doc
advertisement

Multi-Document Summarization: Two
Methods
by Pieter Buzing
May 2001
In this paper we will discuss and compare two methods
for multi document summarization. One approach is
concerned with the explicit meaning of words and viewing
them as concepts, who's (semantic) relations explicitly
represent context. The second approach is more top-down
in its attempt to identify the salient parts of the source
documents. It starts at the paragraph level, which forms
the base for further processing. After comparison we
conclude that the second approach is slightly favorite.
1
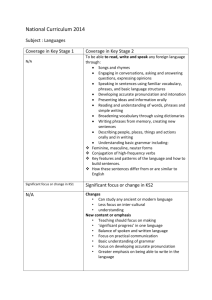
Introduction
For many organizations it is of major importance to archive documents (which are of
relevance in a certain domain or research field) in a database. This database can be
used to search for articles that cover a certain topic. There are three main problems
here. First, it is often hard to judge whether a document is relevant or not. Second, it
is not easy to see the relationships between the documents. Third, these databases can
become very large, resulting in a large number of articles that are returned after a
search query. Even the summaries of those single documents can be too much to
make sense out of it.
Due to the extreme increase in available information in the form of news articles and
scientific documents more and more attention is given to multi-document
summarization, i.e. systems that create a (relatively short) text that gives a good
reflection of the main topics in a set of documents.
I will discuss and compare two techniques that aim to construct good multi-document
summaries. The first method (which we shall address as Conceptual Graph Matching)
is proposed in [Mani & Bloedorn 1997]. It starts at the word level, constructing a
semantic graph of each document. Then it moves up to sentence level, selecting
salient phrases (i.e. phrases that have commonly used concepts) for the summary
Another approach (Theme Recognition) can be found in [McKeown et al. 1999]. It
starts at the paragraph level, considering the complete set of documents, and groups of
paragraphs that are alike into a so-called theme. Then it examines the grammatical
structure of phrases in each theme. It selects the most important phrases from each
theme for the summary.
1
In sections 2 and 3 I will give a more detailed description of the two methods. In the
following section the two approaches will be compared considering content
representation, information fusion, semantics preservation, scalability and domain
independence. These are the factors that we suspect to give the greatest difference
between the two. Section 5 will discuss alternative techniques that have been
developed as well as a few suggestions for improvements of the two methods are
given. Section 6 will give the conclusions of the comparison.
2
The Graph Matching Method
It takes as input a pair of documents. Although Mani and Bloedorn never
implemented a real multi-document version, expanding their method from two to n
documents should not pose much problems. I will go into this in section 4.4. A topic
description also has to be supplied, which can be a (short) text or just a (wellformulated) question. It is used to determine the subjects that are of interest to the
user.
Section 2.1 will give information on the structure of the graphs. Section 2.2
will the spreading activation algorithm. In Section 2.3 the information fusion
algorithm can be found.
2.1
Data structure
Each text is then represented as a graph. Each word occurrence is mapped as a
node (see figure 1). The connections between different nodes represent specific
relations between the words. The ADJ link is the edge between two adjacent words.
The PHRASE link ties together (adjacent) words that form a phrase together. For the
subtask of identifying different phrases an extensive regular-expression-based
sentence boundary disambiguator developed by John Aberdeen (see [Aberdeen 1995])
was used. The SAME link connects two occurrences of the same concept. These
words can be identical or the single/plural forms of the same concept. The NAME
link connects adjacent nodes that together represent a concept. To extract the names
the SRA's NetOwl (see [Krupka 1995]) was used. The COREF link connects name
occurrences that are co-referential. Alpha links represent any semantic association
link between two concepts. For example "president" is an alpha link between "Bill
Gates" and "Microsoft". Mani and
Bloedorn used a corpus-sensitive approach
proposed by Philip Resnik in [Resnik
NAME
1993] that uses a TREC reference corpus.
2.2
ADJ
Spreading activation
ADJ
COREF
A node is given an initial weight
value, roughly calculated by the number of
occurrences in the document. Then a
spreading activation technique (based on
[Chen et al. 1994]) is used to determine the
2
NAME
ADJ
ADJ
Figure 1: An example graph
representation.
salient nodes. Nodes that are identical to words in the topic description are considered
as input nodes. All the nodes connected to an input node are then taken as output
nodes and the activation of the input node is propagated (with an exponentially
decaying function of the activation weight and distance between the nodes) to the
connected output nodes. Then the nodes that are connected to the current output nodes
are considered the new output nodes and the activation of the input nodes is
propagated to these leaves. This is done iteratively until all the nodes (or an arbitrary
maximum number of nodes) have been reached. Apart from some details (like a
different propagation function for different types of links and a bigger activation
propagation for words that are within the same sentence) this covers the whole
activation algorithm. The idea is of course that words that are mentioned in the topic
description should be considered important and that nodes that are connected to these
topic nodes are also relevant. Concepts (nodes) that are connected to many topic
nodes (keep in mind that there can be some nodes in between) should be considered
more salient than words that have little connectivity with input nodes.
2.3
Information fusion
With the two graphs (G1 and G2) we start out to find the similarities and
differences in the documents. The FSD (Find Similarities and Differences) algorithm
works as follows. We create two sets of nodes: one with the common nodes and one
with differences. The sets are given by:
Common = {c|concept_match(c, G1) & concept_match(c, G2)}
Differences = (G1 G2) – Common
concept_match(c, G) is true iff c1 G such that c1 is a topic term or c and c1 are
synonyms.
Now we can select the phrases for the summary. We want to include “common”
sentences (sentences that have a lot of nodes in both graphs) and "different" sentences
(sentences that have a lot of unique words). The ratio of common sentences to
different sentences is a parameter that the user can specify. The “common” score of a
sentence s is calculated by:
score ( s )
1
|c ( s )|
weight ( wi ), where c( s ) {w | w Common s}
| c( s ) | i 1
It means that the score of a sentence is defined as the average of the weight value of
each word in s that is common. The “difference” score of a sentence is calculated the
same way.
The best “common” sentences (i.e., the sentences that have a high score on the
common word set) and the best “different” sentences are selected for the summary.
3
3
The Theme Recognition Method
As input we consider a set of documents. As opposed to the previous system the
number of articles is not limited and a topic description is not required. The algorithm
consists of three steps: first (section 3.1) it identifies themes of a given document
collection. Then (section 3.2), from each theme the important phrases are selected.
This is done by analysis of the grammatical structures of the phrases in each theme:
the phrases with the most common structures are chosen for the summary. In the final
step (section 3.3) these selected phrases are properly placed in the multi-document
summary. See also figure 2.
3.1
theme identification.
First the texts are unraveled into paragraph units, which are then thrown on one big
pile: the document level is behind us. A theme is a set of paragraphs that are similar
with respect to nouns and meaning. So focus is not only on the word-level similarity,
but also on the semantic relations. Now, all the paragraphs must be determined upon
their pairwise similarity. McKeown used four basic features to decide how similar
two text units (paragraphs) are.
-Word co-occurrence: if the text units have many (stemmed) words in common they
have a high similarity.
-Matching noun phrases: the LinkIt tool proposed in [Wacholder 1998] is used to
match noun phrases. This algorithm recognizes noun phrase similarities.
-WordNet synonyms: by making use of the WordNet semantic database (see [Miller
et al. 1990]) we can match words with the same meaning.
-Common semantic classes for verbs: presents a classification of verbs, which is used
to match verbs that belong to the same semantic class.
McKeown also uses composite features (this is the pairwise combination of the
primitive features) to match two text units. These composite features are a powerful
means to express similarity constraints, like “two text units must have matching noun
phrases that appear in the same order and with relative difference in position no more
than five”. Matches on composite features indicate that two text units are related both
semantically and
syntactically.
Articles
Having found
1. break into phrases
the pairwise similarity
2. make grammar
rates between
1. break into
trees
paragraphs, they have
paragraphs
Themes 3. match phrase
2. find similarities
to be divided into
trees
groups. This is done by
3. cluster similar
Phrases
a machine learning
para’s
algorithm, which
classifies each pair of
paragraphs as either
Summary Sentences 1. preprocess
similar or dissimilar.
phrases
This information is then
2. construct
used by a clustering
sentences
algorithm, which places
Figure 2: theme identification, information fusion and
the most related
reformulation
4
paragraphs in the same groups, and thus identifies themes. Mind that text units can be
placed in more than one theme.
3.2
information fusion.
Next, phrases are selected that correctly represent the content of the themes. The
problem is that it is not feasible to just select the sentences that best cover the text
units, because non-important embedded phrases will be included and important
additional information may be excluded. Sentences are too rigid, so Mckeown
developed a method to identify salient phrases, instead of complete sentences. Theme
sentences are first run through a statistical phrase parser to identify the functional
roles like subject or object. Then this information are passed on to a rule-based
component, which constructs a dependency grammer tree. These grammer
representations are compared with each other and if the intersection of two (sub)trees
yields a full phrase, it is proposed for the summary. This means that phrases that
occur more than once are considered to bear important information.
3.3
text reformulation.
The phrases that were selected in the previous step must be transformed into decent
English sentences. First the phrases are ordered in such a way that things mentioned
early in the documents should also return in the start of the summary. Then some
additional information like entity descriptions or temporal references may be added.
Finally the summary sentences are constructed by use of the FUF/SURGE sentence
generator. This is a Functional Unification Formalism that makes use of English
grammar rule set called SURGE to build syntactic trees, which are then transformed
to sentences. This tool (like many other language generators of this type) performs
better if a domain description is given, but McKeown claims that the lack of this
semantic background knowledge need not be a great drawback: during the process a
lot of work is done on time sequencing, synonyms, etc.
4
Comparison
In this section I will attempt to compare these approaches on the basis of content
representation, information fusion, semantics preservation, scalability and domain
independence. Unfortunately these two systems have not yet been evaluated head-tohead and an objective test of the accuracy of a summary is not available at this time.
4.1
Content representation
The Graph Matching method represents the document content on its smallest scale:
each word is considered a node in the graph. Through the whole process this word
level is maintained. The content of the different documents is kept apart until the
actual information fusion takes place.
The Theme Recognition method starts at the paragraph level, immediately
dropping the distinction between the source documents. Then it looks at the meaning
5
of the words, searching for concepts that two paragraphs have in common. Then we
move back up again and consider the grammatical tree structure of phrases.
4.2
Information fusion
In the Graph Matching method we simply look at words that are strongly connected
(in some sense) to the topic items. It then calculates the common score and the
difference score for each sentence. The sentences with the highest score are selected
for the summary.
The Theme Recognition method selects phrases that frequently occur in a
theme. Of course there is the problem of paraphrasing, i.e. phrases that say the same
thing with (slightly) different words, like “the group of students walked away” versus
“the students walked away” and “John warned the girl” versus “the girl was warned
by John”. The algorithm checks on this with simple lexical rules to make sure that in
the first example “group of” is ignored and in the second example the active/passive
switch is detected. The algorithm thus correctly concludes that both example pairs
match each other. This only works with the assumption that the two sentences carry
roughly the same meaning, because such a superficial detection of paraphrasing (on a
high syntactic level) does not guaranty that it is actually the case.
4.3
Semantics preservation
The Graph Matching method is very concerned with meaning of words. It is interested
in the relations between concepts: think of the SAME links, the COREF links and the
alpha links.
The Theme Recognition method does not represent these meanings explicit,
but they are captured in two steps. First the paragraphs that have many words in
common are considered related to each other and thus clustered in the same group
(theme), assuming that paragraphs that share the same words tend to share the same
meaning. Second, phrases that occur several times in a theme are considered salient.
4.4
Scalability
The Graph Matching method described by [Mani & Bloedorn 1997] only allows a two
document input. Adapting the system to a greater number of input documents should
not be considered a major problem, though. The number of graphs that the FSD
algorithm can handle is by not limited, but there would be a large conjunction of
concept_matches of G1, G2, ...Gn. This could result in a very slim set of common
words compared to the set of “different” words. On the other hand, the number of
common words could only get larger and as the desired length of the summary will
probably not change dramatically, the quality of the result should not decay.
The McKeown system was tested with a set of 30 documents, which gave
good results according to [McKeown et al. 1999]. Scaling up would not pose any
difficulty (the number of generated themes would probably go slightly up due to the
6
increased diversity of the source documents), assuming that the size of the summary
also grows accordingly. This is caused by the fact that the number of phrases selected
from a theme is constant (with respect to the length of the theme) and the increase in
the number of themes. Results could get awkward when the number of selected
phrases in each theme is forced down.
4.5
Domain independence
The Graph Matching approach is claimed to be very domain independent by Mani and
Bloedorn, but some arguments against are also easy to find. Main drawback is that it
makes use of a (training) corpus. When the input document set is significantly
different from the corpus, the system could well get in trouble: the construction of the
graph could suffer as SAME links or alpha links may not be recognized. Also the
topic description has to be supplied, and a topic text that states too little information
could give rise to a too slim set of common words. But these effects will not be
decisive, as (i) the corpus gives a good general handhold, (ii) the WordNet synonyms
list is quite extensive and (iii) the algorithm that selects the common words
is only dependent on the supplied topic text.
The method advocated by [McKeown et al. 1999] is also domain independent.
Maybe even more than the other method, because the Theme Recognition system
does not need any special topic description. There is only one negative point
considering domain independence (besides maybe the synonyms list and the verb
classification): the matching algorithm could get hampered when certain domain
specific paraphrases are not known.
5
Discussion
First I will give some alternative approaches that have been tried in this field. After
that a few suggestions for improvement on the two methods discussed in this paper
shall be presented.
[Radev and McKeown 1998] present a system called SUMMONS
(SUMMarizing Online NewS articles), which creates briefings for the user on
information that the user is interested in. It was developed for (large data sets of) short
news articles, and producing a briefing rather than a summary. A briefing is different
from a summary, as briefings focus on the subject that the user has indicated interest
in, sometimes ignoring the real subject of the article. So if the user indicates that he is
interested in e.g. Canadian beer, the system will run through a large number of news
articles, returning information he has found on Canadian beer, without giving any
attention to the full content of the source articles. The system uses the output
produced by a MUC-4 system. This Message Understanding System is very domain
specific (MUC-4 is specialized in terrorism) and returns a template with fields like
“source”, “incident”, “victim”, etc. The fact that it is very domain specific is a great
drawback on the system. I think this is why the research group turned to the approach
described in this paper.
[Yang et al. 1998] proposes a statistical method, which is highly domain
independent. But it is restricted to news stories about one event, and the temporal
order is crucial. Yang uses the well known Term Frequency and Inverse Document
Frequency (abreviated as TF*IDF; IDF = N/nt, where N is the total number of
7
training documents and nt the number of training articles that contained term t) to
cluster terms and phrases. The “strongest” terms are placed in the summary, in order
of appearence in the input stream of documents (this is why the temporal order is
important). Two clustering methods were tried, both producing reasonable results,
according to [Yang et al. 1998].
The method proposed in [Mani & Bloedorn 1997] of course lacks a sentence
construction component. This is a crucial step, because without it (i) its value (ie
usefulness for the user) is very limited, (ii) it cannot be tested, and (iii) expanding the
input to more than two documents is not useful since interpretation of the common
and different word set becomes very difficult (the order of the highlighted phrases is
unknown, which makes reading rather awkward).
[McKeown et al. 1999] proposed a system that performs well. The greatest
point of improvement would be to evaluate the created summary from a global
perspective (ie as a whole) and not locally. The algorithm currently facilitates the
check of global cohesion only in the theme construction phase, where the topics are
spread evenly in a number of clusters. This guarantees that the final summary will
cover all the important issues, but the construction of sentences and paragraphs do not
always provide good cohesion. This is a difficult task, but we think that when you
want to build reliable summaries, issues like context and (subtle) interpretation must
be addressed.
6
Conclusion
We presented two multi document summarization techniques. One was developed by
Mani and Bloedorn. It mainly works at the word level, focussing on the semantical
relations between concepts (words or groups of words that express an entity). The
second approach (described in [McKeown et al. 1999]) relies on the fact that
paragraphs in general consist of coherent sentences (ie semantically in accordance
with each other) and that paragraphs that have a lot of words in common usually
express the same meaning.
We compared the two methods on five points.
Content representation: the first approach creates a graph of each word in a
document and draws the semantical relations between words. The second approach
makes use of the paragraph structure and selects phrases that are common in
multiple paragraphs.
Information fusion: in the first approach sentences that seem to have important
words are selected for the summary. The second approach selects phrases that
occur most in a theme.
Semantics preservation: the first approach makes a lot of effort trying to represent
the meaning of concepts; it succeeds well in maintaining the context. The second
approach tries to maintain phrases, which seems a very natural solution.
Scalability: The first approach is restricted to two-document-input, but the idea by
itself is scalable. The second approach is not limited in the number of input
documents and a sizable document set should not be problem, provided that the
size of the summary grows accordingly (otherwise problems may occur).
Domain independence: Both approaches were tested with news paper articles, but
the two researchers claim that their system is applicable to other kinds of
documents. Both systems should be considered domain independent, though we
8
suspect that source documents that are very different from the corpus documents
would give a slight decline in performance for both approaches.
The easiest way to conclude this comparison paper is to say that the Theme
Recognition method is the best, because it is a working application and the Graph
Matching method never got that far. On the other hand, when we look at the results of
the comparison we could express only a slight preference for the second approach
(McKeown), because the scalability of the graph method is still not proven.
References
[Aberdeen 1995] John Aberdeen, John Burger, David Day, Lynette Hirschman,
Patricia Robinson, and Marc Vilain. MITRE: Description of the Alembic System
Used for MUC-6. In Proceedings of the Sixth Message Understanding Conference
(MUC-6), Columbia, Maryland, November 1995.
[Chen et al. 1994] C.H. Chen, K. Basu, and T. Ng. An algorithmic Approach to
Concept Exploration in a Large Knowledge Network. Technical Report, MIS
Department, University of Arizona, Tucson, AZ.
[Krupka 1995] George Krupka. SRA: Description of the SRA System as Used for
MUC-6. In Proceedings of the Sixth Message Understanding Conference (MUC-6).
Columbia, Maryland, November 1995.
[Mani & Bloedorn 1997] Inderjeet Mani and Eric Bloedorn. Multi-document
Summarization by Graph Search and Matching. In Proceedings of the Fifteenth
National Conference on Artificial Intelligence (AAAI-97)
[McKeown et al. 1999] Kathleen R. McKeown, Judith L. Klavans, Vasileios
Hatzivassiloglou, Regina Barzilay and Elezar Eskin. Towards Multidocument
Summarization by Reformulation: Progress and Prospects. In Proceedings of the
Sixteenth National Conference on Artificial Intelligence (AAAI-99) pp 453-460
[Miller et al. 1990] George A. Miller, Richard Beckwith, Christiane Felllbaum, Derek
Gross, and Kathrine J. Miller. Introduction to WordNet: An On-Line Lexical
Database. International Journal of Lexicography, 3(4): pp 235-312.
[Resnik 1993] Philip Resnik. Selection and Information: A Class-Based Approach to
Lexical Relationships. Ph.D. Dissertation, University of Pennsylvania, Philadelphia,
PA.
[Yang et al. 1998] Yiming Yang, Tom Pierce, Jaime Carbonell. A Study on
Retrospective and On-Line Event Detection. In Proceedings of the 21st Annual
International ACM SIGIR Conference on Research and Development in Information
Retrieval, Melbourne, Australia, August 1998.
9