Overview of ISR, Part 3
advertisement

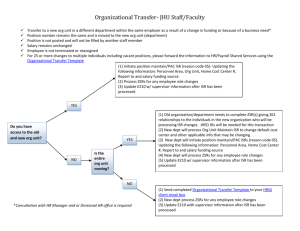
LIS 386.13 Information Technologies and the Information Professions Overview of Information Storage and Retrieval, Part 3 R. E. Wyllys Copyright © 2000 by R. E. Wyllys Last revised 2002 Dec 13 School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s • The first commercially built computer was the UNIVAC I (Universal Automatic Computer). – UNIVAC I performed about 1,000 calculations per second. It used 5,000 vacuum tubes and weighed 8 tons (7,300kg). – The first UNIVAC I was delivered to the U.S. cryptologic agency in 1950; the second was delivered to the Census Bureau in 1951. – The first commercial purchase of the UNIVAC I was in 1954 by the General Electric Company, which used it to prepare payrolls. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s • Other 1950s developments in ISR included – Increasing use of Boolean logic in searches for InBEs relevant to an inquiry – Aperture cards – Optical-coincidence cards – Edge-notched cards – KWIC indexing – Automated indexing and abstracting – The first formal course in information storage and retrieval, held in 1959 School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Example of Boolean Retrieval Using Punched Cards • Boolean logic had been used since the 1930s in searches for InBEs relevant to an inquiry. • Here is an example of Boolean retrieval via punched cards: – Given an InBE, one can prepare a set of punched cards each of which contains an identifier of the InBE and, in a specific field (i.e., set of, say, 4 columns), a series of 4-character codes for retrieval tags associated with the InBE. – I.e., suppose we have an InBE identified by the title "Effects of molecule X on disease Y". School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Example of Boolean Retrieval Using Punched Cards – We punch the title into columns 1-50 of a card (we truncate long titles if necessary) and then punch code 1048 into cols. 51-54 to represent the first retrieval tag associated with the InBE. – Next, we duplicate the first 50 columns of the card into a second card, and into its cols. 51-54 we punch 2236 representing the second tag. – Similarly, we prepare a third card and punch code 4216 into its cols. 51-54, and then a fourth card, with code 8957, for the third and fourth retrieval tags associated with the InBE. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Example of Boolean Retrieval Using Punched Cards – Next, suppose we have a second InBE identified by the title "Experimental treatment of disease Y" and that this InBE shares with the first InBE retrieval tags coded as 2236 and 8957. – We prepare an analogous set of punched cards for the second InBE. – Now, suppose we have a card tray filled with a number of sets of cards. • Suppose further that the tray includes not only the sets for the two documents mentioned above, but also sets of cards for other InBEs • Suppose, still further, that none of these other InBEs happen to have both tags 2236 and 8957 associated with them, but that some of them are associated with one or the other of these tags. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Example of Boolean Retrieval Using Punched Cards – To find those InBEs in our collection that have either tag 2236 and 8957 associated with them, we run cards in the tray through a card sorter. • We do the sorter runs in such a way we wind up with, in one bin, just those cards that contain 2236 in cols. 51-54; in a second bin, just those cards with 8957; and in a third bin, all other cards. – Note: This actually requires several passes through the sorter, but the final result can be as stated. • Such a series of sorter runs will yield a set of cards representing InBEs that have either tag 2236 or tag 8957 associated with them. This constitutes an OR operation in Boolean terms. • Sorting the tray so as to yield a set of cards representing InBEs that have both tag 2236 and tag 8957 is more complicated (and more tedious), but can be done; i.e., AND operations can be accomplished via sorting. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Aperture Cards • Aperture cards were punched cards with curved tabs in the right-hand third of the card arranged so that a piece of 35mm film, containing one image, could be inserted in, and be held by, the tabs. – In the left two-thirds of the card, one could punch codes for identifying the image and codes representing retrieval tags associated with the image. – In some aperture-card systems, the film pieces were glued in place. • A successful major ISR system using millions of aperture cards was Project WALNUT, developed by IBM in the late 1950s and early 1960s at the Central Intelligence Agency Library, at the instigation of the Library's director, Joseph Becker (1923-1995). School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Aperture Cards An aperture card School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Optical-Coincidence Cards • Optical-coincidence cards (also called "peek-a-boo" cards) were sheets of opaque plastic (typically 81/2"x11" in size). – Each 8-1/2"x11" card provided space for a 100x100 matrix of 10,000 positions in which small holes could be drilled using precise positioning of the drill. (Some systems used larger sheets that could accommodate a 200x200 matrix, with 40,000 positions.) – Both rows and columns were numbered from 00 to 99. A hole drilled at the intersection of row 37 and column 25 would represent the number 3725. • Each card represented a retrieval tag: e.g., there might be one card for the term "dog" and another for the term "cat". School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Optical-Coincidence Cards • InBEs in a collection were represented by 4digit numbers (or 6-digit numbers in the systems that used a 200x200 matrix of holes). – Suppose newly arrived InBE 4351 contained information on both dogs and cats. Then the card for dogs and the card for cats would be placed on the drilling stand, and a hole would be drilled in those cards at the intersection of row 43 and column 51. • Note that the dog card would already have other holes, representing other InBEs in the collection that contained information about dogs; and similarly for the cat card. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Optical-Coincidence Cards • To find InBEs in the collection that contained information about dogs, a user needed only to place the dog card on a back-lighted viewing stand and note the numbers (from the row and column numbers) of illuminated holes. Each such pair of numbers identified an InBE relevant to dogs. • To find InBEs relevant to both dogs and cats, the dog and cat cards were placed on top of each other on the viewing stand. The illuminated holes represented InBEs relevant to both dogs and cats (in Boolean terms, dogs AND cats). • An inquiry concerning dogs OR cats would be satisfied by the union of the set of numbers drilled in the dog car and the set of numbers drilled in the cat card. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Edge-Notched Cards • Edge-notched cards were invented by Calvin Mooers (1919-1994). The cards were like punched cards in thickness and stiffness. They came in many sizes, but the 4"x6" size (c. 100mm x 150mm) was quite popular because that size was popular for general filing and hence equipment for storing the cards was easy to obtain. – Around the edges of an edge-notched card were small holes, about 1/16" (1.6mm) in diameter, pre-punched about 1/8" (3.2mm) apart and about 1/4" (6.4mm) in from the edge. The holes were identified from left to right along each edge by numbers in succession. • Each card represented an InBE, and identifying information about the InBE could be typed or written in the interior of the card. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Edge-Notched Cards • Regions could be defined around the edges of the cards. – Suppose that you wanted to choose a region in which to code names of authors of InBEs. Suppose also that you were confident that your collection was unlikely ever to need more than 4,096 = 212 different author names. – Then you could decide to use the first 1-1/2" of the top edge to represent authors' names, thus providing 12 hole positions for the representation. – Potentially, each hole could be used or not used in the representation, so that a total of 212 different patterns would be available for authors' names. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Edge-Notched Cards • Given a set of author names, you would code them using randomly chosen numbers from 0 to 4,096. – You would convert each author number into its binary equivalent. – For each InBE in your collection by a given author, you would use a special punch to cut a V-shaped notch from the hole to the edge of the card, in each position in the author region that corresponded to a 1 in the binary number of the author of the InBE. • For example, author 221210 = 1000101001002 would be represented by notches in the 1st, 5th, 7th, and 10th positions in the region. – The random choice of author numbers would help to distribute the notches over the whole set of 12 positions. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Edge-Notched Cards • How would you identify all the InBEs in your collection written by the author whose name is coded by 2212? – You would place the entire set of edge-notched cards representing your collection in a tray and align them. Then you would insert a sorting needle (like a thin steel knitting needle with a handle) into the 1st position at the top left of the cards, lift up the set, and allow the cards with a notch in that 1st position to drop out of the set. – Next, you would take the set of cards that had thus dropped out, align them in the tray, and then insert the sorting needle in the 5th position and again lift up. A further set of cards would drop out. – You repeat the operations again for each position corresponding to a 1 in the binary representation of author 2212. The final set of cards that drop out will be those representing InBEs whose author number is 2212. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Edge-Notched Cards • Similar procedures worked for any kind of retrieval tag that a user wanted to employ in his or her collection of InBEs. • Edge-notched card systems worked well for small collections, and the costs were very small. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s KWIC Indexing • KWIC stands for "KeyWord In Context". • KWIC indexing could be performed by EAM alone, although it was not till 1957 that Herbert Ohlman (19272002) invented it. – In KWIC indexing, the title of each InBE in a collection is punched into a punched card. – Then the cards are processed by EAMs in such a way for each title, a set of cards is produced. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s KWIC Indexing • In the set of cards for a KWIC Index for a given title – The first card holds the title in its original form – The second card holds the title, but the title begins with the second word in the original title, and the first word in the title appears at the end of the title. – The third card holds the title beginning with the third word in the original title, and the first two words appear at the end of the title. – In this fashion, every word in the title appears in the first position on some card in the set. The words in the title are cycled, or permuted, through all possible positions. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s KWIC Indexing • The sets of cards containing the permuted titles for InBEs in a collection were then sorted, usually employing the center position for alphabetization of the titles, and printed out. • Ohlman called the technique “Permuterm Indexing” or “Permuted Title Indexing.” The name “KWIC Indexing” was coined by H. P. Luhn (about whom more will be said shortly). School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s KWIC Indexing • An example of a KWIC index. – Suppose we have 2 titles to be processed: • Understanding Computers and Cognition • In the Age of the Smart Machine – The KWIC index for these titles is shown in the next slide. • You can see that each word in both titles appears somewhere in the list of permuted forms of the titles. • In the KWIC index for a large number of titles, it is easy to move down the alphabetized center to the places where any given word you might be seeking will appear. • Note that when you find a desired word, you also have a context for that word. This is the reason for the name, KWIC, for this manner of displaying titles. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s KWIC Indexing IN THE UNDERSTANDING COMPUTERS COMPUTERS AND COGNITION UNDERSTANDING SMART MACHINE THE SMART THE AGE OF THE MACHINE IN AGE OF AND COGNITION AGE OF THE SMART MACHINE AND COGNITION COGNITION UNDERSTANDING COMPUTERS AND IN THE AGE OF THE MACHINE IN THE AGE OF OF THE SMART MACHINE IN SMART MACHINE IN THE AGE THE AGE OF THE SMART THE SMART MACHINE IN THE UNDERSTANDING COMPUTERS School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Automated Indexing and Abstracting • Automated indexing and abstracting were techniques invented by an ISR pioneer, Hans Peter Luhn (1896-1964) of IBM, in 1958. – An automated index for an InBE consists of a set of index terms (i.e., subject-related retrieval tags) determined in the following way. • The frequencies of all the different words appearing in the InBE are counted, and the words are arranged in decreasing order of frequency. • "Function" words in a checklist (i.e., words having only syntactic, not semantic, significance, such as "and", "the", "of", "is", "are") are deleted. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Automated Indexing and Abstracting • The first ni words (i.e., the ni highestfrequency words) remaining after the deletion of the function words (where ni is the desired size of the set of index terms) are used to form the set of index terms for the InBE. – Luhn's rationale was two-fold: • The highest-frequency content words (i.e., non-function words) would be words likely related to the subject content of the InBE. • All the operations described could be performed programmatically, i.e., by a computer without human intervention, so that sets of index terms for InBEs could be produced quickly and easily without human effort. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s Automated Indexing and Abstracting • Luhn constructed automated abstracts in an analogous fashion. – An automated index (i.e, set of index terms or retrieval tags) having been determined for an InBE, a program then counted the numbers of index terms in each sentence in the InBE. – The na sentences with highest numbers of index terms (where na is the desired number of sentences in the abstract) are displayed, or printed out, in the order of their occurrence in the InBE, to constitute an automated abstract. – Again, Luhn's rationale was that sentences containing a high number of index terms would likely express key ideas within the overall structure of the InBE. • Automated indexes tended to be reasonably adequate sets of retrieval tags for their InBEs, but automated abstracts tended to be disappointing as condensed representations of their InBEs' content. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s First Formal Course in ISR • In September 1959 the first formal course anywhere dealing with ISR was held at UCLA. The 2-week workshop was developed and taught by two ISR pioneers, Joseph Becker and Robert M. Hayes (1926- ). – Becker was then the head of the CIA Library (a library whose funding, resources, and degree of automation were the envy of many librarians in the 1950s and 1960s). His Project WALNUT has already been mentioned. After retiring from the CIA, Becker spent many years as an ISR consultant. – Hayes was then the head of a research project for Magnavox Corporation aimed at developing magnetic cards whose density was remarkably high for the time, and whose purpose was to provide an easily sortable store of text and/or numeric information. Hayes later served on the faculty, and as the Dean, of the UCLA Graduate School of Library and Information Science. – A personal note: I had the privilege of attending the Hayes and Becker course and learned much from it. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1950s First Formal Course in ISR Robert M. Hayes School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s • The 1960s saw a rapid increase in the number of computers using transistors, which provided great increases in speed and dramatic reductions in size compared with vacuum-tube-based computers. The decade also saw the invention of the integrated circuit, which was to bring about an even more dramatic reduction in size and increase in speed. • In the 1960s, after a decade of disappointing results, machine translation (MT) lost much of its allure as a field of application of computers to textual data. Artificial intelligence (AI), i.e., computer programs imitating the human brain, replaced MT as the most glamorous field for computer research in areas related to natural language. – As with MT, initial forecasts of the prospects of AI turned out to be wildly over-optimistic. Only within the last decade has AI really begun to deliver substantial results. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s • The HARVEST project, sponsored by the National Security Agency (NSA) and carried out by IBM starting in 1961, built the first cassette-tape storage units for computer use; computer tapes had been only reel-to-reel tapes prior to this project. – The HARVEST cassettes were massive units about 1'x3'x3" (30x90x8cm). They used magnetic tape that was 2" (5cm) wide and of extremely high density for the time. – Dozens of cassettes could be searched simultaneously – Automated handling equipment could remove and replace cassettes far faster than reel-to-reel tapes could be loaded. • Note: This seems unremarkable nowadays, but it was a major step forward in computer technology in 1961. – The project engineer for NSA was Samuel Snyder. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s • In the early 1960s, H. P. Luhn developed the first optical storage unit for computers, the glass disk. It held about 1M bytes--a very large memory store at the time--and was intended to hold bilingual dictionaries for machine translation. • In 1961 Eugene Garfield (1925- ) began publishing the Science Citation Index (SCI), the first such index. Garfield's company now publishes citation indexes in several other fields in addition to SCI. – In citation indexing, an InBE is provided with retrieval tags consisting of the citations to that InBE made in other InBEs. – The citations in an InBE reflect the judgment of the author(s) about what other InBEs deal with related matters. – Thus a citation index provides a network of links among InBEs based on the citations found in the InBEs themselves and incorporating human judgment; yet the citation index itself can be prepared entirely programmatically. – Networks formed by citation links are an interesting analog to, and precursor of, hyperlinks as implemented in the World-Wide Web. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s • In 1963, Hayes and Becker published the first book on ISR, based on their course in ISR. • Also in 1963, the Library of Congress (LC) established its Information Systems Division (ISD) to begin automating LC. – One of the first ISD efforts was Project MARC (Machine-Readable Cataloging), whose goal was to develop computer-based tools for disseminating LC catalog-card information. – Project MARC's initial proposal for a computer format for catalogcard information was tested in a pilot project during 1966-1968. – On the basis of what was learned in the pilot project, in 1969 LC published the MARC II format. The current format, MARC 21, is essentially MARC II plus some added features. – The first head of ISD was Samuel Snyder, who had just retired from NSA. When he retired again in 1966, this time from LC, Henriette D. Avram (1919- ), also a former NSA employee, replaced him as the head of Project MARC; she retired from that post in 1992. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s • In 1965 Gerard Salton (1927-1995) initiated his SMART Project at Cornell University. – Under Salton, SMART served as an important test vehicle and source of new ideas in ISR techniques for over 30 years. The project has continued even after Salton's death. – A key tool in SMART was the use in retrieval of thesauri of related terms. The thesauri could be developed programmatically and could evolve dynamically as the collection of InBEs grew. – "Many well-known information retrieval concepts were introduced as a result of SMART, including the vector space model, sophisticated statistical term weighting schemes that distinguish concepts important for text representation from other more marginal concepts, and the relevance feedback technique for query optimization."* – Salton has been called the father of relevance-ranking in retrieval procedures. *From Computing Research News Online, November 1995. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s Precision and Recall • In 1965-1966, Cyril W. Cleverdon (1913-1997), Karen SparckJones, F. Wilfrid Lancaster, and others at Cranfield University (in Cranfield, UK) conducted under the sponsorship of ASLIB a pioneering research effort in retrieval that defined, and explored the use of, the concepts of precision and recall. – The research project has come to be known as the ASLIBCranfield experiments. • What are precision and recall? – Suppose we have a collection of InBEs and apply to the collection a retrieval request that yields a set of InBEs. We can call this the "response set". – In general, some of the InBEs in the response set will be relevant to the retrieval request and others will be irrelevant (the latter are often called "false drops"). – Also in general, there will be some InBEs in the collection that are actually relevant to the retrieval request but are missed, i.e., fail to be among the InBEs in the response set. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s Precision and Recall • Using the foregoing observations about the InBEs in the response set, we can define the following numbers. We let Rr = the number of relevant InBEs retrieved Tr = the total number of InBEs retrieved Rc = the total number of relevant InBEs in the collection • Then we can define precision and recall as Precision = Rr/Tr ; i.e., (relevant retrieved)/(total retrieved) Recall = Rr/Rc ; i.e., (relevant retrieved)/(total relevant) • We can re-state these ideas as follows. – Precision measures how good the system is at returning mainly InBEs that are relevant, with few false drops. – Recall measures how good the system is at retrieving all the relevant InBEs in the collection. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s Precision and Recall • In general, high values of recall tend to occur along with low values of precision, and vice versa. • Note that there can be problems in deciding whether an InBE should be deemed relevant to an inquiry. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s • In 1966 Carlos A. Cuadra (1925- ) created the Annual Review of Information Science and Technology (ARIST). – The ARIST series is still being published annually and continues to be an indispensable reference and source of information about the state-of-the-art in ISR. A number of chapters over the years have been authored by UT-Austin GSLIS faculty members and one chapter by a GSLIS doctoral student. – Cuadra served as the editor of ARIST for 10 years before turning the job over to others. – Cuadra later established one of the earliest online search services, SDC Search. He is still active in ISR as head of Cuadra Associates, which programs and sells sophisticated information-management systems, including the STAR series of programs used by libraries, archives, and records centers. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1960s • During 1963-1968, Douglas C. Engelbart (1925- ) and his team of co-workers at the Stanford Research Institute originated some now commonplace but then remarkable concepts. – They developed the first graphic user interface (GUI) for a computer. – They invented the now indispensable computer mouse, along with the concept of pointing and clicking to activate computer programs represented by an icon on a computer's display screen. • A wealth of information about what Engelbart and his team accomplished is available via the following URL: http://sloan.stanford.edu/mousesite/MouseSitePg1.html – Streaming video views of a public demonstration in 1968 by the Engelbart team of the mouse and other ideas they had developed are available at: http://sloan.stanford.edu/mousesite/1968Demo.html School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1970s • By the early 1970s, Douglas Engelbart and his team (by then working at the Palo Alto Research Center of Xerox Corporation [Xerox PARC]) had put together the first system that could be called a desktop or personal computer. – As has been noted repeatedly in histories of computers, Xerox Corporation thus had the opportunity to be the first company to put a desktop computer on the market. However, Xerox's directors failed to see the commercial potential of what Engelbart's team had developed. • Engelbart continues to be active in ISR, as head of the Bootstrap Institute in Fremont, California. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1970s • Xerox having declined to market a desktop computer, the field was left open for others. • In 1975, the MITS (Micro Instrumentation Telemetry Systems) Company, in Albuquerque, NM, marketed the first personal computer, the Altair 8800. – The Altair 8800 was sold as a kit via ads in such journals as Popular Mechanics. Input was via switches on the front panel, and output consisted of front panel lights that would be set on "on" or "off" according the result to be displayed. • Bill Gates and Paul Allen, the founders of Microsoft, worked briefly as programmers for MITS. • Apple is the best known of the personal computers that entered the marketplace in the late 1970s. – Other personal computers of that era included Commodore, Kaypro, and Osborne. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1980s-1990s • In the 1980s and 1990s things started moving so fast in the area of ISR and computers that in this presentation we shall merely mention trends and a few examples. • High-reduction microimages were a feature of the the early part of this period, when they were handled by highquality optics and high-resolution films. – By the 1990s it was apparent that film-based systems were going to be largely supplanted by digitized images, and much attention was being devoted to developing ever more powerful digitalcompression techniques. – Digitized images, with their large numbers of bytes, helped foster the rapid development of ever more capacious storage devices, and rapid decreases in the costs of storage helped these devices sell well. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1980s-1990s • The IBM PC came on the market in 1980. Because IBM made specifications readily available to manufacturers of peripheral equipment, the cost of hardware for PCs quickly became less than that for Apple's desktop computers. Hence, Apple lost market share to IBM PCs and their clones despite the initial superiority of the Macintosh in 1983. • At the high end of the desktop computer market, machines made by such firms as Alpha, Sun, and Silicon Graphics served an audience (e.g., LucasFilms) for which neither the PC nor the Macintosh was powerful enough. • The proliferation of powerful desktop computers supported a broad market for office-related and professional tools such as wordprocessors, spreadsheets, relational database managers, and graphics and presentation software. Prices trended downwards rapidly as the customer base grew larger and larger. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1980s-1990s • Medium and large public and academic libraries, and special libraries of all sizes, adopted OPACs (online public-access catalogs) replacing card catalogs either completely or at least for new acquisitions. • Library schools became schools of library and information science. • Online retrieval services such as Dialog, Lexis-Nexis, Dow Jones, and CompuServe, many of which had started in the 1970s, flourished in the 1980s and 1990s. • Most spectacular of all has been the development of the World-Wide Web. As a practical matter, the Web can be said to have been born in January 1993, when the first Web browser, Mosaic, was released for public use by the University of Illinois, where a group of students headed by Marc Andreesen had written it. (Shortly afterwards, Andreesen helped to found Netscape.) School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 1980s-1990s • All that we think of as the Web today has developed in the relatively brief period since January 1993! School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Highlights of ISR History: 2000+ • What will the future bring for ISR? – A completely safe prediction is that increases in the size of data stores and in the speeds of computers and telecommunications, i.e., increases that we can foresee, will bring many changes that we cannot foresee. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Sources for ISR History • An interesting source of information on people involved in the history of ISR in the 20th century and later is the Pioneers of Information Science in North America project, originated by Dr. Robert V. Williams of the College of Librarianship and Information Science, University of South Carolina. School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Sources for ISR History (cont’d) • Three recent issues of the Journal of the American Society for Information Science (JASIS) were devoted to the history of ISR and contain many excellent articles: – Buckland, M.; Hahn, T. D., eds. Special Topic Issue: History of Documentation and Information Science, Part I. JASIS 48(4) (April 1997): 285-379 – Buckland, M.; Hahn, T. D., eds. Special Topic Issue: History of Documentation and Information Science, Part II. JASIS 48(9) (September 1997): 773-859 – Bates, M. J., ed. Paradigms, Models, and Methods of Information Science. JASIS 50(12) (October 1999): 1043-1162 School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Request for Corrections, Suggestions for Additions, and Comments • Corrections to this overview, suggestions for additions (topics and, especially, images of people and/or concepts mentioned herein), and comments in general will be very much welcomed. • Please send them to me at wyllys@ischool.utexas.edu School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions Overview of Information Storage and Retrieval • This concludes Part 3 of this overview of ISR. • You may click below to go to – Part 1 – Part 2 School of Information - The University of Texas at Austin LIS 386.13, Information Technologies & the Information Professions