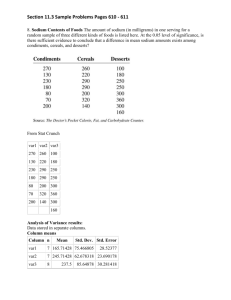
SKEMA – Ph.D programme 2010 – 2011 Quantitative Methods For Social Sciences Lionel Nesta Observatoire Français des Conjonctures Economiques Lionel.nesta@ofce.sciences-po.fr Objective of The Course The objective of the class is to provide students with a set of techniques to analyze quantitative data. It concerns the application of quantitative and statistical approaches as developed in the social sciences, for future decision makers, policy markers, stake holders, managers, etc. All courses are computer-based classes using the STATA statistical package. The objective is to reach levels of competence which provide the students with skills to both read and understand the work of others and to carry out one's own research. Examples Rise in biotechnology Should the EU fund fundamental research in biotechnology? Has biotechnology increased the productivity of firm-level R&D? Did it increase the speed of discovery in pharmaceutical R&D? Increasing university-industry collaborations Does it facilitate innovation by firms? Does it increase the production of new knowledge by academics? Does it modify the fundamental/applied nature of research? Examples Economic (productivity) Growth Does it come mainly from new firms or improving existing firms? Is market selection operating correctly? Why do good firms exit the market? How does the organisation of knowledge impact on performance? How do knowledge stock and specialisation impact on productivity? How do firms enter into new technological fields? Do firms diversify in new technologies/businesses purposively? Structure of the Class Part 1 : Descriptive Statistics Part 2 : Statistical Inference Part 3 : Relationship Between Variables Part 4 : Ordinary Least Squares (OLS) Part 5 : Extension to OLS Part 6 : Qualitative Dependent variables Structure of the Class Part 1 : Descriptive Statistics Mean, variance, standard deviation Data management Part 2 : Statistical Inference Part 3 : Relationship Between Variables Part 4 : Ordinary Least Squares (OLS) Part 5 : Extension to OLS Part 6 : Qualitative Dependent variables Structure of the Class Part 1 : Descriptive Statistics Part 2 : Statistical Inference Distributions Comparison of means Part 3 : Relationship Between Variables Part 4 : Ordinary Least Squares (OLS) Part 5 : Extension to OLS Part 6 : Qualitative Dependent variables Structure of the Class Part 1 : Descriptive Statistics Part 2 : Statistical Inference Part 3 : Relationship Between Variables ANOVA, Chi-Square Correlation Part 4 : Ordinary Least Squares (OLS) Part 5 : Extension to OLS Part 6 : Qualitative Dependent variables Structure of the Class Part 1 : Descriptive Statistics Part 2 : Statistical Inference Part 3 : Relationship Between Variables Part 4 : Ordinary Least Squares (OLS) Correlation coefficient, simple regression Multiple regression Part 5 : Extension to OLS Part 6 : Qualitative Dependent variables Structure of the Class Part 1 : Descriptive Statistics Part 2 : Statistical Inference Part 3 : Relationship Between Variables Part 4 : Ordinary Least Squares (OLS) Part 5 : Extension to OLS Regressions diagnostics Qualitative explanatory variables Part 6 : Qualitative Dependent variables Structure of the Class Part 1 : Descriptive Statistics Part 2 : Statistical Inference Part 3 : Relationship Between Variables Part 4 : Ordinary Least Squares (OLS) Part 5 : Extension to OLS Part 6 : Qualitative Dependent variables Linear probability model Maximum likelihood (logit, probit) Part 1 Descriptive Statistics Types of Data Descriptive statistics is the branch of statistics which gathers all techniques used to describe and summarize quantitative and qualitative data. Quantitative data Continuous Measured on a scale (value its the range) The size of the number reflect the amount of the variable Age; wage, sales; height, weight; GDP Qualitative data Discrete, categorical The number reflect the category of the variable Type of work; gender; nationality Descriptive Statistics All means are good to summarize data in a synthetic way: graphs; charts; tables. Quantitative data Graphs: scatter plots; line plots; histograms Central tendency Dispersion Qualitative data Graphs: pie graphs; histograms Tables, frequency, percentage, cumulative percentage Cross tables Central Tendency and Dispersion A distribution is an ordered set of numbers showing how many times each occurred, from the lowest to the highest number or the reverse Central tendency: measures of the degree to which scores are clustered around the mean of a distribution Dispersion: measures the fluctuations around the characteristics of central tendency In other words, the characteristics of central tendency produce stylized facts, when the characteristics of dispersion look at the representativeness of a given stylized fact. Central Tendency The mode The most frequent score in distribution is called the mode. The median The middle value of all observed values, when 50% of observed value are higher and 50% of observed value are lower than the median The mean The sum of all of the values divided by the number of value 1 X N i n x i 1 i The mode, the mean and the median ore equal if and only of the distribution is symmetrical and unimodal. Dispersion The range Difference between the maximum and minimum values R xmax xmin The variance Average of the squared differences between data points and the mean (average) quadratic deviation i n 2 x i 1 i X 2 N The standard deviation Square root of variance, therefore measures the spread of data about the mean, measured in the same units as the data in 2 x i 1 i X N 2 Research Productivity in the Bio-pharmaceutical Industry EU Framework Programme 7 Stylised Facts about Modern Biotech 1. 2. Innovations emerge from uncertain, complex processes involving knowledge and markets: Roles of networks. Economic value is created in many ways – globally and in geographical agglomerations 3. Various linkages exist among diverse actors (LDFs, DBFs, Univ, Venture Capital) in innovation processes, but the firm plays a particularly important role. 4. Regulations, social structures and institutions affect ongoing innovation processes as well as their impacts on society: Importance of IPR. STATA software Statistical Package for the Social Sciences The Stata software Stata Corp, spinoff from Texas A&M – College Station – Texas (1985) Among the most widely used programs for statistical analysis in social sciences. Probably to most widely used econometric software among economists Data management (case selection, file reshaping, creating derived data) Features of Stata are accessible via pull-down menus The pull-down menu interface generates command syntax. The Stata software STATA is a statistical software in constant evolution Updates are constantly put on the web available to the use of other Stata user (command update all) Most are available through the Boston College server ssc install module_name, all And hundreds of other can be reached as follows: net search key_words net install module_name, all The Stata software Review window Pull down menus Results window Variable window Command window The Stata software How to use STATA ? Using pull-down menus Typing STATA instructions in the Command window Grouping a series of STATA instructions in a .do files Programming new functions (.ado files) Programming new functions with a powerful matrix language (MATA) similar to C (Version 9.0 of STATA onwards) The Stata software All STATA commands used from the menu or the command window are automatically stored in the Review window At the end of a session, the review window can then be saved by right-clicking on it save all : under a .Do-file Send to do-file editor : A new window opens up. A Do-file is a text file containing a list of STATA commands which will be executed step by step by STATA. It is recommended to explore results and methods with the command window. Once the methods are settled, save the series of commands as a do-file. The Stata software All STATA results are displayed in the Result window This window is a buffer. Once it disappears from the screen, it is deleted. That is why you may want to record results. log using log_name.txt (beginning of a session) log close (end of a session) It is recommended to save results in a log file. Moreover, if you work with a do file, you can always get ols results with the do-file. The Stata software Memory settings By default, 10 megabytes are available for database uploading. If a database is greater than 10Mb, STATA does not upload the database. There are also other limits (matrix size, # of variables) which can be managed using the commands below. Useful commands describe using database_name.dta query memory clear set memory 500m, permanently set maxvar n , permanently set matsize n , permanently set virtual on , permanently Data Handling (1): Database creation 1st step: Creating a database Typing data in the database through Data Editor (edit) Importing data insheet myfile.txt , options options : tab ; comma ; delimiter("char") ; clear ; names Importing data from a .txt file - Without fixed format (without dictionnary) infile1 var1 var2 var3 using myfile.txt , options - With a fixed format (with dictionnary) infile2 using mydict.dct , using (myfile.txt) options DH(2): Database Exploration 2nd step: Exploring the Data To obtain a description of the database describe [varlist], options inspect [varlist] codebook [varlist], options nmissing [varlist], options npresent [varlist], options To display all possible values of a variable list [varlist] [if] [in], options Example : list var1 if var2 > var3 in 1/100 DH(3): Database Organisation 3rd step: Organisation of the database Sorting observations sort varlist gsort [ + | - ] varlist Sorting variables order varlist aorder varlist (If no varlist is specified, _all is assumed.) Fusionner plusieurs bases de données (ajouter des variables) merge varlist using base1.dta [base2.dta], options Fusionner plusieurs bases de données (ajouter des observations) append using base1.dta [base2.dta], options DH(3): Database Organisation 3rd step: Organisation of the database Modifying the shape of the database reshape long stubnames, i(varlist) j(varlist) reshape wide stubnames, i(varlist) j(varlist) i i id sex inc80 inc81 inc82 -------------------------------------1 0 5000 5500 6000 2 1 2000 2200 3300 3 0 3000 2000 1000 Wide form j id year sex inc ----------------------------1 80 0 5000 1 81 0 5500 1 82 0 6000 2 80 1 2000 Long form 2 81 1 2200 2 82 1 3300 3 80 0 3000 3 81 0 2000 3 82 0 1000 DH(4) : Saving, Opening, Exporting 4th step: Save and re-use STATA database files (.dta files) Changes the working directory to the specified drive and directory cd "C:\STATA SKEMA" Saves the database as a STATA file (.dta) save myfile.dta , replace Opens a STATA format database (.dta) use myfile.dta , clear Exports a database as a txt files outsheet [varlist]using myfile.txt , options options : comma ; nonames ; replace Handling Variables Create a new variable By assigning a value to it generate var1 = expression [if] [in] Using a predefined function: Extensions to generate egen var1 = fcn(arguments) [if] [in], options by(varlist) fcn : min ; max ; mode ; mean ; median ; sd ; total ; pctile ; group ; count ; etc… Examples : egen mean(salaire) , by(age) egen group(nom) egen count(id), by(sector) Handling Variables Variables modifications and removal Modifying a variable which has already been created replace var1 = expression [in] [if] Erasing variables drop varlist keep varlist Erasing observations drop [in] [if] keep [in] [if] Examples : drop if revenu < 100 keep if age >= 18 Handling Variables Time series and panel data utilities Declaring data as time series or panel data tsset [panelvar] timevar , options options : daily ; weekly ; monthly ; quarterly ; yearly Exemple : tsset id annee , yearly Using time series operators Lagged values L. L2. ou LL. L.X = Xt-1 L2.X = Xt-2 Forwarded values F. F2. ou FF. F.X = Xt+1 F2.X = Xt+2 Differenced values D. D2. ou DD. D.X = Xt - Xt-1 D2.X = Xt - Xt-1 – (Xt-1 - Xt-2 ) Descriptive Statistics with STATA Using log files log using xxx, replace / log close Defining and using labels label variable label define label values Descriptive statistics summarize table table, content() tabulate Manipulating .dta files and exporting collapse save as outsheet using... Log files Log files save the result window. They are useful when producing descriptives statistics on the .dta files and on the variables. log using nom_fichier_log, replace Instructions STATA log close Advantage. Very useful to find back old results (replication and refutation) Drawbacks. Tedious to manipulate Labelling variables Labelling is too often neglected. No influence on the results Large influence on correct interpretation of variables and results label variable. Describe a variable label variable asset "real capital" label define. Define a label label define firm_type 1 "biotech" label values Applies the label label values type firm_type 0 "Pharma" Descriptive statistics: summarize summarize var1 var2....varN Produces number of obs. means, variance, min and max We can add a condition using if summarize var1 var2 ....varN if [condition] We can produce descriptive statistics by subsets of teh database using bysort bysort varcat: summarize var1 var2 ....varN Beware: Most of the time, you do not need a comma before if. However, if you get an error message, there is very high chances that it comes from the absence of a comma before if. Descriptive statistics: table The table command applies to categorical variables (string or categorical). table varcat1 Provide the number of observations by categories of varcat1 table varcat1 varcat2 Provides a cross table between varcat1 and varcat2 table varcat, content(count var1 mean var1 sd var1...) Provide descriptive statistics on var1 by categories of varcat Descriptive statistics: tabulate The tabulate command is similar to table, but obtions are different. tabulate varcat, gen(varcat_) generates dummy variables for each category of varcat tabulate varcat1 varcat2, [options] Generate measures of associations between two categorical variables tabulate varcat1, summarize(var2) Provide descriptive statistics on var2 by categories of var1 Stacking observations: collapse The collapse command produces a new database which is an aggregation of the old database. collapse will aggregate lines (observation) by categories of your choice of a define categorical variable collapse (mean)var1 var2 (sum) var3, by(varcat) Will generate a new database with as many lines as there are categories of varcat, with 3 variables (means of var1 & var2, sum of var3) collapse (mean)var1 var1 (sd) sdvar1=var1 sdvar2=var2, by(varcat1 varcat2) Will generate a new database with as many lines as there are categories of varcat1 & varcat2, with 3 variables (means of var1 & var2, standard deviation of var1 & var2) Note: collapse is interesting to export tables of results to excel. Note: Please save the old and new database under different names! Keywords for table & collapse mean sd sum rawsum count max min iqr median p1 p2 ... p50 ... p98 p99 means (default) standard deviations sums sums, ignoring optionally specified weight number of nonmissing observations maximums minimums interquartile range medians 1st percentile 2nd percentile 3rd-49th percentiles 50th percentile (same as median) 51st-97th percentiles 98th percentile 99th percentile Graphs Graphic representations are a very effective means of synthesis . - Pie graphs, which display proportions of a population or a sample - Two-way graphs linking any two quantitative dimensions - Distribution graphs (histograms) which plots central tendency characteristics and dispersion of a variable Pie Graphs graph pie, over(varcat) C1 C3 D0 E2 F1 F3 F5 C2 C4 E1 E3 F2 F4 F6 Two-way Graphs Two-way graphs link two continuous var1 and var2. There are several types of two-way graphs : - Line graphs twoway line var1 var2 - Classical scatterplot twoway scatter var1 var2 - Conencted graphs twoway connected var1 var2 Line graphes .1 .105 rdi .11 .115 twoway line var1 var2 1988 1990 1992 1994 1996 year twoway line rdi year if name==« Abbott" 1998 Line graphs .1 .15 rdi .2 .25 twoway line var1 var2 1988 1990 1996 1994 1992 1998 year Amgen Abbott twoway (line rdi year if name=="Amgen", sort) (line rdi year if name=="Abbott", sort), legend(on order(1 "Amgen" 2 "Abbott")) Connected graphs .1 .105 rdi .11 .115 twoway connected var1 var2 1988 1990 1994 1992 1996 1998 year twoway (connected rdi year if name=="Abbott") Scatterplots -6 -4 lrdi -2 0 twoway scatter var1 var2 8 10 12 14 16 lassets twoway scatter lrdi lassets 18 Distribution graphs Distribution graphs plot the distribution of one quantitative variable var1 at a time by means of a histogram: On the horizontal axis, classes of var1 are displayed. On the vertical axis, the density of each class is displayed. fj nj Number of observations n j Class range d j c j c j 1 Distributionnal histogrammes 0 .1 Density .2 .3 hist var1 8 10 12 14 lassets hist lassets 16 18 Kernel distributions Using kernel, one can get the probability density function of var1. The probability density function is important to visually look at the normality of the distribution. Normal distributions are also called Gaussian distribution. These are very frenquently used in sciences to account for random processes. They are based on the theory of large numbers and the central limit theorem. Distribution de kernel kdensity var1 .15 .1 0 .05 Density .2 .25 Kernel density estimate 8 10 12 14 lassets kernel = epanechnikov, bandwidth = 0.5319 kdensity lassets 16 18 Exporting Graphs One can simply copy and paste graph in any microsoft office software. One can use.do files, and write: graph export [graph_name], as[extension] options Exemple : graph export SKEMA_rdi.wmf, as(wmf) replace Possible extensions: PostScript (ps), Encapsulated PostScript (eps), Windows Metafile (wmf), Windows Enhanced Metafile (emf), Macintosh PICT format (pict), Acrobat Reader (pdf) SPSS software Statistical Package for the Social Sciences SPSS : Opening SPSS SPSS : Importing data SPSS : Importing data SPSS : Importing data Settings in the “import text” dialogue box No predefine format (1) Delimited (2) First lines contains the variable names (2) One observation per line // all observations (3) Tab delimited only (4) Finish (6) SPSS windows SPSS has opens automatically windows The datasheet window Observe, manage, modify, create, data The results window Everything you do will be stored there The syntax window can be opened SPSS : Data sheet (1) SPSS : Data sheet (2) SPSS : Result / Journal SPSS : Saving data SPSS : working, at last! Recoding Variables Changing existing values to new values (biotechnologie → DBF, pharmaceutique → LDF) 1 2 3 Computing New Variables Taking logarithm (normalization of continuous variables) 1 2 Creating Dummy Variables Taking logarithm (normalization of continuous variables) 1 2 3 Computation of Descriptive Statistics 1 3 2 Descriptive Statistics Statistiques descriptives N patent assets rd spe pharma biotech N valide (listwise) 457 457 457 457 457 457 457 Intervalle 286 35788473.97 1917997.980 2.0235309 1 1 Minimum 0 4422.18 858.53204 -1.1298400 0 0 Maximum Moyenne Ecart type 286 11.92 22.901 35792896.15 4358371.54 6086530.85 1918856.512 330236.630 405160.516 .8936909 -.056808610 .3374751802 1 .63 .482 1 .37 .482 Variance 524.470 3.705E+013 164155043889 .114 .232 .232 Splitting Database 1 2 Descriptive Statistics (by type) Statistique s descripti ves type DB F LDF N patent as sets rd spe pharma biotech N valide (lis twis e) patent as sets rd spe pharma biotech N valide (lis twis e) Int ervalle Minimum 167 202 0 167 2442619 4422.18 167 495443.5 858.53204 167 1.7544527 -1. 12984 167 0 0 167 0 1 167 290 286 0 290 4E +007 218006.47 290 1912600 6256.248 290 1.6904465 -.7967556 290 0 1 290 0 0 290 Maximum 202 2447041 496302.1 .6246127 0 1 Moyenne 12.11 342934.49 58116. 590 -.10630582 .00 1.00 Ec art t ype 21.066 478511.938 88638. 5347 .343286812 .000 .000 Variance 443.764 2E +011 8E +009 .118 .000 .000 286 4E +007 1918857 .8936909 1 0 11.81 6670709.4 486940.24 -.02830504 1.00 .00 23.929 6605972.68 432514.940 .331330781 .000 .000 572.609 4E +013 2E +011 .110 .000 .000 Logarithm Normalization Taking the logarithm is a transformation which usually normalize distribution. Elasticities http://en.wikipedia.org/wiki/Elasticity_(economics) A change in log of x is a relative change of x itself. Cobb-Douglas production function log x x 1 x log x x x
 0
0
advertisement





Download
advertisement
Add this document to collection(s)
You can add this document to your study collection(s)
Sign in Available only to authorized usersAdd this document to saved
You can add this document to your saved list
Sign in Available only to authorized users