Estimates and schedules
advertisement

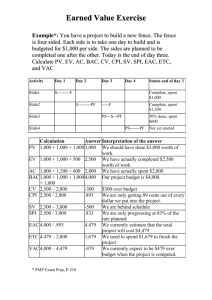
SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules 1. Estimates and schedules Estimates – are assessments based on what we know, how long something should take. Estimation has always been one of the riskiest aspects of project or program planning. This is not because estimators are regularly unqualified or poorly informed -- it is primarily because of the large and growing number of complexities and dependencies that must be factored into software project estimates. Inevitably, as software projects, software products, and IT environments all become more and more complex, so, too, does the task of estimating what they will cost and how long they will take. To compound the challenge, established parameters that form the basis for many estimation techniques are not as universally applicable, or as straightforward to calculate, as they once were. Many estimators are thus left searching for methods that can yield more accurate results. Vitalie Temnenco (vit@umlconsulting.com), Architect, from paper: Software Estimation Enterprise-Wide 1.1 Why do we need Estimates ? Budgeting a project – if we don’t know how much a project will cost, then we don’t know if we should do it. Project Planning – what resources will we need and during what time in the project will we need them. Risk management and trade-off analysis – if we have a limited budget and resources (we are always limited in resources), then we will need to pick and choose what will be developed in conjunction with a customer. Also, if certain items are risky, then we may need to plan for contingencies. To get better at estimating – if we have estimates and track actuals, we have a feedback system with which we can learn to be better at estimating. To ensure that we understand the problem – if we cannot give good estimates, then we probably do not understand what we need to develop. © 2012 Mike Rowe 1 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules 2.1 Top Down approach Start with the whole, break the whole into pieces, and successively break the pieces into smaller pieces. See the figure below on the right. Level 1 might represent subsystems, Level 2 might represent subsubsystems, finally we get done to individual classes. Figure 1: From . Vitalie Temnenco (vit@umlconsulting.com), Architect From paper: Software Estimation Enterprise-Wide The top-down approach, also known as the Macro Model, is based on partitioning project scope and then using averages (either specific to the organization or industry averages) to estimate cost and complexity associated with implementing the parts and their interconnections at each level. The benefit of this approach is that early on, like at the subsystem level, we can start producing estimates. For instance, it might take 400 hours to design, implement and test an average subsystem. It might take 4 hours to design, develop, and test a simple GUI dialog. (2 hours to design, 1 hour to develop and 1 hour to test). It may take 2 hours to design simple a database query. It may take 24 hours to design, implement and unit test an average class. © 2012 Mike Rowe 2 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules It may take use 9.6 hours to develop the code for an average requirement. It may take 8 hours per subsystem to integrate and perform integration testing. The distinctive feature of the top-down approach is its focus on overall system properties, such as integration, change management, and incremental delivery; combined with its relative ease of application. 3.1 Work Breakdown Study – Is a popular Top-down approach that recursively break down tasks until some minimal time per task is achieved. This minimal time can be as small as a couple of hours or half an engineer-day. Bottoms up approach Based on requirements, use cases, function points, . . . estimate produce individual estimates of the lowest level pieces and then start rolling them up. 4.1 Using this approach can provide very good estimates of individual raw components, But, this method can miss or overlook significant system level architectural components and activities. o For example, a Bottoms up approach may miss integration activities at various levels. Hybrid approach Method 1: Start with an outline of your development process. Such as: Analysis, Design, Development, Unit Test, Integration, Integration Test, System Test, . . .. Then for each required piece of the system, based on requirements, use cases, etc. produce task estimates. This results in very small tasks that are function by life-cycle related. 1. TaskA: a. b. c. d. e. Provide persistent data storage for entity X Subtask: Analysis Subtask: Design Subtask: Development Subtask: Unit Test Subtask: Integration // Sometimes individual tasks will not have tasks from this //point on – Integration will be at a higher level. f. Subtask: Integration test g. Subtask: System Test © 2012 Mike Rowe 3 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules Method 2: Varies from method 1 in that you start off by defining your process as the top level Tasks and then list the tasks under them. The second level can either start with Top-Down (as shown) or Bottom-Up. From personal experience, Method 2 with a Top-Down approach is the approach that I prefer. You stop dividing tasks when you get to a point at which the estimates task length is less than some organizational standard (say 4 hours). 1. Analysis a. Subsystem A i. SubA.1 1. SubA.1.1 2. SubA.1.2 3. SubA.1.3 4. . . . ii. SubA.2 1. SubA.2.1 2. . . . iii. SubA.3 1. . . . b. Subsystem B iv. SubB.1 v. SubB.1.1 vi. SubB.1.2 vii. SubB.1.3 viii. . . . 2. Design a. Subsystem A i. SubA.1 ii. SubA.1.1 iii. SubA.1.2 iv. SubA.1.3 v. . . . 3. Subsystem B a. SubB.1 i. SubB.1.1 ii. SubB.1.2 iii. SubB.1.3 iv. . . . © 2012 Mike Rowe 4 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules 2. Schedules Schedules – are based on estimates and are an ordering of the tasks in the order that they should best be completed. Generally, there are resources associated with scheduled tasks. Estimates and Schedules: The fidelity can vary with our needs and the customer’s needs. The fidelity will vary as you progress into a project. o The further you get into a project the more you should know about a project and your fidelity should increase. At the concept stage your estimates should be very rough, whereas after doing detailed requirements and specifications you should have much more knowledge of the project and should be considerably more accurate. If we don’t have some sort of a Schedule, we don’t know if a project is ahead or behind. Schedules match up tasks with resources to perform the tasks. We look for tasks that are dependent on earlier tasks and chain these together. The total schedule time is often dependent on the longest chain through the project. o Critical Path Analysis can help us find this longest chain. We can often shorten total project duration by placing more resources on the tasks that make up this critical path. Actuals or Actual Cost(AC) – the real amount of effort (on most projects this represents cost or engineering hours) used for a project during a certain time period. Sometimes this is called the Actual Cost. © 2012 Mike Rowe 5 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules Estimates – the scheduled amount of time to be spent on each task, subtask or the total project. Baselined Schedule – once we believe the schedule is accurate and maybe after customer signoff, we often lock our estimates. Once work on tasks start, we record the actual time spent on each lowest level task. Schedule Variance is the difference between the estimated and actual time for a task. Estimated Actuals – projections of the actual based on the ratio of actuals to estimates (percent of schedule variance). If we have completed 50% of the total work, and we have taken 25% more effort than we originally estimated, then we can estimate a new actual for upcoming tasks by multiplying upcoming task estimate by 125% The above assumes that we keep resources fixed – no one is added or removed from a project. 2.1 Earned Value Earned Value (EV) – an estimate of the amount of a project that has been completed. This could be based on tasks that have been completed on the schedule or something like the number of tested requirements completed. It can also be more complex, wherein partial credit is earned for analysis, design, implementation, unit testing, integration, integration testing, System Testing, Customer Acceptance, . . . of each schedule item (like a requirement or use case) o If we are using a Requirements based EV – 5% -- reviewing a rqmt 25% -- completing design regarding a rqmt 5% -- design review of a rqmt 20% -- coding of a rqmt 10 % -- unit testing of a rqmt 10% -- code review of a rqmt 10% -- integration of a rqmt’s code into a system 10% -- integration testing of a rqmt code 5% -- deployment of a rqmt o The sum of the ratios for one task (requirement, use case, . . .) totals to 1.0 or 100% o Often EV is normalized to engineer-hours. © 2012 Mike Rowe 6 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules For instance, if our organization averages 20 engineer-hours per requirement (from start to finish), then our earned value using the percentages above could be multiplied by twenty to produce an earned value in hours. Planned Value (PV) – PV is the Earned value that was scheduled at a particular point in time. This can be in dollars (for the customer and our business folks) – for development and maintenance organizations, we would generally use engineer-hours. Often the function looks like a very lazy and tipped ‘S’. Figure 2: From Ray Stratton, Projects @ Work: http://www.projectsatwork.com. If the project eventually completed we will get to 100% of planned value. Note this is based on planed value in dollars, but we could also use engineering-hours. Often this Curve resembles a lazy ‘S’ curve. We can analyze how a project is doing be comparing the planned value, the earned value and the actual cost. Cost Performance Index (CPI): Is the efficiency with which we are achieving earned value. CPI is computed by dividing the current EV by the current AC at some point in time. CPI = EV / AC If we are producing EV at about the cost or hours we had expected, then CPI will be around 1.0. You are at budgeted cost. This is Good. If it is taking us more effort to produce value (EV) than was initially planned then CPI will be less than 1.0. You are over budgeted cost. This is NOT Good. © 2012 Mike Rowe 7 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules And, if we are producing more earned value per actual cost we will have a CPI greater than 1.0. You are under budget cost. This is Very Good. Note: 1. CPI is only an estimate of the efficiency of an organization in producing software to planned cost. It does not say anything about schedule, as we may have more or fewer people working on a project than were initially planned. Or, we could have a CPI much greater than 1.0 but still be behind schedule. 2. Also, we could use EV in engineering-hours – for instance we convert the planned functionality at any point to the planned number of hours scheduled and then we can compare that against AC (also in engineering-hours). Engineering-hours are generally, what is used in software organizations. Hours are better for use in that we may not have control over who is available to work on a project and what they are paid. Schedule Performance Index (SPI): measures how well a project is sticking to its schedule without regard to cost. It is computed by dividing Earned Value by Planned Value at some point in time – basically, do you have the functionality that you planned to have by this date in the schedule. SPI = EV / PV If your project has completed about the same amount of work as you had planned or scheduled to at this point then your SPI will be around 1.0. You are on schedule. This is Good. If your project has less than the amount of work that you had planned or scheduled to at this point then your SPI will be less than 1.0. You are behind schedule. This is NOT Good. If your project has completed more than the amount of work that you had planned or scheduled to at this point then your SPI will be greater than 1.0. You are ahead of schedule. This is Very Good. SPI and CPI are both needed to get the full picture. For example: We could be behind in Schedule, (SPI < 1.0), and ahead in Cost (CPI > 1.0) because we don’t have enough people to work on the project, but those people are working more efficiently than expected. Or, we could be ahead of Schedule, (SPI > 1.0) and behind in Cost (CPI < 1.0) because we have extra people working on the project. but they are not working as efficiently as expected. © 2012 Mike Rowe 8 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules Figure 3: From Ray Stratton, Projects @ Work: http://www.projectsatwork.com. Show how the EV line continues to produce Estimated Actual Project Completion (EAPC) and Estimated Actual Project Cost (EAPC). In the above example: PV = $5M EV = $4M AC = $4.8M Note: that these do not need to be in DOLLAR, EV, AV and PV could be measured in number of Engineer-Hours (since “time is money”). Engineer-Hours is generally more common to see on the software side of things as it’s is more useful for Software Engineers to see, rather than project dollars. The dollars are from the business side (bean counters) of things. o The numbers should be roughly equivalent, if you have the same priced engineers working as were initially planned. Then we can compute CPI = EV / AC = $4M / $4.8M = 0.833 This indicates that to date, it is costing us more than planned to produce the functionality of this system, in fact the project is 16.7% over cost. If EV and AC are measured in Engineer-Hours, we have an answer in Engineer-Hours. We can compute SPI = EV / PV = $4M / $5M = 0.8. This indicates that we are 20% behind schedule in developing this project. © 2012 Mike Rowe 9 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules If EV and PV are measured in Engineering-Hours, this tells us how the schedule has slipped by 20%. Estimate Final Cost and Completion Date: We can use the CPI and SPI to project total project cost and project completion, Estimated Actual Schedule and Estimated Actual Project Cost to complete this project. Estimated Actual Project Completion (EAPC) sometimes called Schedule Estimated Completion. EAPC = ( TotalScheduledDuration ) / SPI EAPC = ( 18months ) / 0.8 = 22.5 months Thus, we estimate that the actual completion date with no allowances for more or less resources will be 22.5 months compared to the original 18 month estimate. This is a slip of 4.5 months. The Estimated Actual Project Cost sometimes called Estimated Actual Cost (EAC) could then be calculated EAC = TotalEVin$ / CPI // Estimated Project Completion Date EAC = $8M / 0.833 = $9.6M Thus, our estimated total project cost will be $9.6 M rather than the original project cost of $8.0M. 3. Estimation That Works: How to Spot Bad Estimates and What to Do About Them From: http://spc-web.ktx002.com/0710/Estimation_atc.html How can you tell if you have a bad estimate? Following are the 5 most frequent scenarios we’ve encountered in recent projects. See if any of these are familiar in your organization. Scenario 1: You estimated very early in the project, and the estimate hasn’t changed since. Bad because: Early estimates are vague, optimistic, and don’t incorporate learning. Early estimates usually are based on only a vague understanding of the requirements, and so © 2012 Mike Rowe 10 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules don’t incorporate detail that comes to light later in the project. The potential downstream consequences of early estimates are significant (Chaos reports consistently confirm this fact). Equally important, this lack of focus tends to make the estimate overly optimistic without an accurate reflection of budgets and timelines. Finally, they don’t account for what is learned about the product and project details as work proceeds. Scenario 2: Your estimate is a [surprisingly] exact number. Bad because: The estimate can lead to incorrect assumptions and hurt credibility. You could be very good at estimating though! And there is nothing bad about being good ;-} Exact numbers often hide major early-stage flaws in the project. For example, management and customers believe you have much more certainty about how the project will proceed than you really do. Also, when issues arise (as they always do) your credibility takes a severe hit when project compromises need to be made. Scenario 3: Targets are dictated by management or the customer so the team doesn't estimate. Bad because: Critical risks aren’t exposed leading to blame and lower quality. The inherent risk in this scenario is that the target is not exposed - no one thinks about what it will really take to deliver the project. As a result, the development team implicitly takes this risk on as their own and are frequently blamed when targets are missed. Inevitably corners are cut, leading to functionality and quality shortfalls. Scenario 4: The estimate is much higher than management or the customer expected or was hoping for. Bad because: Stakeholders perceive failure leading to reactive behavior and conflict. This is a scenario we frequently encounter with client projects. A very high estimate translates to management/customer becoming upset because the project, as estimated, fails to meet their needs. This challenge comes from estimators failing to recognize the purpose for which the estimates were being prepared. A routine reaction is management/customer dictating their own (unrealistic) targets. Scenario 5: The team relies on guesswork instead of true estimation practices. Bad because: © 2012 Mike Rowe 11 1/31/2010 SE 386 Software Maintenance and Reengineering Notes 004- Estimation and Schedules Time is wasted, project expenses increase while team security decreases. This is a self-fulfilling prophecy that gets instigated by using guesswork instead of solid estimation practices. The consequence is the team being too busy dealing with the fallout of their bad estimates to find enough time to produce good ones. Or, they cope by padding the guesstimates by huge margins. Either way, projects come in much more expensively than they need to. In extreme situations, the development team risks being outsourced or disbanded. © 2012 Mike Rowe 12 1/31/2010