Part of Speech tagging (Ido, )
advertisement
")
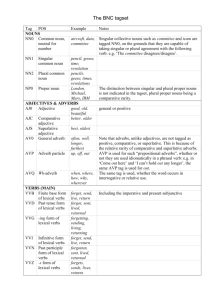
Parts of Speech • Generally speaking, the “grammatical type” of word: – Verb, Noun, Adjective, Adverb, Article, … • We can also include inflection: – – – – Verbs: Tense, number, … Nouns: Number, proper/common, … Adjectives: comparative, superlative, … … • Most commonly used POS sets for English have 50-80 different tags BNC Parts of Speech • Nouns: NN0 Common noun, neutral for number (e.g. aircraft NN1 Singular common noun (e.g. pencil, goose, time NN2 Plural common noun (e.g. pencils, geese, times NP0 Proper noun (e.g. London, Michael, Mars, IBM • Pronouns: PNI Indefinite pronoun (e.g. none, everything, one PNP Personal pronoun (e.g. I, you, them, ours PNQ Wh-pronoun (e.g. who, whoever, whom PNX Reflexive pronoun (e.g. myself, itself, ourselves • Verbs: VVB finite base form of lexical verbs (e.g. forget, send, live, return VVD past tense form of lexical verbs (e.g. forgot, sent, lived VVG -ing form of lexical verbs (e.g. forgetting, sending, living VVI infinitive form of lexical verbs (e.g. forget, send, live, return VVN past participle form of lexical verbs (e.g. forgotten, sent, lived VVZ -s form of lexical verbs (e.g. forgets, sends, lives, returns VBB present tense of BE, except for is …and so on: VBD VBG VBI VBN VBZ VDB finite base form of DO: do …and so on: VDD VDG VDI VDN VDZ VHB finite base form of HAVE: have, 've …and so on: VHD VHG VHI VHN VHZ VM0 Modal auxiliary verb (e.g. will, would, can, could, 'll, 'd) • Articles AT0 Article (e.g. the, a, an, no) DPS Possessive determiner (e.g. your, their, his) DT0 General determiner (this, that) DTQ Wh-determiner (e.g. which, what, whose, whichever) EX0 Existential there, i.e. occurring in “there is…” or “there are…” • Adjectives AJ0 Adjective (general or positive) (e.g. good, old, beautiful) AJC Comparative adjective (e.g. better, older) AJS Superlative adjective (e.g. best, oldest) • Adverbs AV0 General adverb (e.g. often, well, longer (adv.), furthest. AVP Adverb particle (e.g. up, off, out) AVQ Wh-adverb (e.g. when, where, how, why, wherever) • Miscellaneous: CJC Coordinating conjunction (e.g. and, or, but) CJS Subordinating conjunction (e.g. although, when) CJT The subordinating conjunction that CRD Cardinal number (e.g. one, 3, fifty-five, 3609) ORD Ordinal numeral (e.g. first, sixth, 77th, last) ITJ Interjection or other isolate (e.g. oh, yes, mhm, wow) POS The possessive or genitive marker 's or ' TO0 Infinitive marker to PUL Punctuation: left bracket - i.e. ( or [ PUN Punctuation: general separating mark - i.e. . , ! , : ; - or ? PUQ Punctuation: quotation mark - i.e. ' or " PUR Punctuation: right bracket - i.e. ) or ] XX0 The negative particle not or n't ZZ0 Alphabetical symbols (e.g. A, a, B, b, c, d) Task: Part-Of-Speech Tagging • Goal: Assign the correct part-of-speech to each word (and punctuation) in a text. • Example: Two old men bet on the game CRD AJ0 NN2 VVD PP0 AT0 NN1 . PUN • Learn a local model of POS dependencies, usually from pre-tagged data • No parsing Hidden Markov Models • Assume: POS (state) sequence generated as timeinvariant random process, and each POS randomly generates a word (output symbol) 0.2 AJ0 0.2 “a” 0.6 0.3 0.3 NN2 0.5 AT0 “the” 0.4 “cats” “men” 0.9 0.5 NN1 0.1 “cat” “bet” Definition of HMM for Tagging • Set of states – all possible tags • Output alphabet – all words in the language • State/tag transition probabilities • Initial state probabilities: the probability of beginning a sentence with a tag t (t0t) • Output probabilities – producing word w at state t • Output sequence – observed word sequence • State sequence – underlying tag sequence HMMs For Tagging • First-order (bigram) Markov assumptions: – Limited Horizon: Tag depends only on previous tag P(ti+1 = tk | t1=tj1,…,ti=tji) = P(ti+1 = tk | ti = tj) – Time invariance: No change over time P(ti+1 = tk | ti = tj) = P(t2 = tk | t1 = tj) = P(tj tk) • Output probabilities: – Probability of getting word wk for tag tj: P(wk | tj) – Assumption: Not dependent on other tags or words! Combining Probabilities • Probability of a tag sequence: P(t1t2…tn) = P(t1)P(t1t2)P(t2t3)…P(tn-1tn) Assume t0 – starting tag: = P(t0t1)P(t1t2)P(t2t3)…P(tn-1tn) • Prob. of word sequence and tag sequence: P(W,T) = i P(ti-1ti) P(wi | ti) Training from Labeled Corpus • Labeled training = each word has a POS tag • Thus: PMLE(tj) = C(tj) / N PMLE(tjtk) = C(tj, tk) / C(tj) PMLE(wk | tj) = C(tj:wk) / C(tj) • Smoothing applies as usual Viterbi Tagging • Most probable tag sequence given text: T* = arg maxT Pm(T | W) = arg maxT Pm(W | T) Pm(T) / Pm(W) (Bayes’ Theorem) = arg maxT Pm(W | T) Pm(T) (W is constant for all T) = arg maxT i[m(ti-1ti) m(wi | ti) ] = arg maxT i log[m(ti-1ti) m(wi | ti) ] • Exponential number of possible tag sequences – use dynamic programming for efficient computation w1 t1 -2.3 t0 w2 -1.7 t1 -3 -6 -0.3 -1.7 2 t -1.7 t1 -7.3 -0.3 t2 -4.7 -3.4 -1.3 -1 w3 t2 -10.3 -1.3 t3 -2.7 t3 -6.7 t3 -9.3 -log m t1 t2 t3 -log m w1 w2 w3 t0 2.3 1.7 1 t1 0.7 2.3 2.3 t1 1.7 1 2.3 t2 1.7 0.7 3.3 t2 0.3 3.3 3.3 t3 1.7 1.7 1.3 t3 1.3 1.3 2.3 Viterbi Algorithm 1. 2. 3. D(0, START) = 0 for each tag t != START do: D(1, t) = - for i 1 to N do: a. for each tag tj do: D(i, tj) maxk D(i-1,tk) + lm(tktj) + lm(wi|tj) Record best(i,j)=k which yielded the max 4. 5. log P(W,T) = maxj D(N, tj) Reconstruct path from maxj backwards Where: lm(.) = log m(.) and D(i, tj) – max joint probability of state and word sequences till position i, ending at tj. Complexity: O(Nt2 N)