Novelty Detection – Recognition and Evaluation of Exceptional Water Reflectance Spectra
advertisement

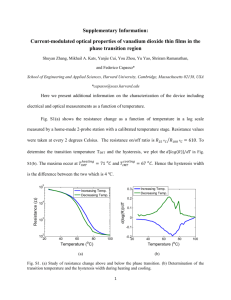
Environ Monit Assess DOI 10.1007/s10661-006-9538-5 Novelty Detection – Recognition and Evaluation of Exceptional Water Reflectance Spectra Helmut Schiller · Wolfgang Schönfeld · Hansjörg L. Krasemann · Kathrin Schiller Received: 16 May 2006 / Accepted: 27 September 2006 © Springer Science + Business Media B.V. 2007 Abstract The aim of environmental surveillance is to monitor known phenomena as well as to detect exceptional situations. Synoptic monitoring of large areas in coastal waters can be performed by remote sensing using multispectral sensors onboard satellites. Many methods are in use which enable the detection and quantification of ‘standard algae’ or specific algae blooms using their known spectral response. The present study focusses on the detection of spectra outside the known range and which are referred to as exceptional spectra. In a first step observations from a one-year period were used to establish the parameterisation of what is defined as ‘normal.’ In a second step observations from a different period were used to test the novelty detection application, i.e. to look for features not occurring in the first period. Podi tuda – ne zna kuda, prinesi to – ne zna qto. Go I know not where, bring back I know not what. – Russian Fairy Tale H. Schiller (B) · W. Schönfeld · H. L. Krasemann · K. Schiller GKSS Forschungszentrum, PF 1160, 21494 Geesthacht, Germany e-mail: schiller@gkss.de Keywords Novelty search · Monitoring · Water quality · Reflectance · Remote sensing 1 Introduction This order given to the hero of the quoted fairy tale could be used to summarise the request received to detect exceptional water reflectance spectra. ‘Exceptional’ here applies to unusual events not lying within the bounds of operationally processed multi-spectral satellite data. Of course, neither the time nor the place of such events or their spectral characteristic are known beforehand. What we are looking for are deviations from what is occurring ‘normally.’ Out of range spectra can result from e.g. exceptional plankton blooms which may form so-called Red Tides (due to the red discolouration of the water) or white water caused by extreme coccolithophore blooms. It is of great interest to detect and map the temporal and spatial development of these events, since it might turn out that such exceptional events or blooms can not be handled by standard algorithms for known substances. In short the above task is one of novelty detection: i.e. training a learning system to identify new or unknown data or data which is different from that presented during the training. Novelty detection is used in signal processing and when Environ Monit Assess applied to multidimensional data, statistical approaches as well as Neural Network based approaches have been used. A recent review of the techniques available is presented by (Markou and Singh 2003a, 2003b), which also illustrates that there is a great variety of areas where novelty detection techniques can be applied. Examples of the use of such novelty detection techniques in the analysis of remotely sensed data are (Auguststeijn and Folkert 2002) and (D’Alimonte et al. 2003). In (Auguststeijn and Folkert 2002) two Neural Net (NN) classification schemes are compared with respect to their ability to identify novel patterns in Thematic Mapper (TM) imagery acquired in spring 1993 of United States Air Force Academy grounds, north of Colorado Springs. Although the temporal and spatial range is rather restricted the variability on the ground was found to be extremely high. In conclusion, it could be shown that the Probabilistic Neural Network (PNN) (Washburne et al. 1993) is significantly more successful in resolving new ground covers types compared to the back-propagation NN. (D’Alimonte et al. 2003) used novelty detection to identify the range of applicability of empirical ocean colour algorithms. Two empirical ocean colour algorithms were constructed on the basis of their respective training data sets. The accuracy of the output of a given algorithm was found to depend on the representativeness of the input data set in the respective training. To estimate the representativeness of a given data set it was shown that a multivariate Gaussian function could accurately model the distribution of the logarithm of the three remote sensing reflectances (wavelengths λ = 490, 555 and 665 nm) used in the algorithm. In contrast to the aforementioned example the present study aimed to develop a novelty detection scheme for water reflectance data which could be used operationally. The basic idea behind this approach is to use a large number of reflectance spectra from one complete year for the North Sea so as to include the annual cycle of plankton species (including their blooms et cetera) to teach a learning system ‘what is normal.’ Only (distinctive) deviations from these known spectra should be classified as novel. Thus, the algorithm should accept all reflectance spectra from the training period as being normal but should still be sensitive enough to detect novel situations. To check if this was the case, a test application data set was used which also included the spectra of a Red Tide which did not occur in the training set. The selection of the appropriate algorithm is the central issue of this paper. It is intimately connected with the type and structure of the data to be tackled. The water reflectances are measured at nine different wavelengths, all of which will be used in the present algorithms. Bio-optical models often exclude several wavebands or give other wavelengths more weight. Since our aim is to detect novel situations with unknown spectral signature we use all the information available. However, due to the resulting high dimensionality of the data set (nine dimensions), performance of different algorithms can not be easily visualised. In Section 2 we therefore start by analysing the basic characteristics of the reflectance data and then construct an artificial two-dimesional showcase data set resembling some properties of these reflectances. This artificial showcase data set is used to test different approaches, namely: a simple statistical scheme, an auto-associative Neural Net, a Neural Net classifier and a tessellation scheme. An algorithm is required which classifies all data from the training (the two-dimensional showcase data set) as normal but will still be sensitive enough to detect novelties. In other words, we need to envelop the data set as tightly as possible and such that all points inside this envelope can be defined as normal. Arguments for choosing the tessellation as the most appropriate novelty detection scheme will be given. In Section 3 the North Sea data sets for training and application testing are presented. The tessellation of the training data is described and the results of the novelty search in the test data are discussed. In Section 4 the conclusions are presented. 2 Choice of the Algorithm The data for which we want to develop a novelty detection scheme are obtained by remote sensing. The sensor and some important aspects of the reflectance spectra are described in Subsection 2.1. Environ Monit Assess 10 reflectance [1/sr] The main characteristics of these data are then used to construct a two-dimensional showcase data set. The performance of different novelty detection schemes with this showcase data set is described in Subsection 2.2. It was found that an appropriate novelty detection scheme can be based on a set of Gaussians. 10 –1 –2 2.1 MERIS water reflectance spectra In March 2002, the European Space Agency launched ENVISAT, an advanced polar-orbiting earth observation satellite which has provided measurements of the atmosphere, ocean, land, and ice for over the five-year period to the present. The ENVISAT satellite has an ambitious and innovative payload that will ensure the continuity of the measurements of the ESA ERS satellites. ENVISAT data supports earth science research and allows the monitoring of the evolution of environmental and climatic changes. One of the instruments onboard ENVISAT is MERIS (Rast et al. 1999), the MEdium Resolution Imaging Spectrometer. The primary mission of MERIS is the measurement of water colour in the oceans and in coastal areas. After atmospheric correction, measurements of the water colour, can be converted into an estimate of the concentrations of chlorophyll pigment, suspended matter and Gelbstoff (yellow substance). The main application domains of such data are (1) the ocean carbon cycle, (2) the thermal regime of the upper ocean and (3) the management of fisheries and coastal zones. MERIS allows global coverage of the earth every 3 days. In this paper the spectrum of water leaving radiance reflectance (reflectance, for short) is used to monitor the oceanic and coastal environment. The nine spectral bands are centred at wavelengths λ = 412, 442, 490, 510, 560, 620, 664, 681, 708 nm. Examples of water reflectance spectra are shown in Fig. 1. This illustrates the great variability of water reflectance spectra: the sea is not always blue. Randomly chosen pixels from MERIS scenes obtained during 2002/2003 in a region1 of the North 1 Details of this data are discussed in Section 3. 10 –3 450 500 550 λ [nm] 600 650 700 Fig. 1 Examples of water reflectance spectra measured by MERIS Sea were used to produce the scatter-plots of logarithms2 of reflectances at different wavelengths as shown in Fig. 2. This shows that there are strong correlations between the reflectances at different wavelengths. Obviously the correlation behaviour is not the same for all pixels as this changes with the type of water present. This leads to point clouds having v-like shapes in some scatter-plots. For real applications of novelty detection hundreds of MERIS scenes, each with tens of thousands of pixels, have to be checked. Therefore it is important to devise an algorithm which has a low rate of false alarms. 2.2 Algorithm performance with the showcase data In order to study the pros and cons of different novelty detection schemes in a realistic manner as well as being able to visualise the findings we construct an artificial two-dimensional data set. This demo data set is a superposition of two 2 We use the natural logarithm of the reflectance rather than the reflectance itself since the latter have distributions strongly skewed to small values, especially in the long wavelength bands. As the reflectance has the unit sr−1 we divide the reflectance by its unit before taking the logarithm. Any scaling of the unit would not change anything since it is always the difference between the variables which is most important for the algorithms considered . Environ Monit Assess "Meris water pixel "Meris water pixel –2 –2.5 –3 –2.5 ln(reflectance at 664nm) ln(reflectance at 490nm) –3.5 –3 –3.5 –4 –4.5 –5 –4 –4.5 –5 –5.5 –6 –6.5 –5.5 –6 –6 –7 –5.5 –5 –4.5 –4 –3.5 ln(reflectance at 412nm) –3 –2.5 –7.5 –6 –2 –5.5 –5 –2 –3 –3 –4 –4 –5 –6 –7 –8 –9 –10 –6 –3 –2.5 –2 "Meris water pixel –2 ln(reflectance at 708nm) ln(reflectance at 708nm) "Meris water pixel –4.5 –4 –3.5 ln(reflectance at 412nm) –5 –6 –7 –8 –9 –5.5 –5 –4.5 –4 –3.5 ln(reflectance at 442nm) –3 –2.5 –2 –10 –5.5 –5 –4.5 –4 –3.5 –3 ln(reflectance at 560nm) –2.5 –2 Fig. 2 Scatter-plots showing examples of water reflectances at different wavelengths as measured by the MERIS sensor onboard the environmental satellite ENVISAT Gaussians which exhibit the kind of v–like structure seen in the MERIS reflectance data shown above. Like the reflectance data the demo data set shows correlations, its variables are continuous and have the same dimension and order of magnitude. Therefore, the demo data set is well suited to exemplifying the novelty search in real reflectance data. A randomly chosen subset of 800 points out of a total of 5, 000 points is shown in Fig. 3. In any novelty search a model of the ‘known’ data K is built which serves to construct a measure ρ(x) of how certain a given point x belongs to the kind of data characterised by the proxy K. In the following subsections we construct four different models of the demo data set and discuss for each of the models the isoline of ρ(x) which encloses 95% of the entire demo data set. For a convenient comparison of the different algorithm performances the comprised results are shown in Fig. 5. 2.2.1 Simple statistical scheme Let x(m) , m ∈ [1, . . . , M] be the M points of the known data K. Then K is characterised to some extent by its first two moments, the centroid q qj = M 1 (m) x M m=1 j and the covariance matrix C Cij = M 1 (m) (x − qi )(x(m) j − qj ) M m=1 i Environ Monit Assess showcase data set to visualize features of novelty searches 3.5 3 2.5 2 y 1.5 1 0.5 0 –0.5 –1 –3 –2 –1 0 1 2 3 4 x Fig. 3 Subset of the demo data which is a superposition of two Gaussians The moments contain information about the position of the points and shape of the point cloud K which is used in the Mahalanobis distance function. The Mahalanobis distance of a given point x from the centre of the points q is ρM (x, q) = (x − q)T (C)−1 (x − q) In Fig. 5a the isoline of the Mahalanobis distance from the centre enclosing 95% of the demo data is shown. This clearly shows that the ellipsoid of equal Mahalanobis distance accounts for the gross arrangement of the data. However, it is not able to account for details such as the v– like shape and the isoline in Fig. 5a also encloses points such as A which could represent a ‘novelty.’ This example shows that such a simple model is not appropriate for our MERIS spectra of water reflectances. Since AANN’s are trained to map the points x ∈ K onto themselves A AN N(x) x after successful training, the distance ρ(x, A AN N(x)) = (x − A AN N(x))2 is small for points from K. Now, to use AANN’s for novelty search the idea is that points which are not like the points in the training set are not projected onto themselves and consequently lead to large ρ(x, A AN N(x)). For the demo data the isoline of ρ(x, A AN N(x)) which encloses 95% of the demo data is shown in Fig. 5b. It clearly demonstrates the AANN’s ability to account for nonlinear correlations. The weakness of the AANN scheme, however, lies in the fact that there is no way of preventing the AANN from mapping points which do not belong to K also onto themselves . Therefore, one can not exclude the possibility of small ρ(x, A AN N(x)) for points such as B in Fig. 5b which could also be ‘novelty’ candidates. 2.2.3 Neural net classifier To avoid the possibility that regions close to K are classified as belonging to K, one can generate points close to K and then train a NN to classify the points. This is illustrated in Fig. 4. In the surrounding of points from K (dots), points belonging to the class ‘non-K’ (crosses) are generated. All the points are then taken together and used as a training and test data set to train subset of two class training data 3.5 3 2.5 2.2.2 Auto-associative neural net 1.5 y Auto-associative Neural Nets (AANN’s) became quite popular for novelty search as illustrated in (Markou and Singh 2003a, 2003b). AANN’s are trained to map the points of K onto themselves whereby at one stage of the mapping the input information is passed through a NN-layer of lower dimension compared to the dimension of x itself (hence a ‘bottleneck’). This can be accomplished only by exploiting correlations existing in K. The AANN’s can account for nonlinear correlations and can handle very distinct input sources. 2 1 0.5 0 –0.5 –1 –3 –2 –1 0 1 2 3 4 x Fig. 4 Two class data to train NN classifier: dots indicate points from the original showcase dataset (K), crosses indicate points which where added and are representatives of ‘non-K’ Environ Monit Assess a) b) isoline: ρ ((x,y),centroid) = 2.6 isoline: ρ((x,y),AANN(x,y)) = 0.71 M 3 3 2.5 2.5 2 2 1.5 1.5 B x y 3.5 y 3.5 x 1 1 A 0.5 0.5 0 0 –0.5 –0.5 –1 –3 –2 –1 0 1 2 3 –1 –3 4 –2 –1 0 x 1 2 3 4 3 4 x c) d) isoline: ρ((x,y),centers) = 2.42 isoline: NN(x,y) = 0.35 3.5 3 3 2.5 2.5 2 2 1.5 1.5 y y 3.5 1 1 0.5 0.5 0 0 –0.5 –0.5 –1 –3 –2 –1 0 1 2 3 4 –1 –3 –2 –1 0 x 1 2 x Fig. 5 The figures show a subset of the showcase dataset together with isolines of the measure ρ(x) which enclose 95% of the data for the four different approaches. a refers to the statistical model, b to the auto-associative Neural Net, c to the Neural Net classifier and d to the tesselation a NN to classify the points accordingly. In this case the NN has just one output value in which we code ‘0’ to represent membership in K and ‘1’ nonmembership in K. The isoline of the NN output enclosing 95% of the data is shown in Fig. 5c. The isoline is now quite close to K. For this demo data the generation of neighbouring points is trivial. For real data the generation of neighbouring points can become a very difficult task in cases of point clouds extending in different directions and having varying intrinsic dimensionalities. 2.2.4 Tessellation scheme Here we first tessellate the known data K and then define a distance of a given point from the tessellation.3 3 This could be the initialisation step of a cluster algorithm (e.g. ‘k – means clustering’) or the construction of a radial basis function (RBF) neural network. However, the respective iterations would compromise the description of the border of K in favour of the better density estimation. Environ Monit Assess To start the tessellation we choose by trial and error a radius R (this is discussed below in detail for the tessellation of the real data). Now – The first point becomes the first centre. – For each of the remaining points the smallest of the distances to all centres is compared with R. If the distance is larger than R the point is included in the set of centres. – In the second step each point is assigned to that centre to which it is closest (Voronoi tessellation). For each of the patches obtained by the tessellation the mean (centre of gravity) and the covariance matrix is calculated and as the distance of a given point to the tessellation the minimum of the Mahalanobis distances is used.4 The isoline of the tesselation enclosing 95% of the data is shown in Fig. 5d. The isoline is again quite close to K. In summary, the simple statistical model is not appropriate for novelty detection in water reflectance spectra. The auto-associative Neural Net approach provides a tighter enclosure of the data set but it is still not tight enough to ensure novelty detection. The Neural Net classifier and the tessellation both provide a tight enclosure of the data set K. The advantage of the tessellation approach compared to the two class Neural Net classifier (where ‘non-K’ points had to be constructed) is its easy and straightforward set up. Thus the tessellation approach will be used for the water reflectance data. Fig. 6 The roi in the North Sea chosen for the tessellation novelty detection scheme in which to search for novelties. In this section we first describe the selection of data used to represent the ‘normal’ situation and then the construction of the tessellation on these data and the cleaning of the results. With a few amendments we found a tessellation which describes our training data. We also discuss the different kinds of novelty which were detected by our tesselation procedure for scenes obtained from the test application period. 3.1 The dataset defining the ‘normal’ situation We used all MERIS scenes from the 26th June 2003 to the 29th June 2004 from a region of the Projection of the roi pixels onto first eigenvectors 1 As an application for the tessellation novelty detection scheme we used MERIS data of the North Sea. The logarithms of the remote sensing reflectances in the first nine MERIS channels (centred at wavelengths λ = 413, 443, 490, 510, 560, 620, 665, 681, 708 nm) were used to span the space 4 It should be mentioned here that this scheme is a blend of the schemes (Auguststeijn and Folkert 2002) and (D’Alimonte et al. 2003) mentioned in the introduction: like in the PNN a set of Gaussians is used but here the covariance matrix of the points of each patch is used instead of univariate smoothing parameters. Projection onto second eigenvector 3 North Sea Results 0 –1 –2 –3 –4 –5 –6 –7 –8 –24 –22 –20 –18 –16 –14 –12 –10 Projection onto first eigenvector –8 –6 Fig. 7 The projection of the roi data onto the eigenvectors with the two largest eigenvalues Environ Monit Assess distance of training pixels from tesselation 7000 6000 80 5000 60 4000 40 3000 20 # North Sea (region of interest = roi) as shown in Fig. 6. We excluded pixels from the sun glint part as well as those which had one or more negative reflectances (bad atmospheric correction). Then ∼ 1, 000 pixels from each scene were randomly sampled thus ending up with 115, 331 pixels for the ‘training’. The projection of (a 10th of) this data onto the eigenvectors with the two largest eigenvalues is shown in Fig. 7. This projection contains 94.9% of the variance of this data. It is obvious that the point cloud has not a simple shape. 0 6 2000 8 10 12 1000 0 0 2 4 6 8 10 12 Mahalanobis distance Fig. 9 The distribution of the distances of the training points from the tessellation. The inset shows the tail of the distribution 3.2 The tessellation The algorithm described in Subsection 2.2.4 was applied to the above data with varying radius R and hence varying number of resulting centres. To choose a sensible tessellation one has to make a compromise between a low number of centres (computing time) and a large number of centres (modelling the details of the probability density function). For this we study Fig. 8 which shows the weighted mean of the ratios of the two largest eigenvalues vs. the number of centres = C 1 λc2 nc N c=1 λc1 where nc , c = 1, . . . , C is the number of points belonging to the cth centre (N = C c=1 nc ) and λc1(2) is the largest (second largest) eigenvalue of the covariance matrix of these points. The quantity is a ‘shape parameter’: if all pixels are forced into one group the ratio λλ21 is about one tenth. With an increasing number of centres this ratio becomes larger and – if many details are modelled – remains constant at around 0.6. As a compromise we decided to use the 26-centres tessellation (R = 2.52). This decision is supported by the finding that the use of the 31-centres tessellation leads to the same large distance points. The distribution of the distances of the training points from the tessellation is shown in Fig. 9. false novelty pixels from training set Weighted mean ratios of eigenvalues vs. # of centers –2 0.7 –3 0.6 –4 0.5 ln(reflectance) –5 ε 0.4 0.3 –6 –7 –8 –9 0.2 –10 0.1 0 0 –11 10 20 30 40 50 # of centers 60 70 80 Fig. 8 The shape parameter as a function of the number of centres –12 400 450 500 550 600 λ [nm] 650 700 750 Fig. 10 The spectra of the 38 pixels of the training set with a distance above 7.5 Environ Monit Assess Fig. 11 One of the four groups which was appended to the tessellation was located near northern Denmark From the blow-up included in this figure we decided to declare points as representing novelty if their distance to the tessellation was above 7.5. The spectra of the 38 pixels of the training set having a distance above 7.5 is shown in Fig. 10. 3.3 Clean-up of the findings The distance cut-off of 7.5 leaves only 38 pixels remaining from the training points. However, if we apply the cut to the 288 complete roi’s (s. Fig. 6), with 16, 575, 000 pixels of the time range from which the training data set was selected, we find 110, 718 pixels with a distance > 7.5 from the tessellation. Inspection of these pixels shows that many are very near to clouds and includes also many single noisy spectra not well represented in the training data set. We therefore introduced two conditions which were not related to the spectral information, namely: 1. Pixels have to be at least three pixels away from clouds. This reduces the number of false alarms from 110, 718 to 39, 860. Fig. 12 The remaining false alarm in the Skagerrak 2. Novelty has to appear in a minimum patch size. We accept pixels as novel only if at least 19 pixel in the surrounding 5 × 5 square have a distance above 7.5. This reduces the number of false alarms from 39, 860 to 2, 670 in altogether 26 scenes. To get rid of the remaining false alarms we identified four groups of pixels such as those shown in Fig. 11. For these four groups we calculated the centre of gravity and the covariance matrix and appended this to the existing tessellation information. After this addition only one false alarm as shown in Fig. 12, remained in the training set. 3.4 Novelties The test application data set comprised 223 scenes from the 30th June 2004 to the 13th October 2005. After the application of our novelty detection scheme a total of 10 scenes remained. Three show a red tide near to the island Helgoland on the 30th July, and on the 3rd and 5th August 2004 (see Fig. 13). Environ Monit Assess Fig. 13 Red tide in the German Bight found as novelty on the 30th of July, 3rd and 5th of August 2004. The fourth sub-picture shows the spectrum of the 3rd of August This red tide was also observed on a measuring campaign between Cuxhaven and Helgoland on the 3rd August 2004 and identified as Myrionecta rubra. Standard algorithms also detected an increase in the chlorophyll content but by construction gave no hint to an unusual bloom. In the scene from the 19th November 2004 novelty was signalled in the Skagerrak area, however, after further inspection this was shown to Fig. 14 Coccolithophoride found as novelty (example from 23rd of June 2005) be simply a processing failure in that a significant number of water reflectances were just unity. The remaining six novelties of 19th, 23rd, 26th, 28th June and 2nd, 18th July 2005 are located in the central and northwestern North Sea. These findings look like distinctive blooms of coccolithophores. An example is shown in Fig. 14. Blooms of coccolithophores are quite frequent every year. As we are signalling novel situations Environ Monit Assess we looked further into the period from which our training data were taken. For several days MODIS reports coccolithophore blooms in the MOD25 product (Balch et al. 1996, 1999; Gordon et al. 1988). We localised these blooms in the MERIS training data and compared the spectra with the novelty detections in our test data application. These spectra were classified as novelties due to their more pronounced blue reflectance as compared to those events within the training period. This is illustrated in Fig. 15 where the band ratio of blue over green reflectance (442/510 nm) is shown. In the upper part for patches in the training period classified by MODIS as coccolithophores the ratio is well below 1.0. The lower part shows clearly that the band ratio is above 1.0 for patches seen as novelty in our application test. For further practical novelty detection, and for those not immediately interested in coccol- coccolithophores in training data (2004) 300 250 # 4 Conclusions A novelty detection scheme which is suitable for regular monitoring purposes using multispectral remote sensing data has been constructed. It is applied to MERIS water reflectances and has a low failure (false positive) rate. It was successful in finding exceptional algae blooms, one of which was also identified as a red tide by in situ measurements. To reach this low failure rate it was necessary to use not only the spectral information but also to avoid pixels close to clouds and to require a minimum novelty patch size. The novelty detection scheme developed is flexible and adaptable to various monitoring needs. It easily allows the exclusion of explained novelties from subsequent searches. Acknowledgements This research was supported by the European Space Agency ESA as a part of the ‘MERIS Case2 Regional’ project. The authors like to thank the BEAM/VISAT development team (see URL http://www.brockmannconsult.de/beam/). The novelty detection processor was developed on the basis of this open source software package and can thus be freely used. 200 150 100 50 0 0.5 ithophore bloom alarms, one would append these spectra to the tesselation as outlined in the data clean-up step (see Section 3.3). 1 1.5 References novelties in test data (2005) 250 200 # 150 100 50 0 0.5 1 band ratio 442nm/510nm 1.5 Fig. 15 Ratio of blue to green reflectance (442/510 nm). Comparison of training data classified as coccolithophores vs. novelties emerging from the test data Auguststeijn, M. F., & Folkert, B. A. (2002). Neural network classification and novelty detection. International Journal of Remote Sensing, 23, 2891–2902. Balch, W. M., Kilpatrick, K., Holligan, P. M., Harbour, D., & Fernandez, E. (1996). The 1991 coccolithophore bloom in the central north Atlantic. II. Relating optics to coccolith concentration. Limnology and Oceanography, 41, 1684–1696. Balch, W. M., Drapeau, D. T., Cucci, T. L., Vaillancourt, R. D., Kilpatrick, K. A., & Fritz, J. J. (1999). Optical backscattering by calcifying algae – Separating the contribution by particulate inorganic and organic carbon fractions. Journal of Geophysical Research, 104, 1541–1558. D’Alimonte, D., Melin, F., Zibordi, G., & Berthon, J. J. (2003). Use of the novelty detection technique to identify the range of applicability of empiri- Environ Monit Assess cal ocean color algorithms. IEEE Transactions on Geoscience and Remote Sensing, 41, 2833–2843. Gordon, H. R., Brown, O. B., Evans, R. H., Brown, J. W., Smith, R. C., Baker, K. S., et al. (1988). A semianalytic radiance model of ocean color. Journal of Geophysical Research, 93, 10909–10924. Markou, M., & Singh, S. (2003a). Novelty detection: A review – Part 1: Statistical approaches. Signal Processing, 83(12), 2481–2497, December. Markou, M., & Singh, S. (2003b). Novelty detection: A review – Part 2: Neural network based approaches. Signal Processing, 83(12), 2499–2521, December. Rast, M., Bézy, J. L., & Bruzzi, S. (1999). The ESA Medium Resolution Imaging Spectrometer MERIS – A review of the instrument and its mission. International Journal of Remote Sensing, 20, 1681– 1702. (see also URL http://envisat.esa.int/instruments/ meris/descr/charact.html). Washburne, T. P., Specht, D. F., & Drake, R. M. (1993). Identification of unknown categories with probabilistic neural networks. In Proceedings of the 1993 international conference on neural networks, San Francisco, CA, 28 March – 1 April, 1993, vol. 1. (pp. 434–437). Piscataway, NJ: IEEE Service Center.