5.5 Choosing the Sample Size for Testing 245

17582_05_ch05_p221-289.qxd 11/25/08 3:35 PM Page 245
5.5
Choosing the Sample Size for Testing m 245
5.5
Choosing the Sample Size for Testing
M
The quantity of information available for a statistical test about m is measured by the magnitudes of the Type I and II error probabilities, a and b ( m ), for various values of m in the alternative hypothesis H a
. Suppose that we are interested in testing H
0
: m m
0 against the alternative H a
: m m
0
. First, we must specify the value of a . Next we must determine a value of m in the alternative, m
1
, such that if the actual value of the mean is larger than m
1
, then the consequences of making a Type II error would be substantial. Finally, we must select a value for b ( m
1
), b . Note that for any value of m larger than m
1
, the probability of Type II error will be smaller than b ( m
1
); that is, b ( m ) b ( m
1
), for all m m
1
Let m
1 m
0
. The sample size necessary to meet these requirements is n s
2
( z a z b
)
2
∆ 2
Note: If s 2 is unknown, substitute an estimated value from previous studies or a pilot study to obtain an approximate sample size.
The same formula applies when testing H
0
: m m
0 against the alternative H a
: m m
0
, with the exception that we want the probability of a Type II error to be of magnitude b or less when the actual value of m is less than m
1
, a value of the mean in H a
; that is, b ( m ) b , for all m m
1 with m
0 m
1
.
EXAMPLE 5.11
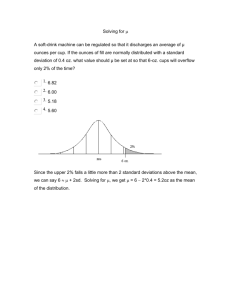
A cereal manufacturer produces cereal in boxes having a labeled weight of 12 ounces. The boxes are filled by machines that are set to have a mean fill per box of 16.37 ounces. Because the actual weight of a box filled by these machines has a normal distribution with a standard deviation of approximately .225 ounces, the percentage of boxes having weight less than 16 ounces is 5% using this setting.
The manufacturer is concerned that one of its machines is underfilling the boxes and wants to sample boxes from the machine’s output to determine whether the mean weight m is less than 16.37
— that is, to test
H
0
: m 16.37
H a
: m 16.37
with a .05. If the true mean weight is 16.27 or less, the manufacturer needs the probability of failing to detect this underfilling of the boxes with a probability of at most .01, or risk incurring a civil penalty from state regulators. Thus, we need to determine the sample size n such that our test of H
0 versus H a has a .05 and b ( m ) less than .01 whenever m is less than 16.27 ounces.
Solution We have a .05, b .01, 16.37 16.27 .1, and s .225. Using our formula with z
.05
1.645 and z
.01
2.33, we have n
( .225
)
2
( 1.645
2.33
)
2
( .1
)
2
79.99
80
Thus, the manufacturer must obtain a random sample of n 80 boxes to conduct this test under the specified conditions.
17582_05_ch05_p221-289.qxd 11/25/08 3:35 PM Page 246
246 Chapter 5 Inferences about Population Central Values
Suppose that after obtaining the sample, we compute y 16.35
computed value of the test statistic is ounces. The z y 16.37
s
1 n
16.35
.225
1
16.37
80
.795
Because the rejection region is z 1.645, the computed value of z does not fall in the rejection region. What is our conclusion? In similar situations in previous sections, we would have concluded that there is insufficient evidence to reject H
0
.
Now, however, knowing that b ( m ) .01 when m 16.27, we would feel safe in our conclusion to accept H
0
: m 16.37. Thus, the manufacturer is somewhat secure in concluding that the mean fill from the examined machine is at least 16.37 ounces.
With a slight modification of the sample size formula for the one-tailed tests, we can test
H
0
: m m
0
H a
: m m
0 for a specified a , b , and , where b ( m ) b , whenever m m
0
Thus, the probability of Type II error is at most b whenever the actual mean differs from m
0 by at least . A formula for an approximate sample size n when testing a two-sided hypothesis for m is presented here:
Approximate Sample Size for a Two-Sided Test of H
0
:
0 n s
2
∆ 2
( z a 2 z b
)
2
Note: If s
2 sample size.
is unknown, substitute an estimated value to get an approximate
5.6
The Level of Significance of a Statistical Test
level of significance p -value
In Section 5.4, we introduced hypothesis testing along rather traditional lines: we defined the parts of a statistical test along with the two types of errors and their associated probabilities a and b ( m a
). The problem with this approach is that if other researchers want to apply the results of your study using a different value for a then they must compute a new rejection region before reaching a decision concerning
H
0 and H a
. An alternative approach to hypothesis testing follows the following steps: specify the null and alternative hypotheses, specify a value for a , collect the sample data, and determine the weight of evidence for rejecting the null hypothesis. This weight, given in terms of a probability, is called the level of significance (or p value ) of the statistical test. More formally, the level of significance is defined as follows: the probability of obtaining a value of the test statistic that is as likely or more likely to reject H
0 as the actual observed value of the test statistic, assuming that the null hypothesis is true.
Thus, if the level of significance is a small value, then the sample data fail to support H
0 and our decision is to reject H
0
. On the other hand, if the level of significance is a large value, then we fail to reject H
0
. We must next decide what is a large or small value for the level of significance. The following decision rule yields results that will always agree with the testing procedures we introduced in Section 5.5.