presentation source
advertisement

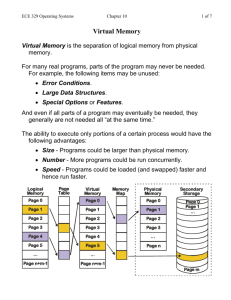
Chapter 11 - Virtual Memory – Fragmentation of contiguous allocation can be eliminated through compaction (Figure 11.1). – Another technique is to avoid contiguous memory allocation. – One way is to separate the program into different segments. – A natural division is separating code from data. One could use two relocation registers (Figure 11.2). • Rethinking Memory Allocation – Result is two separate physical address (Figure 11.3) – Why stop there? Why not 4 relocation (a.k.a. segment) registers? Figure 11.4 -- divide a portion of the 16-bit memory address into a 2-bit segment address and a 14-bit offset. Think of this as an array of base/bound relocation registers on a per-process basis. – Can now get more creative physical address assignments where the process appears to have contiguous memory (Figure 11.5). – Note that now there can be holes in the logical address space (Figure 11.6 & 11.7). • Noncontiguous Logical Address Spaces – Varying the size of the segments can lead to misuse of the segment sizes, assuming that the number of segments is limited. – Why not just fix the size of the segments? Then, we can eliminate the “bound” column in the segment table and agree that all segments are of an equal, fixed size. We’ll call these new fixed-size segments pages. – Page Table Entry - Pointer to physical memory frame. – Page table - collection of page table entries. – Again we divide the logical address into separate portions (4-bit page and 12-bit offset) - Figure 11.8. • Page Tables – If the number of pages gets to be too large to store in registers then we can map the page table into memory (Figure 11.9). – Note the addition of a Page Table Base Register in place of the base register. Now a context switch involves saving/restoring one register for all the page mappings rather than a set of registers. – Can also add a Page Table Length Register so we know on a per-process basis how large the page table is. – Big problem though is now every memory address requires two memory accesses! Program will run at 1/2 the speed! • Translation Lookaside Buffer – Common theme: throw more hardware at the problem! Use a hardware caching mechanism to keep most-recently used page table entries in “fast” parallel search registers. – Translation Lookaside Buffer (TLB) - set of associative registers containing page table entries, the contents of which can be searched in parallel. – TLB flow chart: Figure 11.11. – TLB operation with logical address mapping & page table: Figure 11.13. – Cache hit - page entry found in TLB – Cache miss - page entry not in TLB; resort to memory page table. • Translation Lookaside Buffer – Want the cache hit ratio to be high, else paging slows down to 1/2 memory speed (recall each logical address reference takes two physical memory accesses). – Sample calculation: if cache hit rate = 90 %, then effective memory access time: .9 * 1 + (1-.9) * 2 = .9 +.2 = 1.1, representing a 10% slowdown over a 100% hit ratio. – Note that TLB will require being “flushed” (all entries cleared) on a context switch, since a different page table will be in effect. This cache invalidation is typically done by OS code. • TLB & Paging Behavior – One good reason programs get high cache hit rates is due to a program’s address locality in space and time. – Programs tend to stay in one small address range within a short period of time. – Useful to analyze a program’s behavior and see how it affects paging performance: • • • • Assume we are traversing an array that spans many pages. Each page is 4 KB in size (1024 4-byte words of the array). 1st word of each page will cause a page cache miss. Next 1023 words per page will use the already-cached page entries. • Therefore, 2+1023 (=1025) memory accesses to fetch 1024 words = 1.001 memory cycles per word. Pretty efficient! • TLB & Paging Behavior – What if the program traverses the array with a pagesized stride? This is the worst case scenario (assuming that there is only one page table entry that must be recycled). Each array reference will cause a TLB miss and require a page table lookup. – Figure 11.14: Note assumption that conditions have to be just right to cause this behavior (size of elements in the array have to be exactly traversed in page-sized units). – So, the TLB model assumes that a program “behaves” itself (or that the compiler performs memory layout to minimize page-sized strides). • More Paging terminology – A program’s logical address space is divided up into same-sized pages. – The physical address space is divided up into samesized page frames (use of the word frame should key in physical memory). – Use of paging eliminates external fragmentation as seen with dynamic memory allocation (no holes outside of the segments). – Paging does, however, suffer from internal fragmentation (portion of any page or page frame that is not actually used by the program but unavailable for use by any other program). • More Paging terminology – Illustrative to look at Figure 11.16. It shows a typical page table entry with all the fields. Assumption is a 4KB page size (12 bits; 212 = 4096). • • • • 1-bit “present” bit (used later) 3-bit protection (bit 0 = read, bit 1 = write, bit 2 = execute) Unused field (used later) Base address (no need to store the offset bits) • Skip section 11.3 • Space-sharing memory – Memory is the type of resource that can be spaceshared. – A useful way to share memory is to use disk space as a holding space. • “Ancient” Memory Sharing Techniques – Swapping: move the entire address space of a program to disk, load up another program, repeat. – Figure 11.18. – Program speeds approximate disk speeds as swapping increases. – Suitable for interactive response, assuming disk drives and O/S response is quick enough. – Not terribly efficient, however! – Famous book quote: User needs are the primary concern in designing what operating system services to offer. Efficiency is the primary concern in designing how to implement operating system services. • “Ancient” Memory Sharing Techniques – Overlays: older technique that placed the burden of loading/unloading pieces of a program based on evaluating the subroutine/function usage patterns. – Allowed programs that were larger than physical memory to run! – Lot of effort to create the “overlay tree”, though. – Figure 11.19 is an example. – DOS overlays are a special case of how maintaining an old design (the 640K PC) really muddied the memory management waters of newer PCs for years (Figure 11.20’s plethora of memory styles is mindnumbing). • Virtual Memory – Combines the advantage of swapping (multiple programs space-sharing memory) and overlays (only keep the parts of a program in memory that are currently needed). – Take the paging hardware we’ve already learned and add these rules: • a program doesn’t have to have all it’s page table entries mapped before it runs. • A reference to a missing page frame will cause an interrupt (a page fault), which will transfer control to the O/S. • The page fault handler will fill in the page table entry and restart the process. – The result is an illusion to the program of virtual memory (Figure 11.21). • Virtual Memory – To support VM, we need the following PTE field: • present bit - if = 1, the page is present in memory & the base address field represents a valid page frame number. If = 0, the page reference is to a legal non-mapped page. – A memory access will now cause the following possible events (algorithm on p. 459): • Split logical address into page and offset values. • Check PTE entry for the page and see if the protection bits allow the appropriate access. If not, raise a protection violation interrupt. • Check PTE present bit. If 1, the frame # in the PTE is valid. Generate the physical address by combining the physical frame number and the offset. If 0, generate a page fault interrupt. • Operating System Support for VM – OS manages a swap area - section of disk set aside for keeping pages (try swap -l/swap -a on xi or free on Linux). – Four cases where the OS has to manage page tables: • • • • Process creation Process dispatch (context switch) Page fault Process exit – Figure 11.22 diagrams the VM events. – Let’s step through each of the cases! – Process creation • Calculate the number of pages needed for static code & data. • Allocate paging space on the swap partition. • Allocate memory-resident page table. • Initialize swap area with static binary modules. • Initialize page table fields (all non-present with appropriate protections). • Update the process descriptor (location of page table & the per-process swap area information). – Process dispatch (context switch) • Invalidate the TLB (it’s full of the previous process’s page table entries). • Load page table base register with the address of the new process’s page table. – Page fault (page fault handler code) • Find an empty page frame. If all frames are in use this will involve stealing some other frame (and possibly swapping it out if it contains modified data). • Read in the logical page from the process’s swap area into the new frame. • Fix the PTE: set the present bit to 1 and set the frame number to the new frame value. • Restart the instruction that caused the page fault. – Process exit • Free memory used by page table. • Free disk space on swap partition used by process. • Free the page frames the process was using. • Cost Evaluation of VM – Just as the TLB acted like a cache, where high cache hit rates are required for reasonable operation, the page fault rate (# of page faults/unit of time) needs to be low. If not, the program starts to run at disk speed! – Page faults are dramatically more expensive than a TLB miss -- look at all the software operations involved in a page fault. • Cost Evaluation of VM – Assume memory access time = 200 x 10-9 secs if the frame is in memory. – Assume that the page fault interrupt handler takes 40 x 10-6 secs to execute it’s code. – Assume reading the page from the swap partition on the disk takes 20 x 10-3 seconds. – The disk read time is 6 orders of magnitude larger than the memory access time and will dominate, so we can ignore the time spent executing the page fault handler (it’s 1/500th of the disk read time :). – The result is that a page fault memory address runs 100,000 times slower than a non-page fault memory address! • Cost Evaluation of VM – To run with a 10% slowdown would require that the program achieve one page fault per one million memory accesses! – Luckily, as mentioned with TLB cache hits, program exhibit spatial and temporal locality. – The next instruction or data reference is usually close to the current instruction in memory and close in future execution. – The result is that a program doesn’t usually demand that all of it’s logical pages be assigned to physical pages. Book: for typical programs, 25% to 50% of mapped pages result in acceptable low page fault rates. • Cost Evaluation of VM – Ideally the operating system should only map those pages that fit in the current program’s locality region (some call this a memory footprint or set of resident pages). – Since not all of each program has to be in memory at the same time we can run more programs in memory, as long as we have enough physical memory to hold all the footprints. • VM Management – Figure 11.23 diagrams typical VM data structures required by the OS. • VM Management – OS data structures: • Page frames - physical memory available for user programs. • Page tables - per-process memory-resident page tables. • Free page frame list - list of page frames that are not assigned in any page tables (free to allocate). • Modified free page frame list - list of free page frames that are “dirty” (need to be written back to the paging area on disk prior to re-use). • Replacement algorithm tables - page replacement algorithm state information (more in Chapter 12). • Swap area - Area on disk containing process pages that are not allocated to physical frames. • VM Management – Figure 11.24 shows VM events and procedures. • Bold text = events that cause changes in the tables (page fault, timer context switch & process creation). • Rounded corner shaded rectangles = memory management procedures. • Rectangles = OS managed data structures. – Paging daemon - a special process that is invoked occasionally by the operating system (the timer interrupt is a good place :). The paging daemon manages the free page frame list and can call the page replacement algorithm to start freeing up pages. – Daemon = attendant spirit (not an evil presence); so named because they supplement OS services. • Memory-mapped File I/O – Explicit file I/O (use of open(), read(), write() and close()) is similar to paging to a swap area. – Paging involves implicit I/O that the programmer isn’t aware of; file I/O involves explicit instructions that the programmer needs to be aware of to perform the I/O. – Both, however, involve reading and writing disk blocks. The information in the swap area is transient in that the next page of a process that is swapped out will overwrite any earlier page. File I/O is not transient; the file write()s stick. – Why not use the paging mechanism for use with persistent file data? • Memory-mapped File I/O – File mapping: extension of the VM system that allows the mapping of file I/O into the virtual address space. – Once the mapping is established then file I/O is done through standard memory operations (notice the similarity to memory-mapped I/O). No explicit file I/O system calls are needed! – Mapping a file to a memory address involves a new system call to create the mapping (MapFile()) and one to disconnect the mapping (UnMapFile()). – Most UNIXes provide a file mapping mechanism via the mmap() and munmap(). • Memory-mapped File I/O – Figure 11.25: Differentiates between persistent VM data (the mapped file) and transient VM data (the file on disk). – Figure 11.27: Sample file mapping code. – Figure 11.26: Effects of the MapFile() call. – Advantages to file mapping: • Fewer system calls/unit of I/O (well, sort of -- the page fault handler is still calling the OS on a page miss). • Fewer copies of file blocks in buffers (Figure 11.28). • “Instant” view of the changed data (unlike explicit I/O, which is usually atomic). • Skip section 11.11.4 (IBM 801 discussion).