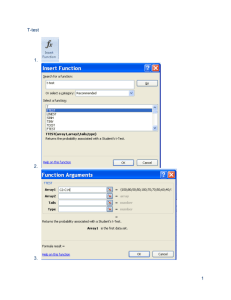
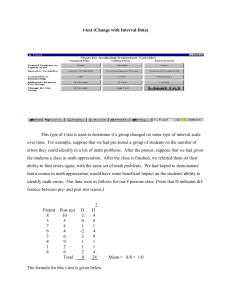
Hypothesis Test
advertisement

Hypothesis Testing
The New York Times Daily Dilemma
Select 50% users to see headline A
◦ Titanic Sinks
Select 50% users to see headline B
◦ Ship Sinks Killing Thousands
Do people click more on headline A or B?
2
Testing Hypotheses
Two Populations
10
4
12
?
?
?
?
9
?
?
?
Which one has the largest average?
3
The two-sample t-test
Is difference in averages between two groups more than
we would expect based on chance alone?
4
More Broadly: Hypothesis Testing Procedures
Hypothesis
Testing
Procedures
Nonparamet
ric
Parametric
Z Test
t Test
Cohen's d
Wilcoxon
Rank Sum
Test
Kruskal-Walli
H-Test
KolmogorovSmirnov test
5
Parametric Test Procedures
Tests Population Parameters (e.g. Mean)
Distribution Assumptions (e.g. Normal distribution)
Examples: Z Test, t-Test, 2 Test, F test
6
Nonparametric Test Procedures
Not Related to Population Parameters
Example: Probability Distributions, Independence
Data Values not Directly Used
Uses Ordering of Data
Examples:
Wilcoxon Rank Sum Test , Komogorov-Smirnov Test
7
Two-sample t-Test
In class experiment with R
Left= c(20,5,500,15,30)
Right = c(0,50,70,100)
t.test(Left, Right,
alternative=c("two.sided","less","greater"),
var.equal=TRUE, conf.level=0.95)
8
t-Test (Independent Samples)
The goal is to evaluate if the average difference between
two populations is zero
Two hypotheses:
H0: μ1 - μ2 = 0
H1: μ1 - μ2 ≠ 0
The t-test makes the following assumptions
• The values in X(0) and X(1) follow a normal
distribution
• Observations are independent
9
t-Test Calculation
General t formula
t = sample statistic - hypothesized population parameter
estimated standard error
Independent samples t
Empirical averages
Estimated standard deviation??
10
t-Test: Standard Deviation Calculation
Standard deviation of difference in empirical averages
How much variance when we use average difference of
observations to represent the true average difference?
11
t-Test: Standard Deviation Calculation (2/2)
Standard deviation of difference in empirical averages
Sample variance of X(0)
Number of observations
in X(0)
with degrees of freedom
Also known as Welsh’s t
12
t-Statistics p-value
H0: μ1 - μ2 = 0
H1: μ1 - μ2 ≠ 0
What is the p-value?
Can we ever accept hypothesis H1 ?
13
14
t-Test: Effect Size
t-Test tests only if the difference is zero or not.
What about effect size?
Cohen’s d
where s is the pooled variance
15
16
Bayesian Approach
Probability of hypothesis given data
The Bayes factor
17
18
Nonparametric Testing of Distributions
Two-sample Kolmogorov-Smirnov Test
Sample size correction
◦ Do X(0) and X(1) come from same underlying distribution?
◦ Hypothesis (same distribution)
rejected at level p if
Confidence interval factor
Empirical
The K-S test is less sensitive when the
differences between curves is greatest at
the beginning or the end of the
distributions. Works best when distributions
differ at center.
Wikipedia
Good reading:
M. Tygert, Statistical tests for whether a given set of independent,
identically distributed draws comes from a specified probability
density. PNAS 2010
19
20
Chi-Squared Test
Twitter users can have gender and number of tweets.
We want to determine whether gender is related to
number of tweets.
Use chi-square test for independence
21
When to use Chi-Squared test
When to use chi-square test for independence:
◦ Uniform sampling design
◦ Categorical features
◦ Population is significantly larger than sample
State the hypotheses:
◦ H0 ?
◦ H1 ?
22
Example Chi-Squared Test
men = c(300, 100, 40)
women = c(350, 200, 90)
data = as.data.frame(rbind(men, women))
names(data) = c('low', 'med', 'large')
data
chisq.test(data)
Reject H0 (p<0.05) means …
23
24
Revisiting The New York Times Dilemma
Select 50% users to see headline A
◦ Titanic Sinks
Select 50% users to see headline B
◦ Ship Sinks Killing Thousands
Assign half the readers to headline A and half to
headline B?
◦ Yes?
◦ No?
◦ Which test to use?
What happens A is MUCH better than B?
25
Sequential Analysis (Sequential Hypothesis Test)
How to stop experiment early if hypothesis seems true
◦ Stopping criteria often needs to be decided before experiment
starts
◦ If ever needed:
26
But there is a better way…
27
Bandit Algorithms
K distinct hypotheses (so far we had K = 2)
◦ Hypothesis = choosing NYT headline
Each time we pull arm i we get reward Xi
(simple version of problem)
Underlying population (reward distribution) does not
change over time
Bandit algorithms attempt to minimize regret
◦ If n = total actions ; ni = total actions i
largest true average
28
Challenge
Note that regret is defined over the true average reward
How can we estimate true average reward Xi?
◦ We need to get lots of observations from population i
◦ But what happens if E[Xi] is small?
Core of decision making problems:
◦ Exploration vs. exploitation
◦ When exploring we seek to improve estimated average reward
◦ When exploiting we try what has worked better in the past
Balancing exploration and exploitation:
◦ Instead of trying the action with highest estimated average, we try
the action with the highest upper bound on its confidence interval
(more on this next class)
29
UCB1 (Upper Confidence Bound 1)
Multi-Armed Bandit (MAB)
◦ Bandit process is a special type of Markov Decision Process
◦ Generally, reward Xi(ni) at ni–th arm pull of arm i is P[Xi(ni) | Xi(ni1)]
UCB1
◦ Use arm i that maximizes
30
R Example
numT <- 2500
# number of time steps
ttest <- c()
# mean of population 1
mean1 = 0.4
# mean of population 2
mean2 = 0.7
# initialize observations
x1 <- c(rbinom(n=1,size=1,prob=mean1))
x2 <- c(rbinom(n=1,size=1,prob=mean2))
n1 = 1
n2 = 1
for (i in 2:numT){
# compute reward of bandit 1
reward_1 = mean(x1) + sqrt(2*log(i)/n1)
# compute reward of bandit 2
reward_2 = mean(x2) + sqrt(2*log(i)/n2)
# decides which arm to pull
if (reward_1 > reward_2) {
x1 <- c(rbinom(n=1,size=1,prob=mean1),x1)
n1 = n1 + 1
} else {
x2 <- c(rbinom(n=1,size=1,prob=mean2),x2)
n2 = n2 + 1
}
# computes the t-Test p-value of observations
if ((n1 > 2) && (n2 > 2)) {
d <- t.test(x1,x2)$p.value
} else {
d=1
}
ttest <- c(ttest, d)
}
par(mfrow=c(1,2))
plot(2:numT,ttest,"l",xlab="Time",ylab="t-Test pvalue",log="y")
barplot(c(n1,n2),xlab="Arm Pulls",ylab="Observations",names.arg=c("n0", "n1"))
31





![[Type text] Fill in a fictional “headline from the future” above](http://s3.studylib.net/store/data/008674091_1-c12eeba0d4bd6938777e08ea064ad30a-300x300.png)