Dear students, you must test your nearest neighbor algorithms on
advertisement

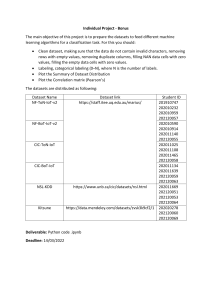
Dear students, you must test your nearest neighbor algorithms on two datasets, one big and one small. You must show your results on the small dataset to a TA or myself before running your algorithm on the big dataset. Here is the method you must use to figure out with datasets to work on. If you work on the wrong datasets, you will get zero credit for this project. 1) For the small dataset, the file number should be the day you were born on. For example, if you were born on 3 day of the month, use cs170_NN_small_test_3.txt, if you were born on Xmas day, use cs170_NN_small_test_25.txt Run your algorithms, you need to figure out which features is the best subset to keep. Count starting from the first column (although the first column is not really a feature, it is the class label). When you are sure you have the right answer, tell the TA something like this… “The best features are 3, 5, 9, 12 and 27, and by using only those, I can get an accuracy of 74.5%” The TA will check this against my reference file, if the results (mostly*) agree, congratulations! Move on the big dataset, if not you have a problem with your code. 2) For the big dataset, add up the last 3 digits of you student ID, and add one. This is the file number you must work on. For example, ****-**-9231 should work on cs170_NN_test_7.txt Good Luck, eamonn * It is possible that the true best features are A, B C and D, but your algorithms finds B, C, D and E, that is, you missed a good feature, and you introduced a bad one. However, your results should substantially agree with the known best results. If you really want to be sure, you can run your code on another random dataset and check with the TA, however, only the assigned datasets results should appear in the report you write.