codes-2
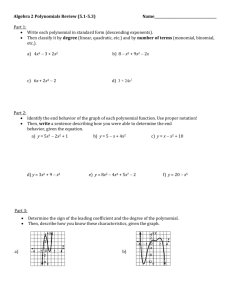
advertisement

Sublinear-Time
Error-Correction and
Error-Detection
Luca Trevisan
U.C. Berkeley
luca@eecs.berkeley.edu
Contents
• Survey of results on error-correcting
codes with sub-linear time checking
and decoding procedures
• Results originated in complexity
theory
Error-correction
x
Encoding
C(x)
Errors
y
i
Decoding
x[i]
Error-detection
x
Encoding
C(x)
Errors
y
Checking
no
Checking
yes
Minimum Distance
If for every x y.d(C ( x ), C ( y))
Then :
error correction problem is solvable
for / 2 errors
error detection problem is solvable
for errors
Also vice - versa
Ideally
• Constant information rate
C (x ) O ( x )
• Linear minimum distance
x x'.d(C(x), C(x' )) (| C() |)
• Very efficient decoding
Sipser-Spielman: linear time
deterministic procedure
Sub-linear time decoding?
• Must be probabilistic
• Must have some probability of
incorrect decoding
• Even so, is it possible?
Motivations & Context
• Sub-linear time decoding useful for
worst-case to average-case
reductions, and in informationtheoretic Private Information
Retrieval
• Sub-linear time checking arises in PCP
• Useful in practice?
Error-correction
Hadamard Code
To encode x {0,1} we write down x, a
n
for all a {0,1}
n
Length of encoding
is 2 , relative min. distance is 1/2
n
Example
Encoding of…
is…
0 0 0
0 0 0 0 0 0 0 0
0 0 1
0 1 0 1 0 1 0 1
0 1 0
0 0 1 1 0 0 1 1
0 1 1
0 1 1 0 0 1 1 0
1 0 0
0 0 0 0 1 1 1 1
1 0 1
0 1 0 1 1 0 1 0
1 1 0
0 0 1 1 1 1 0 0
1 1 1
0 1 1 0 1 0 0 1
“Constant time” decoding
Want to compute xi x, ei
Pick random a,
read x,a and x, a ei
from encoding
Xor the two results
Analysis
Each of two queries is uniform.
If there is fraction of errors,
there is prob. 1 2 of getting
both answers right, and so
getting xi right.
Goldreich - Levin; Blum - Luby - Rubinfeld
A Lower Bound
• If: the code is linear, the alphabet is
small, and the decoding procedure
uses two queries
• Then exponential encoding length is
necessary
Goldreich-Trevisan, Samorodnitsky
More trade-offs
• For k queries and binary alphabet:
Encoding length 2
n1 /( k 1)
is possible (no polynomial s)
BFLS, CGKS, A, Kushilevit z - Ishai
Encoding length nk /(k 1) is necessary
Katz - Trevisan
• More complicated formulas for bigger
alphabet
Construction without
polynomials
View x as n n matrix
For each subsets A, B [ n ] write aA,bB x[a, b]
Exercise : reconstruc t x[i, j] with 4 uniformly
distribute d queries
If fraction of errors, then prob. 1 4
of correct decoding
Note : encoding length 2 2
It's possible to do better
n
Construction with
polynomials
• View message as polynomial p:Fk->F
of degree d (F is a field, |F| >> d)
• Encode message by evaluating p at all
|F|k points
• To encode n-bits message, can have
|F| polynomial in n, and d,k around
(log n)O(1)
To reconstruct p(x)
• Pick a random line in Fk passing through x;
• evaluate p on d+1 points of the line;
• by interpolation, find degree-d univariate
polynomial that agrees with p on the line
• Use interp’ing polynomial to estimate p(x)
• Algorithm reads p in d+1 points, each
uniformly distributed
Beaver-Feigenbaum; Lipton;
Gemmel-Lipton-Rubinfeld-Sudan-Wigderson
x+(d+1)y
x
x+y
x+2y
Error-detection
Checking polynomial codes
• Consider encoding with multivariate
low-degree polynomials
• Given p, pick random z, do the
decoding for p(z), compare with
actual value of p(z)
• “Simple” case of low-degree test.
• Rejection prob. proportional to
distance from code. Rubinfeld-Sudan
Bivariate Code
• A degree-d bivariate polynomial p:F x F -> F can
be represented as 2|F| univariate degree-d
polynomials (the “rows” and the columns”)
2x2 + xy + y2 + 1 mod 5
Y2+ Y2+
1
y+3
1
3
4
4
3
Y2+2y Y2+3y Y2+4y 2x2
+4
+4
+3
+1
2
0
2
3
3
0
4
2
4
0
0
0
4
2
4
2
3
3
2
0
2x2+x 2x2 2x2
+2
+2x +3x
2x2+4x
+2
Bivariate Low-Degree Test
• Pick a random row and a random
column. Chek that they agree on
intersection
• If |F| is a constant factor bigger
than d, then rejection probability is
proportional to distance from code
Arora-Safra, ALMSS,
Polishuck-Spielman
Efficiency of Decoding vs
Checking
Can encode n bits of informatio n using
n/log n elements of an alphabet of size 2
n log n
and do checking with 2 queries
Regardless of alphabet size, impossible to
achieve constant informatio n rate if decoding
uses o(log n / log log n) queries
Tensor Product Codes
• Suppose we have a linear code C with
codewords in {0,1}^m.
• Define new code C’ with codewords in
{0,1}^(mxm);
• a “matrix” is a codeword of C’ if each row
and each column is codeword for C
• If C has lots of codeword and large
minimum distance, same true for C’
Generalization of the
Bivariate Low Degree Test
• Suppose C has K codewords
• Define code C’’ over alphabet [K], with
codewords of length 2m
• C’’ has as many codewords as C’
• For each codeword y of C’, corresponding
codeword in C’’ contains value of each row
and each column of y
• Test: pick a random “row” and a random
“column”, check intersection agrees
• Analysis?
Negative Results?
• No known lower bound for locally
checkable codes
• Possible to get encoding length
n^(1+o(1)) and checking with O(1)
queries and {0,1} alphabet?
• Possible to get encoding length O(n)
with O(1) queries and small alphabet?
Applications?
• Better locally decodable codes have
applications to PIR
• General/simple analysis of checkable
proofs could have application to PCP
(linear-length PCP, simple proof of
the PCP theorem)
• Applications to the practice of faulttolerant data storage/transmission?