Sequence Alignment - Winona State University
advertisement

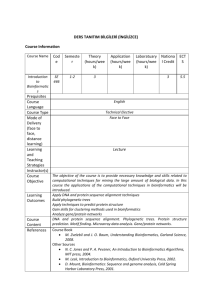
Introduction to Bioinformatics
Sequence Alignments
Sequence Alignments
Cornerstone of bioinformatics
What is a sequence?
• Nucleotide sequence
• Amino acid sequence
Pairwise and multiple sequence alignments
• We will focus on pairwise alignments
What alignments can help
• Determine function of a newly discovered gene sequence
• Determine evolutionary relationships among genes, proteins,
and species
• Predicting structure and function of protein
Intro to Bioinformatics – Sequence Alignment
2
Acknowledgement: This notes is adapted from lecture notes of both Wright State University’s Bioinformatics Program and Professor Laurie Heyer of Davidson College with permission.
DNA Replication
Prior to cell division, all the
genetic instructions must be
“copied” so that each new cell
will have a complete set
DNA polymerase is the enzyme
that copies DNA
• Reads the old strand in the 3´ to 5´
direction
Intro to Bioinformatics – Sequence Alignment
3
Over time, genes accumulate mutations
Environmental factors
• Radiation
• Oxidation
Mistakes in replication or
repair
Deletions, Duplications
Insertions, Inversions
Translocations
Point mutations
Intro to Bioinformatics – Sequence Alignment
4
Deletions
Codon deletion:
ACG ATA GCG TAT GTA TAG CCG…
• Effect depends on the protein, position, etc.
• Almost always deleterious
• Sometimes lethal
Frame shift mutation:
ACG ATA GCG TAT GTA TAG CCG…
ACG ATA GCG ATG TAT AGC CG?…
• Almost always lethal
Intro to Bioinformatics – Sequence Alignment
5
Indels
Comparing two genes it is generally impossible
to tell if an indel is an insertion in one gene, or
a deletion in another, unless ancestry is known:
ACGTCTGATACGCCGTATCGTCTATCT
ACGTCTGAT---CCGTATCGTCTATCT
Intro to Bioinformatics – Sequence Alignment
6
The Genetic Code
Substitutions are
mutations
accepted by
natural selection.
Synonymous:
CGC CGA
Non-synonymous:
GAU GAA
Intro to Bioinformatics – Sequence Alignment
7
Comparing Two Sequences
Point mutations, easy:
ACGTCTGATACGCCGTATAGTCTATCT
ACGTCTGATTCGCCCTATCGTCTATCT
Indels are difficult, must align sequences:
ACGTCTGATACGCCGTATAGTCTATCT
CTGATTCGCATCGTCTATCT
ACGTCTGATACGCCGTATAGTCTATCT
----CTGATTCGC---ATCGTCTATCT
Intro to Bioinformatics – Sequence Alignment
8
Why Align Sequences?
The draft human genome is available
Automated gene finding is possible
Gene: AGTACGTATCGTATAGCGTAA
• What does it do?
One approach: Is there a similar gene in
another species?
• Align sequences with known genes
• Find the gene with the “best” match
Intro to Bioinformatics – Sequence Alignment
9
Gaps or No Gaps
Examples
Intro to Bioinformatics – Sequence Alignment
10
Scoring a Sequence Alignment
Given
Match score:
+1
Mismatch score:
+0
Gap penalty:
–1
Sequences
ACGTCTGATACGCCGTATAGTCTATCT
||||| |||
|| ||||||||
----CTGATTCGC---ATCGTCTATCT
Matches: 18 × (+1)
Mismatches: 2 × 0
Score
Gaps: 7 × (– 1)
Intro to Bioinformatics – Sequence Alignment
= +11
11
Origination and Length Penalties
Note that a bioinformatics computational model or
algorithm must be “biologically meaningful” or
even “biologically significant”
We want to find alignments that are evolutionarily
likely.
Which of the following alignments seems more
likely to you?
ACGTCTGATACGCCGTATAGTCTATCT
ACGTCTGAT-------ATAGTCTATCT
ACGTCTGATACGCCGTATAGTCTATCT
AC-T-TGA--CG-CGT-TA-TCTATCT
We can achieve this by penalizing more for a new
gap, than for extending an existing gap
Intro to Bioinformatics – Sequence Alignment
12
Scoring a Sequence Alignment (2)
Given
Match/mismatch score:
+1/+0
Gap origination/length penalty: –2/–1
Sequences
ACGTCTGATACGCCGTATAGTCTATCT
||||| |||
|| ||||||||
----CTGATTCGC---ATCGTCTATCT
Matches: 18 × (+1)
Mismatches: 2 × 0
Score
Origination: 2 × (–2)
Length: 7 × (–1)
= +7
Caution: Sometime “gap extension” used instead of “gap
length” …
Intro to Bioinformatics – Sequence Alignment
13
How can we find an optimal alignment?
Finding the alignment is computationally hard:
ACGTCTGATACGCCGTATAGTCTATCT
CTGAT---TCG-CATCGTC--T-ATCT
C(27,7) gap positions = ~888,000 possibilities
It’s possible, as long as we don’t repeat our
work!
Dynamic programming: The Needleman &
Wunsch algorithm
Intro to Bioinformatics – Sequence Alignment
14
Dynamic Programming
Technique of solving optimization problems
• Find and memorize solutions for subproblems
• Use those solutions to build solutions for larger
subproblems
• Continue until the final solution is found
Recursive computation of cost function in a
non-recursive fashion
Intro to Bioinformatics – Sequence Alignment
15
Dynamic Programming
Example
• Solving Fibonacci number f(n) = f(n-1) + f(n-2)
recursively takes exponential time
Because many numbers are recalculated
• Solving it using dynamic programming only takes a
linear time
Use an array f[] to store the numbers
f[0] = 1;
f[1] = 1;
for (i = 2; i <= n; i++)
f[i] = f[i – 1] + f[i – 2];
Intro to Bioinformatics – Sequence Alignment
16
Global Sequence Alignment
Needleman-Wunsch algorithm
Di,j = max{ Di-1,j + d(Ai, –), Di,j-1 + d(–, Bj), Di-1,j-1 + d(Ai, Bj) }
B
i-1
A
i
j-1
j
Suppose we are aligning:
Seq1
a with a …
Seq2 a
Intro to Bioinformatics – Sequence Alignment
0
-1
a
-1
17
Dynamic Programming (DP) Concept
Suppose we are aligning:
CACGA
CGA
Intro to Bioinformatics – Sequence Alignment
18
DP – Recursion Perspective
Suppose we are aligning:
ACTCG
ACAGTAG
Last position choices:
G
G
+1
ACTC
ACAGTA
G
-
-1
ACTC
ACAGTAG
G
-1
ACTCG
ACAGTA
Intro to Bioinformatics – Sequence Alignment
19
What is the optimal alignment?
ACTCG
ACAGTAG
Match: +1
Mismatch: 0
Gap: –1
Intro to Bioinformatics – Sequence Alignment
20
Needleman-Wunsch: Step 1
Each sequence along one axis
Gap penalty multiples in first row/column
0 in [1,1] (or [0,0] for the CS-minded)
A
C
A
G
T
A
G
0
-1
-2
-3
-4
-5
-6
-7
A
-1
1
Intro to Bioinformatics – Sequence Alignment
C
-2
T
-3
C
-4
G
-5
21
Needleman-Wunsch: Step 2
Vertical/Horiz. move: Score + (simple) gap penalty
Diagonal move: Score + match/mismatch score
Take the MAX of the three possibilities
A
C
A
G
T
A
G
0
-1
-2
-3
-4
-5
-6
-7
A
-1
1
Intro to Bioinformatics – Sequence Alignment
C
-2
T
-3
C
-4
G
-5
22
Needleman-Wunsch: Step 2 (cont’d)
Fill out the rest of the table likewise…
a
a
c
a
g
t
a
g
0
-1
-2
-3
-4
-5
-6
-7
c
-1
1
Intro to Bioinformatics – Sequence Alignment
t
-2
0
c
-3
-1
g
-4
-2
-5
-3
23
Needleman-Wunsch: Step 2 (cont’d)
Fill out the rest of the table likewise…
a
a
c
a
g
t
a
g
0
-1
-2
-3
-4
-5
-6
-7
c
-1
1
0
-1
-2
-3
-4
-5
t
-2
0
2
1
0
-1
-2
-3
c
-3
-1
1
2
1
1
0
-1
g
-4
-2
0
1
2
1
1
0
-5
-3
-1
0
2
2
1
2
The optimal alignment score is calculated in the
lower-right corner
Intro to Bioinformatics – Sequence Alignment
24
But what is the optimal alignment
To reconstruct the optimal alignment, we must
determine of where the MAX at each step came
from…
a
a
c
a
g
t
a
g
0
-1
-2
-3
-4
-5
-6
-7
Intro to Bioinformatics – Sequence Alignment
c
-1
1
0
-1
-2
-3
-4
-5
t
-2
0
2
1
0
-1
-2
-3
c
-3
-1
1
2
1
1
0
-1
g
-4
-2
0
1
2
1
1
0
-5
-3
-1
0
2
2
1
2
25
A path corresponds to an alignment
= GAP in top sequence
= GAP in left sequence
= ALIGN both positions
One path from the previous table:
Corresponding alignment (start at the end):
AC--TCG
ACAGTAG
Intro to Bioinformatics – Sequence Alignment
Score = +2
26
Algorithm Analysis
Brute force approach
• If the length of both sequences is n, number of
possibility = C(2n, n) = (2n)!/(n!)2 22n / (n)1/2,
using Sterling’s approximation of n! = (2n)1/2e-nnn.
• O(4n)
Dynamic programming
• O(mn), where the two sequence sizes are m and n,
respectively
• O(n2), if m is in the order of n
Intro to Bioinformatics – Sequence Alignment
27
Practice Problem
Find an optimal alignment for these two
sequences:
GCGGTT
GCGT
Match: +1
Mismatch: 0
Gap: –1 g
c
g
t
g
0
-1
-2
-3
-4
Intro to Bioinformatics – Sequence Alignment
c
-1
g
-2
g
-3
t
-4
t
-5
-6
28
Practice Problem
Find an optimal alignment for these two
sequences:
GCGGTT
GCGT
g
c
g
g
t
t
g
c
g
t
0
-1
-2
-3
-4
-1
1
0
-1
-2
-2
0
2
1
0
-3
-1
1
3
2
GCGGTT
GCG-TIntro to Bioinformatics – Sequence Alignment
-4
-2
0
2
3
-5
-3
-1
1
3
-6
-4
-2
0
2
Score = +2
29
Semi-global alignment
Suppose we are aligning:
GCG
GGCG
Which do you prefer?
G-CG
-GCG
GGCG
GGCG
g
g
g
c
g
0
-1
-2
-3
-4
c
-1
1
0
-1
-2
g
-2
0
1
1
0
-3
-1
1
1
2
Semi-global alignment allows gaps at the ends
for free.
• Terminal gaps are usually the result of incomplete
data acquisition no biologically significant
Intro to Bioinformatics – Sequence Alignment
30
Semi-global alignment
Semi-global alignment allows gaps at the ends
for free.
g
g
g
c
g
0
0
0
0
0
c
0
1
1
0
1
g
0
0
1
2
1
0
1
1
1
3
Initialize first row and column to all 0’s
Allow free horizontal/vertical moves in last row
and column
Intro to Bioinformatics – Sequence Alignment
31
Local alignment
Global alignments – score the entire alignment
Semi-global alignments – allow unscored gaps
at the beginning or end of either sequence
Local alignment – find the best matching
subsequence
CGATG
AAATGGA
This is achieved by allowing a 4th alternative at
each position in the table: zero.
Intro to Bioinformatics – Sequence Alignment
32
Local Sequence Alignment
Why local sequence alignment?
• Subsequence comparison between a DNA sequence
and a genome
• Protein function domains
• Exons matching
Smith-Waterman algorithm
Initialization: D1,j = , Di,1 =
Di,j = max{
Di-1,j + d(Ai, –),
Di,j-1 + d(–,Bj),
Di-1,j-1 + d(Ai,Bj),
0}
Intro to Bioinformatics – Sequence Alignment
33
Local alignment
Score: Match = 1, Mismatch = -1, Gap = -1
c
a
a
a
t
g
g
a
0
0
0
0
0
0
0
0
g
0
0
0
0
0
0
0
0
a
0
0
0
0
0
1
1
0
t
0
1
1
1
0
0
0
2
g
0
0
0
0
2
1
0
1
0
0
0
0
1
3
2
1
CGATG
AAATGGA
Intro to Bioinformatics – Sequence Alignment
34
Local alignment
Another example
Intro to Bioinformatics – Sequence Alignment
35
More Example
Align
ATGGCCTC
ACGGCTC
Mismatch = -3
Gap
= -4
Global
Alignment:
ATGGCCTC
ACGGC-TC
-A
T
G
G
C
C
T
C
Intro to Bioinformatics – Sequence Alignment
-0
-4
-8
-12
-16
-20
-24
-28
-32
A
-4
1
-3
-7
-11
-15
-19
-23
-27
C
-8
-3
-2
-6
-10
-10
-14
-18
-22
G
-12
-7
-6
-1
-5
-9
-13
-17
-21
G
-16
-11
-10
-5
0
-4
-8
-12
-16
C
-20
-15
-14
-9
-4
1
-3
-7
-11
T
-24
-19
-14
-13
-8
-3
-2
-2
-6
C
-28
-23
-18
-17
-12
-7
-2
-5
-1
36
More Example
Local
Alignment:
ATGGCCTC
ACGG CTC
or
ATGGCCTC
ACGGC TC
Intro to Bioinformatics – Sequence Alignment
-A
T
G
G
C
C
T
C
-0
0
0
0
0
0
0
0
0
A
0
1
0
0
0
0
0
0
0
C
0
0
0
0
0
1
1
0
1
G
0
0
0
1
1
0
0
0
0
G
0
0
0
1
2
0
0
0
0
C
0
0
0
0
0
3
1
0
1
T
0
0
1
0
0
0
0
2
0
C
0
0
0
0
0
1
1
0
3
37
Scoring Matrices for DNA Sequences
Transition: A G C T
Transversion: a purine (A or G) is replaced by a
pyrimadine (C or T) or vice versa
Intro to Bioinformatics – Sequence Alignment
38
Scoring Matrices for Protein Sequence
PAM 250
Intro to Bioinformatics – Sequence Alignment
39
Scoring Matrices for Protein Sequence
PAM (Percent Accepted Mutations)
1 PAM unit can be thought of as the amount of time in which an
“average” protein mutates 1 out of every 100 amino acids.
Perform multiple sequence alignment on a “family” of proteins that are
at least 85% similar. Find the frequency of amino acid i and j are aligned
to each other and normalize it.
Entry mij in PAM1 represents the probability of amino acid i
substituted by amino acid j in 1 PAM unit
PAM 2 = PAM 1 × PAM 1
PAM n = (PAM 1)n, e.g., PAM 250 = (PAM 1)250
Questions
Why are values in a PAM matrix integers? Shouldn’t a probability be
between 0 and 1?
Why is PAM250 possible? Shouldn’t a probability be less than or equal
to 100%?
Intro to Bioinformatics – Sequence Alignment
40
Scoring Matrices for Protein Sequence
BLOSUM (BLOcks SUbstitution Matrix) 62
Intro to Bioinformatics – Sequence Alignment
41
Using Protein Scoring Matrices
Divergence
BLOSUM 80
PAM 1
Closely related
Less divergent
Less sensitive
BLOSUM 62
PAM 120
Looking for
BLOSUM 45
PAM 250
Distantly related
More divergent
More sensitive
• Short similar sequences → use less sensitive matrix
• Long dissimilar sequences → use more sensitive matrix
• Unknown → use range of matrices
Comparison
• PAM – designed to track evolutionary origin of proteins
• BLOSUM – designed to find conserved regions of proteins
Intro to Bioinformatics – Sequence Alignment
42
Multiple Sequence Alignment
Why multiple sequence alignment (MSA)
• Two sequences might not look very similar.
• But, some “similarity” emerges with more sequences,
however.
Is dynamic programming still applicable?
CLUSTALW
• One of most popular tools for MSA
• Heuristic-based approach
• Basic
1) Calculate the distance matrix based on pairwise alignments
2) Construct a guide tree
NJ (unrooted tree) Mid-point (rooted tree)
3) Progressive alignment using the guide tree
43