final products and nonindustrial supplies (IP, observed monthly), the
annualized quarterly growth rate of the U.S. gross domestic product (GDP, observed
11
quarterly), the trailing 1-year return of the S&P 500 index (RET, observed daily), the
trailing 1-year volatility of the S&P 500 index (VOL, observed daily), the level of the yield
curve measured by the yield of the 3-month Treasury bill yield (LEVEL, observed daily),
the slope of the yield curve measured by the spread between the 10-year Treasury note and
the 1-year Treasury bill (SLOPE, observed daily), the 10-year Treasury note yield (10Y,
observed daily), Moody’s AAA corporate yield (AAA, observed weekly), the credit spread
between the Moody’s BAA and AAA corporate yields (CRED, observed weekly), and a
recession indicator according to the NBER business cycle dates (REC, observed monthly).
Under different econometric assumptions and using different default timing data, Chava
& Jarrow (2004), Das et al. (2007), Duffie et al. (2007), Campbell et al. (2008), Duffie
et al. (2009), Lando & Nielsen (2010), Giesecke et al. (2011), and others have found some
or all of these variables to be significant predictors of U.S. defaults.
4
Reduced-form model
We develop a new reduced-form model of correlated default timing to test the hypotheses
formulated in Section 2. Reduced-form models are widely used in theoretical and empirical
analyses of correlated default risk; see Berndt, Ritchken & Sun (2010), Chava & Jarrow
(2004), Das et al. (2007), Duffie et al. (2007), Duffie et al. (2009), Jarrow & Yu (2001),
Jarrow et al. (2005), Lando & Nielsen (2010), Longstaff & Rajan (2008), and many others.
Our model captures the influence of the observable, time-varying risk factors described
in Section 3, of a dynamically-varying frailty, and of past defaults. The model provides
portfolio loss forecasts for multiple future periods that take account of the time-series
behavior of the observable and latent risk factors over the forecast period.
4.1
Model formulation
The defaults in our sample arrive at an intensity that measures the conditional mean
arrival rate of events per year (see Appendix A for details). To accommodate the potential
sources of default clustering, we allow the intensity to depend on observable explanatory
variables X1 , . . . , Xd , a latent frailty variable Z, and past defaults. More precisely, if Z
were observable, the intensity at time t would be of the form
d
X
λt = exp a0 +
ai Xi,t + Yt + Zt ,
(1)
i=1
where a = (a0 , a1 , . . . , ad ) is a vector of coefficients to be estimated, and Y , which will be
specified below, models the influence of past defaults on the conditional default rate. The
intensity at t given the actually available information is the posterior mean of λt ; details
are provided in Appendix C.
The first term in (1) captures firms’ exposure to the common risk factor X =
(X1 , . . . , Xd ), which represents the variables described in Section 3 above (see Table 1).
12
As in Chava & Jarrow (2004), Das et al. (2007), Duffie et al. (2007) and other articles,
this term takes the classical proportional hazards form of Cox (1972). When Y and Z
are positive, this formulation ensures that the intensity is positive for any value of the
factor vector X. Moreover, when Y = 0 and Z = 0, the influence of the risk factor Xi
is multiplicative and the parameter ai is a proportionality factor. If Xi increases by one
unit, then the intensity increases by a factor of eai − 1.
The term Z in (1) models the influence of a latent frailty risk factor on the timing of
defaults in our sample. We propose a standard mean-reverting Cox-Ingersoll-Ross (CIR)
model for the dynamics of the latent factor Z:
p
dZt = k(z − Zt )dt + σ Zt dWt ,
(2)
for z, k, σ ≥ 0 and 2kz ≥ σ 2 .3 Here, W is a standard Brownian motion independent of X,
and Z is initialized at its stationary gamma distribution with shape parameter 2kz
and
σ2
σ2
scale parameter 2k . The choice of a mean-reverting model is motivated by the results of
Duffie et al. (2009), who find strong evidence for the existence of a mean-reverting frailty
influencing U.S. non-financial default timing between 1979 and 2004.
The term Y in (1) addresses the influence of past failures on default timing. We
propose the classical self-exciting specification of Hawkes (1971), which is widely used in
the empirical and theoretical contagion literature:4
X
Yt = b
e−κ(t−Tn ) Un
(3)
n: Tn ≤t
where b > 0 and κ > 0 are parameters to be estimated. The increasing sequence of
times Tn represent the dates in the sample with at least one default, and the variables
Un characterize the impact of defaults on the conditional default rate. The intensity is
ramped up by bUn given at least one event at Tn . The impact fades away with time at
rate κ. Letting un be the sum of the face values of defaulted debt at Tn , we take
Un = max{0, log un }.
(4)
We justify the choice (4). Figure 6 indicates that defaults with large amounts of
defaulted debt tend to be quickly followed by additional defaults, and that the impact of
defaults with large amounts of defaulted debt on the arrival of future defaults is persistent.
Figure 5 suggests that the variability in defaulted debt can capture the cross sectional
variability of the impact of the industry sector and event category on the arrival of future
defaults. We interpret that defaults with large amounts of defaulted debt have a strong
impact on the default rate, regardless of other default characteristics.
Hertzel et al. (2008), Jorion & Zhang (2007), and Jorion & Zhang (2009) provide
evidence that bankruptcies of firms with large liabilities induce stronger contagion effects
3
We have considered alternative parameterizations of the model (2), including one with unit volatility
but Z in (1) replaced by σZ. The results for these alternatives are very similar to those for (2).
4
See Aı̈t-Sahalia et al. (2015), Bowsher (2007), Errais, Giesecke & Goldberg (2010), and others.
13
than bankruptcies of firms with small liabilities. For the global network of large CDS
counterparties, Yang & Zhou (2013) document that credit risk spillovers from distressed
firms are more severe if the distressed firm has large leverage ratios. Using data of firm
liabilities from Compustat, we find that the amount of defaulted debt is correlated with
total liabilities at default. Among the defaulted firms in our dataset for which liabilities
data is available, the correlation coefficient between the logarithm of defaulted debt and
the logarithm of total liabilities at default is 0.39. Table 2 indicates that an OLS regression
of total liabilities at default on defaulted debt has an adjusted R-squared of 0.15 without
controlling for the influence of the explanatory variables X, and 0.27 after controlling
for X. Figure 7 indicates that the quantiles of the logarithm of defaulted debt almost
perfectly match the quantiles of the logarithm of total liabilities at default, except for
a few defaults with very small and very large amounts of defaulted debt. As a result,
defaulted debt provides a proxy for total liabilities at the time of default. Based on these
observations and because liability data is only available for about one-third of the firms
in our data set, we specify the impact of a default event on the conditional default rate in
terms of defaulted debt and (4). Overall, our contagion factor roughly captures aggregate
credit exposure to defaulted firms, consistent with the contagion mechanism of Jorion &
Zhang (2007, 2009).
4.2
Likelihood estimation
We estimate the parameter θ = (a, b, k, κ, σ, z, s) governing the reduced-form model (1)
by the method of maximum likelihood. Since the frailty Z influencing the intensity cannot
be observed, the likelihood problem is not standard unless z = σ = 0. We implement a
variant of the filtered likelihood estimation developed by Giesecke & Schwenkler (2015);
see Appendix B for details. The likelihood is the posterior mean of the complete-data
likelihood given the observed data, which include the default dates, the defaulted debt, and
time series of the explanatory variables X1 , . . . , Xd discussed in Section 3.5 The posterior
mean is evaluated using a quadrature method. This approach eliminates the need to
perform Monte Carlo simulations of the frailty path over the 43-year sample period, which
would be computationally burdensome. It also avoids the loss of estimation efficiency and
potential biases associated with the simulated expectation-maximization (EM) algorithm
often used for this type of problem.6 The resulting likelihood estimators are consistent
and asymptotically normal as the sample period grows (see Appendix B.3).
5
Following the empirical default timing literature, we interpolate the discrete observations of the
explanatory variables to obtain continuous time series.
6
Duffie et al. (2009), Koopman et al. (2008), Koopman et al. (2011), and others use EM algorithms
to estimate the influence of frailty on default timing. Giesecke & Schwenkler (2015) indicate that EM
algorithms may be unable to precisely differentiate between jump and diffusive movements of the intensity
when the intensity depends on a latent frailty factor and a self-exciting factor as in (1).
14
4.3
Parameter estimates
We fit our model along with three nested (i.e., restricted) alternatives that are described
in Table 3. A model for which b = 0 ignores contagion. A model for which z = σ = 0
ignores frailty. A base model for which b = z = σ = 0 captures only the clustering implied
by firms’ joint dependence on the observable risk factor X. Table 4 reports the parameter
estimates and the corresponding asymptotic standard errors.
The self-excitation term Y is highly significant. Past defaults appear to be significant
predictors of future defaults after controlling for the influence of observable and frailty
factors. A default has a persistent impact on the intensity, with a half-life of about 3
months. Upon a default event with $173 million of defaulted debt, the average in our
data set, the intensity increases by roughly 2.8 events per year. The fitted values of the
parameters b and κ governing the self-excitation term Y are very similar to the fitted
values in the model ignoring the frailty channel. This observation suggests that the term
Y has been appropriately identified. In particular, the role of the term Y is not overstated
at the expense of the frailty term.
The latent frailty factor Z exhibits significant mean-reverting behavior. Even though
our data spans a longer time horizon and includes defaults of financial firms, the parameter
estimates for our frailty factor in the restricted model are almost equal to the estimates
for the frailty factor in the comparable model of Duffie et al. (2009).7 We conclude that
our frailty factor is properly identified. However, the fitted parameters in the unrestricted
model differ by orders of magnitude from those in the model ignoring contagion. On one
hand, the fitted frailty has small volatility and quickly reverts to a low but significant
level in the unrestricted model. On the other hand, the fitted frailty is very persistent
and has a high reversion level and high volatility in the restricted model. These findings
suggest that a model ignoring the contagion channel may overstate the role of frailty.
Among the explanatory variables, GDP growth has a significant influence on the
intensity. The sensitivity of the intensity to this factor is negative, consistent with the
intuition that strong economic growth reduces the likelihood of defaults (see Giesecke
et al. (2011)). Moreover, the fitted value of the sensitivity parameter is similar to the
values estimated for the restricted models (if these values are significant), suggesting that
the impact of GDP growth on the intensity is not overstated at the expense of other risk
factors or the frailty and self-exciting terms. A one-standard deviation shock to GDP
growth may increase the aggregate default intensity by up to 40%.
Unlike Duffie et al. (2007), Duffie et al. (2009), and Lando & Nielsen (2010), we find
that the S&P 500 return is a significant risk factor only in the base model. Our parameter
estimates suggest that this is due to the fact that we control for the frailty and contagion
channels of clustering when measuring the impact of the explanatory variables. The afore7
Duffie et al. (2009) estimate that their frailty factor has a volatility of 0.125 and a mean-reversion
speed of 0.018. We estimate that our frailty factor in the Base + Frailty model has a volatility of 0.129
and a mean-reversion speed of 0.016.
15
mentioned papers control for only one of these channels, or neither. Also the corporate
bond yield spread is found to be insignificant. This finding complements previous results
by Collin-Dufresne, Goldstein & Martin (2001), Giesecke et al. (2011), and Gilchrist &
Zakrajšek (2012) on the connection between credit spreads and the business cycle. It
provides additional evidence that credit spreads contain little information about physical
default probabilities.
4.4
Fitted intensity
Figure 8 compares the fitted intensity to the default data. The fitted intensity at time
t is given by the fitted posterior mean of λt given the data observed to time t. Without
frailty (z = σ = 0), the posterior mean, ht , is equal to λt . With frailty, the computation
of ht is a filtering problem; see Appendix C.
We observe that the base model does a relatively poor job at explaining the default
clusters in the data. It lags clusters and significantly overstates the arrival rates during
the first quarter of the sample period and during the recent financial crisis. The richer
models capture the substantial time-variation of realized arrival rates much better. The
models that address the contagion channel match the low arrival rates during the early
part of the sample better than the models that ignore that channel.
5
Hypotheses tests
Using our fitted models, we test the hypotheses formulated in Section 2 regarding the
potential sources of default clustering.
5.1
Fitted parameters
The Null Hypothesis H0 can be rejected if at least one of the parameters z, σ, or b is
significantly larger than zero. If all of these parameter estimates are significantly positive,
then we have evidence in favor of Alternative Hypothesis H3 . On the other hand, significantly positive estimates of z and σ and an insignificant estimate of b provide evidence in
favor of Alternative Hypothesis H1 . A significantly positive estimate of b and insignificant
estimates of both z and σ are evidence in favor of Alternative Hypothesis H2 .
The model parameter estimates discussed in Section 4.3 above suggest rejection of
the Null Hypothesis H0 . The fitted values of the parameters do not, however, provide clear
evidence in favor of any of the Alternative Hypotheses H1 –H3 . Below, we run likelihood
ratio tests and time-change tests in order to develop a better understanding of the validity
of the alternative hypotheses.
16
5.2
Likelihood ratio tests
Using likelihood ratio tests we measure the improvement in fit achieved by including the
frailty and self-excitation terms. If we obtain a statistically positive likelihood ratio statistic by moving from a more restricted model to a less restricted one, then we can conclude
that the clustering channel ignored in the restricted model is statistically significant.
The test results are reported in Table 5. Relative to the base model, adding either
the frailty term or the self-excitation term leads to a significant improvement in model fit.
However, the inclusion of the self-excitation term leads to a bigger improvement in the
test statistic than the inclusion of the frailty term. Relative to the model that includes
observable risk factors and frailty, the inclusion of the self-excitation term as a third
source of clustering yields further improvements. The inclusion of the frailty term in the
model with observable risk factors and the contagion term does not significantly improve
model fit, however. These tests suggest that even after controlling for frailty, the selfexcitation term representing the contagion channel plays a prominent role. These results
provide evidence in favor of Alternative Hypotheses H2 and H3 , and against Alternative
Hypothesis H1 . They also provide further evidence against the Null Hypothesis H0 .
5.3
Time-scaling tests
We use time-scaling tests of goodness-of-fit to discriminate between Alternative Hypotheses H2 and H3 . An important result of Das et al. (2007) states that if there are no
latent frailty factors and defaults are doubly-stochastic,8 then the default count Nt can
be transformed into a standard Poisson process by a change of time given by the cumulative intensity. This result allows one to evaluate the goodness-of-fit of doubly-stochastic
models with observable risk factors by testing the Poisson property of the time-scaled
default times.
Our model violates the doubly-stochastic hypothesis because it addresses the frailty
and contagion channels. Therefore, the tests of Das et al. (2007) do not apply. We generalize the time-change result of Das et al. (2007) in Proposition D.1 in Appendix D. Our
result also covers models in which the doubly-stochastic assumption is violated because
of the presence of a latent frailty factor or a self-exciting term. We show that the default count Nt can always be transformed into a standard Poisson process by a change of
time given by the cumulative posterior mean ht of the intensity. This result allows us to
compare models addressing different sources of default clustering by testing the Poisson
property of the time-scaled default times.
For a bin of size w > 0, we construct an increasing sequence of times tw
i so that
the cumulative posterior intensity mean ht between two consecutive times is equal to w.
8
A model with observable risk factors is doubly-stochastic if default arrivals are conditionally Poisson
given the paths of the factors. A doubly-stochastic model addresses only the default correlation caused
by firms’ joint exposure to the risk factors.
17
R tw
w
Formally, twi hs ds = w for each i. Let Piw be the number of defaults between tw
i−1 and ti .
i−1
Proposition D.1 implies that the Piw are independent samples from a Poisson distribution
with parameter w. We test this property for different bin sizes w using a series of tests
described in Karlis & Xekalaki (2000) and Das et al. (2007). The Potthoff-WhittinghillBohning test evaluates the moments and the Kocherlakota-Kocherlakota test evaluates
the generating function of the Piw . The other tests examine the independence, dispersion,
tail properties, and distribution of the Piw . If Alternative Hypothesis H3 is valid, then the
complete model should fail the fewest tests at low significance levels. On the other hand,
if Alternative Hypothesis H2 is valid, then there should not be any significant differences
between the test performances of the complete model and the nested model that ignores
the frailty source.
Table 6 reports the p-values of our Poisson property tests. The base model fails
most of these tests at high significance levels. It generates correlated binned event counts
and does not match the corresponding Poisson distributions. Table 7 indicates that the
base model generates binned event counts that are overdispersed, with the variances of
the Piw exceeding the theoretical counterparts. Overdispersed counts are a sign of model
misspecification (see Cameron & Trivedi (1998)), consistent with the failure of the base
model in the tests of Table 6. Consistent with Das et al. (2007), the time-change tests
indicate that the Null Hypothesis H0 is rejected because a model based only on systematic
default risk factors is misspecified.
The model including the frailty channel but ignoring the contagion channel fails the
Potthoff-Whittinghill-Bohning tests of the moments of the Poisson distribution. It also
fails a chi-squared goodness-of-fit test. Table 7 suggest that the model ignoring contagion
fails these tests because it tends to generate underdispersed binned event counts, with
empirical variances of the Piw that are much lower than the corresponding empirical
means. Underdispersion is a sign of positive correlation between model-implied interdefault times (see Winkelmann (1995)). It suggests that the model ignoring contagion
does not properly reflect the correlation structure of default events in the data, resulting
in rejection of Alternative Hypothesis H1 .
The model including the contagion channel but ignoring the frailty channel also fails
the Potthoff-Whittinghill-Bohning test and the chi-squared test, though only for small
bin sizes. We conclude from Table 7 that the model ignoring frailty also fails these tests
due to underdispersion, given the low empirical variances of the Piw in Table 7 for bin
sizes 2 and 4.
The unrestricted model, which addresses all three potential clustering channels, fails
the fewest tests. It exhibits the smallest degree of under- or overdispersion, with empirical
means and variances of the Piw in Table 7 that are closest to each other. All things
considered, the time-scaling tests provide evidence in favor of Alternative Hypothesis H3 ,
which states that both contagion and frailty are significant sources of default clustering
after controlling for firms’ joint exposure to observable risk factors.
18
5.4
Out-of-sample analysis
To understand the distinct roles of the frailty and contagion channels for measuring portfolio credit risk, we consider tests of out-of-sample forecast accuracy. We use Monte Carlo
simulation to generate the conditional distribution of the number of defaults in the year
ahead, given a model fitted to the data available at the beginning of the year. Our approach, detailed in Appendix E, eliminates the need to simulate the paths of the frailty
variable during the forecast period. It is computationally efficient and generates forecast
distributions with small variance.
Figure 9 contrasts the forecast distribution with the realized number of defaults,
for each year between 1991 and 2012, and for each alternative model. We observe that
the base model lags default clusters. It fails to predict the clusters associated with the
burst of the dotcom bubble and the financial crisis. The model including frailty but
ignoring the contagion channel performs better at predicting these clustering episodes.
However, it generates forecast distributions with excessively heavy tails. Moreover, the
means of the forecast distributions show very little variation through the test period.
Thus, if the mean were used as a point forecast, then the forecast would change little every
year, despite the significant variation of observed default rates. The model that includes
the contagion channel but ignores the frailty channel generates much more concentrated
forecast distributions. The forecast mean matches the realized number of defaults quite
well. The unrestricted model, which addresses all potential clustering sources, performs
better still, producing forecast distributions with lower variance during the first third of
the test period.
To test forecast accuracy, we consider the 99% value at risk (VaR) of the forecast
distribution, a standard measure of portfolio credit risk. For a given model, we evaluate
the sequence of “hit” indicators associated with violations of the VaR in different periods.
Under the null, these indicators are independent draws from a Bernoulli distribution
with success probability (1 − 0.99) = 0.01. Table 8 reports the violation rates and the
p-values of an unconditional coverage test due to Kupiec (1995), which tests whether the
actual violation rate is significantly different from 0.01. We also report the p-values of
an independence test due to Christoffersen (1998), a combined test of independence and
Bernoulli distribution against a Markov chain alternative due to Christoffersen (1998),
and the out-of-sample dynamic quantile test of Engle & Manganelli (2004). The dynamic
quantile test examines if there is significant correlation between the hit indicators and the
level of the VaR. With a violation rate of 0/22, the model including the frailty channel
but ignoring the contagion channel outperforms all other models according to these tests.
With a violation rate of 1/22, the unrestricted model comes in second. The base model
is rejected by these tests due its sluggishness. The model including the contagion channel
but ignoring the frailty channel is rejected because its VaR forecasts are too low.
The tests of the hit indicators may unduly favor the frailty model because it generates
forecast distributions with excessively heavy tails, and VaR forecasts that are excessively
19
large. If one were to estimate risk capital according to the VaR, one would end up holding
too much capital relative to the actual risk. While one would be covered in most situations,
scarce risk capital would be wasted. To address this issue, we consider the mean relative
bias and the root mean square relative bias of the VaR forecasts (see Hendricks (1996)).
The former is the percentage deviation of a forecast from the average forecast of all
models, averaged over all forecast periods. The latter accounts for the standard deviation
of the former. The outcomes of these measures, reported in Table 8, indicate that the
frailty model does indeed tend to overstate the VaR and to produce the largest forecast
volatility. The unrestricted model, which addresses all clustering sources, generates the
VaR forecasts with the least amount of bias and volatility.
The results of the out-of-sample tests provide further support for Alternative Hypothesis H3 . A model addressing firms’ exposure to observable and frailty risk factors but
ignoring the contagion channel tends to overstate correlated default risk, while a model
addressing firms’ exposure to observable risk factors and contagion but ignoring frailty
tends to understate it. The issues with these two models can be attributed to the underdispersion property detected by the time-change tests, which results in distorted forecasts
of correlated default risk. The unrestricted model, which addresses all three potential
clustering sources, provides the most balanced and accurate out-of-sample forecasts of
correlated default risk.
5.5
Alternative Hypothesis H3(a) or H3(b) ?
Both the in-sample and out-of-sample tests discussed above provide strong support for
Alternative Hypothesis H3 : contagion and frailty are significant sources of corporate default clustering. Next, we evaluate Alternative Hypotheses H3(a) and H3(b) regarding the
relative importance of frailty and contagion.
We decompose the fitted intensity of the complete model into its three components:
the component exp(a0 +a1 X1,t +· · ·+ad Xd,t ) capturing the exposure to observable systematic default risk factors, the contagion component Yt , and the frailty component given by
the posterior mean Et [Zt ]. Figure 10 shows that, since the mid 1980’s, the first component
consistently accounts for 25% to 35% of the default rate. This finding is consistent with
the estimates of Koopman, Lucas & Schwaab (2012), and suggests that we have properly identified and controlled for the exposure to observable systematic risk factors when
measuring the significance of the frailty and the contagion channels of default clustering.
Figure 10 also indicates that the contagion component represents a significant fraction of
the default rate, and that this fraction is especially large during clustering episodes. In
contrast, the contribution of the frailty term to the default rate is small, and becomes
larger during episodes of low default activity. Thus, we obtain strong support for Alternative Hypothesis H3(a) , that the contagion channel is a more prominent source of clustering
than the frailty channel.
20
6
Robustness checks
6.1
Omitted firm-specific variables
The literature has identified several firm-specific risk factors that are significant predictors
of corporate default probabilities; see Altman (1968), Duffie et al. (2007), Campbell et al.
(2008), Chava & Jarrow (2004), Lando & Nielsen (2010), Ohlson (1980), Shumway (2001),
and many others. These factors include firm size, firm stock returns and volatilities, as
well as distance to default (a volatility-adjusted measure of leverage). One could argue
that our results might be biased because we do not control for the influence of firm-specific
risk factors, resulting in an unjustified rejection of Null Hypothesis H0 . If variations in
the cross section of firm-specific risk factors contain information about systematic default
risks that are not captured by the systematic risk factors we include in our model (see
Table 1), then firm-specific risk factors may be important for default clustering. To show
that this is not the case, we test whether the cross section of omitted firm-specific default
risk factors contains information not captured by our systematic variables.
For the companies in our default data set, we construct monthly time series of cross
sectional averages of significant firm-specific default risk factors.9 Table 9 provides summary statistics. The firm-specific variables we consider are the quick ratio (QUICK),10
ratio of short term debt to total debt (SD), total liabilities (TL), distance to default
(DTD), log book asset value (LBA), net income to total assets ratio (NITA), total liabilities to total assets ratio (TLTA), log relative market capitalization with respect to the
total market capitalization of all NYSE/NASDAQ/AMEX listed firms (RSIZE), 1-year
trailing stock return (RET), and the realized standard deviation of monthly returns over
rolling horizons of 12 months (VOL). Next, we regress the cross sectional averages on our
macroeconomic variables. Table 10 gives a summary of the regression results. We see that
our macroeconomic variables can capture at least 52 percent of the monthly variation
of cross sectional averages of firm-specific default risk factors. Surprisingly, our macroeconomic variables capture 71 percent of the monthly fluctuations of average distance to
default in our data set. Duffie et al. (2007), Duffie et al. (2009), Lando & Nielsen (2010),
and many others find that distance to default is the most economically and statistically
significant determinant of U.S. corporate default probabilities. Yet, our regression analysis
states that the cross-sectional average of distance to default is almost perfectly spanned
by our macroeconomic variables.
Next we regress the frailty and self-exciting terms of the intensity (Yt + Zt ) on the
residuals of the regressions in Table 10. We find that the residuals can only explain
about 22% of the variation of Yt + Zt estimated for the complete model over the sample
9
Proposition 1 of Duffie (1998) implies that the only relevant firm-specific data for modeling the
conditional default rate in our sample are the cross sectional averages of firm-specific default risk factors
after censoring defaulted firms.
10
The quick ratio is the ratio of a firm’s cash, short-term investments, and total receivables over its
current liabilities.
21
period. We conclude that while firm-specific default risk factors may contain significant
information about idiosyncratic default risk, they only contain little information about the
systematic default risk not captured by our macroeconomic variables. Thus, the absence
of firm-specific variables in our model is unlikely to bias our results.
6.2
Economy-wide vs. firm-level default rates
Rather than modeling firm-by-firm default rates, our analysis focuses on the economywide default rate that describes events in the pool of Moody’s rated issuers. To show that
this approach is appropriate for measuring correlated default risk and does not bias our
results, we compare the goodness-of-fit of our simple base model to the goodness-of-fit of
the leading firm-by-firm reduced-form models of Das et al. (2007) and Lando & Nielsen
(2010). Das et al. (2007) study 495 U.S. non-financial default events during the time
period January 1979 to October 2004. A firm’s default intensity depends on the distance
to default, the firm’s trailing 1-year stock return, the 3-month Treasury bill rate, and the
1-year trailing return of the S&P-500 index. Lando & Nielsen (2010) analyze 370 U.S.
non-financial default events between January 1982 and December 2005. A firm’s default
intensity depends on the 1-year return on the S&P-500 index, the 3-month US Treasury
rate, 1-year percentage change in U.S. industrial production, the spread between the 10year and 1-year Treasury rate, a firm’s 1-year equity return, 1-year distance-to-default,
quick ratio, ratio of short-term debt to total debt, and log book value.
Although our base model does not include firm-specific factors, it fits the data at
least as well as the firm-by-firm models of Das et al. (2007) and Lando & Nielsen (2010).
To show this, we re-estimate our base model from a subsample of our data that mirrors
the data sets used by Das et al. (2007) and Lando & Nielsen (2010). Using the same
time-change tests as these authors (see Section 5 above), Table 11 indicates that our
base model performs slightly better than Model I and as well as Model II of Lando &
Nielsen (2010). Further, Table 12 indicates that our base model slightly outperforms the
model of Das et al. (2007). Thus, our base model of aggregate defaults performs as well
as alternative firm-by-firm models of defaults that have been proposed in the literature.
The choice of our modeling approach is not a driver of our results.
6.3
Financial firms
Defaults of financial firms are special as they tend to be rare, large, and surrounded by
government intervention. Among the 2001 distinct default events in our data set, there
are only 126 default events by financial firms. The mean defaulted debt is $240 million,
which is significantly larger than the mean defaulted debt for non-financial firms ($169
million). Further, all defaults of the type “Seized by regulators” in our data set are by
financial firms. Despite the peculiarity of financial firm defaults, empirical evidence on the
impact of financial firm defaults on aggregate default rates is sparse. Giesecke et al. (2014)
22
find evidence that, over the long term, the impact of financial default crises on the real
economy is far more severe than the impact of non-financial default crises. This evidence
is consistent with the financial accelerator mechanism of Bernanke, Gertler & Gilchrist
(1999), which hypothesizes that distress of financial firms may amplify and propagate
shocks to the real economy. Still, Helwege (2010) argues that financial firm distress may
not significantly spread to the real economy given that financial firms are able to endure
large shocks because they are well regulated and they practise extensive diversification.
Further, Helwege & Zhang (2012) show empirically that financial firm bankruptcies have
only triggered modest contagion effects in historical data.
We test if our findings are sensitive to the exclusion of financial firms. Table 13
provides the maximum likelihood parameter estimates of the complete model and the
three nested alternatives after excluding financial firm defaults from our data. We find
that the parameter estimates are essentially the same as those for all (financial and non
financial) firms; compare with the estimates in Table 4. We conclude that the inclusion
of financial firms is not a key driver of our results. Contagion and frailty are significant
sources of clustering even for industrial firms.
6.4
Days with multiple defaults
Our data set includes days with multiple defaults. For example, the default of Texas
International Air on 9/24/1983 was accompanied by the defaults of the Texas International
Air Finance and Texas International Air Capital subsidiaries on the same date. The
formulation (4) aggregates these defaults when modeling their impact on the default
intensity. Alternatively, we could treat each default separately. For example, if there are
Jn defaults on day Tn and unj denotes the face value of defaulted debt of the j-th default
on one such day, then we could set
Un =
Jn
X
max 0, log unj .
(5)
j=1
We have analyzed our models using this alternative convention; see Table 14. The
only affected models are those that include the contagion source. We find that the signs,
magnitudes and statistical significance of the parameter estimates of all models are similar
to those reported in Table 4, with few exceptions. The contagion sensitivity parameter b
decreases by a factor of roughly 0.77. This is primarily driven by the fact that the average
Un under the formulation (5) is about 1.3 times higher than under the formulation (4).
The estimated contagion decay parameter κ is similar under formulations (4) and (5).
However, the maximum log-likelihoods are much lower under specification (5) than under
specification (4). We conclude that (5) yields an inferior specification of the contagion
term that the data do not support.
23
6.5
Industry-specific contagion
The formulations (4) and (5) do not distinguish among defaults in different industries.
However, industry characteristics may be important determinants of the contagion effects induced by a default; see Hertzel et al. (2008), Hertzel & Officer (2012), Jorion &
Zhang (2007), Jorion & Zhang (2009), and Lang & Stulz (1992), among others. Omitted
industry-specific contagion effects may thus bias our estimates on the contagion channel.
To demonstrate that this is not the case, we incorporate industry-specific contagion effects
by formulating Un as follows:
Jn
X
bInj
Un =
max 0, 1 +
log unj ,
b
j=1
(6)
where Inj indicates the industry of the j-th default on day Tn . The parameter bInj measures
the intensity sensitivity to a dummy variable which is equal to 1 if and only if the j-th
default on day Tn occurs in industry Inj .
We re-estimate the models that include the contagion source under formulation (6).
We consider 10 different sectors as defined by Moody’s 11 Code (see Figure 4). Table 14
summarizes our results. The contagion sensitivity is smaller after accounting for different
industries. The average sector contagion sensitivity, weighted by empirical default frequencies, is 0.0044. Significant contagion occurs after a default in the banking, the consumer
industries, the energy & environment, and the retail & distribution sectors. An average
default in these sectors increases the aggregate default intensity by 1.96, 1.88, 1.81, and
2.87 defaults per year, respectively. Despite the contagion sensitivity being smaller, the
estimated contagion decay rate κ under formulation (6) implies a much large persistency
of the contagion factor Y . Defaults in the banking, the consumer industries, the energy &
environment, and the retail & distribution sectors cause large jumps up in the aggregate
default intensity, and these jumps persist with a half-life of about 5 months (the half-life
under specification (4) is only 3 months). All other parameter estimates and standard
errors are roughly the same for formulation (6) than for our original formulation (4).
Likelihood ratio tests of the complete model and the nested submodels under formulation
(6) and under formulation (4) give the same results. We conclude that omitted industryspecific contagion effects do not bias any of our results.
Consistent with Hertzel et al. (2008) and Jorion & Zhang (2009), our results on industry effects confirm that contagion can occur across industries. Our results also confirm
that contagion does not necessarily need to originate in the financial sector, extending our
findings of Section 6.3. A large industrial default can have a similar impact on aggregate
default rates as a default with comparable defaulted debt in the financial sector.
24
7
Concluding remarks
The U.S. credit markets have suffered several significant clusters of corporate default
events. This paper studies the sources of clustering using data on industrial and financial
default timing in the U.S. between 1970 and 2012. It presents strong evidence for the
existence of several clustering channels, including firms’ joint exposure to macroeconomic
factors, the influence of a common latent frailty factor with mean-reverting behavior, and
the persistent impact on firms of past default events.
The results have important implications for the management of portfolio credit risk
at financial institutions. The models widely used to estimate risk capital address only
the default clustering due to firms’ joint exposure to observable risk factors. Our results
suggest that these models significantly understate the risk of large losses from defaults.
This indicates that banks using these models might end up holding inadequate capital to
withstand the large losses induced by default clusters like the one following the financial
crisis of 2007-09. Our results suggest to estimate risk capital using an approach that
also addresses the presence of a mean-reverting frailty factor influencing firms, and the
impact of past failures on default rates. We find that such an approach generates the most
accurate out-of-sample forecasts of correlated default risk.
An understanding of the sources of default clustering is also essential for the pricing,
rating, and risk analysis of securities that are exposed to correlated default risk, such as
collateralized debt obligations. Our findings suggest to account for the impact of frailty
and contagion when examining such securities.
A
Reduced-form model
This appendix provides some technical details regarding our model of default timing
(Section 4). The default data is a realization of a marked point process (Tn , Un )n≥1 defined
on a complete probability space (Ω, F, P) equipped with an information filtration F =
(Ft )t≥0 satisfying the usual conditions of right-continuity and completeness (see Protter
(2004)). That is, (Tn )n≥1 is an increasing sequence of stopping times tending to ∞. The
times Tn represent the dates in the sample with at least one default. Moreover, (Un )n≥1 is
a sequence of FTn -measurable random variables, where Un represents the total amount of
defaulted debt on date Tn . We assume that there exists a positive process λ such that the
Rt
P
variables Nt − 0 λs ds form a local martingale, where Nt = n≥1 1{Tn ≤t} . The process λ
is the intensity of N . We have that E[Nt+∆ − Nt | Ft ] ≈ λt ∆ for small ∆ > 0, suggesting
the interpretation of a conditional mean arrival rate for λ.
25
B
Maximum likelihood estimation
Due to the presence of the frailty factor Z, the problem of estimating the parameter
θ = (a, b, κ, σ, k, z) of the reduced-form model (1) is not standard unless z = σ = 0. We
implement a variant of the filtered likelihood estimation method developed by Giesecke &
Schwenkler (2015) for point process models with incomplete data. This appendix provides
some details.
B.1
The likelihood function
Let Dt denote the data available at time t. These include the default data {Tn , Un : n ≤
Nt } and the (interpolated) covariate data {Xs : s ≤ t}. Let [0, τ ] be the sample period.
The likelihood function Lτ (θ) is the Radon-Nikodym density of the law of the data Dτ
relative to its true distribution; see Section 3.1 of Giesecke & Schwenkler (2015) for a
more precise statement. A maximum likelihood estimator (MLE) is a maximizer of the
likelihood function. To compute the likelihood, let
X
Z τ
(λs − 1)ds ,
(7)
Mτ = exp
log(λTn − )1{Tn ≤τ } −
0
n≥1
and assume that E[1/Mτ ] = 1. We define an equivalent measure P∗ on the σ-field Fτ with
Radon-Nikodym density
dP∗
1
=
.
dP
Mτ
Proposition 3.1 of Giesecke & Schwenkler (2015) states that
Lτ (θ) ∝ E∗ [Mτ | Dτ ] .
(8)
The likelihood function (8) depends on the parameter θ because Mτ is a path functional of the intensity λ = ea·(1,X) + Y + Z. If z = σ = 0, the data set Dτ contains all
relevant information to evaluate Mτ so the likelihood function simplifies to Lτ (θ) ∝ Mτ .
If z, σ > 0, then the conditional expectation (8) is not trivial because the data Dτ do not
include any observations of the frailty Z. The conditional expectation (8) is taken with
respect to the conditional P∗ -law of the frailty given the data Dτ . Girsanov’s and Lévy’s
theorems imply that the Brownian motion W driving the frailty Z remains a Brownian
motion under P∗ . As a result, Z follows the CIR process (2) under P∗ . Furthermore, Girsanov’s and Watanabe’s theorems imply that N is a standard Poisson process under P∗ .
Therefore, N is independent of the frailty Z under P∗ . Also, Z is independent of X by
assumption. Thus, the conditional P∗ -law of Z given Dτ is governed by (k, z, σ).
B.2
Approximate likelihood function
There is no closed-form expression for the likelihood (8) if σ > 0 and z > 0. Giesecke &
Schwenkler (2015) propose to approximate the likelihood using a rectangular quadrature
26
method. We will use a slightly modified approximation based on a trapezoidal quadrature
method that exploits the fact that our frailty Z follows a CIR process. This approximation does not interpolate the path of the frailty. Therefore, it is more accurate and less
susceptible to the implementation choice.
Since Z follows a CIR process under P∗ , a key result of Broadie & Kaya (2006) implies
that for times 0 ≤ t1 < t2 ≤ τ and points z1 , z2 ∈ R+ ,
Z t2
∗
λu du Dτ , Zt1 = z1 , Zt2 = z2
φ(z1 , t1 ; z2 , t2 ) = E exp −
t1
Z
= Φ(z1 , t1 ; z2 , t2 ) exp −
t2
e
a·(1,Xu )
+ Yu
du ,
(9)
t1
where
√
−0.5ζ∆
z1 z2 4ζe
1−e−ζ∆
−k∆ )
ζ(1+e−ζ∆ )
ζe−0.5(ζ−k)∆ (1 − e−k∆ ) (z1 +z2 ) k(1+e
−
−k∆
−ζ∆
1−e
1−e
Φ(z1 , t1 ; z2 , t2 ) = √
e
−0.5k∆ −ζ∆ )
k(1
−
e
Iq z1 z2 4ke
−k∆
1−e
√
for ∆ = t2 −t1 , ζ = k 2 + 2c2 , and Iq the modified Bessel function of the first kind of order
q = 2kz
− 1. An application of the law of iterated expectations leads to a reformulation of
c2
the likelihood in terms of a product of terms as in (9).
Iq
Proposition B.1. For t ≤ τ and a function u on R+ such that u(λt ) is integrable,
#
"
Nτ
Y
λTn − φ(ZTn−1 , Tn−1 ; ZTn , Tn ) Dt .
E∗ [u(λt )Mt | Dt ] = et E∗ u(λt )φ(ZTNτ , TNτ ; Zτ , τ )
n=1
P
Nt
Proof. Letting Πt = u(λt ) exp
n=1 log(λTn − ) , we calculate
E∗ [ u(λt )Mt | Dt ] exp(−t)
"
"
Z TN
Z
t
∗
∗
λu du E exp −
= E Πt exp −
!
# #
λu du Dt , (Zu )u≤TNt , Zt Dt
0
TNt
Z TN
t
∗
= E Πt exp −
λu du φ(ZTNt , TNt ; Zt , t) Dt .
(10)
t
0
Line (10) uses the fact that, by Girsanov’s theorem, the change of measure induced by Mτ
does not affect the law of Z. Consequently, Z is a Markov process under P∗ . We iterate
to complete the proof.
Proposition B.1 allows us to approximate the likelihood (8) using a trapezoidal
quadrature rule that does not interpolate the path of the frailty Z. Algorithm B.2 summarizes the numerical scheme for terms of the form E∗ [u(λτ )Mτ | Dτ ]; the likelihood is
given by u ≡ 1. Convergence of the scheme as the discretization becomes finer follows
along the lines of Theorem 4.1 of Giesecke & Schwenkler (2015). Note that the transition
law of Z is non-central chi-squared since Z follows a CIR process.
27
Algorithm B.2. Fix a state-space discretization {z 1 , . . . , z m } for the frailty Z. Let Ai be
a neighborhood of z i . Define the terms
F n (k, l) = eTn −Tn−1 ea·(1,XTn − ) + YTn − + cz k φ(z l , Tn−1 ; z k , Tn ),
pn (k, l) = P∗ ZTn ∈ Ak Dτ , ZTn−1 = z l ,
for 1 ≤ k, l ≤ m and 1 ≤ n ≤ Nτ . In addition, set TNτ +1 = τ and
F Nτ +1 (k, l) = eτ −TNτ u ea·(1,Xτ ) + Yτ + cz k φ(z l , TNτ ; z k , τ )
pNτ +1 (k, l) = P∗ Zτ ∈ Ak Dτ , ZTNτ = z l ,
For a given θ ∈ Θ, do:
(1) Initialization: Let ξ = (ξ(1), . . . , ξ(m)) be an m-dimensional vector such that ξ(i) =
1 if y ∈ Ai and otherwise ξ(i) = 0.
(2) Iteration: For n = 1, . . . , Nτ + 1 do
(a) Define the m × m-matrix Q̂j with elements F n (k, l)pn (k, l)
(b) Update the vector ξ to ξ ← Q̂j · ξ
(3) Termination: Compute an approximation of E∗ [u(λτ )Mτ | Dτ ] as
B.3
Pm
i=1
ξ(i).
Asymptotic properties
Assume that the true parameter θ0 lies in the interior of the parameter space Θ. If
z = σ = 0, we can compute an MLE θ̂τ analytically and Theorem 3.2 of Giesecke &
Schwenkler (2015) implies that the MLE is consistent.11 Under regularity and identifiability conditions, Theorem 3.3 of Giesecke & Schwenkler (2015) states that θ̂τ will be
√
asymptotically normal so that τ (θ̂τ − θ0 ) converges in distribution to a multivariate
normal distribution with mean 0 and variance-covariance matrix
−1
1 2
Σ = − lim ∇ log Lτ (θ0 )
.
τ →∞ τ
We use the following finite-horizon approximation of Σ:
−1
1 2
Σ̂τ = − ∇ log Lτ (θ0 )
.
τ
If σ > 0 and z > 0, the likelihood is approximated using Algorithm B.2. Define
B.2. An approximate MLE
LA
τ (θ) as the approximate likelihood computed by Algorithm
A
θ̂τ maximizes the approximate likelihood function:
θ̂τA ∈ arg max LA
τ (θ).
θ∈Θ
11
Condition (A3) of Giesecke & Schwenkler (2015) is irrelevant in our setting because the parameters
driving the explanatory factor X can be estimated separately from the default parameter θ.
28
Proposition 4.3 of Giesecke & Schwenkler (2015) implies that, under mild technical conditions, the approximate MLE θ̂τA will be consistent and asymptotically normal as the
sample period grows and the discretization becomes finer. A finite-horizon approximation
of the asymptotic variance-covariance matrix is given by
−1
1 2
A
A A
Σ̂τ = − ∇ log Lτ (θ̂τ )
.
τ
B.4
Implementation
The numerical algorithm and approximate likelihood maximization are implemented in R
and run on an eight-core 32GB Sun blade system. We use the Nelder-Mead optimization
method to locate the maximizers of the likelihood function. To address the issue of local
optima, we run a number of optimizations with random initial values. In order to deal
with very small or very large values of the intensity and the parameters, we scale the time
unit to one week.
C
Posterior mean of intensity
Since the data do not include observations of the frailty Z, the intensity λt cannot be
measured unless z = σ = 0. We consider the posterior mean of λt , denoted by ht . This
appendix explains the computation of ht .
Let G = (Gt )t≥0 be the right-continuous and complete filtration generated by the
observable data, i.e., Gt = σ(Dt ) ⊂ Ft . The posterior mean ht of λt is the optional
projection of λ onto G.12 It satisfies
ht = E [λt | Gt ]
(11)
almost surely, and represents the default rate given the observable data available at t (more
precisely, it is the intensity relative to G). We exploit the change of measure defined by
(7) to efficiently compute ht using two calls of Algorithm B.2, one with u(λ) ≡ 1 and one
with u(λ) = λ. This is based on the following result.
Proposition C.1. Suppose E[1/Mτ ] = 1 for Mτ defined in (7). For t ≤ τ , the posterior
mean ht satisfies almost surely
ht =
E∗ [λt Mt | Dt ]
.
E∗ [ Mt | Dt ]
(12)
Proof. Theorem T3 of Section VI of Brémaud (1980) states that, given E[1/Mτ ] = 1,
the exponential martingale M induces an equivalent probability measure P∗ on the σ∗
field Fτ with Radon-Nikodym density dP
= 1/Mτ . Moreover, the process (1/Mt )t≤τ is
dP
12
See Protter (2004) for details on the optional projection.
29
a martingale with respect to F by Theorem II.T8 of Brémaud (1980). Since Mt > 0 for
all t ≤ τ , it follows that P is also absolutely continuous with respect to P∗ on Ft with
Radon-Nikdoym density
dP = Mt
dP∗ Ft
for t ≤ τ . Optional projection indicates that P is also absolutely continuous with respect
to P∗ on the σ-algebra Gt ⊆ Ft for all t ≤ τ with Radon-Nikodym density E∗ [Mt | Gt ].
Now, λ is positive and F-adapted. This implies that
ht = E [λt | Gt ] =
E∗ [λt Mt | Gt ]
.
E∗ [ Mt | Gt ]
In order to obtain (12), note that Gt = σ(Dt ).
D
Goodness-of-fit tests
This appendix extends a key result of Das et al. (2007) for doubly-stochastic models
with observable risk factors. The extension allows us to construct goodness-of-fit tests for
our default timing model (1), which violates the doubly-stochastic hypothesis due to the
presence of the frailty and self-exciting terms. A key role is played by the posterior mean
ht of the intensity, which is discussed in Appendix C.
Rt
Proposition D.1. Let Ht be the right-continuous inverse to Ct = 0 hu du, i.e.,
Z s
Ht = max s ≥ 0 :
hu du ≤ t .
(13)
0
The time-changed process J defined by Jt = NHt is a standard Poisson process on [0, ∞)
relative to P and the minimal right-continuous completion H of (GHt )t≥0 .
Proof. A result of Meyer (1971) implies that a counting process with compensator that is
continuous and increasing to ∞ almost surely can be transformed into a standard Poisson
process by a change of time given by the compensator. Relative to the filtration G generated by the observable data (see Appendix C), the counting process N has compensator
Rt
C given by Ct = 0 hu du, where h is the posterior mean of the intensity given by Proposition C.1. Since each Ht is a stopping time with respect to G, we can define the stopping
time σ-algebra Ht = GHt , which is the smallest σ-algebra containing all right-continuous
left limit processes sampled at Ht . Meyer’s theorem implies that the time-scaled process
J is a standard Poisson process in the time-changed filtration H, which is the minimal
right-continuous completion of (Ht )t≥0 .
Proposition D.1 states that the default count Nt can be transformed into a standard Poisson process by a change of time given by the cumulative posterior mean of the
intensity. The posterior mean is given by Proposition C.1, and can be computed using
Algorithm B.2. This result allows us to test model fit by testing the Poisson property of
the time-scaled default times.
30
E
Out-of-sample simulation
This appendix describes the simulation procedure we use to forecast the conditional distribution of the total number of defaults out-of-sample.
Inspired by Das et al. (2007), Duffie et al. (2007) and Duffie et al. (2009), we employ a
daily Gaussian vector auto-regression of order 41 for the vector containing the rolling S&P
500 yearly return and volatility, the yield of the 3-month Treasury Bill, and the spread
between the yields of the 10-year and the 1-year Treasury bonds. We employ a monthly
ARMA(1,1) model for the growth rate of the industrial production growth, a quarterly
MA(1) model for the GDP growth rate, and a weekly AR(1) model for the spread between
the yields of BAA and AAA rated corporate bonds. We choose the optimal autoregression
and moving-average orders according to the Akaike information criterion.
Using data Dt available at time t, we estimate the models of the explanatory variables and the models of default timing in Table 3. We then compute the model-implied
conditional distribution of the number of defaults during (t, t + 1]. The distribution is calculated by Monte Carlo simulation of default times using 100,000 trials. The simulation
is based on the (daily) discretization of the posterior mean ht during (t, t + 1] as described
in Giesecke & Teng (2012), and the simulation of the explanatory variables during that
interval. We interpolate the simulated paths of the less frequently observed explanatory
variables to obtain a series of daily values for all variables.
The feasibility of event simulation using ht along with our ability to compute ht using
Proposition C.1 eliminates the need to generate paths of the frailty during (t, t + 1], which
would be required if the simulation were based on the intensity λ. This increases the
efficiency of event prediction by an order of magnitude relative to the prediction based
on λ that is standard in the frailty literature.
References
Acemoglu, Daron, Asuman Ozdaglar & Alireza Tahbaz-Salehi (2015), ‘Systemic risk and
stability in financial networks’, American Economic Review 105(2), 564–608.
Acemoglu, Daron, Vasco M. Carvalho, Asuman Ozdaglar & Alireza Tahbaz-Salehi (2012),
‘The network origins of aggregate fluctuations’, Econometrica 80(5), 1977–2016.
Acharya, Viral V., Yakov Amihuda & Sreedhar T. Bharath (2015), ‘Liquidity risk of
corporate bond returns: A conditional approach’, Journal of Financial Economics .
Forthcoming.
Aı̈t-Sahalia, Yacine, Julio Cacho-Diaz & Roger Laeven (2015), ‘Modeling financial contagion using mutually exciting jump processes’, Journal of Financial Economics .
forthcoming.
31
Altman, Edward I. (1968), ‘Financial ratios, discriminant analysis and the prediction of
corporate bankruptcy’, Journal of Finance 23(4), 589–609.
Aragon, George O. & Philip E. Strahan (2012), ‘Hedge funds as liquidity providers: Evidence from the lehman bankruptcy’, Journal of Financial Economics 103(3), 570 –
587.
Atkeson, Andrew G., Andrea L. Eisfeldt & Pierre-Olivier Weill (2014), Measuring the
financial soundness of u.s. firms, 1926-2012. Working Paper, University of California
at Los Angeles.
Bams, Dennis, Magdalena Pisa & Christian Wolff (2014), Ripple effects from industry
defaults. Working Paper.
Baur, Dirk G. (2012), ‘Financial contagion and the real economy’, Journal of Banking &
Finance 36(10), 2680 – 2692. Australasian Finance Conference 2010: Liquidity crisis,
financial integration and global financial stability.
Benmelech, Efraim & Jennifer Dlugosz (2009), ‘The alchemy of cdo credit ratings’, Journal
of Monetary Economics 56(5), 617 – 634.
Benzoni, Luca, Pierre Collin-Dufresne, Robert Goldstein & Jean Helwege (2015), ‘Modeling credit contagion via the updating of fragile beliefs’, Review of Financial Studies
. forthcoming.
Bernanke, Ben S., Mark Gertler & Simon Gilchrist (1999), The financial accelerator in a
quantitative business cycle framework, in J. B.Taylor & M.Woodford, eds, ‘Handbook
of Macroeconomics’, Vol. 1, Part C, Elsevier, chapter 21, pp. 1341 – 1393.
Berndt, Antje, Peter Ritchken & Zhiqiang Sun (2010), ‘On correlation and default clustering in credit markets’, Review of Financial Studies 23(7), 2680–2729.
Bhansali, Vineer, Robert Gingrich & Francis A Longstaff (2008), ‘Systemic credit risk:
What is the market telling us?’, Financial Analysts Journal pp. 16–24.
Bharath, Sreedhar T. & Tyler Shumway (2008), ‘Forecasting default with the merton
distance to default model’, Review of Financial Studies 21(3), 1339–1369.
Boone, Audra L. & Vladimir I. Ivanov (2012), ‘Bankruptcy spillover effects on strategic
alliance partners’, Journal of Financial Economics 103(3), 551 – 569.
Bowsher, Clive (2007), ‘Modelling security market events in continuous time: Intensity
based, multivariate point process models’, Journal of Econometrics 141, 876–912.
Brémaud, Pierre (1980), Point Processes and Queues – Martingale Dynamics, SpringerVerlag, New York.
32
Broadie, Mark & Ozgur Kaya (2006), ‘Exact simulation of stochastic volatility and other
affine jump diffusion processes’, Operations Research 54(2), 217–231.
Brunnermeier, Markus K. (2009), ‘Deciphering the liquidity and credit crunch 2007-2008’,
Journal of Economic Perspectives 23(1), 77–100.
Cameron, A. Colin & Pravin K. Trivedi (1998), Regression Analysis of Count Data, Econometric Society Monographs, Cambridge University Press.
Campbell, John Y., Jens Hilscher & Jan Szilagyi (2008), ‘In search of distress risk’, Journal
of Finance 63(6), 2899–2939.
Chakrabarty, Bidisha & Gaiyan Zhang (2012), ‘Credit contagion channels: Market microstructure evidence from lehman brothers’ bankruptcy’, Financial Management
41(2), 320–343.
Chava, Sudheer, Catalina Stefanescu & Stuart Turnbull (2011), ‘Modeling expected loss’,
Management Science 57(7), 1267–1287.
Chava, Sudheer & Robert Jarrow (2004), ‘Bankruptcy prediction with industry effects’,
Review of Finance 8, 537–569.
Christoffersen, Peter (1998), ‘Evaluating interval forecasts’, International Economic Review 39, 842–862.
Christoffersen, Peter, Jan Ericsson, Kris Jacobs & Xisong Jin (2010), Exploring dynamic
default dependence. Working Paper.
Collin-Dufresne, Pierre, Robert S. Goldstein & J. Spencer Martin (2001), ‘The determinants of credit spread changes’, Journal of Finance 56(6), 2177–2207.
Cont, Rama & Andreea Minca (2013), ‘Recovering portfolio default intensities implied by
cdo quotes’, Mathematical Finance 23(1), 94–121.
Coval, Joshua D., Jakub W. Jurek & Erik Stafford (2009), ‘Economic catastrophe bonds’,
American Economic Review 99(3), 628–66.
Covas, Francisco & Wouter J. Den Haan (2011), ‘The cyclical behavior of debt and equity
finance’, American Economic Review 101(2), 877–99.
Cox, D. R. (1972), ‘Regression models and life-tables’, Journal of the Royal Statistical
Society. Series B (Methodological) 34(2), 187–220.
Das, Sanjiv, Darrell Duffie, Nikunj Kapadia & Leandro Saita (2007), ‘Common failings:
How corporate defaults are correlated’, Journal of Finance 62, 93–117.
33
Delloye, Martin, Jean-David Fermanian & Mohammed Sbai (2006), ‘Dynamic frailties and
credit portfolio modeling’, Risk 19(1), 101–109.
Duffie, Darrell (1998), First-to-default valuation. Working Paper, Stanford University.
Duffie, Darrell, Andreas Eckner, Guillaume Horel & Leandro Saita (2009), ‘Frailty correlated default’, Journal of Finance 64, 2089–2123.
Duffie, Darrell, Leandro Saita & Ke Wang (2007), ‘Multi-period corporate default prediction with stochastic covariates’, Journal of Financial Economics 83(3), 635–665.
Duffie, Darrell & Nicolae Garleanu (2001), ‘Risk and valuation of collateralized debt
obligations’, Financial Analysts Journal 57(1), 41–59.
Dumontaux, Nicolas & Adrian Pop (2013), ‘Understanding the market reaction to shockwaves: Evidence from the failure of lehman brothers’, Journal of Financial Stability
9(3), 269 – 286.
Eisenberg, Larry & Thomas H. Noe (2001), ‘Systemic risk in financial systems’, Management Science 47(2), 236–249.
Elliott, Matthew, Benjamin Golub & Matthew O. Jackson (2014), ‘Financial networks
and contagion’, American Economic Review 104(10), 3115–53.
Engle, Robert & Simone Manganelli (2004), ‘Caviar: Conditional autoregressive value at
risk by regression quantiles’, Journal of Business and Economic Statistics 22(4), 367–
381.
Errais, Eymen, Kay Giesecke & Lisa Goldberg (2010), ‘Affine point processes and portfolio
credit risk’, SIAM Journal on Financial Mathematics 1, 642–665.
Feldhütter, Peter (2007), An empirical investigation of an intensity based model for pricing
CDO tranches. Working Paper, Copenhagen Business School.
Fernando, Chitru S., Anthony D. May & William L. Megginson (2012), ‘The value of
investment banking relationships: Evidence from the collapse of lehman brothers’,
The Journal of Finance 67(1), 235–270.
Giesecke, Kay (2004), ‘Correlated default with incomplete information’, Journal of Banking and Finance 28, 1521–1545.
Giesecke, Kay, Francis A. Longstaff, Stephen Schaefer & Ilya Strebulaev (2011), ‘Corporate bond default risk: A 150-year perspective’, Journal of Financial Economics
102(2), 233 – 250.
34
Giesecke, Kay, Francis A. Longstaff, Stephen Schaefer & Ilya Strebulaev (2014), ‘Macroeconomic effect of corporate default crises: A long-term perspective’, Journal of Financial Economics 111(2), 297–310.
Giesecke, Kay & Gerald Teng (2012), Numerical solution of jump-diffusion SDEs. Working
Paper, Stanford University.
Giesecke, Kay & Gustavo Schwenkler (2015), Filtered likelihood for point processes. Working paper.
Gilchrist, Simon & Egon Zakrajšek (2012), ‘Credit spreads and business cycle fluctuations’, American Economic Review 102(4), 1692–1720.
Gouriéroux, C., A. Monfort & J.P. Renne (2014), ‘Pricing default events: Surprise, exogeneity and contagion’, Journal of Econometrics 182(2), 397 – 411.
Griffin, John M. & Jordan Nickerson (2015), Debt correlations in the wake of the financial
crisis: What are appropriate default correlations for structured products? Working
Paper.
Hamilton, David (2005), Moodys senior ratings algorithm and estimated senior ratings.
Moodys Investors Service.
Hawkes, Alan G. (1971), ‘Spectra of some self-exciting and mutually exciting point processes’, Biometrika 58(1), 83–90.
Helwege, Jean (2010), ‘Financial firm bankruptcy and systemic risk’, Journal of International Financial Markets, Institutions and Money 20(1), 1 – 12.
Helwege, Jean & Gaiyan Zhang (2012), Financial firm bankruptcy and contagion. Working
Paper.
Hendricks, Darryll (1996), ‘Evaluation of value-at-risk models using historical data’, Economic Policy Review 2(1), 39–69.
Hertzel, Michael G. & Micah S. Officer (2012), ‘Industry contagion in loan spreads’,
Journal of Financial Economics 103, 493–506.
Hertzel, Michael G., Zhi Li, Micah S. Officer & Kimberly J. Rodgers (2008), ‘Inter-firm
linkages and the wealth effects of financial distress along the supply chain’, Journal
of Financial Economics 87(2), 374 – 387.
Hull, John C. & Alan D. White (2008), ‘Dynamic models of portfolio credit risk: A
simplified approach’, The Journal of Derivatives 15(4), 9–28.
Jarrow, Robert A., David Lando & Fan Yu (2005), ‘Default risk and diversification: Theory
and applications’, Mathematical Finance 15, 1–26.
35
Jarrow, Robert A. & Fan Yu (2001), ‘Counterparty risk and the pricing of defaultable
securities’, Journal of Finance 56(5), 555–576.
Jorion, Philippe & Gaiyan Zhang (2007), ‘Good and bad credit contagion: Evidence from
credit default swaps’, Journal of Financial Economics 84(3), 860–883.
Jorion, Philippe & Gaiyan Zhang (2009), ‘Credit contagion from counterparty risk’, The
Journal of Finance 64(5), 2053–2087.
Karlis, Dimitris & Evdokia Xekalaki (2000), ‘A simulation comparison of several procedures for testing the Poisson assumption’, The Statistician 49, 355–382.
Koopman, Siem Jan, Andre Lucas & Andre Monteiro (2008), ‘The multi-stage latent factor intensity model for credit rating transitions’, Journal of Econometrics
142(1), 399–424.
Koopman, Siem Jan, Andre Lucas & Bernd Schwaab (2011), ‘Modeling frailtycorrelated defaults using many macroeconomic covariates’, Journal of Econometrics
162(2), 312–325.
Koopman, Siem Jan, André Lucas & Bernd Schwaab (2012), ‘Dynamic factor models with
macro, frailty, and industry effects for u.s. default counts: The credit crisis of 2008’,
Journal of Business and Economic Statistics 30(4), 521–532.
Kupiec, Paul H. (1995), ‘Techniques for verifying the accuracy of risk measurement models’, Journal of Derivatives 3(2), 73–84.
Lando, David & Mads Stenbo Nielsen (2010), ‘Correlation in corporate defaults: Contagion or conditional independence?’, Journal of Financial Intermediation 19(3), 355–
372.
Lang, Larry & Rene Stulz (1992), ‘Contagion and competitive intra-industry effects of
bankruptcy announcements’, Journal of Financial Economics 32, 45–60.
Lee, Yongwoong & Ser-Huang Poon (2014), ‘Forecasting and decomposition of portfolio
credit risk using macroeconomic and frailty factors’, Journal of Economic Dynamics
and Control 41, 69 – 92.
Longstaff, Francis A. & Monika Piazzesi (2004), ‘Corporate earnings and the equity premium’, Journal of Financial Economics 74(3), 401 – 421.
Longstaff, Francis & Arvind Rajan (2008), ‘An empirical analysis of the pricing of collateralized debt obligations’, Journal of Finance 63(2), 529–563.
Meyer, Paul-André (1971), Démonstration simplifée d’un théorème de Knight, in
‘Séminaire de Probabilités V, Lecture Notes in Mathematics 191’, Springer-Verlag
Berlin, pp. 191–195.
36
Mistrulli, Paolo Emilio (2011), ‘Assessing financial contagion in the interbank market:
Maximum entropy versus observed interbank lending patterns’, Journal of Banking
& Finance 35(5), 1114 – 1127.
Monfort, Alain & Jean-Paul Renne (2013), ‘Default, liquidity, and crises: an econometric
framework’, Journal of Financial Econometrics 11(2), 221–262.
Mortensen, Allan (2006), ‘Semi-analytical valuation of basket credit derivatives in
intensity-based models’, Journal of Derivatives 13, 8–26.
Ohlson, James A. (1980), ‘Financial ratios and the probabilistic prediction of bankruptcy’,
Journal of Accounting Research 18(1), 109–131.
Protter, Philip (2004), Stochastic Integration and Differential Equations, Springer-Verlag,
New York.
Shumway, Tyler (2001), ‘Forecasting bankruptcy more accurately: A simple hazard
model’, Journal of Business 74, 101–124.
Stulz, Rene M. (2010), ‘Credit default swaps and the credit crisis’, Journal of Economic
Perspectives 24(1), 73–92.
Tian, Shaonan, Yan Yu & Hui Guo (2015), ‘Variable selection and corporate bankruptcy
forecasts’, Journal of Banking & Finance 52, 89 – 100.
Winkelmann, Rainer (1995), ‘Duration dependence and dispersion in count-data models’,
Journal of Business & Economic Statistics 13(4), 467–474.
Yang, Jian & Yinggang Zhou (2013), ‘Credit risk spillovers among financial institutions around the global credit crisis: Firm-level evidence’, Management Science
59(10), 2343–2359.
37
38
Weekly
Monthly
CRED
REC
0.19
1.11
8.05
6.98
−1.12
5.28
17.46
8.23
6.71
2.36
Mean
0.40
0.46
2.41
2.79
1.20
3.23
7.50
17.32
4.27
4.11
deviation
Standard
1.55
1.78
0.78
0.61
0.35
0.58
3.40
7.26
3.53
3.27
2.91
3.75
2.50
3.11
−0.39
0.44
5.99
3.95
−0.70
0.75
Kurtosis
Skewness
0.00
0.52
3.26
1.43
−3.53
0.00
2.11
0.00
0.80
6.45
4.89
−1.93
3.30
11.06
−2.14
4.40
−8.40
−48.82
0.62
quartile
First
−11.78
Min.
0.00
0.98
7.73
6.79
−1.20
5.10
16.97
9.95
6.10
2.76
Median
0.00
1.30
9.04
8.33
−0.30
7.13
22.43
20.35
8.60
4.90
quartile
Third
1.00
3.47
15.85
15.84
3.44
17.14
37.07
68.57
25.50
11.22
Max.
516
2243
2243
10740
10740
10740
11218
11218
172
516
observations
Number of
Table 1: Summary statistics of explanatory variables. This table provides summary statistics for the time series of macroeconomic
explanatory variables.
Weekly
Daily
LEVEL
AAA
Daily
VOL
Daily
Daily
RET
10Y
Quarterly
GDP
Daily
Monthly
IP
SLOPE
Sample frequency
Variable
Variable
Constant
log(DEFDEBT)
Regression 1
Regression 2
*** 1.4334
*** 3.5208
(0.2583)
(0.5284)
*** 0.4556
*** 0.3581
(0.0415)
(0.0408)
IP
0.0250
(0.0197)
GDP
0.0078
(0.0217)
−0.0046
RET
(0.0041)
VOL
0.0094
(0.0076)
LEVEL
0.0057
(0.1904)
SLOPE
0.0985
(0.2147)
−0.2689
10Y
(0.1438)
−0.1444
CRED
(0.1708)
AAA
0.0249
(0.1971)
REC
0.0915
(0.1762)
Adjusted R2
0.155
0.269
Data points
2001
2001
Table 2: Coefficient estimates and standard errors of ordinary least squares regressions
of total liabilities. This table presents the results of ordinary least squares regressions of
the logarithm of the total liabilities of a firm at default on the logarithm of the defaulted
debt and our macroeconomic variables at the time of default. Data on total liabilities
is obtained from the quarterly Compustat file when available and otherwise from the
annually Compustat file. * indicates significance at the 95% level, ** significance at the
99% level, and *** significance at the 99.9% level.
39
40
b=z=σ=0
λt =
λt =
λt =
λt =
Intensity
P
exp(a0 + di=1 ai Xi,t )
P
exp(a0 + di=1 ai Xi,t )
P
exp(a0 + di=1 ai Xi,t )
P
exp(a0 + di=1 ai Xi,t )
+Yt
+Yt
+Zt
+Zt
Table 3: Reduced-form model alternatives. The table reports the intensity specification for each reduced-form model we estimate.
Each model addresses a different set of clustering sources.
Base
z=σ=0
b=0
Base + Frailty
Base + Contagion
None
Parameter Restrictions
Complete
Model
41
Base Base + Contagion Base + Frailty
*** 1.0141
** −1.6639
0.5649
(0.1349)
(0.6453)
(0.8971)
−0.0509
−0.0027
−0.0616
(0.0086)
(0.0318)
(0.0471)
*** −0.1117
*** −0.1197
0.0031
(0.0098)
(0.0343)
(0.0391)
* −0.0045
0.0015
−0.0193
(0.0018)
(0.0074)
(0.0173)
** 0.0112
0.0041
0.0123
(0.0038)
(0.0222)
(0.0246)
** −0.0466
0.0277
*** −0.6734
(0.0149)
(0.0857)
(0.1546)
* 0.0821
0.0019
−0.4748
(0.0352)
(0.2770)
(0.2836)
*** −0.7305
−0.0192
−0.0971
(0.0741)
(0.4253)
(0.3035)
*** 0.1288
(0.0146)
*** 0.0156
(0.0002)
*** 0.5335
(0.0577)
*** 0.0101
(0.0017)
*** 0.0563
(0.0098)
446.12
606.21
599.24
Table 4: Parameter estimates for each of the four model alternatives described in Table 3. The asymptotic standard errors are
given parenthetically. They are computed using the Hessian matrix of the log-likelihood at the parameter estimates reported.
Some of the variables of Table 1 are not included here due to lack of significance. * indicates significance at the 95% level, **
significance at the 99% level, and *** significance at the 99.9% level.
Log-likelihood
Contagion decay rate κ
Contagion sensitivity b
Frailty mean reversion level z
Frailty mean reversion rate k
Frailty volatility σ
CRED coefficient a9
SLOPE coefficient a8
LEVEL coefficient a6
VOL coefficient a5
RET coefficient a4
GDP coefficient a3
IP coefficient a1
Constant a0
Complete
** −1.6926
(0.6765)
−0.0013
(0.0334)
*** −0.1235
(0.0360)
0.0017
(0.0078)
0.0038
(0.0208)
0.0284
(0.0612)
0.0007
(0.1751)
−0.01804
(0.3907)
0.2221
(0.1602)
* 6.0203
(2.9545)
* 0.0041
(0.0020)
*** 0.0103
(0.0017)
*** 0.0571
(0.0096)
606.29
42
Table 5: Likelihood ratio tests. This table reports likelihood ratio test statistics, p-values, and degrees of freedom for the
corresponding asymptotic distributions. A likelihood ratio test evaluates the fit of an alternative model relative to a nested
benchmark model. The test statistic is given by twice the difference between the maximum log-likelihood of the alternative
model and the benchmark model. The log-likelihood values are reported in Table 4. The test statistic has, asymptotically, a
chi-squared distribution with degrees of freedom equal to the number of additional parameters included in the alternative. ***
indicates significance at the 99.9% level.
Benchmark model
Base
Base
Base Base + contagion Base + frailty
Alternative model Base + contagion Base + frailty Complete
Complete
Complete
Test statistic
320.18
299.60
320.34
0.16
14.10
Degrees of freedom
2
3
5
3
2
p-value
*** 0.000
*** 0.000 *** 0.000
0.984
*** 0.001
43
***
***
***
***
***
**
***
***
***
***
w
2
4
6
8
10
w
2
4
6
8
10
w
2
4
6
8
10
w
2
4
6
8
10
***
***
***
***
***
***
***
***
***
***
w
2
4
6
*
8
**
10 ***
Base
0.000
0.000
0.000
0.000
0.000
Base
0.000
0.000
0.000
0.000
0.000
Base
0.575
0.158
0.015
0.001
0.000
Kocherlakota-Kocherlakota Test
Base + frailty Base + contagion Complete
0.508
0.688
0.693
0.466
0.719
0.807
0.482
0.833
0.916
0.515
0.965
0.949
0.489
0.952
0.978
Fisher Dispersion Test
Base + frailty Base + contagion Complete
1.000
1.000
1.000
1.000
0.997
0.949
1.000
0.884
0.771
1.000
0.647
0.657
1.000
0.674
0.592
Chi-Squared Test
Base + frailty Base + contagion Complete
*** 0.000
*** 0.000 *** 0.000
*** 0.000
** 0.008
0.115
*** 0.000
0.248
0.517
*** 0.000
0.763
0.746
*** 0.000
0.683
0.849
Table 6: Poisson distribution tests. p-values of Poisson distribution tests for the counts of the binned event counts Piw . The
Potthoff-Whittinghill-Bohning test compares the empirical moments of the Piw to the theoretical moments. Its asymptotic
distribution is standard normal (Karlis & Xekalaki (2000)). The Kocherlakota-Kocherlakota test evaluates the empirical moment
generating function of the Piw and compares to its theoretical counterpart, see Karlis & Xekalaki (2000). The upper tail test
examines the fatness of the right tail of the empirical distribution of the Piw ; see Das et al. (2007). We compute empirical p-values
for the Kocherlakota-Kocherlakota and the upper tail tests via bootstrapping with 100, 000 samples. The independence test is a
BDS test with a distance parameter of one standard deviation. The Fisher dispersion test examines the variance of the realized
Piw s and is described in Das et al. (2007). Finally, we also perform a standard chi-squared goodness of fit test for the Poisson
distribution. The number of samples of Piw for each model are as follows (ordered by increasing bin size). Base: 727, 364, 243,
182, 146. Base + frailty: 775, 388, 259, 194, 155. Base + contagion: 729, 365, 243, 183, 146. Complete: 730, 365, 244, 183, 146.
* indicates rejection with 95% confidence, ** rejection with 99% confidence, and *** rejection with 99.9% confidence.
***
***
***
***
***
w
2
4
6
8
10
Potthoff-Whittinghill-Bohning Test
Base Base + frailty Base + contagion Complete
0.000
*** 0.000
*** 0.000 *** 0.000
0.000
*** 0.000
* 0.012
0.126
0.000
*** 0.000
0.253
0.499
0.000
** 0.001
0.737
0.717
0.000
** 0.002
0.660
0.820
Independence Test
Base Base + frailty Base + contagion Complete
0.000
0.911
0.961
0.517
0.000
0.655
0.148
0.163
0.000
* 0.030
0.118
0.064
0.000
0.074
0.296
** 0.004
0.000
** 0.002
* 0.018
** 0.001
Upper Tail Test
Base Base + frailty Base + contagion Complete
0.004
1.000
0.994
0.985
0.000
1.000
0.921
0.796
0.000
1.000
0.742
0.630
0.000
1.000
0.741
0.672
0.000
1.000
0.769
0.632
Theoretical
Base model
Base + contagion model
Base + frailty model
Complete model
Theoretical
Base model
Base + contagion model
Base + frailty model
Complete model
Theoretical
Base model
Base + contagion model
Base + frailty model
Complete model
Theoretical
Base model
Base + contagion model
Base + frailty model
Complete model
Theoretical
Base model
Base + contagion model
Base + frailty model
Complete model
w=2
Observations
Mean
2.000
727
1.997
729
1.992
775
1.874
730
1.989
w=4
Observations
Mean
4.000
364
3.989
365
3.978
388
3.742
365
3.978
w=6
Observations
Mean
6.000
243
5.975
243
5.975
259
5.606
244
5.951
w=8
Observations
Mean
8.000
182
7.978
183
7.934
194
7.485
183
7.934
w = 10
Observations
Mean
10.000
146
9.945
146
9.945
155
9.368
146
9.945
Variance Skewness Kurtosis
2.000
0.707
3.500
2.617
1.134
6.161
1.585
0.565
3.268
1.302
0.613
3.606
1.597
0.611
3.206
Variance Skewness Kurtosis
4.000
0.500
3.250
6.997
0.846
4.581
3.247
0.391
2.989
2.466
0.393
2.999
3.527
0.592
3.301
Variance Skewness Kurtosis
6.000
0.408
3.167
13.983
0.800
4.274
5.371
0.343
2.854
3.720
0.309
3.203
5.586
0.232
2.690
Variance Skewness Kurtosis
8.000
0.354
3.125
21.900
0.570
3.618
7.655
0.206
3.055
4.987
0.069
2.572
7.633
0.236
2.488
Variance Skewness Kurtosis
10.000
0.316
3.100
33.087
0.502
3.353
9.431
0.095
3.093
6.104
0.168
2.876
9.680
0.130
2.549
Table 7: Moments of binned event counts. This table reports the first four empirical moments of the binned event counts Piw for bin sizes w ∈ {2, 4, 6, 8, 10}, for each alternative
model. We also report the moments of the theoretical Poisson distributions with rate w.
44
45
Base Base + frailty Base + contagion Complete
5/22
0/22
2/22
1/22
*** 0.000
0.506
* 0.020
0.221
0.951
1.000
0.107
0.752
*** 0.000
0.802
* 0.018
0.450
* 0.020
1.000
0.318
0.972
−11.98%
26.44%
−8.13%
−6.32%
17.31%
33.30%
14.37%
13.77%
Table 8: Out-of-sample forecast accuracy tests. The table reports p-values of various tests of forecast accuracy and other measures
of accuracy. The violation rate indicates the number of times that the realized number of defaults in a given year exceeds the
forecast value-at-risk. The null hypothesis of the unconditional coverage test of Kupiec (1995) is that the violation rate does not
exceed 1%. The null hypothesis of the independence test of Christoffersen (1998) is that a binary first-order Markov chain for the
hit indicators has transition matrix given by the identity matrix. The asymptotic distribution of these tests is chi-squared with
one degree of freedom. The Markov test combines the coverage and independence tests. It takes the null of the coverage test and
the alternative of the independence test, see Christoffersen (1998). The asymptotic distribution of this test is chi-squared with
two degrees of freedom. The null hypothesis of the dynamic quantile test due to Engle & Manganelli (2004) is that there is no
correlation between the hit indicators and the number of defaults per year. The asymptotic distribution is chi-squared with three
degrees of freedom. Finally, the mean relative bias is the average relative difference of the value-at-risk predicted by each model,
compared to the average prediction of all models. The root mean squared relative bias is the standard deviation of the latter. *
indicates rejection with 95% confidence, *** indicates rejection with 99% confidence, and *** rejection with 99.9% confidence.
Model
Violation Rate
Unconditional Coverage Test
Independence Test
Markov Test
Dynamic Quantile Test
Mean Relative Bias
Root Mean Squared Relative Bias
46
Monthly
Monthly
Monthly
Monthly
Monthly
Monthly
Monthly
Monthly
Monthly
Monthly
QUICK
SD
TL
DTD
LBA
NITA
TLTA
RSIZE
RET
VOL
5.62
−1.10
10.76
2.69
−10.05
16.26
0.26
0.03
1.58
2.27
951.41
0.23
0.58
deviation
Standard
0.72
0.00
4.68
3.16
628.71
0.18
0.92
Mean
9.89
−2.03
1.68
−1.19
−1.27
5.95
5.10
4.74
3.20
2.47
−0.04
0.28
3.76
10.50
5.06
3.55
Kurtosis
0.72
2.63
1.66
0.84
Skewness
0.00
−24.23
−19.74
0.00
−0.20
9.18
−3.39
−11.13
0.54
−0.01
3.56
1.50
−2.20
1.00
75.20
0.02
0.50
quartile
First
0.00
0.00
0.00
Min.
13.15
0.00
−9.52
0.70
0.00
4.72
2.99
260.65
0.09
0.84
Median
19.71
2.36
−8.27
0.89
0.02
5.81
4.43
708.35
0.25
1.23
quartile
Third
60.76
10.44
−5.64
1.52
0.08
8.51
13.06
5851.77
0.96
2.89
Max.
75529
75531
80636
106036
106590
83906
8751
106048
101739
95739
across firms
Number of obs.
Table 9: Summary statistics of firm-specific default risk factors. This table provides summary statistics for the time series of
firm-specific default risk factors. Except for distance to default, we construct time series from accounting and stock market data
from the joint Compustat/CRSP database quarterly file when available, and otherwise from the annually file. If we were to
construct our own distance to default time series using Compustat/CRSP data, we would have to neglect about two thirds of our
default events due to data unavailability. To circumvent this issue, we obtain distance to default data from the Credit Research
Initiative (CRI) at the National University of Singapore, which is only available starting in the year 1991. The moments and
quantiles are computed from the cross section of firms in our default data set with available data on CRSP/ Compustat / CRI.
We exclude the 5% cross sectional extreme values to ensure continuity of our time series.
Sample frequency
Variable
47
(0.000)
(0.000)
516
516
0.550
(0.005)
*** −0.025
(0.005)
*** 0.051
(0.005)
*** −0.068
(0.006)
*** −0.029
(0.006)
0.008
(0.005)
−0.002
(0.000)
*** 0.001
(0.000)
0.000
(0.001)
* −0.001
(0.001)
−0.001
(0.011)
0.008
TL
264
0.705
(0.001)
* 0.002
(0.001)
*** 0.002
(0.001)
*** −0.002
(0.001)
0.000
(0.001)
*** 0.003
(0.001)
−0.001
(0.000)
*** 0.000
(0.000)
*** 0.000
(0.000)
** 0.000
(0.000)
0.000
(0.002)
* 0.004
DTD
516
0.602
(0.004)
*** −0.016
(0.004)
*** 0.037
(0.004)
*** −0.048
(0.004)
*** −0.016
(0.004)
* 0.010
(0.004)
−0.004
(0.000)
*** 0.001
(0.000)
0.000
(0.000)
−0.001
(0.000)
−0.000
(0.009)
0.002
LBA
516
0.536
(0.005)
*** −0.026
(0.005)
*** 0.054
(0.005)
*** −0.071
(0.006)
*** −0.030
(0.006)
0.009
(0.005)
−0.003
(0.000)
*** 0.001
(0.000)
0.0000
(0.001)
*** −0.002
(0.001)
−0.001
(0.011)
0.016
NITA
516
0.539
(0.005)
*** −0.026
(0.005)
*** 0.052
(0.005)
*** −0.067
(0.006)
*** −0.030
(0.006)
0.009
(0.005)
−0.002
(0.000)
*** 0.001
(0.000)
0.0000
(0.000)
** −0.001
(0.001)
−0.001
(0.011)
0.014
TLTA
516
0.656
(0.003)
** −0.008
(0.003)
*** 0.027
(0.003)
*** −0.033
(0.003)
** −0.010
(0.003)
* 0.007
(0.003)
−0.003
(0.000)
*** 0.001
(0.000)
0.0000
(0.000)
0.000
(0.000)
0.000
516
0.652
(0.003)
* −0.007
(0.003)
*** 0.023
(0.003)
*** −0.031
(0.003)
** −0.008
(0.003)
* 0.007
(0.003)
−0.003
(0.000)
*** 0.000
(0.000)
0.000
(0.000)
0.000
(0.000)
0.000
(0.006)
0.003
−0.004
(0.006)
RET
RSIZE
516
0.660
(0.003)
* −0.006
(0.003)
*** 0.025
(0.003)
*** −0.031
(0.003)
** −0.009
(0.003)
* 0.007
(0.003)
−0.003
(0.000)
** 0.000
(0.000)
0.000
(0.000)
0.000
(0.000)
0.000
(0.006)
0.001
VOL
Table 10: Coefficient estimates and standard errors of ordinary least squares regressions of firm specific default risk factors.
This table presents the results of ordinary least squares regressions of the cross sectional averages of key firm-specific default risk
factors on our macroeconomic variables. We censor firms from the cross sectional averages after a default. * indicates significance
at the 95% level, ** significance at the 99% level, and *** significance at the 99.9% level.
516
Data points
0.522
(0.005)
(0.005)
0.516
*** −0.026
*** −0.022
(0.005)
(0.004)
(0.005)
*** −0.064
*** −0.060
(0.005)
(0.006)
(0.005)
*** 0.051
*** −0.029
*** −0.025
*** 0.044
(0.005)
(0.005)
(0.004)
(0.005)
−0.003
−0.001
* 0.011
(0.000)
(0.000)
0.007
** 0.001
** 0.001
Adjusted R2
REC
AAA
CRED
10Y
SLOPE
LEVEL
VOL
RET
(0.000)
** −0.001
* −0.001
GDP
(0.000)
(0.001)
(0.000)
0.000
−0.001
−0.001
0.000
(0.011)
(0.010)
IP
0.018
* 0.021
Constant
SD
QUICK
Variable
Fisher Dispersion Test
w
Base Model I
Model II
2
0.981
0.110
0.324
4
0.775 * 0.021
0.377
6
0.278 * 0.013
0.406
8
0.111 ** 0.002
0.113
10 * 0.038 ** 0.004
* 0.037
Upper Tail Test (mean)
w
Base Model I
Model II
2
0.891
0.476
0.428
4
0.523
0.211
0.447
6
0.268
0.062
0.501
8
0.138 * 0.012
0.233
10
0.224 * 0.013
0.120
Potthoff-Whittinghill-Bohning Test
w
Base Model I
Model II
2 * 0.022
0.156
0.582
4
0.443
0.023
0.625
6
0.513 * 0.012
0.696
8
0.189 ** 0.001
0.154
10
0.051 ** 0.004
0.051
Serial Correlation Test 1
w
Base Model I Model II
2
0.324 * 0.047
0.289
4
0.059 * 0.011
0.392
6
* 0.022 ** 0.004
0.722
8 ** 0.010 ** 0.003
0.170
10 ** 0.008 ** 0.002
0.177
Upper Tail Test (median)
w
Base Model I Model II
2
1.000
1.000
0.728
4
0.275
0.972
0.972
6
* 0.031
0.136
0.734
8
0.369
0.260
0.257
10
0.555 * 0.025
0.566
Kocherlakota-Kocherlakota Test
w
Base Model I Model II
2
* 0.023
0.152
0.558
4
0.353 * 0.028
0.768
6
0.656 * 0.012
0.787
8
0.305 ** 0.002
0.192
10
0.071 ** 0.006
0.112
Table 11: Comparison to Lando & Nielsen (2010). p-values of Poisson distribution tests
for the base model and Models I and II of Lando & Nielsen (2010). We compute tests
statistics and p-values as indicated in Lando & Nielsen (2010) after fitting the base model
to the data subsample that mirrors the data used by Lando & Nielsen (2010). We copy
p-values for Models I and II from Table 3 of Lando & Nielsen (2010). The number of
samples for the base model are as follows (ordered by increasing bin size): 407, 204, 136,
102, 82. * indicates rejection with 95% confidence, ** rejection with 99% confidence, and
*** rejection with 99.9% confidence.
48
Panel A: Poisson Distribution Tests
Fisher Dispersion Test Upper Tail Test (mean) Upper Tail Test (median)
w Base
DDKS w Base
DDKS w
Base
DDKS
2 0.982 *** 0.000 2 0.781
*** 0.000 2 *** 0.000 *** 0.000
4 0.970 *** 0.001 4 0.728
*** 0.000 4
0.274 *** 0.000
6 0.805 *** 0.000 6 0.636
* 0.020 6
0.056
0.060
8 0.447 *** 0.000 8 0.522
0.080 8
0.321
0.190
10 0.243 *** 0.000 10 0.285
*** 0.000 10
0.630 *** 0.000
Panel B: Distribution of Piw
Mean
Variance
w Base DDKS Theory Base DDKS Theory
2
2.00
2.12
2.00
1.89
2.92
2.00
4
3.99
4.20
4.00
4.42
5.83
4.00
6
5.97
6.25
6.00
6.94
10.37
6.00
8
7.98
8.33
8.00 11.28
14.93
8.00
10 9.97
10.39
10.00 15.63
20.07
10.00
Skewness
Kurtosis
w Base DDKS Theory Base DDKS Theory
2
0.76
1.30
0.71
3.62
6.20
3.50
4
0.65
0.44
0.50
3.49
2.79
3.25
6
0.47
0.62
0.41
3.08
3.16
3.17
8
0.43
0.41
0.35
3.29
2.59
3.12
10 0.48
0.02
0.32
3.49
2.24
3.10
w
Panel C: Distribution of ti
Mean
Base
DDKS Theory
Mean
1.00
0.95
1.00
Variance
0.96
1.17
1.00
Skewness
3.06
2.25
2.00
Kurtosis
20.22
10.06
6.00
Prahl’s Test
** 0.005 *** 0.000
KS Test
*** 0.000 *** 0.000
Table 12: Comparison to Das et al. (2007). Moments and p-values of different tests of the
binned defaults Piw and times tw
i for the base model and the model of Das et al. (2007).
We compute tests statistics and p-values as in Das et al. (2007) after fitting the base
model to the data subsample that mirrors the data used by Das et al. (2007). We copy
the p-values from Section III of Das et al. (2007). The number of samples are as follows
(ordered by increasing bin size). Base model: 499, 250, 167, 125, 100. Das et al. (2007):
230, 116, 77, 58, 46. Our samples are larger than the ones in Das et al. (2007) because
we do not need to eliminate data points for which no data is available on the CRSP data
set given that we do not include firm-specific variables. * indicates rejection with 95%
confidence, ** rejection with 99% confidence, and *** rejection with 99.9% confidence.
49
50
Base Base + Contagion Base + Frailty
*** 0.9501
** −1.7729
0.6876
*** −0.0502
−0.0097
−0.0938
*** −0.1086
*** −0.1182
0.0403
** −0.0050
0.0016
−0.0190
** 0.0115
0.0080
0.0074
** −0.0483
0.0321
. −0.6211
* 0.0849
0.0078
. 0.5893
*** −0.7385
−0.0230
−0.1573
*** 0.1176
* 0.0213
** 0.3278
*** 0.0094
*** 0.0523
466.55
617.36
601.61
*** 0.000
*** 0.000
Table 13: Parameter estimates for each of the four model alternatives described in Table 3 after excluding defaults of financial
firms. Under a financial firm default we understand any default by a firm in our data set with the Moody’s 11 Sector Code
“Banking” or “Finance, Insurance, Real Estate.” While unreported, the asymptotic standard errors are computed using the
Hessian matrix of the log-likelihood at the parameter estimates reported. “.” indicates significance at the 90% confidence level,
“*” indicates significance at the 95% level, “**” significance at the 99% level, and “***” significance at the 99.9% level.
Constant a0
IP coefficient a1
GDP a3
RET coefficient a4
VOL coefficient a5
LEVEL coefficient a6
SLOPE coefficient a8
CRED coefficient a9
Frailty volatility σ
Frailty mean reversion rate k
Frailty mean reversion level z
Contagion sensitivity b
Contagion decay rate κ
Log-likelihood
Likehood ratio vs. Base model
Likehood ratio vs. Base + Frailty model
Likehood ratio vs. Base + Contagion model
Complete
* −1.8939
−0.0113
** −0.1189
0.0015
0.0105
0.0319
−0.0005
0.0067
*** 0.2287
*** 5.9771
*** 0.0044
*** 0.0094
*** 0.0521
617.45
*** 0.000
*** 0.000
0.981
51
Table 14: Parameter estimates for the complete model and the Base + Contagion submodel after accounting for multiple defaults
in one day separately, and for industry-specific contagion effects. While unreported, the asymptotic standard errors are computed
using the Hessian matrix of the log-likelihood at the parameter estimates reported. We also report the p-values of likelihood
ratio tests; see Table 5. “.” indicates significance at the 90% confidence level, “*” indicates significance at the 95% level, “**”
significance at the 99% level, and “***” significance at the 99.9% level.
Constant a0
IP coefficient a1
GDP coefficient a2
RET coefficient a4
VOL coefficient a5
LEVEL coefficient a6
SLOPE coefficient a7
CRED coefficient a8
Frailty volatility σ
Frailty mean reversion rate k
Frailty mean reversion level z
Contagion sensitivity b
Contagion decay rate κ
Banking sensitivity b
Capital Industries sensitivity b + b1
Consumer Industries sensitivity b + b2
Energy & Environment sensitivity b + b3
F.I.R.E sensitivity b + b4
Media & Publishing sensitivity b + b5
Retail & Distribution sensitivity b + b6
Technology sensitivity b + b7
Transportation sensitivity b + b8
Utilities sensitivity b + b9
Log-likelihood
Likehood ratio vs. Base model
Likehood ratio vs. Base + Frailty model
Likehood ratio vs. Base + Contagion model
Likehood ratio (6) vs. (5)
Complete model
Base + Contagion submodel
Formulation (5) Formulation (6) Formulation (5) Formulation (6)
. −0.8879
** −1.6931
−0.8902
** −1.7084
0.0081
−0.0152
0.0090
−0.0146
** −0.1432
** −0.0827
*** −0.1413
* −0.0805
0.0068
−0.0037
0.0076
−0.0040
−0.0107
−0.0052
−0.0110
−0.0054
0.0302
−0.0207
0.0335
−0.0159
−0.0449
0.0261
−0.0555
0.0009
−0.2329
0.3316
−0.2512
0.3069
0.2114
. 0.2222
6.0130
6.0374
0.0037
0.0041
*** 0.0072
*** 0.0079
*** 0.0567
0.0325
*** 0.0618
. 0.0320
* 0.0088
*** 0.0088
0.0030
0.0031
*** 0.0071
. 0.0070
** 0.0064
** 0.0065
0.0000
0.0000
0.0001
0.0001
*** 0.0116
* 0.0112
0.0006
0.0006
0.0000
0.0000
0.0001
0.0000
599.63
615.92
599.31
615.76
*** 0.000
*** 0.000
*** 0.000
*** 0.000
1.000
*** 0.000
0.852
0.967
*** 0.000
*** 0.000
6000
5000
4000
3000
2000
1000
0
Defaulted debt (millions of USD)
1970
1980
1990
2000
2010
1.1
0.9
1.0
1500
0.7
0.8
1000
0.6
500
Total liabilities (millions of USD)
Total liabilities
Total liabilities to total assets
Ratio of total liabilities to total assets
1.2
(a) Time series of daily defaulted debt.
1970
1980
1990
2000
2010
(b) Time series of total liabilities and leverage across all surviving firms in our default data set.
Figure 2: Time series of defaulted debt and leverage. In Figure 2(a) we display the time
series of the sum of defaulted debt on every day of our sample period. In Figure 2(b) we
show the time series of average total liabilities and average ratio of total liabilities to total
assets across all surviving firms in our default data set. Data on total liabilities and total
assets is obtained from the quarterly Compustat file when available and otherwise from
the annually Compustat file.
52
Frequency
400
300
200
100
0
53
0
1000
Defaulted debt (millions of USD)
3000
Figure 3: Histogram of defaulted debt.
2000
4000
5000
6000
54
Utilities
Transportation
Technology
Retail and
Distribution
Media and
Publishing
Finance, Insurance,
Real Estate
Energy and
Environment
Consumer
Industries
Capital
Industries
Banking
0
100
200
300
400
500
(a) Number of defaults by Moody’s event category.
(b) Number of defaults by industry sector according to Moody’s 11 Code.
Figure 4: Defaults by event category and industry sector.
Other
Suspension of payments
Seized by regulators
Prepackaged Chapter 11
Payment moratorium
Missed principal and
interest payments
Missed principal
payments
Missed interest payment
Liquidated
Grace period default
Distressed exchange
Cross default
Conservatorship
Chapter 7
Chapter 11
Chapter 10
Bankruptcy, Section 77
Bankruptcy
0
200
400
600
800
0
0
0.2 0.22
0.11 0.09
0
0
0
0
0.17 0.53 0.75 0.18 0.43
0
0.19 0.14
0.17 0.47
0
0.21 0.17
0
0.16 0.29
0
1
0
0
1
0.15 0.28
0
3 or 4 days
More than 5,
less than 7 days
More than 8,
less than 14 days
More than
15 days
0.21
0.19
0.2 0.25 0.29
0.2 0.38 0.21
0.12 0.12 0.21
0
0
0
0
0
0
1
0
0.17 0.16 0.08
0.19 0.18 0.16
0.21 0.26 0.24
0.16 0.14 0.2
0
1 or 2 days
0.28 0.25 0.08
1
0
0.27 0.26 0.32
0
0
0
0
0.24
0
0
0
0
0
1
0
0.19 0.3
0.16 0.15
0.28 0.09
0
0.18 0.28
0.19 0.17
Between $75 and
$125 million
Between $125 and
$224 million
More than $224
million
0
1
0
0.08 0.12 0.21
0.33
0.29
0
0
0.19
0.47
0
1
0
0.26 0.08 0.16
0.18 0.14 0.28
0.15 0.18 0.28
Less than $27
million
Between $27 and
$75 million
0
0
0
0.11 0.75 0.17
0.16 0.12
0
0
0.21 0.24 0.12
0.2 0.36 0.16
1 or 2 days
3 or 4 days
More than 5,
less than 7 days
More than 8,
less than 14 days
More than
15 days
0.33
0.04
0.17
0.29
0.17
0.18
0.06
0.13
0.27
0.35
0.32
0.13
0.22
0.19
0.14
0.27
0.18
0.19
0.21
0.15
0.32
0.17
0.2
0.2
0.1
0.4
0.2
0.12
0.19
0.09
0.25
0.13
0.14
0.25
0.23
0.31
0.16
0.18
0.2
0.15
0.28
0.2
0.18
0.18
0.16
0.2
0.18
0.27
0.24
0.12
Between $75 and
$125 million
Between $125 and
$224 million
0.08
0
0.42
0.16
0.13
0.11
0.16
0.16
0.36
0.33
0.12
0.17
0.14
0.21
0.29
0.17
0.2
0.35
0.16
0.12
0.25
0.27
0.18
0.18
0.24
0.24
0.13
0.14
0.1
0.04
(d) Sector versus quintiles of defaulted debt.
More than $224
million
Between $27 and
$75 million
0.25
Less than $27
million
0.25
0.23
0.37
0.19
0.13
0.19
0.18
0.17
0.18
0.19
0.09
0.23
0.23
0.2
0.18
0.17
0.22
0.57
0.16
(b) Sector versus time until next default.
Figure 5: Joint distributions. These charts show different empirical bivariate distributions of: (a) Default type versus time until
the next default, (b) Sector of defaulted firm versus time until the next default, (c) Default type versus amount of defaulted debt,
and (d) Sector of defaulted firm versus amount of defaulted debt. The breakdowns correspond to the quintiles of each variable.
(c) Event category versus quintiles of defaulted debt.
1
0
0.18 0.29
0
0
0
0
0
0
Bankruptcy
0.2
Bankruptcy, Section 77
0
0
Chapter 10
0
1
Chapter 7
Chapter 11
0
0.26 0.5 0.19 0.71
0.2
(a) Event category versus time until next default.
Cross default
Conservatorship
0.33 0.05
0
0.67 0.68 0.5
0
0.15
0
1
0
Chapter 7
0.33
0
Bankruptcy
0
0.34 0.24
Bankruptcy, Section 77
0
Chapter 10
0.25 0.32 0.14
Chapter 11
0
Distressed exchange
Distressed exchange
0.33
Cross default
Conservatorship
Liquidated
Liquidated
Banking
Banking
Grace period default
Grace period default
Capital
Industries
Capital
Industries
Missed interest payment
Missed interest payment
Consumer
Industries
Consumer
Industries
Missed principal
payments
Missed principal
payments
Energy and
Environment
Energy and
Environment
Missed principal and
interest payments
Missed principal and
interest payments
Finance, Insurance,
Real Estate
Finance, Insurance,
Real Estate
Payment moratorium
Payment moratorium
Media and
Publishing
Media and
Publishing
Prepackaged Chapter 11
Prepackaged Chapter 11
Retail and
Distribution
Retail and
Distribution
Seized by regulators
Seized by regulators
Technology
Technology
Other
Suspension of payments
Transportation
Transportation
Suspension of payments
Other
Utilities
Utilities
55
1 or 2 days
0.16
0.17
0.19
0.13
0.16
3 or 4 days
0.15
0.19
0.18
0.23
0.16
More than 5,
less than 7 days
0.22
0.18
0.21
0.21
0.23
More than 8,
less than 14 days
0.26
0.21
0.12
0.1
0.12
More than
15 days
More than $224
million
0.33
Between $125 and
$224 million
0.32
Between $75 and
$125 million
0.31
Between $27 and
$75 million
0.25
Less than $27
million
0.21
(a) Defaulted debt versus time until next default.
Less than $196
million
0.28
0.2
0.09
0.08
0.04
Between $196 and
$565 million
0.24
0.25
0.18
0.15
0.18
Between $565 and
$1145 million
0.14
0.23
0.22
0.22
0.18
Between $1145 and
$2294 million
0.19
0.23
0.47
0.52
0.59
More than $2294
million
More than $224
million
0.01
Between $125 and
$224 million
0.02
Between $75 and
$125 million
0.03
Between $27 and
$75 million
0.08
Less than $27
million
0.16
(b) Defaulted debt versus cumulated defaulted debt over the 30-day period post default.
Figure 6: Impact of defaulted debt. These charts show the empirical joint distributions
of the amount of defaulted debt and the amount of days until the next default occurs
(top chart), and the amount of defaulted debt and the cumulated defaulted debt over the
30-day period post default. The breakdowns of the buckets correspond to the quintiles of
each variable.
56
●
2
●
●
●
●
●
●
●
●●
●
●●
4
●●
●
●
●●
●
●●●
●
●● ●
●
●● ●●
●
●
●
●●
●
Quantiles of log total liabilities
6
8
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●●
●
●●●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
Figure 7: QQ-plot of log defaulted debt versus log total liabilities. This figure maps the realized quantiles of the logarithm of
defaulted debt onto the quantiles of the logarithm of total liabilities at default of a firm. The slope of the line is 1.05. Number
of observations: 650.
Quantiles of log defaulted debt
8
6
4
2
0
−2
57
200
150
100
50
1/1/70
0
200
150
1/1/80
Fitted intensity, base + contagion model
1/1/80
Fitted intensity, base model
1/1/90
1/1/90
1/1/00
1/1/00
1/1/10
1/1/10
1/1/70
1/1/70
1/1/80
Fitted intensity, complete model
1/1/80
Fitted intensity, base + frailty model
1/1/90
1/1/90
1/1/00
1/1/00
1/1/10
1/1/10
Figure 8: Fitted intensities. A figure shows the fitted intensity (measured in defaults per year) implied by the maximum likelihood
estimates reported in Table 4. A grey bar represents the realized number of defaults per year.
1/1/70
50
0
100
200
150
100
50
0
200
150
100
50
0
58
300
250
200
150
100
50
0
300
250
200
150
100
50
●
●
●
1994
● ●
1991
●
●
1994
● ●
1991
●
● ●
1997
●
2000
●
●
2003
●
● ●
2006
●
●
2009
●
●
2012
●
●
Realized number of defaults
●
●
2003
●
● ●
2006
●
●
2009
●
●
●
2012
●
Realized number of defaults
● ●
2000
●
●
Forecast distributions, base + contagion model
1997
●
● ●
●
● ●
●
Forecast distributions, base model
●
●
●
1994
● ●
1991
●
●
1994
● ●
1991
●
● ●
1997
●
1997
●
● ●
●
● ●
2006
●
●
2009
●
●
2012
●
●
●
●
● ●
2006
●
●
2009
●
●
●
2012
●
Realized number of defaults
2003
● ●
●
Forecast distributions, complete model
2000
●
●
2003
●
●
Realized number of defaults
● ●
2000
●
●
Forecast distributions, base + frailty model
Figure 9: Out-of-sample forecast distribution of the number of defaults in the year ahead. The plot shows the Gaussian kernelsmoothed forecast distributions, with a horizontal line indicating the mean. The dot indicates the realized number of defaults.
The forecast distributions are computed via Monte Carlo simulation as described in Appendix E.
0
300
250
200
150
100
50
0
300
250
200
150
100
50
0
59
1970
Frailty source
Macro source
Contagion source
Defaults per year
1980
1990
2000
2010
Defaults per year
Figure 10: Decomposition of fitted default intensity. This figure decomposes the time series of the fitted default intensity, Et [λt ],
into its macro, contagion, and frailty components, and compares to the number of defaults in each year. The fitted intensity at
any point of time is normalized to unity so that each component is displayed as percentage of the fitted intensity. The fitted
intensity and its components are computed as described in Appendix C using the parameter estimates of Table 4.
Fitted intensity decomposition
100%
80%
60%
40%
20%
0%
150
100
50
0
60