Analysis and Acceleration for Target ... Jairam Ramanathan
advertisement
Analysis and Acceleration for Target Recognition by Jairam Ramanathan Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Master of Engineering at the BARKER MASSACHUSETTS INSTITUTE OF TECHNOLOGY MASSACHUSETTS INSTITUTE OF TECHNOLOGY JUL 3 12002 February 2001 LIBRARIES @ Jairam Ramanathan, MMI. All rights reserved. The author hereby grants to MIT permission to reproduce and distribute publicly paper and electronic copies of this thesis document in whole or in part. A uthor ...................................... Department of Electrical Engineeri ng and Computer Science February 6, 2001 Certified by....... Paul D. Fiore Senior Principal Engineer, BAE SYSTEMS VI-A Company Thesis Supervisor Certified by....... Dan E. Dudgeon Senior Staff, MIT Lincoln Laboratory MIT Thesis Supervisor Accepted by......... Arthur C. Smith Chairman, Department Committee on Graduate Students Analysis and Acceleration for Target Recognition by Jairam Ramanathan Submitted to the Department of Electrical Engineering and Computer Science on February 6, 2001, in partial fulfillment of the requirements for the degree of Master of Engineering Abstract This thesis examined the hardware acceleration properties of automatic target recognition algorithms. It specifically focused on an algorithm produced by the SystemOriented High Range Resolution Automatic Recognition Program at the WrightPatterson Air Force Base. Analysis of this algorithm determined which calculations would be most suitable for and derive the most benefit from hardware acceleration. The algorithm was appropriately modified and restructured to ease its hardware translation while not significantly affecting the algorithm performance. A portion of the algorithm was then implemented and executed on a custom hardware board containing multiple field-programmable gate arrays, and the timing and algorithmic performance were compared with the corresponding software execution statistics. The near order of magnitude speedup showed the viability of custom hardware acceleration for target recognition algorithms. VI-A Company Thesis Supervisor: Paul D. Fiore Title: Senior Principal Engineer, BAE SYSTEMS MIT Thesis Supervisor: Dan E. Dudgeon Title: Senior Staff, MIT Lincoln Laboratory 2 Acknowledgments Generous financial support for my work was provided by BAE SYSTEMS (formerly Sanders, a Lockheed Martin Company). In particular at BAE SYSTEMS, I would like to thank Dr. Cory Myers for his advice and guidance over the past three years. I would also like to thank my thesis advisors, Dr. Paul Fiore of BAE SYSTEMS and Dr. Dan Dudgeon of MIT Lincoln Laboratory, for their help in bringing my thesis to completion. I would like to thank Ken Smith, John Zaino, and Marion Reine of BAE SYSTEMS, and Eric Pauer, formerly of Sanders, for their assistance and advice while I was undertaking my research. I would finally like to thank my parents for their constant support and encouragement while I pursued my goals. 3 Contents 1 Introduction 9 1.1 Automatic Target Recognition . . . . . . . . . . . . . . . . . . . . . . 9 1.2 Acceleration Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 1.3 Overview of the Thesis . . . . . . . . . . . . . . . . . . . . . . . . . . 13 2 Project Background 3 15 2.1 Initial Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . 16 2.2 Wordlength Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 2.2.1 Bit Precision Assignment . . . . . . . . . . . . . . . . . . . . . 19 2.2.2 Scheduling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 2.3 Final Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 2.4 Synthesis and Generation . . . . . . . . . . . . . . . . . . . . . . . . 24 2.5 Target D evice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 2.6 Sum m ary 25 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . SHARP Algorithm 26 3.1 SAR to HRR Conversion .. . . . . . . . . . . . . . . . . . . . . . . . 28 3.2 Least Squares Fitting. . . . . . . . . . . . . . . . . . . . . . . . 29 3.3 Preprocessing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 3.3.1 . . . . . . . . . . . . . . . . . . . . . . 32 . . . . . . . . . . . . . . . . . . . . . . . . . 33 . .. Power Transformation 3.4 Algorithm Performance. 3.5 Summary ....... ... ................. 4 .. ... ..... .. 35 4 5 36 Software Analysis 4.1 Timing Analysis ........... 37 4.2 Least Squares Fit . . . . . . . . . . 38 4.2.1 QR Factorization Approach 39 4.2.2 Matched Filter Approach . 40 4.3 Power Transformation . . . . . . . 46 4.4 Revised Timing Analysis . . . . . . 46 4.5 Summary . . . . . . . . . . . . . . 47 49 Hardware-Specific Analysis 5.1 5.2 5.3 Power Transformation . . . . . . . . . . . . . . . . . . . . . . . . . . 50 . . . . . . . . . . . . . . . . . . . . 50 5.1.1 Vector Transformation 5.1.2 Vector Averaging..... 54 Least Squares Fitting . . . . . . . 5.2.1 Bias Removal and Magnitu< Normalization 5.2.2 Correlation Summary 55 55 . . . . . . . . 58 . . . . . . . . . . . . . 61 62 6 Performance Comparison 6.1 Bias Removal and Normalization 6.2 Correlation . . . . . . . . . . . . 68 6.3 Final Comparison Estimates . . . 72 63 6.3.1 Algorithm Performance . 72 6.3.2 Algorithm Timing..... 73 6.4 Proposed Improvements..... 6.5 Summary 74 . . . . . . . . . . . . . 75 7 Summary 76 A Acronyms 78 5 List of Figures 1-1 Overview of forced decision and threshold decision methods. (a) Forced decision. (b) Threshold decision . . . . . . . . . . . . . . . . . . . . . 10 1-2 SHARP Approach 11 2-1 Ptolemy Screenshots. (a) ACS Domain Palette (b) Example Dataflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . D iagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-2 Wordlength Analysis Tool Outputs. 18 (a) All cost-variance pairs (b) Pareto-optimal cost-variance pairs . . . . . . . . . . . . . . . . . . . . 22 3-1 Segmentation of SAR image to simulate Doppler filtering . . . . . . . 28 3-2 SHARP Algorithm Block Diagram 29 4-1 Range shifting of a bmp263 target by using 70-windows. (a) Original . . . . . . . . . . . . . . . . . . . 80-vector (b)-(l) 11 70-wide range shifts from rightmost to leftmost. . 4-2 43 Range shifting of a bmp263 target by using 80-windows. (a) Original 90-vector. (b)-(l) 11 80-wide range shifts from rightmost to leftmost. . 45 5-1 Power Transformation Block Diagram . . . . . . . . . . . . . . . . . . 51 5-2 Divider Output - Floating Point and <4.8> Fixed Point . . . . . . . 52 5-3 LUT Output - Floating Point Input and <4.8> Fixed Point Input . . 53 5-4 LUT Output - Floating Point and <1.8> Fixed Point . . . . . . . . . 53 5-5 LUT Output - Floating Point Input and <1.8> Transformed Divider Input......... .................................... 54 5-6 Normalization Block Diagram . . . . . . . . . . . . . . . . . . . . . . 56 5-7 Ptolemy Normalization Design . . . . . . . . . . . . . . . . . . . . . . 57 6 5-8 Correlation Block Diagram . . . . . . . . . . . . . . . . . . . . . . . . 58 5-9 Ptolemy Correlation Design . . . . . . . . . . . . . . . . . . . . . . . 60 6-1 Execution Schedule for the Normalization Routine . . . . . . . . . . . 64 6-2 FPGA Occupancy for the Normalization Routine . . . . . . . . . . . 65 6-3 Input Signature to Normalization Routine . . . . . . . . . . . . . . . 66 6-4 Normalization Routine - Software and Hardware . . . . . . . . . . . . 66 6-5 Normalization Routine - Floating Point and Modified Fixed Point . 67 6-6 Execution Schedule for the Correlation Routine . . . . . . . . . . . . 69 6-7 FPGA Occupancy for the Correlation Routine . . . . . . . . . . . . . 70 6-8 Correlation Target Signature . . . . . . . . . . . . . . . . . . . . . . . 71 6-9 Correlation Template Signature . . . . . . . . . . . . . . . . . . . . . 71 6-10 Correlation by Range Shift . . . . . . . . . . . . . . . . . . . . . . . . 72 7 . List of Tables 3.1 Confusion Matrix by Vehicle Using Original AFRL Code 3.2 Confusion Matrix by Vehicle Type Using Original AFRL Code . . . 34 . . . 34 4.1 Timing Analysis of Original Software . . . . . . . . . . . . . . . . . . 38 4.2 Confusion Matrix by Vehicle Using Matched Filter . . . . . . . . . . 44 4.3 Confusion Matrix by Vehicle Type Using Matched Filter . . . . . . . 44 4.4 Timing Analysis of Optimized Software . . . . . . . . . . . . . . . . . 47 5.1 Elementary Function Blocks . . . . . . . . . . . . . . . . . . . . 50 6.1 Normalization Design Bit Precisions . . . . . . . . . . . . . . . . . . . 63 6.2 Correlation Design Bit Precisions . . . . . . . . . . . . . . . . . . . . 68 6.3 Confusion Matrix by Vehicle Using Fixed-Point Simulation . . . 72 6.4 Confusion Matrix by Vehicle Type Using Fixed-Point Simulation . . . 73 8 . . Chapter 1 Introduction Automatic target recognition (ATR) is an important part of many military applications. The ability to discriminate between hostile and friendly targets as well as the ability to differentiate between various hostile targets are often mission critical objectives for real-time systems. As such, it is a common priority to produce the best possible recognition performance in the least possible time. In terms of execution speed, there are limits to what can be currently accomplished in software. Many high-speed applications are turning to dedicated hardware to provide an execution speed that software cannot attain. ATR is a promising candidate for hardware execution. ATR systems are computationally intensive, but the computations performed are highly repetitive, enabling even a minor speedup to significantly improve execution time. In this chapter, we present a brief introduction to ATR, examine the major issues to be considered for acceleration and discuss our method of approach, and finally present an outline for the remainder of the thesis. 1.1 Automatic Target Recognition Target recognition entails classifying a target given characteristic signatures (templates) of several target classes. It is important to note that the number of different types of observable targets will generally exceed the number of targets for which tem- 9 plates are available. Consequently, a design choice must be made to deal with the situation that the target does not belong to any of the template classes. There are two reasonable options: the identifier can either match the target as well as possible to one of the template classes (forced-decision) or it can leave the target unclassified (threshold-decision). These approaches are shown in Figure 1-1. Observation Profile rATR AspectTret iTarget ID DTemnplated (a) Observation Profile A TR or tifier, BelowTagtI Threshicld Aspect T e TUnknown (b) Figure 1-1: Overview of forced decision and threshold decision methods. (a) Forced decision. (b) Threshold decision. There are strengths and shortcomings to both threshold-decision and forceddecision approaches. Forced-decision methods are guaranteed to classify all known targets. However, they will also (incorrectly) identify all unknown targets. Conversely, threshold-decision methods will leave most unknown targets unclassified. However, they will generally also fail to identify some known targets. It is computationally more intensive to implement a threshold-decision approach. Before classifying any target, the decision must be made whether that target should be classified at all. In many cases, all the calculations for a forced-decision approach must be repeated in a threshold-decision approach, but end up unused due to the threshold comparison. Consequently, the method chosen for a particular application depends strongly on the performance and computational specifications. The extent to which the template set spans the possible target set also strongly impacts the choice of approach. 10 ATR Adar Target ID Figure 1-2: SHARP Approach The Air Force Research Laboratory (AFRL) at Wright-Patterson Air Force Base (WPAFB) has developed an algorithm that implements a forced-decision method. The algorithm attempts to classify targets given their high range resolution (HRR) radar signatures. Their approach is called the System-Oriented HRR Automatic Recognition Program (SHARP) [32]. The basic premise of the SHARP approach is shown in Figure 1-2. The SHARP objective is to develop and mature advanced air-to-ground HRR ATR capabilities for transition into suitable operational Air Force airborne platforms. It is clear that in an application of this type, it is desirable to minimize the latency between data collection and classification. Therefore, this thesis examined a framework that provided the SHARP algorithm with a significant speedup via hardware acceleration. Field-programmable gate arrays (FPGAs) have received a great deal of attention in recent years. FPGAs are hardware devices that contain a large array of small configurable logic blocks (CLBs) surrounded by many routing resources [10]. Consequently, they can be easily reconfigured to perform functions required by the user. This thesis used custom hardware containing FPGAs to achieve the hardware acceleration of the SHARP algorithm. 1.2 Acceleration Issues The first stage of acceleration is purely at the software level. In order to properly reap the benefits of hardware acceleration, an algorithm must be reorganized and modified in a manner that is conducive towards hardware mapping. In many cases, this reor- 11 ganization actually provides a speed gain for software execution. However, this gain is even more pronounced when demonstrated in the hardware domain. These types of improvements are generally achieved by using alternate methods for calculations that increase the computational efficiency of the algorithm. This research examined the SHARP algorithm to determine what portions would benefit the most from an algorithmic speedup, and then attempted to improve their efficiency. Another class of algorithm modification may result in better performance when implemented in hardware, but may actually slow the performance in software. Typically, these types of improvements are made by modifying the control flow of the algorithm. Software implementations of algorithms are able to make full use of the incoming data and alter their behaviors based on this data. However, it is expensive and inefficient to change the steps of an algorithm in hardware. Designs in which the flow of the data is independent of what the data contains are more suitable for implementation in hardware and result in better performance than algorithms with variable control flows. Every effort must be made to remove data dependencies from the control flow in order to make the best use of the available hardware resources. This research examined all data dependencies in the SHARP algorithm and designed reasonable alternatives for dealing with them. An additional factor that must be considered in the mapping of an algorithm to hardware is the precision of the data. While most software algorithms use floatingpoint calculations, it is currently impractical to implement floating-point operations in hardware. Even assuming fixed-point arithmetic, decisions must be made regarding the data precisions to be kept at various points in the algorithm. It is important to note that whenever floating-point data is truncated to a fixed-width precision, error is introduced. Therefore, bit precisions were chosen in a manner that minimized the effect on the output. While the aforementioned considerations can be viewed as hardware independent, it is essential that the actual specifics of the hardware be taken into consideration. It is common practice to make use of libraries of basic hardware elements when generating a large-scale design. It is possible that these libraries may not contain 12 some elements required by the design. In such cases, a decision must be made to either create a design for the missing element or to alter the algorithm to make use of existing blocks. These decisions generally must be made on a case-by-case basis because the complexities of both approaches depend on the specific situation. In addition, the physical hardware resources must also be considered. Many hardware boards contain more than one FPGA, so it is necessary to determine an efficient way to partition the algorithm to make use of the available resources. Ideally, a design would use up as much of the FPGAs as possible, since speedup is generally proportional to area in FPGA designs. In addition, the transfer of data between FPGAs must be considered. There are typically a limited number of interconnects between FPGAs, restricting the amount of data that can be passed from one FPGA to another. This research attempted to partition the SHARP algorithm in a manner that made use of the available resources while still facilitating analysis and debugging. A final concern to be addressed is data transfer to and from the hardware. For most applications, the time needed to write data to the memory of the hardware board and read the output is not negligible. In fact, for small-scale designs, the data transfer time may exceed the time actually spent on computation. Consequently, it is important that the data transfer be managed so that the speed benefit gained by executing the computation in hardware is not outweighed by the time lost in data transfer. By addressing the above issues, this thesis shows that it is possible to produce a hardware design that provides a significant speedup in execution time for the SHARP algorithm, while not adversely affecting the algorithm's performance. As a result, it will be more feasible to incorporate computationally-intensive ATR methods in practical real-time systems. 1.3 Overview of the Thesis We begin in Chapter 2 by presenting our approach to generating hardware designs. The approach was to utilize the tools produced by the Algorithm Analysis and Map13 ping Environment for Adaptive Computing Systems (ACS) [4] project at BAE SYSTEMS. In this chapter, we will present an overview of the methodology of the ACS project. In Chapter 3, we present a development of the SHARP algorithm. The necessary computations are arranged in two separate components that execute sequentially in order to facilitate analysis. We also present the results of execution of the SHARP algorithm in order to measure the performance of the algorithm. Chapter 4 begins the analysis of the SHARP algorithm in a way that prepares the algorithm for hardware implementation, without making decisions that rely on the use of any particular hardware device. All modifications to the SHARP algorithm are performed strictly at the software level. We use a timing analysis in order to better focus our efforts and present the modified performance and timing results at the end of the chapter. In Chapter 5, we discuss modifications and analyses that focus on the hardware level. This chapter discusses both design decisions that would be necessary for any hardware implementation as well as decisions that are specifically intended for the hardware board used on the ACS program. Chapter 6 presents the hardware implementation of the algorithm and compares its performance with the performance of its software counterpart. We provide timing estimates and discuss how they could be improved through further design modification. We also discuss the extent to which the hardware acceleration benefits the algorithm as a whole. Finally, in Chapter 7, we summarize our findings and discuss the results of this research. 14 Chapter 2 Project Background In order to create the hardware designs used to accelerate the SHARP algorithm, this research made use of the tools developed by the Algorithm Analysis and Mapping Environment for Adaptive Computing Systems (ACS) [4] project at BAE SYSTEMS. The goal of this project is to decrease the amount of time spent in creating hardware designs by automating much of the design process. The ACS project has specifically concentrated on implementing digital signal processing (DSP) algorithms in field-programmable gate arrays (FPGAs), because FPGAs offer very high-speed processing at a small hardware cost [11]. To demonstrate the potential of FPGA computation for DSP algorithms, the ACS tools were used to implement a Winograd Discrete Fourier Transform (DFT) [24] and a linear FM detector [25]. It has also been shown [30] that FPGAs are particularly suitable for ATR applications because logic can be configured down to the bit level. While FPGAs do not offer the computing power of other technologies, such as application-specific integrated circuits (ASICs), their high speed-to-cost ratio makes them attractive to developers. Additionally, unlike ASICs, which are programmed at the factory, FPGAs can be repeatedly reprogrammed by the user to suit the functionality needed [10]. FPGAs have been used to accelerate both target detection [17], and target recognition algorithms, typically using SAR imagery [6], [9], [30]. For these reasons, it was decided to employ the tools provided by the ACS project 15 in order to achieve hardware acceleration of the SHARP algorithm. Because development of the ACS tools was continually progressing, this involved contributing to the actual development of the software in order to be able to reap the benefits of its capabilities. This chapter will present the methodology of the ACS project. Section 2.1 will describe the method used to lay out an algorithm in software as a starting point from which hardware design can begin. Section 2.2 will present the tool used to automatically set bit precisions throughout the algorithm as well as schedule the execution of the algorithm components. Section 2.3 will describe how this information was then employed to begin the generation of hardware-level components. Section 2.4 will show how the design process was brought to completion, resulting in full hardware designs that are ready for implementation. Finally, in Section 2.5, we present specifics of the target hardware device used on the ACS program. 2.1 Initial Implementation The first step taken in the ACS program to create a hardware design is to lay out the algorithm in Ptolemy [29], a software program developed at the University of California at Berkeley. Ptolemy is a simulation tool that enables designers to build and test large-scale systems using elementary building blocks. Since this is very much the same approach taken when building large-scale hardware designs, the ACS project created a new domain in Ptolemy that provided the functionality necessary to begin hardware design. [19] shows a very similar approach that used Khoros, produced by Khoral Research [16] for the simulation tool. From an interface standpoint, the ACS domain of Ptolemy is very similar to its other domains. Namely, a system is built up by placing elementary computational blocks (such as adders, multipliers, etc.) on the workspace and connecting them together to built more complex functions. Figure 2-1 shows both a typical group of blocks (called a "palette") and a dataflow, which will be used again later in this thesis. However, the difference between the ACS domain and the other domains in 16 Ptolemy lies in the interpretation of the individual blocks. Because Ptolemy is at its core a simulation environment, most domains are used for simulation. For example, in the synchronous dataflow (SDF) domain, the functionality of an adder is to sum its inputs and produce the result as its output. However, the goal of the ACS domain is not simulation; instead, the ACS domain tries to encapsulate the information necessary to implement an element in hardware within that block. Consequently, at the simplest level of abstraction, the adder block contains the instructions for building an adder in hardware. Naturally, there are more layers of complexity to be addressed. There is no universal adder design capable of handling all situations. Different applications may require different precisions on the input or output, or may require different input-to-output latencies. Consequently, the ACS blocks have two primary functions. The first function is to generate files which can be used in conjunction with the wordlength analysis tool to be discussed in Section 2.2 to help the designer configure the block to meet the needs of the larger system. We discuss this function below. The second function is to actually generate a design that fits the criteria that the designer has specified. This function will be discussed in Section 2.3. The intention of the ACS program was to make each element as configurable as possible. For example, in addition to being able to set bit precisions on the input and output, designers would be able to choose among different designs for the same element, depending on whether area or latency was a priority. However, while the blocks have been implemented in such a way that adding these capabilities is possible, they are not currently implemented. Consequently, the main use of the first function of the ACS blocks is to determine the bit precisions for the fixed-precision calculations that occur in hardware. The ACS blocks have many variable parameters. Many blocks operate on vectors rather than scalars, so vector lengths can be specified. Particular blocks, such as a gain element, may have parameters specific to their function, such as the gain level. Additionally, all blocks have bit precision parameters. If the designer knows the precisions that are required for the system and knows that the underlying design will 17 (a) (b) Figure 2-1: Ptolemy Screenshots. Diagram (a) ACS Domain Palette (b) Example Dataflow 18 be able to handle those precisions, they can be manually entered and locked. In many cases, the designer may not know what the precision requirements are for a specific block. In these cases, the wordlength analysis tool discussed in Section 2.2 can be used to suggest wordlengths. In order to be able to use the wordlength tool, the ACS blocks must be able to generate files that describe their input/output relationships. These files are produced as MATLAB [21] scripts. They consist of files that calculate the output of the block from its input, calculate the possible output range given the ranges of its inputs, characterize the input-to-output latency, describe any restrictions imposed by the underlying design on the input and output wordlengths, as well as estimate the space needed for the design based on its parameters. The generation of these files will be discussed in Section 2.3. 2.2 Wordlength Analysis The wordlength analysis tool serves two primary purposes. First, it is responsible for choosing bit precisions for all inputs and outputs that have not already been locked by the user. There are two components of the bit precision of a fixed-point number: the major bit, indicating the significance of the highest order bit of the number in two's complement form, and the wordlength, indicating the number of bits used to quantize that number. The second function of the tool is to generate scheduling information for the design. This information is necessary to compensate for the different latencies that may exist along different datapaths in the design. The schedule will be used in Section 2.3 to ensure that all inputs to a particular block arrive at the same time, regardless of when they are first available in hardware. We discuss each of these functions below. 2.2.1 Bit Precision Assignment The first step in assigning bit precisions is to choose all of the major bits. Typically, this can be done easily using the information provided by each block concerning the output range span. The tool imposes the requirement that the input precisions be 19 chosen. Consequently, the input range span is known. From this, the range spans for every node in the design can be calculated. As a result, the major bits are set to the minimum value that spans the required range. Once the major bits have been set, it is necessary to choose wordlengths for each node. Unlike the major bits, which are essentially prechosen due to range analysis, there is a large degree of flexibility in the wordlengths. Any set of wordlengths that satisfies the constraints specified by the different blocks is considered a feasible combination. However, most feasible combinations are of little practical value. It is therefore necessary to establish a way to score each combination and determine which of these combinations are "optimal." The method used to optimize the design wordlengths is described in detail in [10] and [13]. The tool makes use of the Markov chain Monte Carlo (MCMC) method [7] to choose wordlengths that are jointly optimized with regards to output noise variance and hardware cost. Specifically, the only wordlength combinations of interest are those such that no other design has both lower variance and lower hardware cost. These combinations are known as "Pareto-optimal" points. The MCMC method is used as follows. The initial starting point is a large number of randomly chosen wordlength combinations. Note that all wordlengths that have been explicitly chosen by the designer will not be changed. Combinations that violate any of the constraints imposed by the individual blocks are rejected. Presumably, unless the wordlength constraints are highly restrictive, many feasible combinations remain. At this point, the combinations are evaluated with regards to cost and variance. Any of the combinations that are not Pareto-optimal are rejected. The remaining combinations are randomly perturbed. From a given combination, the subsequent combination will either be identical to the original, or will differ by 1 in one of the wordlengths. Assuming there are n wordlengths to be chosen, this results in 2n + 1 possible perturbations. Again, all designs that violate constraints or are not Paretooptimal are rejected. Through repeated iteration of this process, several steady-state points will be 20 reached. From any steady-state point, altering any of the wordlengths will either violate a constraint or result in a higher output variance or hardware cost. These jointly-optimized combinations are then presented to the designer. Typically, the designer will want to choose the design with the highest cost that will still fit in the physical hardware, since these designs will usually have the lowest variances. However, in some circumstances, a lower cost design may be desired, so the user is free to choose a different design. Figure 2-2 shows typical outputs of the wordlength analysis. Figure 2-2a shows all of the cost-variance pairs encountered during iteration, while Figure 2-2b shows only those pairs that are Pareto-optimal. Once the wordlengths have been set, all that remains to be done is scheduling after which the design is ready to be created as in Section 2.3. 2.2.2 Scheduling Recall that the purpose of scheduling is essentially to synchronize the inputs to all blocks. This is achieved through use of the latency information provided by each block. Latency generally depends on the wordlength chosen for a block. Therefore, it is to be expected that different wordlength combinations will result in different schedules. Scheduling is achieved in a feed-forward sense, beginning with the data sources and progressing through to the data sinks. All blocks that are connected to the sources and have no other inputs can execute as soon as the schedule is launched. This rationale is applied to every block. Namely, a block can execute as soon as all of its inputs are available. Using the latency information, it is reasonably straightforward to schedule all the blocks. Note that in many cases, this scheduling implies that while the output of a block may be available, it may not actually be consumed for many clock cycles. Consequently, some delay must be introduced to synchronize the datapaths in hardware. The wordlength analysis tool includes these anticipated delays in its cost estimates. The insertion of these delays will be discussed below. 21 1030 10 9 C 1028 1027 1050 1100 1300 1250 1200 1150 1350 1400 Cost (a) 10, 28 .Lu 10 0a 7 10271 1050 Number of Designs=9 1100 1150 1200 Cost 1250 1300 1350 (b) Figure 2-2: Wordlength Analysis Tool Outputs. (a) All cost-variance pairs (b) Paretooptimal cost-variance pairs 22 2.3 Final Implementation Once the wordlengths and schedule have been generated, this information is once again used by the ACS domain in Ptolemy to actually begin creating the design. The bit precisions provided by the wordlength analysis tool are entered and locked into Ptolemy. Ptolemy then uses the generation capability of each block to actually create designs that meet the user specifications. This is currently achieved in one of two ways. The block will either contain instructions for generating a custom-designed Very High Speed Integrated Circuit (VHSIC) Hardware Design Language (VHDL) file or initiate a call to the external Core Generator tool, produced by Xilinx [34]. An invocation of the Core Generator will result in both a VHDL file and an Electronic Design Interchange Format (EDIF) file. It is from these underlying designs that the Ptolemy blocks were initially constructed. All of the information that the blocks provide to the wordlength analysis tools are properties of either the custom-made designs or the generic designs provided by the Core Generator. Consequently, the characteristics of the designs have been encapsulated and analyzed before any designs are actually instantiated. In addition to generating the individual hardware designs, Ptolemy is also responsible for connecting the individual blocks so that they function together as a system. There are two factors to be considered in making connections between blocks. First, any differences in bit precision on either end of a connection must be accounted for. Note that there will not be any difference in major bit, only in wordlength. Additionally, the wordlength can only decrease across a connection, since an increase in wordlength would only result in artificial bits being appended. Consequently, Ptolemy ensures that all connections are made properly by trimming off any unneeded low order bits. Additionally, Ptolemy must implement the delays implied by the schedule. For example, if a block produces its output at clock cycle 1, but the block that will consume this output can only execute at clock cycle 3 due to latency on another input, Ptolemy inserts a delay of 2 clock cycles on this connection to synchronize the 23 inputs. These additions to accommodate varying bit precisions and input latencies are made through the inclusion of additional VHDL files. 2.4 Synthesis and Generation There are two remaining tasks to be completed before the design can be used. The VHDL files that have been generated are read into Synplify, a software tool produced by Synplicity [28]. This tool is used to simulate the hardware execution of the design to ensure that it performs as expected. Once the simulation results are approved, the design is synthesized. Recall that only the VHDL files produced by invoking the Core Generator have corresponding EDIF files. Synthesis of the design produces EDIF files for the remaining VHDL files. The final task is processing all of the EDIF files using the Alliance Series tools produced by Xilinx [34]. This results in final bitstreams which can be used to program the hardware and actually execute the design. Execution is accomplished through use of software libraries provided by the board manufacturer to communicate with the hardware. The Alliance tools were used to target an Annapolis Micro Systems [2] Wildforce hardware board, which is described below. 2.5 Target Device The hardware details of the Wildforce board are presented in [3]. Here we will only present a brief description of those features of the Wildforce that will play a role in our design process. The Wildforce board has 5 Xilinx [34] XC4062 FPGAs labeled CPEO and PElPE4. However, CPEO is used for external interface. All start signals are sent to CPEO and CPEO returns all the interrupts. Consequently, there are 4 FPGAs available for use in design. With each FPGA is an associated memory bank, which can contain 262,144 (256K) 36-bit values. Each FPGA has a 36-bit connection to its associated memory. Additionally, there 24 is a 32-bit connection from each FPGA to a local bus which can be used to transfer data between FPGAs. Through the use of the Peripheral Component Interconnect (PCI) bus, the external world also has 36-bit connections to each of the memory banks. 2.6 Summary This chapter presented the approach of the ACS project. Ptolemy was used in conjunction with the wordlength analysis tool to fully specify the design and then to begin hardware generation. Several tools were then used to simulate and complete generation of the design, resulting in bitstreams that could actually be implemented in a reconfigurable hardware board. We also presented some specifications of the Wildforce board, which was used as the target device by the ACS program. The role of these specifications in our hardware-specific analysis of the SHARP algorithm will be shown in Chapter 5. The results of using the ACS tools for accelerating the SHARP algorithm will be presented in Chapter 6. 25 Chapter 3 SHARP Algorithm Moving target identification is a long-standing military objective. [26] provides a brief overview of the recent history of ATR development, culminating in the current focus on hardware implementation for target identification. The ability to classify an unknown target regardless of velocity, orientation, or heading has obvious applications. Various approaches have been taken to attempt to handle this problem. Traditional synthetic aperture radar (SAR) approaches have been tried [5]; however, SAR ATR of moving targets has been less successful than SAR ATR of stationary targets. Due to the long processing interval inherent with SAR imagery, target information is prone to blurring, resulting in degraded ATR performance. Target identification using moving target indication (MTI) radar has also been attempted [14]. MTI radar has the advantage over SAR imagery of being able to detect and track moving targets. However, MTI radar lacks the bandwidth necessary for target discrimination. Consequently, although targets can be detected, they cannot be identified. As a result, the Air Force Research Laboratory (AFRL) at Wright-Patterson Air Force Base (WPAFB) has begun investigating the potential of high range resolution (HRR) radar for the moving target problem [22]. HRR radar is well-suited for identifying moving targets for two reasons. Unlike SAR, HRR radar signatures can be formed quickly, allowing the ground clutter to be separated from the target through the use of Doppler filtering [20]. Additionally, because of its large range resolution, 26 HRR provides the bandwidth lacking in MTI radar, making target discrimination feasible. The AFRL initiated the System-oriented HRR Automatic Recognition Program (SHARP) [32] in order to develop HRR ATR capability. As part of the SHARP program, an algorithm was designed that implemented a forced-decision ATR approach. The algorithm classifies targets based on their signatures and aspect angles using an extensive template set. The SHARP algorithm makes use of the dataset from the Moving and Stationary Target Acquisition and Recognition (MSTAR) [15] database to measure its performance. The subset of the MSTAR dataset used had seven classes, consisting of three BMP2 armored personnel carriers (APCs), one BTR70 APC, and three T72 main battle tanks. There were two sets of data available: the training set and the test set. The training set was taken at a 170 depression angle and consisted of roughly 230 different aspect angles for each class spread across the total 3600 span. The test set was taken at a 15* depression angle and consisted of roughly 195 aspect angles for each class. The results of using the SHARP algorithm to classify the entire test set are stored in a confusion matrix. Confusion matrices are described in [8] and provide a way to measure the performance of a classification algorithm. The rows of the confusion matrix represent the test set, while the columns represent the template set. The value in row i and column j of the matrix is the percentage of signatures in Class i that were classified as Class j. The MSTAR data was available as SAR imagery rather than HRR signatures. In Section 3.1, we discuss the calculations necessary to obtain simulated HRR data from the SAR images. These calculations were necessary so that there was data with which to test the algorithm performance, but they were not considered part of the algorithm (which is intended to operate on real HRR data). The SHARP algorithm consists of some preprocessing and a least squares fitting, but we present these out of order in Sections 3.2 and 3.3 because their development is more intuitive in this order. Finally, in Section 3.4 we present the results of executing the SHARP algorithm on 27 the MSTAR dataset. 3.1 SAR to HRR Conversion The approach of the SHARP algorithm is to employ the characteristics of HRR radar signatures to achieve better results for moving target recognition. However, the MSTAR dataset used to determine algorithm performance consisted only of SAR imagery. It was therefore necessary to perform some preprocessing of the data in order to be able to simulate HRR data and get a better estimate of the algorithm performance. The method used to obtain simulated HRR data from the available SAR images is discussed in [14] and [32]. The dimensions of the original SAR images were 128x 128. These were subsampled by taking the center 101x70 pixels where the actual target was contained as shown in Figure 3-1. This was done to simulate the results of the Doppler filtering which would be performed on actual HRR signatures to separate the target from the ground clutter. The subimages were then zero padded back up to 128x 128 so that an inverse Fast Fourier Transform (IFFT) could be taken. The IFFT was taken on the dimension that was 70 pixels wide before zero padding and resulted in range signatures collected over the radar aperture (the dimension that was originally 101 pixels wide). Figure 3-1: Segmentation of SAR image to simulate Doppler filtering The resulting signatures were finally deweighted in angle using an inverse Taylor 28 HRR Signature Least Squares Fit Preprocessing arget ID Templates Aspect Angle Figure 3-2: SHARP Algorithm Block Diagram window [31] to make the energy of the signatures uniform. The result was a 128x 128 matrix, representing 128 signatures that were each 128-wide in range. It is important to note that only the center 101x70 of this matrix represented real data while the rest was zero padding. This 128x 128 matrix was used as the input to the algorithm; it would be compressed to a single signature, which was then used for classification. The method of performing this compression will be discussed in Section 3.3. 3.2 Least Squares Fitting The dataflow of the SHARP algorithm is shown in Figure 3-2, a revision of Figure 1-1. We begin by presenting the least squares fit routine. The SHARP algorithm minimizes an error metric and bases its classification decision on that minimum error. Consequently, it makes sense to begin our development of the algorithm by defining this metric. Given a target vector d and a template vector m, the SHARP algorithm tries to fit the vectors to each other by altering the bias and magnitude of m. Specifically, the algorithm determines an optimal offset k, and an optimal gain k 2 such that k, + k2 * mi 1 m] k di, or equivalently, d. (3.1) Since in most cases it is not possible to find a k such that Equation 3.1 is exactly satisfied, the least squares method provides a k that minimizes the error between the 29 two sides of Equation 3.1. This solution is developed in [27) and is given by 1T 1T TMIT k= d. (3.2) Our primary focus is not to determine the least squares solution to this equation, but to determine the error associated with that solution because our objective is to find the minimum error. Naturally, the error is dependent on the choice of k and is given by = 1 m k -) d [ 1 m k -d) . (3.3) Consequently, the SHARP algorithm determines the least squares solution k to Equation 3.1 and then evaluates Equation 3.3 to determine the resultant error. Now that we have defined a metric by which to compare the various template signatures, we must define the template set to which this metric will be applied. The template set spans two dimensions which we must take into account: aspect angle and range. Clearly, one possible solution is the brute force attempt; we can consider template vectors spanning all aspect angles and consider all possible range shifts and minimize the error across all the resulting comparisons. However, this is a highly inefficient approach that fails to utilize knowledge of the data. The SHARP algorithm assumes that the signal information is contained in the center 70 range gates of the entire 128-gate span. The algorithm further assumes that the templates are already close to being correctly aligned. Consequently, the decision was made to only consider shifts within five range gates. This results in a dramatic savings in computation when compared with considering all 139 possible range shifts. In order to facilitate performing the eleven necessary range shifts, the target vector is padded on each end with five zeros to produce an 80-wide vector. The eleven shifts are generated by taking subvectors (1-70, 2-71, ... , 11-80) of the padded vector. To cut down on the number of aspects we must consider, we make use of the fact that we know the aspect angle of the target vector. It therefore makes sense to choose some subset of angles centered around the target aspect. In fact, [1] shows 30 that performance may actually be improved by constraining the aspect angles to avoid mismatches that may occur at drastically different angles. The SHARP algorithm only considers templates whose aspects are within 5' of the aspect angle of the target. This is again a huge savings since a 360-degree span has been reduced to a 10-degree span. The result of these decisions is to reduce the number of error calculations that must be computed to a manageable number. The template data contained signatures that were multiples of 10 apart in aspect. Consequently, the maximum number of aspect angles to be considered for any given target aspect angle a is eleven (i.e. a - 5, a - 4,. . . , a + 5). Therefore, we see that for a given target signature, we must perform at most 11 (aspects) x 11 (ranges) x 7 (classes) = 847 error calculations. 3.3 Preprocessing We recall that the input data was available as a 128x 128 matrix. Additionally, we know that the least squares fitting component of the SHARP algorithm expects the data as a 70-wide (or 80-wide, depending on zero padding) vector. Consequently, it is apparent that some preprocessing had to be done on the input data before the least squares fit could be performed. Since we know that only the center 101x70 of the input matrix represented the target data, only this submatrix was used for processing. The first step in the preprocessing was to remove automatic gain control and range effects from the signatures in order to improve classifier performance. This was achieved through a normalization. Recall that each input signature r was 70-wide and contained range gate magnitudes. From this vector, a power vector p was formed such that pi = r2. The root mean square (RMS) amplitude of p was then calculated and is given by 1 Prms =\128 7 PI(.4 (3.4) where the -L factor is due to the mean being taken over all 128 range gates (including zero padding). The power vector was then normalized by this RMS amplitude to 31 obtain n= . (3.5) Prms Combining Equations 3.4 and 3.5, we obtain n= 2 (3.6) We finally substitute for p and obtain n = (3.7) where the squaring is done elementwise. Before the resulting signatures could be averaged to produce a single vector, an additional transformation had to be performed to satisfy the constraints of the least squares fit routine. This is discussed below in Section 3.3.1. 3.3.1 Power Transformation It is important to note that using the method of error calculation above made the SHARP algorithm a Gaussian classifier. As shown in [33], this means that the incoming data was assumed to have a Gaussian distribution. Equivalently, the incoming data had to be completely characterized by its first and second moments, i.e. its mean (y) and variance (o2 ). This assumption was implicitly made by using Equation 3.3 to perform the least squares fit. Determining the optimal bias k, was equivalent to matching the means of the two signatures because the new mean Pnew was equal to k1 . Similarly, finding the optimal gain k 2 was equivalent to matching the variances because the new variance 2 Oj was equal to k2 * o 2. Although the data was assumed to be Gaussian, it has been shown that the statistics of HRR data are better modeled as having a Rayleigh distribution [22]. Consequently, in order to maximize the performance of the classifier, it was necessary to transform the data. Empirical studies conducted in [1] determined that a trans- 32 form of the form t = nc would transform the distribution such that it more closely resembled a Gaussian distribution. Specifically, using c = 0.2 resulted in improved classifier performance. Combining the power transformation with Equation 3.7, we see that the calculation performed on each of the 101 signatures is t= (3.8) r Up to now, the preprocessing was identical for both the template and target sigAt this point, the computation finally differed. natures. Because we wanted the template signatures to be as accurate as possible, all 128 signatures were averaged together to obtain a single 70-gate vector. However, the target signatures should attempt to simulate the quality of real HRR signatures. Consequently, only the center eight profiles were averaged. Target vectors were finally padded with five zeros on either end to accommodate the range shifting of the least squares fit. 3.4 Algorithm Performance We present the results of execution of the SHARP algorithm on the 1,362 MSTAR test signatures in two different formats. Table 3.1 shows the confusion matrix arranged by vehicle. Table 3.2 shows the confusion matrix arranged by vehicle class. Recall that element (i, j) indicated the percentage of Class i signatures that were assigned to Class j. Through these tables, we can see quantitatively how the SHARP algorithm performs. We see from Table 3.1 that the performance by vehicle was certainly not optimal. In fact, for the BMP263 and BMP2c21, less than 50% of the signatures were correctly classified. However, we see from Table 3.2 that the majority of misclassifications were still the same vehicle type. Consequently, we see that while the SHARP algorithm did not perform well on a vehicle-by-vehicle basis, it did perform well on vehicle types. In fact 86.64% of the target signatures were correctly matched with their vehicle class. 33 Table 3.1: Confusion Matrix by Vehicle Using Original AFRL Code Actual BMP263 BMP266 BMP2c21 BTR70c21 BMP263 47.69% 7.69% 21.54% 3.59% BMP266 16.92% 60.00% 12.31% 4.10% BMP2c21 23.08% 14.87% 49.74% 5.64% T72812 T72s7 0.00% 1.57% 2.05% 4.19% 1.54% 2.62% Predicted BTR70c21 3.59% 4.10% 4.62% 76.92% 1.54% 1.57% T72132 3.59% 4.10% 4.10% 3.08% 5.64% 8.90% T72812 -2.56% 3.59% 3.59% 3.08% -75.38% 10.99% T72s7 3.59% 5.64% 4.10% 3.59% 13.85%7 70.16% Table 3.2: Confusion Matrix by Vehicle Type Using Original AFRL Code Actual BMP2 BTR70 T72 BMP2 84.62% 13.33% 6.87% Predicted BTR70 T72 4.10% 11.28% 76.92% 9.74% 1.20% 91.92% A detailed timing analysis of the SHARP algorithm will be presented in Chapter 4, but we note here that the time required for classification of the test signatures (excluding the time necessary for template formation) was approximately 21.64 minutes. While a speedup of a process that only takes 21.64 minutes to execute is not very significant, it is important to note that in a practical system, this time would be much larger. It is likely that the template set would be much more densely populated in aspect and would contain data for many depression angles. Consequently, we could expect a realistic execution time to be on the order of days. In this case, the speedup provided by hardware acceleration would clearly be significant. We present the results of algorithm execution not only to demonstrate what the capabilities and shortcomings of the SHARP algorithm are, but also to provide a point of reference for our further analysis. Since we are attempting to provide the same capability as the SHARP algorithm, but with hardware acceleration which will significantly decrease the execution time, we need a quantifiable way to compare the results. We would therefore like to see that executing some or all of the SHARP algorithm in hardware does not significantly change the confusion matrices from those in Tables 3.1 and 3.2. 34 3.5 Summary In this chapter, we presented the methods used in the SHARP algorithm. We demonstrated how the SAR imagery from the MSTAR dataset was processed to produce simulated HRR signatures for classification. The SHARP algorithm was developed in two parts: preprocessing and least squares fitting. The preprocessing consisted of a normalization and a power transformation. This power transformation was necessary because the least squares fit routine was implemented as a Gaussian classifier. Since the goal of this research was to accelerate the algorithm without significantly affecting performance, the results of executing the SHARP algorithm were presented to serve as a reference point for future comparisons. Chapter 4 will begin our analysis of the SHARP algorithm, which will rely heavily upon an understanding of the framework presented in this chapter. 35 Chapter 4 Software Analysis In attempting to accelerate an algorithm, it is important that the original software be optimized as much as possible. Achieving a 10 x speedup through the use of hardware acceleration is not very impressive if a 5 x speedup can be gained simply by improving the software. Thus, it is only possible to get a true measure of the impact of hardware acceleration by comparison to a software implementation that is fully optimized. Additionally, this software optimization can typically lead to better hardware performance. Naturally, functions that require few computations will execute faster in both hardware and software. However, the lack of computational elements results in extra FPGA area. Therefore, the existing blocks can be implemented using larger area designs which can either improve the precision of the calculation or reduce its latency. Consequently, it is clear that software optimization is an important step towards hardware acceleration. In Section 4.1, we present a timing analysis of the SHARP algorithm. Section 4.2 presents an analysis of the least squares fit routine. The section begins with the original AFRL approach and then presents an alternative that significantly improves its efficiency. Section 4.3 presents optimizations that target the preprocessing in the SHARP algorithm. Finally, in Section 4.4, we present a revised timing analysis to demonstrate the effects of these modifications and refocus further study. 36 4.1 Timing Analysis It is important to recognize that the SHARP algorithm consisted of two separate parts. Template signature formation comprised the first part while target signature formation and classification made up the second part. The important distinction between these parts is that the former could be computed and stored ahead of time. The compilation of the template library was not be considered part of the algorithm execution since the template data was static. Once the templates had been computed, they could simply be stored and read on subsequent execution. Consequently, our analysis of the SHARP algorithm focused only on the formation and classification of target signatures. We began our analysis by examining the execution of the SHARP algorithm to determine the relative amounts of computation involved. A profiling of this sort was helpful to determine what calculations dominated the execution time and would therefore demonstrate the greatest benefit from an acceleration. Conversely, it also prevented us from undertaking a detailed analysis to gain a significant speedup in a computation that did not make up a significant portion of the algorithm execution time. Through analysis of the initial execution of the algorithm, we were able to better focus our efforts and achieve the greatest speedup. All timing tests were conducted on a Sun Microsystems Ultra 5 running at 360 MHz with 320 MB of RAM. As mentioned above, we ignored the time required for template formation. Consequently, we broke our analysis into three categories: target loading/preprocessing, least squares fitting, and classification. The timing is shown in Table 4.1 for all seven target classes, which we recall consisted of 1,362 signatures (128x 128 matrices). All timings are shown in seconds. As expected, the first priority for acceleration was the least squares fit routine. Least squares fitting required many error calculations, each of which required several vector multiplications. Additionally, the least squares fit was performed on many vectors. Consequently, it was no surprise that it was responsible for most of the execution time. 37 Table 4.1: Timing Analysis of Original Software BMP263 BMP266 BMP2c21 BTR70 T72132 T72812 T72s7 Total Loading/Preprocessing 24.55 24.89 24.56 24.62 24.54 25.05 24.50 172.71 Least Squares Fit 164.16 160.08 162.55 161.00 156.27 161.48 159.52 1125.06 Classification .11 .11 .11 .11 .11 .11 .11 .77 We also see that the secondary area for acceleration was the preprocessing. While we could not do much to improve the load time of the data, we could improve the time required to preprocess the data into power-transformed HRR signatures. Consequently, we also focused on the power transformation and attempted to improve its execution time. 4.2 Least Squares Fit We recall from Chapter 3 that the goal of the least squares fitting was to minimize the error between the target signature and the class to which it was assigned. Specifically, the SHARP algorithm determined the class that minimized the error between the target signature and all template signatures that were within 50 in aspect and within 5 range gate shifts. In this context, the error to be minimized was E2 =IIM][ k I- d)'( 1 m ][k I- d), (4.1) where m and d are column vectors representing the template and target signatures, respectively, and k is a 2 x 1 vector consisting of the optimal offset and gain between the vectors. 38 4.2.1 QR Factorization Approach The approach taken by the original AFRL code to calculate the fitting error was relatively straightforward. The code first calculated the least squares solution k and then plugged it into Equation 4.1 to arrive at the fitting error. However, rather than simply using Equation 3.2 to calculate k, the AFRL code employed a QR factorization in order to reduce the amount of calculation necessary. From [27], we know that the goal of QR factorization is to take a matrix A and produce two matrices, Q and R, such that A orthonormal columns (implying that QTQ = = QR. Additionally, Q must have I) and R must be upper triangular. The AFRL took advantage of this method by taking the QR factorization of [ 1 m ]. Since the dimensions of [1 m ] were 70 x 2, the dimensions of Q and R were 70 x 2 and 2 x 2, respectively. This factorization was then substituted into Equation 3.2. This substitution is shown below: 1T T 1T k k T [1 M =((QR)T QR)-'(QR)T d d (4.2) (4.3) k = (RTQTQR)-IRTQTd (4.4) k (RTR)-RTQTd. (4.5) It is not clear that using QR factorization provided a benefit over the straightforward calculation. In fact, from [27) we know the QR factorization of a 70 x 2 matrix requires 280 multiplications. Additionally, we can easily calculate the number of multiplications in Equations 4.2 and 4.5 to be 430 and 161, respectively. It would thus seem that the QR factorization approach required 441 total multiplications (11 more than straightforward calculation). However, the benefit of the QR approach was in the context of its use. Recall that in order to compare one target signature to one template signature, there were eleven range shifts to be considered. For straightforward calculation, this resulted in 11 x 430 = 4,730 multiplications. However, in the QR approach, 39 factorization only had to be done once per template. Consequently, only 280 + 11 x 161 = 2,051 multiplications were required. While this was clearly an improvement over the straightforward approach, it could be improved further using a matched filter. 4.2.2 Matched Filter Approach The foundation for using a matched filter approach for the SHARP algorithm is developed in [12]. We will present this development, extend it to implementation, and demonstrate the resulting benefit. The development of the matched filter approach began with the original equation by which the SHARP algorithm performed the least squares fitting, MI[ k 1 (4.6) ~ d. From [273, we know that the least squares solution k is found by solving 1T [ 1T 1 k m d = (4.7) or equivalently, N Nm - mlk]= Nd (4.8) where N is the length of m and d (in this case, 70), and fn and d are the means of m and d, respectively. Solving the first line of this equation gives Nk1 + Nmfk 2 = Nd, k1 = d-fk 40 (4.9) 2. (4.10) Substituting back into Equation 4.6 gives [1 m]dk rn 2 d, (4.11) d, (4.12) k2 Al - k2 fn1 + k 2 m ~ and finally, (4.13) (m - fn1)k2~ (d - dl). Note that m - iil is simply m with its bias removed. Similarly, d - Al is d with its bias removed. Defining rhn = m - mn1 and d = d - dl, we obtain inhk 2 ~d. (4.14) From this, we know the least squares solution for k 2 is k2 (4.15) Tr7 mm Using Equations 4.14 and 4.15, we can calculate the fitting error: E2 = (k 2 xh E2 = (k 2 1n a)T (k 2 ih - a) (4.16) _ d T ) (k 2 in - a) (4.17) (4.18) (k 2~n-rTh - 2k 2 xhTd + ada) 62 62 - = dd -h T (4.19) d. mm We see from Equation 4.19 that if f~n and d were normalized so that Iil = jdl = 1, then minimizing the least squares error could be accomplished by maximizing ~nTa, which is precisely the objective of a matched filter [23]. Therefore, we see that by removing the bias from the template and target vectors and then normalizing them to unit magnitude, we could accomplish the necessary error minimization by maximizing the correlation between the two vectors. However, it was important to realize that calculating the bias and normalizing were expensive calculations. Consequently, it 41 was desirable that these operations not be performed frequently. Recall from Section 3.2 that a single target vector was compared against seven template classes. Within each template class, signatures were only considered if their aspect angles were within 5' of the target signature. Additionally, the target signature was shifted up to 5 range gates in either directions to align the signatures. Cleary, the choice of template vector had no bearing on processing the target vector. However, a bias removal and normalization was necessary for every range shift using the AFRL approach for range shifting. The range shifting done by the algorithm was performed by padding the original 70-vector with 5 zeros on either end and then taking a window of size 70 from the resulting 80-vector. However, Figure 4-1 shows the problem with such an approach. Figure 4-la shows the 80-vector obtained by zero-padding one of the bmp263 target signatures. Figures 4-1b through 4-11 show the 11 range shifts of that signature. The 70 samples containing target information were elements 6 through 75 of the 80-vector. However, every window besides the center one left out at least one of these samples. In the extreme case, windows 1-70 and 11-80 left out 5 samples of the original vector as shown in Figure 4-1b and 4-11. In many cases, this did not matter because the actual target signatures were generally smaller than 70 range gates, but in some cases, real data samples were lost. Consequently, the mean of the vector could potentially change with every range shift, requiring constant bias removal and normalization. Instead of accepting this conclusion and taking the resulting performance degradation, we proposed a modification to the algorithm which enabled the bias removal and normalization to be performed only once for each target vector. This modification was to ensure that samples were never dropped. This was accomplished by providing additional zero padding and taking a larger window. Specifically, the original 70vector was padded with 10 zeros on either end resulting in a 90-vector. The 11 range shifts were then performed by taking a subwindow of size 80. Note that the target samples were contained in elements 11-80 of the 90-vector. We then see in Figure 4-2 that each range shift included all 70 of the target samples. Consequently, the mean 42 2 2 2 (b) (a) (c) U) 1i[ 1 1i[ 0 20 40 60 80 0 20 40 60 (e) (d) ci 20 40 60 0 20 40 60 0 20 40 60 20 40 60 20 40 60 2 (h) (g) 60 1i[ 2 2 40 (f) if[ 0 20 2 2 2 0 (I) E) 1i 11 0 20 40 60 0 20 40 60 2 2 2 (k) (j) (I) +-p CE 1 0 0 1 1 20 40 Range 60 0 20 40 Range 60 0 Range Figure 4-1: Range shifting of a bmp263 target by using 70-windows. (a) Original 80-vector (b)-(l) 11 70-wide range shifts from rightmost to leftmost. 43 did not change across the range shift, implying that bias removal and normalization only needed to be performed once for each target vector. Making this modification did slightly change the performance of the algorithm since forcing all the target samples to be kept changed some of the error calculations from the original version. The modified performances are shown in Tables 4.2 and 4.3. As before, element (i, J) indicates the percentage of Class i signatures that were identified as Class j. Note that the algorithm performance actually improved slightly because by not dropping samples, we were using a more accurate measurement of the least squares error. Table 4.2: Confusion Matrix by Vehicle Using Matched Filter Actual BMP263 BMP266 BMP2c21 BTR70c21 T72132 T72812 T72s7 I BMP263 47.69% 7.69% 21.03% 3.59% 2.04% 2.04% 1.05% BMP266 16.41% 60.51% 12.82% 4.10% 1.02% 1.04% 3.66% BMP2c21 24.10% 13.33% 50.26% 6.15% 4.08% 4.04% 2.62% Predicted BTR70c21 4.62% 4.10% 3.59% 77.44% 0.51% 0.5% 1.05% T72132 T72812 2.56% 2.05% 4.62% 3.59% 4.10% 4.10% 3.08% 3.08% 76.02% 7 .90% 76.02% 7.90% 8.90% 11.52% T72s7 2.56% 6.15% 4.10% 2.56% 6.122% 12% 71.20% Table 4.3: Confusion Matrix by Vehicle Type Using Matched Filter Actual BMP2 BTR70 T72 Predicted BMP2 BTR70 T72 84.62% 4.10% 11.28% 13.85% 77.44% 8.72% 5.84% 1.20% 92.96% We recall that QR factorization provided an advantage over straightforward calculation because the cost of factorization was amortized across the eleven range shifts. Similarly, the matched filter approach provided an advantage over QR factorization because the cost of bias removal and normalization was amortized across the number of template signatures to be considered. Bias removal and normalization required 80 multiplications as did the calculation of the correlation. Consequently, to compare against M template signatures, QR factorization required 2,051M multiplications, 44 . 2 2 (a) . - 2 (b) (c) 1[ E 1 0 20 40 60 0 80 2 (d) a) 60 80 20 40 60 80 20 40 60 80 0 40 60 80 2 20 40 60 80 60 80 0 20 40 60 80 40 60 Range 80 2 2 (k) U) 40 1 0 (j) 20 (I) 1 20 80 2 (h) 1i 60 1 0 (g) 40 (f) 2 2 20 2 1* 0 0 (e) 1 0 0) 40 2 I. 0) 20 () 1 1 *0 20 40 60 Range 80 0 20 40 60 Range 80 0 20 Figure 4-2: Range shifting of a bmp263 target by using 80-windows. (a) Original 90-vector. (b)-(l) 11 80-wide range shifts from rightmost to leftmost. 45 while the matched filter approach required 80 + M x 11 x 80 = 80 + 880M multiplications. In addition, by comparing Tables 4.1 and 4.4, we see that adopting a matched filter approach provided a significant advantage over the QR factorization approach in the algorithm timing. 4.3 Power Transformation In considering the power transformation, we chose not to conduct an in-depth analysis to determine if alternate calculations could achieve the same result more efficiently. Instead, we noted that there was one straightforward but critical change that could be implemented which resulted in a dramatic speedup. Recall from Section 3.3.1 that for target formation, the center eight profiles of the 101 available signatures were averaged together to produce the target signature, while template formation employed all 101 profiles. However, the original AFRL code performed the power transformation and range gate normalization on all profiles in both cases. The only difference between the template and target formation in the AFRL code was that the target formation code used only eight of these profiles for averaging, in spite of having preprocessed all of the signatures. It was apparent that we could gain a substantial savings in computation simply by eliminating the unnecessary calculations from the original AFRL code. By ensuring that the preprocessing only occurred on the eight profiles used in the averaging rather than all 101 profiles, we expected a speedup on the order of 12x. This ensured that the time spent on computing the power transformation and the range gate normalization would be dominated by the time required for the least squares fitting. The next section will present a revised timing analysis that incorporates the above modifications. 4.4 Revised Timing Analysis Table 4.4 shows the results of the timing analysis on the fully optimized software. All timings are shown in seconds. 46 Table 4.4: Timing Analysis of Optimized Software BMP263 BMP266 BMP2c21 BTR70 T72132 T72812 T72s7 Total Loading/Preprocessing 2.79 2.53 2.58 2.54 2.63 2.69 2.57 18.33 Least Squares Fit 34.22 33.93 34.55 34.14 34.67 34.20 33.64 239.35 Classification .11 .12 .12 .11 .11 .11 .12 .80 By comparing Tables 4.1 and 4.4, we see that the software optimizations made a significant impact upon the execution time of the algorithm. The total execution time was reduced from 1298.54 seconds to 258.48 seconds. Additionally, the ratio between least squares fitting time and preprocessing time had almost doubled, further supporting the supposition that least squares fitting dominated the execution. Therefore, accelerating the least squares fitting remained our highest priority. 4.5 Summary This chapter began the analysis of the SHARP algorithm. The timing analysis presented in Section 4.1 led us to focus our efforts primarily on the least squares fitting routine, and secondarily on the power transformation. The QR factorization approach used by the AFRL was presented and analyzed. It was then replaced with a matched filter approach, which significantly decreased its execution time. The unnecessary calculations were removed from the power transformation which also resulted in a speedup. Finally, we presented a revised timing analysis. This analysis showed that the algorithm execution time had been greatly reduced due to our optimizations and further supported the claim that accelerating the least squares fitting was the highest priority. Having concluded our software analysis, we begin a hardware-specific analysis in Chapter 5 that alters the already modified algorithm to further improve its 47 anticipated hardware performance. 48 Chapter 5 Hardware-Specific Analysis In this chapter, we examine the SHARP algorithm from a hardware standpoint. Thus far, hardware has not been a factor in our analysis. This chapter considers the difficulties that may present themselves when mapping the SHARP algorithm into hardware using the ACS program approach. Recall from Section 1.2 that our concerns with regards to hardware implementation are control flow modifications, bit precisions, design availability, partitioning, and data transfer. While Chapter 2 indicated that most of the bit precision decisions could be left to the wordlength analysis tool, this chapter discusses situations in which the tool would not suffice, and considers the remaining hardware issues. These issues are analyzed with regards to our two areas of interest: the power transformation and the least square fitting. Our hardware-specific analysis begins with the power transformation in Section 5.1. We ultimately decided not to implement the power transformation in hardware, but this section explains why this decision was made and provides insight which can be used in further analysis. We then analyze the least squares fit in Section 5.2, concluding with the Ptolemy diagrams of our design in Figures 5-7 and 5-9. 49 5.1 Power Transformation We begin our analysis with a list of the elementary blocks available for use in our design in Table 5.1. From these blocks, we were able to construct larger systems that implemented the functionality we desired. Table 5.1: Elementary Function Blocks Accumulator Chop Const Divider Lookup Table (LUT) Maximum Multiply Register Shift Sqrt Square Subtractor Produces a running total of its input Produces a subvector of its input Produces a constant value Produces the quotient of its two inputs Performs a table lookup on its input Produces the maximum of its two inputs Produces the product of its two inputs Repeats its input Performs a bitshift on its input Produces the square root of its input Squares its input Produces the difference of its two inputs Recall from Section 3.3.1 that the ultimate purpose of the power transformation was to average eight power-transformed vectors. Consequently, from an implementation standpoint, there were two components to consider. First, the range gate normalization and power transformation calculation had to be performed on the eight input vectors. Second, the eight vectors had to be averaged together. We consider these components in Sections 5.1.1 and 5.1.2. 5.1.1 Vector Transformation From Chapter 3, we recall that the equation to be implemented on each vector is (tI r 0.4 70 )0-1 (5.1) where r contains the magnitudes of the individual range gates and the exponentiation is done elementwise. This calculation is represented as a block diagram in Figure 5-1. 50 The vector was squared at the outset. The lower datapath was then used to calculate the RMS amplitude. The vector was squared again and then accumulated. The Chop was used to read the 90 partial sums produced by the Accumulator and only output the final sum. The Shift was a right shift by 7 bits, which was equivalent to a division by 128. The square root of the value was then taken, resulting in the RMS amplitude. The Register repeated the amplitude 90 times so that each element of squared 90-vector could be normalized. Finally, a LUT was used to implement the function y input = x 0., completing the calculation. Divider Square Square Accumulator Chop Shift Sqrt LUT -- output Register Figure 5-1: Power Transformation Block Diagram There were two issues that needed to be considered to make this design feasible. First, the output precision of the divider had to be manually chosen. This was necessary for all dividers and was a consequence of the inability to sufficiently characterize the divider input. Specifically, the denominator input could theoretically be very close to zero. As a result, the major bit chosen by the wordlength analysis tool would be extremely conservative and result in a high quantization error. Therefore, we attempted to choose an appropriate major bit for the divider output based on our knowledge of the system. In order to choose the divider precision, we considered the system after the first Square and before the LUT. Note that if we removed the Shift (which is equivalent to a gain of ) then the system was a straightforward normalization. That is, the output vector was simply the input vector divided by its magnitude. As a result, without the Shift, the output range span could be no larger than [-1,1]. We then had to trace the effect of the Shift. Passing through the Sqrt resulted in a factor of . The Register did not affect this factor, but passing through the Divider inverted it, so the divider output range span could be no larger than [-8V2-, 8VZ] ~ [-11.3,11.3]. Consequently, the output major bit of the divider could be set to 4, which would 51 - Floating Point Fixed Point 7- 6- 5- 'E 4 CU 3- 2- 0 0 10 20 30 40 50 60 70 Range Figure 5-2: Divider Output - Floating Point and <4.8> Fixed Point easily span this range. The second factor to be considered was the LUT. The underlying design provided by Xilinx supported up to 256 256-bit values [34]. This effectively meant the wordlength of the input to the LUT had to be 8, since there were only 28 = 256 different addresses in the LUT. Combining this with our earlier choice of major bit, the output precision of the divider had to be set to <4.8>, using the notation <mb.wl> to indicate a major bit of mb and a wordlength of wl. This meant that the least significant bit (LSB) only had a significance of 2-, so all quantizations were only guaranteed to be within .125 of the corresponding floating point values. Figure 5-2 shows the output of the Divider in floating point and at <4.8> precision for a typical bmp263 target. Figure 5-3 shows the corresponding outputs of the exponentiation. Figure 5-4 shows the floating point output and the same output quantized to <1.8> precision. It is apparent that from Figures 5-2 and 5-3 that <4.8> precision was not sufficient to characterize the input. However, Figure 5-4 shows that <1.8> precision was 52 1.6 - Floating Point Fixed Point 1.4 1.2 C- ca .8 C 0.6- 0.4- 0.2 - U - 0 i 10 20 i 30 40 , . ,I . 50 60 70 Range Figure 5-3: LUT Output - Floating Point Input and <4.8> Fixed Point Input 1.6 - Floating Point Fixed Point 1.4 1.2 P 1 -o 0.8 F 0) 0.6- 0.4 - 0.2- 0 10 20 30 40 50 60 70 Range Figure 5-4: LUT Output - Floating Point and <1.8> Fixed Point 53 1.6 - Floating Point Fixed Point 1.4- 1.2- 1 Z 0.80) 0.6- 0.4- 0.2- 0 10 20 30 40 50 60 70 Range Figure 5-5: LUT Output Input - Floating Point Input and <1.8> Transformed Divider acceptable for the output. Consequently, if we could make the input more closely resemble the output, 8-bit precision would be sufficient. We accomplished this by inserting two Sqrt's between the Divider and LUT. We used the Sqrt's to maintain 16-bit precision until the input of the LUT, which was set to <1.8> precision. However, the input had already been raised to the 0.25 power by the Sqrt's, so the LUT was used to implement the function y = x 0.8 , resulting in an overall exponent of 0.2. The output precision was then set to <1.16>. The floating point and <1.16> fixed point outputs are shown in Figure 5-5. 5.1.2 Vector Averaging In order to be able to average the eight transformed vectors, it was necessary to develop a way to parallelize them. The only reasonable way to do this was through the use of a memory element. The output of the transformation calculation could be stored in memory. Then, when all eight vectors were in memory, an address 54 generator could output the vectors in parallel. Specifically, the first element of each vector would be produced, followed by the second element of each vector until all elements had been produced. The advantage of rearranging the elements in this fashion was that it was then possible to produce the average of the 8 vectors. In order to produce the first element of the average vector, the first elements of each of the 8 original vectors could be passed into an accumulator in serial order. The output of the accumulator could be downsampled to produce the final sum, which could be passed through a gain of }8 to produce the final average. Unfortunately, time was not available for this approach to be taken. The complexity involved in including a memory bank into the calculation and developing the necessary address generator did not permit its implementation. Fortunately, as Section 4.4 indicates, the time saved in performing the power transformation in hardware was not the dominating factor in the final performance. Consequently, we concentrated the remainder of our analysis on the least squares fit. 5.2 Least Squares Fitting The least squares fitting consisted of two distinct parts. First, the input vectors had their biases removed and their magnitudes normalized. Second, the correlation between the target vectors and the appropriate template vectors was calculated. 5.2.1 Bias Removal and Magnitude Normalization We begin as before by presenting a block diagram of the desired calculation in Figure 5-6. In order to calculate the bias, a Chop was used to take an 80-subvector of the input 90-vector. The vector was accumulated and a Chop was used to extract the total sum. The bias was finally calculated by multiplying by a constant of 80~. The bias was then repeated 80 and 90 times, so that it could subtracted from both the original 90-vector and the 80-subvector. Note that this could also have been achieved through 55 input Subrato Chop Divider Subtractor AccumulatorHChop Multiply Square - Accumulator Sqr output Register Register ConstRegister Figure 5-6: Normalization Block Diagram the use of one Register and Subtractor operating on the 90-vector. However, because the magnitude which was calculated next operated on the 80-vector, an additional Chop would have been necessary, increasing the latency of the design. Consequently, two Registers and Subtractors were used to operate on both the 90-vector and the 80-subvector. To calculate the magnitude, the 80-vector was squared and accumulated. Once again, a Chop was used to get the total sum. The square root of this sum was the desired magnitude. The magnitude was repeated 90 times and used to normalize the 90-vector by using a Divider. We note once again that we had to manually set the output range of the divider. Fortunately, the purpose of this divider was to divide the elements of a vector by its magnitude, so we fixed its output range to [-1,1]. Aside from this, all precisions were left for the wordlength analysis tool to assign. The normalization design was estimated to be large enough to require an entire FPGA dedicated to it. Consequently, PEI was used for normalization, requiring the signature data to be written to the memory bank of PEl. Chapter 6 will show this estimate was accurate, as PEI had a relatively high design occupancy. Figure 5-7 shows the Ptolemy graph for the normalization design. Note that Ptolemy requires buffers (Shifts of 0) to be placed after the inputs, but these did not affect our analysis, so we disregard them. 56 Figure 5-7: Ptolemy Normalization Design 57 Multiply Cop AM ulator Chop Multiply Accumulator Chop -- pMultiply Accumulator Chop Multiply Accumulator Chop Multiply|- Accumulator Chp Accumulator Chop Ac Chop data input - -Multiply ulator Chop - Accumulator Chop Accumulator Chop Accumulator Chop -_N0 Multiply|-hoMultiply -- 7 f o ~ : MultiplyMultiply ang l inp t-- T emfay - Maximum Maximum Maximum iMultiply muAccumulator output Maximum Maximum Maximum Maximum Maximum Maximum _L-,t __,Ib Figure 5-8: Correlation Block Diagram 5.2.2 Correlation The block diagram for the correlation calculation is shown in Figure 5-8. There were two inputs to the correlation: a target signature and an angle input which was used to produce a template signature. Once both signatures had been generated, the target signature (which was 90-wide) was passed to 11 parallel Chops which took the 11 different range shifts. Each of these 80-vectors was correlated with the template vector through the use of a Multiply, an Accumulator, and a Chop. Finally, the 11 correlations were passed through a binary tree of Maximums to produce the maximum correlation. There were many issues to be resolved with the correlation design. The most difficult decision was how to handle the template library. In software execution, all templates within 50 in aspect were considered. Due to nonuniform aspect spacing, this meant that the number of templates being considered was aspect-dependent. Consequently, there was a data-dependent control flow. In order to remove this dependency, the template set was filled out to contain 360 templates. Because templates were spaced in multiples of 10, any angles that were not represented had templates containing all zeros inserted. Additionally, to facilitate the 58 ±50 aspect span, the template sets were given 5' wraparound at each end. Therefore, for a given angle, there were exactly 11 templates per class to be considered and they appeared sequentially in the template library. This resulted in a template library size of 7 (classes) x 370 (vectors) x 80 (elements/vector) = 207,200 elements. An additional problem was how the template library would be used. Because there was no way to hold a target vector in place, the decision was made to only perform one vector comparison per initiation. Note that this meant that each target vector had to be repeated 77 times (7 (classes) x 11 (aspect angles/class)) for all the comparisons to be made. Consequently, a simple address generator was built into the template library which would output one signature given its starting address. Clearly, this is not the most efficient approach, but timing constraints prevented an alternate approach (i.e. a memory element could be used to hold the target vector in place) from being investigated. The target set consisted of 1,362 vectors. Since each vector had to be repeated 77 times, the input dataset consisted of 104,874 90-vectors, meaning 9,438,660 elements had to be written to the hardware memory. Because the memory banks only had 262,144 addresses, this dataset was broken into 37 smaller pieces. To make processing simpler, vectors were not split across pieces; rather, each download consisted of 37 90-vectors repeated 77 times (256,410 elements). The only remaining difficulties were related to bit precision. The decision was made to put all of the correlation calculation (not necessarily the template address generation) in a single FPGA. If the correlation was not able to fit into a single FPGA, additional designs would be necessary in order to be able to route the template data to multiple FPGAs, due to the limited number of interconnects between FPGAs. The most expensive elements in the correlation design were the Multiplies. It was not possible to fit 11 16-bit multipliers in a single FPGA. Consequently, the multipliers were reduced to 12-bit input precision. This still resulted in accuracy down to 2-1 (assuming <1.12> precision), which would be sufficient for determining maximum correlations. Figure 5-9 shows the Ptolemy graph for the correlation design. Again, the buffers can be disregarded. 59 Figure 5-9: Ptolemy Correlation Design 60 At this point, since the crucial design elements had been decided, the only remaining issue was to make FPGA assignments. Since there were only two large components (the normalization and the correlation), this was relatively easy. The data input and normalization had already been placed in PEI. The address input was sent to PE2. The template library and address generator were placed in PE3. Finally, the correlator and output memory were assigned to PE4. 5.3 Summary This chapter analyzed the SHARP algorithm to eliminate any difficulties in creating a hardware design for it. After analyzing the power transformation, it was decided that the complexity inherent in creating a design for it outweighed the benefit that would be gained through its hardware acceleration. Consequently, execution of the power transformation was left in software. The least squares fit was also analyzed with regards to hardware issues. The biggest difficulty encountered was handling the template library. The library was modified to remove data dependencies and a compromise was made to repeat the input data set in order to reduce the complexity of the design. Although this compromise greatly reduced the efficiency of the design, Chapter 6 will show that the resulting hardware acceleration still provided a significant speedup. This chapter finally presented the Ptolemy diagrams that were used to produce the hardware designs that will be presented in Chapter 6. 61 Chapter 6 Performance Comparison Our initial intent was to provide hardware acceleration for the SHARP algorithm, such that a standalone application could be developed that implemented a portion of the algorithm in hardware, and demonstrated an appreciable speedup over its fully software counterpart. Unfortunately, due to project funding and timing constraints, it was not possible to fully meet this objective. However, here we present the results we were able to obtain which show that the ultimate objectives are completely attainable. Recall from Chapter 5 that our decision was to only implement the least squares fit routine in hardware, due to the inherent complexity of implementing the power transformation. Consequently, the least squares fit was split into two components. Bias removal and normalization comprised the first part while correlation and a maximum tree comprised the second. These designs were created separately in order to facilitate testing, and also because they are completely modular; there would be no difficulty in merging the components once each had been fully tested. In Section 6.1, we present the normalization design. We consider both its timing and algorithmic performance. We also suggest further modifications that result in improved performance. Section 6.2 presents the correlation design. Although this design was not fully functional, its performance and timing were estimated. Section 6.3 combines the two designs and compares the estimated timing and performance results with the software results presented in Chapter 4. Finally, Section 6.4 indicates how these designs could be further modified to improve the overall performance. 62 Table 6.1: Normalization Design Bit Precisions Block input Chop Accumulator Chop Const Multiply Register Register Subtractor Subtractor Square Accumulator Chop Sqrt Register Divider output 6.1 Input II Input 2 <4.16> <4.16> <11.16> <11.15> <4.15> <4.16> <4.16> <4.16> <5.15> <10.16> <17.17> <17.16> <9.15> <5.14> <-6.14> <4.15> <4.16> <9.15> Output <4.16> <4.16> <11.17> <11.15> <-6.14> <4.16> <4.15> <4.16> <5.16> <5.16> <10.16> <17.18> <17.17> <9.15> <9.15> <6.16> <6.16> Bias Removal and Normalization We begin first with the precisions chosen by the wordlength analysis tool, shown in Table 6.1. Elements are listed as they appear in Figure 5-6, in column-major order. There are two factors of interest in this table. First, the input precision was arbitrarily chosen to be <4.16>. We know from our analysis of the power transformation in Section 5.1.1 that a precision of <1.16> would be more appropriate and provide better precision on the input. Additionally, we note that the Divider output was not manually set to <1.16>. The <6.16> output precision was a result of the conservative precision assignment made by the wordlength analysis tool. Figure 6-1 shows the execution schedule for the design, indicating an execution time of 312 clock cycles. Figure 6-2 shows a floorplan of PEI for this design that indicates the area of the design. This floorplan was generated using the graphical floorplanner tool in the Xilinx Alliance tools. The floating point software and fixed point hardware results for the input bmp263 63 0- - -5 -10 - - - - -15 a) E -20 a) 0 -30 .. . . . . . . -35 -40~ 0 50 100 150 Clock cycles 200 250 Figure 6-1: Execution Schedule for the Normalization Routine 64 300 0I" %ZNII! %~NIX :i J x K t. ZI 4;I Figure~~~~~~~~~~~ 6-:FG-cupnyfrteNomlztnRuie 65 1.5 ca 0.5- 0 0 10 20 30 40 50 60 70 80 90 Range Figure 6-3: Input Signature to Normalization Routine 0.5 - Software Hardware 0.4- 0.3- 0.2as 0.1 0- -0.1 -0.21 0 10 20 30 40 50 60 70 80 90 Range Figure 6-4: Normalization Routine - Software and Hardware 66 0.3 -- Floating Point Fixed Point 0.25- 0.2- 0.15- CD 0.1 CD 0O 2 0.05 - 0- -0.05 - -0.1 -0.151 0 10 20 30 40 50 60 70 80 90 Range Figure 6-5: Normalization Routine - Floating Point and Modified Fixed Point signature shown in Figure 6-3 are shown in Figure 6-4. We can see that the normalization only performed well in hardware at output values close to zero. As the output signature moved away from 0, the error between the software and hardware versions increased. By examining the precisions, it was determined that the cause of this poor performance was a result of the two Accumulators and the Square. The output precisions of these blocks were only accurate within 2--, 20, and 2', respectively. By modifying these precisions so that precision was accurate up to the LSB of the input, we would hope to see better results. In fact the floating point output is compared with a software implementation using these fixed-point precision in Figure 6-5. Here, we see excellent performance, even using fixed-precision arithmetic. We would also expect this performance to further improve when the input precision and divider precision are manually set to <1.16> since these precisions better fit the data. Additionally, we expect the design cost to decrease slightly because the wordlengths would grow more slowly given an initial major bit of 1. 67 Table 6.2: Correlation Design Bit Precisions Input 1 Input 2 1 Output Block data input <1.16> angle input <15.16> Template Library <15.16> <1.16> Chop <1.16> <1.12> Multiply <1.12> <1.12> <2.16> Accumulator <2.16> <9.16> Chop <9.16> <4.16> Maximum <4.16> <4.16> <4.16> output <4.16> 6.2 Correlation While project funding prevented a working correlation design from being fully tested, we had all the information necessary to simulate execution and predict what the result would have been. We begin as before with the precisions provided by the wordlength analysis tool. The precisions along the 11 parallel paths and the precisions of the 10 Maximums were identical, so we present a condensed version of the precision table in Table 6.2. Figure 6-6 shows the corresponding execution schedule, taking a total of 100 clock cycles. Figure 6-7 shows the occupancy of PE4, since most of the calculation was there. PE2 and PE3 only contained hardware for address and template generation and, as a result, were mostly unoccupied. We see from Table 6.2 that once again, precision was lost in the accumulator. Consequently, we again modified the accumulator precision to be accurate to the LSB of its input (i.e. from <9.16> to <9.23>). Figure 6-10 shows the comparison between software floating point and fixed point simulation when the target signature shown in Figure 6-8 (already normalized) was correlated with the template signature shown in Figure 6-9. Figure 6-10 shows the correlations for each of the 11 range shifts. We can see from Figure 6-10 that with the modified precisions, the correlation design worked well with fixed-precision arithmetic. Section 6.3 will present results for the overall algorithm execution. 68 0 E z 00 I -150 L 0 10 20 30 U: 40 60 50 Clock cycles 70 80 90 Figure 6-6: Execution Schedule for the Correlation Routine 69 100 Figure 6-7: FPGA Occupancy for the Correlation Routine 70 0.3 0.3 I I I I 10 20 30 40 I I I I 50 60 70 80 0.25 0.2 F 0.15 (D 0.1 .E M1 cts 0.05 0 -0.05 -0.1 -0.15 0 90 Range Figure 6-8: Correlation Target Signature 0.3 G 0.3- 0.2 5 0.20.1 5ca *0 0.1- 0.0 5 -- 0- -0. )5- -0 0 00 10 20 30 40 Range 50 60 Figure 6-9: Correlation Template Signature 71 70 80 1 1 -! 0.9 0.8 Floating Point Fixed Point Ix 5 - 0.7 0.6 0 -60.5 0 0 0.4 0.3- 0.2 - 0.1 - 1 2 3 4 5 6 Shift 7 8 9 10 11 Figure 6-10: Correlation by Range Shift 6.3 Final Comparison Estimates 6.3.1 Algorithm Performance Our first concern should be the fidelity of the algorithm. Whether the hardware version of the algorithm executes faster than its software counterpart is irrelevant if the hardware version performs very poorly. Thus, in Tables 6.3 and 6.4 we present the confusion matrices obtained through software execution, but with the least squares fit performed using the precisions we have chosen for the hardware implementation. Table 6.3: Confusion Matrix by Vehicle Using Fixed-Point Simulation Actual BMP263 BMP266 BMP2c21 BTR70c21 T72132 T72812 T72s7 BMP263 46.15% 7.69% 20.51% 4.62% 2.04% 0.00% 1.57% BMP266 15.90% 58.97% 13.33% 6.15% 1.53% 2.05% 4.19% BMP2c21 24.10% 14.36% 50.77% 5.13% 4.08% 1.54% 2.09% 72 Predicted BTR70c21 4.10% 4.10% 4.10% 75.38% 0.00% 1.03% 1.05% T72132 3.08% 4.10% 4.62% 3.08% 75.00% 6.15% 8.90% T72812 4.10% 4.62% 2.56% 2.56% 10.20% 74.87% 11.51% T72s7 2.56% 6.15% 4.10% 3.08% 7.14% 14.36% 70.68% Table 6.4: Confusion Matrix by Vehicle Type Using Fixed-Point Simulation Actual BMP2 BTR70 T72 BMP2 83.93% 15.90% 6.36% Predicted BTR70 T72 4.10% 11.97% 75.38% 8.72% 0.69% 92.96% We can see that through comparison with Tables 4.2 and 4.3, that the performance degraded slightly due to the use of fixed-precision calculation. However, this degradation did not appear to be very significant since the fixed point results were within 2% of the floating point results. 6.3.2 Algorithm Timing We also estimated the timing performance of the hardware version of the algorithm. Because we know that we will suffer some performance degradation through the use of fixed-point arithmetic, a hardware implementation is not advantageous when compared with the software version unless it runs significantly faster. A timing test was performed to measure the time necessary to transfer all of the input (data input as well as angle input) to the hardware board and read back the output in the same manner that this would be done in the final working version. The total time spent in data transfer was 6.99 seconds. We must now estimate the time spent in calculation. Recall that the normalization and correlation designs took 312 and 100 clock cycles to execute, respectively. However, the last 90 clock cycles of the normalization design were used for writing the output vector to a memory bank because the design was standalone. Consequently in a combined design, the total execution time would be 312 + 100 - 90 = 322 clock cycles to compare one target vector to one template vector. The data was processed in 37 pieces, each consisting of 37 vectors, repeated 77 times. This results in a total of 37 x 37 x 77 x 322 ==33,942,986 clock cycles to process all vectors. Since the board was running at a clock speed of 2.5 MHz, we should 73 expect a total computation time of 13.58 seconds. Consequently, the total time spent in least squares fitting is 20.57 seconds. Because we have not altered the remainder of the algorithm, we can use the timing measurements from Table 4.4 to estimate the total execution time for the accelerated algorithm. We should still expect 18.33 seconds to preprocess the data. Our timing estimate for least squares fitting is 20.57 seconds. The time for classification should remain unchanged at .80 seconds. Consequently, the estimated total time for execution of the accelerated SHARP algorithm is 39.70 seconds. This is clearly an improvement over the software execution time of 258.48 seconds and indicates that even with a suboptimal design such as the one proposed here, a significant benefit can be gained over software execution. 6.4 Proposed Improvements Even though we have shown that the above design provides a significant speedup for the SHARP algorithm, there are several further modifications that can be made that will further improve the hardware speedup of the SHARP algorithm. Here, we briefly discuss two improvements. The first improvement is fairly straightforward. Even though the Wildforce board was only running at 2.5 MHz, it supports clock speeds up to 50 MHz [3]. Consequently, if the clock speed could be increased, we would expect a directly proportional decrease in the computation time of the least squares fit. The board was only clocked at 2.5 MHz due to a difficulty encountered in receiving board interrupts at higher clock speeds. Consequently, if this problem were resolved, the execution time could be decreased by simply increasing the Wildforce clock speed. The second improvement is to design a memory element to hold target vectors in place. Recall that the lack of this element required the dataset to be repeated 77 times. Consequently, we should expect a dramatic savings if we successfully implemented it. However, in order to make full use of it, the template library address generator would have to be expanded to produce all 77 comparison template vectors. 74 The first effect of this change would be to reduce the data transfer time. The input dataset would only consist of 1,362 90-vectors and 1,362 aspect angles. The output would consist of 77 correlations for each of the 1,362 input vectors. Consequently, only one download would be necessary. We conservatively estimate the data transfer time to be 1 second. Additionally, for each input vector, normalization only occurs once, while correlation happens 77 times. Consequently, even if we assume a one-time cost of 90 clock cycles to store the target vector and a cost of 50 clock cycles for address generation (a conservative estimate), then the total number of clock cycles to fully process one vector would be at most 312 + 90 + 77 x (50 + 100) = 11,952 clock cycles. To process all 1,362 vectors (still at 2.5 MHz) would then take approximately 6.5 seconds. Including data transfer, we see that even our conservative estimate of 7.5 seconds is a significant improvement over the estimate of 20.57 seconds in Section 6.3. 6.5 Summary In this chapter, we have presented timing and performance results, both measured and estimated, for the hardware acceleration of the SHARP algorithm. We have demonstrated that although the hardware design we presented was not optimal, its inefficiency was outweighed by the benefit of simply running in hardware. Our timing estimate indicated that hardware execution would result in a speedup on the order of 6.5x when compared with the optimized software implementation results presented in Chapter 4, while the performance of the algorithm in hardware remained within 2% of its software counterpart. We also indicated areas in which the design could be further improved. By increasing the Wildforce clock speed and using a memory element to eliminate the need to repeat the dataset 77 times, the algorithm speedup could be increased to well over an order of magnitude, demonstrating the potential of reconfigurable hardware. 75 Chapter 7 Summary ATR is an evolving military application. As technology advances, the performance standards for ATR systems are set higher. Until ATR systems achieve perfect recognition, they will continue increasing in computational intensity as technology permits in order to improve performance. It is naturally important that the time for classification remain relatively constant as the classification performance increases. The merits of perfect recognition are questionable if the recognition cannot be included in a real-time system. Consequently, for military applications, it is important to investigate technologies that are increasing in computational power as well as speed. FPGAs have a promising future in areas of intensive computing. Reconfigurable computing has recently received a great deal of attention due to its computational capabilities coupled with its affordability and ease of design. Numerous defense- related projects have begun examining the potential of FPGAs for computationally intensive applications. This thesis examined the potential of FPGA acceleration for a particular ATR system, the SHARP algorithm. While the identification performance of the algorithm was clearly not precise enough to be including in a practical system, it served as an instructional case to demonstrate the capabilities of reconfigurable hardware for target recognition systems. This thesis also demonstrated the advances being made in FPGA design tools. 76 The amount of time being spent in hardware design is being drastically reduced due to the existence of tools like those provided by the ACS program. While the development of these tools is still far from maturation, this thesis demonstrated that they can already be used to design and implement sophisticated systems while hiding most of the low-level decisions from the designer. As this field matures, we can expect even more low-level decisions to be abstracted away, while achieving more efficient underlying designs. By examining these technologies through the framework of a comparatively simple ATR algorithm, this thesis created a foundation that demonstrates what the current capabilities are and where the needs for further study lie. It is hoped that the methods and results presented in this thesis will serve as a basis to advance future research. 77 Appendix A Acronyms ACS: Adaptive Computing Systems AFRL: Air Force Research Laboratory APC: Armored Personnel Carrier ASIC: Application Specific Integrated Circuit ATR: Automatic Target Recognition CLB: Configurable Logic Block DFT: Discrete Fourier Transform EDIF: Electronic Design Interchange Format FPGA: Field-Programmable Gate Array HRR: High Range Resolution IFFT: Inverse Fast Fourier Transform LSB: Least Significant Bit LUT: Lookup Table MCMC: Markov Chain Monte Carlo MSTAR: Moving and Stationary Target Acquisition and Recognition MTI: Moving Target Indication RMS: Root Mean Square SAR: Synthetic Aperture Radar SDF: Synchronous Dataflow SHARP: System-Oriented HRR Automatic Recognition Program 78 VHDL: VHSIC Hardware Description Language VHSIC: Very High Speed Integrated Circuit WPAFB: Wright-Patterson Air Force Base 79 Bibliography [1] Air Force Research Laboratory, An Air-to-Ground Classification Analysis. AFRL Internal Memo, 1994. [2] Annapolis Micro Systems, Inc., Annapolis Micro Systems Home Page. http://www.annapmicro.com, 2001. [3] Annapolis Micro Systems, Inc, Wildforce Reference Manual, 1999. [4] BAE SYSYEMS, Algorithm Analysis and Mapping Environment for Adaptive Computing Systems. http://www.sanders.com/adv-tech/aam.htm, 2000. [5] B. Bhanu, G. Jones III, Object Recognition Results Using MSTAR Synthetic Aperture Radar Data. IEEE Workshop on Computer Vision Beyond the Visible Spectrum: Methods and Applications, pages 55-62, 2000. [6] Y. Cho, Optimized Automatic Target Recognition Algorithm on Scalable Myrinet/Field Programmable Array Nodes. IEEE Asilomar Conference on Signals, Systems, and Computers, 2000. [7] P. Djuric, Bayesian Methods for Signal Processing. IEEE Signal ProcessingMagazine, pages 26-28, September 1998. [8] R. Duda, P. Hart, Pattern Classification and Scene Analysis. John Wiley & Sons, Inc. 1973. [9] P. Fiore, P. Topiwala, Bit-ordered Tree Classifiers for SAR Target Classification. IEEE Asilomar Conference on Signals, Systems, and Computers, 1997. 80 [10] P. Fiore, A Custom Computing Framework for Orientation and Photogrammetry. Ph.D. Thesis, Massachusetts Institute of Technology, June 2000. [11] P. Fiore, C. Myers, J. Smith, E. Pauer, Rapid Implementation of Mathematical and DSP Algorithms in Configurable Computing Devices. SPIE International Symposium on Voice, Video, and Data Communications, November 1998. [12] P. Fiore, Suitability of AFRL Forced Decision Algorithm for ACS Demo. Sanders Internal Memo, August 1999. [13] P. Fiore, Wordlength Optimization via the MCMC for Custom DSP Computing. Submitted to IEEE Transactions on Signal Processing,November 2000. [14] D. Gross et al. High Range Resolution Ground Moving Target ATR Using Advanced Space-Based SAR/MTI Concepts. AIAA Space Technology Conference & Exposition, September 1999. [15] R. Hummel, Moving and Stationary Target Acquisition and Recognition 2001. (MSTAR). http://www.darpa.mil/spa/Programs/mstar.htm, [16] Khoral Research, Inc. Khoral Home Page. http://www.khoral.com, 2001. [17] D. Kottke, P. Fiore, Systolic Array for Acceleration of Template Based ATR, IEEE International Conference on Image Processing, 1997. [18] T. Lamont-Smith, Translation to the Normal Distribution for Radar Clutter. IEEE Proceedings - Radar, Sonar, and Navigation, Vol. 147, No. 1, pages 17-22, February 2000. [19] B. Levine et al. Mapping of an Automated Target Recognition Application from a Graphical Software Environment to FPGA-based Reconfigurable Hardware. IEEE Symposium on Field-ProgrammableCustom Computing Machines, pages 292-293, 1999. 81 [20] T. Marzetta, E Martinsen, C. Plum, Fast Pulse Doppler Radar Processing Accounting for Range Bin Migration. IEEE National Radar Conference, pages 264268, 1993. [211 The Mathworks, MATLAB Introduction Home Page. http://www.mathworks.com/products/matlab/ 2001. [22] R. Mitchell, R. DeWall, Overview of High Range Resolution Radar Target Identification. SPIE Automatic Target Recognition Conference, pages 35-47, October 1994. [23] A. Oppenheim, R. Schafer, Digital Signal Processing. Prentice-Hall, 1975. [24] E. Pauer, P. Fiore, J. Smith, C. Myers, Algorithm Analysis and Mapping Environment for Adaptive Computing Systems. A CM InternationalSymposium on Field-ProgrammableGate Arrays, 1999. [25] E. Pauer, P. Fiore, J. Smith, Algorithm Analysis and Mapping Environment for Adaptive Computing Systems: Further Results. IEEE Symposium on FieldProgrammable Custom Computing Machines, pages 264-265, April 1999. [26] J. Ratches, C. Walters, R. Buser, B. Guenther, Aided and Automatic Target Recognition Based Upon Sensory Inputs from Images Forming Systems. IEEE Transactionson PatternAnalysis and Machine Intelligence, Vol. 19, No. 9, pages 1004-1019, September 1997. [27] G. Strang, Introduction to Linear Algebra, Wellesley-Cambridge Press, 1998. [28] Synplicity, Inc., Synplicity Home Page, http://www.synplicity.com, 2001. [29] University of California at Berkeley, The Ptolemy Project. http://ptolemy.eecs.berkeley.edu, 2001. [30] J. Villasenor et al. Configurable Computing Solutions for Automatic Target Recognition. IEEE Symposium on Field-ProgrammableCustom Computing Machines, pages 70-79, 1996. 82 [31] A. Wilkinson, R. Lord, M. Inggs, Stepped-Frequency Processing by Reconstruction of Target Reflectivity Spectrum. IEEE Southern African Symposium on Communications and Signal Processing, September 1998. [32] R. Williams et al. Automatic Target Recognition of Time Critical Moving Targets Using 1D High Range Resolution (HRR) Radar. IEEE Radar Conference, pages 54-59, 1999. [33] A. Willsky, G. Wornell, J. Shapiro, Stochastic Processes, Detection, and Estimation, 6.432 Course Notes, 1999. [34] Xilinx Corporation, Xilinx Home Page http://www.xzilinx.com, 2000. 83
 0
0
advertisement

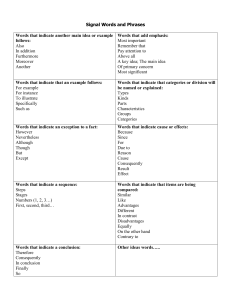




Download
advertisement
Add this document to collection(s)
You can add this document to your study collection(s)
Sign in Available only to authorized usersAdd this document to saved
You can add this document to your saved list
Sign in Available only to authorized users