Project Number: IST-1999-20393 Project Title: Deliverable Type:
advertisement

Project Number:
IST-1999-20393
Laboratories Over Next
Generation Networks
Project Title:
Deliverable Type:
P – public
CEC Deliverable Number:
IST-1999-20393/ PTIN/WP2/DS/P/003/b0
Contractual Date of Delivery to the
CEC:
M14
Actual Date of Delivery to the CEC:
31-January-2001
Title of Deliverable:
Advanced Network Services: description and
support in LONG network
Work package contributing to the
Deliverable:
WP 2
Nature of the Deliverable:
R – Report
Author(s):
Jacinto Vieira (PTIN), Francisco Fontes (PTIN),
Carlos Ralli Ucendo (TID), Cristina Peña Alcega
(TID), Alberto Garcia (UC3M), Marcelo Bagnulo
(UC3M), Juan F. Rodriguez (UC3M), Eva M. Castro
(UPM), Alberto López (UPM), Joaquim Godinho
(UEV), Mário Filipe (UEV), Miguel Ramos (UEV),
Jordi Domingo-Pascual (UPC), Josep ManguesBafalluy (UPC), Alberto Cabellos-Aparicio (UPC).
Editor:
Jacinto Vieira (PTIN)
Abstract:
This document describes the study performed in the
LONG project for the deployment of network and
application level services in mixed IPv4/IPv6
scenarios. The theoretical and functional aspects of
services are presented. Also, this document identifies
the services that are being deployed on LONG
infrastructure and how those will be used in order to
evaluate their behaviour in a near-real environment.
Keyword List:
LONG, IPv6, Next Generation Networks, Advanced
Network Services, Advanced Network Platforms,
Access Technologies.
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Executive Summary
This document, D2.3-“Advanced Network Services: description and support in LONG
network”, describes the services that are being deployed over LONG infrastructure. The
deployment of these services is performed involving IPv4 and IPv6 networks. This document
presents the theoretical and functional aspects of the deployment of network and application
level services, while D4.3 will describe the results of the tests. The final design of the
networks, as well as the services deployed and tested, will be written in the D2.4.
http://heim.ifi.uio.no/~paalee/
Page 2 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Table of contents
1.
INTRODUCTION
8
2.
NETWORK LEVEL SERVICES
9
2.1. Mobility
2.1.1. Introduction
2.1.2. IPv4 Mobility
2.1.2.1. Data Forwarding
2.1.3. IPv6 Mobility
2.1.3.1. Binding Mechanism
2.1.3.2. Discovery, Registration and Tunneling
2.1.3.3. Data Forwarding
2.1.4. IPv6 vs IPv4 Mobility
2.1.5. Mobility in Transition Scenarios
2.1.5.1. Considerations on scenarios of interest
2.1.5.2. Current approaches in IETF
9
9
10
14
15
15
15
16
17
17
18
21
2.2. Multicast
2.2.1. Introduction
2.2.2. IPv4 Multicast
2.2.2.1. Address format
2.2.2.2. IGMP protocol
2.2.2.3. Routing protocols
2.2.3. IPv6 Multicast
2.2.3.1. Address format
2.2.3.2. MLD protocol
2.2.3.3. Routing protocols
2.2.3.4. Available implementations
2.2.4. IPv6 vs IPv4 Multicast
2.2.5. Multicast in transition scenarios
2.2.5.1. Translation mechanisms
2.2.5.2. Tunneling mechanism
22
22
22
22
23
24
27
27
28
34
35
37
38
38
43
2.3. Anycast
45
2.4. Multihomming
2.4.1. Introduction.
2.4.2. Motivations and requirements
2.4.2.1. Motivations for multi-homing
2.4.2.2. Requirements for IPv6 multi-homing
2.4.3. IPv6 site multi-homing solutions taxonomy
2.4.3.1. Topological constraints.
2.4.3.2. Address engineering.
2.4.3.3. End to End.
2.4.4. Summary for IPv6 Multi-homing solutions
2.4.5. Address Selection for Peering Support
2.4.5.1. Introduction
2.4.5.2. Address Selection for IPv6
46
46
46
47
47
48
48
49
50
50
51
51
51
2.5. DNS
2.5.1. Introduction
2.5.1.1. Name Servers
2.5.1.2. Resolvers
2.5.2. DNS with IPv6 Support
53
53
54
55
55
Page 3 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.5.2.1. DNS Extensions to Support IPv6
2.5.2.2. DNS Extension to Support IPv6 Address Aggregation and Renumbering
2.5.2.3. AAAA or A6?
55
56
57
2.6. DHCP v6
2.6.1. Introduction to DHCP
2.6.1. IPv6 Stateless Autoconfiguration
2.6.2. IPv6 Stateful Configuration.
2.6.3. DHCP for IPv6
2.6.4. Applicable Standards and Issues
2.6.5. Known DHCPv6 Implementations
2.6.6. Applications Scenarios
58
58
58
58
59
59
60
61
2.7. QoS – Differentiated Services
2.7.1. Diffserv architecture
2.7.1.1. Diffserv architecture concepts
2.7.1.2. Diffserv architecture components
2.7.2. IPv6 Diffserv implementations
2.7.3. Diffserv in transition scenarios
2.7.4. IPv6 Diffserv configuration
2.7.4.1. Start.
2.7.4.2. Making ALTQ-kernel.
2.7.4.3. Configuration file samples for loopback interface (/etc/altq.conf)
61
62
62
63
65
66
67
67
67
69
2.8. Security
2.8.1. Introduction
2.8.2. A bit of history
2.8.3. IPsec
2.8.3.1. IPsec goals
2.8.3.2. IPsec Overview
2.8.4. Security Associations
2.8.4.1. Performance Issues
2.8.5. IP Authentication Header
2.8.5.1. Introduction
2.8.5.2. Authentication Header Processing
2.8.5.3. Auditing
2.8.5.4. Conformance Requirements
2.8.6. IP Encapsulating Security Payload (ESP)
2.8.6.1. Introduction
2.8.6.2. Encapsulating Security Protocol Processing
2.8.6.3. Auditing
2.8.6.4. Conformance Requirements
2.8.7. The Internet IP Security Domain of Interpretation (IPsec DOI)
2.8.7.1. Introduction
2.8.7.2. Fitting into IPsec
2.8.8. Internet Security Association and Key Management Protocol (ISAKMP)
2.8.8.1. Introduction
2.8.8.2. ISAKMP Concepts
2.8.8.3. Security Considerations
2.8.8.4. Conclusions
2.8.9. The Internet Key Exchange (IKE)
2.8.9.1. Introduction
2.8.9.2. Discussion
2.8.9.3. Terms and Definitions
2.8.9.4. more detailed introduction
2.8.9.5. Exchanges
2.8.9.6. Implementation Hints
2.8.9.7. Security Considerations
2.8.10. Future Developments
Page 4 of 206
71
71
71
72
72
72
74
90
91
91
91
93
93
94
94
94
97
97
97
97
98
99
99
106
108
109
110
110
110
110
111
113
114
115
116
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.8.10.1. Operating Systems
2.8.10.2. Router manufacturers
2.8.11. Scenarios
2.8.12. Conclusion
3.
117
117
118
119
APPLICATION LEVEL SERVICES
120
3.1. Web Server
120
3.2. FTP Server
3.2.1. FTP brief description
3.2.2. FTP and IPv6
3.2.3. FTP in transition scenarios
120
120
121
121
3.3. Mail Server
3.3.1. SMTP Mail Servers
3.3.2. POP3 Mail Servers.
3.3.3. Mail Servers behind firewalls, NAT and similar.
121
122
123
123
3.4. Teleconference
3.4.1. ISABEL Application
3.4.2. Hardware requirements and configuration
3.4.2.1. Audio equipment
3.4.2.2. Video equipment
3.4.3. Local Network Connection
3.4.4. ISABEL software setup.
123
123
124
124
126
128
128
3.5. News
3.5.1. Introduction
3.5.2. Available Implementations
133
133
134
3.6. IRC
135
3.7. NFS
3.7.1. Introduction
3.7.2. NFS Implementation
3.7.3. IPv6 NFS Compliant
3.7.4. RPC/NFS Applications available to IPv6
135
135
135
136
136
3.8. Remote Authentication Dial In User Service (RADIUS)
3.8.1. RADIUS Features
3.8.2. How RADIUS works?
3.8.3. Authentication and Authorization
3.8.4. Accounting
3.8.5. Packet Format
3.8.5.1. Packet types
3.8.5.2. Attribute-Value Pairs
3.8.6. RADIUS Files
3.8.6.1. Dictionary File
3.8.6.2. Clients File
3.8.6.3. Users File
3.8.7. RADIUS and IPv6
3.8.7.1. IPv6 Support
3.8.7.2. IPv6 Attributes
3.8.7.3. IPv6 Dialup Operation
3.8.8. Possible AAA scenarios
3.8.8.1. Future Developments
136
137
138
138
139
139
140
141
142
142
142
142
143
143
143
144
145
146
Page 5 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
3.9. LDAP
3.9.1. Directories
3.9.2. Predecessors of LDAP (X.500)
3.9.3. LDAP
3.9.4. Configuring an LDAP Server and Client
3.9.4.1. LDAP distributed architecture
3.9.5. LDAP IPv6 Particularities
3.9.6. LDAP in transition Scenarios
4.
ADVANCED SERVICES IN LONG PROJECT
147
147
147
148
150
152
154
154
155
4.1. Introduction
155
4.2. Mobile IPv6 local testbed
4.2.1. Installation process
4.2.2. MIPL Mobile IPv6 installation
4.2.3. Tests
155
155
156
157
4.3. Multicast
159
4.4. Multihoming
4.4.1. Multi-homing support at exit routers
4.4.2. Address Selection
4.4.2.1. Configuration
161
161
162
163
4.5. DNS
4.5.1. Platform: BIND 9
4.5.2. Description of scenario and cases.
4.5.2.1. Case 1
4.5.2.2. Results
4.5.2.3. Case 2
4.5.2.4. Results
163
163
164
165
168
171
173
4.6. DHCPv6
4.6.1. Ralph Meyer’s DHCPv6 implementation for Linux.
4.6.2. KAME/WIDE’s implementation for FreeBSD.
4.6.3. Proposed testbed.
175
175
176
177
4.7. QOS - Differentiated Services
178
4.8. Mail
179
4.9. Telecoconference
4.9.1. ISABEL application
181
181
4.10. News
4.10.1. Proposed testbed
4.10.2. Installation Guide
184
184
185
4.11. IRC
186
4.12. NFS
187
4.13. Remote Authentication Dial In User Service
189
4.14. LDAP
190
Page 6 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
5.
CONCLUSIONS
191
6.
GLOSSARY AND ABBREVIATIONS
192
7.
REFERENCES AND BIBLIOGRAPHY
195
APPENDIX A: MOBILE CONFIGURATION FILES.
199
APPENDIX B: DNS ZONE FILES.
201
Page 7 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
1. Introduction
The exponential growth of the Internet, connecting more and more users worldwide, is the
main reason for the need for a new protocol. IPv4 addressing and routing limitations becomes
more relevant, while Internet growth rates are progressively increasing.
IPv6 is becoming more and more important every day. Services are being migrated to this new
IP protocol version, including services at network level and services at application level.
New requirements, such as security and mobility, have been considered in the Internet market.
Another aspect is related to the transition from IPv4 to IPv6. The transition has to be gradual
and the IPv6 networks have to work with existing network protocols.
Taking into consideration the fact that the migration towards IPv6 will take some time and
will involve the usage of special mechanisms to guarantee the required connectivity, it is
important to study how this will have impact on today services, evaluating their usability in
mixed IPv4/IPv6 scenarios.
This document will focus on the study of functional aspects related with the deployment of a
number of network and application level services in mixed IPv4/IPv6 scenarios. Services
usage in transition scenarios will require more than pure connectivity between hosts
distributed over mixed networks. This is the reason why there are special transition
mechanisms and, in particular, application level gateways (ALG)1, since some of the services
do use a particular protocol, including addresses and other information in the exchanged
protocol messages, depending on the protocol version.
In other cases, service operation and/or architecture are different between both protocol
versions, causing major difficulties to the ones that need to use the same service over a mixed
infrastructure (IPv4 and IPv6).
In this document, the services that are being deployed over LONG infrastructure are
identified. It also describes the scenarios where those services could be used.
In the next chapter, the theoretical and functional aspects of network level services are
presented, with focus on mixed IPv4/IPv6 scenarios. Also, the available implementations are
identified.
In the third chapter, a number of the application level services are presented and it describes
the impact of their usage when IPv4 an IPv6 networks are involved.
In the forth chapter, the services that are being deployed over the LONG infrastructure are
described, including network topologies and network elements configurations, and obtained
results.
Finally, in the fifth chapter, some conclusions are drawn.
1 Please refer to LONG deliverable D2.1, “Description of IPv4/IPv6 available transition strategies”
Page 8 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2. Network level services
2.1. Mobility
2.1.1. Introduction
The number of mobile systems with Internet support has increased during the last decade.
Furthermore, there are already products based on cellular technology offering IP services
based on WAP or GPRS, and their number will increase rapidly. It is known that cellular
devices of 3rd generation will be packet switched devices instead of circuit switched.
When Internet Protocol (IP) was designed, it was assumed that hosts could not change their
location, e.g., it was assumed that a host could not be unplugged from one network to another
without any configuration task. In the IP protocol, the net ID part of the address identifies the
geographic position of the network where the node is connected. If the node moves to another
network, there is no way to determine its new location without assigning a new IP address to
the host. and, therefore, the routing protocols fail in the delivery of datagrams that are destined
to him. This task will only be successful if the node acquires a new IP address when it moves
to another network.
This new address must have the net ID of the new IP network it has moved to. This solution
works only for new connections and all connections initiated before the network transition
will fail. In order to achieve node mobility, IETF (Internet Engineering Task Force) has
defined protocol enhancements, initially for IPv4 (the Mobile IPv4 [RFC2002] ) and more
recently for IPv6 (Mobile IPv6 - working in progress [D-MIPv6]).
Before explaining how Mobile IP works, it is important to become familiar with terminology
used in such technology. We will use these terms extensively in the description of Mobile IP.
·
Mobile Node (MN): a node running Mobile IP protocol that is able to move
between different IP networks.
·
Home Network (HN): the network, which corresponds the home address of the
mobile node.
·
Home Address: the globally addressable IP address of MN in its HN.
·
Foreign Network (FN): any network which is not the HN.
·
Care-of address: one IP address assigned to MN when it is attached to a FN.
·
Home Agent (HA): a functional entity (that can be located in a host or a router
attached to the HN) that represents MN when it is connected to a FN.
·
Foreign Agent (FA): a functional entity (that can be located in a host or \a router
attached to the FN) that assists the MN in the communications between him and its
HA; additionally, it can implement service access policies imposed by the FN
manager.
·
Correspondent Node (CN): any host that is communicating with the mobile node.
Page 9 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.1.2. IPv4 Mobility
Mobile IPv4 was specified by “IP Routing for Wireless/Mobile Hosts” IETF Working group
and was published as a proposed standard in 1996 [RFC2002] .
Mobility service involves four functional entities: the Mobile Node (MN), the Home Agent
(HA), the Foreign Agent (FA) and the Correspondent Node (CN). Mobility is a service
provided by the network to the Mobile Node and it is transparent to the CN. Therefore, CN
uses IP network in the traditional way.
·
Discovery, Registration and Tunnelling
To support Mobile IP there are three basic processes:
·
Discovery: When a MN changes to a new IP network it uses a discovery procedure to
identify either its HA (if it has changes to its HN) or an available FA.
·
Registration: After concluding discovery procedure, a MN uses an authenticated
registration procedure to inform the HA with its new location.
·
Tunneling: Tunneling is used by HA to forward IP packets to MN.
Discovery
Internet Control
Message
Protocol
ICMP
Registration
Tunneling
User datagram
Protocol
(UDP)
Internet Protocol (IP)
Figure 1 –Three basic process of the mobility
The Discovery procedure has two objectives: to enable MN the detection of IP network
change and, when it happens, to acquire a care-of address.
HA and FA periodically broadcast agent advertisements to advertise their presence.
Additionally, MN can broadcast an agent solicitation message to request information of
available FAs. The Discovery procedure is similar to the router advertisement process defined
in ICMP. The MN uses these advertisements to determine if it has changed its network
position. If a network change is detected, MN goes to the Registration procedure. Note that if
MN is attached to its HN, no mobility mechanisms are used and MN behaves like a “normal”
host. On the other hand, if MN returns to its HN, it goes also to the Registration mechanism.
If MN determines that it is on a FN, it obtains a care-of address from a foreign agent or a
collocated care-of address through a DHCP server. The main difference between these two
types of address is depicted in the next figure: a care-of address is an IP address that belongs
to the FA and a collocated care-of address is an IP address temporarily leased to the MN. The
motivation for these two options is related with the scarceness of IP addresses. As it will be
Page 10 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
described later, the collocated care-of address simplifies data forwarding but requires IP
address availability in the FN.
Since handoff occurs at the physical layer without notification to the network layer Discovery
procedure must run in continuous mode in MN.
192.168.101.1
Mobile Node with a
care-of address
192.168.10.1
192.168.101.1
Internet
192.168.10.20
Mobile Node
with a collocated
care-of address
Figure 2 – Care-of address and collocated care-of address
Since HA and FAs can exist in HN, not all foreign agent advertisements received by MN
mean that it is away from home. There are two main mechanisms to determine if a handoff
has happened.
·
Use of the lifetime field.
When MN receives agent advertisements, it keeps the lifetime field information as a timer
that decreases with time. When the timer reaches zero before MN receives another
advertisement, MN assumes that a handoff has happened and starts broadcasting agent
solicitations. However, MN can receive agent advertisement messages from another FA
even if the timer associated to a previous FA has not expired. In this case, it does not
broadcast agent solicitations. Although this case does not necessary mean that a handoff
has happened, the Registration procedure must follow as if a handoff had happened.
·
Use of network prefix.
If MN receives an agent advertisement with a different network prefix, then it concludes
that there was an handoff and starts broadcasting agent solicitation.
The Registration procedure has one objective: to enable MN to inform its HA with a careof-address that can be used by HA to contact him. The registration process is made in four
steps (illustrated in Figure 3).
A – The MN sends a registration request to FA that it wants to use.
B – The Foreign Agent sends this registration request to the HA of that MN.
C – The HA receives and processes the request. HA sends to FA the result of the
request. It can accept or denies the request.
D – The FA relays this replay to MN.
Page 11 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The registration messages are carried by UDP protocol. The FA can be bypassed when MN
has acquired a collocated care-of address through a DHCP server. In this case, the
Registration procedure runs directly between MN and HA. This decision is made based on the
following rules:
·
If MN has acquired a care-of address, the Registration procedure is made through the
FA.
·
If MN has acquired a collocated care-of address but it has received an agent
advertisement from a FA with flag R on, the register procedure must be made also by
the FA.
·
If MN has acquired a collocated care-of address and either did not receive any FA
agent advertisement or if it has received an agent advertisement with flag R off, then
the Registration procedure is made directly to HA.
B
Foreign Agent
A
Internet
Home Agent
D
C
Mobile Node
Figure 3 – Registration procedure
In the Registration procedure the default authentication algorithm uses MD5 keys to produce a
128 bit message digest. The digest is computed over a shared secret key, followed by the
protection fields from the registration message, followed by the shared secret key again. There
are three types of authentication extensions: Mobile-Home, provide authentication between
MN and HA; Mobile-Foreign, may be required by FA and provides authentication between
MN and FA; and Foreign-Home, may be required by FA and provides authentication between
FA and HA. All registration messages include strong authentication to avoid the possibility of
DoS (denial of service) attacks. The method to distribute these keys is not defined in Mobile
IPv4 RFC.
After the discovery and registration processes are performed, HA must be able to intercept
datagrams sent to MN IP home address. These datagrams should be forwarded to the MN
(collocated) care-of address (known through the Registration procedure). HA uses
encapsulation to forward these datagrams to MN current location.
Consider the example of next figure. Because MN is away from HN and has made a
Registration procedure, HA intercepts IP datagrams whose IP destination address is the MN
home address. For each such datagram, HA creates a new IP datagram with its IP address as
source address and the care-of address IP address as a destination and it put the entire
datagram received as payload (1). FA receives the IP datagram, decapsulates the original
packet and forwards it to MN (2). This is the case when a non-collocated care-of-address was
Page 12 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
announced by MN in the Registration procedure. In the collocated case, the tunnel is done
directly from HA to MN.
Foreign
Agent
Home
Agent
Mobile
Node
2
1
Home
Network
Internet
Foreign
Network
Correspondent
Node
Figure 4 – HA uses a tunnel to forward the datagrams to MN current location
Tunnels can be implemented based on one of three possible types of encapsulation:
·
IP-in-IP Encapsulation
Conceptually it is the simplest form of encapsulation and it is defined in RFC2003.
Outer IP Header
Original IP Header
Original IP Payload
Inner IP Header
Original IP Payload
Other Headers
(Optional)
Figure 5 – IP-in-IP encapsulation
·
Minimal Encapsulation
This type of encapsulation uses less fields of information, therefore it has a lower
overhead but it cannot be used when fragmentation exists. It is defined in RFC2004.
Tunnel Endpoints
Original IP Header
Original IP Payload
Destination IP
Address
Outer IP Header
Minimal Encapsulation Header
Original IP Payload
Figure 6 – Minimal encapsulation
Page 13 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
Generic Routing Encapsulation (GRE)
This protocol was designed in order to support any protocol over any protocol. It is the
encapsulation method with a higher overhead.
Delivery Header
Packet Payload
GRE Header
Figure 7 – Generic Routing encapsulation
IP-in-IP is the most used encapsulation protocol due the simplicity and it can be used when
fragmentation happens.
2.1.2.1. Data Forwarding
The data exchange between the CN and the MN is shown in the next figure for the case of a
non-collocated care-of address.
Original packet
IP source address - CN IP address
IP destination address - MN home address
Encapsulated IP packet
IP source address - HA IP address
IP destination address - Foreign Agent
Foreign
Agent
Mobile
Node
3
2
Home
Agent
Home
Network
Path used from CN to
MN
Internet
Foreign
Network
4
Path used from MN to
CN
MN to CN IP packet
IP source address - HA IP address
IP destination address - Correspondent Node
1
Original Packet
IP source address - CN IP address
IP destination address - MN home address
Correspondent
Node
Figure 8 – Example of data forwarding
CN generates IP packets with MN home address and sends them through the network (1). HA
captures these packets and sends them through a tunnel to the care-of address (2). FA receives
the encapsulated packets, recover the original IP packets and forward them to the MN(3). In
the opposite direction, MN generates packets to the CN address using its home address as the
origin address (4).
Note that packets sent from CN to MN go always to HA which is, in the general case, a suboptimal routing path. This is sometimes referred as the triangular routing problem of IPv4
mobility. This is the price to pay to achieve mobility with the requirement this it is transparent
Page 14 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
to CN, e.g., the CN does not need to run any special feature apart from its normal IPv4
protocol stack.
2.1.3. IPv6 Mobility
IPv6 has introduced a set of functionalities that were not presented on IPv4. Before proceed
with the IPv6 mobility, it is necessary to describe one such functionality, which has a major
impact on how IPv6 mobility works: the binding mechanism.
2.1.3.1. Binding Mechanism
Binding can be defined as the association of an original IP address to a binding IP address.
The owner of the original address is responsible to announce to other hosts the binding IP
address together with the lifetime. These announcements are sent have binding updates that
can be stand alone or sent within a data packet. A binding update is implemented through a
special IPv6 Destination Option Header.
An IPv6 host with an IP packet to send to a given IP address, checks its binding cache: if there
is no entry, it sends the packet to the original IP address; if it has an associated binding
address, it sends the packet to the binding IP address and adds an IPv6 Routing Option Header
with the original IP address.
The binding mechanism includes also two other messages: binding requests that are sent by
destinations when the binding lifetime expires, and binding acknowledgements sent by origin
host in response to previous binding requests. These messages are also implemented as special
IPv6 Destination Option Headers.
2.1.3.2. Discovery, Registration and Tunneling
Like in the IPv4 case, when MN changes its location, it is necessary to determine its location
and obtain a care-of address. ICMPv6 has several functions that are used in the discovery
procedure. These functions include, routers advertisements, neighbor advertisements, Router
solicitations and address auto-configuration. A MN can determine its current location by
listening to the router advertisements and comparing prefix of the source address with his
home address. If router address prefix is equal to MN home address, then MN is on the its
HN. Otherwise it is on a FN. The same process is used to determine if MN changed from a FN
to another FN.
If the MN does not want to wait for a router advertisement it can send a route solicitation
asking the routers to send router advertisements.
After MN concludes that it is in a FN it is necessary to obtain a care-of address. To obtain a
care-of address it can use IPv6 statefull or stateless address auto-configuration.
In the stateless address auto-configuration, MN obtains a care-of address adding a EUI-64
word (based on its MAC address) to the router advertisement prefix. Based on received router
advertisements messages, a mobile node maintains an entry in its Default Router List for each
router, and an entry in the Prefix List for each network prefix. Each entry has an associated
expire time value, extracted from the received advertisements. While MN is away from home
it should select one router from its Default Router List to use as default router and one
network prefix to use as the network prefix in its primary care-of address. In the statefull autoconfiguration, MN uses a DHCPv6 server, to obtain its care-of address.
Page 15 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
After having the care-of address, MN must register this care-of address with its HA. To do so,
MN sends a binding update message to its HA containing a binding update option. The
Binding Update flag A and H must be on. For this reason the HA must answer with a binding
acknowledgement. After MN has concluded the Registration procedure, HA intercepts all
packets destined to MN.
In the Registration procedure, MNs can dynamically detect their home agent and choose one
home agent if there is more than one available in its HN. This process is named Dynamic
Home Agent Address Discovery and works as follows. MN sends a Binding Update to the all
IPv6 nodes on their home subnet with the flag H on. MN encapsulates this packet in another
packet with the HN sub-network router anycast address as its destination address (will be
delivered to any router on the MN’s home link). The router decapsulates this packet and
multicasts the inner packet to all nodes on the link. All Home Agent nodes present in Home
Network will answer with a rejected binding acknowledgement. All binding
acknowledgements received by MN contain the globally unicast address of each HA. The MN
collects these addresses and chooses one to be its HA. MN repeats the registration process
using the globally unicast selected home agent. At this time HA may accept the binding
update.
HA cannot use a Routing Option Header to send the intercepted packets to MN, because it
cannot modify the packet. If HA modifies it the IPv6 authentication fails at the receiver. For
this reason a HA must use IPv6 encapsulation to forward intercepted datagrams. When a HA
encapsulates a datagram to send it to MN care-of address, it uses MN care-of address as
destination and it uses its own IPv6 address as the source address as the outer IPv6 header
addresses (Figure 9)
IPv6 external Header
IPv6 internal Header
IPv6 external Header
. Source address - HA address
. Destination address - MN CoA
Payload
IPv6 internal Header
. Source address - CN address
. Destination address - MN Home Addess
Figure 9 – Encapsulated datagram sent by HA to MN care-of address
2.1.3.3. Data Forwarding
MNs use the previously described binding mechanism to optimize data forwarding between
MN and CN. As we have seen in the Binding mechanism section, before sending a packet to
any destination, an IPv6 node must first check its Binding Cache for a binding to this address.
If no binding cache entry is found, CN sends the datagram to the MN Home Address - HA1
will intercept the datagram and tunnel it, using IPv6 encapsulation, to its current primary careof address. The sender does not know that it is communicating with a mobile node.
When MN receives an encapsulated datagram from its HA, it sends a binding update to CN.
After CN receives a Binding Update from MN, the following datagrams to MN will be send
1 We suppose that MN is away from home network and Home Agent knows its care-of address.
Page 16 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
directly to MN primary care-of address, using a Routing Option Header. The route specified
by this routing header has two hops (next figure). The first hop is the MN care-of address and
the second is its Home Address.
Source
CN IP address
1st Hop
IP Care-of address of the
Mobile Node
2st Hop
IP Home address of the
Mobile Node
Figure 10 – The routing header of a packet sent directly to a mobile node
The MN receives the datagram by its care-of address and forwards it to the next hop in the
routing header. The final hop is the home address of the mobile node, this means that the
packet will be looped back inside mobile node. As consequence the upper network layers will
process the packet in the same way as if the mobile node was at home. The MN can answer
directly to CN using its care-of address and sends its home address in the IPv6 Destination
Option Header. The visible address for the upper layers continues to be the MN home address.
2.1.4. IPv6 vs IPv4 Mobility
Mobility is supported by both Internet Protocol versions (IPv4 and IPv6) but due to the
features introduced by IPv6, the mobility support has been integrated more efficiently in IPv6.
In this section we list some Mobile IPv6 advantages:
·
IPv6 has a larger address space; MN can always get a collocated care-of address and
the use of Foreign Agents is not fundamental.
·
Using stateless address autoconfiguration and neighbor discovery mechanisms Mobile
IPv6 does not need DHCP servers to configure its care-of address.
·
Use of Routing Header Options enable source routing implementation, which is used
to solve the triangular routing problem of IPv4 implementation.
·
Use of Destination Header Options allows the implementation of binding mechanism
without network performance degradation (these options are only processed at
destination nodes).
·
IPv6 has security built in mechanisms that can be used in authentication, data integrity
protection and replay protection.
·
The Dynamic Home Agent Discovery mechanism increases the Mobile IPv6
robustness in case of one of the home agent fails.
2.1.5. Mobility in Transition Scenarios
The migration from IPv4 to IPv6 will be progressive and the different steps of this migration
will be based on different transition scenarios. Several transition mechanisms have been
proposed as pieces of a puzzle that can be set up to solve the requirements of the different
transition scenarios. Unfortunately, most of these mechanisms have been designed to solve
basic network services and do not address the requirements of advanced services, like
Page 17 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
mobility for example. Recently, a few IETF drafts have addressed this issue on how mobility
can be provided in transition scenarios but it seems that this task is still in its first stages. This
section is divided in two. First, some considerations are presented on which transition
scenarios make sense to be addressed in the provision of mobility between IPv4 and IPv6
nodes. Then, we summarize the current views of IETF on how mobility can be provided in
transition scenarios.
2.1.5.1. Considerations on scenarios of interest
Mobility in transition scenarios where IPv6 networks are interconnected by an IPv4 network
(based on mechanisms like configured tunnels or 6to4) is straighforward. In these scenarios,
mobility involves only IPv6 service elements (MNs, CNs and HAs) and the IPv4 network acts
just as a point-to-point technology that interconnects IPv6 routers. The opposite is also true:
IPv4 networks interconnected by an IPv6 network. In this case, mobility involves only IPv4
service elements (MNs, CNs, HAs and FAs). Therefore, we consider as scenarios of interest,
the ones that require mobility where MNs and CNs are in different network protocols (one in
IPv6 and the other in IPv4).
In these cases, a transition mechanism (TM) must deal with the mapping between IPv4 and
IPv6 which involves a single network element between the two networks. For example, if
NAT-PT is used, even if different NAT-PT routers connect an IPv4 network with an IPv6
network, the communications between hosts that are in opposite sides must cross the same
NAT-PT router in both directions. Moreover, most of these mechanisms were designed for
typical situations where one of the network is the public network and the other is an island,
possibly belonging to an organisation or an ISP. Therefore, as a first approach, we consider as
scenarios of interest, the ones that require mobility between a host that is in the public
network and an host that is in islands.
MNs and HAs are administrative related. In typical cases, either they belong to the same
organisation or the MNs owner has an administrative contract with the HA administrator (for
example, an ISP). It is not evident any administrative interest of having MNs and HAs in hosts
running opposite IP versions. Technically, this requirement is difficult to deal and would
require a kind of a mobile Bump-in-Stack approach running in MN (or perhaps in HA) that, as
far as we know, has not been addressed. Therefore, we only consider scenarios of interest, the
ones where HAs (and FAs in IPv4 case) run over the same IP version of MNs.
Taking these considerations into account, the following scenarios were derived.
Scenario A
MN handoff is from an IPv4 Network to another IPv4 Network while communicating with an
IPv6 CN. This scenario can be decomposed on two scenarios depending on which is the
public network. The first scenario considers the IPv4 as the public network. This is typically
one of the first stages in the IPv4 to IPv6 migration where a company has already an IPv6
network but is yet connected to the public IPv4 Internet. IPv4 mobility is required when a
public mobile user is accessing server hosts of the company (for example, a Web server or a
FTP server). The second scenario considers the IPv6 as the public network. This is typically
one of the last stages in the IPv4 to IPv6 migration where a company has still an IPv4 network
but is already connected to the public IPv6 Internet. IPv4 mobility is required inside the
company network when MN is communicating with public Internet servers.
Page 18 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
CN
IPv4
TM
IPv6
MN IPv4
TM - Transition Mechanism
IPv4
Figure 11 – Mobility: scenario A
Scenario B
MN handoff is from an IPv6 Network to another IPv6 Network while communicating with an
IPv4 CN. As in scenario A, it can be decomposed on two scenarios depending on which is the
public network. The first scenario considers the IPv4 as the public network and represents one
of the first stages in the IPv4 to IPv6 migration where a company has already an IPv6 network
but is yet connected to the public IPv4 Internet. IPv6 mobility is required inside the company
network when is communicating with public Internet servers. The second scenario considers
the IPv6 as the public network. Once again, this represents one of the last stages in the IPv4 to
IPv6 migration where a company has still an IPv4 network but is connected to the public IPv6
Internet. IPv6 mobility is required when a public mobile user is accessing server hosts of the
company (for example, an Web server or an FTP server).
CN
IPv6
TM
MN IPv6
IPv6
Figure 12 - Mobility: scenario B
Page 19 of 206
IPv4
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Scenario C
MN handoff is from an IPv6 Network to another IPv6 Network while communicating with an
IPv4 CN. This scenario considers the IPv4 as the public network and represents one of the
first stages in the IPv4 to IPv6 migration where a company is spread in different sites with an
IPv6 network in each site and uses the public IPv4 Internet. IPv4 mobility is required inside
the company between the different sites when MN is communicating with public Internet
servers.
CN
TM
IPv6
IPv4
MN IPv6
TM
IPv6
Figure 13 - Mobility: scenario C
Scenario D
MN handoff is from an IPv4 Network to another IPv4 Network while communicating with an
IPv6 CN. This scenario considers the IPv6 as the public network and represents one of the last
stages in the IPv4 to IPv6 migration where a company is spread in different sites with an IPv4
network in each site and uses the public IPv6 Internet. IPv6 mobility is required inside the
company between the different sites when MN is communicating with public Internet servers.
Figure 14 - Mobility: scenario D
Page 20 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.1.5.2. Current approaches in IETF
Only a few IETF draft proposals have been submitted that address mobility in IPv4-IPv6
transition scenarios. Among those, most of them address the requirements of mobility
elements (MNs, HAs,…) to be able to support mobility between IPv4 and IPv6 hosts and do
not study how adequate the available transition mechanisms are to set-up the network. From
the drafts proposed recently, we consider the following ones as the most relevant in the
following discussion:
§
Transitional Integration of Mobile IPv4 and Mobile IPv6 (version 01), Engelstad,
Telenor R&D, expires 9 Feb 2002.
§
Moving in a dual stack Internet (version 00), Tsao, Tsirtis, Boehm, CCL, ITRI; Flarion
Technologies; Siemens; expires Jan 2002.
§
Requirements for 6to4 mobility transition using Hierarchical Mobility Agent (version
00), Kahng, Jung, Cheon, Korea University, expires 2002
The strongest idea behind most proposals is the use of dual stack hosts. The simplest
proposals consider that all hosts are dualstack and the solutions are based on tunneling IPv4
packets into IPv6 (no transition mechanism required).
There are proposals that combine dualstack MNs and the DSTM transition mechanism. This
solution that does not require tunneling up to the IPv4 hosts and, therefore, does not require
dualstack in IPv4 CNs. For a dual stack MN, it is possible to move between different
networks while communicating with CNs using DSTM. The routing looks very much like
mobile IPv4 without routing optimization. This solution can be used in Scenario B where the
TM element is a DSTM router and requires dualstack implementation on MNs together with
additional network elements (DHCPv6 and AIIH servers). Because of the coordination of the
additional network elements, this solution seems to be manageable only in scenario B where
IPv4 network is in the public network.
Note that these proposals consider that in the IPv6 part of the network, hosts tunnel IPv4
packet into IPv6. This is simple if applications are IPv4-based but require a transition
mechanism inside the host if applications are IPv6-based. In this second case, these schemes
are quite inefficient since IPv6 application packets are translated into IPv4 packets that are
tunneled into IPv6 packets before being sent to the network.
There is at least one proposal that refers the use of transition mechanisms (typically in
scenario B) and point out SIIT and NAT-PT. Although this kind of solution seems to be
straightforward when mobility is required for IPv4 hosts (scenario A), it must be carefully
studied when mobility is required for IPv6 hosts (scenario B). It is not possible for an IPv6
MN to send Binding Updates to an IPv4 CN since the TM element cannot translate the
Binding Update information without breaking the Authentication Header in the packet. A
binding cache mechanism must be included in the TM element. Without such a kind of
solution, the IPv4-IPv6 address mapping is no longer valid since the IPv6 source address
changes with handoffs.
Scenarios C and D are more complex and current proposals are not directly applied. In these
cases, a complete solution must deal also with the registration procedure (that happens in
every MN handoff) which requires the use of tunneling transition mechanisms to solve this
part of the problem.
Page 21 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.2. Multicast
2.2.1. Introduction
A number of emerging network applications require the delivery of packets from one or more
senders to a group of receivers. These applications include bulk data transfer, streaming
continuous media, shared data applications, data feeds, WWW cache updating and interactive
gamming. For each of these applications, an extremely useful abstraction is the notion of a
multicast: the sending of a packet from one sender to multiple receivers with a single sends
operation.
It is therefore important to understand that multicast is a service that is most beneficial to
users that source information (e.g. content providers) and to ISPs and carriers. Multicast
reduces the time it takes to send data to a large set of receivers and reduces the network
capacity required to deliver information to a group of receivers. For carriers and ISPs,
multicast represents an opportunity to reduce network load and end-to-end delay. For
receivers, it is unimportant whether data is delivered via unicast or multicast services.
2.2.2. IPv4 Multicast
From a networking standpoint, the multicast abstraction can be implemented in many ways.
One possibility is for the sender to use a separate unicast transport connection to each of the
receivers. An application-level data unit that is passed to the transport layer is then duplicated
at the sender and transmitted over each of individual connections. This approach implements a
one-sender-to-many-receivers multicast abstraction using an underlying unicast network layer.
It requires no explicit multicast support from the network layer to implement multicast
abstraction; multicast is emulated using multiple point-to-point unicast connections. The
network routers are not actively involving in supporting the multicast.
A second alternative is to provide explicit multicast support at the network layer. In this
approach, a single data stream is transmitted from the sending host. This datagram (or a copy
of this datagram) is then replicated at the network router whenever it must be forwarded on
multiple outgoing links in order to reach the receivers. The network routers are actively
involved in supporting the multicast.
Clearly, this second approach toward multicast makes more efficient use of network
bandwidth in that only a single copy of datagram will ever traverse a link. On the other hand,
considerable network layer support is needed to implement multicast-aware network layer.
2.2.2.1. Address format
In the Internet architecture, a single identifier is used for the group of receivers, and a copy of
datagram that is addressed to the group using this simple identifier is delivered to all of the
multicast receivers associated with that group. In the Internet the single identifier that
represents a group of receivers is a class D multicast address. The group of receivers
associated with a class D address is referred to as a multicast group.
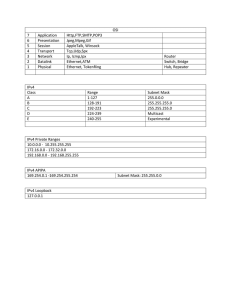
Class D addresses have the following format:
Page 22 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Figure 15 - IPv4 multicast address
In standard notation, the multicast addresses are presented in 224.0.0.0 to 239.255.255.255
range.
There are a number of multicast groups assigned by the Internet Assigned Numbers Authority
(IANA). The addresses 224.0.0.x and 224.0.1.x are reserved for administrative use, and the
range of 239.0.0.0 to 239.255.255.255 is destined to the private networks.
2.2.2.2. IGMP protocol
The Internet Group Management Protocol, IGMP version 2 [RFC2236], operates between a
host and its directly attached router (informally, think of the directly attached router as the
“first-hop” router that a host would see on a path to any other host outside its own local
network, or the “last-hop” router on any path to that host).
IGMP provides the means for a host to inform its attached router that an application running
on the host wants to join a specific multicast group. Given that the scope of IGMP interaction
is limited to a host and its attached router, another protocol is required to coordinate the
multicast routers (including the attached routers) throughout the Internet, so that multicast
datagrams are routed to their final destinations. The network-layer multicast routing
algorithms such as PIM, DVMRP and MOSPF accomplishes this later functionality.
IGMP messages have the following format:
8
Type
16
Maximum
Response Time
32
Checksum
Multicast Group Address
Figure 16 - IGMP message format
IGMP version 2 has three messages types.
A general membership_query message is sent by a router to all hosts on an attached interface
to determine the set of all multicast groups that have been joined by the hosts on that interface.
A router can also determine if a specific multicast group has been joined by hosts on an
attached interface, using a specific membership_query. The specific query includes the
multicast address of the group being queried in the multicast group address field of the IGMP
membership_query message.
Hosts respond to a membership_query message with an IGMP membership_report message.
Hosts can also generate this message when an application first joins a multicast group without
waiting for a membership_query message from the router. The router, as well as all hosts on
the attached interface receives membership_report messages. Each membership_report
contains the multicast address of a single group that responding host has joined. Note that
attached router doesn’t really care which hosts have joined a given multicast group or even
how many hosts on the same LAN have joined the same group.
Page 23 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Since a router really only cares about whether one or more of its attached hosts belong to a
given multicast group, it would ideally like to hear from only one of the attached hosts that
belongs to each group. IGMP thus provides an explicit mechanism aimed at decreasing the
number of membership_report messages generated when multiple attached hosts belong to the
same multicast group.
Each membership_query message sent by a router also includes a “maximum response time”
value filed. After receiving a membership_query message and before sending a
membership_report message for a given multicast group, a host waits a random amount of
time between zero and the maximum response time value. If the host observes a
membership_report message from some other attached host for that given multicast group, it
suppresses its own pending membership_report message, since the host now knows that the
attached router already knows the one or more host are joined to that multicast group. This
form of feedback suppression is thus a performance optimization - it avoids the transmission
of unnecessary membership_report messages.
The final type of IGMP message is the optional leave_group message. The router infers that
no host are joined to a given multicast group when no host responds to a membership_query
message with the given group address.
IGMP messages are encapsulated within an IP datagram, with an IP protocol number of 2.
There is no control over who sends to the multicast group. Datagrams sent by different hosts
can be arbitrarily interleaved at the various receivers (with different interleaving possible at
different receivers). A malicious sender can inject datagrams into the multicast group
datagram flow. Even with benign senders, since there is no network-layer coordination of the
use of multicast addresses, it is possible that two different multicast groups will choose to use
the same multicast address. From a multicast application viewpoint, this will result in
interleaved extraneous multicast traffic.
Although the network layer does not provide filtering, ordering, or privacy of multicast
datagrams, these mechanisms can all be implemented at the application layer. In many ways,
the current Internet multicast service model reflects the same philosophy as the Internet
unicast service model – an extremely simple network layer with additional functionality being
provided in the upper-layer protocols in the hosts at the edges of the network.
2.2.2.3. Routing protocols
The goal of multicast routing is to find a tree of links that connects all of the routers that have
attached hosts belonging to the multicast group. Multicast packets will then be routed along
this tree from the sender to all the hosts belonging to the multicast tree. The tree may contain
routers that do not have attached hosts belonging to the multicast group.
In practice two approaches have been adopted for determining the multicast routing tree. They
differ according to whether a single tree is used to distribute the traffic for all senders in the
group, or whether a source-specific routing tree is constructed for each individual sender.
In the Group-shared tree approach, only a single routing tree is constructed for the entire
multicast group.
In a Source-based approach, an individual routing tree is constructed for each sender in the
multicast group. In a multicast group with N hosts, N different routing trees will be
constructed for that single multicast group. Packets will be routed to multicast group members
in a source-specific manner.
Page 24 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Group-Shared Tree
In this case the multicast routing problem appears quite simple: find a tree within the network
that connect all routers having an attached host belonging to that multicast group. If it will be
assigned a “cost” to each link then an optimal multicast tree is one having the smallest sum of
the tree link costs.
The problem of finding a minimum cost tree is known as the Steiner tree problem. It is
interesting to note that none of the existing Internet multicast routing algorithms have been
based on this approach, because information is needed about all links in the network. Another
reason is that in order for a minimum-cost tree to be maintained, the algorithm needs to be
rerun whenever link costs change.
An alternate approach toward determining the group-shared multicast tree, one that is used in
practice by several Internet multicast routing algorithms, is based on the notion of defining a
center node (also known as rendezvous point). In the center-based approach, a center node is
first identified for the multicast group. Routers with attached hosts belonging to the multicast
group then unicast so-called join messages addressed to the center node. A join message is
forwarded using unicast routing toward the center until it either arrives at a router that already
belongs to the multicast tree or arrives at the center. In either case, the path that the join
message has followed defines the branch of the routing tree between the edge router that
initiated the join message and the center. One can think of this new path as being grafted onto
the existing multicast tree for the group.
A critical question for center-based tree multicast tree routing is the process used to select the
center. Center-selection algorithms are discussed, and the centers can be chosen so that the
resulting tree is within a constant factor of optimum (the solution to the Steiner tree problem).
Source-Based tree
The least-cost path tree is not the same as the minimum overall cost tree computed as the
solution to the Steiner tree problem. The reason for this difference is that the goals of these
two algorithms are different: least unicast-cost path tree minimizes the cost from the source to
each of destinations (that is, there is no other tree that as a shorter distance path from the
source to any of the destinations), while the Steiner tree minimizes the sum of the link costs in
the tree.
The least-cost path multicasting routing algorithm is a link-state algorithm. It requires that
each router know the state of each link in the network in order to be able to compute the leastcost path tree from the source to all destinations. A simpler multicasting algorithm, one that
requires much less link state information than the least-cost path routing algorithm, is the
reverse path forwarding (RPF) algorithm. The idea behind this algorithm is: when a router
receives a multicast packet with a given source address, it transmit the packet on all of its
outgoing links (except the one on which it was received) only if the packet arrived on link that
is on its own shortest path back to the sender. Otherwise, the router simply discards the
incoming packet without forwarding it on any of its outgoing links. Such a packet can be
dropped because the router knows it either will receive, or has already received, a copy of this
packet on the link that is on its own shortest path back to the sender. Note the reverse path
forwarding does not require that a router know the complete shortest path from itself to the
source; it need only know the next hop its unicast shortest path to the sender.
The solution to the problem of receiving unwanted multicast packets under RPF is known as
pruning. A multicast router that receives multicast packets and has no attached hosts joined to
Page 25 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
that group will send a prune message to its upstream router. If a router receives prune
messages from each of its downstream routers, then it can forward a prune message upstream.
While pruning is conceptually straightforward, two subtle issues arise. First, pruning requires
that a router know which routers downstream are dependent on it for receiving their multicast
packets. This requires additional information beyond that required for RPF alone. A second
complication is more fundamental: if a router sends a prune message upstream, then what
should happen if a router later needs to join that multicast group? If a prune message removes
a branch from that tree, then some mechanism is needed to restore that branch. One possibility
is to add a graft message that allows a router to “unprune” a branch. Another option is to
allow pruned branches to time-out and is added again to the multicast RPF tree; a router can
then re-prune the added branch if the multicast traffic is still not wanted.
The previous concepts are used on the standardized Internet multicast routing protocols such
as DVMRP (Distance Vector Multicast Routing Protocol), MOSPF (Multicast Open Shortest
Path), and PIM (Protocol Independent Multicast).
DVMRP
DVMRP uses a distance vector algorithm that allows each router to compute the outgoing link
(next hop) that is on its shortest path back to each possible source. This algorithm implements
source-based tree with reverse path forwarding, pruning and grafting.
When a router has received a prune message from all of its dependent downstream routers for
a given group, it will propagate a prune message upstream to the router from which it receives
its multicast traffic for that group. A DVMRP prune message contains a prune lifetime (with a
default value of two hours) that indicates how long a pruned branch will remain pruned before
being automatically restored. DVMRP graft messages are sent by a router to its upstream
neighbor to force a previously pruned branch to be added back on to the multicast tree.
The problem of the Internet deployment multicast routing is that only a small fraction of the
Internet routers are multicast-capable. Tunneling can be used to create a virtual network of
multicast-capable routers on top of a physical network that contains a mix of unicast and
multicast routers. This is the approach take in the Internet MBone. The router’s administrator
must explicitly configure the tunnels. Each tunnel has three parameters: the destination router,
a cost that is used to compute DVMRP distances, and a “threshold”.
MOSPF
MOSPF [RFC1584] extends OSPF by having routers add their multicast group membership to
the link state advertisements that are broadcast by routers as part of the OSPF protocol. All
routers have not only complete topology information, but also they know which edge routers
have attached hosts belonging to various multicast groups. The routers within the AS can
build source-specific, pre-pruned, shortest-path trees for each multicast group.
PIM
The PIM routing protocol [RFC2362] explicitly envisions two different multicast distribution
scenarios. In dense mode, multicast group members are densely located, i.e., many or most of
routers in the area need to be involved in routing multicast datagrams. In sparse mode, the
number of routers with attached group members is small with respect to the total number of
routers.
Page 26 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
In dense mode, since most routers will be involved in multicast it is practical to assume that
each and every router should be involved in multicast. Therefore, an approach like RPF that
floods datagrams to every multicast router (unless a router explicitly prunes itself) is
acceptable to this scenario.
In sparse mode the default assumption should be that a router is not involved in a multicast
distribution; the router should not have to do any work unless it wants to join a multicast
group. This argues for a center-based approach, where routers send explicit join messages, but
otherwise uninvolved in multicast forwarding. The sparse-mode approach is being receiverdriven type (that is, nothing happens until a receiver explicitly joins a group) while the densemode approach is data-driven type (that is, that datagrams are multicast everywhere, unless
explicitly pruned).
PIM Dense Mode is a flood-and-prune reverse-path-forwarding technique similar in spirit to
DVMRP. PIM is protocol-independent, i.e., independent of the underlying unicast routing
protocol. Because PIM makes no assumptions about the underlying routing protocol, its RPF
algorithm is slightly simpler, although slightly less efficient than DVMRP.
PIM Sparse Mode is a center-based approach. PIM routers send join messages toward a
rendezvous point to join the tree and intermediate routers set up multicast state and forward
the join message toward the rendezvous point. There is no acknowledgment generated in
response to a join message. Join message are periodically sent upstream to refresh/maintain
the PIM routing tree. PIM has the ability to switch from a group-shared tree to a sourcespecific tree after joining the rendezvous point. A source-specific tree may be preferred due to
the decreased traffic concentration that occurs when multiple source-specific trees are used.
In PIM Sparse Mode, the router that receives a datagram to send from one of its attached hosts
will unicast the datagram to the rendezvous point. The rendezvous point then multicasts the
datagram via the group-shared tree. A sender is notified by the rendezvous point that it must
stop sending to the rendezvous point whenever there are no routers joined to the tree, i.e., no
one is listening.
2.2.3. IPv6 Multicast
One of the design goals of IPv6 was to include multicast as part of the base standard, not as an
add-on. Instead of having a separate group membership discovery, the IPv6 equivalent of
IGMP will be part of ICMPv6, and will be expected to be present in all IPv6 hosts and routers.
The set of ICMPv6 messages that enable “Multicast Listener Discovery” (MLD) [RFC2710]
are the multicast listener “query”, “report” and “done”, which are roughly equivalent to IGMP
membership query, report and leave.
2.2.3.1. Address format
The most visible innovation in IPv6 will be the size and the structure of the multicast
addresses. All hosts and routers IPv6 must implement the multicast mechanism.
An IPv6 multicast address [RFC2373] is an identifier for a group of nodes. A node may
belong to any number of multicast groups.
Multicast addresses have the following format:
8 bits
4 bits
4bits
112 bits
Page 27 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
11111111
flags
Scope
Group ID
Figure 17 - IPv6 multicast address
The FF hexadecimal number at the start of the address identifies the address as being
multicasts address.
The flags field is a set of four flags, where the high-order 3 flags are reserved, and must be
initialized to 0. The multicast addresses can be permanently-assigned (by the global internet
numbering authority) or non-permanently-assigned, depending of the fourth flag (T) value.
Scope is a 4-bit multicast scope value used to limit the scope of the multicast group. The
possible scope values are described at [RFC2373]
The Group ID field identifies the multicast group, either permanent or transient, within the
given scope.
The meaning of permanently-assigned multicast address is independent of the scope value.
Otherwise, non-permanently-assigned multicast addresses are meaningful only within a given
scope. For example, a group identified by the non-permanent site-local multicast address at
one site bears no relationship to a group using the same address at a different site, nor to a
non-permanent group with the same group ID, nor to a permanent group with the same group
ID.
The multicast addresses must not be used as a source addresses in IPv6 packets or appear in
any routing header.
2.2.3.2. MLD protocol
The purpose of MLD is to enable each IPv6 router to discover the presence of multicast
listeners (nodes wishing to receive multicast packets) on its directly attached links, and to
discover specifically which multicast addresses are of interest to those neighboring nodes.
This information is then provided to whichever multicast routing protocol is being used by the
router, in order to ensure that multicast packets are delivered to all links where there are
interested receivers.
MLD is an asymmetric protocol, specifying different behaviors for multicast listeners and for
routers. For those multicast addresses to which a router itself is listening, the router performs
both parts of the protocol, including responding to its own messages.
If a router has more than one interface to the same link, it need perform the router part of
MLD over only one of those interfaces. On the other hand, listeners must perform the listener
part of MLD on all interfaces from which an application or upper-layer protocol has requested
reception of multicast packets.
MLD is derived from version 2 of IPv4's Internet Group Management Protocol, IGMPv2.
One important difference to note is that MLD uses ICMPv6 (IP Protocol 58) message types,
rather than IGMP (IP Protocol 2) message types.
MLD message have the following format:
0
8
Type
16
Code
32
Checksum
Maximum Response Delay
Reserved
Page 28 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Multicast Address
Figure 18 - MLD message format
As IGMP version 2 messages, MLD have three messages types: Multicast Listener Query,
Multicast Listener Report and Multicast Listener Done.
The General Query, used to learn which multicast address have listeners on attached link, is
one subtype of Multicast Listener Query, and the Multicast-Address-Specific Query, used to
learn if a particular multicast address has any listeners on attached link, is another subtype of
Multicast Listener Query. In a Query message, the Multicast Address field is set to zero when
sending a General Query, and set to a specific IPv6 multicast address when sending a
Multicast-Address-Specific Query.
The Maximum Response Delay field is meaningful only in Query messages, and specifies the
maximum allowed delay before sending a responding Report, in units of milliseconds. In all
other messages, it is set to zero by the sender and ignored by receivers. Varying this value
allows the routers to tune the "leave latency" (the time between the moment the last node on a
link ceases listening to a particular multicast address and moment the routing protocol is
notified that there are no longer any listeners for that address). The others MLD message
fields are explained at [RFC2710].
As it was said previously, routers use MLD protocol to learn which multicast addresses have
listeners on each of their attached links. Each router keeps a list, for each attached link, of
which multicast addresses have listeners on that link, and a timer associated with each of
those addresses. For each attached link, a router selects one of its link-local unicast addresses
on that link to be used as the IPv6 Source Address in all MLD packets it transmits on that
link.
With respect to each of its attached links, a router may assume one of two roles: Querier,
when it is designated to transmit MLD queries on a link, or Non-Querier, when there is
another router designated to transmit MLD queries on a link.
A Querier for a link periodically (Query Interval) sends a General Query on that link, to solicit
reports of all multicast addresses of interest on that link. On startup, a router should send
General Queries spaced closely together (Startup Query Interval) on all attached links in order
to quickly and reliably discover the presence of multicast listeners on those links. General
Queries are sent to the link-scope all-nodes multicast address (FF02::1), with a Multicast
Address field of 0, and a Maximum Response Delay of Query Response Interval.
When a node receives a General Query, it sets a delay timer for each multicast address to
which it is listening on the interface from which it received the Multicast Listener Query.
Each timer is set to a different random value selected from the range [0, Maximum Response
Delay] with Maximum Response Delay as specified in the Multicast Listener Query packet. If
a timer for any address is already running, it is reset to the new random value only if the
requested Maximum Response Delay is less than the remaining value of the running timer. If
the Multicast Listener Query packet specifies a Maximum Response Delay of zero, each timer
is effectively set to zero, and the action specified below for timer expiration is performed
immediately.
When a node receives a Multicast-Address-Specific Query, if it is listening to the queried
Multicast Address on the interface from which the Multicast Listener Query was received, it
Page 29 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
sets a delay timer for that address to a random value selected from the range 0 to Maximum
Response Delay. If a timer for the address is already running, it is reset to the new random
value only if the requested Maximum Response Delay is less than the remaining value of the
running timer. If the Multicast Listener Query packet specifies a Maximum Response Delay of
zero, the timer is effectively set to zero, and the action specified below for timer expiration is
performed immediately.
If a node's timer for a particular multicast address on a particular interface expires, the node
transmits a Multicast Listener Report to that address via that interface; the address being
reported is carried in both the IPv6 Destination Address field and the MLD Multicast Address
field of the Report packet. The IPv6 Hop Limit of 1 prevents the packet from traveling beyond
the link to which the reporting interface is attached.
If a node receives another node's Multicast Listener Report from an interface for a multicast
address while it has a timer running for that same address on that interface, it stops its timer
and does not send a Multicast Listener Report for that address, thus suppressing duplicate
reports on the link.
When a router receives a Multicast Listener Report from a link, if the reported address is not
already present in the router's list of multicast address having listeners on that link, the
reported address is added to the list, its timer is set to Multicast Listener Interval, and its
appearance is made known to the router's multicast routing component. When a Report is
received for a multicast address that is already present in the router's list, the timer for that
address is reset to Multicast Listener Interval. If an address's timer expires, it is assumed that
there are no longer any listeners for that address present on the link, so it is deleted from the
list and its disappearance is made known to the multicast routing component. When a node
starts listening to a multicast address on an interface, it should immediately transmit an
unsolicited Report for that address on that interface, in case it is the first listener on the link.
When a node ceases to listen to a multicast address on an interface, it should send a single
Multicast Listener Done message to the link-scope all-routers multicast address (FF02::2),
carrying in its Multicast Address field the address to which it is ceasing to listen. If the
node's most recent Report message was suppressed by hearing another Report message, it may
send nothing, as it is highly likely that there is another listener for that address still present on
the same link. If this optimization is implemented, it must be able to be turned off but should
default to on.
When a router in Querier state receives a Multicast Listener Done message from a link, if the
Multicast Address identified in the message is present in the Querier's list of addresses having
listeners on that link, the Querier sends Last Listener Query Count Multicast-Address-Specific
Queries, one every Last Listener Query Interval to that multicast address. These MulticastAddress-Specific Queries have their Maximum Response Delay set to Last Listener Query
Interval. If no Multicast Listener Reports for the address are received from the link after the
response delay of the last query has passed, the routers on the link assume that the address no
longer has any listeners there; the address is therefore deleted from the list and its
disappearance is made known to the multicast routing component. This process is continued
to its resolution (i.e. until a Multicast Listener Report is received or the last MulticastAddress-Specific Query is sent with no response) despite any transition from Querier to NonQuerier on this link.
On the other hand, routers in Non-Querier state must ignore Multicast Listener Done
messages. When a router in Non-Querier state receives a Multicast-Address- Specific Query,
Page 30 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
if its timer value for the identified multicast address is greater than Last Listener Query Count
times the Maximum Response Delay specified in the message, it sets the address's timer to
that latter value.
The state transitions diagrams can specify a node and router behaviors.
A node may be in one of three possible states with respect to any single IPv6 multicast address
on any single interface.
(i)
Non-listener state, when the node is not listening to the address on the interface;
(ii)
Delaying Listener state, when the node is listening to the address on the interface
and has a report delay timer running for that address;
(iii)
Idle-Listener, when the node is listening to the address on the interface and does
not have a report delay timer running for that address. The state transition diagram
is the following.
Stop Listening
( stop timer, Send done if flag set)
Stop Listening
(Send done if flag set)
Non-Listener
Start Listening
( send report, set flag, start
timer)
Delaying
Listener
Query received
(reset timer if
Max Resp Delay
< current time
Query received (start timer)
Idle
Listener
Report Received (stop timer,
clear flag)
Timer expired (send report, set flag)
Figure 19 - Node state Transition Diagram
As we can see there are five significant events that can cause MLD state transitions:
Start Listening occurs when the node starts listening to the address on the interface.
Stop Listening occurs when the node stops listening to the address on the interface.
Query received occurs when the node receives either a valid General Query message, or a
valid Multicast-Address-Specific Query message.
Report received occurs when the node receives a valid MLD Report message.
Timer expired occurs when the report delay timer for the address on the interface expires
In all of the above state transition diagrams, each state transition arc is labeled with the event
that causes the transition, and, in parentheses, any actions [RFC2710] taken during the
transition. Note that the transition is always triggered by the event; even if the action is
conditional, the transition still occurs.
Page 31 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
As it was seen previously, a router may be in one of two possible states, Querier and NonQuerier, with respect to any single attached link. There are three events that cause the change
of router state:
·
query timer expired occurs when the timer set for query transmission expires
·
query received from a router with a lower IP address occurs when a valid MLD
Query is received from a router on the same link with a lower IPv6 Source Address
·
other querier present timer expired occurs when the timer set to note the presence of
another querier with a lower IP address on the link expires
To respond to the above events there are three actions [RFC2710] that may be taken. The
router state transition diagram is the following:
gen. query timer expired
(send general query, start
gen. query timer)
(send gen. query,
start initial general
query timer)
Initial
Querier
query received from a
router with a lower IP
address (start other
querier present timer)
other querier
present timer expired
(send gen. query, start
gen. query timer)
Non-Querier
query received from a
router with lower IP address
(start other querier present
timer)
Figure 20 - Router State Transition Diagram
A router starts in the Initial state on all attached links, and immediately transitions to Querier
state.
In addition, to keep track of which multicast addresses have listeners, a router may be in one
of three possible states with respect to any single IPv6 multicast address on any single
attached link:
·
No Listeners Present state, when there are no nodes on the link that have sent a
Report for this multicast address
·
Listeners Present state, when there is a node on the link that has sent a Report for this
multicast address.
·
Checking Listeners state, when the router has received a Multicast Listener Done
message but has not yet heard a Multicast Listener Report for the identified address.
There are five significant events that cause router state transitions:
Page 32 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
report received occurs when the router receives a Multicast Listener Report for the
address from the link
·
done received occurs when the router receives a Multicast Listener Done message for
the address from the link
·
multicast-address-specific query received occurs when a router receives a MulticastAddress-Specific Query for the address from the link
·
timer expired occurs when the timer set for a multicast address expires
·
retransmit timer expired occurs when the timer set to retransmit a Multicast-AddressSpecific Query expires
To respond to the above events there are seven possible actions [RFC2710] that may be taken.
The following state transition diagram is for a router in Querier state, and is apply per group
per link.
Timer expired
(notify routing -)
No Listeners
Present
Timer expired
(notify routing -, clear rxmt tmr)
Rexmt timer expired
(send m-a-s query,
st rxmt tmr)
report received
(notify routing +,
start timer)
Listeners
Present
report received
(start timer, clear rxmt tmr )
Checking
Listeners
done received (start timer, start
rxmt timer, send m-a-s query)
report received
(start timer)
Figure 21 - State transition diagram for a router in Querier state
The state transition diagram for a router in Non-Querier state is similar, but non-Queriers do
not send any messages and are only driven by message reception.
Page 33 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Timer expired
(notify routing -)
No Listeners
Present
Timer expired
(notify routing -)
report received
(notify routing +,
start timer)
Listeners
Present
report received
(start timer)
Checking
Listeners
m-a-s query rec’d
(start timer*)
report received
(start timer)
Figure 22 - State transition diagram for a router in Non-Querier state
2.2.3.3. Routing protocols
The IPv6 multicast routing protocols are stil in development and they are not standardized.
The PIMv6 is one IPv6 multicast routing protocol, and it is the result of protocol clarifications
within the Protocol Independent Multicast (PIM) routing protocol for efficiently routing to
multicast groups communicating with the Internet Protocol version 6.
There is a permanently assigned link-scoped IPv6 multicast address for the PIM protocol,
which is the All-PIM-routers multicast address. It is assumed that a router running PIM for
IPv6 will have a network unique, domain-wide reachable IPv6 address that will be used for
multiple messages.
The checksum field in the PIM (PIM sparse mode and PIM dense mode) header covers the
entire PIM message. When running PIM over IPv6, it must use the standard checksum
calculation for IPv6 applications as specified in [RFC2460].
The IPv6 destination address of a Hello message must be the All-PIM-routers multicast
address and the IPv6 source address must be the IPv6 link-local address of the interface on
which the message is being forwarded. The link-local address in the source field will be used
to determine the neighbour adjacency and for Designated Router (DR) election.
The register message is addressed to domain-wide reachable IPv6 address of the rendezvous
point. The source address of the message is the domain-wide reachable IPv6 address of the
DR.
The register-stop message is addressed in the same manner as the register message.
In the transmission of a Join/Prune, Graft, or Graft-Ack Message, a router sets the IPv6
destination address to the All-PIM-Routers multicast address. The IPv6 source address is set
to the link local address of the interface on which the message is forwarded. The Upstream
Neighbor Address field is set to the link local address of the next hop router, which is
obtained from the RPF lookup.
Page 34 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
When sending a Bootstrap Message, a PIM router sets the IPv6 destination address field to the
All-PIM-Routers multicast address. The source address is set to the link local address of the
interface on which the message is forwarded.
The Assert Message has an IPv6 destination address of the All-PIM-Routers multicast address
and an IPv6 source address of the link local address of the interface forwarding the message.
The link local address in the IPv6 source address field is used to resolve ties in the assert
process. Downstream routers save the winning assert router's link local address to resolve any
future RPF requirements.
The Candidate-RP-Advertisement Message uses the domain-wide reachable IPv6 address of
the Bootstrap Router (BSR) as the IPv6 destination address. The source address is a domainwide reachable IPv6 address unique to the candidate Rendezvous Point (RP). The RP
Address field is set to a domain-wide reachable IPv6 address of the candidate RP. Each
candidate RP router creates this message and unicasts it to the BSR.
The main scoping issue involves the bootstrap mechanism, which is a centralized function, i.e.
there is one bootstrap center per PIM domain. In order for bootstrap mechanism function
properly, the PIM domain must be a subset of the scoped address domain or all multiple hop
messages must use globally reachable IPv6 address.
2.2.3.4. Available implementations
Ericsson Telebit A/S has developed an IPv6 router that is used in Denmark's National IPv6
Academic and Research Network run by UNI-C. This router implements the IPv6 multicast.
Also the KAME’s pile developed by the Wide consortium currently allows IPv6 multicast
routing. It is developed for the operating systems BSD (FreeBSD, NetBSD, OpenBSD,
BSD/OS). IPv6 multicast routers will be PC based equipped with the FreeBSD operating
system.
The IPv6 multicast applications can be launched by different PCs with different Operating
Systems.
KAME’s implementation supports MLD (to implement the host-router part) and PIM (to
implement the router-router part), and can act both as a router and as a host [HUITEMA].
Uses an interface name or index to identify a specific interface both in the kernel and in
applications. It has two network daemons implemented in the user space to handle PIM for
IPv6: pim6dd for PIM dense mode and pim6sd for PIM sparse mode.
Once all IPv6 nodes are required to support multicasting all routers should be multicastcapable, which means that they do not have to use multicast tunnels to deploy IPv6
multicasting.
Implementation characteristics of PIM for IPv6
KAME's implementation supports PIM for IPv6 as a multicast routing protocol.
PIM uses a separate routing mechanism, which runs independently of PIM itself, in order to
determine network topology and to detect an upstream router for Reverse Path Forwarding
(RPF).
IPv6 allows a node to assign multiple addresses on each interface. As an example, consider an
IPv6 router that assigns a global address as well as a link-local address on an interface. As it
was referred on Routing Protocols section, the specification of PIM for IPv6 [D-PIM6]
Page 35 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
requires the use of a link-local address as the source address of PIM Hello messages and uses
the address as an identifier of the router. But the link-local address is not necessarily used to
specify the router as a gateway in unicast routing, as it happens on a multiprotocol extension
for BGP to handle IPv6 might use an IPv6 global address as a gateway. In the cases that a
network administrator of a router might install a static global address as the gateway
destination a PIM router is not correctly recognized and RPF does not work. To resolve this
problem KAME’s implementation restricts their PIM domain to an Interior Gateway Protocol
(IGP) domain. Since all IGPs currently defined for IPv6[RFC2740] use link-local addresses as
the next hop for forwarding packets, they are much safer than BGP. When it is configured a
static route in a PIM domain, it is always used a link-local address as the gateway of the route.
It is not assigned multiple link-local addresses on each interface of a PIM router in order to
avoid possible address mismatches between PIM and unicast routing.
Scoping issues on PIM
The IPv6 addressing architecture [RFC2373] has a notion of scope for unicast and multicast
addresses. A four-bit field is reserved for each multicast address to define scopes. Routers do
not forward a multicasted packet with a specific scope outside of a domain in which the
multicast address is valid.
The scopes introduce another kind of difficulty into PIM. When the first hop router for a
multicast source receives a multicast packet, it encapsulates the packet into a PIM Register
message and forwards the encapsulated packet by unicast to the Rendezvous Point (RP) for
the multicast address. Although the Register message might break the boundary of the scope
zone to which the original multicast packet belongs, intermediate routers between the first hop
router and the RP cannot detect the fact that it has done so.
A router that acts as an RP periodically sends Candidate-RP-Advertisement messages to the
Bootstrap Router (BSR) in its PIM domain. Each message contains a unicast address of the
RP associated with a list of multicast addresses, which that particular RP will handle. If the
unicast address is a scoped one, the Candidate-RP-Advertisement message may break a
boundary of the scope zone. Even if the unicast address is global, a multicast address of the
list may break a boundary of the scope zone. The KAME’s project proposes to introduce
several restrictions on PIM routers to deal with these problems. The following relationships
between unicast and multicast scopes are made:
·
The scope zone for a link is the same for unicast and multicast.
·
The scope zone for a site is the same for unicast and multicast.
·
An organization-local scope for multicast is larger than site-local scopes; any
zone of a site-local scope does not intersect with or contain a zone for any
organization-local scope.
In order to prevent a Register message from breaking a zone boundary of a scope, KAME
proposes that the source and destination addresses of an encapsulated multicast packet in a
PIM Register message must not have smaller scope than the respective scopes of the source
and destinations addresses of the Register message.
When a first hop router forwards a multicast packet that has a site-local scope, for example,
the router must choose an address with a site-local or a smaller scope as the source address of
the Register message. This constraint also means that every RP should be configured with an
Page 36 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
address whose scope is smaller than or equal to the scopes of the multicast addresses that the
RP handles.
KAME’s project also proposes several rules for the PIM bootstrap mechanism to deal with the
scope issues. When a router forwards a bootstrap message, it should check the scope of the
bootstrap router address and should not forward the message on a link that breaks the zone
boundary of the scope. Also, a multicast address contained in the message should be removed
when the message is forwarded on an interface that belongs to a different scope zone from the
zone of an incoming interface. If an RP address for a multicast address contained in the
message has a larger scope than the scope of the multicast address, the RP should be ignored
and should not be contained in a forwarded message. Two rules have been proposed for PIM
Candidate-RP-Advertisement messages: the unicast RP address stored in PIM Candidate-RPAdvertisement message should not have a smaller scope than the respective scopes of the
source and destination address of the message; no multicast address associated with RP
should have a smaller scope than the scope of the RP address.
Experimental implementation
KAME’s implementation experimentally supports a multicast version of traceroute called
mtrace6. A query of mtrace6, like one of mtrace, is forwarded along the reverse path for a
specified multicast address and a source of the multicast address, collecting information about
the path, and is finally returned to the query sender as a response message. The mtrace6 tool is
used to grasp routing topology, to detect a routing loop for RPF, or to identify points of packet
loss on a reverse path. This tool is useful especially when we use a different routing protocol
for RPF from that used for unicast forwarding.
The query and response messages for mtrace6 are implemented as ICMPv6 messages,
whereas messages for the original mtrace are parts of IGMP messages. This is because there is
no IGMP for IPv6 and because MLD messages are also contained in ICMPv6. Mtrace6 does
not use IPv6 addresses to designate incoming and outgoing interfaces, because an IPv6
address, especially a link-local one, is not necessarily unique even in a single node. Instead,
interface indices are used; they are also used in the kernel and in other applications. All
mtrace6 messages have a common header [I2000M].
2.2.4. IPv6 vs IPv4 Multicast
The basic notion of multicast is common to IPv4 and IPv6. Several new characteristics are
introduced in IPv6 multicast that are not in IPv4 multicasting.
The IPv6 multicast is categorized into two parts, as is IPv4 multicasting: the host-router part
and the router-router part.
IPv6 explicitly limits the scope of a multicast address by using a fixed address field, whereas
the scope was specified using TTL (Time to Live) of a multicast packet IPv4.
Traditional implementations of IPv4 multicasting use unicast addresses to identify a network
interface. However, such an approach is not suitable for IPv6 for the following reasons: First
an IPv6-capable node may assign multiple addresses on a single interface, which tends to
cause a configuration mismatch. Also, a link-local address is not necessarily unique within a
node and consequently, it may not identify a single interface. A user must specify the interface
index as well as the address in such a case. Since the specified index itself should identify a
single interface, the address is actually redundant.
Page 37 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Multicast tunnels were introduced to deploy the IPv4 multicasting, even with routers that were
not multicast-capable. In spite of difficulties involved in handling tunnels, such as topology
complexity and encapsulation overheads, they were necessary because multicasting was an
extension in IPv4 and there was no guarantee that every router supported multicasting.
Although all IPv6 nodes are multicast-capable, the tunnel mechanism can be used to deploy
multicasting because there are no current commercial routers to implement the IPv6
multicasting routing protocols.
2.2.5. Multicast in transition scenarios
In the transition stage from IPv4 to IPv6 it is necessary that IPv4 nodes and IPv6 nodes can
communicate directly. It is necessary to provide a transition mechanism for multicast.
2.2.5.1. Translation mechanisms
The working in progress considers a multicast translator and an address mapper who are
located at the site boundary between IPv4 and IPv6 compose the scheme of multicast
communication between IPv4 nodes and IPv6 nodes. In order to allow IPv4 nodes and IPv6
nodes to directly communicate using multicast, they need to be installed on the site boundary
between IPv4 and IPv6.
The transition mechanism can be applicable to small-scale network systems, and to the extent
of division networks in intranets where its administrator can operate the setup easily on
demand by receivers. It cannot be applicable to large-scale network systems like world- wide
Internet as it stands because it needs the setup by its administrator. In order to apply it to
large-scale network systems, it needs developing a new standard protocol between multicast
translators and receivers for carrying out the setup automatically on demand by receivers. In
order to apply it to large-scale network systems, it is necessary to automate the setup that the
administrator carries out according to the requests of the receivers, i.e., the receivers directly
call on the IPv4 multicast proxy (or the IPv6 multicast proxy) to join in the group which they
want to receive. The interaction can be carried out by some protocols.
Page 38 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
IPv4 Multicast
Sender Node
IPv6 Multicast
Sender Node
Address Mapper
Translator
IPv4
land
IPv4
Multicast
Proxy
IPv6
land
IPv6
Multicast
Proxy
Multicast Translator
IPv4 Multicast
Receiver Node
IPv6 Multicast
Receiver Node
Figure 23 - Network System
The multicast translator is located between an IPv4 land and an IPv6 land. It is composed by
three sub-components:
Translator – translates IPv4 multicast packets into IPv6 multicast packets and vice-versa.
The Gateway is one translation type, which terminates the data bound for an IPv4 multicast
group at the application layer, and relays the data to an IPv6 multicast group and vice-versa.
The Header conversion router is another translation type that when receiving IPv4 multicast
packets converts the IPv4 headers into IPv6 headers, fragments the IPv6 packets if necessary,
and then forwards the packets. Likewise, when receiving IPv6 multicast packets, it converts
the IPv6 headers into IPv4 headers, and then forwards the IPv4 packets.
IPv4 Multicast Proxy - joins IPv4 multicast groups as a proxy of IPv6 receiver
nodes.
By this means it receives packets bound for the IPv4 multicast groups, and then hands the
packets to the translator.
IPv6 Multicast Proxy - joins IPv6 multicast groups as a proxy of IPv4 receiver
nodes.
In that way it receives packets bound for the IPv6 multicast groups, and then hands the
packets to the translator.
Address Mapper - maintains each unicast address spool for IPv4 and IPv6. The IPv4
spool, for example, consists of private addresses bound for the multicast translator. An
example of the IPv6 spool is IPv6 address space assigned to virtual IPv6 organization on the
IPv4 land.
The address mapper also maintains a mapping table that consists of pairs of an IPv4 address
and an IPv6 address. When the translator (or the IPv4 Proxy or the IPv6 Proxy) requests the
address mapper to assign an IPv6 address corresponding to an IPv4 address, it selects a proper
IPv6 address out of the table, and returns the address to the translator. If there is not a proper
entry for an IPv4 unicast address, the address mapper selects and returns an IPv6 unicast
address out of the spool, and registers a new entry into the table. When there is not a proper
Page 39 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
entry for an IPv4 multicast group address, the address mapper registers a new entry, which
consists of the IPv4 multicast group address and that of IPv6 corresponding to the IPv4
address, into the table.
When the translator (or the IPv4 Proxy or the IPv6 Proxy) requests the address mapper to
assign an IPv4 address corresponding to an IPv6 address, it works like the above.
The mechanism uses a special type of an IPv6 address, which is termed an “IPv4-compatible”
IPv6 multicast group address. The format is the following:
96-bits
32-bits
ffxx:0:0:0:0:0
IPv4 multicast
group address
Figure 24 - IPv4-compatible IPv6 multicast address format
The communication from one IPv4 multicast sender node (sender4) to one or more IPv6
multicast receiver nodes (receiver6) can be explained by the following sequential diagram:
IPv4
multicast
proxy
sender4
IPv6
multicast
proxy
Translator
Address
mapper
receiver6
(1)
(2)
(3)
(4)
(5)
(6)
Translate IPv4 into
(7)
IPv6
Figure 25 - The interaction communicating from IPv4 to IPv6
Where,
– Sends an “IGMP Membership Report” for joining the IPv4 multicast group
– Registers a entry for the group into the mapping table
– Sends an IPv4 multicast packet
– Hands the IPv4 multicast packet
– Request IPv6 addresses corresponding to the IPv4 addresses
– Reply with the IPv6 addresses
– Forwards an IPv6 multicast packet
The communication from one IPv6 multicast sender node (sender6) to one or more IPv4
multicast receiver nodes (receiver4) can be explained by the following sequential diagram:
Page 40 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
IPv4
multicast
proxy
receiver4
IPv6
multicast
proxy
Translator
Address
mapper
sender6
(1)
(2)
(3)
(4)
(5)
(6)
Translate IPv6 into
IPv4
(7)
Figure 26 - The interaction communicating from IPv6 to IPv4
Where,
(1) – Sends an “MLD Multicast Listener Report” for joining the IPv6 multicast group
(2) – Registers a entry for the group into the mapping table
(3) – Sends an IPv6 multicast packet
(4) – Hands the IPv6 multicast packet
(5) – Request IPv4 addresses corresponding to the IPv6 addresses
(6) – Reply with the IPv4 addresses
(7) – Forwards an IPv4 multicast packet
This transition mechanism has limitations. In common with NAT, IP conversion needs to
translate IP addresses embedded in application layer protocols, thus it is hard to translate all
such applications completely.
mBIS
Hitachi work group proposed multicast extensions to dual stack hosts using the “Bump-In-theStack”.
BIS is used as an internal translator to allow IPv4 applications to communicate with IPv6
hosts (the BIS host should have a connection to an IPv6 network). A host that runs BIS has
the ability of a translator in a TCP/IPv4 stack. Is a self-translator, which is a kind of a dual
stack host and it don’t have necessity to run IPv6 applications. The BIS host does not modify
the IPv4 applications.
Page 41 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
BIS
IPv4 applications
T
IPv4
IPv6
Translator
IPv4
apps
IPv4
T
IPv6
Figure 27 - BIS
The mBIS is a translator for the multicast packets. In the IPv4 Inbound action the translator
forwards an IGMP report as it is. On the IPv6 Inbound action the translator intercepts an
IGMP report, and creates a proper MLD report. This is illustrated on the next figures:
mBIS
Translator
IPv4 multicast
applications
IGMP report
IPv4
IPv4 multicast
packets
Figure 28 - IPv4 Inbound action
Page 42 of 206
IPv4 Server
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
IPv4 multicast
applications
IPv4 Multicast
packets
mBIS
IGMP report
IPv6
IPv6 Server
Translator
MLD report
IPv6 multicast
packets
Figure 29 - IPv6 Inbound action
On the outbound action, mBIS can send IPv4 multicast packets and/or IPv6 multicast packets.
(Select-able)
The mBIS is useful in initial stage where it is hard to provide a complete set of IPv6
applications. It is also useful in the somewhat old hosts not supporting IPv6.
IPv4
IPv4 multicast
applications
Translator
IPv4 multicast
packets
IPv4 Client
IBM Compatible
IP
v4
->
Select-able
IPv6 Client
Pv
6
IPv6 multicast
packets
IBM Compatible
IPv6
Figure 30 - Outbound Action
2.2.5.2. Tunneling mechanism
Tunneling mechanism can be used in a network of tunnels with end equipment that supports
the multicast IPv6, when between multicast end-points the intermediate routers are not
multicast capable.
The topology chosen is a star-shape network centered on an IPv6 multicast router.
The next three cases can be emerge:
·
The sites will have only connectivity over the IPv4 network and will want to be
connected to unicast and multicast IPv6 network. In this situation it is necessary create
an IPv6 multicast tunnel over IPv4.
·
An isolated user will want to follow the multicast session, and does not have IPv6
connectivity. For this case it is necessary create an IPv6 multicast tunnel over IPv4
Page 43 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Audio/Video
IPv6 Server
Central
Router
IPv6
Multicast
Router
IPv6 Multicast tunnel over IPv4
IPv6
IPv4
client
IPv6 Multicast tunnel over IPv4
Figure 31 – IPv6 Multicast tunnel over IPv4
The sites that will want to follow the diffusion of the multicast session will be already
connected to the IPv6 network via IPv6 over IPv4 tunnels. In this case it is necessary to create
an IPv6 multicast tunnel over the previous tunnel.
Figure 32 - Tunneling mechanism
Page 44 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.3. Anycast
The IPv6 Addressing Architecture [RFC2373] defines three types of addresses i.e. unicast,
multicast and anycast. Anycast addresses are defined as “an identifier for a set of interfaces”.
That means that this kind of addresses will not identify neither a particular interface, such as
an unicast address, nor a group of interfaces as a multicast address, but one interface out of a
group of possible interfaces. The interface is chosen according to the routing distance from the
source, meaning that the interface, that belongs to the intended group, that is closer to the
source, will be selected. It should be noted that the source has no control or knowledge of
which one of the possible destinations will be reached.
Anycast addresses are regular unicast addresses that turn into anycast addresses when they are
assigned to more than one interface, so they there is not a special range of addresses reserved.
Routing of an anycast address: Depending on the geographical spread of the different
interfaces that have the anycast address assigned, routing towards the anycast address can be
more or less expensive for the network.
The simplest case is when all the interfaces belong to the same subnet, so the packet sent to
the anycast address is routed as an unicast addressed packet, and once inside the particular
subnet, the packet is forwarded to the closest interface with the particular anycast address.
This is, as we already said, the simplest case and also the less interesting one.
A more general case occurs when all the interfaces that share the same anycast address belong
to different networks, and all these networks share a prefix. Reachability information will be
propagated for each interface with an anycast address; this prefixes are aggregated by the
routing system when the routing data is propagated to the outside of the considered region.
Then, a packet submitted to an anycast address, regular routing is applied until a network that
has been assigned this prefix is reached. Once inside that network, a flat routing scheme is
applied by means of host routes i.e. routes with a length of 128 bits.
The worst case arises when the common prefix for the subnetworks that host the anycast
interfaces has length 0, so that host routes must be distributed all over the Internet. These are
called global anycast addresses; this is expected to be a very restricted feature due to the
obvious scaling problems that it presents.
Restriction to the use of anycast addresses: Since there is very little experience in the usage of
anycast addresses, there are several restriction imposed to their use. a) An anycast address
cannot be used as a source address in any packet. b) An anycast address can only be assigned
to routers and not to hosts.
The initial use for anycast addresses is limited to routers and all the routers in a subnet are
required to have the subnet-router anycast address configured in all their interfaces. This
anycast addresses identifies the routers of a subnet and it can be used to choose a path by
means of including the desired networks anycast address in the routing header of the packets.
Future uses: It is expected that as more experience is gained with anycast addresses, the
restrictions imposed to their usage will be softened, and several interesting uses will appear.
Anycast addresses seem to be useful to achieve some properties such as fault-tolerance and
load sharing, since it is the network who chooses the final destination, depending on
availability and proximity. For example it has been proposed the usage of anycast addresses to
identify DNS servers in a subnet, which seems to be a valuable service.
Page 45 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
However there are still many open issues referring to security and scalability that need further
study, as it is presented in [D-AANYC]. Additional concerns are, for example, a statefull
interaction with a server identified by an anycast address cannot be assured, since there is no
way of assuring that the same server is reached all time. Fragmented IPv6 packets may suffer
from the same problem. Host anycast addresses are also difficult to handle, since the routing
system should be aware of the service. There are different approaches to perform this: hosts
may act as a router in order to inject new routes into the routing system; or a special protocol
could be devised for allowing host-to-router communication, or viceversa.
There are not specific implementations for anycast support, except for a procedure for
finishing a TCP connection initiated by host addressing the anycast address of a router, since
this operation is not allowed (FreeBSD Kame 4.4). The router will generate an ICMP
“destination unreachable” to notify this occurrence [D-TCPANYC].
In the LONG project we will test the access to a DNS service via anycast addresses. These
addresses will be propagated by prefix injection inside the LONG network.
2.4. Multihomming
In this section, the early steps towards an IPv6 multi-homing solution (all of them at most at
the personal draft status at the IETF) are presented.
2.4.1. Introduction.
The extended usage of the currently available IPv4 multi-homing solution is jeopardizing
Internet’s future since it became a main contributor to the explosive growth of the routing
tables of the Network’s core routers. A cornerstone of IPv6 design was routing system
scalability, which precludes massive route injection into core routers. As a natural result of
this policy, direct adoption of IPv4 multi-homing techniques into IPv6 world is for now
inhibited, so new mechanisms are been proposed. However, actual IPv6 multi-homing
solutions fail to provide IPv4 multi-homing equivalent benefits, which imposes an additional
penalty for those adopting the new protocol. This IPv6 handicap prevents migration in critical
environments and provides an excellent excuse to reluctant users. The magnitude and the
complexity of this problem is reflected in the creation of a specific working group (multi6) in
the Internet Engineering Task Force (IETF), and its massive attendance in lasts IETF´s
meetings.
In the next section, we will present the motivations for multi-homing, and the IPv4 multihoming solution along with its drawbacks. Then we will present an IPv6 multi-homing
solution taxonomy based on design criteria. Finally the set of proposed IPv6 multi-homing
approaches will be summarized.
2.4.2. Motivations and requirements
We will first start this section by defining a multi-homed site as a site that obtains Internet
connectivity through two or more connections. Then, in the following paragraphs, we will
describe the motivations for site multi-homing and later we will study the IPv4 case, including
its invalidating drawbacks which will lead us to the final requirement definition for an IPv6
multi-homing solution
Page 46 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.4.2.1. Motivations for multi-homing
Essentially, a site multi-homes in order to improve the quality of its Internet connectivity in
some aspect. The most obvious one is fault tolerance; by multi-homing, a site improves its
robustness against different types of failures. The range of failures covered depends on the
solution used and it may include from physical link failure to exchange failure. An optimal
solution would be the one that preserves connectivity when at least one valid path exists.
Some sites may also decide to multi-home to avoid long-term congested or poorly connected
areas, by means of provider selection. Finally, once a site is multi-homed, different providers
may offer different qualities at different costs, so it is in site’s best interest to be able to shift
different types of traffic on different providers, according to its own internal policy.
The IPv4 case
In the IPv4 world, when a site connects to the Internet, it obtains an address range from its
provider. Then when this site decides to become multi-homed and it obtains connectivity
through another provider, it keeps on using the same address range, which reachability is
advertised through both providers. This mechanism achieves the desired effect by relying on
the routing system to provide fault tolerance capabilities and best available path selection.
Moreover, this solution is optimal referring to fault tolerance, in the sense formerly described.
In addition, some basic form of policy-based ISP selection may be achieved through routing
system configuration.
The IPv4 available solution is extremely attractive from the site point of view, since it
achieves optimal fault tolerance, including preservation of established communication in case
of failure. Besides, this is accomplished in a very simple way, without needing extra protocols
or devices and without requiring substantial additional configuration. However, this solution
has a major impact on the global routing system, basically because each new multi-homer
injects a new route in every routing table of each core router of the Internet, and consequently
stressing the routing system capacity. For additional information about the IPv4 multi-homing
solution and its limitations the reader is referenced to the work being done in IETF´s multi6
working group [D-MH4].
2.4.2.2. Requirements for IPv6 multi-homing
A central task assigned to the multi6 working group is the definition of the requirements for a
multi-homing solution [D-MH6] . We will first present the mandatory requirements and then
the ones that are recommended but not compulsory.
Mandatory requirements. Essentially, a multi-homing solution must provide the basic features
that have motivated the site to become multi-homed in an IPv4 scenario i.e. complete fault
tolerance and policy based provider selection. In particular, the solution must be able to
preserve connectivity, including established transport sessions, in case of failures of the
following elements: physical link, logical link, routing protocol, transit provider and exchange
point. Additionally, an acceptable solution must allow provider selection based on policy
parameters. Another set of mandatory requirements is related to the effort needed to deploy.
Essentially, a new solution must not be much more complex than the IPv4 solution. Besides,
the impact on existent equipment must be minimized, meaning that needed modification on
existent implementations of hosts and/or routers must be either minor or in the form of
separate functions working in parallel with previous non multi-homed enabled ones.
Page 47 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Moreover, new multi-homed enabled devices (hosts, routers and even applications) must be
able to interoperate with non multi-homed enabled ones, allowing the lost of multi-homing
benefits in that particular communication.
Recommended requirements. Optional requirements include additional benefits of multihoming that would be desirable, like load-sharing features among providers or performance
based provider selection in order to avoid congested or poorly connected paths.
2.4.3. IPv6 site multi-homing solutions taxonomy
In this section we will present three different approaches to the multi-homing issue:
topological constraints, address engineering and end-to-end based multi-homing.
Additionally, several solutions that have been proposed based on the different approaches will
be referenced.
2.4.3.1. Topological constraints.
The motivation for the application of topological constraints is based on the observation that
the multi-homed sites contribution to core-network route table growth is due to the fact that
the different paths to the multi-homed site can only be aggregated into one route in the DFZ.
So, the basic idea of this approach is to impose aggregation points somewhere below in the
network hierarchy where the different paths (routes) to a multi-homed site converge. There are
two possible types of constraints that will be presented in the following order: constraints to
the attachment point of the multi-homed site and global network topology constraints.
Multi-homed site network attachment point constraints.
The most restrictive option would be to limit multi-homing to only one provider. In this case,
as the site can only have several connections to the Internet through one ISP, only one route to
that site is propagated beyond this particular ISP, keeping all the multi-homing issues internal
to that ISP. There are several obvious unacceptable drawbacks in this solution, among which
we can highlight the extremely limited fault tolerance and insufficient policing features.
In order to improve this proposal, the aggregation point can be placed higher in the network
hierarchy. An attempt to achieve this is the exchange-based aggregation. In this case, an
address range is assigned to an exchange point, and the sites attached to the providers with
presence in that exchange may obtain their addresses from that range. This enable site multihoming with different ISPs of the exchange without leaking routes outside the given
exchange. It also enables the change of ISP without renumbering as long as the new ISP is
connected to the same exchange. Even though this proposal is more robust than the previous
one, it still has a single point of failure in the exchange point. Whether this is acceptable or
not it depends on the specific needs of the particular site. It should also be observed that this
solution has a limited geographical scope, meaning that, since all the ISPs that a site multihomes to must be attached to the same exchange point, this solution will be hardly compatible
with the needs of a world-wide extended site.
Network topology constraints.
If we try to place the aggregation point higher in the hierarchy once more, in order to
overcome the weaknesses of the previous proposals, we have to impose more general
restrictions that apply to the whole network and not only to the multi-homed sites. Attempts to
Page 48 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
do this are the geographical aggregation schemes, such as the Provider Independent
addressing [D-IUNIC]. These addressing schemes provide aggregation based on geographical
proximity, and in order to achieve it, they impose that all the different providers of a particular
area meet in an aggregation point of that area, just like the telephone system. It should be
noted the major architectural impact of these “centralized” aggregation points, in contrast with
the traditional peer to peer design of the Internet. However, it is also important to notice that
geographical aggregation, as it is stressed in [D-IUNIC], can coexist with other aggregation
mechanisms such as the Provider Aggregation used in the Internet today.
2.4.3.2. Address engineering.
Internet addresses identify not only an end point attached to the network but also the route to
reach it. This means that an address contains both identification information and routing
information. In the IPv4 world, the fact that usually only one address is assigned to each
interface has softened the problem presented by this linkage of information. However, in the
IPv6 world, where an interface usually has several addresses, and where provider based
aggregation imposes different routes for prefixes delegated by different ISPs, this rigid
association between identification and routing information precludes the possibility to use
alternative available routes to a given destination. Address engineering approaches are a
workaround to this problem; essentially destination addresses of the packets are changed for
another address with equivalent identification information but with different routing
information in order to change the path followed by the packet. Obviously, the initial address
must be restored in order to provide transparency to end nodes.
The simplest mechanism for address engineering is tunneling. The basic idea behind them is
that the end point of the tunnels are aware that two different addresses share the same
identification information, but with different routing information. Then the endpoints of the
tunnel can reach a destination through two different paths, either by sending the packet
directly into the net or by encapsulating it into the alternative destination address. The
proposed application ( [RFC2260] ) of the former mechanism to a multi-homed site, allows
the packets to be forwarded through the alternative ISP, using the tunnel, when the usual path
is not available. The main drawback of this particular approach is its limited fault tolerance,
since the fault domain is limited to the direct service providers. In case of a failure somewhere
higher in the hierarchy, connectivity is lost.
In order to improve the fault tolerance capability of the solution, state information, meaning
the mapping between different addresses containing equivalent identification information but
different routing information, can be stored in other fashions. One possibility is to use a
database to store this information. It has been proposed the usage of DNS. However, this
solution must be thoroughly studied because of the dependencies already existing between
DNS and the routing system i.e. the DNS needs routing for proper functioning. Another
possibility is to build a new database that contains such information, as it is proposed in [DMHTP] . This approach presents at least complexity as a major drawback and it also has an
important architectural impact on the network, since it may introduce a server role in the
current peer to peer routing system. Another possibility is to store the state information
directly in the IP layer of end hosts, as it is proposed in [D-LIN6]. The main problem with this
proposal is the difficulty to access reachability information since this one is only available for
the routing system. Finally, it could be conceived a distributed peer to peer location of this
information, according to the architectural principles of the Internet routing system.
Page 49 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.4.3.3. End to End.
Another option is to state that the multiple addresses caused by multi-homing is an issue that
will not be solved by the network and that end hosts will have to cope with. In this case, and
end-to-end solution is needed. So end hosts will have to manage the different addresses and
they will need to know when to use which one. They should also be able to handle the
information flow from a sequence of packets with different destination addresses. At the end
host, these tasks can be performed at two different levels: TCP level or application level. A
transport level solution is application transparent, but a specific solution need to be developed
for each transport layer used. The particular case of TCP is addressed in [D-PTCPS]
, but
solution for connectionless protocols such as UDP are less clear. The application layer can
take care of the problem as it is presented in [D-AMH], which obviously imposes that each
application develops a module to cope with multiple addresses in the case that the hosts that
are running the application were placed in a multi-homed site.
The main obstacle that this approach comes up against is the lack of network status
information at the end nodes. A possible solution to this problem could be just to guess, i.e. if
an address fails, just try with another one. Clearly, this solution is much less than optimal and
expected latency is high. Another solution could be to obtain the needed information from
some network element such as the routing system. There are some open issues with this
approach, like end host-routing system interaction or how far the needed information resides.
2.4.4. Summary for IPv6 Multi-homing solutions
Three different approaches to solve the multi-homing problem have been presented. The first
one is an approach based on imposing topological restrictions on the network connectivity.
These restrictions can apply only to attachment points of multi-homed sites or to the whole
network. The first option is expected to be implemented through the assignment of address
ranges to exchanges points. This is an acceptable solution for a large number of sites, but
geographically extended institutions with extremely fault tolerant demanding sites will need
further support. The second option is much more ambitious as it pretends to impose a new
address aggregation scheme, and in order to achieve this, it demands the existence of
geographical meeting points where aggregation is performed. These levels of topological
requirements are not easily imposed in a network such as the Internet where there is no owner
or even a regulation authority.
The second approach presented is based on managing addresses in order to reach the correct
destination through different available routes. This approach has different levels of complexity
depending on the fault domain covered. For reduced fault domains, the solution, based on
tunnels, is simple and it is already implemented. For more extended domains, the solutions
seems to be much more complex and it introduces critical points in the network topology.
The third approach presented is the end-to-end one. In this case, end nodes manage the
multiple addresses caused by multi-homing support. This approach covers the appropriate
fault domain since it the multi-homing functions reside at the end host, also known as fatesharing (because the service is available unless the user machine fails). It also presents another
desirable characteristic: the complexity (i.e. the cost) is placed in the same system that gets the
benefits. The main problem with this solution is that it is incomplete, since the end node does
not have all the needed information to choose addresses in an optimal way.
Page 50 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.4.5. Address Selection for Peering Support
2.4.5.1. Introduction
Another aspect of multi-homing is peering, the way in which communication is established
with closely connected networks. First of all it should be stated that, when provider
aggregated addresses are used, and while no other mechanism were available, address
selection is a powerful tool for path selection. We can consider the communication of two
hosts that reach internet through providers with different TLA. In this case, the destination
address will force the path from the DFZ (Default Free Zone, where only specific routes to
each TLA are exchanged) to the end host. And the source address will also determine for a
response packet the route from the DFZ to the host. In certain circumstances, selecting the
proper address can be capital for proper route selection.
In the LONG scenario, in which it is planned to share a single prefix for all partners, proper
address selection is important for using addresses belonging to the common prefixes when
communication with the rest of the partners is desired, and other particular prefixes for
accessing to the Internet6.
2.4.5.2. Address Selection for IPv6
The general way of selecting the addresses is as follow: The pool of possible destination
addresses is returned by a DNS query; the application, that typically will not have additional
information, will choose the first address retrieved. For source address selection, this is
established at socket creation time, and selected by the stack if no explicit request is done by
the application. Therefore, an address selection mechanism will consist of an algorithm for
ordering DNS returned addresses, and an algorithm for selecting a source address for a given
destination.
The mechanism for Address Selection for IPv6 proposed in [D-DAS6]tries to select the best
matching destination address/source address pair. The guidelines for the criteria to apply are:
Prefer destination/source pairs with the same scope
Prefer smaller scopes for destination addresses
Prefer non deprecated addresses
Prefer native IPv6 addresses rather than transition mechanism addresses
Prefer destination/source address pairs with longest prefix match
Allow the definition of specific policies for a given domain
The algorithm proceeds as follows:
Source address selection for a given destination address D. First of all, a candidate set
for source address is chosen, being recommended the addressed assigned to the interface
used for delivering the packet towards D. Then, the following algorithm is applied to pairs
of addresses belonging to the candidate set (lets say SA and SB):
1 – Prefer same address
if D=SA, choose SA; and vice-versa.
2 – Prefer appropriate scope
Page 51 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
if [Scope (SA) < Scope (SB)] AND [Scope (SA) < Scope (D)], chose SB; and vc.
3 – Prefer non-deprecated addresses
4 – Prefer Home Addresses
5 – Prefer addresses belonging to the appropriate outgoing interface (if this has not
been applied before for obtaining the candidate set)
6 – Prefer label matching. There is a policy table on each system. Each entry has a
prefix, a precedence, and a label. Each address is checked against this table, searching
for the longest prefix match between the address and the prefix table, in order to
obtain the most appropriate label for the address. Then,
If [Label(SA) = Label (SB)] AND [Label(SB) <> Label(D)], choose SA, and vc.
7 – Prefer public addresses over temporal addresses (temporal addresses expire, and
can be used, for example, for privacy enhancement – the rule can be reversed,
depending on the policy to enforce).
8 - Prefer longest matching prefixes
There is a default policy table, that is listed below:
Prefix
Precedence
Label
::1/128
50
0
::/0
40
1
2002::/16
30
2
::/96
20
3
::ffff:0:0/96
10
4
For a large number of cases, rule 6 is executed (for example, to choose among several global
addresses). The default table guarantees that for 6to4, IPv4-compatible and IPv4-mapped,
correspondent addresses are chosen if available. New policies can be added by means of
writing new entries.
A similar approach is taken for destination address selection: destination addresses are pairwise compared, also using for the comparison the most appropriate source address found for
each destination one. Now the aim is to obtain an ordered set of destination addresses. The
rules for this process are:
1 – Avoid unusable destinations (known by other means that cannot be reached)
2 – Scope matching
If [Scope(DA)=Scope (Source(DA)] AND [Scope(DB) <> Scope(Source(DB))],
place DA before DB
3 – Avoid deprecated addresses
4 – Prefer Home Addresses for Source addresses
5 – Prefer “matching label”. The table is the same than for source address selection
If [Label (Source (DA)) = Label (DA)] AND [Label (Source(DB) <> Label(DB)],
prefer DA.
Page 52 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
6 – Prefer highest precedence for destination addresses
If Precedence(DA) > Prefecedence (DB), prefer DA
7 – Prefer native transport (avoid tunnels, etc.)
8 – Use longest matching prefix
If CommonPrefixLen(DA, Source (DA)) > CommonPrefixLen(DB, Source (DB), use
DA before DB).
9 – Leave unchanged.
The selection mechanism proposed in [D-MHSER] presents a series of rules for selecting
among different source and destination addresses available. It is required a consistent
mechanism for being able to understand how this process is carried out in a system, making
this independent from its particular implementation. Additionally, some form of configuration
is needed, in order to be able to implement the policy specifics of each domain.
2.5. DNS
2.5.1. Introduction
To establish any kind of communication it is necessary to know the IP address of a host. For
that, the Domain Name System translates machine names into IP addresses and vice-versa.
Main elements in a DNS system are:
§
The Domain Name Space and Resource Records.
§
Name Servers.
§
Resolvers.
The Domain Name Space and Resource Records
The Domain Name Space is a tree structure. Each node and leaf in the tree corresponds to a
resource set and has a label (0-63 byte length). Brother nodes may not have the same label but
nodes in different domains may use the same label. Null label is reserved for the root.
The FQDN (Full Qualified Domain Name) of a node is the sequence of labels in the path from
the node to the root domain separated by “.”. By convention, labels are read from left to right
and names are case insensitive.
The resource set associated to each node is composed of different resource records (RRs).
Each resource record has a standard format:
<owner>
[<ttl>]
[<class>] <type>
§
Owner: domain name where the RR is.
§
Type: encoded 16-bit value which can be:
A: Host address.
CNAME: Canonical name of an alias.
HINFO: CPU and OS used by a host.
MX: Mail exchange for the domain.
Page 53 of 206
<data>
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
NS: The authoritative name server.
PTR: A pointer to another part of the domain.
SOA: Start of authority.
Classes: encoded 6-bit value which identifies the protocol family.
IN: Internet.
CH: Chaos.
TTL: Time limit on how long an RR can be kept in cache.
RDATA: Data which describes the resource.
Other rules are: parentheses are used to group data that crosses a line boundary; a semicolon
starts a comment; the asterisk is used for wildcarding; and the “@” denotes the current default
domain name.
The Domain Name Space is maintained in a distributed manner, with local cache to improve
performance.
The IN-ADDR.ARPA Domain
The IN-ADDR.ARPA domain was created to make reverse translation easier. Within the
domain, there are subdomains that include the number of the network in the name.
For instance, the ARPANET is network 10. So, there is a domain called 10.IN-ADDR.ARPA
for reverse lookups in the zone.
2.5.1.1. Name Servers
Name servers are programs that set and maintain information about the domain’s tree
structure in a database. This database is divided up into sections called zones.
The file that describes a zone contains:
Authoritative data for all nodes in the zone.
Data that defines the top node of the zone.
Data that describes delegated subzones.
Data that allows access to name servers for subzones.
Any zone will be available from several name servers to avoid unavailability due to any
communication error such as host failures, link fall downs, etc. One of the name servers is the
master or primary server. Changes are coordinated at the master: after editing the text file, the
administrator has to increase the serial number and causes the name server to load the new
zone file. Slaves or secondary servers periodically check the serial number of the zone to
detect if changes have occurred.
The periodic checking for changes is controlled by the parameters REFRESH, RETRY and
EXPIRE fixed in the SOA RR of the zone. A slave waits REFRESH seconds before checking
the SERIAL of the master. If this operation cannot be completed, the slave starts it again after
RETRY seconds. If after EXPIRE seconds the operation is not completed, the slave server
must assume that its zone copy is obsolete and must discard it.
Page 54 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
If both the master and the secondary SERIAL are the same, it means the zone files are also the
same.
If the primary server SERIAL is greater than the secondary one, this one must request a zone
transfer via an AXFR. The several RRs are transmitted in several messages. To ensure
accuracy TCP or another reliable protocol must be used. It is not mandatory to retrieve zone
files from a master name server.
2.5.1.2. Resolvers
Resolvers are programs that obtain information from name servers in response to client
requests. It is located in the same machine as the program that requests is services, but it may
need to consult name servers in other hosts.
The top-level algorithm has four steps:
1. Is answer in local
cache?
YES
Send data to
the client
NO
2. Find the best servers
to ask.
3. Send them queries
until one answers.
4. Analyze the response
Correct data
Cache
cname
Cache
delegat
.
Cache
data
Delegation to other server
Alias (cname)
Server failure
Figure 33 - Algorithm of a Resolver
2.5.2. DNS with IPv6 Support
2.5.2.1. DNS Extensions to Support IPv6
Classical DNS system cannot support IPv6 simply because IPv6 addresses are too long to be
recorded in an A resource record.
[RFC1886] defines three basic changes to be made to DNS to support IPv6:
1. A new resource record type to store an IPv6 address: the AAAA record.
Page 55 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2. A new domain to support lookups based on IPv6 addresses: IP6.INT domain (later
obsoleted by IP6.ARPA domain in [RFC3152]).
3. Updated definitions of existing query types.
The AAAA Record
An AAAA record stores a single 128-bit IPv6 address, so a host owning more than one IPv6
address must have more than one AAAA resource record.
The address is stored in the data field of the RR in network order.
AAAA has been used since 1996 just like A record for IPv4. It has been working fine ever
since and there are already several implementations (BIND 4, BIND 8, BIND 9, etc.) that
support it.
AAAA main advantage is that by storing a complete address, it minimizes the effort involved
in fetching addresses. But, on the other hand, in the event of network renumber administrator
needs to update the whole DNS zone file. Besides, the time it takes to resign all of the
addresses in a zone after a renumbering event is longer with AAAA RRs.
The IP6.ARPA Domain
It was created to help reverse lookups for IPv6 just as the IN-ADDR.ARPA domain for IPv4.
A name is represented as a sequence of nibbles in reverse order separated by dots ending with
the suffix "IP6.ARPA".
For example to look for the domain name correspondent to address a:b:c:d:e::f, the resolver
would ask for
f.0.0.0.0.0.0.0.0.0.0.0.e.0.0.0.d.0.0.0.c.0.0.0.b.0.0.0.a.0.0.0.IP6.ARPA.
2.5.2.2. DNS Extension to Support IPv6 Address Aggregation and Renumbering
[RFC2874]defines the following changes:
1. A new resource record type to store an IPv6 address in a way that facilitates network
renumbering: the A6 record.
2. Updated definitions of existing query types that return Internet addresses as part of
additional section processing.
3. A new zone structure for reverse lookups that allows a zone to be used without
modification for parallel copies of an address space.
The A6 Record
The RDATA field of the A6 record has the format:
Prefix Length
Address Suffix
Prefix name
(1 octet)
(0..16 octets)
(0..255 octets)
Figure 34 – A6 Record
Page 56 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Note: The domain name component SHALL NOT be present if prefix length is zero.
The address suffix component SHALL NOT be present if the prefix length is 128.
With A6 it is possible to define an IPv6 address by using multiple DNS records. Hence, A6
can represent addresses in which a prefix portion of the address can change without any action
by the parties controlling the DNS zone. This is the main advantage of A6 records because it
helps renumbering. The withdraw that arises here is that to resolve an address it may be
necessary to perform N queries of A6 RRs which will take N-times de time AAAA would
take. As regards to security, there is also more work involved in verifying the signatures
received back for A6 records.
Focusing in practical implementations, only BIND 9 supports A6.
Reverse Lookups
With A6, a new zone structure is defined for reverse lookups that allows a zone to be used
without modification for parallel copies of an address space (as for a multihomed provider or
site) and across network renumbering events.
It relies on a new type of DNS label called the “bitstring label”[RFC2673]. As a significant
example any of the following domain names could be used to find the name of the node with
IPv6 address 3ffe:a:b:c:d:e::fff.
\[x3FFE000a000b000c000d000e00000fff/128].IP6.ARPA
\[x000d000e00000fff /64].\[x000c/16].\[x3FFE000a000b/48].IP6.ARPA
DNS address space delegation is implemented by the DNAME resource record. For instance
while looking for the name associated to the address a.b.c.d.e.f a resolver may find a DNAME
record like this:
d.e.f DNAME w.xy
which will cause it to look for a.b.c.w.xy.
2.5.2.3. AAAA or A6?
At this moment there are two RR types defined for holding IPv6 addresses (AAAA and A6)
but there are not any IPv6 reachable root DNS servers, partly because both AAAA and A6
exist. Questions arose whether A6 is really needed or not, or whether it is really possible to
migrate to A6 or not.
A draft of the IETF from July 2001 states that "AAAA records are preferable at the moment
while A6 records have interesting properties that need to be better understood before
deployment. It is still not known if the benefits of A6 outweigh the costs and risks" and
recommends:
-
[RFC 1886] stay on Standard Track and be advanced.
-
Move [RFC 2874] to Experimental status.
-
Deprecate the use of DNAME RRs in the reverse tree.
Page 57 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.6. DHCP v6
2.6.1. Introduction to DHCP
The Dynamic Host Configuration Protocol is a protocol designed to pass configuration
information to workstations. DHCP (see [RFC2131] for details about operation) is capable of
transferring most configuration parameters because of the flexible options header. It is widely
used for network parameters configuration (IP address, subnet mask, static route, root path,
swap server), although it may be used for other parameters as well.
The key point of DHCP is that the host doesn’t have to keep any information, and that all
configuration parameters can be passed using DHCP without any human interaction.
However, this easy-of-use is also the source of most of the security problems related to
DHCP. It is important to note that DHCP is not a policy but a mechanism for the host
configuration. The system administrators have to define the policy and implement it with the
DHCP server.
In general, DHCP reduces the cost of ownership by centralizing the management of network
resources such as IP addresses, routing information, OS installation information, directory
service information, and other such information on a few DHCP servers, rather than
distributing such information in local configuration files among all network nodes. DHCP is
generic in the sense of that it is extensible to carry new configuration parameters.
2.6.1. IPv6 Stateless Autoconfiguration
Stateless autoconfiguration is a powerful mechanism included in IPv6. With stateless
autoconfiguration, a host gains an address via an interface automatically "leasing" an address
and does not require the establishment of a server to delve out address space. Stateless
autoconfiguration allows a host to propose an address that will probably be unique (based on
the network prefix and its Ethernet MAC address) and propose its use on the network.
Because no server has to approve the use of the address, or pass it out, stateless
autoconfiguration is simple. This is the default mode of operation for most IPv6 systems,
including servers.
As we have seen IPV6 stateless configuration is simple because it does not need servers or
other external entities (apart from the gateway that always exists), but it lacks of some
functionality that may be of interest. For example, it makes an inefficient (uncontrolled) use of
the address space, it does not provide any access control, it provides only addresses, and the
most important, it does not provide authentication.
Stateless autoconfiguration is described in RFC2462 ("IPv6 Stateless Address
Autoconfiguration") with some proposed extensions in the Internet draft "Privacy Extensions
for Stateless Address Autoconfiguration in IPv6."
2.6.2. IPv6 Stateful Configuration.
Stateful autoconfiguration is the IPv6 equivalent of DHCP. This is called "stateful" because
the DHCP server and the client must both maintain state information to keep addresses from
conflicting, to handle leases, and to renew addresses over time. Stateful configuration is more
complex as it requires the presence of external databases and networks administrators, but in
Page 58 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
general it provides all the functionality that stateless autoconfiguration is not able to provide
(authentication, options, access control, etc.).
2.6.3. DHCP for IPv6
As in the DHCPv4 case, the Dynamic Host Configuration Protocol for IPv6 (DHCPv6) is an
UDP protocol that enables DHCP servers to pass configuration parameters such as IPv6
network addresses to IPv6 nodes.
In IPv6 it is commonly used to avoid management tasks such as service configurations in
hosts that cannot be offered by the stateless autoconfiguration. As we have seen, DHCPv6 is
the stateful counterpart to stateless autoconfiguration. Note that both stateful and stateless
autoconfiguration can be used concurrently in the same environment, leveraging the strengths
of both mechanisms in order to reduce the cost of ownership and management of network
nodes.
The main difference between DHCPv4 and DHCPv6 is that the DHCPv6 is not BOOTP
compatible and all broadcast traffic is moved to multicast groups.
In the IPv6 network the host has always a link-local address. This of course means that there
are many addresses linked to any given network connector. The function of the DHCPv6 is
shifting towards higher-level protocol configurations as the network protocols take care of the
basic connection parameters.
Other major difference is that clients are expected to listen to the UDP port number 546 to be
able to change their network configurations if the administrators request it.
2.6.4. Applicable Standards and Issues
DHCP for IPv6 standard is currently being defined in the DHC IETF working group [1]. The
standardization work is still far from being finished, and this ongoing work is still in form of
an Internet Draft (draft-ietf-dhc-dhcpv6-22.txt) from December 21 2001. Although this draft
is close to be a final call for becoming an IETF RFC, still several issues are raised regarding
the need of the use of such a complex protocol in IPv6.
Specifically, there is a controversial discussion about service discovery and DHCPv6 in the
IPNG WG. DHCP detractors argument that DHCP, and in general any stateful configuration,
places an unnecessary middle-stage in the service discovery and autoconfiguration
functionality. The use of a middleware may provoke inconsistencies in the server databases
and thus erroneous configuration may be offered to clients. They claim that IPv6 address
configuration is already covered by the stateless IPv6 address configuration, and that service
discovery (e. g. see [D-ADNSv6]) may make use of existing and powerful IPv6 tools such as
anycast messages (for example querying to the all_available_dns anycast address). The use of
this anycast address will provide the client with an easy way of locating services, and it is
clear that querying the appropriate server itself is safer than placing an intermediate database,
that has to be actualized with the corresponding burden that this suppose in the network.
This all-stateless configuration solution still presents some caveats. It relies in the state of the
anycast implementation, which is still far from being stable. It is also said that it forces the use
of a well-known (anycast) address that has to be configured manually on the clients, although
we believe that this is not a real problem. The most clear attack against the use of the totalstateless configuration and to the use of DHCPv6 is that the former is not enough for the
complexity that autoconfiguration requires. As new services appear more and more code has
Page 59 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
to be introduced in clients, while DHCPv6 protocol is designed to cope with any possible
extension that may be introduced in the near future.
In any case, it is very likely that both approaches will live together as they are both designed
to cohabit without major problems in the same client.
2.6.5. Known DHCPv6 Implementations
Despite of the need of a DHCP protocol in IPv6, little effort has been applied so far in the
provision of implementations of the protocol for the most commonly used operating systems.
This lack of implementation is the result of the immatureness of the definition and the on
going discussions to get a consensus in this matter. We have produced a list of the status of
the implementations of DHCP for IPv6 in the most common platforms:
Linux: we have tried the Ralph Meyer’s implementation for Linux [DHCPv6Lx] . The code
is in a very alpha state, and needs a bit of code hacking just to be compiled, so it is still not
appropriate for a production network. Moreover the functionality is severely reduced, and it is
only able to provide the IP address to the given host, unlike the common IPv4 functionality Domain Name Server address, default gateway address, and more. This lack of functionality
prevents it for being used in the same way that the DHCP for IPv4 is usually configured
(providing more information that just an IP address). We provide some feedback and tips on
this implementation in section 4.
*BSD: The [WIDE]
project provides a DHCP for IPv6 implementation for the [KAME]
stack, for *BSD operating systems. The KAME stack usually provides good implementations
as they are maintained by a group of people instead of individuals; this implementation does
not provide to hosts IPv6 address nor gateway, but only DNS server. We have tested this
implementation in detail. Results from the tests can be found also in section 4.
Dhawal Kumar published a DHCPv6 implementation for the INRIA IPv6 *BSD stack in
1999. A more mature implementation is the one from Yunzhou (for NetBSD systems), but as
in the Linux case it only provides the client with an IP address, still lacking of other
parameters configurations such the DNS server IP or the gateway address.
Solaris: Sun Solaris OS does not provide any implementation of the DHCPv6 protocol. A
possible solution is the use of BSD (and maybe Linux) implementations, as they use to be
easily compiled and configured on many other UNIX-like systems.
Windows: As in the Solaris case, Windows IPv6 implementation does not provide DHCPv6
support in neither of its IPv6 stacks: Microsoft Server .NET implementation, Windows XP,
Microsoft IPv6 Technology Preview and Microsoft Research Internet Protocol Version 6. It is
expected to be included in the near future.
Cisco: Cisco routers do not provide DHCP for its IPv6 implementation for it is not actually
needed at the layer that routers understand (layer three). That is, IP addresses, gateway and so
on are set by the Router Advertisement message. DHCPv6 seems not to be included in Cisco
IOS, not even in Phase III where other advanced capabilities such as QoS will be added.
Page 60 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Summarizing, none of the more usual operating systems provide a full implementation of the
DHCP protocol for IPv6 (neither client nor server). Developers and network companies are
waiting for a complete specification from the IETF, and only free software (because of its
researching nature) is putting some effort in making it available.
2.6.6. Applications Scenarios
We propose the following recommendations for the transition scenarios we may encounter in
the near future:
·
IPv4 only hosts: the use DHCPv4 is commonly extended and working fine. It is
highly recommended, as IPv4 does not include in the protocol itself any
autoconfiguration facility.
·
IPv6/IPv4 hosts: we recommend the use DHCPv4 for IPv4, as IPv4 does not have
any stateless configuration mechanism. For IPv6 the best option is the use of
stateless autoconfiguration for the IPv6/prefix and gateway address, and maybe
relaying on IPv6 enabled DHCPv4 servers, at least to provide DNS server
addresses. If using *BSD as DHCPv6 server and as host, we may also use
DHCPv6 the Domain Name Server address (see how to below).
·
IPv6 only hosts: are supposed to be uncommon enough such as to be manually
configured if needed. Stateless autoconfiguration is used to set the IPv6 address
and gateway, but Domain Name Server has to be manually configured until
DHCPv6 implementations support this option, or new service discovery solutions
are put in place. As commented before, in the particular case of *BSD, the given
DHCPv6 implementation can be used to provide the DNS information but this is
not automatic and the implementation is still immature.
2.7. QoS – Differentiated Services
This section is devoted to introduce the technologies for QoS provisioning that will be used in
LONG tests. Though the Intserv architecture (e.g. RSVP) has received some attention in the
past, it seems to be loosing interest in the networking community when compared to the
Diffserv architecture. This latter architecture tries to solve the scalability problems that
appeared in Intserv due to state maintenance in all the equipment involved in an end-to-end
communication. The Diffserv architecture [RFC 2475] tries to offer QoS to aggregates of
flows with similar requirements and not to host-to-host application flows (which is the case
for Intserv). Therefore, service differentiation provides a coarser granularity, but the
management and configuration burden are remarkably reduced. These are the reasons why the
QoS tests will focus on the Diffserv architecture.
As far as we know, there is no difference in the conceptual framework of the Diffserv
architecture when IPv4 or IPv6 are considered. The functionality of the mechanisms
implemented to classify, shape, meter, mark, drop, and schedule are the same for both
protocols. Thus, all the documents that define the theoretical framework of the diffserv
Page 61 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
architecture may be understood the same way for both protocols. Therefore, the following
section is devoted to briefly describe the diffserv architecture.
2.7.1. Diffserv architecture
The diffserv architecture is explained in [RFC2475]. This section is mostly based on that and
other IETF documents related to diffserv and produced by the diffserv working group
[DSWG].
The goal of the diffserv architecture is to provide scalable service differentiation in the
Internet. And, unlike in the Intserv model, this service differentiation is applied to aggregates
rather than application-to-application flows.
Another important characteristic is that no per-flow state is stored in the routers along the path
of the flow. This frees the core routers from the complexity of managing a huge amount of
flow information. In fact, the complexity of the architecture is moved to the less-loaded border
routers, which are in charge of the traffic classification and marking. These operations are
based on multiple fields of the IP header (e.g. source/destination address and/or port, TOS or
traffic class field). Once the traffic is marked, the core routers inside a diffserv domain take
their forwarding decisions based on just the code put in the IP header by the ingress router.
This code travels in the TOS field for IPv4 packets or the in the Traffic Class field for IPv6
packets, but according to [RFC2474] there is no difference in the values assigned for the same
services for IPv4 and IPv6.
The requirements may be specified in a quantitative or statistical way in terms of throughput,
delay, jitter and/or loss, or may be specified in terms of some relative priority of access to
network resources.
Up to know, the aggregates may receive one of the following services:
·
Expedited forwarding, which emulates leased line services
·
Assured forwarding, which provides a service equivalent to a lightly loaded network,
even when lower priority traffic is experiencing congestion
·
Best-effort, which is the default service when no QoS requirements are specified for a
given aggregate.
Other services or modifications of the previous ones are being considered but they did not yet
obtain the RFC status.
2.7.1.1. Diffserv architecture concepts
Before describing the components that allow the provisioning of service differentiation, let us
introduce some concepts that will help in explaining the framework of the diffserv
philosophy.
Per-Hop-Behavior (PHB)
According to [RFC2475], “a per-hop-behavior (PHB) is a description of the externally
observable forwarding behavior of a DS node applied to a particular aggregate.” In some way,
the PHB may understood as the description of the treatment that an aggregate must receive in
a given node. Therefore, the concatenation of the treatments at each node along the path, if
defined in a coherent way, provides the QoS for that aggregate inside a given diffserv domain
Page 62 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
(i.e. a diffserv network controlled by a unique administrator). For paths traversing more
domains, there must be a contract at each boundary to define how services from the upstream
domain map to those offered by the downstream domain. This contract is called Service Level
Agreement (see below).
Each PHB is assigned a code, which differentiates one PHB from the rest. This code is called
the differentiated services code point (DSCP) and is carried in the TOS field in IPv4 and the
Traffic Class field in IPv6. Therefore, for both network level protocols the field is organized
as in the following figure.
DSCP
0
1
2
3
CU
4
5
6
7
Figure 35 - Differentiated Services (DS) field (DSCP=Differentiated Services CodePoint,
CU= Currently Unused)
Apart from the services described above (expedited (RFC 2598), assured (RFC 2597), and
default [RFC2474]) which correspond to a PHB each, there is another PHB defined for
backward compatibility reasons with routers using IP precedence as defined in RFC 791 and
RFC 1812. It is called the class selector PHB [RFC 2474].
Service Level Agreement (SLA)
It is a service contract between a customer (be it an end customer or an upstream diffserv
domain) and the diffserv provider. It specifies how the upstream traffic will be treated in the
downstream domain. In the case of inter-domain traffic it specifies how upstream PHBs are
mapped to downstream PHBs so as to offer an end-to-end service differentiation. It may also
include traffic conditioning rules for the incoming traffic, i.e. how incoming traffic is treated
when it is conformant and when it is not. All these rules which define how to carry out the
metering, shaping, dropping and marking are known as Traffic Conditioning Agreement
(TCA).
Mechanism
It is important to separate the concepts introduced above from the particular implementations
of queuing, scheduling algorithms, etc. used to offer them. We refer to these implementations
as mechanisms. In fact, different mechanisms may be used to offer the same PHB.
2.7.1.2. Diffserv architecture components
The services and contracts explained above are implemented in the routers with a series of
components which are described in the following paragraphs. The general scheme of a
diffserv router is represented in [PEREZ].
Page 63 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Traffic
Classifier
Traffic
Conditioner
Forwarding
Classifier
Scheduler
Input interface
Output transmission
queue
Output interface
Figure 36 - Diffserv router building blocks
Traffic Classifier
The classifier is in charge of deciding what treatment will receive any given packet traversing
the current node or entering a diffserv domain. This result of this operation will determine the
PHB to which this packet belongs.
Figure 36 shows the architecture of a border router. Usually, border routers are more complex
than interior routers because multi-field traffic classification operations are carried out there.
In this case, multi-field means that packets are assigned a different DSCP based on one or
more of the following fields in the IP header: source address, destination address, source port,
destination port, protocol ID, and/or DSCP.
On the other hand, interior routers are simpler because all their forwarding decisions are just
based on the DSCP field, which has been filled in at the ingress router. Therefore, single-field
traffic classification is implemented.
Traffic Conditioner
The traffic conditioner (Figure 37) groups a series of blocks represented in the following
figure (meter, marker, shaper, and dropper). Though the classifier is not a component of the
traffic conditioner it is also presented to show the relationship among both.
Meter
Traffic
classifier
Marker
Shaper/
Dropper
Figure 37 Interaction among the Traffic Conditioner and the Traffic Classifier.
The meter is in charge of determining whether the packets belonging to a stream (after being
classified by the classifier) is in- or out-of-profile according to the contracts defined with the
customer. The results of the metering process will affect the way the packet will be marked,
shaped or dropped. The influence of the meter over the rest of the blocks is represented in the
figure.
The marker is in charge of setting the DSCP of the packet according to what the meter
measured. As stated above, the DSCP value determines the PHB to which the packet belongs,
and thus, the treatment it will receive from the diffserv domain it just entered. For interdiffserv-domain communications, the marker is also in charge of remarking the packets in
Page 64 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
case a packet should be demoted if it is out-of-profile. This is an alternative solution to
dropping (see below).
Packets being out-of-profile according to the contract may be shaped or dropped depending on
the design decisions for that PHB. Shapers introduce some delay to some or all packets to
make them compliant with the contract. On the other hand, droppers discard packets that are
not compliant. But remark that the goal is the same, that is, to make the packet stream comply
with the contract.
Forwarding
After classifying the packet, the router decides the output interface to which the packet will be
sent. This is the function of the forwarding module.
Scheduling
Once in the output interface, the packet enters the scheduler, that also has a classifier. Thus, it
is classified according to the DSCP it carries and stored in one from a set of queues. Each
queue is assigned a different priority depending on the configuration of the scheduling
mechanism, which will offer a given PHB. As stated in previous sections, a given PHB is not
bound to only one scheduling mechanism. The choice of the mechanism to implement a given
PHB depends on the administrator. Some of the mechanisms that may be considered are:
Class-Based Queueing (CBQ), Weighted Fair Queuing (WFQ), Priority Queueing, and
Hierarchical Fair Service Curve (HFSC). There are also other less common mechanisms.
2.7.2. IPv6 Diffserv implementations
This section describes the information on IPv6 and Diffserv available for the most common
platforms the partners of the LONG project have in their premises:
·
Cisco. Their statement of direction published in 2001 claims that IPv6 QoS
(classification, policing, DSCP marking/remarking, queueing) is planned for Phase III
software deployment, which corresponds to 2002.
·
FreeBSD. This platform seems to be the most promising one for diffserv over IPv6
testing in the short term. There is a software package called Alternate Queueing
(ALTQ) for BSD UNIX that includes CBQ, HFSC, PRIQ, WFQ, RED, RIO, and Blue
mechanisms. FreeBSD4.2 supports both IPv6 and ALTQ together. However there are
some points still missing including flowlabel and the implementation of a traffic class
API. This latter points are scheduled to be finished before the end of 2002 in project
Kame (www.kame.net).
·
Windows 2000. The Microsoft Research IPv6 (MSRIPv6) stack supports some
transition mechanisms but it does not seem to support any diffserv features yet.
·
Linux. It does not seem to support any diffserv functionality as such. A further study
of the netfilter and tc tools from the iproute2 package (for kernels 2.4 and above) may
help in determining if some diffserv-like service could be offered.
Therefore, the most likely implementation to be used in the diffserv tests is ALTQ - FreeBSD.
Page 65 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
There are other IPv6 diffserv commercial implementations in some routers from 6WIND
(www.6wind.com), Hitachi (www.internetworking.hitachi.com), and Thomson-CSF
(www.thomson-csf.com).
2.7.3. Diffserv in transition scenarios
The final step in the transition to IPv6 is an all IPv6 network. As there is no difference among
IPv4 and IPv6 as far as the diffserv functionality is concerned, the same kind of services that
are being currently offered in diffserv networks may be planned for IPv6.
But before attaining a fully IPv6 scenario, the usual case will be a network using both IPv4
and IPv6. The possible scenarios during the transition were described in previous deliverables.
From all those scenarios, two main groups may be considered as far as diffserv is concerned.
The first one involves translation mechanisms. In this case, there are two clouds (one IPv6 and
one IPv4) that communicate through the translator. Therefore, if end-to-end QoS is offered,
diffserv routers are required in the IPv4 cloud that will use the TOS field and diffserv routers
are also required in the IPv6 cloud that will use the traffic class field. Besides, the machine
acting as translator should map the TOS field to the traffic class field and viceversa. Apart
from that, it should also carry out the functions assigned to border routers if both clouds are
two distinct diffserv domains.
The second generic scenario corresponds to the tunneling case. Though there are transition
mechanisms that tunnel IPv4 packets into IPv6, the most usual case would be IPv6 over IPv4
tunnels. In this case, one possible scenario could be the one presented in Figure 38.
Sender
Flow 2
Receiver
IPv6 over IPv4 tunnel
Router B
Router A
Router C
Flow 1
Sender
Receiver
Figure 38 - Tunneling transition scenario
There is one main issue to solve, that is, how packets travelling through the tunnel are given
the treatment they require if intermediate routers that handle the tunnel just take care of the
outer IP header and not the header of the tunneled packet. This topic is dealt with in
[RFC2983]. Besides, recall that, in the scenario we are discussing, the inner packet is an IPv6
one and the outer packet is an IPv4 one, that is, they carry the DSCP in different fields.
Anyway, this scenario could help in benefiting from the current implementations of IPv4
diffserv while the IPv6 ones are not available, as is the case for most of the platforms (see
implementations section above).
Page 66 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.7.4. IPv6 Diffserv configuration
As stated above, the only platform available to LONG partners that at the same time supports
differentiated services in IPv6 is FreeBSD with the ALTQ [ALTQ].This section is devoted to
explain how to configure the ALTQ package in a PC running FreeBSD 4.3.
Though there are two methods we used the second one. According to the readme installation
files in the ALTQ package, the steps we followed to install and run it are described below.
2.7.4.1. Start.
Downloading the ALTQ program files from these urls
ALTQ v3.0 (sources) - ftp://ftp.csl.sony.co.jp/pub/kjc/altq-3.0.tar.gz
ALTQ v3.0 (patch) - ftp://ftp.csl.sony.co.jp/pub/kjc/altq-3.0-sys-altq-freebsd-4.3.patch
Presuming you installed the kernel sources in /usr/src directory
# cd /usr/src
unpackage the archive
# gzip -d altq-3.0.tar.gz
# tar -xvf altq-3.0.tar
Rename the new patch for freebsd 4.3
# cp altq-3.0-sys-altq-freebsd-4.3.patch altq-3.0/sys-altq/sys-altq-freebsd-4.3.patch
Patch the kernel and altq src (a backup is made). It helps if you have done a 'make clean'
recently (optional).
# mkdir sys-altq
# cd sys
# tar cvf - . | (cd ../sys-altq; tar xf -)
# cd /usr/src/sys-altq
2.7.4.2. Making ALTQ-kernel.
Applying the patch to the kernel source tree and make a new kernel.
The kernel patch only contains modifications to the existing source files.
The altq original files are provided in the separate directory.
Apply the altq kernel patch to the kernel source
# patch -p < ALTQ_DIST/sys-altq/sys-altq-OSTYPE-X.X.patch
Here "ALTQ_DIST" is the altq distribution directory
Page 67 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Copy the altq files to "sys-altq/altq" directory.
# mkdir altq
# cp ALTQ_DIST/sys-altq/altq/* altq/
If your kernel version is not supported (e.g., -stable): Try one of the patches close to your
version. The "patch" command might fail to patch some files. You can find the failed files by
# find . -name "*.rej" -print
You also need to edit the ALTQ kernel config file that is for the original version.
Make and install the new kernel.
# cd i386/conf
# config ALTQ
# cd ../../compile/ALTQ
# make depend
# make clean
# make
# make install
# shutdown -r now
You might need to uncommnet "options ALTQ_NOPCC" in the config file if your machine is
386/486 (non-pentium) CPUs which don't have TSC, or SMP (by default, ALTQ uses
processor cycle counter, Pentium TSC on i386 and PCC on alpha, for measuring time.)
For FreeBSD, the default configuration includes no queueing discipline but disciplines can be
loaded at run time using KLD.
Disciplines can also be built-in by specifying them in the kernel configuration
file.(uncomment options in the ALTQ kernel config file.)
Making (or re-making) altq devices
# cd ALTQ_DIST
# sh MAKEDEV.altq all
the altq major device numbers for FreeBSD is 96. this is the official number from FreeBSD.
(the device major number is defined in sys-altq/altq/altq_conf.c.)
Loading altq queueing desciplines (for FreeBSD)
The altq kernel modules are automatically built and installed as part of the kernel build/install.
To manually make the altq KLD modules:
Page 68 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
# cd /usr/src/sys-altq/modules/altq
# make
# make install
The modules are installed in the "/modules" directory. The altq modules have names starting
with "altq_" (e.g., altq_cbq.ko).
altqd(8) tries to load required modules automatically so that you do not need to "kldload"
modules explicitly.
In case you want to manipulate the modules by hand,
To load a module:
# kldload altq_cbq
To check the loaded modules:
# kldstat -v
To unload a module:
# kldunload altq_cbq
2.7.4.3. Configuration file samples for loopback interface (/etc/altq.conf)
CBQ (TCP-UDP +IPv6)
To setup the interface lo0 (loopback) a bandwidth in bits per second of 5 Mbps with queueing
discipline cbq:
interface lo0 bandwidth 5M cbq
The following command specifies a packet scheduling class for CBQ named "root_class" with
percentage of the interface bandwidth allocated of 100 percent
class cbq lo0 root_class NULL pbandwidth 100
The next one, specifies a packet scheduling class for CBQ named "def_class" with parent
name "borrow" with percentage of the interface bandwidth allocated of 95 percent - default
class (all no matching are allocated here)
class cbq lo0 def_class root_class borrow pbandwidth 95 default
Page 69 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The following one, specifies a packet scheduling class for CBQ named "tcp_class" with parent
name "def_class" with percentage of the interface bandwidth allocated of 10 percent
class cbq lo0 tcp_class def_class pbandwidth 10
The next one, specifies a filter to classify packets into scheduling class "tcp_class".
filter_value = (dst_addr, dport, src_addr, sport, proto) 0 is taken as a wildcard (6 TCP)
filter lo0 tcp_class 0 0 0 0 6
To specify a packet scheduling class for CBQ named "udp_class" with parent name
"def_class" with percentage of the interface bandwidth allocated of 10 percent:
class cbq lo0 udp_class def_class pbandwidth 10
To specify a filter to classify packets into scheduling class "udp_class". filter_value =
(dst_addr, dport, src_addr, sport, proto) 0 is taken as a wildcard (17 UDP)
filter lo0 udp_class 0 0 0 0 17
Filters for ipv6
filter6 lo0 tcp_class ::0 0 ::0 0 6
filter6 lo0 udp_class ::0 0 ::0 0 17
HFSC (TCP-UDP)
Setup for the interface lo0 (loopback) a bandwidth in bits per second of 5 Mbps with queueing
discipline hfsc
interface lo0 bandwidth 5M hfsc
Specifies a packet scheduling class for HFSC named "def_class" 50% of the excess bandwidth
goes to this class
class hfsc lo0 def_class root pshare 50 default
Page 70 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Specifies a packet scheduling class for HFSC named "tcp_class" with Guaranteed rate of
10Mbps (no excess bandwidth assigned); this specifies a linear real-time service
class hfsc lo0 tcp_class root grate 10M
Specifies a filter to classify packets into scheduling class "tcp_class". filter_value = (dst_addr,
dport, src_addr, sport, proto) 0 is taken as a wildcard, (6 TCP)
filter lo0 tcp_class 0 0 0 0 6
Specifies a packet scheduling class for HFSC named "udp_class" with Guaranteed rate of
5Mbps (no excess bandwidth assigned); this specifies a linear real-time service.
class hfsc lo0 udp_class root grate 5M
Specifies a filter to classify packets into scheduling class "udp_class". filter_value =
(dst_addr, dport, src_addr, sport, proto) 0 is taken as a wildcard, (17 UDP)
filter lo0 udp_class 0 0 0 0 17
2.8. Security
2.8.1. Introduction
Security on the Internet is an old problem. Throughout the years people have been trying to
solve or at least minimize this problem with the creation of add-ons (both software and
hardware) that would work over IPv4 stack (SSL is such an add-on).
IPv6 was developed during this times of concern and as a result security provisions were
included into the protocol. However these provisions do not provide security by themselves
and an extra set of protocols had to be created to provide security. The end result of this work
is IPsec, which will be described below.
IPsec is not only a protocol but also a group of protocols that can not only fit into IPv6 but can
also be used on IPv4 guaranteeing a good level of interoperability between both IP versions.
On this document we describe IPsec (the all suite of protocols), show some of its possible
application scenarios and talk a bit about future developments.
2.8.2. A bit of history
The current version of IPsec (the all suite of protocols) was published in November of 1998
(RFCs 2401-2412). This version is an improved version of the first witch was introduced in
August of 1995 (RFCs 1825-1829).
Page 71 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The major differences that were introduced into this second version are protocol clarifications
and small improvements. The clarifications were needed because some aspects of the first
version were not clearly defined and as result there were several implementations of the
protocols, which were incompatible.
The improvements are mainly related with small security corrections and other minimal
problems with the initial specification.
As
usual
IPsec
is
a
work
in
progress
(as
can
be
seen
at
http://www.ietf.org/html.charters/IPsec-charter.html) and as such some modifications to this
second version have already been published.
2.8.3. IPsec
2.8.3.1. IPsec goals
IPsec is designed to provide interoperable, high quality, cryptographically based security for
IPv4 and IPv6 (in this document IPv4 will only be mentioned when strictly needed, since the
focus is IPv6). The set of security services offered includes access control, connectionless
integrity, data origin authentication, protection against replays (a form of partial sequence
integrity), confidentiality (encryption) and limited traffic flow confidentiality. These services
are provided at the IP layer, offering protection for IP and/or upper layer protocols.
These objectives are met through the use of two traffic security protocols, the Authentication
Header (AH) and the Encapsulating Security Payload (ESP), and through the use of
cryptographic key management procedures and protocols. The set of IPEC protocols employed
in any context, and the ways in which they are employed, will be determined by the security
and system requirements of users, applications, and/or sites/organizations.
When these mechanisms are correctly implemented and deployed, they ought not to adversely
affect users, hosts, and other Internet components that do not employ these security
mechanisms for protection of their traffic. These mechanisms are also designed to be
algorithm-independent. This modularity permits selection of different sets of algorithms
without affecting the other parts of the implementation. For example, different user
communities may select different sets of algorithms if required.
A standard set of default algorithms is specified to facilitate interoperability in the global
Internet. The use of these algorithms, in conjunction with IPsec traffic protection and key
management protocols, is intended to permit system and application developers to deploy high
quality, Internet layer, and cryptographic security technology.
2.8.3.2. IPsec Overview
This section provides a high level description of how IPsec works, the components of the
system, and how they fit together to provide the security services noted above. The goal of this
description is to enable the reader to “picture” the overall process/system, see how it fits into
the IP environment, and to provide context for later sections of this document, which describe
each of the components in more detail.
An IPsec implementation operates in a host or a security gateway environment, affording
protection to IP traffic. The protection offered is based on requirements defined by a Security
Policy Database (SPD) established and maintained by a user or system administrator, or by an
application operating within constraints established by either of the above. In general, packets
Page 72 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
are selected for one of three processing modes based on IP and transport layer header
information matched against entries in the database (SPD). Each packet is either afforded
IPsec security services, discarded, or allowed to bypass IPsec, based on the applicable
database policies identified by the Selectors.
What IPsec Does?
IPsec provides security services at the IP layer by enabling a system to select required security
protocols, determine the algorithm(s) to use for the service(s), and put in place any
cryptographic keys required to provide the requested services. IPsec can be used to protect one
or more “paths” between a pair of hosts, between a pair of security gateways, or between a
security gateway and a host. (The term “security gateway” is used throughout the IPsec
documents to refer to an intermediate system that implement IPsec protocols. For example, a
router or a firewall implementing IPsec is a security gateway.)
The set of security services that IPsec can provide includes access control, connectionless
integrity, data origin authentication, rejection of replayed packets (a form of partial sequence
integrity), confidentiality (encryption) and limited traffic flow confidentiality. Because these
services are provided at the IP layer, they can be used by any higher layer protocol, e.g., TCP,
UDP, ICMP, BGP, etc.
The IPsec DOI also supports negotiation of IP compression, motivated in part by the
observation that when encryption is employed within IPsec, it prevents effective compression
by lower protocol layers.
How IPsec Works ?
IPsec uses two protocols to provide traffic security: Authentication Header (AH) and
Encapsulating Security Payload (ESP).
The IP Authentication Header (AH) provides connectionless integrity, data origin
authentication, and an optional anti-replay service.
The Encapsulating Security Payload (ESP) protocol may provide confidentiality
(encryption), and limited traffic flow confidentiality. It also may provide connectionless
integrity, data origin authentication, and an anti-replay service. (One or the other set of these
security services must be applied whenever ESP is invoked.)
Both AH and ESP are vehicles for access control, based on the distribution of
cryptographic keys and the management of traffic flows relative to these security protocols.
These protocols may be applied alone or in combination with each other to provide a desired
set of security services in IPv4 and IPv6.
Each protocol supports two modes of use: transport mode and tunnel mode. In transport mode
the protocols provide protection primarily for upper layer protocols; in tunnel mode, the
protocols are applied to tunneled IP packets. The differences between the two modes are
discussed below.
IPsec allows the user (or system administrator) to control the granularity at which a security
service is offered. For example, one can create a single encrypted tunnel to carry all the traffic
between two security gateways or a separate encrypted tunnel can be created for each TCP
connection between each pair of hosts communicating across these gateways. IPsec
management must incorporate facilities for specifying:
Page 73 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
Which security services to use and in what combinations
·
The granularity at which a given security protection should be applied
·
The algorithms used to effect cryptographic-based security
Because these security services use shared secret values (cryptographic keys), IPsec relies on a
separate set of mechanisms for putting these keys in place. (The keys are used for
authentication/integrity and encryption services.) This document requires support for both
manual and automatic distribution of keys. It specifies a specific public-key based approach
(IKE, described in Section 2.8.9) for automatic key management, but other automated key
distribution techniques may be used. For example, KDC-based systems such as Kerberos and
other public-key systems such as SKIP could be employed.
Where IPsec May Be Implemented ?
There are several ways in which IPsec may be implemented in a host or in conjunction with a
router or firewall (to create a security gateway). Several common examples are provided
below:
·
Integration of IPsec into the native IP implementation. This requires access to the IP
source code and is applicable to both hosts and security gateways.
·
“Bump-in-the-stack” (BITS) implementations, where IPsec is implemented
“underneath” an existing implementation of an IP protocol stack, between the native
IP and the local network drivers. Source code access for the IP stack is not required in
this context, making this implementation approach appropriate for use with legacy
systems. This approach, when it is adopted, is usually employed in hosts.
·
The use of an outboard crypto processor is a common design feature of network
security systems used by the military, and of some commercial systems as well. It is
sometimes referred to as a “Bump-in-the-wire” (BITW) implementation. Such
implementations may be designed to serve either a host or a gateway (or both). Usually
the BITW device is IP addressable. When supporting a single host, it may be quite
analogous to a BITS implementation, but in supporting a router or firewall, it must
operate like a security gateway.
2.8.4. Security Associations
This section defines Security Association management requirements for all IPv6
implementations that implement AH, ESP, or both. The concept of a “Security Association”
(SA) is fundamental to IPsec. Both AH and ESP make use of SAs and a major function of
IKE is the establishment and maintenance of Security Associations. All implementations of
AH or ESP must support the concept of a Security Association as described below. The
remainder of this section describes various aspects of Security Association management,
defining required characteristics for SA policy management, traffic processing, and SA
management techniques.
Definition and Scope
A Security Association (SA) is a simplex “connection” that affords security services to the
traffic carried by it. Security services are afforded to an SA by the use of AH, or ESP, but not
both. If both AH and ESP protection is applied to a traffic stream, then two (or more) SAs are
Page 74 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
created to afford protection to the traffic stream. To secure typical, bi-directional
communication between two hosts, or between two security gateways, two Security
Associations (one in each direction) are required.
A security association is uniquely identified by a triple consisting of a Security Parameter
Index, an IP Destination Address, and a security protocol (AH or ESP) identifier. In principle,
the Destination Address may be a unicast address; an IP broadcast address, or a multicast
group address. However, IPsec SA management mechanisms currently are defined only for
unicast SAs. Hence, in the discussions that follow, SAs will be described in the context of
point-to-point communication, even though the concept is applicable in the point-tomultipoint case as well.
As noted above, two types of SAs are defined: transport mode and tunnel mode. A transport
mode SA is a security association between two hosts. In IPv6, the security protocol header
appears after the base IP header and extensions, but may appear before or after destination
options, and before higher layer protocols. In the case of ESP, a transport mode SA provides
security services only for these higher layer protocols, not for the IP header or any extension
headers preceding the ESP header. In the case of AH, the protection is also extended to
selected portions of the IP header, selected portions of extension headers, and selected options
(contained in the IPv6 Hop-by-Hop extension header, or IPv6 Destination extension headers).
For more details on the coverage afforded by AH, see the AH specification below.
A tunnel mode SA is essentially an SA applied to an IP tunnel. Whenever either end of a
security association is a security gateway, the SA must be tunnel mode. Thus an SA between
two security gateways is always a tunnel mode SA, as is an SA between a host and a security
gateway. Note that for the case where traffic is destined for a security gateway, e.g., SNMP
commands, the security gateway is acting as a host and transport mode is allowed. But in that
case, the security gateway is not acting as a gateway, i.e., not transiting traffic. Two hosts may
establish a tunnel mode SA between themselves. The requirement for any (transit traffic) SA
involving a security gateway to be a tunnel SA arises due to the need to avoid potential
problems with regard to fragmentation and reassembly of IPsec packets, and in circumstances
where multiple paths (e.g., via different security gateways) exist to the same destination
behind the security gateways.
For a tunnel mode SA, there is an “outer” IP header that specifies the IPsec processing
destination, plus an “inner” IP header that specifies the (apparently) ultimate destination for
the packet. The security protocol header appears after the outer IP header, and before the inner
IP header. If AH is employed in tunnel mode, portions of the outer IP header are afforded
protection (as above), as well as all of the tunneled IP packet (i.e., all of the inner IP header is
protected, as well as higher layer protocols). If ESP is employed, the protection is afforded
only to the tunneled packet, not to the outer header.
In summary,
·
A host must support both transport and tunnel mode.
·
A security gateway is required to support only tunnel mode. If it supports transport
mode, that should be used only when the security gateway is acting as a host, e.g., for
network management.
Security Association Functionality
Page 75 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The set of security services offered by an SA depends on the security protocol selected, the SA
mode, the endpoints of the SA, and on the election of optional services within the protocol.
For example, AH provides data origin authentication and connectionless integrity for IP
datagrams (hereafter referred to as just “authentication”). The “precision” of the
authentication service is a function of the granularity of the security association with which
AH is employed, as discussed below (Selectors ).
AH also offers an anti-replay (partial sequence integrity) service at the discretion of the
receiver, to help counter denial of service attacks. AH is an appropriate protocol to employ
when confidentiality is not required (or is not permitted, e.g., due to government restrictions
on use of encryption). AH also provides authentication for selected portions of the IP header,
which may be necessary in some contexts. For example, if the integrity of an IPv6 extension
header must be protected en route between sender and receiver, AH can provide this service
(except for the non-predictable but mutable parts of the IP header.)
ESP optionally provides confidentiality for traffic. (The strength of the confidentiality service
depends in part, on the encryption algorithm employed.) ESP also may optionally provide
authentication (as defined above). If authentication is negotiated for an ESP SA, the receiver
also may elect to enforce an anti-replay service with the same features as the AH anti-replay
service. The scope of the authentication offered by ESP is narrower than for AH, i.e., the IP
header(s) “outside” the ESP header is (are) not protected. If only the upper layer protocols
need to be authenticated, then ESP authentication is an appropriate choice and is more space
efficient than use of AH encapsulating ESP. Note that although both confidentiality and
authentication are optional, they cannot both be omitted. At least one of them must be
selected.
If confidentiality service is selected, then an ESP (tunnel mode) SA between two security
gateways can offer partial traffic flow confidentiality. The use of tunnel mode allows the inner
IP headers to be encrypted, concealing the identities of the (ultimate) traffic source and
destination. Moreover, ESP payload padding also can be invoked to hide the size of the
packets, further concealing the external characteristics of the traffic. Similar traffic flow
confidentiality services may be offered when a mobile user is assigned a dynamic IP address
in a dialup context, and establishes an (tunnel mode) ESP SA to a corporate firewall (acting as
a security gateway). Note that fine granularity SAs generally are more vulnerable to traffic
analysis than coarse granularity ones which are carrying traffic from many subscribers.
Combining Security Associations
The IP datagrams transmitted over an individual SA are afforded protection by exactly one
security protocol, either AH or ESP, but not both. Sometimes a security policy may call for a
combination of services for a particular traffic flow that is not achievable with a single SA. In
such instances it will be necessary to employ multiple SAs to implement the required security
policy. The term “security association bundle” or “SA bundle” is applied to a sequence of SAs
through which traffic must be processed to satisfy a security policy. The order of the sequence
is defined by the policy. (Note that the SAs that comprise a bundle may terminate at different
endpoints. For example, one SA may extend between a mobile host and a security gateway
and a second, nested SA may extend to a host behind the gateway.)
Security associations may be combined into bundles in two ways: transport adjacency and
iterated tunneling.
Page 76 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
Transport adjacency refers to applying more than one security protocol to the same IP
datagram, without invoking tunneling. This approach to combining AH and ESP
allows for only one level of combination; further nesting yields no added benefit
(assuming use of adequately strong algorithms in each protocol) since the processing is
performed at one IPsec instance at the (ultimate) destination.
Internet
Security
Gateway 2 Host 2
Security
Gateway 1
Host 1
Security Association 1 (ESP transport)
Security Association 2 (AH transport)
Figure 39 – Transport Adjacency
1. Iterated tunneling refers to the application of multiple layers of security protocols
effected through IP tunneling. This approach allows for multiple levels of nesting,
since each tunnel can originate or terminate at a different IPsec site along the path. No
special treatment is expected for ISAKMP traffic at intermediate security gateways
other than what can be specified through appropriate SPD entries.
There are 3 basic cases of iterated tunneling -- support is required only for cases 2 and 3.:
1) Both endpoints for the SAs are the same -- The inner and outer tunnels could
each be either AH or ESP, though it is unlikely that Host 1 would specify both
to be the same, i.e., AH inside of AH or ESP inside of ESP.
Internet
Host 1
Security
Gateway 1
Security
Gateway 2 Host 2
Security Association 1 (tunnel)
Security Association 2 (tunnel)
Figure 40 – Iterated tunneling – Both endpoints are the same
2) One endpoint of the SAs is the same -- The inner and outer tunnels could each
be either AH or ESP.
Page 77 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Internet
Host 1
Security
Gateway 2
Security
Gateway 1
Host 2
Security Association 1 (tunnel)
Security Association 2 (tunnel)
Figure 41 - Iterated tunneling : one endpoint is the same
3) Neither endpoint is the same -- The inner and outer tunnels could each be
either AH or ESP.
Internet
Host 1
Security
Gateway 2 Host 2
Security
Gateway 1
Security Association 1
(tunnel)
Security Association 2 (tunnel)
Figure 42 – Iterated tunneling: neither endpoint is the same
These two approaches also can be combined, e.g., an SA bundle could be constructed from
one tunnel mode SA and one or two transport mode SAs, applied in sequence. Note that
nested tunnels can also occur where neither the source nor the destination endpoints of any of
the tunnels are the same. In that case, there would be no host or security gateway with a
bundle corresponding to the nested tunnels.
For transport mode SAs, only one ordering of security protocols seems appropriate. AH is
applied to both the upper layer protocols and (parts of) the IP header. Thus if AH is used in a
transport mode, in conjunction with ESP, AH should appear as the first header after IP, prior
to the appearance of ESP. In that context, AH is applied to the ciphertext output of ESP. In
contrast, for tunnel mode SAs, one can imagine uses for various orderings of AH and ESP.
The required set of SA bundle types that must be supported by a compliant IPsec
implementation is described below.
Security Association Databases
Many of the details associated with processing IP traffic in an IPsec implementation are
largely a local matter, not subject to standardization. However, some external aspects of the
processing must be standardized, to ensure interoperability and to provide a minimum
management capability that is essential for productive use of IPsec. This section describes a
Page 78 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
general model for processing IP traffic relative to security associations, in support of these
interoperability and functionality goals. The model described below is nominal; compliant
implementations need not match details of this model as presented, but the external behavior
of such implementations must be mappable to the externally observable characteristics of this
model.
There are two nominal databases in this model: the Security Policy Database and the Security
Association Database. The former specifies the policies that determine the disposition of all IP
traffic inbound or outbound from a host, security gateway, or BITS or BITW IPsec
implementation. The latter database contains parameters that are associated with each (active)
security association. This section also defines the concept of a Selector, a set of IP and upper
layer protocol field values that is used by the Security Policy Database to map traffic to a
policy, i.e., an SA (or SA bundle).
Each interface for which IPsec is enabled requires nominally separate inbound vs. outbound
databases (SAD and SPD), because of the directionality of many of the fields that are used as
selectors.
Typically there is just one such interface, for a host or security gateway (SG). Note that an SG
would always have at least 2 interfaces, but the “internal” one to the corporate net, usually
would not have IPsec enabled and so only one pair of SADs and one pair of SPDs would be
needed. On the other hand, if a host had multiple interfaces or an SG had multiple external
interfaces, it might be necessary to have separate SAD and SPD pairs for each interface.
The Security Policy Database (SPD)
Ultimately, a security association is a management construct used to enforce a security
policy in the IPsec environment. Thus an essential element of SA processing is an
underlying Security Policy Database (SPD) that specifies what services are to be offered
to IP datagrams and in what fashion. The form of the database and its interface are outside
the scope of this specification. However, this section does specify certain minimum
management functionality that must be provided, to allow a user or system administrator
to control how IPsec is applied to traffic transmitted or received by a host or transiting a
security gateway.
The SPD must be consulted during the processing of all traffic (INBOUND and
OUTBOUND), including non-IPsec traffic. In order to support this, the SPD requires
distinct entries for inbound and outbound traffic. One can think of this as separate SPDs
(inbound vs. outbound). In addition, a nominally separate SPD must be provided for each
IPsec-enabled interface.
An SPD must discriminate among traffic that is afforded IPsec protection and traffic that
is allowed to bypass IPsec. This applies to the IPsec protection to be applied by a sender
and to the IPsec protection that must be present at the receiver. For any outbound or
inbound datagram, three processing choices are possible: discard, bypass IPsec, or apply
IPsec. The first choice refers to traffic that is not allowed to exit the host, traverse the
security gateway, or be delivered to an application at all. The second choice refers to
traffic that is allowed to pass without additional IPsec protection. The third choice refers
to traffic that is afforded IPsec protection, and for such traffic the SPD must specify the
security services to be provided, protocols to be employed, algorithms to be used, etc.
For every IPsec implementation, there must be an administrative interface that allows a
user or system administrator to manage the SPD. Specifically, every inbound or outbound
Page 79 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
packet is subject to processing by IPsec and the SPD must specify what action will be
taken in each case. Thus the administrative interface must allow the user (or system
administrator) to specify the security processing to be applied to any packet entering or
exiting the system, on a packet-by-packet basis. (In a host IPsec implementation making
use of a socket interface, the SPD may not need to be consulted on a per packet basis, but
the effect is still the same.) The management interface for the SPD must allow creation of
entries consistent with the selectors, and must support total ordering of these entries. It is
expected that through the use of wildcards in various selector fields, and because all
packets on a single UDP or TCP connection will tend to match a single SPD entry, this
requirement will not impose an unreasonably detailed level of SPD specification. The
selectors are analogous to what are found in a stateless firewall or filtering router and
which are currently manageable this way.
In host systems, applications may be allowed to select what security processing is to be
applied to the traffic they generate and consume. However, the system administrator must
be able to specify whether or not a user or application can override (default) system
policies. Note that application specified policies may satisfy system requirements, so that
the system may not need to do additional IPsec processing beyond that needed to meet an
application’s requirements. The form of the management interface is not specified by this
document and may differ for hosts vs. security gateways, and within hosts the interface
may differ for socket-based vs. BITS implementations. However, this document does
specify a standard set of SPD elements that all IPsec implementations must support.
The SPD contains an ordered list of policy entries. Each policy entry is keyed by one or
more selectors that define the set of IP traffic encompassed by this policy entry. These
define the granularity of policies or SAs. Each entry includes an indication of whether
traffic matching this policy will be bypassed, discarded, or subject to IPsec processing. If
IPsec processing is to be applied, the entry includes an SA (or SA bundle) specification,
listing the IPsec protocols, modes, and algorithms to be employed, including any nesting
requirements. For example, an entry may call for all matching traffic to be protected by
ESP in transport mode using 3DES-CBC with an explicit IV, nested inside of AH in
tunnel mode using HMAC/SHA-1. For each selector, the policy entry specifies how to
derive the corresponding values for a new Security Association Database (SAD) entry
from those in the SPD and the packet (Note that at present, ranges are only supported for
IP addresses; but wildcarding can be expressed for all selectors):
·
Use the value in the packet itself - This will limit use of the SA to those packets
which have this packet’s value for the selector even if the selector for the policy
entry has a range of allowed values or a wildcard for this selector.
·
Use the value associated with the policy entry - If this were to be just a single
value, then there would be no difference between (b) and (a). However, if the
allowed values for the selector were a range (for IP addresses) or wildcard, then in
the case of a range, (b) would enable use of the SA by any packet with a selector
value within the range not just by packets with the selector value of the packet that
triggered the creation of the SA. In the case of a wildcard, (b) would allow use of
the SA by packets with any value for this selector.
For example, suppose there is an SPD entry where the allowed value for source address is
any of a range of hosts (192.168.2.1 to 192.168.2.10). And suppose that a packet is to be
sent that has a source address of 192.168.2.3. The value to be used for the SA could be
Page 80 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
any of the sample values below depending on what the policy entry for this selector says is
the source of the selector value:
Source for the value to be used in the SA
Example of new SAD selector value
A. packet
192.168.2.3 (one host)
b. SPD entry
192.168.2.1 to 192.168.2.10 (range of hosts)
Table 1 - Values for the SA
Note that if the SPD entry had an allowed value of wildcard for the source address, then
the SAD selector value could be wildcard (any host). Case (a) can be used to prohibit
sharing, even among packets that match the same SPD entry.
As described below, selectors may include “wildcard” entries and hence the selectors for
two entries may overlap. (This is analogous to the overlap that arises with ACLs or filter
entries in routers or packet filtering firewalls.) Thus, to ensure consistent, predictable
processing, SPD entries must be ordered and the SPD must always be searched in the
same order, so that the first matching entry is consistently selected. (This requirement is
necessary as the effect of processing traffic against SPD entries must be deterministic, but
there is no way to canonicalize SPD entries given the use of wildcards for some selectors.)
Note that if ESP is specified, either (but not both) authentication or encryption can be
omitted. So it must be possible to configure the SPD value for the authentication or
encryption algorithms to be “NULL”. However, at least one of these services must be
selected, i.e., it must not be possible to configure both of them as “NULL”.
The SPD can be used to map traffic to specific SAs or SA bundles. Thus it can function
both as the reference database for security policy and as the map to existing SAs (or SA
bundles). (To accommodate the bypass and discard policies cited above, the SPD also
must provide a means of mapping traffic to these functions, even though they are not, per
se, IPsec processing.)
Because a security policy may require that more than one SA be applied to a specified set
of traffic, in a specific order, the policy entry in the SPD must preserve these ordering
requirements, when present. Thus, it must be possible for an IPsec implementation to
determine that an outbound or inbound packet must be processed through a sequence of
SAs. Conceptually, for outbound processing, one might imagine links (to the SAD) from
an SPD entry for which there are active SAs, and each entry would consist of either a
single SA or an ordered list of SAs that comprise an SA bundle. When a packet is
matched against an SPD entry and there is an existing SA or SA bundle that can be used
to carry the traffic, the processing of the packet is controlled by the SA or SA bundle entry
on the list. For an inbound IPsec packet for which multiple IPsec SAs are to be applied,
the lookup based on destination address, IPsec protocol, and SPI should identify a single
SA.
The SPD is used to control the flow of all traffic through an IPsec system, including
security and key management traffic (e.g., ISAKMP) from/to entities behind a security
gateway. This means that ISAKMP traffic must be explicitly accounted for in the SPD,
else it will be discarded. Note that a security gateway could prohibit traversal of encrypted
packets in various ways, e.g., having a DISCARD entry in the SPD for ESP packets or
Page 81 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
providing proxy key exchange. In the latter case, the traffic would be internally routed to
the key management module in the security gateway.
Selectors
An SA (or SA bundle) may be fine-grained or coarse-grained, depending on the selectors
used to define the set of traffic for the SA. For example, all traffic between two hosts may
be carried via a single SA, and afforded a uniform set of security services. Alternatively,
traffic between a pair of hosts might be spread over multiple SAs, depending on the
applications being used (as defined by the Next Protocol and Port fields), with different
security services offered by different SAs. Similarly, all traffic between a pair of security
gateways could be carried on a single SA, or one SA could be assigned for each
communicating host pair. The following selector parameters must be supported for SA
management to facilitate control of SA granularity. Note that in the case of receipt of a
packet with an ESP header, e.g., at an encapsulating security gateway or BITW
implementation, the transport layer protocol, source/destination ports, and Name (if
present) may be “OPAQUE”, i.e., inaccessible because of encryption or fragmentation.
Note also that both Source and Destination addresses should either be IPv4 or IPv6.
·
Destination IP Address (IPv4 or IPv6): this may be a single IP address (unicast,
anycast, broadcast (IPv4 only), or multicast group), a range of addresses (high and
low values (inclusive), address + mask, or a wildcard address. The last three are
used to support more than one destination system sharing the same SA (e.g.,
behind a security gateway). Note that this selector is conceptually different from
the “Destination IP Address” field in the <Destination IP Address, IPsec Protocol,
SPI> tuple used to uniquely identify an SA. When a tunneled packet arrives at the
tunnel endpoint, its SPI/Destination address/Protocol are used to look up the SA
for this packet in the SAD. This destination address comes from the encapsulating
IP header. Once the packet has been processed according to the tunnel SA and has
come out of the tunnel, its selectors are “looked up” in the Inbound SPD. The
Inbound SPD has a selector called destination address. This IP destination address
is the one in the inner (encapsulated) IP header. In the case of a transported packet,
there will be only one IP header and this ambiguity does not exist.
·
Source IP Address(es) (IPv4 or IPv6): this may be a single IP address (unicast,
anycast, broadcast (IPv4 only), or multicast group), range of addresses (high and
low values inclusive), address + mask, or a wildcard address. The last three are
used to support more than one source system sharing the same SA (e.g., behind a
security gateway or in a multihomed host).
·
Name: There are 2 cases (Note that these name forms are supported in the IPsec
DOI.)
1) User ID
A fully qualified user name string (DNS), e.g., mozart@foo.bar.com
X.500 distinguished name, e.g., C = US, SP = MA, O = GTE Internetworking, CN =
Stephen T. Kent.
2) System name (host, security gateway, etc.)
§
A fully qualified DNS name, e.g., foo.bar.com
Page 82 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
§
X.500 distinguished name
§
X.500 general name
·
Data sensitivity level: (IPSO/CIPSO labels)
·
Transport Layer Protocol: Obtained from the IPv4 “Protocol” or the IPv6 “Next
Header” fields. This may be an individual protocol number. These packet fields
may not contain the Transport Protocol due to the presence of IP extension
headers, e.g., a Routing Header, AH, ESP, Fragmentation Header, Destination
Options, Hop-by-hop options, etc. Note that the Transport Protocol may not be
available in the case of receipt of a packet with an ESP header, thus a value of
“OPAQUE” should be supported.
·
Source and Destination (e.g., TCP/UDP) Ports: These may be individual UDP or
TCP port values or a wildcard port. (The use of the Next Protocol field and the
Source and/or Destination Port fields (in conjunction with the Source and/or
Destination Address fields), as an SA selector is sometimes referred to as
“session-oriented keying.”). Note that the source and destination ports may not be
available in the case of receipt of a packet with an ESP header, thus a value of
“OPAQUE” should be supported.
The following table summarizes the relationship between the “Next Header” value
in the packet and SPD and the derived Port Selector value for the SPD and SAD.
Next Hdr in Packet
Protocol in SPD
Value in SPD and SAD
ESP
ESP or ANY
ANY (i.e., don’t look at it)
Don’t care
ANY
ANY (i.e., don’t look at it)
Specific value fragment
Specific value
NOT ANY (i.e., drop packet)
Specific value not fragment
Specific value
Actual port selector field
Table 2 – Relationship between NH and SPD/SAD
If the packet has been fragmented, then the port information may not be available
in the current fragment. If so, discard the fragment. An ICMP PMTU should be
sent for the first fragment, which will have the port information.
The IPsec implementation context determines how selectors are used. For example, a host
implementation integrated into the stack may make use of a socket interface. When a new
connection is established the SPD can be consulted and an SA (or SA bundle) bound to
the socket. Thus traffic sent via that socket need not result in additional lookups to the
SPD/SAD. In contrast, a BITS, BITW, or security gateway implementation needs to look
at each packet and perform an SPD/SAD lookup based on the selectors. The allowable
values for the selector fields differ between the traffic flow, the security association, and
the security policy.
The following table summarizes the kinds of entries that one needs to be able to express
in the SPD and SAD. It shows how they relate to the fields in data traffic being subjected
to IPsec screening. (Note: the “wildcard” entry for src and dst addresses includes a mask,
range, etc.)
Page 83 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Field
Traffic Value
SAD Entry
SPD Entry
Src addr
Single IP addr
Single, range, wildcard
Single, range, wildcard
Dst addr
Single IP addr
Single, range, wildcard
Single, range, wildcard
Xpt protocol
Xpt protocol
Single, wildcard
Single, wildcard
Src port
Single src port
Single, wildcard
Single, wildcard
Dst port
Single dst port
Single, wildcard
Single, wildcard
User id
Single user id
Single, wildcard
Single, wildcard
Sec. Labels
Single value
Single, wildcard
Single, card
Table 3- The kinds of entries for SAD and SAD
Security Association Database (SAD)
In each IPsec implementation there is a nominal Security Association Database, in which
each entry defines the parameters associated with one SA. Each SA has an entry in the
SAD. For outbound processing, entries are pointed to by entries in the SPD. Note that if
an SPD entry does not currently point to an SA that is appropriate for the packet, the
implementation creates an appropriate SA (or SA Bundle) and links the SPD entry to the
SAD entry. For inbound processing, each entry in the SAD is indexed by a destination IP
address, IPsec protocol type, and SPI. The following parameters are associated with each
entry in the SAD. This description does not purport to be a MIB, but only a specification
of the minimal data items required to support an SA in an IPsec implementation.
For inbound processing: The following packet fields are used to look up the SA in the
SAD:
·
Outer Header’s Destination IP address: the IPv4 or IPv6 Destination address.
·
IPsec Protocol: AH or ESP, used as an index for SA lookup in this database.
Specifies the IPsec protocol to be applied to the traffic on this SA.
·
SPI: the 32-bit value used to distinguish among different SAs terminating at the
same destination and using the same IPsec protocol.
For each of the selectors defined above, the SA entry in the SAD must contain the value
or values that were negotiated at the time the SA was created. For the sender, these values
are used to decide whether a given SA is appropriate for use with an outbound packet.
This is part of checking to see if there is an existing SA that can be used. For the receiver,
these values are used to check that the selector values in an inbound packet match those
for the SA (and thus indirectly those for the matching policy). For the receiver, this is part
of verifying that the SA was appropriate for this packet. These fields can have the form of
specific values, ranges, or wildcards as described above in “Selectors”. Note that for an
ESP SA, the encryption algorithm or the authentication algorithm could be “NULL”.
However they must not both be “NULL”.
The following SAD fields are used in doing IPsec processing:
Page 84 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Sequence Number Counter: a 32-bit value used to generate the Sequence Number
field in AH or ESP headers.
Sequence Counter Overflow: a flag indicating whether overflow of the Sequence
Number Counter should generate an auditable event and prevent transmission of
additional packets on the SA.
Anti-Replay Window: a 32-bit counter and a bit-map (or equivalent) used to
determine whether an inbound AH or ESP packet is a replay.
AH Authentication algorithm, keys, etc.
ESP Encryption algorithm, keys, IV mode, IV, etc.
ESP authentication algorithm, keys, etc. If the authentication service is not
selected, this field will be null.
Lifetime of this Security Association: a time interval after which a SA must be
replaced with a new SA (and new SPI) or terminated, plus an indication of which
of these actions should occur. This may be expressed as a time or byte count, or a
simultaneous use of both, the first lifetime to expire taking precedence. A
compliant implementation must support both types of lifetimes, and must support
a simultaneous use of both. If time is employed, and if IKE employs X.509
certificates for SA establishment, the SA lifetime must be constrained by the
validity intervals of the certificates, and the NextIssueDate of the CRLs used in the
IKE exchange for the SA. Both initiator and responder are responsible for
constraining SA lifetime in this fashion.
IPsec protocol mode: tunnel, transport or wildcard. Indicates which mode of AH
or ESP is applied to traffic on this SA. Note that if this field is “wildcard” at the
sending end of the SA, then the application has to specify the mode to the IPsec
implementation. This use of wildcard allows the same SA to be used for either
tunnel or transport mode traffic on a per packet basis, e.g., by different sockets.
The receiver does not need to know the mode in order to properly process the
packet’s IPsec headers.
Path MTU: any observed path MTU and aging variables.
Basic Combinations of Security Associations
This section describes four examples of combinations of security associations that must be
supported by compliant IPsec hosts or security gateways. Additional combinations of AH
and/or ESP in tunnel and/or transport modes may be supported at the discretion of the
implementer. Compliant implementations must be capable of generating these four
combinations and on receipt, of processing them, but should be able to receive and process
any combination. The diagrams and text below describe the basic cases. The legend for the
diagrams is:
Page 85 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
label – No IPsec Support
label+ - IPsec
- connectivity
-one or more security associations (AH or ESP, transport or tunnel)
Case 1
The case of providing end-to-end security between 2 hosts across the Internet (or an Intranet).
Inter/Intranet
Host 1+
Host 2+
Figure 43 – Basic SA combinations – Case 1
Transport
Tunnel
1. [IP1][AH][upper]
4. [IP2][AH][IP1][upper]
2. [IP1][ESP][upper]
5. [IP2][ESP][IP1][upper]
3. [IP1][AH][ESP][upper]
Case 2
This case illustrates simple virtual private networks support.
Local
Intranet
Host 1
Internet
Local
Intranet
Security
Gateway 2+
Security
Gateway 1+
Figure 44 – Basic SA combinations – Case 2
Tunnel
4. [IP2][AH][IP1][upper]
5. [IP2][ESP][IP1][upper]
Page 86 of 206
Host 2
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Case 3
This case combines cases 1 and 2, adding end-to-end security between the sending and
receiving hosts. It imposes no new requirements on the hosts or security gateways, other
than a requirement for a security gateway to be configurable to pass IPsec traffic
(including ISAKMP traffic) for hosts behind it.
Host 1+
Local
Intranet
Security
Gateway 1+
Local
Intranet
Internet
Security
Gateway 2+
Host 2+
Figure 45 – Basic SA combinations – Case 3
Case 4
This covers the situation where a remote host (H1) uses the Internet to reach an
organization’s firewall (SG2) and to then gain access to some server or other machine
(H2). The remote host could be a mobile host (H1) dialing up to a local PPP/ARA server
(not shown) on the Internet and then crossing the Internet to the home organization’s
firewall (SG2), etc. The details of support for this case (how H1 locates SG2,
authenticates it, and verifies its authorization to represent H2) are discussed below in the
section “Locating a Security Gateway”.
Local
Intranet
Internet
Security
Gateway 2+
Host 1+
Host 2+
Figure 46 – Basic SA combination – Case 4
As noted above, support for additional combinations of AH and ESP is optional. Use of
other, optional combinations may adversely affect interoperability.
SA and Key Management
IPsec mandates support for both manual and automated SA and cryptographic key
management. The IPsec protocols, AH and ESP, are largely independent of the associated SA
Page 87 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
management techniques, although the techniques involved do affect some of the security
services offered by the protocols. For example, the optional anti-replay services available for
AH and ESP require automated SA management. Moreover, the granularity of key
distribution employed with IPsec determines the granularity of authentication provided. (See
also a discussion of this issue in the next section) In general, data origin authentication in AH
and ESP is limited by the extent to which secrets used with the authentication algorithm (or
with a key management protocol that creates such secrets) are shared among multiple possible
sources.
The following text describes the minimum requirements for both types of SA management.
Manual Techniques
The simplest form of management is manual management, in which a person manually
configures each system with keying material and security association management data
relevant to secure communication with other systems. Manual techniques are practical in
small, static environments but they do not scale well. For example, a company could
create a Virtual Private Network (VPN) using IPsec in security gateways at several sites.
If the number of sites is small, and since all the sites come under the purview of a single
administrative domain, this is likely to be a feasible context for manual management
techniques. In this case, the security gateway might selectively protect traffic to and from
other sites within the organization using a manually configured key, while not protecting
traffic for other destinations. It also might be appropriate when only selected
communications need to be secured. A similar argument might apply to use of IPsec
entirely within an organization for a small number of hosts and/or gateways. Manual
management techniques often employ statically configured, symmetric keys, though other
options also exist.
Automated SA and Key Management
Widespread deployment and use of IPsec requires an Internet-standard, scalable,
automated, SA management protocol. Such support is required to facilitate use of the antireplay features of AH and ESP, and to accommodate on-demand creation of SAs, e.g., for
user- and session-oriented keying. (Note that the notion of “rekeying” an SA actually
implies creation of a new SA with a new SPI, a process that generally implies use of an
automated SA/key management protocol.)
The default automated key management protocol selected for use with IPsec is IKE under
the IPsec domain of interpretation. Other automated SA management protocols may be
employed.
When an automated SA/key management protocol is employed, the output from this
protocol may be used to generate multiple keys, e.g., for a single ESP SA. This may arise
because:
·
The encryption algorithm uses multiple keys (e.g., triple DES)
·
The authentication algorithm uses multiple keys
·
Both encryption and authentication algorithms are employed
The Key Management System may provide a separate string of bits for each key or it may
generate one string of bits from which all of them are extracted. If a single string of bits is
Page 88 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
provided, care needs to be taken to ensure that the parts of the system that map the string
of bits to the required keys do so in the same fashion at both ends of the SA. To ensure
that the IPsec implementations at each end of the SA use the same bits for the same keys,
and irrespective of which part of the system divides the string of bits into individual keys,
the encryption key(s) must be taken from the first (left-most, high-order) bits and the
authentication key(s) must be taken from the remaining bits. The number of bits for each
key is defined in the relevant algorithm specification RFC. In the case of multiple
encryption keys or multiple authentication keys, the specification for the algorithm must
specify the order in which they are to be selected from a single string of bits provided to
the algorithm.
Locating a Security Gateway
This section discusses issues relating to how a host learns about the existence of relevant
security gateways and once a host has contacted these security gateways, how it knows
that these are the correct security gateways. The details of where the required information
is stored are a local matter.
Consider a situation in which a remote host (H1) is using the Internet to gain access to a
server or other machine (H2) and there is a security gateway (SG2), e.g., a firewall,
through which H1‘s traffic must pass. An example of this situation would be a mobile
host (Road Warrior) crossing the Internet to the home organization’s firewall (SG2). (See
Case 4 in the section below, Basic Combinations of Security Associations.) This situation
raises several issues:
1. How does Host 1 know/learn about the existence of the security gateway Security
Gateway 2?
2. How does it authenticate Security Gateway 2, and once it has authenticated
Security Gateway 2, how does it confirm that Security Gateway 2 has been
authorized to represent Host 2?
3. How does Security Gateway 2 authenticate Host 1 and verify that Host 1 is
authorized to contact Host 2?
4. How does Host 1 know/learn about backup gateways that provide alternate paths
to Host 2?
To address these problems, a host or security gateway must have an administrative
interface that allows the user/administrator to configure the address of a security gateway
for any sets of destination addresses that require its use. This includes the ability to
configure:
·
The requisite information for locating and authenticating the security gateway and
verifying its authorization to represent the destination host.
·
The requisite information for locating and authenticating any backup gateways and
verifying their authorization to represent the destination host.
It is assumed that the SPD is also configured with policy information that covers any other
IPsec requirements for the path to the security gateway and the destination host.
Page 89 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Security Associations and Multicast
The receiver-orientation of the Security Association implies that, in the case of unicast traffic,
the destination system will normally select the SPI value. By having the destination select the
SPI value, there is no potential for manually configured Security Associations to conflict with
automatically configured (e.g., via a key management protocol) Security Associations or for
Security Associations from multiple sources to conflict with each other. For multicast traffic,
there are multiple destination systems per multicast group. So some system or person will
need to coordinate among all multicast groups to select an SPI or SPIs on behalf of each
multicast group and then communicate the group’s IPsec information to all of the legitimate
members of that multicast group via mechanisms not defined here.
Multiple senders to a multicast group should use a single Security Association (and hence
Security Parameter Index) for all traffic to that group when a symmetric key encryption or
authentication algorithm is employed. In such circumstances, the receiver knows only that the
message came from a system possessing the key for that multicast group. In such
circumstances, a receiver generally will not be able to authenticate which system sent the
multicast traffic. Specifications for other, more general multicast cases are deferred to later
IPsec documents.
At the time the specification for IPsec was published, automated protocols for multicast key
distribution were not considered adequately mature for standardization. For multicast groups
having relatively few members, manual key distribution or multiple use of existing unicast
key distribution algorithms such as modified Diffie-Hellman appears feasible. For very large
groups, new scalable techniques will be needed. An example of current work in this area is the
Group Key Management Protocol (GKMP).
2.8.4.1. Performance Issues
The use of IPsec imposes computational performance costs on the hosts or security gateways
that implement these protocols. These costs are associated with the memory needed for IPsec
code and data structures, and the computation of integrity check values, encryption and
decryption, and added per-packet handling. The per-packet computational costs will be
manifested by increased latency and, possibly, reduced throughout. Use of SA/key
management protocols, especially ones that employ public key cryptography, also adds
computational performance costs to use of IPsec. These per-association computational costs
will be manifested in terms of increased latency in association establishment. For many hosts,
it is anticipated that software-based cryptography will not appreciably reduce throughput, but
hardware may be required for security gateways (since they represent aggregation points), and
for some hosts.
The use of IPsec also imposes bandwidth utilization costs on transmission, switching, and
routing components of the Internet infrastructure, components not implementing IPsec. This is
due to the increase in the packet size resulting from the addition of AH and/or ESP headers,
AH and ESP tunneling (which adds a second IP header), and the increased packet traffic
associated with key management protocols. It is anticipated that, in most instances, this
increased bandwidth demand will not noticeably affect the Internet infrastructure. However, in
some instances, the effects may be significant, e.g., transmission of ESP encrypted traffic over
a dialup link that otherwise would have compressed the traffic.
Page 90 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The initial SA establishment overhead will be felt in the first packet. This delay could impact
the transport layer and application. For example, it could cause TCP to retransmit the SYN
before the ISAKMP exchange is done. The effect of the delay would be different on UDP than
TCP because TCP shouldn't transmit anything other than the SYN until the connection is set
up whereas UDP will go ahead and transmit data beyond the first packet.
2.8.5. IP Authentication Header
2.8.5.1. Introduction
The IP Authentication Header (AH) is used to provide connectionless integrity and data origin
authentication for IP datagrams (hereafter referred to as just "authentication"), and to provide
protection against replays. The receiver may select this latter, optional service, when a
Security Association is established (although the default calls for the sender to increment the
Sequence Number used for anti-replay, the service is effective only if the receiver checks the
Sequence Number.). AH provides authentication for as much of the IP header as possible, as
well as for upper level protocol data. However, some IP header fields may change in transit
and the value of these fields, when the packet arrives at the receiver, may not be predictable
by the sender. The values of such fields cannot be protected by AH. Thus the protection
provided to the IP header by AH is somewhat piecemeal.
AH may be applied alone, in combination with the IP Encapsulating Security Payload (ESP),
or in a nested fashion through the use of tunnel mode (see above). Security services can be
provided between a pair of communicating hosts, between a pair of communicating security
gateways, or between a security gateway and a host. ESP may be used to provide the same
security services, and it also provides a confidentiality (encryption) service. The primary
difference between the authentications provided by ESP and AH is the extent of the coverage.
Specifically, ESP does not protect any IP header fields unless those fields are encapsulated by
ESP (tunnel mode).
2.8.5.2. Authentication Header Processing
Authentication Header Location
Like ESP, AH may be employed in two ways: transport mode or tunnel mode. The former
mode is applicable only to host implementations and provides protection for upper layer
protocols, in addition to selected IP header fields. (In this mode, note that for "bump-in-thestack" or "bump-in-the-wire" implementations, as defined in the previous section, inbound
and outbound IP fragments may require an IPsec implementation to perform extra IP
reassembly/fragmentation in order to both conform to this specification and provide
transparent IPsec support. Special care is required to perform such operations within these
implementations when multiple interfaces are in use.)
In transport mode, AH is inserted after the IP header and before an upper layer protocol, e.g.,
TCP, UDP, ICMP, etc. or before any other IPsec headers that have already been inserted. In
the IPv6 context, AH is viewed as an end-to-end payload, and thus should appear after hopby-hop, routing, and fragmentation extension headers. The destination options extension
header(s) could appear either before or after the AH header depending on the semantics
desired. The following diagram illustrates AH transport mode positioning for a typical IPv6
packet.
Page 91 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Before AH
IPv6
Ext. Headers
Original IP
Header
TCP
Data
(if present)
After AH
IPv6
Original IP
Header
AH
H.By H.,
Dest*, Rout.
Fragment
Dest.
TCP
Data
Opt.*
Authenticated
Except for mutable fields
* = if present, could be before AH, after AH, or both
Figure 47 – Applying AH to IPv6 in transport mode
Tunnel mode AH may be employed in either hosts or security gateways (or in so-called
"bump-in-the-stack" or "bump-in-the-wire" implementations, as defined in the Section below).
When AH is implemented in a security gateway (to protect transit traffic), tunnel mode must
be used. In tunnel mode, the "inner" IP header carries the ultimate source and destination
addresses, while an "outer" IP header may contain distinct IP addresses, e.g., addresses of
security gateways. In tunnel mode, AH protects the entire inner IP packet, including the entire
inner IP header. The position of AH in tunnel mode, relative to the outer IP header, is the
same as for AH in transport mode. The following diagram illustrates AH tunnel mode
positioning IPv6 packets.
IPv6
New
IP
Hdr
Ext. Hdrs
(if present)
AH
Orig.
IP
Hdr
Ext. Hdrs
(if present)
TCP
DATA
Authenticated
Except for mutable fields
Figure 48 – Applying AH to IPv6 in tunnel mode
Authentication Algorithms
The SA specifies the authentication algorithm employed for the ICV computation. For pointto-point communication, suitable authentication algorithms include keyed Message
Authentication Codes (MACs) based on symmetric encryption algorithms (e.g., DES) or on
one-way hash functions (e.g., MD5 or SHA-1). For multicast communication, one-way hash
algorithms combined with asymmetric signature algorithms are appropriate, though
performance and space considerations currently preclude use of such algorithms. The
mandatory-to-implement authentication algorithms are described below in the section
"Conformance Requirements". Other algorithms may be supported.
Outbound Packet Processing
In transport mode, the sender inserts the AH header after the IP header and before an upper
layer protocol header, as described above. In tunnel mode, the outer and inner IP
header/extensions can be inter-related in a variety of ways. The construction of the outer IP
header/extensions during the encapsulation process is described above.
Page 92 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
If there is more than one IPsec header/extension required, the order of the application of the
security headers must be defined by security policy. For simplicity of processing, each IPsec
header should ignore the existence (i.e., not zero the contents or try to predict the contents) of
IPsec headers to be applied later. (While a native IP or bump-in-the-stack implementation
could predict the contents of later IPsec headers that it applies itself, it won't be possible for it
to predict any IPsec headers added by a bump-in-the-wire implementation between the host
and the network.)
Inbound Packet Processing
If there is more than one IPsec header/extension present, the processing for each one ignores
(does not zero, does not use) any IPsec headers applied subsequent to the header being
processed.
Reassembly
If required, reassembly is performed prior to AH processing. If a packet offered to AH for
processing appears to be an IP fragment, i.e., the OFFSET field is non-zero or the MORE
FRAGMENTS flag is set, the receiver must discard the packet; this is an auditable event.
The audit log entry for this event should include the SPI value, date/time, Source Address,
Destination Address, and (in IPv6) the Flow ID.
2.8.5.3. Auditing
Not all systems that implement AH will implement auditing. However, if AH is incorporated
into a system that supports auditing, then the AH implementation must also support auditing
and must allow a system administrator to enable or disable auditing for AH. For the most part,
the granularity of auditing is a local matter. However, several auditable events are identified in
this specification and for each of these events a minimum set of information that should be
included in an audit log is defined. Additional information also may be included in the audit
log for each of these events, and additional events, not explicitly called out in this
specification, also may result in audit log entries. There is no requirement for the receiver to
transmit any message to the purported sender in response to the detection of an auditable
event, because of the potential to induce denial of service via such action.
2.8.5.4. Conformance Requirements
Implementations that claim conformance or compliance with this specification must fully
implement the AH syntax and processing described here and must comply with all
requirements presented above. If the key used to compute an ICV is manually distributed,
correct provision of the anti-replay service would require correct maintenance of the counter
state at the sender, until the key is replaced, and there likely would be no automated recovery
provision if counter overflow were imminent. Thus a compliant implementation should not
provide this service in conjunction with SAs that are manually keyed. A compliant AH
implementation must support the following mandatory-to-implement algorithms:
·
HMAC with MD5
·
HMAC with SHA-1
Page 93 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.8.6. IP Encapsulating Security Payload (ESP)
2.8.6.1. Introduction
The Encapsulating Security Payload (ESP) header is designed to provide a mix of security
services. ESP may be applied alone, in combination with the IP Authentication Header (AH),
or in a nested fashion, e.g., through the use of tunnel mode.
Security services can be provided between a pair of communicating hosts, between a pair of
communicating security gateways, or between a security gateway and a host.
The ESP header is inserted after the IP header and before the upper layer protocol header
(transport mode) or before an encapsulated IP header (tunnel mode). These modes are
described in more detail below.
ESP is used to provide confidentiality, data origin authentication, connectionless integrity, an
anti-replay service (a form of partial sequence integrity), and limited traffic flow
confidentiality. The set of services provided depends on options selected at the time of
Security Association establishment and on the placement of the implementation.
Confidentiality may be selected independent of all other services. However, use of
confidentiality without integrity/authentication (either in ESP or separately in AH) may
subject traffic to certain forms of active attacks that could undermine the confidentiality
service. Data origin authentication and connectionless integrity are joint services (hereafter
referred to jointly as "authentication) and are offered as an option in conjunction with
(optional) confidentiality. The anti-replay service may be selected only if data origin
authentication is selected, and its selection is solely at the discretion of the receiver. (Although
the default calls for the sender to increment the Sequence Number used for anti-replay, the
service is effective only if the receiver checks the Sequence Number.) Traffic flow
confidentiality requires selection of tunnel mode, and is most effective if implemented at a
security gateway, where traffic aggregation may be able to mask true source-destination
patterns. Note that although both confidentiality and authentication are optional, at least one
of them must be selected.
It is assumed that the reader is familiar with the terms and concepts described above. In
particular, the reader should be familiar with the definitions of security services offered by
ESP and AH, the concept of Security Associations, the ways in which ESP can be used in
conjunction with the Authentication Header (AH), and the different key management options
available for ESP and AH. (With regard to the last topic, the current key management options
required for both AH and ESP are manual keying and automated keying via IKE.)
2.8.6.2. Encapsulating Security Protocol Processing
ESP Header Location
Like AH, ESP may be employed in two ways: transport mode or tunnel mode. The former
mode is applicable only to host implementations and provides protection for upper layer
protocols, but not the IP header. (In this mode, note that for "bump-in-the-stack" or "bump-inthe-wire" implementations, as defined above, inbound and outbound IP fragments may require
an IPsec implementation to perform extra IP reassembly/fragmentation in order to both
conform to this specification and provide transparent IPsec support. Special care is required to
perform such operations within these implementations when multiple interfaces are in use.)
Page 94 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
In transport mode, ESP is inserted after the IP header and before an upper layer protocol, e.g.,
TCP, UDP, ICMP, etc. or before any other IPsec headers that have already been inserted. In
the IPv6 context, ESP is viewed as an end-to-end payload, and thus should appear after hopby-hop, routing, and fragmentation extension headers. The destination options extension
header(s) could appear either before or after the ESP header depending on the semantics
desired. However, since ESP protects only fields after the ESP header, it generally may be
desirable to place the destination options header(s) after the ESP header. The following
diagram illustrates ESP transport mode positioning for a typical IPv6 packet.
Before ESP
IPv6
Original IP
Header
Ext. Headers
(if present)
TCP
Data
After ESP
IPv6
Original IP
Header
E
S
P
H by H, Dest*,
Routing,
Fragment
Dest.
Opt.*
TCP
DATA
ESP
trailer
and auth
Encrypted
Authenticated
* = if present, could be before AH, after AH, or both
Figure 49 - Applying ESP to IPv6 in transport mode
Headers can be combined in a variety of modes. The IPsec Architecture document describes
the combinations of security associations that must be supported.
Tunnel mode ESP may be employed in either hosts or security gateways. When ESP is
implemented in a security gateway (to protect subscriber transit traffic), tunnel mode must be
used. In tunnel mode, the "inner" IP header carries the ultimate source and destination
addresses, while an "outer" IP header may contain distinct IP addresses, e.g., addresses of
security gateways. In tunnel mode, ESP protects the entire inner IP packet, including the entire
inner IP header. The position of ESP in tunnel mode, relative to the outer IP header, is the
same as for ESP in transport mode. The following diagram illustrates ESP tunnel mode
positioning for typical IPv6 packets.
After ESP
IPv6
New IP
Header
New ext.
Headers
E
S
P
Original
IP
Header
Original
ext.
Headers
T
C
P
D
A
T
A
Encrypted
Authenticated
Figure 50 – Applying ESP to IPv6 in tunnel mode
Page 95 of 206
ESP trailer
and auth
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Algorithms
The mandatory-to-implement algorithms are described later in the Section "Conformance
Requirements". Other algorithms maybe supported. Note that although both confidentiality
and authentication are optional, at least one of these services must be selected hence both
algorithms must not be simultaneously NULL.
Encryption Algorithms
The SA specifies the encryption algorithm employed. ESP is designed for use with symmetric
encryption algorithms. Because IP packets may arrive out of order, each packet must carry any
data required to allow the receiver to establish cryptographic synchronization for decryption.
This data may be carried explicitly in the payload field, e.g., as an IV (as described above), or
the data may be derived from the packet header. Since ESP makes provision for padding of
the plaintext, encryption algorithms employed with ESP may exhibit either block or stream
mode characteristics. Note that since encryption (confidentiality) is optional, this algorithm
may be "NULL".
Authentication Algorithms
The SA specifies the authentication algorithm employed for the ICV computation. For pointto-point communication, suitable authentication algorithms include keyed Message
Authentication Codes (MACs) based on symmetric encryption algorithms (e.g., DES) or on
one-way hash functions (e.g., MD5 or SHA-1). For multicast communication, one-way hash
algorithms combined with asymmetric signature algorithms are appropriate, though
performance and space considerations currently preclude use of such algorithms. Note that
since authentication is optional, this algorithm may be "NULL".
Outbound Packet Processing
In transport mode, the sender encapsulates the upper layer protocol information in the ESP
header/trailer, and retains the specified IP header (and any IP extension headers in the IPv6
context). In tunnel mode, the outer and inner IP header/extensions can be inter-related in a
variety of ways. The construction of the outer IP header/extensions during the encapsulation
process is described above. If there is more than one IPsec header/extension required by
security policy, the order of the application of the security headers must be defined by security
policy.
Inbound Packet Processing
Reassembly
If required, reassembly is performed prior to ESP processing. If a packet offered to ESP
for processing appears to be an IP fragment, i.e., the OFFSET field is non-zero or the
MORE FRAGMENTS flag is set, the receiver must discard the packet; this is an auditable
event. The audit log entry for this event should include the SPI value, date/time received,
Source Address, Destination Address, Sequence Number, and (in IPv6) the Flow ID.
Page 96 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.8.6.3. Auditing
Not all systems that implement ESP will implement auditing. However, if ESP is incorporated
into a system that supports auditing, then the ESP implementation must also support auditing
and must allow a system administrator to enable or disable auditing for ESP. For the most
part, the granularity of auditing is a local matter. However, several auditable events are
identified in this specification and for each of these events a minimum set of information that
should be included in an audit log is defined. Additional information also may be included in
the audit log for each of these events, and additional events, not explicitly called out in this
specification, also may result in audit log entries. There is no requirement for the receiver to
transmit any message to the purported sender in response to the detection of an auditable
event, because of the potential to induce denial of service via such action.
2.8.6.4. Conformance Requirements
Implementations that claim conformance or compliance with this specification must
implement the ESP syntax and processing described here and must comply with all
requirements of the Security Architecture document. If the key used to compute an ICV is
manually distributed, correct provision of the anti-replay service would require correct
maintenance of the counter state at the sender, until the key is replaced, and there likely would
be no automated recovery provision if counter overflow were imminent. Thus a compliant
implementation should not provide this service in conjunction with SAs that are manually
keyed. A compliant ESP implementation must support the following mandatory-to-implement
algorithms:
·
DES in CBC mode
·
HMAC with MD5
·
HMAC with SHA-1
·
NULL Authentication algorithm
·
NULL Encryption algorithm
Since ESP encryption and authentication are optional, support for the 2 "NULL" algorithms is
required to maintain consistency with the way these services are negotiated. Note that while
authentication and encryption can each be "NULL", they must not both be "NULL".
2.8.7. The Internet IP Security Domain of Interpretation (IPsec DOI)
2.8.7.1. Introduction
The Internet Security Association and Key Management Protocol (ISAKMP, defined in the
next section) defines a framework for security association management and cryptographic key
establishment for the Internet. This framework consists of defined exchanges, payloads, and
processing guidelines that occur within a given Domain of Interpretation (DOI). This section
defines the Internet IP Security DOI (IPsec DOI), which instantiates ISAKMP for use with IP
when IP uses ISAKMP to negotiate security associations.
Page 97 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
In Detail
Within ISAKMP, a Domain of Interpretation is used to group related protocols using
ISAKMP to negotiate security associations. Security protocols sharing a DOI choose security
protocol and cryptographic transforms from a common namespace and share key exchange
protocol identifiers. They also share a common interpretation of DOI-specific payload data
content, including the Security Association and Identification payloads.
Overall, ISAKMP places the following requirements on a DOI definition:
·
Define the naming scheme for DOI-specific protocol identifiers
·
Define the interpretation for the Situation field
·
Define the set of applicable security policies
·
Define the syntax for DOI-specific SA Attributes (Phase II)
·
Define the syntax for DOI-specific payload contents
·
Define additional Key Exchange types, if needed
·
Define additional Notification Message types, if needed
The remainder of this section details the instantiation of these requirements for using the IP
Security (IPsec) protocols to provide authentication, integrity, and/or confidentiality for IP
packets sent between cooperating host systems and/or firewalls.
2.8.7.2. Fitting into IPsec
IPsec Naming Scheme
Within ISAKMP, all DOI's must be registered with the IANA in the "Assigned Numbers"
RFC. The IANA Assigned Number for the Internet IP Security DOI (IPsec DOI) is one (1).
IPsec Security Policy Requirements
The IPsec DOI does not impose specific security policy requirements on any implementation.
However, the following sections touch on some of the issues that must be considered when
designing an IPsec DOI host implementation. This section should be considered only
informational in nature.
Key Management Issues
It is expected that many systems choosing to implement ISAKMP will strive to provide a
protected domain of execution for a combined IKE key management daemon. On
protected-mode multiuser operating systems, this key management daemon will likely
exist as a separate privileged process.
In such an environment, a formalized API to introduce keying material into the TCP/IP
kernel may be desirable. The IP Security architecture does not place any requirements for
structure or flow between a host TCP/IP kernel and its key management provider.
Page 98 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Static Keying Issues
Host systems that implement static keys, either for use directly by IPsec, or for
authentication purposes, should take steps to protect the static keying material when it is
not residing in a protected memory domain or actively in use by the TCP/IP kernel.
For example, on a laptop, one might choose to store the static keys in a configuration store
that is, itself, encrypted under a private password.
Depending on the operating system and utility software installed, it may not be possible to
protect the static keys once they've been loaded into the TCP/IP kernel, however they
should not be trivially recoverable on initial system startup without having to satisfy some
additional form of authentication.
Host Policy Issues
It is not realistic to assume that the transition to IPsec will occur overnight. Host systems
must be prepared to implement flexible policy lists that describe which systems they
desire to speak securely with and which systems they require speak securely to them.
Some notion of proxy firewall addresses may also be required.
A minimal approach is probably a static list of IP addresses, network masks, and a
security required flag or flags.
A more flexible implementation might consist of a list of wildcard DNS names (e.g.
'*.foo.bar'), an in/out bitmask, and an optional firewall address. The wildcard DNS name
would be used to match incoming or outgoing IP addresses, the in/out bitmask would be
used to determine whether or not security was to be applied and in which direction, and
the optional firewall address would be used to indicate whether or not tunnel mode would
be needed to talk to the target system though an intermediate firewall.
Certificate Management
Host systems implementing a certificate-based authentication scheme will need a
mechanism for obtaining and managing a database of certificates.
Secure DNS is to be one certificate distribution mechanism, however the pervasive
availability of secure DNS zones, in the short term, is doubtful for many reasons. What's
far more likely is that hosts will need an ability to import certificates that they acquire
through secure, out-of-band mechanisms, as well as an ability to export their own
certificates for use by other systems.
However, manual certificate management should not be done so as to preclude the ability
to introduce dynamic certificate discovery mechanisms and/or protocols as they become
available.
2.8.8. Internet Security Association and Key Management Protocol (ISAKMP)
2.8.8.1. Introduction
This section describes an Internet Security Association and Key Management Protocol
(ISAKMP). ISAKMP combines the security concepts of authentication, key management, and
Page 99 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
security associations to establish the required security for government, commercial, and
private communications on the Internet.
The Internet Security Association and Key Management Protocol (ISAKMP) defines
procedures and packet formats to establish, negotiate, modify and delete Security Associations
(SA). SAs contain all the information required for execution of various network security
services, such as the IP layer services (such as header authentication and payload
encapsulation), transport or application layer services, or self-protection of negotiation traffic.
ISAKMP defines payloads for exchanging key generation and authentication data. These
formats provide a consistent framework for transferring key and authentication data which is
independent of the key generation technique, encryption algorithm and authentication
mechanism.
ISAKMP is distinct from key exchange protocols in order to cleanly separate the details of
security association management (and key management) from the details of key exchange.
There may be many different key exchange protocols, each with different security properties.
However, a common framework is required for agreeing to the format of SA attributes, and
for negotiating, modifying, and deleting SAs. ISAKMP serves as this common framework.
Separating the functionality into three parts adds complexity to the security analysis of a
complete ISAKMP implementation. However, the separation is critical for interoperability
between systems with differing security requirements, and should also simplify the analysis of
further evolution of an ISAKMP server.
ISAKMP is intended to support the negotiation of SAs for security protocols at all layers of
the network stack (e.g., IPsec, TLS, TLSP, OSPF, etc.). By centralizing the management of
the security associations, ISAKMP reduces the amount of duplicated functionality within each
security protocol. ISAKMP can also reduce connection setup time, by negotiating a whole
stack of services at once.
The Need for Negotiation
ISAKMP extends the previous assertion that authentication and key exchanges must be
combined for better security to include security association exchanges. The security services
required for communications depend on the individual network configurations and
environments. Organizations are setting up Virtual Private Networks (VPN), also known as
Intranets, that will require one set of security functions for communications within the VPN
and possibly many different security functions for communications outside the VPN to
support geographically separate organizational components, customers, suppliers, subcontractors (with their own VPNs), government, and others. Departments within large
organizations may require a number of security associations to separate and protect data (e.g.
personnel data, company proprietary data, medical) on internal networks and other security
associations to communicate within the same department. Nomadic users wanting to "phone
home" represent another set of security requirements. These requirements must be tempered
with bandwidth challenges. Smaller groups of people may meet their security requirements by
setting up "Webs of Trust".
ISAKMP exchanges provide these assorted networking communities the ability to present
peers with the security functionality that the user supports in an authenticated and protected
manner for agreement upon a common set of security attributes, i.e. an interoperable security
association.
Page 100 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
What can be negotiated?
Security associations must support different encryption algorithms, authentication
mechanisms, and key establishment algorithms for other security protocols, as well as IP
Security. Security associations must also support host-oriented certificates for lower layer
protocols and user- oriented certificates for higher-level protocols.
Algorithm and mechanism independence is required in applications such as e-mail, remote
login, and file transfer, as well as in session oriented protocols, routing protocols, and link
layer protocols.
ISAKMP provides a common security association and key establishment protocol for this
wide range of security protocols, applications, security requirements, and network
environments.
ISAKMP is not bound to any specific cryptographic algorithm, key generation technique, or
security mechanism. This flexibility is beneficial for a number of reasons. First, it supports the
dynamic communications environment described above. Second, the independence from
specific security mechanisms and algorithms provides a forward migration path to better
mechanisms and algorithms. When improved security mechanisms are developed or new
attacks against current encryption algorithms, authentication mechanisms and key exchanges
are discovered, ISAKMP will allow the updating of the algorithms and mechanisms without
having to develop a completely new KMP or patch the current one.
ISAKMP has basic requirements for its authentication and key exchange components. These
requirements guard against denial of service, replay / reflection, man-in-the-middle, and
connection hijacking attacks. This is important because these are the types of attacks that are
targeted against protocols. Complete Security Association (SA) support, which provides
mechanism and algorithm independence, and protection from protocol threats are the strengths
of ISAKMP.
Security Associations and Management
A Security Association (SA) is a relationship between two or more entities that describes how
the entities will utilize security services to communicate securely. This relationship is
represented by a set of information that can be considered a contract between the entities. The
information must be agreed upon and shared between all the entities. Sometimes the
information alone is referred to as an SA, but this is just a physical instantiation of the existing
relationship. The existence of this relationship, represented by the information, is what
provides the agreed upon security information needed by entities to securely interoperate. All
entities must adhere to the SA for secure communications to be possible. When accessing SA
attributes, entities use a pointer or identifier referred to as the Security Parameter Index (SPI).
Security Associations and Registration
The attributes specified for an IP Security SA include, but are not limited to, authentication
mechanism, cryptographic algorithm, algorithm mode, key length, and Initialization Vector
(IV). Other protocols that provide algorithm and mechanism independent security must define
their requirements for SA attributes. The separation of ISAKMP from a specific SA definition
Page 101 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
is important to ensure ISAKMP can establish SAs for all possible security protocols and
applications.
In order to facilitate easy identification of specific attributes (e.g. a specific encryption
algorithm) among different network entities the attributes must be assigned identifiers and a
central authority must register these identifiers. The Internet Assigned Numbers Authority
(IANA) provides this function for the Internet.
ISAKMP Requirements
Security Association (SA) establishment must be part of the key management protocol
defined for IP based networks. The SA concept is required to support security protocols in
a diverse and dynamic networking environment. Just as authentication and key exchange
must be linked to provide assurance that the key is established with the authenticated
party, SA establishment must be linked with the authentication and the key exchange
protocol.
ISAKMP provides the protocol exchanges to establish a security association between
negotiating entities followed by the establishment of a security association by these
negotiating entities in behalf of some protocol (e.g. ESP/AH). First, an initial protocol
exchange allows a basic set of security attributes to be agreed upon. This basic set
provides protection for subsequent ISAKMP exchanges. It also indicates the
authentication method and key exchange that will be performed as part of the ISAKMP
protocol. If a basic set of security attributes is already in place between the negotiating
server entities, the initial ISAKMP exchange may be skipped and the establishment of a
security association can be done directly. After the basic set of security attributes has been
agreed upon, initial identity authenticated, and required keys generated, the established
SA can be used for subsequent communications by the entity that invoked ISAKMP. The
basic set of SA attributes that must be implemented to provide ISAKMP interoperability
is later.
Authentication
A very important step in establishing secure network communications is authentication of the
entity at the other end of the communication. Many authentication mechanisms are available.
Authentication mechanisms fall into two categories of strength – weak and strong. Sending
cleartext keys or other unprotected authenticating information over a network is weak, due to
the threat of reading them with a network sniffer. Additionally, sending one-way hashed
poorly chosen keys with low entropy is also weak, due to the threat of brute-force guessing
attacks on the sniffed messages. While passwords can be used for establishing identity, they
are not considered in this context because of recent statements from the Internet Architecture
Board. Digital signatures, such as the Digital Signature Standard (DSS) and the RivestShamir-Adleman (RSA) signature, are public key based strong authentication mechanisms.
When using public key digital signatures each entity requires a public key and a private key.
Certificates are an essential part of a digital signature authentication mechanism. Certificates
bind a specific entity's identity (be it host, network, user, or application) to its public keys and
possibly other security-related information such as privileges, clearances, and compartments.
Authentication based on digital signatures requires a trusted third party or certificate authority
to create, sign and properly distribute certificates.
Page 102 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Certificate Authorities
Certificates require an infrastructure for generation, verification, revocation, management
and distribution. The Internet Policy Registration Authority (IPRA) has been established
to direct this infrastructure for the IETF. The IPRA certifies Policy Certification
Authorities (PCA). PCAs control Certificate Authorities (CA) that certify users and
subordinate entities. Current certificate related work includes the Domain Name System
(DNS) Security Extensions that will provide signed entity keys in the DNS. The Public
Key Infrastructure (PKIX) working group is specifying an Internet profile for X.509
certificates. There is also work going on in industry to develop X.500 Directory Services
which would provide X.509 certificates to users. The U.S. Post Office is developing a
(CA) hierarchy. The NIST Public Key Infrastructure Working Group has also been doing
work in this area. The DOD Multi Level Information System Security Initiative (MISSI)
program has begun deploying a certificate infrastructure for the U.S. Government.
Alternatively, if no infrastructure exists, the PGP Web of Trust certificates can be used to
provide user authentication and privacy in a community of users who know and trust each
other.
Entity Naming
An entity's name is its identity and is bound to its public keys in certificates. The CA must
define the naming semantics for the certificates it issues. When the certificate is verified,
the name is verified and that name will have meaning within the realm of that CA. An
example is the DNS security extensions that make DNS servers CAs for the zones and
nodes they serve. Resource records are provided for public keys and signatures on those
keys. The names associated with the keys are IP addresses and domain names that have
meaning to entities accessing the DNS for this information. A Web of Trust is another
example. When webs of trust are set up, names are bound with the public keys. In PGP
the name is usually the entity's e-mail address that has meaning to those, and only those,
who understand e-mail. Another web of trust could use an entirely different naming
scheme.
ISAKMP Requirements
Strong authentication must be provided on ISAKMP exchanges. Without being able to
authenticate the entity at the other end, the Security Association (SA) and session key
established are suspect. Without authentication you are unable to trust an entity's
identification, which makes access control questionable. While encryption (e.g. ESP) and
integrity (e.g. AH) will protect subsequent communications from passive eavesdroppers,
without authentication it is possible that the SA and key may have been established with
an adversary who performed an active man-in-the-middle attack and is now stealing all
your personal data.
A digital signature algorithm must be used within ISAKMP's authentication component.
However, ISAKMP does not mandate a specific signature algorithm or certificate
authority (CA). ISAKMP allows an entity initiating communications to indicate which
CAs it supports. After selection of a CA, the protocol provides the messages required to
support the actual authentication exchange. The protocol provides a facility for
Page 103 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
identification of different certificate authorities, certificate types (e.g. X.509, PKCS #7,
PGP, DNS SIG and KEY records), and the exchange of the certificates identified.
ISAKMP utilizes digital signatures, based on public key cryptography, for authentication.
There are other strong authentication systems available, which could be specified as
additional optional authentication mechanisms for ISAKMP. Some of these authentication
systems rely on a trusted third party called a key distribution center (KDC) to distribute
secret session keys. An example is Kerberos, where the trusted third party is the Kerberos
server, which holds secret keys for all clients and servers within its network domain. A
client's proof that it holds its secret key provides authentication to a server.
The ISAKMP specification does not specify the protocol for communicating with the
trusted third parties (TTP) or certificate directory services. These protocols are defined by
the TTP and directory service themselves and are outside the scope of this specification.
The use of these additional services and protocols will be described in a Key Exchange
specific document.
Public Key Cryptography
Public key cryptography is the most flexible, scalable, and efficient way for users to obtain the
shared secrets and session keys needed to support the large number of ways Internet users will
interoperate. Many key generation algorithms, that have different properties, are available to
users. Properties of key exchange protocols include the key establishment method,
authentication, symmetry, perfect forward secrecy, and back traffic protection.
Key Exchange Properties
Key Establishment (Key Generation / Key Transport): The two common methods of using
public key cryptography for key establishment are key transport and key generation. An
example of key transport is the use of the RSA algorithm to encrypt a randomly generated
session key (for encrypting subsequent communications) with the recipient's public key.
The encrypted random key is then sent to the recipient, who decrypts it using his private
key. At this point both sides have the same session key, however it was created based on
input from only one side of the communications. The benefit of the key transport method
is that it has less computational overhead than the following method. The Diffie-Hellman
(D-H) algorithm illustrates key generation using public key cryptography. Two users
exchanging public information begin the D-H algorithm. Each user then mathematically
combines the other's public information along with their own secret information to
compute a shared secret value. This secret value can be used as a session key or as a key
encryption key for encrypting a randomly generated session key. This method generates a
session key based on public and secret information held by both users. The benefit of the
D-H algorithm is that the key used for encrypting messages is based on information held
by both users and the independence of keys from one key exchange to another provides
perfect forward secrecy. There are a number of variations on these two key generation
schemes and these variations do not necessarily interoperate.
Key Exchange Authentication: Key exchanges may be authenticated during the protocol
or after protocol completion. Authentication of the key exchange during the protocol is
provided when each party provides proof it has the secret session key before the end of the
Page 104 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
protocol. Encrypting known data in the secret session key during the protocol exchange
can provide proof. Authentication after the protocol must occur in subsequent
communications. Authentication during the protocol is preferred so subsequent
communications are not initiated if the secret session key is not established with the
desired party.
Key Exchange Symmetry: A key exchange provides symmetry if either party can initiate
the exchange and exchanged messages can cross in transit without affecting the key that is
generated. This is desirable so that computation of the keys does not require either party to
know who initiated the exchange. While key exchange symmetry is desirable, symmetry
in the entire key management protocol may provide vulnerablity to reflection attacks.
Perfect Forward Secrecy: An authenticated key exchange protocol provides perfect
forward secrecy if disclosure of long-term secret keying material does not compromise the
secrecy of the exchanged keys from previous communications. The property of perfect
forward secrecy does not apply to key exchange without authentication.
ISAKMP Requirements
An authenticated key exchange must be supported by ISAKMP. Users should choose
additional key establishment algorithms based on their requirements. ISAKMP does not
specify a specific key exchange. However, IKE describes a proposal for using the Oakley
key exchange in conjunction with ISAKMP. Requirements that should be evaluated when
choosing a key establishment algorithm include establishment method (generation vs.
transport), perfect forward secrecy, computational overhead, key escrow, and key strength.
Based on user requirements, ISAKMP allows an entity initiating communications to
indicate which key exchanges it supports. After selection of a key exchange, the protocol
provides the messages required to support the actual key establishment.
ISAKMP Protection
Anti-Clogging (Denial of Service)
Of the numerous security services available, protection against denial of service always
seems to be one of the most difficult to address. A "cookie" or anti-clogging token (ACT)
is aimed at protecting the computing resources from attack without spending excessive
CPU resources to determine its authenticity. An exchange prior to CPU-intensive public
key operations can thwart some denial of service attempts (e.g. simple flooding with
bogus IP source addresses). Absolute protection against denial of service is impossible,
but this anti-clogging token provides a technique for making it easier to handle.
Connection Hijacking
ISAKMP prevents connection hijacking by linking the authentication, key exchange and
security association exchanges. This linking prevents an attacker from allowing the
authentication to complete and then jumping in and impersonating one entity to the other
during the key and security association exchanges.
Man-in-the-Middle Attacks
Page 105 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Man-in-the-Middle attacks include interception, insertion, deletion, and modification of
messages, reflecting messages back at the sender, replaying old messages and redirecting
messages. ISAKMP features prevent these types of attacks from being successful. The
linking of the ISAKMP exchanges prevents the insertion of messages in the protocol
exchange. The ISAKMP protocol state machine is defined so deleted messages will not
cause a partial SA to be created, the state machine will clear all state and return to idle.
The state machine also prevents reflection of a message from causing harm. The
requirement for a new cookie with time variant material for each new SA establishment
prevents attacks that involve replaying old messages. The ISAKMP strong authentication
requirement prevents an SA from being established with anyone other than the intended
party. Messages may be redirected to a different destination or modified but this will be
detected and an SA will not be established. The ISAKMP specification defines where
abnormal processing has occurred and recommends notifying the appropriate party of this
abnormality.
Multicast Communications
It is expected that multicast communications will require the same security services as unicast
communications and may introduce the need for additional security services. The issues of
distributing SPIs for multicast traffic are presented above.
2.8.8.2. ISAKMP Concepts
Negotiation Phases
ISAKMP offers two "phases" of negotiation. In the first phase, two entities (e.g. ISAKMP
servers) agree on how to protect further negotiation traffic between them, establishing an
ISAKMP SA. This ISAKMP SA is then used to protect the negotiations for the Protocol SA
being requested. Two entities (e.g. ISAKMP servers) can negotiate (and have active) multiple
ISAKMP SAs.
The second phase of negotiation is used to establish security associations for other security
protocols. This second phase can be used to establish many security associations. The security
associations established by ISAKMP during this phase can be used by a security protocol to
protect many message/data exchanges.
While the two-phased approach has a higher start-up cost for most simple scenarios, there are
several reasons that it is beneficial for most cases.
First, entities (e.g. ISAKMP servers) can amortize the cost of the first phase across several
second phase negotiations. This allows multiple SAs to be established between peers over
time without having to start over for each communication.
Second, security services negotiated during the first phase provide security properties for the
second phase. For example, after the first phase of negotiation, the encryption provided by the
ISAKMP SA can provide identity protection, potentially allowing the use of simpler secondphase exchanges. On the other hand, if the channel established during the first phase is not
adequate to protect identities, then the second phase must negotiate adequate security
mechanisms.
Page 106 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Third, having an ISAKMP SA in place considerably reduces the cost of ISAKMP
management activity - without the "trusted path" that an ISAKMP SA gives you; the entities
(e.g. ISAKMP servers) would have to go through a complete re-authentication for each error
notification or deletion of an SA.
Negotiation during each phase is accomplished using ISAKMP-defined exchanges or
exchanges defined for a key exchange within a DOI.
Note that security services may be applied differently in each negotiation phase. For example,
different parties are being authenticated during each of the phases of negotiation. During the
first phase, the parties being authenticated may be the ISAKMP servers/hosts, while during
the second phase, users or application level programs are being authenticated.
Identifying Security Associations
While bootstrapping secure channels between systems, ISAKMP cannot assume the existence
of security services, and must provide some protections for itself. Therefore, ISAKMP
considers an ISAKMP Security Association to be different than other types, and manages
ISAKMP SAs itself, in their own name space. ISAKMP uses the two cookie fields in the
ISAKMP header to identify ISAKMP SAs. The Message ID in the ISAKMP Header and the
SPI field in the Proposal payload are used during SA establishment to identify the SA for
other security protocols. The interpretation of these four fields is dependent on the operation
taking place.
During the SA establishment, a SPI must be generated. ISAKMP is designed to handle
variable sized SPIs. This is accomplished by using the SPI Size field within the Proposal
payload during SA establishment. Handling of SPIs will be outlined by the DOI specification.
When a security association (SA) is initially established, one side assumes the role of initiator
and the other the role of responder. Once the SA is established, both the original initiator and
responder can initiate a phase 2 negotiations with the peer entity. Thus, ISAKMP SAs are bidirectional in nature.
Additionally, ISAKMP allows both initiator and responder to have some control during the
negotiation process. While ISAKMP is designed to allow an SA negotiation that includes
multiple proposals, the initiator can maintain some control by only making one proposal in
accordance with the initiator's local security policy. Once the initiator sends a proposal
containing more than one proposal (which are sent in decreasing preference order), the
initiator relinquishes control to the responder. Once the responder is controlling the SA
establishment, the responder can make its policy take precedence over the initiator within the
context of the multiple options offered by the initiator. Selecting the proposal best suited for
the responder’s local security policy and returning this selection to the initiator accomplish
this.
Page 107 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Miscellaneous
Transport Protocol
ISAKMP can be implemented over any transport protocol or over IP itself.
Implementations must include send and receive capability for ISAKMP using the User
Datagram Protocol (UDP) on port 500. The Internet Assigned Numbers Authority (IANA)
has assigned UDP Port 500 to ISAKMP. Implementations may additionally support
ISAKMP over other transport protocols or over IP itself.
Anti-Clogging Token ("Cookie") Creation
The details of cookie generation are implementation dependent, but must satisfy these
basic requirements:
1. The cookie must depend on the specific parties. This prevents an attacker from
obtaining a cookie using a real IP address and UDP port, and then using it to swamp
the victim with Diffie-Hellman requests from randomly chosen IP addresses or ports.
2. It must not be possible for anyone other than the issuing entity to generate cookies
that will be accepted by that entity. This implies that the issuing entity must use local
secret information in the generation and subsequent verification of a cookie. It must
not be possible to deduce this secret information from any particular cookie.
3. The cookie generation function must be fast to thwart attacks intended to
sabotage CPU resources.
2.8.8.3. Security Considerations
Cryptographic analysis techniques are improving at a steady pace. The continuing
improvement in processing power makes once computationally prohibitive cryptographic
attacks more realistic. New cryptographic algorithms and public key generation techniques are
also being developed at a steady pace. New security services and mechanisms are being
developed at an accelerated pace. A consistent method of choosing from a variety of security
services and mechanisms and to exchange attributes required by the mechanisms is important
to security in the complex structure of the Internet. However, a system that locks itself into a
single cryptographic algorithm, key exchange technique, or security mechanism will become
increasingly vulnerable as time passes.
UDP is an unreliable datagram protocol and therefore its use in ISAKMP introduces a number
of security considerations. Since UDP is unreliable, but a key management protocol must be
reliable, the reliability is built into ISAKMP. While ISAKMP utilizes UDP as its transport
mechanism, it doesn't rely on any UDP information (e.g. checksum, length) for it’s
processing.
Another issue that must be considered in the development of ISAKMP is the effect of
firewalls on the protocol. Many firewalls filter out all UDP packets, making reliance on UDP
questionable in certain environments.
Page 108 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
A number of very important security considerations are presented in above. One bears
repeating. Once a private session key is created, it must be safely stored. Failure to properly
protect the private key from access both internal and external to the system completely
nullifies any protection provided by the IP Security services.
2.8.8.4. Conclusions
The Internet Security Association and Key Management Protocol (ISAKMP) is a well
designed protocol aimed at the Internet of the future. The massive growth of the Internet will
lead to great diversity in network utilization, communications, security requirements, and
security mechanisms. ISAKMP contains all the features that will be needed for this dynamic
and expanding communications environment.
ISAKMP's Security Association (SA) feature coupled with authentication and key
establishment provides the security and flexibility that will be needed for future growth and
diversity. This security diversity of multiple key exchange techniques, encryption algorithms,
authentication mechanisms, security services, and security attributes will allow users to select
the appropriate security for their network, communications, and security needs. The SA
feature allows users to specify and negotiate security requirements with other users. An
additional benefit of supporting multiple techniques in a single protocol is that as new
techniques are developed they can easily be added to the protocol. This provides a path for the
growth of Internet security services. ISAKMP supports both publicly or privately defined SAs,
making it ideal for government, commercial, and private communications.
ISAKMP provides the ability to establish SAs for multiple security protocols and applications.
These protocols and applications may be session-oriented or sessionless. Having one SA
establishment protocol that supports multiple security protocols eliminates the need for
multiple, nearly identical authentication, key exchange and SA establishment protocols when
more than one security protocol is in use or desired. Just as IP has provided the common
networking layer for the Internet, a common security establishment protocol is needed if
security is to become a reality on the Internet. ISAKMP provides the common base that allows
all other security protocols to interoperate.
ISAKMP follows good security design principles. It is not coupled to other insecure transport
protocols; therefore it is not vulnerable or weakened by attacks on other protocols. Also, when
more secure transport protocols are developed, ISAKMP can be easily migrated to them.
ISAKMP also provides protection against protocol related attacks. This protection provides
the assurance that the SAs and keys established are with the desired party and not with an
attacker.
ISAKMP also follows good protocol design principles. Protocol specific information only is
in the protocol header, following the design principles of IPv6. The data transported by the
protocol is separated into functional payloads. As the Internet grows and evolves, new
payloads to support new security functionality can be added without modifying the entire
protocol.
Page 109 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.8.9. The Internet Key Exchange (IKE)
2.8.9.1. Introduction
ISAKMP provides a framework for authentication and key exchange but does not define
them. ISAKMP is designed to be key exchange independent; that is, it is designed to support
many different key exchanges.
Oakley describes a series of key exchanges—called "modes"-- and details the services
provided by each (e.g. perfect forward secrecy for keys, identity protection, and
authentication).
SKEME describes a versatile key exchange technique that provides anonymity, repudiability,
and quick key refreshment.
This section describes a protocol using part of Oakley and part of SKEME in conjunction with
ISAKMP to obtain authenticated keying material for use with ISAKMP, and for other security
associations such as AH and ESP for the IETF IPsec DOI.
2.8.9.2. Discussion
Processes that implement IKE can be used for negotiating virtual private networks (VPNs)
and also for providing a remote user from a remote site (whose IP address need not be known
beforehand) access to a secure host or network.
Client negotiation is supported. Client mode is where the negotiating parties are not the
endpoints for which security association negotiation is taking place. When used in client
mode, the identities of the end parties remain hidden.
This does not implement the entire Oakley protocol, but only a subset necessary to satisfy its
goals. It does not claim conformance or compliance with the entire Oakley protocol nor is it
dependant in any way on the Oakley protocol.
Likewise, this does not implement the entire SKEME protocol, but only the method of public
key encryption for authentication and its concept of fast re-keying using an exchange of
nonces. This protocol is not dependant in any way on the SKEME protocol.
2.8.9.3. Terms and Definitions
Perfect Forward Secrecy
When used in the memo Perfect Forward Secrecy (PFS) refers to the notion that compromise
of a single key will permit access to only data protected by a single key. For PFS to exist the
key used to protect transmission of data must not be used to derive any additional keys, and if
the key used to protect transmission of data was derived from some other keying material, that
material must not be used to derive any more keys.
Perfect Forward Secrecy for both keys and identities is provided in this protocol.
Page 110 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Security Association
A security association (SA) is a set of policy and key(s) used to protect information. The
ISAKMP SA is the shared policy and key(s) used by the negotiating peers in this protocol to
protect their communication.
2.8.9.4. more detailed introduction
Oakley and SKEME each define a method to establish an authenticated key exchange. This
includes payloads construction, the information payloads carry, and the order in which they
are processed and how they are used.
While Oakley defines "modes", ISAKMP defines "phases". The relationship between the two
is very straightforward and IKE presents different exchanges as modes that operate in one of
two phases.
Phase 1 is where the two ISAKMP peers establish a secure, authenticated channel with which
to communicate. This is called the ISAKMP Security Association (SA). "Main Mode" and
"Aggressive Mode" each accomplish a phase 1 exchange. "Main Mode" and "Aggressive
Mode" must only be used in phase 1.
Phase 2 is where Security Associations are negotiated on behalf of services such as IPsec or
any other service that needs key material and/or parameter negotiation. "Quick Mode"
accomplishes a phase 2 exchange. "Quick Mode" must only be used in phase 2.
"New Group Mode" is not really a phase 1 or phase 2. It follows phase 1, but serves to
establish a new group that can be used in future negotiations. "New Group Mode" must only
be used after phase 1.
The ISAKMP SA is bi-directional. That is, once established, either party may initiate Quick
Mode, Informational, and New Group Mode Exchanges. Per the base ISAKMP document, the
ISAKMP SA is identified by the Initiator's cookie followed by the Responder's cookie—the
role of each party in the phase 1 exchange dictates which cookie is the Initiator's. The cookie
order established by the phase 1 exchange continues to identify the ISAKMP SA regardless of
the direction the Quick Mode, Informational, or New Group exchange. In other words, the
cookies must not swap places when the direction of the ISAKMP SA changes.
With the use of ISAKMP phases, an implementation can accomplish very fast keying when
necessary. A single phase 1 negotiation may be used for more than one phase 2 negotiation.
Additionally a single phase 2 negotiation can request multiple Security Associations. With
these optimizations, an implementation can see less than one round trip per SA as well as less
than one DH exponentiation per SA. "Main Mode" for phase 1 provides identity protection.
When identity protection is not needed, "Aggressive Mode" can be used to reduce round trips
even further. Developer hints for doing these optimizations are included below. It should also
be noted that using public key encryption to authenticate an Aggressive Mode exchange will
still provide identity protection.
This protocol does not define its own DOI per se. The ISAKMP SA, established in phase 1,
may use the DOI and situation from a non-ISAKMP service (such as the IETF IPsec DOI). In
Page 111 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
this case an implementation may choose to restrict use of the ISAKMP SA for establishment
of SAs for services of the same DOI. Alternately, an ISAKMP SA may be established with the
value zero in both the DOI and situation and in this case implementations will be free to
establish security services for any defined DOI using this ISAKMP SA. If a DOI of zero is
used for establishment of a phase 1 SA, the syntax of the identity payloads used in phase 1 is
that defined in and not from any DOI that may further expand the syntax and semantics of
identities.
The following attributes are used by IKE and are negotiated as part of the ISAKMP Security
Association. (These attributes pertain only to the ISAKMP Security Association and not to
any Security Associations that ISAKMP may be negotiating on behalf of other services.)
·
Encryption algorithm
·
Hash algorithm
·
Authentication method
·
Information about a group over which to do Diffie-Hellman.
All of these attributes are mandatory and must be negotiated. In addition, it is possible to
optionally negotiate a pseudo-random function ("prf"). (There are currently no negotiable
pseudo-random functions defined in this document. Private use attribute values can be used
for prf negotiation between consenting parties). If a "prf" is not negotiation, the HMAC
version of the negotiated hash algorithm is used as a pseudo-random function. Other nonmandatory attributes are described in Appendix A. The selected hash algorithm must support
both native and HMAC modes.
The Diffie-Hellman group must be either specified using a defined group description or by
defining all attributes of a group. Group attributes (such as group type or prime must not be
offered in conjunction with a previously defined group (either a reserved group description or
a private use description that is established after conclusion of a New Group Mode exchange).
IKE implementations must support the following attribute values:
·
DES in CBC mode with a weak, and semi-weak, key check.
·
MD5 and SHA.
·
Authentication via pre-shared keys.
·
MODP over default group number one (see below).
In addition, IKE implementations should support: 3DES for encryption; Tiger for hash; the
Digital Signature Standard, RSA signatures and authentication with RSA public key
encryption; and MODP group number 2. IKE implementations may support any additional
encryption algorithms defined in Appendix A and may support ECP and EC2N groups.
The IKE modes described here must be implemented whenever the IETF IPsec DOI is
implemented. Other DOIs may use the modes described here.
Page 112 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
2.8.9.5. Exchanges
There are two basic methods used to establish an authenticated key exchange: Main Mode and
Aggressive Mode. Each generates authenticated keying material from an ephemeral DiffieHellman exchange. Main Mode must be implemented; Aggressive Mode should be
implemented. In addition, Quick Mode must be implemented as a mechanism to generate
fresh keying material and negotiate non-ISAKMP security services. In addition, New Group
Mode should be implemented as a mechanism to define private groups for Diffie-Hellman
exchanges. Implementations must not switch exchange types in the middle of an exchange.
Exchanges conform to standard ISAKMP payload syntax, attribute encoding, timeouts and
retransmits of messages, and informational messages-- e.g. a notify response is sent when, for
example, a proposal is unacceptable, or a signature verification or decryption was
unsuccessful, etc.
The SA payload must precede all other payloads in a phase 1 exchange. Except where
otherwise noted, there are no requirements for ISAKMP payloads in any message to be in any
particular order.
The Diffie-Hellman public value passed in a KE payload, in either a phase 1 or phase 2
exchange, must be the length of the negotiated Diffie-Hellman group enforced, if necessary,
by pre-pending the value with zeros.
The length of nonce payload must be between 8 and 256 bytes inclusive.
Main Mode is an instantiation of the ISAKMP Identity Protect Exchange: The first two
messages negotiate policy; the next two exchange Diffie-Hellman public values and ancillary
data (e.g. nonces) necessary for the exchange; and the last two messages authenticate the
Diffie-Hellman Exchange. The authentication method negotiated as part of the initial
ISAKMP exchange influences the composition of the payloads but not their purpose. The
XCHG for Main Mode is ISAKMP Identity Protect.
Similarly, Aggressive Mode is an instantiation of the ISAKMP Aggressive Exchange. The
first two messages negotiate policy, exchange Diffie-Hellman public values and ancillary data
necessary for the exchange, and identities. In addition the second message authenticates the
responder. The third message authenticates the initiator and provides a proof of participation
in the exchange. The XCHG for Aggressive Mode is ISAKMP Aggressive. The final message
may not be sent under protection of the ISAKMP SA allowing each party to postpone
exponentiation, if desired, until negotiation of this exchange is complete. The graphic
depictions of Aggressive Mode show the final payload in the clear; it need not be.
Exchanges in IKE are not open-ended and have a fixed number of messages. Receipt of a
Certificate Request payload must not extend the number of messages transmitted or expected.
Security Association negotiation is limited with Aggressive Mode. Due to message
construction requirements the group in which the Diffie-Hellman exchange is performed
cannot be negotiated. In addition, different authentication methods may further constrain
attribute negotiation. For example, authentication with public key encryption cannot be
negotiated and when using the revised method of public key encryption for authentication the
Page 113 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
cipher and hash cannot be negotiated. For situations where the rich attribute negotiation
capabilities of IKE are required Main Mode may be required.
Quick Mode and New Group Mode have no analog in ISAKMP. Main Mode, Aggressive
Mode, and Quick Mode do security association negotiation. Security Association offers take
the form of Transform Payload(s) encapsulated in Proposal Payload(s) encapsulated in
Security Association (SA) payload(s). If multiple offers are being made for phase 1 exchanges
(Main Mode and Aggressive Mode) they must take the form of multiple Transform Payloads
for a single Proposal Payload in a single SA payload. To put it another way, for phase 1
exchanges there must not be multiple Proposal Payloads for a single SA payload and there
must not be multiple SA payloads. This document does not proscribe such behavior on offers
in phase 2 exchanges.
There is no limit on the number of offers the initiator may send to the responder but
conformant implementations may choose to limit the number of offers it will inspect for
performance reasons.
During security association negotiation, initiators present offer for potential security
associations to responders. Responders must not modify attributes of any offer, attribute
encoding excepted. If the initiator of an exchange notices that attribute values have changed or
attributes have been added or deleted from an offer made, that response must be rejected.
Four different authentication methods are allowed with either Main Mode or Aggressive
Mode-- digital signature, two forms of authentication with public key encryption, or preshared key.
The negotiated authentication method influences the content and use of messages for Phase 1
Modes, but not their intent. When using public keys for authentication, the Phase 1 exchange
can be accomplished either by using signatures or by using public key encryption (if the
algorithm supports it). Following are Phase 1 exchanges with different authentication options.
2.8.9.6. Implementation Hints
Using a single ISAKMP Phase 1 negotiation makes subsequent Phase 2 negotiations
extremely quick. As long as the Phase 1 state remains cached, and PFS is not needed, Phase 2
can proceed without any exponentiation. How many Phase 2 negotiations can be performed
for a single Phase 1 is a local policy issue. The decision will depend on the strength of the
algorithms being used and level of trust in the peer system.
An implementation may wish to negotiate a range of SAs when performing Quick Mode. By
doing this they can speed up the "re-keying". Quick Mode defines how KEYMAT is defined
for a range of SAs. When one peer feels it is time to change SAs they simply use the next one
within the stated range. A range of SAs can be established by negotiating multiple SAs
(identical attributes, different SPIs) with one Quick Mode.
An optimization that is often useful is to establish Security Associations with peers before
they are needed so that when they become needed they are already in place. This ensures there
would be no delays due to key management before initial data transmission. This optimization
is easily implemented by setting up more than one Security Association with a peer for each
requested Security Association and caching those not immediately used.
Page 114 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Also, if an ISAKMP implementation is alerted that a SA will soon be needed (e.g. to replace
an existing SA that will expire in the near future), and then it can establish the new SA before
that new SA is needed.
The base ISAKMP specification describes conditions in which one party of the protocol may
inform the other party of some activity—either deletion of a security association or in
response to some error in the protocol such as a signature verification failed or a payload
failed to decrypt. It is strongly suggested that these Informational exchanges not be responded
to under any circumstances. Such a condition may result in a "notify war" in which failure to
understand a message results in a notify to the peer who cannot understand it and sends his
own notify back which is also not understood.
2.8.9.7. Security Considerations
This entire memo discusses a hybrid protocol, combining parts of Oakley and parts of
SKEME with ISAKMP, to negotiate, and derive keying material for, security associations in a
secure and authenticated manner.
Confidentiality is assured by the use of a negotiated encryption algorithm. Authentication is
assured by the use of a negotiated method: a digital signature algorithm; a public key
algorithm that supports encryption; or, a pre-shared key. The confidentiality and
authentication of this exchange is only as good as the attributes negotiated as part of the
ISAKMP security association.
Repeated re-keying using Quick Mode can consume the entropy of the Diffie-Hellman shared
secret. Implementers should take note of this fact and set a limit on Quick Mode Exchanges
between exponentiations.
Perfect Forward Secrecy (PFS) of both keying material and identities is possible with this
protocol. By specifying a Diffie-Hellman group, and passing public values in KE payloads,
ISAKMP peers can establish PFS of keys-- the identities would be protected by SKEYID_e
from the ISAKMP SA and would therefore not be protected by PFS. If PFS of both keying
material and identities is desired, an ISAKMP peer must establish only one non-ISAKMP
security association (e.g. IPsec Security Association) per ISAKMP SA. PFS for keys and
identities is accomplished by deleting the ISAKMP SA (and optionally issuing a DELETE
message) upon establishment of the single non-ISAKMP SA. In this way a phase one
negotiation is uniquely tied to a single-phase two negotiation, and the ISAKMP SA
established during phase one negotiation is never used again.
The strength of a key derived from a Diffie-Hellman exchange using any of the groups defined
here depends on the inherent strength of the group, the size of the exponent used, and the
entropy provided by the random number generator used. Due to these inputs it is difficult to
determine the strength of a key for any of the defined groups. The default Diffie-Hellman
group (number one) when used with a strong random number generator and an exponent no
less than 160 bits is sufficient to use for DES. Groups two through four provide greater
security. Implementations should make note of these conservative estimates when establishing
policy and negotiating security parameters.
Note that these limitations are on the Diffie-Hellman groups themselves. There is nothing in
IKE that neither prohibits using stronger groups nor is there anything which will dilute the
Page 115 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
strength obtained from stronger groups. In fact, the extensible framework of IKE encourages
the definition of more groups; use of elliptical curve groups will greatly increase strength
using much smaller numbers.
For situations where defined groups provide insufficient strength New Group Mode can be
used to exchange a Diffie-Hellman group that provides the necessary strength. In is incumbent
upon implementations to check the primality in groups being offered and independently arrive
at strength estimates.
It is assumed that the Diffie-Hellman exponents in this exchange are erased from memory
after use. In particular, these exponents must not be derived from long-lived secrets like the
seed to a pseudo-random generator.
IKE exchanges maintain running initialization vectors (IV) where the last ciphertext block of
the last message is the IV for the next message. To prevent retransmissions (or forged
messages with valid cookies) from causing exchanges to get out of sync IKE implementations
should not update their running IV until the decrypted message has passed a basic sanity
check and has been determined to actually advance the IKE state machine-- i.e. it is not a
retransmission.
While the last roundtrip of Main Mode (and optionally the last message of Aggressive Mode)
is encrypted it is not, strictly speaking, authenticated. An active substitution attack on the
ciphertext could result in payload corruption. If such an attack corrupts mandatory payloads it
would be detected by an authentication failure, but if it corrupts any optional payloads (e.g.
notify payloads chained onto the last message of a Main Mode exchange) it might not be
detectable.
2.8.10. Future Developments
Despite being the second generation of IPsec, the present version continues to have some
problems for which solutions are been searched. This section introduces some of these
problems and some possible solutions for them.
One of the biggest problems faced by IPsec is NAT traversal! There are several drafts
available on the IETF (http://www.ietf.org) that propose solutions for this problem and it is
expected that in a near future one or more standards may emerge to clear it.
Another aspect of IPsec that is being actively developed is a replacement for IKE (which is
deemed by many as insecure). At this point there are already several proposals for new Key
Exchange Protocols (son-of-IKE, JFK), while others attempt to improve IKE itself.
There are also some draft proposals for the use of new authentication and encryption protocols
on IPsec (like OpenPGP, AES and others).
Page 116 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
1.1.1
IPsec support
2.8.10.1. Operating Systems
*BSD
Support for IPSec in most of the BSD variants is provided through the work of the Kame
project (http://www.kame.org).
The latest release of the Kame Project provides an IPsec implementation that works well for
both IPv4 and IPv6. According to the web page of the project, most algorithms on RFC are
covered and tests were already performed with success.
The Kame Project also provides an IKE daemon that, according to them, still needs some
stabilization but has already been tested with a certain amount of success.
Linux
There are presently two different projects working on IPsec for Linux: the Usagi Project
(http://www.linux-ipv6.org), which is working on a full featured IPv6 stack, and the
FreeS/WAN project (http://www.freeswan.org), which working on an IPsec implementation
only.
The latest Usagi kernel supports only a very basic set of IPsec, allowing only manual keying
and only transport mode between two hosts.
The latest release of FreeS/WAN provides an IPv4/IPv6 IPsec implementation and also an
IKE daemon implementation. The big issue for FreeS/WAN is that the code is not integrated
with the Linux Kernel IPv6 stack, unlike the Usagi project.
Windows
According to Microsoft Research’s web page (http://www.research.microsoft.com) all
Windows versions (including Windows 9x, NT, 2000 and XP) have support for IPsec, but
only for authentication (both in AH and ESP, tunnel and transport mode). According to the
same page encryption is not supported due to the US export laws.
Solaris
According to Sun’s web page (http://www.sun.com), Solaris 8 already supports IPv6, but the
IPsec version available only works on the IPv4 stack.
2.8.10.2. Router manufacturers
Cisco
Cisco (http://www.cisco.com) has been providing a beta version of it’s IOS router operating
system, with support for IPv6 since mid May 2000 but according to Cisco itself the current
version does not yet support IPsec, although some IPsec configuration instructions have been
found.
Page 117 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Nortel
Nortel (http://www.nortelnetworks.com) claims that they have been producing IPv6 enabled
software since 1997 in the release 12.0 of their BayRS Software. However there is no apparent
support for IPsec on the IPv6 stack.
Firewall Manufacturers
No kind of support for IPsec was found on commercial firewalls.
2.8.11. Scenarios
At this point in the development of IPsec it is not possible to use any transition mechanisms,
since most of them involve some modification of the packets between both ends and IPsec
does not work very well (if at all). In the light of this statement, the scenarios described below
are applicable to an all IPv4 or all IPv6 situation.
The described scenarios are very similar to the four cases presented in Section above and as
such the images will not be repeated in this section. However a more detailed (with possible
real world examples of use) description of each scenario is provided.
Scenario 1
This scenario deals with a connection between two hosts across an insecure medium. This
insecure medium can be either the Internet or a local Intranet.
This is a rare scenario and a possible application could be one user connecting his home
computer to his work computer to synchronize them, transfer some files or remote access.
Scenario 2
The second scenario deals with the connection between two separated local Intranets across
the Internet.
This is the typical VPN scenario and it is quite common amongst companies.
Scenario 3
This scenario deals with a special case of the previous one. Like the previous one, there is a
connection between two separated Intranets, but, unlike the previous one, a secure connection
is made between two hosts inside the Intranet.
One example of such a use is reading e-mail in a secure way. In this situation the traffic is
protected from the insecurity of the Internet (through the first connection, between the
Security Gateways) and at the same time it is protected from the insecurity of the local
Intranets (through the second connection, between the hosts). This scenario is starting to have
a growing interest!
Page 118 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Scenario 4
This is probably the most common scenario of them all. It deals with those situations in witch
a secure connections is established between a host, across the Internet, to a local Intranet and
possibly to a host inside that Intranet.
This scenario is very common for companies that have employees on the road (the so called
“Road Warriors”) and they need to connect to the company’s servers. In some cases the
connection can be simple (just one connection to the Security Gateway) and in others it can be
more complex (two connections: one between the host and the Security Gateway and the other
between both hosts). The choice will be determined by the company’s internal security
policies.
2.8.12. Conclusion
As can be seen from this description, IPsec is a very complete set of protocols for secure
communications not only on IPv6 (where IPsec is mandatory), but also on IPv4 (where IPsec
is optional).
The greatest problem of IPsec is the apparent lack of support, but according to several
manufacturer’s web pages, the support for the latest version of IPsec is on the way and should
be available quite soon.
Page 119 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
3. Application level services
3.1. Web Server
Web servers are used to server the requests of web pages using HTTP (HyperText Transfer
Protocol).
The most used Web Server for Unix systems is Apache. Apache supports IPv6 natively in his
latest versions. It also supports an increasing number of applications and services, like PHP (a
scripting language executed in the server), SSL (for secure transactions), proxy, PERL scripts,
Shell scripts, etc.
There are several browsers supporting IPv6. The two more widely used in Unix is Mozilla (a
variant of Netscape Navigator) and Lynx, a text-mode browser. Several web pages retrievers
for automatic processing as WGET are available too.
Web Servers do not need major changes to work with IPv6. They have to listen to IPv6
sockets, and they need to parse the new IPv6 address in the requests. The Web clients
(browsers) must support IPv6 as an answer for a DNS solicitation (A6 and AAAA registers),
and as direct address input for the URL (Universal Resource Locator).
Web Servers are usually located directly connected to the Internet, as they main purpose is to
provide WEB access with local and/or personal information.
A server listens to TCP port 80 for incoming connections. So this port must be accessible
from the Internet. If the Web Server is protected by a firewall, that port must be unfiltered. If
the access to the Internet is provided by a NAT server, a port redirection must be done to
allow incoming connections reach the web server.
3.2. FTP Server
The File Transfer Protocol (FTP) is one of the first protocols used to transfer files over the
Internet.
FTP is the simplest way to exchange files between computers on the Internet. Like the
Hypertext Transfer Protocol (HTTP), which transfers displayable Web pages and related files,
and the Simple Mail Transfer Protocol (SMTP), which transfers e-mail, FTP is an application
protocol that uses the Internet's TCP/IP protocols. FTP is commonly used to transfer Web
page files from their creator to the computer that acts as their server for everyone on the
Internet. It is also commonly used to download programs and other files to the user computer
from other servers.
As a user, FTP can be used with a simple command line interface (for example, from the
Windows MS-DOS Prompt window) or with a commercial program that offers a graphical
user interface. A Web browser can also make FTP requests to download the programs selected
from a Web page.
3.2.1. FTP brief description
FTP servers usually need to authenticate the user to allow them to access to their accounts.
But FTP servers may allow an “anonymous” account with username “anonymous” and the
password is the user’s email. The email is provided for logging purposes. The anonymous
account is used to distributed software, as if the software where in a Web page.
Page 120 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
FTP uses two connections for every user. The first connection, where the user sends the
username and password, is the control connection. It is open all the time. A second
connection, the data connection, is established every time that the user wants to transfer a file
or get a directory listing. So data connection does not exist all the time.
Data connection can be established by the server or by the user. The server establishes it by
default, and it is called the “active” mode. The user may request “Passive” mode. In that
mode, when a transfer is requested, server listens on a port and the user must connect to it.
Passive mode is an extension introduced into ftp to make it work in a NAT o firewall
environment. Incoming connections used in active mode are usually denied by firewalls and
almost impossible with NAT. Passive mode change them to outgoing connections, allowed by
firewalls and NATs.
When the user requests a file in active mode, he tells the FTP server the address and the port
where he will listen to the incoming connection with the command “PORT”. In passive mode,
the user sends a “PASV” command, and the server answers the address and port where it
expects the connection.
PORT command is designed for IPv4 and it cannot be used for IPv6 directly.
3.2.2. FTP and IPv6
A new RFC was developed to specify a new set of commands to use FTP with IPv6. The RFC
2428 defines, among others, the EPRT command (Extended PORT) and EPSV (Extended
PASV). They can be used both for IPv4 and IPv6, because they include in their parameters the
“address family” value, that may be for IPv4 and IPv6.
Also a FTP program has to listen on port 21 (the FTP port) in the IPv6 stack
Several IPv6 servers are implemented. One of them is FTPD-BSD (ftp://ftpdbsd.psychasia.com/pub/ftpd-bsd/). This implementation is very easy to install and it doesn’t
require any special configuration for IPv6. FTPD-BSD must be launched from an inetd
daemon supporting IPv6, like xinetd.
3.2.3. FTP in transition scenarios
Original FTP protocol did not support the passive mode, and it caused problems when NAT
and firewalls appeared. FTP was modified and the passive mode was added, so the problems
were solved.
As the IPv6 extensions defined in the RFC 2428 apply to active and passive modes, there
should not be any problem in NAT-PT.
When tunnels are present, both active and passive modes work, because the IP address that
initiates the connection is the same than reaches the FTP server, and it is not changed in the
path, as NAT does.
3.3. Mail Server
Mail Servers can be classified in two main groups depending on the protocol used: SMTP or
POP3.
Page 121 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
SMTP (Simple Mail Transfer Protocol) is used by clients to send mail to the local mail
server, and between servers to deliver the mail to its destination server.
·
POP3 (Post Office Protocol v3) is used only by the clients to fetch their mail. Mail is
never delivered to the client computer; it is the client who has to get it using POP3. A
server that handles the POP3 requests is the POP3 server. It is usually located in the
same host that the SMTP server, because they share the mail files, but frequently they
are different packages from different authors.
The use of each protocol is shown in this graph:
Sender
Internet
MTA
Receiver
MTA
SMTP
POP3
Figure 51 – Connection to mail server
The arrows’ direction shows who establish the TCP connection, from client to server.
3.3.1. SMTP Mail Servers
There are several SMTP Mail Servers with native IPv6 support.
§
The most used in the Internet is Sendmail (www.sendmail.org). It is the oldest SMTP
server available. However, it lacks of the latest capabilities like SPAM filters, it is hard to
configure and it has a large history of software bugs.
§
Zmailer (www.zmailer.org) is another Mail Transfer Agent with native IPv6 support. It is
designed to be light loaded, delivering great amounts of mail without a big impact in
machine’s performance.
§
Exim (www.exim.org) is one of most secure and reliable MTA which natively supports
IPv6. It also supports POP3 (see below).
§
Courier Mail (www.courier-mta.org) is a complete mail package supporting SMTP and
POP3. It also supports other protocols, as ESMTP, IMAP, it has a webmail interface and
mailing list services.
Mail Servers using SMTP need minor changes to work with IPv6. SMTP itself is independent
of the network layer but MTA must be changed to recognize the IPv6 registers in the DNS
entry, so that it should be able to process the AAAA and A6 entries. MX entry points to a
hostname, not an IP address.
For example, if a mail to igo@tid.es is received in a local MTA in an enterprise, the MTA will
ask to his DNS server:
“Where have I to send the mail for @tid.es?”
DNS will respond: “Send it to tid.tid.es”
Page 122 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
When tid.tid.es is resolved, it may be have A6 or AAAA entries, and the connection should be
established using IPv6 to that address. Once the connection is done, SMTP works as usual,
regardless of the underlying network layer.
Also minor changes should be done to manage properly the IPv6 addresses in the mail
headers.
3.3.2. POP3 Mail Servers.
POP3 is the protocol used by the final user to fetch his mail from the mail server. There are
several native IPv6 implementations of POP3 servers.
As commented in the SMTP Mail servers, Exim and Courier Mail support POP3 using IPv6.
POP3 is a protocol independent of the network layer. No modifications are required on it to
work with IPv6. It has to be able to open IPv6 sockets, but once the connection is established,
there are no IPv6-specific issues.
Also the process of getting the mail has not to resolve IP addresses except for the initial
connection.
3.3.3. Mail Servers behind firewalls, NAT and similar.
The connection requisites of the SMTP server are quite small. To receive mail, it listens to
TCP port 25, so if it is behind a firewall or NAT, port 25 must be redirected to the mail server.
In order to deliver mail received locally, SMTP server opens a TCP connection to the external
SMTP server in port 25. Local port is unimportant, so the connection can be established using
NAT or with a firewall that allows opening connections to external addresses.
SMTP will not work in completely closed local networks connected to the Internet with a
Proxy. There are no SMTP proxies.
Also a SMTP server needs to resolve addresses and it needs the complete DNS entry to get the
MX register, so if the local network has a private DNS server, it has to be configured to return
the entire DNS entry.
POP3 server are usually located inside local networks. As they only are used to get the local
mail once the SMTP server has received it, the connections will be originated in the local
network and there is no need of external port redirection. Of course, if an external service is
required, TCP port 110 must be redirected to the POP3 server.
3.4. Teleconference
3.4.1. ISABEL Application
The ISABEL CSCW application is a group communication tool for the Internet, which allows
efficient organization of working procedures in large enterprises or groups. The ISABEL main
features for global interconnection of auditoriums are completely described in D2.3 and they
can be summarized as follows:
Scalable architecture: supports a large geographical coverage and large number of
participating sites or access points.
Page 123 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Integrated event management function: supports the design of effective collaboration
management strategies, and which are specific to each service.
Define new services to meet user requirements.
The capability to use heterogeneous networks in the event with different QoS, using the
ISABEL network component named FlowServer.
The ISABEL4.5-beta7 version or upper is required to work over IPv6 networks. The ISABEL
application, installation guidelines and the support information can be found at
http://isabel.dit.upm.es.
To participate in a distributed event an ISABEL terminal must be configured. There are two
phases to get an ISABEL terminal working in an event:
1) Hardware requirements and configuration: audio, video and network infrastructure.
2) ISABEL software setup.
3.4.2. Hardware requirements and configuration
An ISABEL terminal is a PC running ISABEL over Linux and with the hardware
configuration shown in Table 4:
Operating System
Linux RedHat 7.0 (IPv6 supported)
Linux SuSE 7.1
(IPv6 supported)
Processor
Pentium III+ 800+ with 133Mhz bus minimum for good video quality (coding and decoding
is performed by software).
Memory
256 MBytes
Sound Card:
Sound Blaster Live or PCI 128
Or any full duplex board supported by ALSA http://alsa.alsa-project.org/~goemon/
Video Card
Most common video cards are supported: ATI, Intel, Matrox, etc. Details can be found in
http://www.xfree.org/3.3.6/README3.html#3.
Video Capturer
Based on BT848, BT878: Avermedia, MIRO PCTV, Studio PCTV, Videologic Captivator,
etc. Any board supported in video4linux (http://www.exploits.org/v4l/).
Network Interface
10/100 LAN interface for the recommended network access. Other interfaces may be
necessary if other network access technologies are used.
Table 4 - Recommended hardware configuration of an ISABEL terminal.
3.4.2.1. Audio equipment
One of the more important issues for achieving a natural interaction with remote sites using
ISABEL application is the good quality microphones, mixers and loudspeakers. The table 1.2
summarizes the recommended microphone types.
Page 124 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Standing or moving speaker
HIFI wireless bodypack microphone: AKG WMS 51, 60, 300 wireless system,
etc.
Sitting speaker
HIFI directional microphone: AKG GN30 E, etc.
Audience
HIFI wireless handheld microphone: AKG WMS 51, 60, 300 wireless system,
etc.
Sound mixer
Mixing table for all the microphones and sound inputs: Behringer MX602A,
MX802A, etc.
Loud speakers
A permanent setup with loudspeakers on the ceiling is best, but for small rooms
up to 20 persons good loudspeakers located in the front of the room can be
used. For example, Soundman from Logitech.
Table 5 - Microphone types recommended with ISABEL application.
A simple set up for a small room without a local sound system is shown in figure 1.1. The
loudspeakers are only used to hear the sound coming from the other ISABEL terminals, hence,
local audio is not amplified in the room. This configuration is adequate when planning a
telemeeting session. The user from his/her office room and using his/her personal computer
can participate in a virtual meeting.
Figure 52 - Hardware audio configuration for a small room without local sound system.
A more complex hardware audio configuration is needed when more local microphones are
used and when the local sound entries must be amplified, see figure 1.2. In this scheme a
mixing table is required to mix all local audio inputs, these local inputs are fed to the
amplifier directly without passing via ISABEL in order to avoid the delay introduced by the
coding-decoding software process performed in the terminal.
Page 125 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Figure 53 - Mixing multiple local audio channels for ISABEL use.
The audio communication between ISABEL remote terminals is shown in Figure 54. An
ISABEL terminal sends its local audio mixture and receives the remote audio mixture. Both
mixtures are amplified using a local sound system.
Figure 54 - Network view of the audio communication.
3.4.2.2. Video equipment
Good quality images are needed for achieving a good sense of remote presence for achieving a
natural interaction over the platform. The Table 6 summarizes recommendations for video
equipment.
Page 126 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
For a small access point to the platform for 2-6 participants a large monitor of
21” or higher is enough.
Video Monitor
For a larger audience a screen projector is recommended.
For the speaker in a teleconference event or a lecturer in teleeducation event a
smaller screen is advisable, for example a flat panel display of 13” or a 15”
monitor is adequate.
A screen projector with over 1000 ANSI lumens is advisable such that the
projection can be seen with the room illuminated.
Screen Projector
The screen projector should have the same resolution or higher resolution than
the PC screen. Having the same resolution in both is best. A resolution of
800x600 is recommended for best results.
Fixed Video Camera
Any video camera with VC video signal output is acceptable as long as the
quality provided is sufficient.
Robotized Video Camera
A robotized video camera with remote control by the PC. The SONY EVID30 is supported by ISABEL
Table 6 - Recommendations for video equipment.
The camera is usually connected to the VC input of the video capture board of the PC, see
Figure 55. ISABEL captures video frames using the capture board, encodes them and sends to
the remote participants.
Figure 55 - Video hardware connections.
When setting up a teleconference or lecture room, the PC screen must be projected in order to
allow all the participants in an auditorium to follow the remote lecture.
ISABEL can control the robotized cameras of remote sites from the distance. ISABEL camera
control panel allows camera controlling to focus in the most important session aspect.
Page 127 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Figure 56 - Video hardware connections.
Several cameras in a lecture room can provide better views of the event but this needs more
sophisticated video equipment. The cameras must be connected by means of a video matrix to
the VC input of the ISABEL PC.
3.4.3. Local Network Connection
An ISABEL terminal may connect to the other ISABEL terminals with the standard TCPUDP/IP protocols over a variety of access network technologies, including LANs, ISDN,
ADSL, ATM, satellite, etc. Besides, there is an ISABEL network configuration using IP
multicast, which requires multicast support activated in the PC running ISABEL. The main
requirement is to assure some quality of service for the IP traffic flowing to the other ISABEL
terminals. ISABEL needs to assure a bandwidth reservation and a maximum the end to end
delay and delay jitter. The bandwidth needed by an ISABEL session ranges from 128Kb/s to 2
Mb/s, depending on the desired quality of audio and video.
3.4.4. ISABEL software setup.
Before starting ISABEL application an Interactive Configuration Wizard (ICW) script should
be invoked to create an agenda of software configurations. Once the configuration process is
finished, the user can select one of the saved configurations to start the application. See
http://isabel.dit.upm.es to get detailed information about the ISABEL setup process.
An ISABEL site is defined as one of following participant event roles:
1. Master site: coordinator of the collaboration session. It is burden of controlling the
conference global state and the user access to a session. One and only one Master is
required in a ISABEL session.
2. Interactive site: actively participant site in a session. An interactive site exchanges
multimedia flows with the rest of interactive sites in the same session.
Page 128 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
3. Flowserver site: application router of ISABEL multimedia flows. The Flowserver
enables the creation of large multi-point collaboration sessions over heterogeneous
networks.
4. Watchpoint site: passively receiver of a session.
In deliverable D3.2, the ISABEL porting to IPv6 is explained in detail. As we have seen in
this deliverable, two solutions were studied and implemented to get ISABEL application
working over IPV6. Hence, different ways to start ISABEL application are defined according
to the IP protocol version and the ISABEL reliable transport component design:
1. Isabel IPv4/IPv6 TCP translator:
Unicast TCP connections following star topology centered in master site. Connectivity
from each interactive site to master is required to establish the reliable communication
virtual network at application level.
2. Reliable multicast transport:
Reliable communications use ISABEL unreliable network service (Irouter), taking
advantages of network details isolation, adaptation bandwidth and flow priority system.
ISABEL does not use TCP connections, only connectivity to a near Flowserver is
required.
The Table 7 shows the ISABEL script name which should be invoked when starting the
application using the different reliable transport communication models.
IP version
ISABEL script name
Reliable transport communication model
IPv4
Isabel
ISABEL traditional reliable communication model: unicast TCP
connections following a start topology centered in master site.
Connectivity to master from every interactive site is required.
Isabel-v2
Reliable multicast transport.
Isabel6
Isabel IPv4/IPv6 TCP translator.
Isabel6-v2
Reliable multicast transport.
IPv6
Table 7 - Script to start ISABEL application.
The scripts named isabel and isabel-v2 are used when running ISABEL over IPv4
networks, and the scripts named isabel6 and isabel6-v2 are used over IPv6 networks.
In the same ISABEL session, the application works over heterogeneous IP networks, that
means, IPv4 and IPv6.
In the Table 8, the interoperability of ISABEL versions is shown:
INTERACTIVE SITE
isabel
isabel-v2
isabel6
isabel6-v2
isabel
IPv4
--
--
--
MASTER
isabel-v2
--
IPv4
--
--
SITE
isabel6
IPv4
--
IPv6
--
isabel6-v2
--
IPv4
--
IPv6
Table 8 - Interoperability of ISABEL versions.
Page 129 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The Table 8 is summarized in the following rules:
·
When the master site is using Isabel version, only interactive sites with the
same version can connect to this session using IPv4 networks, see Figure 57.
Dual stack host
ISABEL Master
(isabel)
Irouter
UDP
IPv6
IPv6
Reliable
transport
TCP
IPv4
IPv4
IPv4 host
IPv6 host
ISABEL Interactive
(isabel)
Irouter
Reliable
transport
UDP
IPv4 address
IPv4
a.b.c.d
TCP
ISABEL Interactive
Irouter
Reliable
transport
UDP
TCP
IPv4 address
IPv6
IPv6
a.b.c.d
Not possible
Network
Figure 57 - Isabel working over IPv4 networks (UDP and TCP traffic).
Page 130 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
If the master site is running isabel-v2 version, only interactive sites with the
same version can connect to this session using IPv4 networks, see Figure 58.
Dual stack host
ISABEL Master
(isabel-v2)
Reliable
transport
Irouter
UDP
IPv6
IPv6
TCP
IPv4
IPv4
IPv4 host
IPv6 host
ISABEL Interactive
(isabel-v2)
ISABEL Interactive
Reliable
transport
Irouter
Reliable
transport
Irouter
UDP
IPv4 address
IPv4
IPv4
a.b.c.d
TCP
UDP
TCP
IPv4 address
IPv6
IPv6
a.b.c.d
Not possible
Network
Figure 58 - Isabel working over IPv4 networks (only UDP traffic).
·
When the master site is using isabel6 version, only interactive sites with
isabel and isabel6 versions can connect to this session exchanging
IPv4/IPv6 packets respectively, see Figure 59.
Page 131 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Dual stack host
ISABEL Master
(isabel6)
Irouter
UDP
IPv6
IPv6
Reliable
transport
TCP
IPv4
IPv4
IPv4 host
IPv6 host
ISABEL Interactive
(isabel)
Irouter
Reliable
transport
UDP
TCP
ISABEL Interactive
(isabel6)
Irouter
Reliable
transport
UDP
TCP
IPv4 address
IPv6
IPv6
a.b.c.d
IPv4 address
IPv4
IPv4
a.b.c.d
Network
Figure 59 - Isabel working over IPv4 and IPv6 networks (TCP and UDP traffic).
If the master site is using isabel6-v2 version, only interactive sites with isabel-v2
and isabel6-v2 versions can connect to this session exchanging IPv4/IPv6 packets
respectively, see Figure 60.
Dual stack host
ISABEL Master
(isabel6-v2)
Reliable
transport
Irouter
UDP
IPv6
IPv6
TCP
IPv4
IPv4
IPv4 host
IPv6 host
ISABEL Interactive
(isabel-v2)
Reliable
transport
Irouter
UDP
IPv4 address
IPv4
a.b.c.d
TCP
ISABEL Interactive
(isabel6-v2)
Reliable
transport
Irouter
UDP
TCP
IPv4 address
IPv6
IPv6
a.b.c.d
Network
Figure 60 - Isabel working over IPv4 and IPv6 networks (only UDP traffic).
Page 132 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Although there are different ISABEL scripts to start the application it only concerns to the
network configuration, not to the configuration or the application service. Then, all these
scripts show the same Interactive Configuration Wizard which request some information to
define the ISABEL site behavior:
·
·
Terminal Identification:
-
Acronym: Unique identification code to be used as a short name in an
ISABEL session.
-
Public Name: Visible name used to identify the terminal in the configuration
of components, for instance, video window title.
Hostname: Hostname or IP address of the machine.
Control Display Configuration:
Assigns a display for the control panel of each multimedia component.
Event Role Selection:
Specifies one of the ISABEL roles previously described: Master, Interactive,
Flowserver and Watchpoint. If an Interactive site is being configured it must be
provided the hostname or IP address of the Master.
·
Network Access Parameters:
-
Multicast: Multipoint over native multicast network. Multicast group
addresses must be configured to transport ISABEL flows and Time-To-Live
(TTL) value. Application bandwidth limit is defined to use when sending
information to multicast network.
-
Flow concentration station: Multipoint over unicast network using the
Flowserver component. Trees of Flowservers can be formed and configured in
different sites to deploy ISABEL network elements. Application bandwidth
limit is defined to send/receive information to/from another Flowserver.
Sites Configuration:
The Master can register interactive terminals in advance. In a closed event only
registered participants can join to the session.
The agenda of ISABEL configurations saves different values of these parameters to be loaded
by user at any time.
3.5. News
3.5.1. Introduction
Usenet is a worldwide-distributed discussion system. It consists of a set of "newsgroups" with
names that are classified hierarchically by subject. "Articles" or "messages" are "posted" to
these newsgroups by people on computers with the appropriate software -- these articles are
then broadcast to other interconnected computer systems via a wide variety of networks.
The news server listens in TCP port 119 for other servers and clients. Uses SMTP-like
commands and responses.
Page 133 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The technical aspects of Usenet/Netnews are described in RFC 977 (“Network News Transfer
Protocol”) and in RFC 1036 (“Standard for Interchange of USENET Messages”).
3.5.2. Available Implementations
The migration of the Netnews server from IPv4 to IPv6 is based on the standards defined at
the RFC 2553 (“Basic Socket Interface Extensions for IPv6”).
Platforms
News Server
News Client
FreeBSD/NetBSD
Ö
Ö
Linux
Ö
Ö
Not available?
Ö (Not tested)
Windows
News servers
INN
INN is one of the most used news servers for *nix systems. It’s developed by the ISC
Consortium and the source code is available free of charge. There are several branches of
IPv6 porting of INN and none from ISC. The most active IPv6 porting of INN is from
NORTH, and includes several extensions to the IPv4 INN:
·
§
IPv6 TCP socket can be used to send/receive articles.
§
INND and NNRPD can create multiple (more than two) TCP sockets to wait
connections from remote servers/clients.
§
Admin can bind (2) each socket to appropriate IP (or IPv6) address separately.
§
RFC2553 (“Basic Socket Interface Extensions for IPv6”) based socket (and its
address) family handling.
SN
SN is a small news systems for small sites serving perhaps a few dozen newsgroups, with
a slow connection to the Internet. It requires ucspi-tcp with IPv6 support enabled
(http://www.fefe.de/ucspi/).
Clients
The following clients are available, mostly for *nix platforms. Mozilla (aka: Netscape 6) as
Windows and *nix verions.
·
trn (*nix)
·
nn-tk (*nix)
·
mozilla (*nix, Windows, others?)
·
tin (*nix)
Page 134 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
3.6. IRC
Internet Relay Chating (described in [RFC2810],[RFC2811] ,[RFC2812] and [RFC2813]
) is a protocol devised for allowing textual conferencing. It is based in a distributed
client-server model. Servers are the elements in charge of linking clients and other servers in
order to provide communication among end users (that can be real users, or service clients, i.e.
automatic processes that may act as end users for purposes such as gathering statistics, etc.).
The servers are identified with a label that may not coincide with the host name in the DNS.
The topology of the server’s connection is a spanning tree. Clients cannot establish direct
communication among them.
Communications are established using TCP. The relation among the servers is a peer-to-peer
one. The servers can be grouped into
·
hub nodes, that maintain more than one connexion to other servers, or
·
leaf nodes, that at most held one connexion with another server
To connect tow servers, at least one of them has to be configured to establish the TCP
connection with the other.
A key IRC concept is the channel: a channel is a label that identifies a group of users that
receive the same messages. One-to-many communication, using IRC channels, is performed
by the servers in a way similar to multicast (although in this case, data replication and
delivering is handled at application level, and not at network level).
3.7. NFS
3.7.1. Introduction
NFS - Network File System – allows authorized users to access file located on remote system
as if they were local. From the user’s perspective, NFS is transparent. A user can execute an
application that uses arbitrary files local or remote.
NFS was initially developed by SUN Microsystems. The current NFS specification can be
found in RFC 1813 – NFS version 3 Protocol Specification, and RFC 3010 – NFS Version 4
protocol.
3.7.2. NFS Implementation
When an application is executed, it uses the operation system to open and create a file, or to
store and retrieve data from files. In this operation, if the file is on the local disk the file
access, mechanism accepts the request and automatically passes it to the local file system, or
to the NFS client, if the file is on remote machine.
In the case of the file being on remote machine, the NFS client uses a protocol to contact the
appropriate server on a remote machine that will perform the requested operation. When the
remote server replies, the NFS client returns the results to the application.
The NFS protocol is designed to be independent of the operating system and transport
protocol.
Figure 61 illustrates how NFS is embedded in an operation system.
Page 135 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Application
Operating System
Operating System
NFS
Client
Local
File
System
NFS Server
RPC
Local
Disk
RPC
UDP and TCP over IP
I/O
Primitives
Disk
Figure 61 – Network File System
NFS is the RPC application program providing file I/O functions to remote host. The user can
operate the files, regardless of whether the file is located locally or remotely.
3.7.3. IPv6 NFS Compliant
No changes are needed to perform in NFS software to support the IPv6. The problem is on the
RPC implementation. For an operating system, if the RPC can run over IPv6 them, the NFS
will work on that operating system.
Mostly the RPC implementations are Socket-based (TS-RPC). The porting to IPv6 follows
the same rules as defined in RFC-2553 an RFC-2292
3.7.4. RPC/NFS Applications available to IPv6
The operating systems, which the RFC has been ported to IPv6 are present on the table below.
Platforms
RPC/IPv6
NFS
FreeBSD/NetBSD/OpenBSD
Ö
Ö
Windows 2000
Ö
Not available
Windows XP
Ö
Not available
Table 9 – RPC/NFS implementations
3.8. Remote Authentication Dial In User Service (RADIUS)
The RADIUS protocol was developed by Livingston Enterprises, Inc., as an access server
authentication and accounting protocol. The RADIUS specification -RFC 2865- is a proposed
standard protocol and RADIUS accounting standard is only informational.
RADIUS is a client/server protocol. The RADIUS client is typically a NAS and the RADIUS
server is usually a daemon process running on a UNIX or Windows NT machine. The client
passes user information to designated RADIUS servers and acts on the response that is
Page 136 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
returned. RADIUS servers receive user connection requests, authenticate the user, and then
return the configuration information necessary for the client to deliver services to the user. A
RADIUS server can act as a proxy client to other RADIUS servers or other kinds of
authentication servers.
Communication between a Network Access Server (NAS) and a RADIUS server is based on
the User Datagram Protocol (UDP). So, issues related to server availability, retransmission,
and timeouts (normally handled by the transport protocol) must be handled by RADIUS.
Then, why use UDP instead of TCP as transport protocol? Namely because RADIUS is a
transaction based protocol which has several interesting characteristics:
·
If the request to a primary Authentication server fails, a secondary server must
be queried; to meet this requirement, a copy of the request must be kept above the
transport layer to allow alternate transmission. This means that retransmission timers
are still required.
·
The timing requirements of this particular protocol are significantly different
than TCP provides:
·
-
At one extreme, RADIUS does not require a "responsive" detection of lost data.
The user is willing to wait several seconds for the authentication to complete. The
generally aggressive TCP retransmission (based on average round trip time) is not
required, nor is the acknowledgement overhead of TCP.
-
At the other extreme, the user is not willing to wait several minutes for
authentication. Therefore the reliable delivery of TCP data two minutes later is
not useful. The faster use of an alternate server allows the user to gain access
before giving up.
The stateless nature of this protocol simplifies the use of UDP; clients and servers
come and go. Each client and server can open their UDP transport just once and leave
it open through all types of failure events on the network.
3.8.1. RADIUS Features
As stated in RFC2865, the key features of RADIUS are:
·
Client/Server Model
A Network Access Server (NAS) operates as a client of RADIUS. The client is
responsible for passing user information to designated RADIUS servers, and then acting
on the response which is returned.
RADIUS servers are responsible for receiving user connection requests, authenticating the
user, and then returning all configuration information necessary for the client to deliver
service to the user.
·
Network Security
Transactions between the client and RADIUS server are authenticated through the use of a
shared secret, which is never sent over the network. In addition, any user passwords are
sent encrypted between the client and RADIUS server, to eliminate the possibility that
someone snooping on an unsecure network could determine a user's password.
Page 137 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
Flexible Authentication Mechanisms
The RADIUS server can support a variety of methods to authenticate a user. When it is
provided with the user name and original password given by the user, it can support PPP
PAP or CHAP, UNIX login, and other authentication mechanisms.
·
Extensible Protocol
All transactions are comprised of variable length Attribute-Length-Value 3-tuples. New
attribute values can be added without disturbing existing implementations of the protocol.
3.8.2. How RADIUS works?
A RADIUS application has two components, the RADIUS server and the RADIUS client. The
first one is usually a computer equipped with server software which has authentication and
access information in a form that is compatible with the client. The second can be a router or
an access server with client software. Both equipments usually reside on the same LAN.
Remote network
Internet
RADIUS server
PSTN
NAS
(RADIUS client)
Remote user
User dial ( remote call via PSTN )
User initiates PPP negotiation with the NAS
RADIUS auth.
Access rejected
Access accepted
Parameters passed
Communication established
Figure 62 – Working of the Radius
3.8.3. Authentication and Authorization
The RADIUS server can support a variety of methods to authenticate a user. When a client is
configured to use RADIUS, any user of the client presents authentication information to the
client. This might be with a customizable login prompt, where the user is expected to enter
their username and password. Alternatively, the user might use a link framing protocol such
as the Point-to-Point Protocol (PPP), which has authentication packets which carry this
information.
Once the client has obtained such information, it may choose to authenticate using RADIUS.
To do so, the client creates an Access-Request containing such Attributes as the user's name,
the user's password, the ID of the client and the Port ID which the user is accessing.
The Access-Request is submitted to the RADIUS server via the network. If no response is
returned within a length of time, the request is re-sent a number of times. The client can also
forward requests to an alternate server or servers in the event that the primary server is down
Page 138 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
or unreachable. An alternate server can be used either after a number of tries to the primary
server fail, or in a round-robin fashion. Retry and fallback algorithms are the topic of current
research and are not specified in detail in this document.
Typically, when a remote user calls the RADIUS client, the client passes the call request
(referred as the Access-Challenge) to the RADIUS server. The Access-Challenge contains the
user’s name and password - this password is hidden using a method based on the RSA
Message Digest Algorithm MD5. The server verifies the user’s identity and, for authorized
callers, responds with an Access-Accept message, which includes the required access
information. This information is sent to the client, which passes it to the remote user.
If the remote user is not authorized, the server responds with an Access-Reject message.
In RADIUS, authentication and authorization are coupled together. If the username is found
and the password is correct, the RADIUS server returns an Access-Accept response, including
a list of attribute-value pairs that describe the parameters to be used for this session. Typical
parameters include service type (shell or framed), protocol type, IP address to assign the user
(static or dynamic), access list to apply, or a static route to install in the NAS routing table.
The configuration information in the RADIUS server defines what will be installed on the
NAS.
NAS
(RADIUS client)
RADIUS server
Figure 63 – Authentication and authorization
3.8.4. Accounting
An accounting session is the time during which the remote user communicates with the client.
The session begins when the client passes an Accounting-Request from the remote user to the
server and ends when the client sends a second request.
The client sends Accounting-Request only to the server configured for accounting, enabling
the use of different servers for accounting and authentication.
3.8.5. Packet Format
Exactly one RADIUS packet is encapsulated in the UDP Data field. The fields in each
RADIUS packet are:
·
Code
This field identifies the type of RADIUS packet. When a packet is received with an
invalid Code field, it is discarded.
Page 139 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
Identifier
This field aids in matching requests and replies. The RADIUS server can detect a
duplicate request if it has the same client source IP address, source UDP port and
Identifier within a short span of time.
·
Length
This field indicates the length of the packet including the Code, Identifier, Length,
Authenticator and Attribute fields.
·
Authenticator
This field is 16 octets. The most significant octet is transmitted first; it is used to
authenticate the reply from the RADIUS server. The two types of authenticators are as
follows:
Request-Authentication, available in Access-Request and Accounting-Request
packets.
Response-Authenticator, available in Access-Accept, Access-Reject, AccessChallenge, and Accounting-Response packets.
·
Attributes
The Attributes field is variable in length, and contains a list of zero or more Attributes.
Valid RADIUS Codes :
1
2
3
4
5
11
Access-Request
Access-Accept
Access-Reject
Accounting-Request
Accounting-Response
Access-Challenge
Figure 64 - Summary of the RADIUS packet format and codes
3.8.5.1. Packet types
The various types of RADIUS packet types that can contain attribute information are:
·
Access-Request
Sent from a client to a RADIUS server. The packet contains information that allows the
RADIUS server to determine whether to allow access to a specific network access server
(NAS), which will allow access to the user.
·
Access-Accept
Once a RADIUS server receives an Access-Request packet, it must send an AccessAccept packet if all attribute values in the Access-Request packet are acceptable. AccessAccept packets provide the configuration information necessary for the client to provide
service to the user.
Page 140 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
·
Access-Reject
Once a RADIUS server receives an Access-Request packet, it must send an Access-Reject
packet if any of the attribute values are not acceptable.
·
Access-Challenge
Once the RADIUS server receives an Access-Accept packet, it can send the client an
Access-Challenge packet, which requires a response. If the client does not know how to
respond or if the packets are invalid, the RADIUS server discards the packets. If the client
responds to the packet, a new Access-Request packet should be sent with the original
Access-Request packet.
·
Accounting-Request
Sent from a client to a RADIUS accounting server, which provides accounting
information. If the RADIUS server successfully records the Accounting-Request packet, it
must submit an Accounting Response packet.
·
Accounting-Response
Sent by the RADIUS accounting server to the client to acknowledge that the AccountingRequest has been received and recorded successfully.
3.8.5.2. Attribute-Value Pairs
AVPs Consist of a type identifier associated with one or more assignable values. AVPs
specified in user and group profiles define the authentication and authorization characteristics
for their respective users and groups. RADIUS implements an array of AVPs, each with
separate type definitions and characteristics.
Attributes are stored on the RADIUS daemon.
Internet Engineering Task Force Attributes
RADIUS IETF attributes are the original set of 255 standard attributes that are used to
communicate AAA information between a client and a server. Because IETF attributes are
standard, the attribute data is predefined and well known; thus all clients and servers who
exchange AAA information via IETF attributes must agree on attribute data such as the exact
meaning of the attributes and the general bounds of the values for each attribute.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
User-Name
User-Password
CHAP-Password
NAS-IP-Address
NAS-Port
Service-Type
Framed-Protocol
Framed-IP-Address
Framed-IP-Netmask
Framed-Routing
Filter-Id
Framed-MTU
Framed-Compression
Login-IP-Host
15
16
18
19
20
22
26
27
28
29
30
31
Login-Service
Login-TCP-Port
Reply-Message
Callback-Number
Callback-Id
Framed-Route
Vendor-Specific
Session-Timeout
Idle-Timeout
Termination-Action
Called-Station-Id
Calling-Station-Id
Figure 65 – Most important attribute types
Page 141 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Vendor-Specific Attributes
RADIUS VSA are derived from one IETF attribute vendor-specific (attribute 26). Attribute 26
allows a vendor to create additional 255 attributes however they wish. That is, a vendor can
create an attribute that does not match the data of any IETF attribute and encapsulate it behind
attribute 26; thus, the newly created attribute is accepted if the user accepts attribute 26.
3.8.6. RADIUS Files
Understanding the types of files used by RADIUS is important for communicating AAA
information from a client to a server. Each file defines a level of authentication or
authorization for the user: the Dictionary File defines which attributes the user's NAS can
implement; the Clients File defines which users are allowed to make requests to the RADIUS
server; the Users File defines which user requests the RADIUS server will authenticate based
on security and configuration data.
3.8.6.1. Dictionary File
A Dictionary File provides a list of attributes that are dependent upon which attributes the
NAS supports. However, a set of attributes can be added to the Dictionary File for custom
solutions. It defines attribute values, thereby allowing to interpret attribute output such as
parsing requests.
3.8.6.2. Clients File
A Clients File contains a list of RADIUS clients that are allowed to send authentication and
accounting requests to the RADIUS server. To receive authentication, the name and
authentication key the client sends the server must be an exact match with the data contained
in Clients File.
3.8.6.3. Users File
A RADIUS Users File contains an entry for each user that the RADIUS server will
authenticate. Each entry, which is also referred to as a user profile, establishes the attributes
the user can access with.
The first line in any user profile is always a User-Access line; that is, the server must check
the attributes on the first line before it can grant access to the user. The first line contains the
name of the user, which can be up to 252 characters, followed by authentication information
such as the password of the user.
Additional lines, which are associated with the User-Access line, indicate the attribute reply
that is sent to the requesting client or server. The attributes sent in the reply must be defined in
the Dictionary File.
When looking at a Users File, please note that the data to the left of the equal (=) character is
an attribute defined in the Dictionary-File, and the data to the right of the equal character is
the configuration data.
Page 142 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
3.8.7. RADIUS and IPv6
Several references where found and studied regarding AAA and IPv6. They define the
guidelines regarding the deployment of IPv6 support regarding RADIUS protocol, namely
operation of RADIUS over IPv6 as well as the RADIUS attributes used to support IPv6
network access. Nevertheless, the fact that these issues are relatively recent means that there
are not yet any complete implementations.
The most complete specification is defined in [RFC3162].
3.8.7.1. IPv6 Support
The NAS can provide IPv6 access natively, or alternatively, via other methods such as IPv6
within IPv4 tunnels or 6over4. The choice of method for providing IPv6 access has no effect
on RADIUS usage per se. Nevertheless, tunnel attributes should be utilised if it is desired an
IPv6 within IPv4 tunnel to be opened to a particular location.
Compatibility with IPv6 requires both the ability for RADIUS protocol to be transported over
IPv6, as well as the ability to carry attributes required to configure IPv6 network access. Since
hosts requiring network access may be dual stack, and the AAA server sending a RADIUS
Access-Request may not know a-priori whether the host will be using IPv4, IPv6, or both it
may need to return both IPv4 and IPv6 attributes and allow the NAS and host to decide which
one to use. For example, within PPP, IPv6CP occurs after LCP, so that address assignment
will not occur until after RADIUS authentication and authorization is completed.
Also routers and DHCPv6 servers are expected to work in conjunction with AAA servers to
determine client's access and authentication.
3.8.7.2. IPv6 Attributes
IPv6 attributes required for dialup are described in RFC3162 [6]. RFC3169 regarding
“Criteria for Evaluating Network Access Server Protocols” states, as a requirement of AAA
protocol used by NAS, that:
«… The AAA protocol must support simple attribute data types, including integer,
enumeration, text string, IP address, and date/time. The AAA protocol must also provide
some support for complex structured data types. Wherever IP addresses are carried within
the AAA protocol, the protocol must support both IPv4 and IPv6 addresses….»
IPv6 attributes are sent along with IPv4-related attributes within the same RADIUS message.
The NAS will then decide which attributes to use, regarding the addresses and prefixes that
the client can actually use. For example, there is no need for the NAS to reserve use of an
IPv4 address for a host that only supports IPv6. By the same reason, a host only using IPv4 or
6to4 doesn’t require allocation of an IPv6 prefix.
NAS-IPv6-Address
This attribute indicates the identifying IPv6 Address of the NAS which is requesting
authentication to the user, and should be unique to the NAS within the scope of the RADIUS
server. NAS-IPv6-Address is only used in Access-Request packets. A NAS-IPv6-Address
and/or a NAS-IP-Address may be present in an Access-Request packet; however, if neither
attribute is present then a NAS-Identifier must be present.
Page 143 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Framed-Interface-Id
This attribute indicates the IPv6 interface identifier to be configured for the user. It may be
used in Access-Accept packets. If the Interface-Identifier IPv6CP option has been successfully
negotiated, this Attribute must be included in an Access-Request packet as a hint by the NAS
to the server that it would prefer that value. It is recommended, but not required, that the
server honour the hint.
Framed-IPv6-Prefix
This attribute indicates an IPv6 prefix (and corresponding route) to be configured for the user.
It may be used in Access-Accept packets, and can appear multiple times. It MAY be used in
an Access-Request packet as a hint by the NAS to the server that it would prefer these
prefix(es), but the server is not required to honour the hint. Since it is assumed that the NAS
will plumb a route corresponding to the prefix, it is not necessary for the server to also send a
Framed-IPv6-Route attribute for the same prefix.
Login-IPv6-Host
This attribute indicates the system which the user has to be connected to, when the LoginService Attribute is included. It may be used in Access-Accept packets. It may be used in an
Access-Request packet as a hint to the server that the NAS would prefer to use that host, but
the server is not required to honour the hint.
Framed-IPv6-Route
This attribute provides routing information to be configured for the user on the NAS. It is
used in the Access-Accept packet and can appear multiple times.
Framed-IPv6-Pool
This attribute contains the name of an assigned pool that should be used to assign an IPv6
prefix for the user. If a NAS does not support multiple prefix pools, the NAS must ignore this
attribute.
3.8.7.3. IPv6 Dialup Operation
With the deployment of IPv6, it becomes more apparent that we have different operational
requirements in IPv6 dialup operation, than in IPv4 dialup operation. For example, it would
be desirable to see static address allocation, rather than dynamic address allocation, whenever
possible. With the IPv4 PPP this has been impossible due to address space shortage, and IPCP
dynamic address allocation has been used. With IPv6 PPP and other dialup connectivity, it is
possible to perform static address allocation from ISPs to downstream customers, as there's
enough address to spare.
The main issues being discussed regarding IPv6 dialup services refer to address space,
address allocation (static or dynamic assignment), address allocation models (/48 to behind
the customer router, /64 to behind the customer router, /64 to dialup point-to-point link ) and
mechanisms for address assignment.
Page 144 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
User-Address Mapping
The mechanisms defined for IPv6 user address mapping are:
-
Static configurations in routers and RADIUS / AAA servers.
3.8.8. Possible AAA scenarios
RADIUS for the purposes of authentication, authorization and accounting in IPv6-enabled
networks. In such networks, the RADIUS protocol may run either over IPv4 or over IPv6.
All proposed scenarios present a AAA server IPv6 enabled, meaning that IPv6 attributes are
sent to the NAS, regarding remote host configuration.
IPv4 dialup - Tunnel over PPP
The remote host will receive both IPv4 and IPv6 attributes, in order to connect directly to the
IPv4 network or via tunnel to the LONG IPv6 network (with endpoint at the dual stack
router).
Internet
Ipv4 Router
RADIUS Ipv4 server
(Ipv6 enabled)
PSTN
Ipv4 NAS
(RADIUS client)
Remote host
IPv4/IPv6
(Dual Stack)
Dual Stack Router
LONG
IPv6 Network
Figure 66 – Tunnel over PPP
IPv6 dialup : IPv4 AAA server
The remote host will only receive IPv6 attributes. These are sent to the NAS through the
“border” IPv4/IPv6 router.
Page 145 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Ipv4 Router
Internet
RADIUS Ipv4
server
(Ipv6 enabled)
Dual Stack Router
PSTN
LONG
IPv6 Network
Ipv6 NAS
(RADIUS client)
Remote host
IPv6
Figure 67 – IPv4 AAA server
IPv6 dialup - IPv6 AAA server
The remote host will only receive IPv6 attributes. These are sent to the NAS directly from the
AAA server in a all IPv6 network.
Internet
Ipv4 Router
Dual Stack Router
RADIUS Ipv6
server
(Ipv6 enabled)
Ipv6 NAS
(RADIUS client)
PSTN
Remote host
IPv6
LONG
IPv6 Network
Figure 68 - IPv6 AAA server
3.8.8.1. Future Developments
Authentication and authorization issues are still being studied, new guidelines concerning
RADIUS are being proposed and new requirements are being developed. Nevertheless, as
soon as a RADIUS server is deployed regarding the IPv6 attributes being send to a RADIUS
client, wherever this acts as a native IPv4 or IPv6 NAS, it will be possible to implement
within LONG testbed any of the previously described scenarios.
By the time being and, while there aren’t any available AAA implementations considering
IPv6 attributes it isn’t possible to propose or describe any configurations besides those used in
a total IPv4 environment which isn’t the scope of this description.
One of the activities concerning RADIUS within LONG is to keep track of AAA server
implementations and simultaneously to study the possibility of porting open-source
Page 146 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
implementation to IPv6, such as Cistron or freeRadius. For instance, when 4.2 is released it
will support RFC 3162 "RADIUS and IPv6". Some examples of IPv6 Attributes would be:
Nas-IPv6-Address="::"
Nas-IPv6-Address="::FFFF:1.2.3.4"
Nas-IPv6-Address="DEAD::BEEF"
Framed-Interface-Id=42
Framed-Interface-Id=0xFFFFFFFFFFFFFFFF
Framed-Interface-Id=9223372036854775807
Framed-Interface-Id=9223372036854775808
Framed-Interface-Id=10000000000000000000
3.9. LDAP
This section explains the LDAP protocol, its functionalities and particularities related to IPv6.
In the first section we will briefly explain what is a Directory and how it is used. In the second
section we will explain the predecessor of LDAP (X.500). In the following section a
description of the protocol and its functionalities are explained. In the fourth section the
configuration tasks are detailed and finally, in the last section the particularities of LDAP
working with IPv6 are discussed.
3.9.1. Directories
A directory is a listing of information about objects arranged in some order (usually
hierarchically) that gives details about each object. A directory has a limited functionality if
compared to a powerful database manager. The main difference between the directory and a
database is that the information stored in the directory is very descriptive and based on
attributes. Usually its information is more read than written, and thereby a directory is
optimised to access information, rather than updating or adding it.
The information stored in a directory is based on entries, each entry is referenced by a unique
key, and all the entries are structured in a hierarchically way (but it is not mandatory). This
tree-structure is very useful in finding data.
Typical examples of directories include telephone directories, lists of e-mail addresses and
DNS (Domain Name System). When a directory is stored in a computer is much more flexible
than, for example, telephone directories because they can usually be searched by specific data
criteria, not just by a predefined set of categories. For example, in a telephone directory you
can only search by name, then you get telephone and address. In a computer directory you can
search by names starting with “A” or all the names that have a certain address.
3.9.2. Predecessors of LDAP (X.500)
The former CCITT (current ITU-T) created the X.500 standard in 1988 (ISO 9594). X.500
uses the OSI Protocol stack and it is a “heavyweight” service. It is very functional and scalable
but sometimes too complex to use. X.500 specifies that communication between the directory
client and the directory server uses the Directory Access Protocol (DAP). DAP requires the
OSI protocol stack to operate. Using this stack requires more resources than are available in
many small environments, an interface to an X.500 directory server using less resources was
desired.
Page 147 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
3.9.3. LDAP
LDAP stands for Lightweight Directory Access Protocol, it is also known as X.500 lite. It was
originated at the University of Michigan jointly with Netscape in 1996, as a lightweight
alternative to DAP. LDAP has 90% of the functionality (omitting some X.500 esoteric
features) but with only 10% of the “cost”. The protocol is based on TCP but can be mapped to
other protocols.
LDAP is formed by elements named entries. Entries are organized in a tree-like structure
called the Directory Information Tree (DIT). Entries are arranged within the DIT based on
their Distinguished Name (DN). A DN is used to uniquely identify the entry in the whole
directory structure, it is meant (RFC 1777) to be used by humans (not just computers). Each
DN is a sequence of components called RDN (Relative Distinguished Name). Each RDN in a
DN corresponds to a branch in the DIT leading from the root of the DIT to the directory entry.
A RDN (Relative Distinguished Name) has the form <attribute name> = <value>. A RDN can
be formed with more than one attribute.
The attributes have a type and a name, the type describes the kind of data stored in the
attribute (string, telephone number, binary data…). On the following tables some of the LDAP
most used attribute types and names are shown:
Type
Description
Bin
Binary Information
Ces
Case Sensitive String
Cis
Case Ignore String
Tel
Telephone Number
Dn
Distinguished Name
Generalized Time Year Month Day and Time Represented as a Printable
String
Postal Address
Postal Address With Lines Separated by “$” Characters
Table 10 – Example of LDAP attribute types
Attribute Name
Type Description
Example
commonName,cn
cis
Common Name of an Entry
Dave Hollinger
surname,sn
cis
Surname (last name) of a Hollinger
Person
TelephoneNumber
tel
Telephone Number
organisationUnitName,
ou
cis
Name of an Organisation Unit Graduate Students
Owner
dn
Distinguished Name of the cn=Dave
Hollinger,
Person that owns the Entry
ou=Grad Student, o=RPI,
c=US
Page 148 of 206
555-33-22
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
organization, o
cis
Name of an Organisation
RPI
JpegPhoto
bin
Photographic Image in JPEG Photograph
Format
Hollinger
of
Dave
Table 11 - Most common LDAP attribute types and names
The following example represents a little LDAP directory example. First we will see the
“Dave Hollinger” entry, here we have his DN (which identifies his entry unambiguously in the
DIT):
CN = Dave Hollinger, OU =
University Institute, C = US
Grad
Student,
O
=
Rensselaer
Polytechnic
The DN is formed by different RDN’s (like OU = Grad Student). The different RDN’s are
separated by commas creating a DN, note that DN’s are read from leaf to root as opposed to
file system names, which are usually read from root to leaf. When a RDN has more than one
attribute, the syntax used is the following one:
C = US + D = United States
All this information can be viewed as a tree, where the last component is at the highest level
in the hierarchy:
C=US
O=MIT
O=RPI
OU=Undergrad
OU=Grad
CN=Dave Hollinger
Figure 69 - Example “LDAP” tree.
The root directory entry is conceptual, but does not actually exist (in the example it is possible
to add more countries ( C ) that would be hanging from the rood entry.
LDAP implementations allow a client to request that an LDAP server searches through some
portion of the DIT for information. The search can be very general or very specific. The search
operation allows to specify the starting point within the DIT, how deep within the DIT to
search, what attributes an entry must have to be considered to match, and what attributes to
return for matched entries. To make a search, the following parameters must be specified:
·
BASE: A DN that points a node of the DIT where the search will start.
·
SCOPE: How deep the DIT tree will be searched (starting from the BASE). There are
three options:
-
BaseObject: Only the BaseObject is examined.
Page 149 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
-
SingleLevel: The immediate children of the BaseObject are examined.
-
WholeSubtree: The BaseObject and all his children are examined.
·
SEARCH FILTER: Is a Boolean combination of attribute value assertions. An
attribute value assertion tests the value for equality, less, and so on.
·
ATTRIBUTES TO RETURN: This parameter specifies which attributes that match
the search filter must be returned to the user.
·
LIMITS: The user may specify time and size limits. Size limits refers to the
maximum number of entries returned from the search, the time limits refer to the total
time taken by the search at the server. Servers are free to impose stricter time or size
limits than specified by clients.
Other requests and responses are detailed in RFC1777. Programming an LDAP client is quite
easy, there is no need to know all the details of the protocols because there is an API (RFC
1823) available.
3.9.4. Configuring an LDAP Server and Client
We have chosen the OpenLDAP implementation (http://www.openldap.org) for the LDAP
server, this implementation is from University of Michigan. It supports Unix-like platforms
(Linux, FreeBSD, Solaris…) and it is OpenSource. To configure an LDAP Server IPv4 and
IPv6 enabled:
Get the software
Obtain a copy of the software from http://www.openldap.org/software/download/). The last
stable release is 2.0.2.1.
Unpack the distribution
Unpack the distribution doing:
gunzip -c openldap-2.0.2.1.tgz | tar xvfB cd openldap-2.0.2.1
Run configure
Before installing it we must configure it. Run the following command to have an LDAP server
IPv4 and IPV6 enabled.
./configure –enable-IPv6
Build the software
First resolve dependencies and then make the software.
make depend
make
Test the build
Page 150 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
To ensure that all is ok test the implementation:
make test
Install the software
To install the software use the following command (you need super-user priviledge):
su root -c 'make install'
Edit the configuration file
Edit /usr/local/etc/openldap/slapd.conf and add or update the following lines:
database ldbm
suffix "dc=long,dc=org"
#This is the rootdn, write your domain here
rootdn "cn=Manager,dc=long,dc=org"
rootpw <your_ldap_administrator_password>
directory /usr/local/var/openldap-ldbm
Start SLAPD
To start and stand-alone LDAP server run the following command:
su root -c /usr/local/libexec/slapd
To check that your LDAP server is running correctly type the following command:
ldapsearch -x -b '' -s base '(objectclass=*)' namingContexts
This is a LDAP administrator utility to search in the Directory structure, the response will be:
dn:
namingContexts: dc=long,dc=org
Add initial entries to your directory
To add entries to your directory create a LDIF file (the Directory “database”):
Create a file “example.ldif” containing:
dn: dc=long,dc=org
objectclass: dcObject
objectclass: organization
o: Organization unit
dc: long
dn: cn=Manager,dc=long,dc=org
objectclass: organizationalRole
Page 151 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
cn: Manager
NOTE: Be sure to trim any leading and trailing whitespace.
To add the information type the following command:
ldapadd -x -D "cn=Manager,dc=long,dc=org" -W -f example.ldif
See if it works
To see if the Directory has been updated type the following command:
ldapsearch -x -b 'dc=long,dc=org' '(objectclass=*)'
This command will search for and retrieve every entry in the database.
At this point we are able to have a stand-alone LDAP server IPv4 and IPv6 enabled. By the
moment, no user-friendly LDAP IPv6 client has been yet ported (for Linux). Peter Bieringer
IPv6
Linux
Web
says
that
it
will
be
“soon
available”
(http://www.bieringer.de/linux/IPv6/status/IPv6+Linux-status-apps.html).
However
OpenLDAP 2.0 server includes some client tools that allow adding, updating and requesting
information on LDAP servers. These tools can be used as LDAP clients despite they are not
user friendly.
3.9.4.1. LDAP distributed architecture
LDAP information can be distributed. There are two ways of doing this, replicating
information on different LDAP servers or partitioning information. When the directory
information is replicated, different LDAP servers have exactly the same information. When it
is partitioned, different LDAP servers store a unique and non-overlapping subset of the
information.
LDAP servers, replicated information
Sometimes, a stand-alone LDAP server is not enough, in this case we can execute more than
one LDAP server in different machines. In the OpenLDAP implementation, the LDAP server
daemon is called “slapd”. Another daemon is included in the implementation, called the
“slurpd”. The “slurpd” process reads from a “replogfile” (replica logging file) generated by
the “slapd” master daemon (the “slurpd” daemon and the “slapd” master daemon must be
executed on the same machine). The “slurpd” will send all the directory information stored on
the “replogfile” to another “slapd” slave instances running on different machines using the
LDAP protocol. Once the different LDAP slave servers are updated, the “slurpd” daemon
remains asleep until it detects a change on the “replogfile”, then it updates all the “slapd”
slave instances. In the following figure we can see a scheme of the distributed architecture:
Page 152 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Slave
slapd
Master
slapd
replogfile
slurpd
Slave
slapd
Figure 70. Scheme of a distributed architecture.
In LDAP distributed architectures, clients can search on any LDAP server (master or slave)
and also can add/delete or modify de Directory Information using any LDAP server (master or
slave). If LDAP server is slave it will forward the request to the LDAP master server that will
update the “replogfile”, then the “slurpd” daemon will update all the LDAP slave servers.
LDAP servers, distributed information
LDAP servers can be configured to store only a part of the information. The LDAP servers
support subordinate and superior knowledge information. When an LDAP server is configured
to have a subordinate knowledge information, a part of the sub-tree is stored by another LDAP
server. For this purpose the referral attribute is configured, a referral attribute allows to refer
the information to another LDAP server.
If the server a.example.net holds
dc=example,dc=net and wants to delegate the sub-tree ou=subtree, dc=example, dc=net to
another server b.example.net the following named referral object would be added to
a.example.net (expressed in OpenLDAP syntax):
dn: dc=subtree,dc=example,dc=net
objectClass: referral
objectClass: extensibleObject
dc: subtree
ref: ldap://b.example.net/dc=subtree,dc=example,dc=net
The server uses this information to generate referrals and search continuations to subordinate
servers.When an LDAP server is part of a superior knowledge information it must be
configured to know which LDAP server is his immediate superior on the structure tree. The
referral directive is used for this, in the previous example, the server b.example.net has his
superior information stored on a.example.net, so its configuration may include (expressed in
OpenLDAP syntax):
referral
ldap://a.example.net/
Page 153 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
3.9.5. LDAP IPv6 Particularities
LDAP is a high level protocol and changing Level 3 protocol (IPv4 for IPv6) has no effect. Its
functionalities are the same. However some changes has to be made at the configuration file
(explained above).
3.9.6. LDAP in transition Scenarios
The following figure presents a transition scenario for LDAP in IPv6. In this scenario all the
combinations between client-server pairs, are taken into consideration. Two LDAP servers are
running, the first over IPv6 and the second one over IPv4. The servers constitute a distributed
LDAP architecture, it is not important if the information is partitioned or replicated, its
functionality is exactly the same. Anyhow, the servers must be able to communicate, and a
Translation Mechanism is needed between them. This Translation Mechanism could be TRT,
NAT-PT… Two clients are also included into the transition scenario, one for IPv4 and one for
IPv6. The communications between the IPv6 client and server are done using native IPv6, the
same happens for the communications between the IPv4 client and server (i.e. IPv4 is used).
But, for the correct interaction between IPv4 client-IPv6 server and IPv6 client-IPv4 server a
Translation Mechanism is needed.
LDAP
Server
IPv6
LDAP
Server
IPv4
TM
TM
TM
LDAP
Client
IPv6
TM
LDAP
Client
IPv4
Translation Mechanism
Figure 71. Transition scenario with LDAP
Although no tunnel is explicitly drawn in the figure, they could be some transition mechanism
in the network that establish either IPv4 over IPv6 or (more often) IPv6 over IPv4 tunnels.
Anyway, the functional scheme of interaction represented in the figure does not change, as we
have the same protocol at both sides of the tunnel.
Page 154 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
4. Advanced Services in LONG project
4.1. Introduction
This section describes the experiments carried out locally, including network topologies and
network elements configurations. Relevant obtained results are presented.
Based on this experience, multi-site testbeds for the referred network and application level
services are proposed in order to evaluate them in larger and heterogeneous environments.
4.2. Mobile IPv6 local testbed
The following figure shows the used MobileIPv6 testbed:
Figure 1: Mobile IPv6 testbed
The software used in the testbed is MIPL mobile IPv6 [D-MIPv6], from the Helsinki
University of Technology (HUT). This implementation provides mobility support in IPv6 for
Linux computers, based on the Internet draft [D-MIPv6].
Operating System and kernel
All nodes run SuSE 7.2 Linux or later [SuSE]. They may be properly configured with IPv6
support.
We have used the USAGI IPv6 implementation in Linux kernel source tree. It is synchronized
with HUT's MIPv6 implementation since its latest snapshot, so it’s not necessary to apply any
kernel patches. The latest snapshot (2002-01-21) includes the latest kernel release (2.4.17).
4.2.1. Installation process
The first step is the installation of USAGI. This process is very similar to the installation of a
kernel. For supporting HUT’s MIPv6, at least the following kernel options must be set:
CONFIG_EXPERIMENTAL=y
CONFIG_SYSCTL=y
CONFIG_PROC_FS=y
CONFIG_MODULES=y
Page 155 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
CONFIG_NET=y
CONFIG_NETLINK=y
CONFIG_RTNETLINK=y
CONFIG_NETFILTER=y
CONFIG_UNIX=y
CONFIG_INET=y
CONFIG_IPV6=m
CONFIG_IPV6_IPV6_TUNNEL=m
CONFIG_IPV6_MOBILITY=m
Some kernel options are not recommended in USAGI’s doc files, because may cause
compilation errors. Some of them are:
CONFIG_IPV6_DEBUG=n
CONFIG_IPV6_6TO4_NEXTHOP=n
CONFIG_IPV6_NDISC_DEBUG=n
CONFIG_IPV6_ACONF_DEBUG=n
CONFIG_IPV6_RT6_DEBUG=n
CONFIG_IPV6_MLD6_DEBUG=n
CONFIG_IPV6_MLD6_NO_SUPPRESS_DONE=n
CONFIG_IPV6_NODEINFO=n
CONFIG_IPV6_NODEINFO_DEBUG=n
CONFIG_IPV6_NODEINFO_USE_UTS_DOMAIN=n
CONFIG_IPV6_MOBILITY=n
CONFIG_ATM_IPV6
The following steps may be followed:
%
%
%
%
%
%
%
%
%
%
#
cd SOMEWHERE/usagi
make prepare TARGET=$linux24
cd kernel
cd $linux24
make mrproper
make menuconfig (or "make config" or "make xconfig" as you like)
make dep
make bzImage
make modules
su
make install
(or you should copy arch/YOUR_ARCH/boot/bzImage file and
System.map file into /boot directory).
# make modules_install
# vi /etc/lilo.conf
# /sbin/lilo
Next step is installing building and installing userland applications, by doing:
%
%
%
%
#
cd SOMEWHERE/usagi/usagi
./configure
make
su
make install
For further instructions please refer to USAGI documentation [USAGI].
4.2.2. MIPL Mobile IPv6 installation
After downloading and uncompressing HUT’s MIPv6 implementation [1], we must do the
following:
% ./configure
% make
(creates Makefile and mobile-ip6 for your system)
Page 156 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
% make install (compiles and installs user level tools, man pages, init scripts and
example configuration files).
Configuration
The configuration is done via two configuration files: network-mip6.conf and
/etc/mipv6_acl.conf. They are pretty self-explanatory. You can see our configuration files
in section 4.1.6.
Usage
There is an automatic startup script for the module, called mobile-ip6, with the following
options: {start|stop|status|restart}
Module may also be loaded by hand using insmod.
4.2.3. Tests
We have performed the following test: the mobile node starts at the home network. The test
lasts 2 minutes. In the second 50, the mobile node makes a handover to the foreign network
and gets connectivity in the second 61. We have obtained the following results:
Here is a ping from the correspondent node to the mobile node during a simple handover:
roma:~ # ping6 3ffe:3328:4:1::5
PING 3ffe:3328:4:1::5 (3ffe:3328:4:1::5): 56 data bytes
64 bytes from 3ffe:3328:4:1::5: icmp_seq=0 ttl=63 time=11.001 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=1 ttl=64 time=0.781 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=2 ttl=64 time=0.777 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=3 ttl=64 time=0.778 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=4 ttl=64 time=0.77 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=16 ttl=63 time=934.708 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=19 ttl=63 time=1.554 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=20 ttl=63 time=1.569 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=21 ttl=63 time=1.601 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=22 ttl=63 time=1.534 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=23 ttl=63 time=1.681 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=24 ttl=63 time=1.623 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=25 ttl=63 time=1.573 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=26 ttl=63 time=1.57 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=27 ttl=63 time=1.526 ms
64 bytes from 3ffe:3328:4:1::5: icmp_seq=28 ttl=63 time=1.621 ms
--- 3ffe:3328:4:1::5 ping statistics --29 packets transmitted, 16 packets received, 44% packet loss
round-trip min/avg/max = 0.77/60.291/934.708 ms
Note that we perform the handover at sequence number 5. We observe a great delay and after
that the communication is recovered. Note also that we have performed the handover ‘by
hand’, (i.e. unplugging and plugging the cable by hand) so the delay is not representative.
There is a diagnostics and configuration tool, provided with MIPL Mobile IPv6, that can give
information about the mobility status, and can be used to configure MIPL with:
Page 157 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
peru:~ # mipdiag
Usage: mipdiag [-acdlsIL]
Show Mobile IP information
mipdiag [-hHdrtRMSCP value] Modify Mobile IP runtime parameters
mipdiag [-?|--help]
mipdiag [-V|--version]
-a, --access
-c, --bcache
-l, --bulist
-m, --mninfo
-s, --statistics
-I, --ifaces
-h, --homeaddress
-H, --homeagent
-i, --if_name
with -P
-P, --set_if_pref
-d, --debuglevel
-r, --rule
-R --rulelist
-t, --tunnel_sitelocal
-S, --addsa
-p, --spi
-A, --algorithm
-D, --direction
-x, --key_in_hex
-k, --key
--showsa
--delsa
--safile
Detailed usage syntax
Display version/author and exit
show access control list
show binding cache
show bingding update list
show MN information
show statistics
show current interfaces and priorities
set MN's home address and prefix length
set MN's home agent's address
set interface for which preference is adjusted
set priority for an interface
get/set module's debug level
set access control rule
read access control list from file
set tunnel sitelocal option
add security association
set SPI for SA
set algorithm for SA
set direction for SA
use hexadecimal key
set key for SA
show SA for address or all SAs
delete SA for address
add SAs from a file
We show here the binding cache of the Home Agent (peru). We can see the mobile node
address registered, and that the care-of-address acquired (by stateless autoconfiguration) is
3ffe:3328:4:3:220:e0ff:fe10:5d4.
peru:~ # mipdiag -c
Mobile IPv6 Binding cache
Home Address
Care-of Address
3ffe:3328:4:1::5
3ffe:3328:4:3:220:e0ff:fe10:5d4
Lifetime
45
Type
2
The mobile node (driza) register the care-of-address and its home address. It also keeps the
home agent address which register its movements.
driza2-movil:~ # mipdiag -m
Home Address
Home Agent Address
3ffe:3328:4:1::5 3ffe:3328:4:1::6
Care-of address
Registered
3ffe:3328:4:3:220:e0ff:fe10:5d4 1
Using mgen6 tool we have obtained the following graphic, showing the throughput:
Page 158 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Figure 72 - Traffic in simple handover 1
4.3. Multicast
We aim to perform three tests concerning IPv6 multicast. At this time of document, the set-up
of the appropriate testbeds is being done and are showing some configuration problems. The
equipments used are:
1. The IPv6 multicast routers are PC based equipment with FreeBSD Release 4.3 and
the IPv6 Kame stack. The multicast routing protocol is the pim6dd (daemon for
PIM Dense Mode version 6 routing protocol).
2. Multicast hosts can run any operating system (FreeBSD, Linux and W2k). In our
tests, Linux Red Hat 7.1 with USAGI IPv6 support is used.
3. The multicast tool that is used is the rat audio tool.
First test aims to verify what happens when two hosts on the same link join the same multicast
session. The network topology is the following:
Page 159 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Pluton
gordon
Linux – rat server
Linux – multicast client
eth0
eth0
xl0
vx0
xl0
vx0
Hub
vostok
Simmons
FreeBSD – IPv6 multicast
router
eth0
FreeBSD – IPv6 multicast
router
intrepin
Linux – multicast client
Figure 73 - IPv6 multicast on the same link scenario
The second test aims to verify the multicast mechanism when two hosts on different links join
to same multicast session. The network topology is the following:
Pluton
gordon
Linux – rat server
Linux – multicast client
eth0
eth0
xl0
xl0
vx0
xl0
vostok
FreeBSD – IPv6 multicast
router
vx0
Simmons
FreeBSD – IPv6 multicast
router
eth0
intrepin
Linux – multicast client
Figure 74 - IPv6 multicast mechanism on different links scenario
The third test aims to verify the provisioning of IPv6 multicast routing to a local IPv6 network
that has only unicast IPv4 routing connectivity to outside. The network topology is presented
in the following figure. In this testbed, Vostok multicast router is inserted in the local network
to provide IPv6 multicast service to Intrepid and Gordon. This case works with Kame and
through a double tunneling solution: the inner tunnel is an IPv6 multicast over an IPv6 tunnel
between the multicast routers (vostok and simmons); the outer tunnel is an IPv6 over IPv4
tunnel between double stack routers (odyssey and vennus). Note that, although odyssey and
vennus are directly connected, this path can be provided through IPv4 routers in between with
the proposed solutions.
Page 160 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Pluton
linux – rat server
Intrepid
Linux –multicast client
eth0
Vostok
xl0
Simmons
FreeBSD – IPv6 multicast
vx0
FreeBSD – IPv6 multicast
Router
Router
eth0
vx0
eth0
xl0
eth1
eth0
Hub
eth0
eth1
Odyssey – Linux
Vennus – Linux
IPv6 / IPv4 unicast Router
IPv6 / IPv4 unicast Router
Gordon
Linux –multicast client
Tunnel IPv6 / IPv4
Tunnel IPv6 multicast
Figure 75 - IPv6 multicast tunneling scenario
4.4. Multihoming
In this section we will describe the multi-homing technologies that will be tested in the LONG
project. A survey on the current solutions proposed for multi-homing has been presented in
section 2.4. Most of these proposals have not been implemented. After this study, we have
considered two different approaches to be tested, multi-homing support at exit routers, and the
address selection algorithm [D-DAS6] for peering, based on the availability of
implementations, and in the appropriateness for the goals of the LONG project.
Additional mechanisms could be tested, provided that some implementations were available,
and that could add value to the project.
4.4.1. Multi-homing support at exit routers
Multi-homing support at exit routers, presented in [RFC2260] and developed for IPv6 in [DMHSER] , is aimed to provide link fault tolerance through multi-homing. Provider-based
aggregation is assumed, so each ISP delegates one prefix to the considered site. Link fault
tolerance is achieved through tunnels between site egress routers (RA, RB) and ISP border
routers (BRB, BRA) as it is depicted in figure 1. In normal operation tunneled paths are
advertised with a low priority, to guarantee that traffic is routed through direct links whenever
possible. In case of link failure, the link that is down is no longer advertised as a valid route,
so tunneled path becomes the preferred route (in spite of its low priority).
Page 161 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Tunnels
ISP B
ISP A
BRB
BRA
RA
RB
PrefA
PrefB
Figure 76 - Multi-homing at exit routers
In this case, only proper tunnel and routing configuration is required.
4.4.2. Address Selection
For the LONG purposes, we state the following criteria:
1) Communication among partner sites should be performed using a common prefix, if
available.
2) Communication with sites external to the project should be done with non-common
prefixes, if available (in order to not use the rest of the sites as ISPs).
For achieving this, the following entry should be added:
LONGPref/prefLen
5
5
Here we give a pair of examples to illustrate the idea behind it:
Example 1
Suppose an internal communication:
DA=LONGPref::2, DB=2001:2::2
SA=LONGPref::1
and
SB=3ffe:1::1;
-
For DA, the selected source will be SA, because (rule 6) they match in the policy
table, and DA and SB do not match.
-
For DB, the selected source will be the source with longest prefix match with DA
(rule 8).
In the comparison among destination addresses, rule 5 is applied and the pair DA, SA are
selected because their labels match, and DB, Sx labels do not match. This was the intended
result as stated in requirement (1).
Example 2
Suppose we want to communicate with a machine that is external to the LONG network:
SA=LONGPref::1 and SB=3ffe:1::1; DA = 2007:aaaa::1, DB …
It is not relevant for our consideration the selection among different destination addresses.
The process of source address selection uses rule 6, matching label: Label (DA)=1; Label
(SA) = 5; Label (SB) = 1. So, since Label(DA)=Label(SB), and Label(DA)<>Label(SA),
SB is selected, as was the intended result specified by requirement (2).
Page 162 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
This approach can be used by the LONG partners, in order to assure proper connectivity.
4.4.2.1. Configuration
The source address selection mechanism, still in draft status, is implemented in the Kame
FreeBSD 4.4 of the 21st Jan Release.
Entries in the table are added by use of the ip6addrctl command. By default, no policy table is
loaded into the system executing the following commands:
ip6addrctl add ::1/128
50 0
ip6addrctl add ::/0
40 1
ip6addrctl add 2002::/16
30 2
ip6addrctl add ::/96
20 3
ip6addrctl add ::ffff:0:0/96
10 4
4.5. DNS
In this section we describe the DNS service deployed in the LONG project.
4.5.1. Platform: BIND 9
BIND 9 is the first BIND (Berkeley Internet Name Domain) release that supports native IPv6
queries when running on an IPv6 capable system. The IPv6 support in BIND 9 follows the
[RFC 2874]. BIND 9 also supports [RFC 1886]. It means that it still supports AAAA records
useful to maintain interoperability with networks where AAAA records are still used. In fact
much operating systems support only AAAA lookups because following A6 chains is much
harder.
Supporting both RFCs means also that the nibble format as well as the bitstring label is
supported for reverse lookups.
Currently, BIND 9 requires a UNIX system with an ANSI C compiler, basic POSIX support,
and a 64-bit integer type. It has been built and tested by the ISC (Internet Software
Consortium), who develops it, on the following systems:
·
AIX 4.3
·
COMPAQ Tru64 UNIX 4.0D
·
COMPAQ Tru64 UNIX 5 (with IPv6 EAK)
·
FreeBSD 3.4-STABLE, 3.5, 4.0, 4.1
·
HP-UX 11.x, x < 11
·
IRIX64 6.5
·
NetBSD 1.5
·
Red Hat Linux 6.0, 6.1, 6.2, 7.0
·
Solaris 2.6, 7, 8
·
Windows NT/W2K
Page 163 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
BIND 9.1.0 has been successfully installed and tested across LONG network. It worked
properly in Red Hat 6.0, Red Hat 7.1 and FreeBSD platforms.
Red Hat 7.1 has integrated support for IPv6 and it uses BIND 9 automatically. Working with
other OS without integrated IPv6 support, it is necessary to build it. For that, just:
./configure
make
4.5.2. Description of scenario and cases.
The correct interaction of BIND 9 with IPv6 will be tested in network (3FFE:3328:6::/48) that
corresponds to tid.long domain.
Such network is divided into several subnetworks. One of them, network 3FFE:3328:6:3::/64,
hosts cocodrilo6.tid.long which will act as a primary server. Network 3FFE:3328:6::2::/64
hosts cantonal.tid.long .
Several IPv4/IPv6 hosts are placed along this network. They will perform A/AAAA queries.
DNS Primary Server
cocodrilo6.tid.long
( 3FFE:3328:6:3::148 )
DNS Secondary Server
cantonal.tid.long
(3FFE:3328:6:2::5)
To
Internet
siritinga.tid.long
3FFE:3328:6::3/64
3FFE:3328:6::2/64
aboli.tid.long
Figure 77 – DNS scenario testbed
Both name servers are Red Hat 7.1 machines running BIND 9.1.0. They serve A and AAAA
queries. Since they are dual stack machines, they can be configured to listen IPv4 and IPv6
queries.
Client hosts are Linux boxes with different versions of Red Hat (RH 6.0, RH 6.2, and RH 7.1)
Some of them are dual stack, but there are still some IPv4 only hosts.
Cases
Two cases will be studied:
·
Case 1: cocodrilo6.tid.long will be the primary server in the domain. As it can not
access the root servers in the Internet, it will forward all queries it can not resolve to
Page 164 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
cantonal.tid.long. Cantonal will act just as a caching-only forwarder, being unable to
resolve local addresses.
·
Case 2: to make sure DNS system continues working even when cocodrilo6.tid.long
has some problem, cantonal.tid.long will be configured as a secondary server.
Configuration files
There are three kinds of files to configure in order to set up the DNS system:
In the name server systems:
·
/etc/named.conf: It is the most important configuration file. It instructs the BIND name
server about the zone files it is serving.
·
Zone files: They describe each of the zones using resource records:
-
SOA for start of authority
-
NS for name servers
-
MX for the mail exchange
-
A for IPv4 address
-
AAAA for IPv6 address
-
PTR for reverse resolution
In the client systems:
·
/etc/resolv.conf: It specifies the address of the DNS server to ask and, optionally, the
local domain and the domains to search.
Clients with Red Hat 7.1 can perform IPv6 queries towards the nameservers hence
they will have an entry such as "nameserver 3FFE:3328:6:3::148". Clients with
previous releases of Red Hat can ask to the NS just using IPv4.
Diagnostic tools
There are several monitoring and diagnostic tools for controlling the nameserver daemon.
·
named-checkconf: Checks the syntax of named.conf file.
named-checkconf [filename]
·
named-checkzone: Performs syntax and consistency checks on a individual zone
named-checkzone [-dq] [-c class] zone [filename]
·
dig (domain information groper): It is a command line tool that can be used to gather
information from DNS servers
dig [@server] domain [<query-type>] [<query-class>]
[+<query-option] [-<dig-option>] [%comment]
4.5.2.1. Case 1
As explained above, in this case cantonal.tid.long will only forward queries to the root servers
as cocodrilo6 will forward any query it does not know how to resolve to cantonal.tid.long.
Page 165 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
FQDN
IPv6 address
IPv4 address
Domain
tid.long
3FFE:3328:6::/48
---
Primary NS
cocodrilo6.tid.long
3FFE:3328:6:3::148
193.146.185.148
Forwarder NS
cantonal.tid.long
3FFE:3328:6:2::5
192.168.234.5
Configuration files
Primary NS: cocodrilo6.tid.long
·
/etc/named.conf
options {
directory "/etc/dns";
notify yes;
auth-nxdomain yes;
// By default, the server will not listen in any IPv6 address
listen-on-v6 { any; };
/*
* forward first causes the server to query the forwarders first,
* and if that doesn't answer the question the server will then
* look for the answer itself.
*/
forward first;
// IP address to be used for forwarding
forwarders {3ffe:3328:6:2::5;};
};
// Reverse mapping for the loopback addresses
zone "0.0.127.in-addr.arpa" {
type master;
file "db.127.0.0";
};
zone "0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.arpa" {
type master;
file "db.localhostv6";
};
// Cocodrilo is master server for tid.long
zone "tid.long" {
type master;
file "db.tid.long";
};
Page 166 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
// Reverse mapping for tid.long
zone "6.0.0.0.8.2.3.3.e.f.f.3.ip6.arpa" {
type master;
file "db.tid.long.rev";
};
·
Zone files: there are two zone files for each zone served (for direct and reverse
lookups). They are specified in the configuration file /etc/named.conf and they must
be place under the working directory.
If there is any doubt about how to configure them, see Appendix B.
Forwarder NS: cantonal.tid.long
·
/etc/named.conf
options {
directory "/var/named";
notify yes;
listen-on-v6 { any; };
};
//
// a caching only nameserver config
//
zone "." IN {
type hint;
file "named.ca";
};
zone "0.0.127.in-addr.arpa" IN {
type master;
file "named.local";
};
zone "0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.arpa" {
type master;
file "db.localhostv6";
};
Zone files: They can be consulted in Appendix B.
Client RH7.1: siritinga.tid.long
·
/etc/resolv.conf
nameserver 3FFE:3328:6:3::148
Page 167 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
search tid.long long
Client with RH6.2: aboli.tid.long
·
/etc/resolv.conf
nameserver 193.146.185.148
4.5.2.2. Results
Below, the results of making the following queries with dig tool are shown.
CLIENT
TRANS. PROT.
QUERY TYPE
(local) AAAA
siritinga
(local) A
IPv6
(Internet) AAAA
NAMESERVER
cocodrilo6
cocodrilo6 -> cantonal ->
-> root servers
(Internet) A
Aboli
IPv4
(local) AAAA
cocodrilo6
(local) A
cocodrilo6
It must be noticed again that siritinga.tid.long sends IPv6 queries and aboli.tid.long sends
IPv4 ones, but both of them can obtain resolution for A and AAAA queries.
Resolution of local addresses from siritinga.tid.long:
[root@siritinga]# dig -t AAAA unreachable6.tid.long
; <<>> DiG 9.1.0 <<>> -t AAAA unreachable6.tid.long
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7432
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1
;; QUESTION SECTION:
;unreachable6.tid.long.
IN
AAAA
;; ANSWER SECTION:
unreachable6.tid.long. 604800 IN
AAAA
3ffe:3328:6:2::4
;; AUTHORITY SECTION:
tid.long.
604800 IN
NS
cocodrilo6.tid.long.
;; ADDITIONAL SECTION:
cocodrilo6.tid.long.
604800 IN
AAAA
3ffe:3328:6:3::148
;; Query time: 17 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
Page 168 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
;; WHEN: Wed Jan 23 12:39:07 2002
;; MSG SIZE rcvd: 120
[root@siritinga]# dig unreachable.tid.long
; <<>> DiG 9.1.0 <<>> unreachable.tid.long
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 47705
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1
;; QUESTION SECTION:
;unreachable.tid.long.
IN
A
;; ANSWER SECTION:
unreachable.tid.long. 604800 IN
A
192.168.234.4
;; AUTHORITY SECTION:
tid.long.
604800 IN
NS
cocodrilo6.tid.long.
;; ADDITIONAL SECTION:
cocodrilo6.tid.long.
604800 IN
AAAA
3ffe:3328:6:3::148
;; Query time: 3 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Wed Jan 23 12:41:27 2002
;; MSG SIZE rcvd: 107
Resolution of Internet addresses from siritinga.tid.long:
[root@siritinga]# dig -t AAAA www.kame.net
; <<>> DiG 9.1.0 <<>> -t AAAA www.kame.net
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46383
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 2, ADDITIONAL: 8
;; QUESTION SECTION:
;www.kame.net.
IN
AAAA
;; ANSWER SECTION:
www.kame.net.
86322 IN
CNAME apple.kame.net.
apple.kame.net.
86322 IN
CNAME kame220.kame.net.
kame220.kame.net.
86322 IN
AAAA
2001:200:0:4819:280:adff:fe71:81fc
kame220.kame.net.
86322 IN
AAAA
3ffe:501:4819:2000:280:adff:fe71:81fc
;; AUTHORITY SECTION:
kame.net.
86322 IN
NS
coconut.itojun.org.
kame.net.
86322 IN
NS
orange.kame.net.
;; ADDITIONAL SECTION:
Page 169 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
orange.kame.net.
86322 IN
A
203.178.141.194
orange.kame.net.
86322 IN
A6
64 ::220:18ff:fe58:adca sharedsegment.a6.kame.net.
orange.kame.net.
86322 IN
A6
64 ::220:18ff:fe58:adca karigome-bb.v6.wide.ad.jp.
orange.kame.net.
86322 IN
AAAA
2001:200:0:4819:220:18ff:fe58:adca
orange.kame.net.
86322 IN
AAAA
3ffe:501:4819:2000:220:18ff:fe58:adca
karigome-bb.v6.wide.ad.jp. 3524 IN
A6
wide-stla.v6.wide.ad.jp. 3524 IN
A6
48 0:0:0:4819:: wide-stla.v6.wide.ad.jp.
0 2001:200::
sharedsegment.a6.kame.net. 86322 IN
A6
48 0:0:0:2000:: karigome.v6.wide.ad.jp.
;; Query time: 5 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue Jan 22 12:25:52 2002
;; MSG SIZE rcvd: 473
[root@siritinga]# dig www.yahoo.es
; <<>> DiG 9.1.0 <<>> www.yahoo.es
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 47757
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 5, ADDITIONAL: 0
;; QUESTION SECTION:
;www.yahoo.es.
IN
A
;; ANSWER SECTION:
www.yahoo.es.
6135
IN
www2.vip.lng.yahoo.com. 1800
CNAME www2.vip.lng.yahoo.com.
IN
A
217.12.3.11
;; AUTHORITY SECTION:
lng.yahoo.com.
7200
IN
NS
ns1.snv.yahoo.com.
lng.yahoo.com.
7200
IN
NS
ns2.san.yahoo.com.
lng.yahoo.com.
7200
IN
NS
ns3.europe.yahoo.com.
lng.yahoo.com.
7200
IN
NS
ns4.dal.yahoo.com.
lng.yahoo.com.
7200
IN
NS
ns5.dcx.yahoo.com.
;; Query time: 1006 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue Jan 22 12:29:40 2002
;; MSG SIZE rcvd: 195
Resolution of local addresses from aboli.tid.long:
root@aboli]# dig -t AAAA unreachable6.tid.long
; <<>> DiG 9.1.3 <<>> -t AAAA unreachable6.tid.long
;; global options: printcmd
;; Got answer:
Page 170 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40932
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1
;; QUESTION SECTION:
;unreachable6.tid.long.
IN
AAAA
;; ANSWER SECTION:
unreachable6.tid.long. 604800 IN
AAAA
3ffe:3328:6:2::4
;; AUTHORITY SECTION:
tid.long.
604800 IN
NS
cocodrilo6.tid.long.
;; ADDITIONAL SECTION:
cocodrilo6.tid.long.
604800 IN
AAAA
3ffe:3328:6:3::148
;; Query time: 80 msec
;; SERVER: 193.146.185.148#53(193.146.185.148)
;; WHEN: Wed Jan 23 10:14:35 2002
;; MSG SIZE rcvd: 120
[root@aboli]# dig unreachable.tid.long
; <<>> DiG 9.1.3 <<>> unreachable.tid.long
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 52078
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1
;; QUESTION SECTION:
;unreachable.tid.long.
IN
A
;; ANSWER SECTION:
unreachable.tid.long. 604800 IN
A
192.168.234.4
;; AUTHORITY SECTION:
tid.long.
604800 IN
NS
cocodrilo6.tid.long.
;; ADDITIONAL SECTION:
cocodrilo6.tid.long.
604800 IN
AAAA
3ffe:3328:6:3::148
;; Query time: 17 msec
;; SERVER: 193.146.185.148#53(193.146.185.148)
;; WHEN: Wed Jan 23 10:17:25 2002
;; MSG SIZE rcvd: 107
4.5.2.3. Case 2
In this case cantonal.tid.long is configured as a secondary DNS server for the domain
tid.long.
Domain
FQDN
IPv6 address
IPv4 address
tid.long
3FFE:3328:6::/48
---
Page 171 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Primary NS
cocodrilo6.tid.long
3FFE:3328:6:3::148
193.146.185.148
Secondary NS
cantonal.tid.long
3FFE:3328:6:2::5
192.168.234.5
Configuration files
Primary NS: cocodrilo6.tid.long
·
/etc/named.conf: This file is the same as for case1.
·
Zone files: Zone files for local host do not change from case 1. Whereas zone files for
direct and reverse resolution of domain tid.long must include two new RRs: a NS resource
record specifying that cantonal.tid.long is also a name server for the domain and an
AAAA record specifying IPv6 address of such name server.
They can be consulted in Appendix B.
Secondary NS: cantonal.tid.long
·
/etc/named.conf
options {
directory "/var/named";
notify yes;
listen-on-v6 { any; };
};
//
// a caching only nameserver config
//
zone "." IN {
type hint;
file "named.ca";
};
zone "0.0.127.in-addr.arpa" IN {
type master;
file "named.local";
};
zone "0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.arpa" {
type master;
file "db.localhostv6";
};
// definition of zones served as a slave server.
zone "tid.long" {
type slave;
Page 172 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
file "db.tid.long";
masters {3ffe:3328:6:3::148;};
};
zone "6.0.0.0.8.2.3.3.e.f.f.3.ip6.arpa" {
type slave;
file "db.tid.long.rev";
masters {3ffe:3328:6:3::148;};
};
·
Zone files: No changes must be made to zone files. Even no new zone files must be
created. Cantonal.tid.long will obtain them from cocodrilo6.tid.long as explained in
section 2.6.1.2 Name Servers.
Client RH7.1: siritinga.tid.long
·
/etc/resolv.conf
nameserver 3FFE:3328:6:3::148
nameserver 3FFE:3328:6:2::5
search tid.long long
Client with RH6.2: aboli.tid.long
·
/etc/resolv.conf
nameserver 193.146.185.148
nameserver 192.168.234.5
4.5.2.4. Results
After testing in case 1 that name servers work properly independently of the type of queries
(IPv4/IPv6), in case 2 correct behaviour of slave server will be checked. For that,
cocodrilo6.tid.long will be stopped so cantonal, as a slave server, will have to attend queries
from clients. And then, both DNS servers will be stopped in order to see the result of dig.
Below, the results of making the following queries with dig tool are shown.
CLIENT
TRANS. PROT.
siritinga
IPv6
QUERY TYPE
(local) AAAA
(local) A
NAMESERVER
cantonal.tid.long
cantonal.tid.long
none
Resolution of queries from siritinga.tid.long with only cantonal working:
[root@siritinga]# dig -t AAAA unreachable6.tid.long
Page 173 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
; <<>> DiG 9.1.0 <<>> -t AAAA unreachable6.tid.long
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 17873
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 2
;; QUESTION SECTION:
;unreachable6.tid.long.
IN
AAAA
;; ANSWER SECTION:
unreachable6.tid.long. 604800 IN
AAAA
3ffe:3328:6:2::4
;; AUTHORITY SECTION:
tid.long.
604800 IN
NS
cantonal.tid.long.
tid.long.
604800 IN
NS
cocodrilo6.tid.long.
;; ADDITIONAL SECTION:
cantonal.tid.long.
604800 IN
AAAA
3ffe:3328:6:2::5
cocodrilo6.tid.long.
604800 IN
AAAA
3ffe:3328:6:3::148
;; Query time: 13 msec
;; SERVER: 3ffe:3328:6:2::5#53(3ffe:3328:6:2::5)
;; WHEN: Wed Jan 23 18:27:32 2002
;; MSG SIZE rcvd: 171
[root@siritinga]# dig unreachable.tid.long
; <<>> DiG 9.1.0 <<>> unreachable.tid.long
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20595
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 2
;; QUESTION SECTION:
;unreachable.tid.long.
IN
A
;; ANSWER SECTION:
unreachable.tid.long. 604800 IN
A
192.168.234.4
;; AUTHORITY SECTION:
tid.long.
604800 IN
NS
cocodrilo6.tid.long.
tid.long.
604800 IN
NS
cantonal.tid.long.
;; ADDITIONAL SECTION:
cantonal.tid.long.
604800 IN
AAAA
3ffe:3328:6:2::5
cocodrilo6.tid.long.
604800 IN
AAAA
3ffe:3328:6:3::148
;; Query time: 10 msec
;; SERVER: 3ffe:3328:6:2::5#53(3ffe:3328:6:2::5)
;; WHEN: Wed Jan 23 18:27:49 2002
;; MSG SIZE rcvd: 158
Page 174 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Resolution of queries from siritinga.tid.long without any server working:
[root@siritinga]# dig unreachable.tid.long
; <<>> DiG 9.1.0 <<>> unreachable.tid.long
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 25316
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0
;; QUESTION SECTION:
;unreachable.tid.long.
IN
A
;; AUTHORITY SECTION:
.
10800 IN
SOA
2002012300 1800 900 604800 86400
A.ROOT-SERVERS.NET. nstld.verisign-grs.com.
;; Query time: 534 msec
;; SERVER: 3ffe:3328:6:2::5#53(3ffe:3328:6:2::5)
;; WHEN: Wed Jan 23 18:28:39 2002
;; MSG SIZE rcvd: 113
4.6. DHCPv6
In this section we describe the DHCPv6 services tested in the LONG project. We have
followed the considerations of section 2.6.3, testing one Linux and one FreeBSD
implementation of DHCPv6, both server and client.
4.6.1. Ralph Meyer’s DHCPv6 implementation for Linux.
First we provide a short guide to install this DHCPv6 implementation for Linux OS.
Download the tarball from http://www.hycomat.co.uk/dhcp/ and unpack it:
tar xIvf dhcpv6XXXX.tar.bz2
Remove any work.* directory, and run ./configure (a directory named work.linux2.2 will be created).
Enter now that directory and edit Makefile (USERBINDIR, BINDIR and CLIENTDIR) just in
case you want to install it into another directory.
Running make will fail, because one of the symbolic links is not created in the
./configure, so that link will be needed to be created:
cd common; ln -s ../../common/getifaddrs.c; cd ..
The building of relay and dhcpctl also fails, so a line must be changed in the Makefile to
avoid its compilation:
SUBDIRS=
common $(MINIRES) dst omapip server client relay dhcpctl
Page 175 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
to
SUBDIRS=
common $(MINIRES) dst omapip server client
Everything should go fine after this, and the client and the server are created. make install
will copy the binaries to the given directories.
Evaluation
Server implementation seems to work fine. However, the server will only answer to a client if
it is asked about netmask and dns-server-address (this has to be set up in the client
configuration), although it is only able to provide IPv6 address to hosts.
The client side is completely unfinished and it is not suitable for a production use. An
example configuration file is provided in config/dhcpd.conf, so use that file to create
your own (in /etc/dhcpd.conf). The only field that apparently should be written with an
IPv6 address is fixed-ip6-address (neither subnet nor range), but unfortunately this
doesn’t work, and it is not documented anywhere.
After checking the source code we discovered that the client side is in a debugging state. For
example, the host always sends the same identification string to server (i. e. it is hard-coded in
the source code, “878787”) so it is clearly in a debugging state. We have been able to make
the client to send the 4 last bytes of the MAC address to the server, but the server dies when
receiving this information. This bug seems easy to correct in the way of the server accepting
miscellaneous identification ASCII-strings to the server, but not accepting hardware addresses
(string identification and hardware address identification are different DHCP options, it is not
just sending the MAC address as an ASCII string).
After receiving the information from the server (IPv6 address) the client executes a script that
uses commands that are now old in most Linux distributions. This is also easy to correct.
As a summary, we have been able to set up an IPv6 address to a Linux host, hacking with the
host identification. With some work on the implementation it is likely to make it work but up
to now it is not ready for a production use.
4.6.2. KAME/WIDE’s implementation for FreeBSD.
Download the latest snapshot of the KAME software from the project web page (dhcp6 is not
provided as a standalone tarball) and once unpackaged, move to the kame/kame/dhcp6
directory. A classical ./configure, make, make install sequence is used to compile
the software (--prefix=/path/to/install can be used to install it into the wanted
directory).
Let’s start the server now, by running dhcp6s –n <DNS IPv6 address> (in case of
malfunction, -fdD options can be used to avoid the server to daemonize, provide debug
information and provide even more debug information, respectively). A detail to be noticed is
that the server needs to own a valid global IPv6 address (neither a Link Local, Site Local,...
nor a private address), for it will exit with an error in other case.
Page 176 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The client can also be run with –dD options, but must be used with the –f one. When run in
the foreground, it asks the server for a DNS server IPv6 address and prints it to stderr, in a
format suitable to be added to the /etc/resolv.conf system file, but when daemonized, it
do not prints it nor adds it itself.
A small shell script has been developed to use that information to configure the system:
#!/bin/sh
# jsedano@dit.upm.es
# Uses dhcp6c to set /etc/resolv.conf
# BUGS: lacks a lot of error detection
# Configuration
DHCP6C=/usr/local/dhcp6/dhcp6c
PIDFILE=/var/run/dhcp6c.pid
DEV=ed0
TMP=/tmp
TMPFILE=$TMP/.dhcp6client.tmp.`date +%s`
RESOLV=/etc/resolv.conf
# Do not edit bellow this point
# Removes any reference to nameservers in the
# resolv.conf file
cat $RESOLV | grep -v nameserver > $TMPFILE
# Runs the client and adds the output of the command
# to the resolv.conf file
$DHCP6C -f $DEV 2>> $TMPFILE &
# Waits for a few seconds (for the server to provide
# the address to us) and kills the dhcp6c client.
sleep 5
kill `cat $PIDFILE`
# Copies the file to the correct place and removes
# the temporary file
cp $TMPFILE $RESOLV
rm $TMPFILE
Evaluation
This FreeBSD implementation provides the basic functionality that is missing in the stateless
autoconfiguration, that is, the dns discovery. With the small script we have developed, this
implementation can be used without problems.
4.6.3. Proposed testbed.
In our stable testbed we have used a FreeBSD host and a FreeBSD DHCPv6 server. As
showed on the figures the host uses stateless IPv6 autoconfiguration to acquire IPv6 address
and gateway address, while it uses DHCPv6 to acquire DNS server address.
Page 177 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The following figures summarize in a graphical way the whole autoconfiguration approach
used in out testbed.
Figure 78 – Stateless IPv6 autoconfiguration (1)
Figure 79 - Stateless IPv6 autoconfiguration (2)
4.7. QOS - Differentiated Services
The goal of any network willing to offer QoS is to offer it in an end-to-end basis. Therefore, in
the case of diffserv, this fact implies that all the routers in any end-to-end path in the network
should be diffserv-enable. Because if a no-diffserv domain is crossed all the QoS guarantees
are lost. Furthermore, if native IPv6 services must be offered, that means that there must be
IPv6 diffserv support in all the routers along the path. Both requirements make the
deployment of a permanent diffserv domain in the LONG network very difficult with the
current equipment and network services available.
Page 178 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
There are some problems to solve before a diffserv network among all the partners could be
deployed. First, the current network of the LONG project was mostly built using IPv6 over
IPv4 tunneling mechanisms that traverse the Spanish Academic Research Network (RedIRIS)
for the Spanish partners, the Portuguese Academic Research Network (FCCN) for the
Portuguese partners and Geant links for the interconnection between both countries. There are
also other commercial services networks being used to connect some of the companies
involved in the project. Second, as far as we know, there is not yet a clear idea of how to offer
QoS to the users of all these networks, e.g. through Geant’s Premium service. And all the
current discussion deals with IPv4 services. The deployment of fully-IPv6 diffserv
architectures will have to wait a little more due to lack of commercial diffserv routers (except
those mentioned in section 2). As soon as QoS services are provided by GEANT and NRN a
stable platform with QoS will be deployed in LONG network.
4.8. Mail
This section describe the procedures to install the Sendmail MTA package and how to
configure it for intradomain use, that is, where only one machine has sendmail installed. All
the machines in the network will configure this machine as the SMTP server. The server will
listen to IPv4 and IPv6 connections. The local mail must be checked in the SMTP server, via
telnet, using a local mail program, like ‘mail’, ‘elm’ or ‘pine’, because a POP3 is not installed
yet.
Note that this configuration procedure is not a “elegant” configuration, because no security or
interdomain connection have been considered.
The configuration is done for the machine “cocodrilo”, with IPv6 address “cocodrilo6”. The
domain where cocodrilo is connected is tid.long.
The package may be obtained from the original source, the Sendmail
http://www.sendmail.org. The one installed and configured is the version 8.12.1.
web,
Uncompress it in a temporal directory. A sendmail-8.12.1 directory will be created. In the
document, that directory will be referred as BASE, so if Sendmail is uncompressed in /tmp,
BASE is /tmp/sendmail-8.12.1
Go to BASE/sendmail and edit the file conf.h. This header file contains some definitions that
select what is compiled and what not.
Comment lines 148 “#ifndef NETINET6” and 150 “#endif” preceding them with //.
In line 149, change the 0 for 1, so the line looks “#define NETINET6 1”.
In the same directory, compile Sendmail with:
# sh Build
Sendmail uses a group and a user called smmsp, so they must be created before installing it.
# groupadd smmsp
# useradd –g smmsp smmsp
Be sure that there is not an older sendmail running:
# killall sendmail
Now sendmail can be installed.
# sh Build install
Page 179 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
The installation procedure creates the configuration directory /etc/mail with some files by
default. The spooling directory is /var/spool/mqueue for messages files pending and
/var/spool/mail with the received messages in mbox format.
Go to BASE/cf/cf.
Copy the file generic-linux.cf to /etc/mail with the name sendmail.cf:
#cp generic-linux.cf /etc/mail/sendmail.cf
Edit it. Comment lines 227 and 228, so they are:
227: # O DaemonPortOptions=Name=MTA
228: # O DaemonPortOptions=Port=587, Name=MSA, M=E
This disables the MSA service. If it is activated, sendmail will not listen to IPv6. The cause is
unknown for now.
Add the line 229:
229: O DaemonPortOptions=Family=inet6
Remove the comment in line 232:
232: O ClientPortOptions=Family=inet, Address=0.0.0.0
Add the line 233:
233: O ClientPortOptions=Family=inet6
This will enable the IPv6 socket. With this configuration, sendmail will accept local mail.
Local mail doesn’t have a @. The addresses of local mail are just the accounts created in the
machine. To accept addresses of the local domain, for example, igo@tid.long, some
configuration changes are needed.
Add in line 69 (after Cwlocalhost):
69: Cwtid.long
Uncomment line 76 and change it to look:
76: Dj$w.tid.long
With these changes, sendmail will complain if it receives a mail to igo@tid.long, because it
will consider that the mail must be relayed (received outside cocodrilo6 and the destination is
outside cocodrilo6). To avoid this behavior, comment line 1070:
1070: # R$*
$#error $@ 5.7.1 $: "550 Relaying denied"
Please note that with this line, Relay is enabled, so it will accept mail from any domain and to
any email address. If destination is not in domain .tid.long, it will ask for the MX entry and
send the mail to the destination MTA, allowing anyone to send mail. This is specially
dangerous if a spammer found this server, because it may use it to send mail to thousands or
millions of email addresses. As cocodrilo6 is in a private network, the problem doesn’t exist.
This behavior must be corrected before connecting it to a public network.
Now Sendmail is configured for local use. To launch it:
# sendmail –bd
To try it, connect to localhost 25 using IPv6 and send a test message, as in this example. Blue
indicates text sent.
[prueba@cocodrilo prueba]$ telnet6 cocodrilo6 25
Trying 3ffe:3328:6:3::148...
Page 180 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Connected to cocodrilo6.
Escape character is '^]'.
220 cocodrilo.tid.long ESMTP Sendmail 8.12.1/8.12.1; Fri,
17:35:32 +0100
HELO tid.long
250 cocodrilo.tid.long Hello [IPv6:::1], pleased to meet you
MAIL FROM: prueba@tid.long
250 2.1.0 prueba@tid.long... Sender ok
RCPT TO: prueba@tid.long
250 2.1.5 prueba@tid.long... Recipient ok
DATA
354 Enter mail, end with "." on a line by itself
It works! Great!
25
Jan
2002
.
250 2.0.0 g0PGZWdC027101 Message accepted for delivery
QUIT
221 2.0.0 cocodrilo.tid.long closing connection
Connection closed by foreign host.
[prueba@cocodrilo prueba]$ mail
Mail version 8.1 6/6/93. Type ? for help.
"/var/spool/mail/prueba": 1 message 1 new
>N 1 prueba@tid.long
Fri Jan 25 17:36 11/396
& 1
Message 1:
From prueba@tid.long Fri Jan 25 17:36:17 2002
Date: Fri, 25 Jan 2002 17:35:32 +0100
From: Usuario de Prueba <prueba@tid.long>
It works! Great!
& quit
Saved 1 message in mbox
[prueba@cocodrilo prueba]$
If Sendmail complains about forged IP addresses or if it is unable to resolve IP addresses,
comment the following lines in sendmail.cf:
1124: #R<FORGED>
$#error $@ 5.7.1 $: "550 Relaying denied. IP
name possibly forged " $&{client_name}
1125: #R<FAIL>
$#error $@ 5.7.1 $: "550 Relaying denied. IP
name lookup failed " $&{client_name}
4.9. Telecoconference
4.9.1. ISABEL application
ISABEL sessions are based on two main configuration parameters: the node which is playing
the Master role and the network service at the application level.
In some cases, as we have seen in section 3.4.1, ISABEL requires connectivity from every
Interactive site to the Master of a session. Hence, when selecting the Master site this
requirement should be took into account.
ISABEL network service at the application level is provided by the Irouter component. The
Irouter component provides a multicast virtual network between all participants of an ISABEL
session in order to transmit multimedia flows. ISABEL allows two different network
scenarios configuring the Irouter component:
Page 181 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
1. Unicast point-to-point connections.
2. Multicast communication.
In deliverable D3.2, local test scenarios using these network configurations were deployed. In
the following subsections scenarios connecting all LONG participants are defined.
1. Unicast point-to-point connections
The unicast point-to-point configuration depends on the physical network topology. The
ISABEL FlowServer is used in some network nodes to provide an efficient routing of
multimedia flows.
LONG
network
Other
partner
UPM
NOR
PTIN
TID
UC3M
UEV
UPC
Master
Interactive
Figure 80 - UPM site connected to each LONG partner.
The first tests are based on a configuration to connect only two LONG participants: UPM
connected to each LONG partner, see Figure 80. This is the simplest scenario to test the
application using an IPv6 network.
More complex scenarios are defined with all LONG partners. Figure 81 shows one of the
virtual network configurations at application level. This tree configuration is based on the
physical network. In this session, UPM plays the Master role and the rest of LONG partners
are configured as Interactive sites. The blue lines in Figure 82 are the connections between
Irouters to perform the Irouters tree configuration.
Page 182 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
MS: Master site
IS: Interactive Site
UPM
MS
UC3M
IS
IS
TID
LONG network
IS
PTIN
NOR
IS
IS
UEV
UPC
IS
Figure 82 - ISABEL virtual network: tree configuration.
Following this configuration, isabel6 or isabel6-v2 scripts can be started. Each one of
them executes a different implementation of the ISABEL reliable transport layer, providing
the same service.
2. Multicast communication
The multicast configuration uses a native IP multicast network. Since all LONG partners do
not support multicast routing protocols over IPv6, it is impossible to define an ISABEL virtual
network over native IPv6 multicast and heterogeneous solutions are proposed.
Figure 83 shows a solution combining point-to-point and native multicast communication.
UPM plays the Master role and the rest of LONG partners are configured as Interactive sites.
Only UPM and PTIN sites are using native multicast network over IPv6 in their own internal
networks. Hence, both LONG partners UPM and PTIN can connect other Interactive sites to
the same session using native multicast network. The rest of connections are the same as the
ones shown in the Figure 82
Page 183 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
MS: Master site
IS: Interactive Site
IS
UPM
MS
TID
IS
multicast
UC3M
IS
IS
PTIN
IS
LONG network
multicast
IS
IS
NOR
IS
IS
UPC
UEV
IS
Figure 83 - ISABEL virtual network: multicast and point-to
4.10. News
4.10.1. Proposed testbed
The scenarios can include several servers and clients in IPv6 and IPv4 networks talking with
each other. Connections to a news server are established using a single TCP destination port,
119, so both NAT and TRT could be used.
Page 184 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Ipv4 News
Server/Client
Dual Stack
Router
Internet
LONG
IPv6 Network
IPv6
News
client
INN IPv6
Server
IPv6 News
Server/Client
Figure 84 – News IPv6 & IPv4 scenario
4.10.2. Installation Guide
INN was our choice due to is widespread usage all over the Internet. To install INN in a *nix
server, do the following:
1. Get the original.
You can get the original source code from ftp://ftp.isc.org/isc/inn/inn-2.3.2.tar.gz
2. Get the patch.
You can get it via anonymous FTP ( ftp://ftp.north.ad.jp/pub/IPv6/INN/inn-2.3.2v6-20010807.diff.gz).
3. Extract the original source code and the patch.
# gzip -dc inn-2.3.2.tar.gz | tar xf # gzip -d inn-2.3.2-v6-20010807.diff.gz
4. Apply the patch.
# cd inn-2.3.2
# patch -p1 < ../inn-2.3.2-v6-20010807.diff
5. Build
# ./configure –enable-ipv6
# make
Page 185 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
6. Install and start server.
Please see the document of the original source code.
7. Configuration notice for inn.conf.
If you want to accept IPv6 hosts/servers, you should add the following line to your
"inn.conf":
listenonipv6:
yes
Some parameters are available for IPv6 environment in inn.conf. Please see
inn.conf(5).
8. Configuration notice for readers.conf.
You can write IPv6 addresses in your "readers.conf" for access control. Wildmat
expression for IPv6 addresses are not tested, but "network-address/prefix" style (e.g.
"3ffe:500::/24") may work.
4.11. IRC
The aim of the IRC architecture in the LONG network is to seamlessly support
communication among both IPv4 and IPv6 clients. The IRC service is widely used for
connecting the different partners for the execution of experiences (including Isabel events).
The deployment of the service in the LONG network is based in the following server
architecture:
UPM
UC3M
Malpica
IPv4
Mira
IPv4
TRT translator
IPv6
IPv4
ti
connection
IPv6 connection
Alacran
(IPv6)
Viena
(IPv6/IPv4)
Figure 85 - IRC server architecture in the LONG network
In alacran (FreeBSD), an IPv6-only IRC server has been installed. IPv6 clients can connect
directly to this server. In mira.ipv4 (this is the label that identifies the IRC server), an IPv4only IRC server has been installed.
To be able to communicate alacran.uc3m.long with mira.uc3m.long, a translation mechanism
is required. Connections are established using a single TCP destination port, 7000, so both
NAT and TRT could be used. In fact, we have tested both configurations. Finally the TRT
option has been deployed, with the FreeBSD faithd process running in mira. If more services
Page 186 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
are to be translated, NAT would be a better option, since just one translator and configuration
file are required. In this case, TCP relay is performed for just the selected port; no Application
Level Gateway is required for the IRC protocol. However, IRC servers have to be configured
to establish its communication from the IPv6 server to the IPv4 server, and not in the opposite
direction, because the faithd implementation only allow 6-to-4 translating. DNS ALG is not
required neither for server communication (server configuration uses IP addresses) nor for
client communication (each client is intended to access the server with the same IP version).
In the UPM side, the IRC server installed in viena.upm.long accepts connexions from both
IPv4 and IPv6 machines (an IPv6 socket opened for accepting connections in all its interfaces
can also receive IPv4 packets – whose source address is shown as a IPv4-mapped address).
Malpica.upm.long uses IPv4 to communicate with viena.upm.long.
Below we detail alacran’s configuration file (ircd.conf, FreeBSD IRC server, ircd2.10.3):
The C/N configuration sequence specifies the server connections. There must be a N entry
(showing what servers are allowed to connect with this) per C entry (showing what servers are
to be contacted by mira). The separator used is “%”. The presence of a port number in the
second last parameter of the C entry implies that this server will try to establish the connection
with its partner just after being executed.
C%3ffe:3328:4:1:210:4bff:fe70:9bbf%passwd1%viena.upm.long%7000%2
N%3ffe:3328:4:1:210:4bff:fe70:9bbf%passwd2%viena.upm.long%%2
c%3ffe:3328:6:4444::163.117.139.166%passwd3%mira.uc3m.long%7000%2
N%3ffe:3328:6:4444::163.117.139.166%passwd4%mira.uc3m.long%%2
Note that 3328:6:4444::163.117.139.166 is an address with an IPv6 prefix reserved for
mapping IPv4 addresses; in this case, the mapped IPv6 address corresponds to mira.
Finally, to ease client operation, several new DNS registers have been created:
irc
IN
A
163.117.139.166
irc
IN
A
163.117.139.160
irc
IN
AAAA 3ffe:3328:6:ffff:2c0:26ff:fea3:5df6
Therefore, an IPv4-only will obtain an IPv4 address for the IRC server, while clients with
IPv6 connectivity, and appropriate client support, will obtain an IPv6 address.
Basic tests of connectivity have been performed to test IRC interworking: IPv4 clients
accessing IPv4 servers, communicating with IPv6 clients accessing IPv6 servers.
The server tested is ircd. There are several IRC clients: BitchX works also for Windows;
UNIX IPv6 ported clients are xchat, kvirc.
4.12. NFS
This section describes the scenarios, which will be deployed in LONG project with NFS. Two
scenarios are proposed: one is to deploy the NFS over IPv6 native network, while the other is
to deploy a mixed IPv4/IPv6 network. In the last case, a translator mechanism, between the
IPv4 and IPv6 network is used.
At this moment, only a freeBSD 5.0 current supports the IPv6-NFS. So, we chose this
software to implement a file server.
Page 187 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Scenario A
Figure 86 presents the scenario the NFS over IPv6 native network.
File
Server
NFS-Client
NFS-Server
IPv6 Network
Figure 86 – NFS over IPv6 Network
Configuration of the NFS-Server
nfsd – The NFS daemon which services request from NFS clients
mountd – The NFS Mount daemon which actually carries out requests that nfsd passes on it.
portmap – The portmapper daemon which allows NFS clients to find out which port the NFS
server is using.
Edit the /etc/rc.conf file and make sure you have
portmap_enable=”YES”
nfs_server_enable=”YES”
nfs_server_flags=”-u –t –n 4”
mountd_flags=”-r”
mountd is automatically run whenever the NFS server is enable. The –u and –t flags to nfsd
tell it to serve UDP and TCP clients. The –n 4 flag tells nfsd to start 4 copies of itself.
Configuration of NFS-Client
nfsiod – The NFS async I/O daemon which services requests from its NFS server.
Edit the /etc/rc.conf and make sure you have:
nfs_client_enable=”YES”
nfs_client_flags=”-n 4”
Like nfsd, the –n 4 flag tells nfsiod to start 4 copies of itself
Page 188 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Last configurations
On server machine create a file called /etc/exports. The exports file specifies which file
system on your server will be shared and with what clients they will be shared. Here is an
example /etc/exports entries:
/usr/home –maproot=root NFS-client
With –maproot flag the credential of the root user is used for remote access by root. On this
situation the /etc/hosts file must be configure with the NFS-client address.
After perform the above configurations, both machines needs to be restarted.
On client machine for mount a remote file system is necessary to execute the following
instruction:
mount server_name:/usr/home /client
At this time the file system should be already mounted.
Scenario B
Figure 87 presents the scenario the NFS over IPv6/IPv4 network. The NFS-server and NFSclient configurations are same on scenario A.
File
Server
NFS-Server
IPv4
NFS-Client
IPv6 Network
IPv4 Network
Translation
mechanism
Figure 87 – NFS over Network over mixed IPv4/IPv6
4.13. Remote Authentication Dial In User Service
Regarding actual scenarios to be deployed in LONG testbed, as there isn't yet any RADIUS
IPv6-enabled implementation available it won't be possible for now to refer neither support
nor configuration regarding this protocol.
Nevertheless it's expected to have NavisRADIUS 4.2 available very soon and this
implementation will support IPv6 attributes. It will then be possible to deploy any of the
scenarios referred in section 2 (AAA/RADIUS). For that purpose it will be used a Nortel
Passport 2430 router with BRI and 10/100 interfaces and IPv6 PPP Control Protocol
(IPv6CP), acting as an access server. This router will act as a RADIUS client -it can receive
an IPv6 dial-in and pass it to a configured AAA Linux sever. In order to recognize the access
Page 189 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
server it will be necessary to update the "dictionary file" in order to define the "vendorspecific attributes (VSAs)" from Nortel.
Some information available concerning this equipment configuration is available at
[NORTELW].
4.14. LDAP
The following figure is a proposal to provide LDAP services at the LONG network. An LDAP
IPv6 server will be installed at the UPC. This LDAP server can receive requests from a IPv6
client thru the LONG IPv6 network in a “native way”. Another IPv4 LDAP server will be
installed, this one at the UC3M. This server could be a “replica” of the first one, It also could
be part of a distributed LDAP architecture with partitioned information. But for the simple
scenario in figure below distribution may have no sense. Anyway the functional test of the
protocol is the same in both cases. Both servers have to communicate to update the
information, and thus, the UC3M IPv4 LDAP server must include a NAT-PT to provide
translation of IPv6 ß à IPv4 packets. IPv6 packets would travel thru the LONG IPv6
network. In this scenario, IPv4 LDAP clients are also taken into consideration. They can
natively exchange information to the UC3M IPv4 LDAP server (using the IPv4 Network) and
using NAT-PT with the UPC IPv6 LDAP server (again thru the IPv4 Network). Finally the
IPv6 LDAP clients can also talk with the IPv4 LDAP Server using the NAT-PT implemented
on the UC3M server.
UPC
LONGv6 Network
UC3M (replica)
LDAP
Server
IPv6 NAT-PT
LDAP
Server
NAT-PT IPv4
LONG
IPv6
Network
IPv4
Network
LDAP
Client
IPv4
LDAP
Client
IPv6
Figure 88 - LDAP services at the LONG network
Page 190 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
5. Conclusions
The exponential growth of the Internet and the impending exhaustion of the IPv4 address
space become the IPv6 more and more important every day. The transition from IPv4 to IPv6
is being gradual and the services are being migrated to this new protocol, including services at
network level and services at applications level.
However, not all services have been adapted to IPv6 yet. There are still difficulties in
deploying of services over an IPv4/IPv6 mixed infrastructure.
Several transition mechanisms have been proposed. Most of these mechanisms have been
design to solve basic network service and did not address the requirements of advanced
services.
IPv6 introduces a set of the features that were not present on IPv4. The implementations of
network and application level can take advantage of these features. For example, the IPv6
mobility optimizes the routing between MN and CN by using the Routing Header Option.
Most of the applications that implement the advanced services are few reliable, since are still
in a maturation state. Some aspects related to transition from IPv4 to IPv6 are still discussed
at IETF forum.
It was only possible to present theoretic scenarios over mixed IPv6/IPv4 networks, since many
of the existing proposals for using of these services on theses scenarios are not yet
implemented.
However, it was possible to use implementations of nearly all the services in local IPv6
scenarios.
The work performed until now has permitted to known the current state of the application
available in way to define the services will be deployment in LONG network. Final network
configuration of this network and the services deployment will be presented in the deliverable
2.4.
Page 191 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
6. Glossary and Abbreviations
AG
Security Gateway
AH
Authentication Header
AH
Authentication Header
ALG
Application Level Gateway
API
Application Programming Interface
BIS
Bump-In-the-Stack
CA
Certificate Authorities
CHAP
PPP Challenge Handshake Authentication Protocol
CN
Correspondent Node
DHCP
Dynamic Host Configuration Protocol
DHCPv4
Dynamic Host Configuration Protocol for IPv4
DHCPv6
Dynamic Host Configuration Protocol for IPv6
DNS
Domain Name System
DOI
Domain of Interpretation
DSS
Digital Signature Standard
DSTM
Dual Stack Transition Mechanism
DVMRP
Distance Vector Multicast Routing Protocol
ENR
Extensions Name Resolver
ESP
Encapsulating Security Payload
FA
Foreign Agent
FN
Foreign Network
GRE
Generic Routing Encapsulation
HA
Home Address
HN
Home Network
ICMP
Internet Control Message Protocol
ICMPv4
Internet Control Message Protocol for IPv4
ICMPv6
Internet Control Message Protocol version 6
IETF
Internet Engineering Task Force
IGMP
Internet Group Management Protocol
IKE
Internet Key Exchange
IP
Internet Protocol
IPSec
Security Internet Protocol
Page 192 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
IPv4
Internet Protocol Version 4
IPv6
Internet Protocol Version 6
ISP
Internet Service Provider
LAN
Local Area Network
LAPD
Lightweight Directory Access Protocol
LONG
Laboratories Over Next Generation networks
MBIS
Multicast extensions BIS
MLD
Multicast Listener Discovery
MN
Moblile Node
MOSPF
Multicast Open Shortest Path
MSRIPv6 Microsoft Research IPv6
MTU
Maximum Transmission Unit
NAS
Network Access Server
NAT-PT
Network Address Translation – Protocol Translation
ND
Neighbor Discovery
NFS
Network File System
NH
Next Header
PAP
Password Authentication Protocol
PHB
Per-Hop-Behavior
PIM
Protocol Independent Multicast
PPP
Point-to-Point protocol
QoS
Quality of Service
RADIUS
Remote Authentication Dial In User Service
RPC
Remote procedure Call
SA
Security Association
SAD
Security Association Database
SIIT
Stateless IP/ICMP Translation Algorithm
SLA
Service Level Agreement
SPD
The security Policy Database
TCA
Traffic Conditioning Agreement
TCP
Transmission Control Protocol
TLA
Top Level Aggregate (referred to IPv6 addresses hierarchy)
TM
Transition mechanism
TM
Transition Mechanisms
Page 193 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
TTL
Time To Live
TTP
Trust Third Parties
UDP
User Datagram Protocol
URL
Uniform Resource Locator
V4
Version 4 (referred to IPv4 issues)
V6
Version 6 (referred to IPv6 issues)
Page 194 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
7. References and Bibliography
[ALTQ]
http://www.csl.sony.co.jp/person/kjc/programs.html#ALTQ
[ARES]
José María Ares “Servicios de directorio en GNU/Linux: OpenLDAP” –
Linux Año 1 Número 14, October 2000 (In Spanish)
[CISTRAD]
Cistron RADIUS server, http://www. radius.cistron.nl/
[D- DHCPv6] Droms et al. “Dynamic Host Configuration Protocol for IPv6 (DHCPv6)”.
IETF (work in progress),.draft-ietf-dhc-dhcpv6-21, November 2001.
[D-AANYC] Jun-ichiro itojun Hagino, K. Ettikan, “An analysis of IPv6 anycast”, IEFT
(work in progress), draft-ietf-ipngwg-ipv6-anycast-analysis-00.txt ,January
2001.
[D-ADNSv6]
[D-AMH]
Thaler, Dave, Analysis of DNS Server Discovery Mechanisms for IPv6”,
IETF (work in progress),. draft ietf-ipngwg-dns-discovery-01,.March 2001.
M. Ohta, “ The Architecture of End to End Multihoming”, IETF. (work in
progress), 2001.
[D-DAS6]
Draves, R., Default Address Selection for IPv6, IETF, draft-ietf-ipngwgdefault-addr-select-04, May 2001.
[DHCPv6Lx]
DHCPv6 Linux page: http://www.hycomat.co.uk/dhcp/ (links
some KAME project code)
EURESCOM. ‘DISCMAN - Differentiated Services - Network Configuration
and
Management.’
http://www.eurescom.de/public/projects/P1000series/p1006/default.asp
[DISCMAN]
[D-IUNIC]
T. Hain, “An IPv6 Provider-Independent Global Unicast Address Format”,
IETF, (work in progress), 2001.
[D-LIN6]
F. Teraoka, M. Ishiyama, M. Kunishi, A. Shionozaki, “LIN6: A Solution to
Mobility and Multi-Homing in IPv6”, IETF (work in progress), 2001.
[D-MADR6]
Jung-Soo Park, Myung-Ki Shin and Yong-Jin Kim, “Host-based IPv6
Multicast Addresses Allocation”, draft-park-host-based-mcast-01.txt, IETF,
(work in progress)
[D-MH4]
J. Abley, B. Black, V. Gill, “IPv4 Multihoming Motivation, Practices and
Limitations”, IETF (work in progress), 2001.
[D-MH6]
B. Black, V. Gill, J. Abley, “Requirements for IPv6 Site-Multihoming
Architectures”, Work in progress, 2001.
[D-MHSER]
Hagino, J.: IPv6 multihoming support at site exit routers, draft-ietf-ipngwgipv6-2260-01,. IETF (work in progress), April 2001.
[D-MHTP]
M. Py, “Multi Homing Translation Protocol”, IETF (work in progress), 2001.
[D-MIPv6]
Johnson and Perkins, Mobility Support in IPv6,
http://www.mipl.mediapoli.com/drafts/draft-ietf-mobileip-ipv6-14.txt
Page 195 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
[D-MTRNS]
K.Tsuchiya, H. Higuchi, S. Sawada and S. Nozaki, “An IPv6/IPv4 Multicast
Translator based on IGMP/MLD Proxying”, draft-ietf-ngtrans-mtp-00.txt,
IETF (working in progress), 2001.
[D-PIM6]
B. Haberman, H. Sandick, and G. Kump, “Protocol Independent Multicast
Routing in the Internet Protocol Version 6 (IPv6)”,draft-ietf-pim-ipv6-03.txt,
IETF (working in progress), 2000.
[D-PTCPS]
P. Tattam, “Preserving active TCP sessions”, IETF (work in progress).
[DSWG]
IETF’s Diffserv Working Group. http://www.ietf.org/html.charters/diffservcharter.html
[D-TCPANYC]
Jun-ichiro itojun. “Disconnecting TCP connection toward IPv6 anycast
address”, IETF (work in progress), 2001
[FREERAD]
FreeRADIUS Server Project, http://www.freeradius.org/
[FREESW]
Introduction to FreeS/WAN,
http://www.freeswan.org/freeswan_trees/freeswan-1.94/doc/intro.html
[FSWAM]
Introduction to FreeS/WAN,
http://www.freeswan.org/freeswan_trees/freeswan-1.94/doc/intro.html
[HUITEMA]
C. Huitema, “Routing in the Internet”, 2ª edition, Prentice Hall[I2000M]
“Implementation and Deployment of IPv6 Multicast”,
http://www.isoc.org/inet2000/cdproceedings/1c/1c_2.htm
[IBM]
Heinz Johner, Larry Brown, Franz-Stefan Hinner, Wolfgang Reis and Johan
Westman. ‘IBM® International Technical Support Organization,
Understanding LDAP’ June 1998
[IPsec]
IP Security Protocol (IPsec) Charter, http://www.ietf.org/html.charters/ipseccharter.html
[IPSEC]
IP Security Protocol (IPsec) Charter, http://www.ietf.org/html.charters/ipseccharter.html; All RFCs and Drafts mentioned in the IPsec Charter Web Page
[IPv6NOR]
Nortel IPv6 Products,
http://www.nortelnetworks.com/corporate/technology/ipv6/products.html
[KAME]
[KUROSE]
KAME project: http://www.kame.net/
J. Kurose, K. Ross, “Computer Networking, A Top-Down Approach
Featuring the Internet”, Addison Wesley[LIP6CISCO] About Cisco IOS
IPv6,
http://www.cisco.com/warp/public/732/Tech/ipv6/ipv6_learnabout.shtml
[LUCRAD4]
NavisRadius Version 4.1, http://www.lucentradius.com/
[MIPL]
MIPL Mobile IPv6 for Linux. http://www.mipl.mediapoli.com/
[MSRIP]
Microsoft Research IPv6 implementation,
http://www.research.microsoft.com/msripv6/
[MSRIPv6]
Microsoft Research IPv6 implementation,
http://www.research.microsoft.com/msripv6/
Page 196 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
[NORTELW]
http://www25.nortelnetworks.com/library/tpubs/pdf/router/soft150/index.htm
[OPENLDAP] http://www.openldap.org - OpenLDAP 2.0 Administration Guide
[PEREZ]
Pérez C. and García A. ‘Design of an IPv6 environment. Chapter 2:
Differentiated Services.’ Internal report. Carlos III University. Madrid. 2000.
(in spanish)
[RFC 1777]
W.Yeong, T. Howes and S.Kille ‘Ligthweight Directory Access Protocol’.
IETF RFC 1777. March 1995
[RFC 1823]
T. Howes and M. Smith ‘he LDAP Application Program Interface’. IETF
RFC 1823. August 1995
[RFC1584]
J. Moy, “Multicast Extensions to OSPF”, RFC 1584, 1994
[RFC1886]
Thomson, Huitema, DNS Extensions to support IP version 6, RFC 1886,
IETF, December 1995.
[RFC2002]
Perkins, C., IP Mobility Support, RFC 2002, IETF, October 1996.
[RFC2003]
C. Perkins, “IP Encapsulation within IP”, RFC 2003, 1996
[RFC2080]
G.Malkin and R.Minnear, “RIPng for IPv6”, RFC 2080, 1997
[RFC2131]
R. Droms. Dynamic Host Configuration Protocol. Internet engineering Task f
Force, RFC 2131, March 1997.
[RFC2236]
W. Fenner, “Internet Group Management Protocol, Version 2”, RFC 2236,
1997
[RFC2260]
T. Bates, Y. Rekhter, ”Scalable Support for Multi-homed Multi-provider
Connectivity”, RFC 2260, IETF, 1998.
[RFC2362]
D. Estrin, D. Farinacci, A. Helmy, D. Thaler, S. Deering, M. Handley, V.
Jacobson, C. Liu, P. Sharma and L. Wei, “Protocol Independent MulticastSparse Mode (PIM-SM): Protocol Specification”, RFC 2362, IETF, 1998
[RFC2372]
R. Hinden, S. Deering, “IP Version 6 Addressing Architecture”, RFC 2373,
IETF, 1998
[RFC2373]
R. Hinden and S. Deering, “IP Version 6 Addressing Architecture”, RFC
2373, IETF, 1998.
[RFC2460]
S. Deering and R. Hinden, “Internet Protocol, Version 6 (IPv6)
Specification”, RFC 2460, IETF,1998.
[RFC2462]
Thomson, Narten, IPv6 Stateless Address Autoconfiguration, RFC 1998,
IETF, December 1998.
[RFC2474]
Nichols K., Blake S., Baker F., and Black D. ‘Definition of the Differentiated
Services Field (DS Field) in the IPv4 and IPv6 Headers’. IETF RFC 2474.
December 1998.
Page 197 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
[RFC2475]
Blake S., Black D., Carlson M., Davies E., Wang Z., and Weiss W. ‘An
Architecture for Differentiated Services’. IETF RFC 2475. December 1998.
[RFC2475]
Blake S., Black D., Carlson M., Davies E., Wang Z., and Weiss W. ‘An
Architecture for Differentiated Services’. IETF RFC 2475. December 1998.
[RFC2673]
Crawford, M, Binary Labels in the Domain Name System, RFC 2673, IETF,
1999.
[RFC2710]
S. Deering, W. Fenner and B. Haberman, “Multicast Listener Discovery for
IPv6”, RFC 2710, IETF, 1999
[RFC2740]
R. Coltun, D. Ferguson and J. Moy, “OSPF for IPv6”, RFC 2740, IETF, 1999
[RFC2810]
C. Kalt,. Internet Relay Chat: Architecture. RFC 2810, IETF,. April 2000.
[RFC2811]
C. Kalt. Internet Relay Chat: Channel Management. RFC 2811, IETF,. April
2000.
[RFC2812]
C. Kalt,. Internet Relay Chat: Client Protocol,. RFC 2812, IETF, April 2000.
[RFC2813]
C. Kalt,. Internet Relay Chat: Server Protocol, RFC 2813, IETF,. April 2000.
[RFC2874]
Crawfordm Huitema, DNS Extensions to Support IPv6 Address Aggregation
and Renumbering, RFC 2874, IETF, 2000.
[RFC2893]
Black D. ‘Differentiated Services and Tunnels.’ IETF RFC 2893. October
2000.
[RFC3152]
Bush, R., Delegation of IP6.ARPA, RFC 3153, IETF, 2001.
[RFC3162]
B. Aboba, G. Zorn, D. Mitton, RADIUS and IPv6, RFC 3162, IETF, 2001
[SECCISCO]
An introduction to IP Security Encryption,
http://www.cisco.com/warp/public/105/IPSECpart1.html
[SFAQ]
Solaris IPv6, http://www.sun.com/software/solaris/ipv6/faqs.html
[SuSE]
SuSE Linux http://www.suse.de/es/
[USAGI]
USAGI Project - Linux IPv6 Development Project http://www.linuxipv6.org/
[WIDE]
Project: http://wide.net
Page 198 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Appendix A: Mobile Configuration files.
MOBILE NODE
File: /etc/network-mip6.conf
# MIPL Mobile IPv6 Configuration file
# Should this node act as a home agent (ha), mobile node (mn) or
# correspondent node (cn). HA and MN both have CN functionality
# embedded. Default: cn.
FUNCTIONALITY=mn
# In error situations it may be desired to get more detailed
# information what is happening. Increase this value to get more
# messages from the module (default: 0).
# You need option CONFIG_IPV6_MOBILITY_DEBUG=y in your kernel in order # to
raise this value.
DEBUGLEVEL=1
# Number of tunnel devices MIPL can use. Limits the number of
# simultaneous bindings between different HAs and MNs.
# If commented, there is no limit.
#TUNNEL_NR=10
# Home address for mobile node with prefix length. Example:
# 3FFE:2620:6:1234:ABCD::1/48 (Don't use the example value!)
HOMEADDRESS=3ffe:3328:4:1::5/64
# Home agent's address for mobile node.
HOMEAGENT=3ffe:3328:4:1::6/64
# Configuration file for security associations used for authentication # of
MIPv6 signaling. If commented, there will be no authentication.
#SAFILE=/etc/mipv6_sas.conf
# Mobile nodes are allowed to send Router Solicitation messages at a
# shorter minimum interval than normal IPv6 nodes (default: 4
# seconds). This value controls the mobile nodes minimum Router
# Solicitation interval in seconds (default: 1). If you increase this #
value, the handover time could increase, but you will decrease the
#
number of control packets in your network.
RTR_SOLICITATION_INTERVAL=1
# After sending MAX_RTR_SOLICITATIONS (defined by IPv6, default: 3)
# mobile node reduces Router Solicitation send rate with binary
# exponential back-off mechanism until the maximum send time limit is
# reached. This option sets the maximum send time in seconds.
RTR_SOLICITATION_MAX_SENDTIME=5
HOME AGENT
File: /etc/network-mip6.conf
# MIPL Mobile IPv6 Configuration file
# Should this node act as a home agent (ha), mobile node (mn) or
# correspondent node (cn). HA and MN both have CN functionality
# embedded. Default: cn.
FUNCTIONALITY=ha
# In error situations it may be desired to get more detailed
# information what is happening. Increase this value to get more
# messages from the module (default: 0).
Page 199 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
# You need option CONFIG_IPV6_MOBILITY_DEBUG=y in your kernel in order # to
raise this value.
DEBUGLEVEL=1
# Should unicasts to node's site-local address be tunneled when mobile
# node is not in its home network (default: yes).
#TUNNEL_SITELOCAL=yes
# Number of tunnel devices MIPL can use. Limits the number of
# simultaneous bindings between different HAs and MNs.
# If commented, there is no limit.
#TUNNEL_NR=10
#
#
#
#
Path for a file containing list of IPv6 addresses (and other
information) of mobile nodes for which this node is allowed to act
as a home agent. If commented, there will be no authentication.
MOBILENODEFILE=/etc/mipv6_acl.conf
# Uncomment this to use the new authentication mechanism from draft
# 15. Otherwise the signaling is authenticated only if you compiled AH #
support
#AUTHENTICATION=draft15
# Configuration file for security associations used for authentication
# of MIPv6 signaling.
#SAFILE=/etc/mipv6_sas.conf
Page 200 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Appendix B: DNS Zone files.
In this Appendix zone files can be consulted in case there is any doubt about how to configure
them.
CASE ONE
Primary NS: cocodrilo6.tid.long
§
File db.127.0.0
$TTL 604800
@
IN
SOA
cocodrilo6.tid.long.
1
; serial
86400
; refresh
7200
; retry
3600000
; expiry
86400 )
; minimum
@
IN
NS
cocodrilo6.tid.long.
1
IN
PTR
localhost.
§
cocodrilo6.tid.long. (
File db.localhostv6
$TTL 604800
@
IN
SOA
cocodrilo6.tid.long.
1
; serial
86400
; refresh
7200
; retry
3600000
; expiry
86400 )
; minimum
@
IN
NS
cocodrilo6.tid.long.
1.0.0.0
IN
PTR
localhost.
§
cocodrilo6.tid.long. (
File db.tid.long
$TTL 604800
@
IN
SOA
cocodrilo6.tid.long.
cocodrilo6.tid.long. (
1
; serial
86400
; refresh
7200
; retry
3600000
; expiry
86400 )
; minimum
@
IN
NS
cocodrilo6.tid.long.
@
IN
MX
10
cocodrilo6.tid.long.
error
IN
A
192.168.234.3
unreachable
IN
A
192.168.234.4
Page 201 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
ipv6gw
IN
A
192.168.234.1
gigacom
IN
A
193.146.185.145
cocodrilo
IN
A
193.146.185.148
ipv6gw6
IN
AAAA
3ffe:3328:6:2::1
error6
IN
AAAA
3ffe:3328:6:2::3
unreachable6 IN
AAAA
3ffe:3328:6:2::4
gigacom6
IN
AAAA
3ffe:3328:6:3::2
cocodrilo6
IN
AAAA
3ffe:3328:6:3::148
File db.tid.long.rev
$TTL 604800
@
@
IN
SOA
IN
cocodrilo6.tid.long.
NS
cocodrilo6.tid.long. (
1
; serial
86400
; refresh
7200
; retry
3600000
; expiry
86400 )
; minimum
cocodrilo6.tid.long.
3.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0
IN PTR
error6.tid.long.
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0
IN PTR
ipv6gw6.tid.long.
2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.3.0.0.0
IN PTR
gigacom6.tid.long.
4.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0
IN PTR
unreachable.tid.long.
8.4.1.0.0.0.0.0.0.0.0.0.0.0.0.0.3.0.0.0
IN PTR
cocodrilo6.tid.long.
Forwarder NS: cantonal.tid.long
§
File named.local
$TTL 604800
@
IN
SOA
localhost.
@
IN
NS
localhost.
1
IN
PTR
localhost.
§
root.localhost. (
1
; serial
86400
; refresh
7200
; retry
3600000
; expiry
86400 )
; minimum
File db.localhostv6
$TTL 604800
@
IN
SOA
localhost.
root.localhost. (
1
; serial
86400
; refresh
7200
; retry
Page 202 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
@
IN
NS
localhost.
1.0.0.0
IN
PTR
localhost.
§
3600000
; expiry
86400 )
; minimum
File named.ca
;
This file holds the information on root name servers needed to
;
initialize cache of Internet domain name servers
;
(e.g. reference this file in the "cache
;
configuration file of BIND domain name servers).
.
<file>"
;
;
This file is made available by InterNIC registration services
;
under anonymous FTP as
;
file
;
on server
;
/domain/named.root
FTP.RS.INTERNIC.NET
-OR- under Gopher at
;
under menu
;
submenu
;
file
RS.INTERNIC.NET
InterNIC Registration Services (NSI)
InterNIC Registration Archives
named.root
;
;
last update:
Aug 22, 1997
;
related version of root zone:
1997082200
;
;
; formerly NS.INTERNIC.NET
.
3600000
IN NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET.
3600000
A
.
3600000
NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET.
3600000
A
.
3600000
NS C.ROOT-SERVERS.NET.
C.ROOT-SERVERS.NET.
3600000
A
.
3600000
NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET.
3600000
A
.
3600000
NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET.
3600000
A
198.41.0.4
;
; formerly NS1.ISI.EDU
128.9.0.107
;
; formerly C.PSI.NET
192.33.4.12
;
; formerly TERP.UMD.EDU
128.8.10.90
;
; formerly NS.NASA.GOV
192.203.230.10
Page 203 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
;
; formerly NS.ISC.ORG
.
3600000
NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET.
3600000
A
192.5.5.241
;
; formerly NS.NIC.DDN.MIL
.
3600000
NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET.
3600000
A
192.112.36.4
;
; formerly AOS.ARL.ARMY.MIL
.
3600000
NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET.
3600000
A
128.63.2.53
;
; formerly NIC.NORDU.NET
.
3600000
NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET.
3600000
A
192.36.148.17
;
; temporarily housed at NSI (InterNIC)
.
3600000
NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET.
3600000
A
198.41.0.10
;
; housed in LINX, operated by RIPE NCC
.
3600000
NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET.
3600000
A
193.0.14.129
;
; temporarily housed at ISI (IANA)
.
3600000
NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET.
3600000
A
198.32.64.12
;
; housed in Japan, operated by WIDE
.
3600000
NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET.
3600000
A
202.12.27.33
; End of File.
CASE TWO
Primary NS: cocodrilo6.tid.long
§
File db.127.0.0: This file is the same as for case 1.
§
File db.localhostv6: This file is the same as for case 1.
§
File db.tid.long
$TTL 604800
@
IN
SOA
cocodrilo6.tid.long.
Page 204 of 206
cocodrilo6.tid.long. (
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
1
; serial
86400
; refresh
7200
; retry
3600000
; expiry
86400 )
; minimum
@
IN
NS
cocodrilo6.tid.long.
@
IN
NS
cantonal.tid.long.
@
IN
MX
10
; new entry for sec.NS
cocodrilo6.tid.long.
error
IN
A
192.168.234.3
unreachable
IN
A
192.168.234.4
ipv6gw
IN
A
192.168.234.1
gigacom
IN
A
193.146.185.145
cocodrilo
IN
A
193.146.185.148
ipv6gw6
IN
AAAA
3ffe:3328:6:2::1
error6
IN
AAAA
3ffe:3328:6:2::3
unreachable6 IN
AAAA
3ffe:3328:6:2::4
gigacom6
IN
AAAA
3ffe:3328:6:3::2
cocodrilo6
IN
AAAA
3ffe:3328:6:3::148
File db.tid.long.rev
$TTL 604800
@
IN
SOA
cocodrilo6.tid.long.
cocodrilo6.tid.long. (
1
; serial
86400
; refresh
7200
; retry
3600000
; expiry
86400 )
; minimum
@
IN
NS
cocodrilo6.tid.long.
@
IN
NS
cantonal.tid.long.
3.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0
IN PTR
error6.tid.long.
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0
IN PTR
ipv6gw6.tid.long.
2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.3.0.0.0
IN PTR
gigacom6.tid.long.
4.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0
IN PTR
unreachable.tid.long.
8.4.1.0.0.0.0.0.0.0.0.0.0.0.0.0.3.0.0.0
IN PTR
cocodrilo6.tid.long.
IN PTR
cantonal.tid.long
; new entry for secondary NS resolution
5.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0
Secondary NS: cantonal.tid.long
No changes must be made to zone files. Even no new zone files must be created.
Cantonal.tid.long will obtain them from cocodrilo6.tid.long as explained in section 2.6.1.2
Name Servers.
Page 205 of 206
IST-1999-20393/ PTIN /WP2.4/DS/P/1/b0
Advanced Network Services: description and support in LONG network
Page 206 of 206