L15_MinimumSpanningT..
advertisement

COMMONWEALTH OF AUSTRALIA
Copyright Regulations 1969
WARNING
This material has been reproduced and communicated to
you by or on behalf of Monash University pursuant to
Part VB of the Copyright Act 1968 (the Act). The material
in this communication may be subject to copyright under
the Act. Any further reproduction or communication of
this material by you may be the subject of copyright
protection under the Act. Do not remove this notice.
www.monash.edu.au
1
prepared from lecture material © 2004 Goodrich & Tamassia
Prepared by:
Bernd Meyer from lecture materials © 2004 Goodrich & Tamassia
March 2007
FIT2004
Algorithms & Data Structures
L15: Minimum Spanning Trees
www.monash.edu.au
Minimum Spanning Trees (Goodrich & Tamassia § 12.7)
Spanning subgraph
– Subgraph of a graph G
ORD
1
containing all the vertices of G
Spanning tree
– Spanning subgraph that is
itself a (free) tree
Minimum spanning tree (MST)
– Spanning tree of a weighted
graph with minimum total edge
weight
•
Applications
– Communications networks
10
DEN
PIT
9
6
STL
4
8
DFW
7
3
DCA
5
2
ATL
– Transportation networks
www.monash.edu.au
3
prepared from lecture material © 2004 Goodrich & Tamassia
Cycle Property
Cycle Property:
– Let T be a minimum
spanning tree of a
weighted graph G
– Let e be an edge of G that
is not in T and let C be the
cycle formed by e with T
– For every edge f of C,
weight(f) weight(e)
Proof:
– By contradiction
– If weight(f) > weight(e) we
can get a spanning tree of
smaller weight by
replacing e with f
f
2
6
8
C
9
3
8
4
e
7
7
Replacing f with e yields
a better spanning tree
f
2
6
8
C
9
3
8
4
e
7
7
www.monash.edu.au
4
prepared from lecture material © 2004 Goodrich & Tamassia
Partition Property
U
Partition Property:
– Consider a partition of the vertices of G into
subsets U and V
– Let e be an edge of minimum weight across
the partition
– There is a minimum spanning tree of G
containing edge e
Proof:
– Let T be an MST of G
– If T does not contain e, consider the cycle C
formed by e with T and let f be an edge of C
across the partition
– By the cycle property,
weight(f) weight(e)
– Thus, weight(f) = weight(e)
– We obtain another MST by replacing f with e
V
f 7
9
8
5
2
8
4
3
e
7
Replacing f with e yields
another MST
U
2
V
f 7
9
8
5
8
e
4
3
7
www.monash.edu.au
5
prepared from lecture material © 2004 Goodrich & Tamassia
How to compute a MCST
Try to apply an inductive approach
-
what does the induction run over?
-
what is the base case?
-
what is the induction hypothesis?
-
can you prove it?
www.monash.edu.au
6
prepared from lecture material © 2004 Goodrich & Tamassia
How to compute a MCST
Three basic ideas:
1.
Kruskal’s Algorithm: start with no edges and successively add edges in
order of increasing cost (making sure that we don’t insert edges that create
cycles)
2.
Prim’s algorithm: start with any node and iteratively grow a tree from it. At
each step add the node (and associated edge) that is the cheapest
extension to the tree
3.
Reverse Deletion Algorithm: start with the full graph and delete edges in
order of decreasing cost (making sure that we don’t disconnect the graph)
Note that all of these are greedy approaches !
Why do they work?
www.monash.edu.au
7
prepared from lecture material © 2004 Goodrich & Tamassia
Kruskal’s Algorithm
A priority queue stores
the edges outside the
cloud
Key: weight
Element: edge
At the end of the
algorithm
We are left with one
cloud that encompasses
the MST
A tree T which is our
MST
Algorithm KruskalMST(G)
for each vertex V in G do
define a Cloud(v) {v}
let Q be a priority queue.
Insert all edges into Q using their
weights as the key
T
while T has fewer than n-1 edges do
edge e = Q.removeMin()
Let u, v be the endpoints of e
if Cloud(v) Cloud(u) then
Add edge e to T
Merge Cloud(v) and Cloud(u)
return T
www.monash.edu.au
8
prepared from lecture material © 2004 Goodrich & Tamassia
Kruskal Example
www.monash.edu.au
9
prepared from lecture material © 2004 Goodrich & Tamassia
Data Structure for Kruskal Algortihm
• The algorithm maintains a forest of trees
• An edge is accepted it if connects distinct trees
• We need a data structure that maintains a partition, i.e., a
collection of disjoint sets, with the operations:
-find(u): return the set storing u
-union(u,v): replace the sets storing u and v with their
union
www.monash.edu.au
10
prepared from lecture material © 2004 Goodrich & Tamassia
List-based Partition Implementation
• Each set is stored in a sequence represented
with a linked-list
• Each node should store an object containing
the element and a reference to the set name
www.monash.edu.au
11
prepared from lecture material © 2004 Goodrich & Tamassia
Runtime of union/find
• Each set is stored in a sequence
• Each element has a reference back to the set
– operation find(u) takes O(1) time, and returns the set
of which u is a member.
– in operation union(u,v), we move the elements of the
smaller set to the sequence of the larger set and
update their references
– the time for operation union(u,v) is min(nu,nv), where
nu and nv are the sizes of the sets storing u and v
• Whenever an element is processed, it goes into a set
of size at least double, hence each element is
processed at most log n times
www.monash.edu.au
12
prepared from lecture material © 2004 Goodrich & Tamassia
Partition-Based Implementation
A partition-based version of Kruskal’s Algorithm performs
cloud merges as unions and tests as finds.
Algorithm Kruskal(G):
Input: A weighted graph G.
Output: An MST T for G.
Let P be a partition of the vertices of G, where each vertex forms a separate set.
Let Q be a priority queue storing the edges of G, sorted by their weights
Let T be an initially-empty tree
while Q is not empty do
(u,v) Q.removeMinElement()
if P.find(u) != P.find(v) then
Running time:
Add (u,v) to T
O((n+m)log n)
P.union(u,v)
return T
www.monash.edu.au
13
prepared from lecture material © 2004 Goodrich & Tamassia
Prim-Jarnik’s Algorithm
• Similar to Dijkstra’s algorithm (for a connected graph)
• We pick an arbitrary vertex s and we grow the MST as a cloud
of vertices, starting from s
• We store with each vertex v a label d(v) = the smallest weight of
an edge connecting v to a vertex in the cloud
At each step:
We add to the cloud the
vertex u outside the cloud
with the smallest distance
label
We update the labels of the
vertices adjacent to u
www.monash.edu.au
14
prepared from lecture material © 2004 Goodrich & Tamassia
Prim-Jarnik’s Algorithm (cont.)
•
A priority queue stores the
vertices outside the cloud
– Key: distance
– Element: vertex
•
Priority queue should be
implemented with a little
trick: Locator-based. Each
element keeps a pointer
(index, locator) to its position
in the queue. This allows to
use replacekey without
having to search the queue.
•
We store three labels with
each vertex:
– Distance
– Parent edge in MST
– Locator in priority queue
Algorithm PrimJarnikMST(G)
Q new heap-based priority queue
s a vertex of G
for all v vertices(G)
if v = s
setDistance(v, 0)
else
setDistance(v, )
setParent(v, )
l insert(Q, getDistance(v), v)
while isEmpty(Q)
u min(Q); Q removeMin(Q)
for all e incidentEdges(G, u)
z opposite(G,u,e)
r weight(e)
if r < getDistance(z)
setDistance(z,r)
setParent(z,e)
replaceKey(Q,z,r)
www.monash.edu.au
15
prepared from lecture material © 2004 Goodrich & Tamassia
Example
2
B
0
2
2
B
5
C
5
0
A
7
4
9
5
C
5
2
0
F
8
E
7
7
2
4
F
8
7
B
8
7
9
8
A
D
7
D
7
3
E
7
2
F
8
8
A
4
9
8
C
5
2
D
7
E
2
3
7
B
0
3
7
7
4
9
5
C
5
F 4
8
8
A
D
7
7
E
3
7
www.monash.edu.au
16
prepared from lecture material © 2004 Goodrich & Tamassia
Example (contd.)
2
2
B
0
4
9
5
C
5
F
8
8
A
D
7
7
7
E
4
3
3
2
2
7
B
0
7
4
9
5
C
5
F
8
8
A
D
7
E
4
3
3
www.monash.edu.au
17
prepared from lecture material © 2004 Goodrich & Tamassia
Analysis
•
Graph operations
– Method incidentEdges is called once for each vertex
•
Label operations
– We set/get the distance, parent and locator labels of vertex z O(deg(z)) times
– Setting/getting a label takes O(1) time
•
Priority queue operations
– Each vertex is inserted once into and removed once from the priority queue,
where each insertion or removal takes O(log n) time
– The key of a vertex w in the priority queue is modified at most deg(w) times,
where each key change takes O(log n) time (this is for reheap by percolating)
•
Prim-Jarnik’s algorithm runs in O((n + m) log n) time provided the graph is
represented by the adjacency list structure
– Recall that Sv deg(v) = 2m
•
The running time is O(m log n) since the graph is connected
www.monash.edu.au
18
prepared from lecture material © 2004 Goodrich & Tamassia
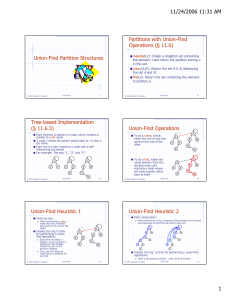
Appendix: a better union/find structure:
Tree-based Implementation
• Each element is stored in a node, which contains a
pointer to a set name
• A node v whose set pointer points back to v is also a set
name
• Each set is a tree, rooted at a node with a selfreferencing set pointer
• For example: The sets “1”, “2”, and “5”:
1
4
2
7
3
5
6
9
8
11
10
12
www.monash.edu.au
20
prepared from lecture material © 2004 Goodrich & Tamassia
Union-Find Operations
• To do a union, simply make
the root of one tree point to
the root of the other
5
2
8
3
10
6
11
• To do a find, follow setname pointers from the
starting node until
reaching a node whose setname pointer refers back to
itself
9
12
5
2
8
3
10
6
11
9
12
www.monash.edu.au
21
prepared from lecture material © 2004 Goodrich & Tamassia
Union-Find Heuristic 1
• Union by size:
– When performing a
union, make the root of
smaller tree point to the
root of the larger
• Implies O(n log n) time for
performing n union-find
operations:
– Each time we follow a
pointer, we are going to
a subtree of size at least
double the size of the
previous subtree
– Thus, we will follow at
most O(log n) pointers
for any find.
5
2
8
3
10
6
11
9
12
www.monash.edu.au
22
prepared from lecture material © 2004 Goodrich & Tamassia
Union-Find Heuristic 2
• Path compression:
– After performing a find, compress all the pointers on the
path just traversed so that they all point to the root
5
8
5
10
8
11
3
6
9
11
12
2
10
12
2
3
6
9
• Implies O(n log* n) time for performing n union-find
operations:
– Proof is complex… (in Weiss 8.6.1, Theorem 8.1)
www.monash.edu.au
23
prepared from lecture material © 2004 Goodrich & Tamassia
Log*
•
•
•
log* is an amazingly slow growing function.
It is the inverse of the tower-of-twos function
(ie. the number of time you can draw the logarithm of n before
the result is less than 2)
•
so far practically relevant numbers, O(n log* n) is not much
worse than O(n) and the constants (which Big-O neglects) is
probably more important.
n
log* n
2
22
2
22
2
22
=4
22
=16
22
=65536
22
1
2
3
4
5
www.monash.edu.au
24
prepared from lecture material © 2004 Goodrich & Tamassia