This material concerns modeling and inference for a binomial success... that is a function of one or more predictors
advertisement

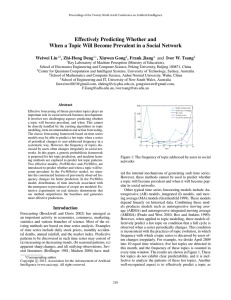
Stat 401B Handout on Logistic Regression This material concerns modeling and inference for a binomial success probability p that is a function of one or more predictors x1 , x2 , , xk . The most common version of this modeling is that where the log odds are taken to be linear in the predictors, i.e. where p ln 0 1 x1 2 x2 k xk 1 p This is equivalent to a model assumption that p x1 , x2 , , xk exp 0 1 x1 2 x2 k xk 1 exp 0 1 x1 2 x2 k xk (*) To aid understand the meaning of this assumption, below there is a plot of the "s-shaped" exp u function p u . 1 exp u The assumption (*) says that the input values and parameters produce the value u 0 1 x1 2 x2 k xk that gets translated into a probability through p u . 1 We consider a model where for i 1, 2, , N , independent binomial random yi variables have corresponding success probabilities pi p 0 1 x1i 2 x2i k xki While all that follows can be easily generalized to cases where the numbers of trials ni for the yi are larger than 1, for ease of exposition, we'll suppose here that all ni 1 . In this case, the joint pmf of the observables y1 , y2 , , yN is the function of the parameters 0 , 1 , 2 , , k N f y1 , y2 , , y N | 0 , 1 , 2 , , k piyi 1 pi 1 yi i 1 With observed values of the yi plugged into f , one has a function of the parameters only. The logarithm of this is the so-called "log-likelihood function" L 0 , 1 , 2 , , k ln f y1 , y2 , , yN | 0 , 1 , 2 , , k ln p 0 1 x1i k xki i with yi 1 ln 1 p 0 1 x1i k xki i with yi 0 that is the basis of inference for the parameter vector β 0 , 1 , 2 , , k and related quantities. To begin, the parameter vector b b0 , b1 , b2 , , bk that optimizes (maximizes) L β is called the "maximum likelihood estimate" of β . Further, the shape of the log-likelihood function near the maximum likelihood estimate ( b ) provides the basis of confidence regions for the parameter vector β and intervals for its entries j . First, the set of parameter vectors β with "large" log-likelihood form a confidence set for β . In fact, for U2 an upper percentage point of the N2 k 1 distribution, those β with 1 L β L b U2 2 (those with log-likelihood within 1 2 U of the maximum possible value) form an approximate 2 confidence region for β . 2 Second, the curvature of the log-likelihood function at the maximizer b provides standard errors for the entries of b . That is, for 2 H L β k 1 k 1 i j βb the "Hessian" matrix (the matrix of second partials) of the log-likelihood at the maximizer, estimated variances of the entries of b can be obtained as diagonal entries of H 1 (the negative inverse Hessian). The square roots of these then serve as standard errors for the estimated coefficients b j (values SEb ) that get printed out by statistical systems like R. j Corresponding approximate confidence limits for j are then b j z SEb j Somewhat more reliable confidence limits can be produced by a more complicated/subtle method and can be gotten from glm(). The value lˆ b0 b1 x1 b2 x2 bk xk serves as a fitted log odds. glm() in the R package will produce fitted values for the data set (and for new vectors of inputs) and will also produce corresponding standard errors. Call these SE ˆ . Then, approximate confidence limits for the log odds 0 1 x1 2 x2 k xk are l lˆ z SE ˆ l Simply inserting these limits into the function p u produces confidence limits for the success probability at inputs x1 , x2 , , xk , namely p lˆ z SE ˆ l and p lˆ z SE ˆ l giving a way to see how much one knows about the success probabilities at various vectors of inputs. 3