Statistics 2014, Fall 2001
advertisement

1
Chapter 4 – Probability Distributions
Defn: A random variable is a real-valued function whose domain is the sample space of a random
experiment. A random variable is called discrete if it has either a finite or a countably infinite number
of possible values. If the number of possible values is uncountably infinite, then the random variable
is called continuous.
Example 1: If the random experiment is to flip a fair coin twice, the sample space is
𝑆 = {𝐻𝐻, 𝐻𝑇, 𝑇𝐻, 𝑇𝑇}.
Define a random variable X = number of heads that occur when I flip a fair coin twice. This is an
example of a discrete random variable. Then 𝑋(𝐻𝐻) = 2, 𝑋(𝐻𝑇) = 1, 𝑋(𝑇𝐻) = 1, and 𝑋(𝑇𝑇) = 0.
Note: We will discuss continuous random variables in Chapter 5. In Chapter 4, we discuss discrete
distributions, including certain useful families of discrete distributions.
Defn: The probability distribution of a discrete random variable X is a set of ordered pairs of
numbers. In each pair, the first number is a possible value, x, of X, and the second number is the
probability that the observed value of X will be x when we perform the random experiment. We can
represent the distribution either as a function or (if the number of possible values of X is relatively
small) as a table. As a function, we would write
𝑓(𝑥) = 𝑃(𝑋 = 𝑥),
for all possible values of X. The probability distribution must satisfy the following two conditions:
𝑖) 𝑓(𝑥) ≥ 0, 𝑓𝑜𝑟 𝑎𝑙𝑙 𝑥, 𝑎𝑛𝑑
𝑖𝑖) ∑ 𝑓(𝑥) = 1.
𝑎𝑙𝑙 𝑥
The function f is also called the probability mass function (p.m.f.) of the random variable.
Example : Continuing the above example, we can find the probabilities associated with X by
considering the probabilities associated with the outcomes in the sample space. Since we assume the
coin is fair, each outcome in the sample space is equally likely to occur. Therefore, we may represent
the probability distribution of X in the following table:
x
𝑓(𝑥) = 𝑃(𝑋 = 𝑥)
0
0.25
1
0.50
2
0.25
The conditions above translate into saying that every number in the second column must be between 0
and 1, and the sum of the second column must be 1.
Defn: The cumulative distribution function (c.d.f.) (or distribution function) for a random variable X
is defined by
𝐹(𝑥) = 𝑃(𝑋 ≤ 𝑥), −∞ < 𝑥 ≤ ∞.
Note that the c.d.f. is defined for all real values of x, even though the random variable is discrete.
2
Example: Continuing the example with flipping a fair coin twice. We want to find the c.d.f. and
construct a graph. The graph will be a step function.
Bernoulli Distribution
The simplest type of discrete distribution is one for which the r.v. has two possible values.
Defn: A discrete r.v. X is said to have a Bernoulli distribution with parameter p (X ~ Bernoulli(p)) if
there are exactly two possible values 0 and 1 of X, such that P(X = 1) = p, and P(X = 0) = 1 – p.
Example: Our random experiment is to flip a fair coin once. We define X = number of heads. Then
X ~ Bernoulli(0.5). Then P(X = 1) = 0.5, and P(X = 0) = 0.5
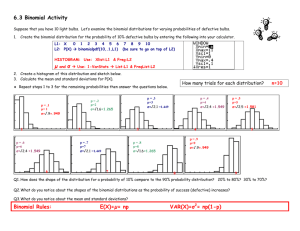
Binomial Distribution
Assume that instead of flipping the fair coin once or twice, we flip it 10 times. The sample space of
the experiment has 1024 possible outcomes. The number of events that could be defined is then 21024 .
These numbers are rather unwieldy to work with directly. Hence we define a random variable X to be
the number of heads that occur when we flip a fair coin 10 times. We want to be able to calculate
probabilities associated with X.
Defn: A discrete r.v. X is said to have a binomial distribution with parameters n and p if
n
n x
P X x p x 1 p , for x = 0, 1, …, n.
x
Derivation of the Binomial Distribution:
A binomial experiment is a random experiment which satisfies the following conditions:
1) The experiment consists of a fixed number, n, of trials.
2) The trials are identical to each other, in that they are all performed the same way.
3) The trials are independent of each other, meaning that the outcome of one trial gives us no
information about the outcome of any other trial.
4) Each trial has two possible outcomes, which we will call Success and Failure.
5) The probability of Success is the same, p, for each of the trials.
Note that the author states only three conditions. Please use the five conditions listed above when
checking to see whether a random experiment is a binomial experiment.
We let X = # of Successes in the n trials. The possible values of X are 0, 1, 2, 3, …, n. For a given x
{0, 1, 2, …, n}, what is P(X = x)?
One way that we can have exactly x Successes out of n trials is for the first x trials to result in Success
and the remaining n – x trials to result in failure. If the trials are independent (the outcome of one trial
is unrelated to the outcome of any other trial), then
P(x Successes followed by n-x Failures) =
p x 1 p
n x
.
3
Any other ordering of x Successes and n – x Failures will have the same probability of occurring. How
many such orderings are there?
Defn: Given a set of n objects, the number of ways to choose a subset of x of the objects is given by
the binomial coefficient:
n
n!
x x ! n x ! .
The number of different orderings of x Successes and n – x Failures is the same as the number of ways
of choosing x of the n trials to be Successes.
Hence, the probability that there will be exactly x Successes in n Bernoulli trials is given by:
n
n x
P X x p x 1 p ,
x
or x = 0, 1, …, n.
Example: Let’s go back to our random experiment of flipping a fair coin 10 times. Let X = number of
heads that occur. Does this satisfy the conditions of being a binomial experiment?
10
5
5
P X 5 0.5 0.5 0.24609375
5
We have
.
5
10
x
10 x
0.6230 . Clearly the calculations can
What about P(X 5)? P X 5 0.5 0.5
x 0 x
become tedious.
To find binomial probabilities using Excel: If X ~ binomial(n, p), and we want to find P(X x), then
in the cell of the worksheet, enter
=BINOMDIST(x, n, p, TRUE).
In our example, we want to find P(X 5). In cell A1, we enter
=BINOMDIST(5,10,0.5,TRUE)
We get 0.6230.
If we want P(X = 5), we enter
=BINOMDIST(5,10,0.5,TRUE) – BINOMDIST(4,10,0.5,TRUE) We get 0.2461.
If we want P(X > 5), we enter
=1-BINOMDIST(5,10,0.5,TRUE)
We get 0.3770.
To find binomial probabilities using the TI-83/84 calculator: If X ~ binomial(n, p), and we want to find
P(X = x) or P(X ≤ x), refer to the calculator handout.
Examples of Binomial Experiments:
1) Assume that the date is October 15, 2012. We want to predict the outcome of the Presidential
election. We will assume, for simplicity, that there are only two candidates, President Barack Obama
4
and former Governor Sarah Palin. We select a simple random sample of n = 1068 voters from the
population of all eligible, registered, and likely voters. We ask each voter in the sample, “Do you
intend to vote for President Obama?” Let X = number of voters in the sample who plan to vote to reelect President Obama. Is this a binomial experiment? We need to check to see whether each of the
five conditions is satisfied.
2) A worn machine tool produces 1% defective parts. We select a simple random sample of 25 parts
produced by this machine, and let X = number of defective parts in the sample.
3) I give a pop quiz to the class consisting of 10 multiple choice questions, each with four possible
responses, only one of which is the correct response. A student has been goofing off all semester, and
comes to class totally unprepared for the quiz. He decides to randomly guess the answer to each
question. Let X = his score on the quiz.
4) It is known that of the entire population of adults in Florida, 5% have a certain blood type. We
select a random sample of Florida and obtain blood samples to test. Let X = number of people in the
sample who have the blood type.
Example: p. 88, first example
The Hypergeometric Distribution
Consider the following situation. You are working in quality control for a manufacturer of PC’s. Your
company has just received a large shipment (of size N) of identical electronic components that are to
be used in producing a particular type of PC. Your company has a policy that, if the proportion of
defective components in a shipment exceeds 2%, the shipment will not be accepted. It is impractical to
test each of the N components for defects. Hence, you will select a random sample of size n from the
shipment and test each component in the sample for defects. If the number of defective components in
the shipment is a, how likely is it that you will discover a certain number, x, of defective components
in the sample? You will select the sample from the shipment in such a way that, after each component
is selected, each of the remaining components in the shipment has an equal chance of being selected
next. This is an exercise in sampling without replacement. If we replace each component selected
before selecting the next, so that a component could possibly be selected more than once, then we are
doing sampling with replacement, and the binomial distribution would be the correct distribution to
use.
The total number of ways of selecting a sample of size n from the shipment is given by
𝑁
( ).
𝑛
If there are a defective components in the shipment and N – a non-defective components, then the
number of ways of choosing a sample of size n and obtaining x defective components and n – x nondefective components is, using our counting rules,
𝑎 𝑁−𝑎
( )(
).
𝑥 𝑛−𝑥
Defn: A discrete random variable X is said to have a hypergeometric distribution with parameters N,
a, and n if the p.m.f. of X is given by
5
𝑎 𝑁−𝑎
( )(
)
𝑥 𝑛−𝑥
𝑓(𝑥) = 𝑃(𝑋 = 𝑥) =
,
𝑁
( )
𝑛
for x = 0, 1, 2, 3, …, n, subject to the conditions that x cannot exceed a and n-x cannot exceed N-a.
Note: If the sample size is much smaller than the population size, then we may approximate the
𝑎
Hypergeometric(N, a, n) distribution with a Binomial(n, 𝑁) distribution. (In fact, in almost all cases in
which a binomial distribution is used, we are approximating a hypergeometric. The binomial
distribution is mathematically more tractable than the hypergeometric distribution.)
Example: p. 90, at top.
Mean and Variance of a Discrete Distribution
n
Defn: The mean, or expectation, or expected value, of a discrete r.v. X is given by xi f xi .
i 1
Defn: The variance of a discrete r.v. X is given by
n
2 xi f xi
2
i 1
.
The standard deviation of X is just the square root of the variance.
Note: It is generally easier to calculate the variance using the equivalent formula
n
xi2 f xi 2
2
i 1
.
Example: The random experiment is to flip a fair coin twice. Let X = number of heads.
We found the distribution of X earlier. We want to find the expected number of heads, and the
variance and standard deviation of X. First, the mean is given by
2
𝜇 = ∑ 𝑥𝑓(𝑥) = (0)(0.25) + (1)(0.50) + (2)(0.25) = 1.
𝑥=0
After we have calculated the mean, we need to calculate the second moment of the distribution
2
∑ 𝑥 2 𝑓(𝑥) = (0)(0.25) + (1)(0.50) + (4)(0.25) = 1.5.
𝑥=0
If we subtract the square of the mean from the second moment, we obtain the variance:
2
𝜎 2 = ∑ 𝑥 2 𝑓(𝑥) − 𝜇 2 = 1.5 − 1 = 0.50,
𝑥=0
and the standard deviation
2
𝜎 = √∑ 𝑥 2 𝑓(𝑥) − 𝜇 2 = √0.50 = 0.7071.
𝑥=0
6
Interpretation of the mean of the distribution: The random experiment is to flip a fair coin twice and
count the number of heads that occur. If we perform this experiment repeatedly, very many times the
average of the counts obtained will get closer and closer to 1.
The above example is a special case of the binomial distribution.
If X ~ Binomial(n, p), then 𝜇 = 𝐸[𝑋] = 𝑛𝑝. and 𝜎 2 = 𝑉𝑎𝑟(𝑋) = 𝑛𝑝(1 − 𝑝).
Derivation of the mean of a binomial distribution:
By definition,
𝑛
𝑛
𝜇 = ∑ 𝑥𝑓(𝑥) = ∑ 𝑥
𝑥=0
𝑥=0
The first term in the sum is 0, giving
𝑛
𝜇 = ∑𝑥
𝑥=1
𝑛!
𝑝 𝑥 (1 − 𝑝)𝑛−𝑥 .
𝑥! (𝑛 − 𝑥)!
𝑛!
𝑝 𝑥 (1 − 𝑝)𝑛−𝑥 .
𝑥! (𝑛 − 𝑥)!
We will factor out n and p from the sum, and use the fact that
𝑥
1
=
,
𝑥! (𝑥 − 1)!
Giving
𝑛
(𝑛 − 1)!
𝜇 = 𝑛𝑝 ∑
𝑝 𝑥−1 (1 − 𝑝)(𝑛−1)−(𝑥−1) .
(𝑥 − 1)! ((𝑛 − 1) − (𝑥 − 1))!
𝑥=1
Next, we change the variable to z = x – 1. We find
𝑛−1
(𝑛 − 1)!
𝑝 𝑧 (1 − 𝑝)(𝑛−1)−𝑧 .
𝑧! ((𝑛 − 1) − 𝑧)!
𝑧=0
But the sum is just the sum of probabilities, over all possible values of a random variable Z that has a
Binomial(n-1, p) distribution. Hence, the sum is 1, and we have
𝜇 = 𝑛𝑝.
Derivation of the variance (using the same technique) is left as a exercise.
𝜇 = 𝑛𝑝 ∑
Example 1: Assume that the date is October 15, 2012. We want to predict the outcome of the
Presidential election. We will assume, for simplicity, that there are only two candidates, President
Barack Obama and former Governor Sarah Palin. We select a simple random sample of n = 1068
voters from the population of all eligible, registered, and likely voters. We ask each voter in the
sample, “Do you intend to vote for President Obama?” Let X = number of voters in the sample who
plan to vote to re-elect President Obama.
The expected number of voters in the sample who will vote to re-elect President Obama is
𝜇 = 𝑛𝑝 = (1068)(𝑝).
If his level of support in the 2012 election were the same as in the 2008 election, then we would expect
that
𝜇 = 𝑛𝑝 = (1068)(0.53) = 566.04
voters in the sample would vote to re-elect the President. The standard deviation of the distribution
would be
𝜎 = √𝑛𝑝(1 − 𝑝) = √(1068)(0.53)(0.47) = 16.3107.
7
Example 2: A worn machine tool produces 1% defective parts. We select a simple random sample of
25 parts produced by this machine, and let X = number of defective parts in the sample.
X ~ Binomial(n = 25, p = 0.01). Therefore, the expected number of defective parts in the sample
would be 𝜇 = 0.25, and the standard deviation of X would be 𝜎 = √(25)(0.01)(0.99) = 0.4975.
What if we selected such a sample and found that there were 2 defective parts in the sample? The
value x = 2 is about 3.5176 standard deviations greater than the expected value under the assumption
that the defect rate is 1%. We would then conclude that the actual defect rate is likely to be higher than
1% (assuming that the sampling was done randomly).
Let the discrete random variable X ~ Hypergeometric(N, a, n). Then the mean of the distribution is
𝑎
𝜇=𝑛 ,
𝑁
and the variance of the distribution is
𝑎
𝑎 𝑁−𝑛
𝜎 2 = 𝑛 ( ) (1 − ) (
).
𝑁
𝑁 𝑛−1
Do these formulae look familiar?
Example: p. 98.
Defn: Let X be a discrete random variable with p.m.f. f(x). We define the kth moment about the origin
to be
𝜇𝑘′ = ∑ 𝑥 𝑘 𝑓(𝑥).
𝑎𝑙𝑙 𝑥
We also define the kth central moment (or the kth moment about the mean) as
𝜇𝑘 = ∑ (𝑥 − 𝜇)𝑘 𝑓(𝑥).
𝑎𝑙𝑙 𝑥
The first moment about the origin is just the mean of the distribution. The second central moment is
the variance of the distribution. Third moments are related to the skewness of the distribution (see
page 89).
Chebyshev’s (aka Tchebychev’s)Theorem
Theorem 4.1: If a probability distribution has mean µ and standard deviation σ < +∞, then for any k ≥
1
1, the probability of obtaining a value of X that deviates from µ by at least kσ is at most 𝑘 2 .
Symbolically, we write
𝑃(|𝑋 − 𝜇| ≥ 𝑘𝜎) ≤
1
.
𝑘2
Equivalently, we can say that
𝑃(|𝑋 − 𝜇| < 𝑘𝜎) ≥ 1 −
1
.
𝑘2
Example: A worn machine tool produces 1% defective parts. We select a simple random sample of 25
parts produced by this machine, and let X = number of defective parts in the sample.
8
X ~ Binomial(n = 25, p = 0.01). Therefore, the expected number of defective parts in the sample
would be 𝜇 = 0.25, and the standard deviation of X would be 𝜎 = √(25)(0.01)(0.99) = 0.4975.
Let k = 2. Then we find that
1
𝑃(|𝑋 − 𝜇| < 𝑘𝜎) = 𝑃(𝜇 − 2𝜎 < 𝑋 < 𝜇 + 2𝜎) ≥ 1 − = 0.75.
4
Assuming that the 1% defect rate is true, the probability that the measure value of X will differ from
the expected count, 𝜇 = 0.25, by no more than 2𝜎 = 0.995, is at least 75%.
Let k = 3. Then we find that
1
𝑃(|𝑋 − 𝜇| < 𝑘𝜎) = 𝑃(𝜇 − 3𝜎 < 𝑋 < 𝜇 + 3𝜎) ≥ 1 − = 0.8889.
9
Assuming that the 1% defect rate is true, the probability that the measure value of X will differ from
the expected count, 𝜇 = 0.25, by no more than 3𝜎 = 0.995, is at least 88.89%.
Poisson Distribution
This distribution provides the model for the occurrence of rare events over a period of time, distance,
or some dimension.
Examples:
1) X = number of cars driving through an intersection in an hour.
2) X = number of accidents occurring at an intersection in a year.
3) X = number of alpha particles emitted by a sample of U-238 over a period of time.
The common characteristics of Poisson processes are these:
We divide the interval of time (distance, etc.) into a large number of equal subintervals.
1) The probability of occurrence of more than one count in a small subinterval is 0;
2) The probability of occurrence of one count in a small subinterval is the same for all equal
subintervals, and is proportional to the length of the subinterval;
3) The count in each small subinterval is independent of other subintervals.
We let X = count of occurrences in the entire interval.
Defn: A discrete r.v. X is said to have a Poisson distribution with mean if the p.m.f. of the
distribution is
e x
f x
, for x = 0, 1, 2, 3, ….
x!
The mean and variance of the distribution are
E X and V(X) = .
Note: We may derive the Poisson distribution as a limiting case of the binomial distribution with the
number of trials going to infinity and the probability of success on each trial going to 0 in such a way
that the mean of the distribution remains constant. This is done in the textbook. Here it is:
Example 1: The number of cracks in a section of interstate highway that are significant enough to
require repair is assumed to follow a Poisson distribution with a mean of 2 cracks per mile.
First, does this situation actually satisfy the Poisson conditions?
a) What is the probability that there are no cracks that require repair in a 5-mile section of highway?
9
b) What is the probability that at least one crack requires repair in a ½ mile section of highway?
Example 2: Contamination is a problem in the manufacture of optical strorage disks. The number of
particles of contamination that occur on an optical1 disk has a Poisson distribution, and the average
number of particles per square centimeter of media surface is 0.1. The area of a disk under study is
100 square centimeters. Find the probability that 12 particles occur in the area under study.
Poisson Processes
Any random process that satisfies the Poisson conditions is called a Poisson process.
Example: p. 107.
Example: p. 108.
Another example occurs in the insurance industry. Assume that an insurance company has a large
number of policyholders who have a certain type of auto-insurance policy. Under certain general
assumptions, accidents occur for policyholders according to a Poisson process with an expected value
of λ. Hence, claims for accidents also are modeled by a Poisson process.
The Geometric Distribution
Let’s go back to the binomial experiment, and relax one of the conditions of the experiment, i.e., we no
longer require that the number of trials in the experiment be fixed. We still require that the trials be
performed identically, that they be independent of each other, that each trial have two possible
outcomes (Success or Failure), and that the probability of Success be the same, p, for each trial. Let
X = the number of trials that must be performed to encounter the first success.
Defn: A discrete random variable X is said to have a Geometric(p) distribution if its p.m.f. is given by
𝑓(𝑥) = 𝑃(𝑋 = 𝑥) = 𝑝(1 − 𝑝)𝑥−1 ,
for x = 1, 2, 3, ….
1
The mean of the Geometric(p) distribution is 𝜇 = 𝑝. The variance of the distribution is 𝜎 2 =
Example: p. 110, Exercise 4.62
1−𝑝
𝑝2
.