Annexes??
The graph (cfr annexes) shows the most significant variables selected by the Principal
Component Analysis in order to construct the two first factors. The interpretation is quite
simple: the most significant variables are near the unit circle and the projection of each vector
on the axes represents the contribution of the variable to the construction of the axe.
Figure 1: Representation of the variables on the first 2 factors
As we can see, the ratios “loan loss provisions/average assets” and “loan loss
provisions/average net loans” are the most important for the construction of the first factor,
which ratios related tot the asset quality of the bank.
The highest values of the vector-projection on the second factor are for the ratios “liquid
assets/total assets” and “liquid assets/total dep & borrowing”. The second indicates thus the
liquidity of the bank.
Variables
We selected 12 variables relating to the profitability, capital, liquidity, asset quality and the
growth in order to see if those variables can explain the ratings, as shown in the following
table.
Table 1: Variables included in the PCA
Return On Equity
Profitability Non interest income/revenues
Non interest expenses/revenues
Equity/net loans
Capital
Common equity/net loans
Liquid assets/total dep and bor
Liquidity Liquid assets/total assets
Loan loss provisions/average assets
Asset
quality
Loan loss provisions/average net loans
Growth
Pretax income growth
1
7
8
2
4
11
3
5
6
10
Profitability: The higher profitability the better a banks rating. We expect thus those variables
having a positive impact on the ratings.
Capital adequacy and leverage: The more equity an institution has the more buffer they have
against the risk. We expect that the less the capital ratios are the worse the rating will be.
Asset quality: Default risk gives a lower rating and has an important influence on the rating
especially in commercial and saving banks. Good proxies to measure that risk are:
o Loan loss provisions/total assets: As already explained this measure seems us
more a measure for credit risk than for profitability. The reason to include it is
obvious. The higher this ratio the more it is exposed to the risks that the
illiquid loans have.
o Loan loss provisions/Total loans(expected): We look at the influence of the
provision make on the expected total loans. The higher this ratio the more
defaults they expect and it is thus a negative relation to the rating.
Methodology
The Factor Analysis
The purpose of the Factor Analysis is to reduce the dataset. We are going to use this statistical
method in order to replace our set of variables by several principal components. The
advantage of this methodology is that we make a data-reduction and that we get components
that are not linearly correlated with each other. The second step will be to analyze the way
these factors were constructed to understand what they represent (in our case, liquidity,
profitability, capital, asset quality, growth).The last part of our analysis will be to introduce
the factor scores into a Logit Model.
The Logit Model
Results
Communalities
Initial
1.000
Extraction
.399
EQULOAN
1.000
.646
LIQASSET
1.000
.896
COMEQLOA
1.000
.667
LLPASSET
1.000
.890
LLPLOANS
1.000
.792
NONININC
1.000
.610
NONINEXP
1.000
.526
PRETAXIN
1.000
.246
ROE
DEPBOR
1.000
.907
Extraction Method: Principal Component Analysis.
The extraction column shows the variance of each variable explained by the principal
components. We can notice that most of the variables are well represented by the factors,
except the pretax income growth.
Table 2: KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of
Sampling Adequacy.
Bartlett's Test of
Sphericity
Approx. Chi-Square
df
Sig.
,488
870,622
45
,000
In order to do a Factor Analysis, we need sufficient correlation between the variables included
in the model. This is the reason why we ask for the Bartlett’s test before running the program.
Indeed, the two tests above indicate the suitability of our data for structure detection.
The Kaiser-Meyer-Olkin Measure of sampling adequacy indicates the proportion of variance
in our variables that might be caused by underlying factors.
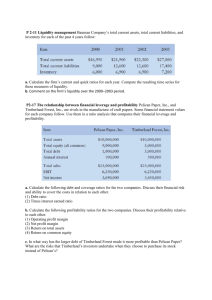
Table 3: Variability explained
Component
Extraction Sums of Squared Loadings
1
Total
2.810
% of Variance
28.103
Cumulative %
28.103
2
2.452
24.524
52.627
3
1.316
13.160
65.787
4
.904
9.044
74.831
5
.863
8.625
83.456
6
.814
8.144
91.600
7
.472
4.720
96.320
8
.317
3.170
99.489
9
.044
.440
99.930
10
.007
.070
Extraction Method: Principal Component Analysis.
100.000
This table shows the percentage of variability of the initial variables explained by each
component. As we can see, the four first factors represent more or less 75% of the total
information. This also means that we will loose 25% of the information by introduce these
factors instead of the initial variables in the Logit Model.
The following graph gives an indication about the number of factors that should be used.
Indeed, it illustrates the eigenvalue of each component. As we can see, there is a sharp decline
of the curve until the fourth factor. This is the reason why we will limit ourselves to the use of
four factors in the Logit Model, which is the next step of our analysis.
Figure 2: Scree plot
Scree Plot
3,0
2,5
2,0
1,5
Eigenvalue
1,0
,5
0,0
1
2
3
4
5
6
7
8
9
10
Component Number
The next table shows the components of each variable for each factor.
Table 4: Rotated Component Matrix(a)
ROE
EQULOAN
LIQASSET
COMEQLOA
LLPASSET
LLPLOANS
NONININC
NONINEXP
PRETAXIN
DEPBOR
1
0.086
0.299
0.982
0.107
-0.065
0.111
0.000
0.142
-0.054
0.976
Component
2
3
-0.008
-0.044
-0.015
0.283
0.014
0.055
-0.021
0.945
0.925
-0.027
0.973
-0.005
0.280
-0.199
0.257
0.002
-0.063
0.036
0.043
0.073
4
0.993
-0.012
0.051
-0.051
0.046
-0.049
0.066
-0.004
-0.047
0.059
Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization.
a Rotation converged in 4 iterations.
This table gives an indication of what the factors represent.
From the analysis of this table, the variables that are most highly correlated with the first
component are “Loan loss provisions/average assets” and “Loan loss provisions/average net
loans”. We can thus interpret the first factor as representing the asset quality. We would
expect a negative impact of those variables on the ratings because large loan loss provisions
ratios mean that the bank faces a large default risk.
This factor gives an indication of the liquidity of the banks because it was mainly constructed
by the ratios “Liquid assets/total deposits and borrowings” and “Liquid assets/total assets”.
On one hand, we would expect this factor having a negative impact on the ratings because
high liquid assets also mean lower return of those assets. On the other hand, high liquidity can
be a good thing for a bank.
The third factor is mostly correlated with the variable “Common equity/net loans”, which is a
variable describing the capital. We expect this component having a positive impact on the
ratings.
Concerning the fourth component, we can say that the highest correlation concerns the
variable “Return on Equity”. We can thus interpret this factor as representing the profitability
of the banks. We expect a positive influence of this component on the ratings but must be kept
in mind that this factor explains only 9% of the total variability.
The Logit model
Dependent Variable: RATINGS
Method: ML - Ordered Logit
Date: 03/08/04 Time: 18:43
Sample(adjusted): 1 127
Included observations: 111
Excluded observations: 16 after adjusting endpoints
Number of ordered indicator values: 7
Convergence achieved after 4 iterations
Covariance matrix computed using second derivatives
Coefficient
Std. Error
z-Statistic
Prob.
FAC1
FAC2
FAC3
FAC4
-0.327560
-0.254750
-0.232040
0.444867
0.175489
0.165797
0.170704
0.165707
-1.866553
-1.536521
-1.359314
2.684660
0.0620
0.1244
0.1740
0.0073
-6.716827
-6.646280
-1.958915
3.816357
6.988979
7.119057
0.0000
0.0000
0.0501
0.0001
0.0000
0.0000
Limit Points
LIMIT_4:C(5)
LIMIT_5:C(6)
LIMIT_6:C(7)
LIMIT_7:C(8)
LIMIT_8:C(9)
LIMIT_9:C(10)
Akaike info criterion
Log likelihood
Restr. log likelihood
LR statistic (4 df)
Probability(LR stat)
-3.475092
-1.793099
-0.395201
0.810834
2.013006
3.040442
3.555554
-187.3333
-194.8520
15.03751
0.004624
0.517371
0.269790
0.201745
0.212463
0.288026
0.427085
Schwarz criterion
Hannan-Quinn criter.
Avg. log likelihood
LR index (Pseudo-R2)
3.799656
3.654579
-1.687687
0.038587
 0
0