Recorded Crime Statistics - Central Statistics Office
advertisement

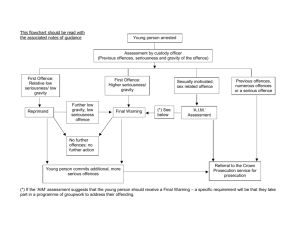
Crime Section, Central Statistics Office. The Crime Section would like to acknowledge the assistance provided by the Probation Service in this project. ◦ In particular, we would like to thank Michael Donnellan and Aidan Gormley. Connectivity between the various Criminal Justice Database Systems The Challenge - Absence of unique identifier The Solution – CSO statistical matching. Results of matching exercise Future Goals •Robust links between PULSE and CCTS. •Tenuous link between PULSE/CCTS and Probation •Need to make these links into strong links - but how? Common unique identifier allows rapid integration of datasets. The common identifiers between PULSE and CCTS include Charge No., Summons No. These are linked to the Person PULSE ID in PULSE, to allow linking by individual. Result: Able to produce statistics combining police and court outcome data. However, there is a problem.... No such common identifier between CCTS/PULSE and Probation Probation Service uses its own unique identifiers. No linking between this and PULSE identifiers such as Person PULSE ID and Court Outcome number. Cannot link the datasets and cannot produce statistics. But a solution exists: If persons in the separate systems can be matched across variables that exist in both systems: Then a table linking unique identifiers can be produced. Variables such as first name, surname, data of birth and address exist in both systems. These can be used to link the two systems. This is the basis of the CSO solution. The CSO received a test dataset from the Probation Service, for years 2007 and 2008. Over 8700 data orders with corresponding info. First, a manual matching exercise was carried out to test feasibility Matching by first name, surnames, addresses, dates of birth on over 7800 probation records. A random sample of 800 records It took 8.5 person-days to process this 10% sample. At this rate, it would have taken over90 days to process the entire dataset. The next step was to automate the matching process, for entire dataset. Fully automated matching solution – not really possible. A mixed-model method incorporating automatic and manual matching, to achieve 99% matching. 70% of matches were automatically matched, without human role. This match was on first name, surname and date of birth. Additional sorting/matching algorithms to simplify manual matching of remaining 28%. There were four additional stages, with progressively increasing human role. These were to identify cases where age or address data does not match, for example. Processes still mainly automated and algorithm based, so fast to process. The entire process was completed in 2manday. 99% of all the records (7,800+) matched. Compared to projected (90+ man days). Step one. Both datasets sorted by names, addresses and dates of birth. NB All datasets shown are merely representations, not actual data These are large datasets. Step Two. The probation and PULSE records are matched automatically by names and date of birth – using SAS. 70% of entries are matched automatically, this way. For each probation ID, the corresponding PULSE Ids are listed. People may have multiple PULSE Ids, for each probation ID. Step Three. The next step is to ensure that surnames with the prefix “O’” are recorded in the same manner in both datasets Step has minimal human involvement. One dataset records “O’ ” as “O” This is not detected or matched in initial stage This can be performed with an automatic software “Replace” function When the automatic matching (Step Two) is run again: Now 85% of records match automatically. Step Four ◦ The next step is to match on cases where the surname and date of birth match, first names are closely related: ◦ This step has more human involvement. Geographical info is used as a further check. This allows us to find aliases. ◦ Example shown here: It is clear that although “Liz” and “Elizabeth”, and “Alex” and “Lex” differ, they refer to same person. Ma tch Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes First Proba t. Fa ke N a me Fa ke ID PU LS E ID Proba tio Surna me D a te of Proba t. Birth Pr ZZ1522 ZZ1522 ZZ1522 ZZ1522 ZZ1522 ZM1533 ZM1533 ZM1533 ZM1533 ZM1533 ZM1533 Great Great Great Great Great Tudor Tudor Tudor Tudor Tudor Tudor 2085343 2085343 2085345 2085345 2085345 1085389 1085389 1085389 1085391 1085391 1085391 Alex Alex Alex Alex Alex Liz Liz Liz Liz Liz Liz First Le tte r 01/01/1982 A 01/01/1982 A 01/01/1982 A 01/01/1982 A 01/01/1982 A 01/01/1900 L 01/01/1900 L 01/01/1900 L 01/01/1900 L 01/01/1900 L 01/01/1900 L First N a me PU LS E Surna me D a te of Addre ss Line 1 Addre ss Line PU LS E Birth PU L Prob 1 PU LS E Addre ss Line Addre ss Line 2 2 Prob PU LS E Alexander Alexander Lex Lex Lex Elizabeth Elizabeth Elizabeth Elizabeth Elizabeth Elizabeth Great Great Great Great Great Tudor Tudor Tudor Tudor Tudor Tudor 06/06/1982 Royal Palace 06/06/1982 Royal Palace 06/06/1982 Royal Palace 06/06/1982 Royal Palace 06/06/1982 Royal Palace Royal Palace Royal Palace On Campaign On Campaign On Campaign Macedon Macedon Macedon Macedon Macedon Macedon Macedon Macedon Macedon Macedon 30/01/1986 Raleighs 30/01/1986 Raleighs 30/01/1986 Raleighs 30/01/1986 Raleighs 30/01/1986 Raleighs 30/01/1986 Raleighs Raleighs Raleighs Raleighs Raleighs Raleighs Raleighs Essex Essex Essex Essex Essex Essex Essex Essex Essex Essex Essex Essex Step Five. ◦ Additional matching steps are then carried out. One is to check for matching first names, surnames and geographical info, but where dates of birth differ. Special checks can identify matching cases here. ◦ Another set of checks involves searching for matching first name, date of birth but slightly different surnames. All these steps lead to match of over 95%. The final step is a fully manual operation to match the remaining 5% The CSO produced detailed results from this linkage. Tables were produced showing: Number of subsequent First Offices (recidivism), during the period 2008-11, by individuals with probation orders issued in 2007-08 Table B: Subsequent First Offences (recidivism), during the period 2008-11, by individuals with probation orders issued in 2007-08, as percentage of the Original Primary Offence Table C: Subsequent First Offence (recidivism) by individuals, during the period 2008-11, with probation orders issued in 200708 as a percentage of total original primary offences Table D: Subsequent First Offence (recidivism) during the period 2008-11 of individuals with probation orders issued in 2007-08 as a % of total subsequent First Offences Unfortunately, we can show only sample data here. Table A: Number of subsequent First Offices (recidivism), during the period 2008-11, by individuals with probation orders issued in 2007-08 Original Primary Offence Subsequent First Offence Group 01 Group 02 Group 03 Group 04 Group 05 Group 06 Group 07 Group 08 Group 09 Group 10 Group 11 Group 12 Group 13 Group 14 Group 15 Group 1 Homicide offences Sexual Offences Assaults, Attempts and Threats to Murder, Harassment and Related Offences Dangerous and Negligent Acts Kidnapping and Related Offences Robbery and Related offences Burglary and Related Offences Theft and Related Offences Fraud and Related offences Drug offences Weapons and Explosive s Offences Crimes against Property Public Order Offences Road Traffic Offences Offences against Justice Miscellane Offence N N N N N N N N N N N N N N N Total Offence N N 01 Homicide Offences 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 02 Sexual Offences 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 03 Attempts/Threats to Murder, Assaults, Harassments and Related offences 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 04 Dangerous or Negligent Acts 05 Kidnapping and Related Offences 06 Robbery, Extortion and Hijacking Offences 07 Burglary and Related Offences 08 Theft and Related Offences 09 Fraud, Deception and Related Offences 10 Controlled Drug Offences 11 Weapons and Explosives Offences 12 Damage to Property and to the Environment 13 Pubilc Order and other Social Code Offences 14 Road and Traffic Offences (n.e.c.) 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 15 Offences against Government , Justice Procedures and Organisation of Crime 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 Offences Not Elsewhere Classified 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 99 Not Stated Total Table D: Subsequent First Offence (recidivism) during the period 2008-11 of individuals with probation orders issued in 2007-08 as a % of total subsequent First Offences, Original Primary Offence Subsequent First Offence Group 01 Group 02 Group 03 Group 04 Group 05 Group 06 Group 07 Group 08 Group 09 Group 10 Group 11 Group 12 Group 13 Group 14 Group 15 Group 16 Homicide offences Sexual Offences Assaults, Attempts and Threats to Murder, Harassment and Related Offences Dangerous and Negligent Acts Kidnapping and Related Offences Robbery and Related offences Burglary and Related Offences Theft and Related Offences Fraud and Related offences Drug offences Weapons and Explosives Offences Crimes against Property Public Order Offences Road Traffic Offences Offences against Justice Miscellaneous Offences N N N N N N N N N N N N N N Offence Total N N 01 Homicide Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 02 Sexual Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 03 Attempts/Threats to Murder, Assaults, Harassments and Related offences N 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 04 Dangerous or Negligent Acts 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 05 Kidnapping and Related Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 06 Robbery, Extortion and Hijacking Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 07 Burglary and Related Offences 08 Theft and Related Offences 09 Fraud, Deception and Related Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 10 Controlled Drug Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 11 Weapons and Explosives Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 12 Damage to Property and to the Environment 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 13 Pubilc Order and other Social Code Offences 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 14 Road and Traffic Offences (n.e.c.) 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 15 Offences against Government , Justice Procedures and Organisation of Crime 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 16 Offences Not Elsewhere Classified 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 99 Not Stated 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% Total 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% Further development of matching model. To incorporate text analysis, fuzzy matching. To develop a fully automatic process to match to 99%. This project shows a simple, effective solution to integrating datasets in the absence of a common identifier. This project doesn’t invalidate the importance of development of unique identifiers. ◦ But it does allow matching of records where it is not feasible to retroactively apply any planned common identifier. This method is not limited to Criminal Justice Administrative Data. ◦ It can be applied to any datasets with common information on names, dates of birth etc.