The interplay of root, suffix and whole-word
advertisement
The interplay of root, suffix and whole-word frequency in processing derived words* Cristina Burani and Anna M. Thornton In three lexical decision experiments we investigated whether the relative frequency of root, derivational suffix and whole-word affects processing of Italian printed derived stimuli. Experiment 1 considered pseudowords made up of pseudoroots combined with either high-,medium-, or low-frequency suffixes. Only pseudowords with high-frequency suffixes resulted in increased decision times and higher error rates relative to nonsuffixed pseudowords. Experiments 2 and 3 dealt with suffixed derived words. In Experiment 2, low-frequency words with high-or low-frequency roots and with high or low-frequency suffixes were orthogonally contrasted. Lexical decision latencies were a function of the frequency of both the root and the suffix. However, post-hoc comparisons showed an effect of wholeword familiarity. In Experiment 3, low-frequency derived words with orthogonal variation of root and suffix frequency, and equal whole-word familiarity, were investigated, and were contrasted with low-frequency nonderived words. Words with high-frequency roots showed quicker and more accurate lexical decision responses, irrespective of suffix frequency. By contrast, words with low-frequency roots, irrespectively of suffix frequency, did not differ from nonderived words. These results are interpreted within Schreuder and Baayen’s (1995) parallel dualroute model for morphological processing, as evidence for both benefits and costs of morphemic access, due to the balancing of the quantitative characteristics of root, suffix and whole word. 1. Introduction In most models of morphological processing, it is assumed that the probability of accessing morphological constituents of words is conditioned, at the different processing stages, by many properties of the morphologically complex words. Among these properties, the frequency of morphological constituents relative to the frequency of the complex word as a whole form can play a major role. Evidence for reliance on morphological structure in accessing printed complex words comes from low-frequency words which include higher frequency constituents (see, e.g., Andrews 1986; Burani and Caramazza 1987; Meunier and Segui 1999). In parallel dual-route models of lexical 158 Burani and Thornton access (see, e.g., Burani and Laudanna 1992; Chialant and Caramazza 1995; Frauenfelder and Schreuder 1992; Schreuder and Baayen 1995), words composed of more than one morpheme may activate in parallel two types of access units, namely units corresponding to the whole word and units corresponding to the morphemes included in the stimulus. In these models, the relative frequency of the whole word and of the constituent morphemes affect the relative time-course of activation of the different units in the different components. Hence, frequency is the major determinant of the relative probability that lexical access is either whole-wordbased or morpheme-based. The assumption underlying these models is that the higher the frequency of a given lexical unit, be it a word, a root or an affix, the greater the likelihood that this unit is quickly activated and processed in the different processing components. What is crucial, in determining the probability that lexical access is provided by either whole-word or morpheme processing, is the complex balance existing between the frequency of the whole word and the frequency of its constituent morphemes, both roots and affixes, i.e., it is relative frequency, rather than absolute frequency (for a similar proposal, see Hay 2000; 2001). Hence, it might be predicted that a transparent derived word which has low-frequency in the language, like Italian bassezza (‘lowness’), but is composed of a very frequent root (i.e., bass-, ‘low’) and a very frequent suffix (i.e., -ezza, ‘-ness’) is likely to be accessed via activation of its morphemic constituents, rather than via the unit corresponding to the wholeword, which is supposed to be very scarcely activated. This prediction implies that the frequencies of both the root and the suffix are capable of affecting processing, and calls for evidence concerning the roles of both root and suffix frequency. However, and surprisingly, only the frequency of roots has been considered so far, while the frequency of affixes has been usually neglected. No study on lexical access to derived words has systematically varied the quantitative values of derivational affixes. By contrast, these values have been investigated in the context of pseudoword processing (see below). 1.1. Studies on words Several studies conducted in different languages, including English, Italian, French and Dutch, have shown that access times and accuracy to suffixed The interplay of root, suffix and whole-word frequency 159 derived words are significantly affected by root frequency (see, e.g., Beauvillain 1996; Bradley 1979; Burani and Caramazza 1987; Colé, Beauvillain and Segui 1989; Holmes and O’Regan 1992; Schreuder, Burani, and Baayen 2002). Lexical decisions were faster and more accurate when a suffixed word, usually of low frequency, included a root of high frequency. The facilitatory effect of high-frequency root morphemes was found both when calculation of root frequency included the frequency of the base word and its inflected forms only (Burani and Caramazza 1987), and when it was extended to include the frequencies of all the derived word-forms sharing the same root (Colé, Beauvillain and Segui 1989). The root frequency effect has been found in the context of suffixed derived words that were both orthographically and phonologically transparent with respect to their base root, and were usually transparent for meaning with respect to the meaning of their base. However, there has been evidence of root frequency effects also for derived words that included bound roots, or could be rated as semantically opaque with respect to their base (see, e.g., Holmes and O’Regan 1992; Schreuder, Burani and Baayen 2002). In the studies in which root frequency effects have been found, suffixes were usually productive and had high frequency. Suffix frequency was not directly investigated per se, but it was usually kept constant across categories by including the same suffixes in the high-frequency and lowfrequency root sets. 1.2. Studies on pseudowords An investigation of suffix frequency per se was recently made, by adopting pseudoword contexts made up of illegal root-suffix combinations. Burani et al. (1997) submitted, to both lexical decision and naming, pseudowords that were made up of real roots combined with derivational suffixes not compatible with the root. In order to demonstrate that the probability of access through activation of morphemic units corresponding to suffixes is constrained by their frequency values (see also Laudanna and Burani 1995), Burani et al. (1997) made use of suffixes belonging to two distinct frequency ranges. In one experimental set, roots were combined with highfrequency suffixes, and the resulting pseudowords were contrasted with pseudowords in which the same roots were combined with control sequences that had analogous orthographic frequency in final position of Italian words, but were not suffixes. In the second set, a comparison was 160 Burani and Thornton made between pseudowords composed of roots plus low-frequency suffixes, and the same roots combined with control low-frequency orthographic final sequences. Roots were in both cases of medium frequency. In order to control for asymmetries in the possibility to assign meaning to suffixed pseudowords of the two kinds (i.e., with high- and low-frequency suffixes, respectively), suffixed pseudowords in the two frequency sets were matched for mean interpretability values derived from participants’ empirical ratings. The lexical decision results by Burani et al. (1997) showed that the interference effect which is usually found on pseudowords that include real affixes (see, e.g., Caramazza, Laudanna and Romani 1988; Taft and Forster 1975; see also, for derivational suffixes, Jarvella and Wennstedt 1993) is conditioned by the frequency of the embedded suffixes: Longer reaction times and higher error rates were found, with respect to control pseudowords, only when pseudowords included high-frequency suffixes. By contrast, pseudowords with low-frequency suffixes took no longer to be rejected than control pseudowords. From these results on suffixed pseudowords, Burani et al. (1997) concluded that the probability that suffixes will affect processing is conditioned by their frequency (see also Laine 1996, for Finnish productive derivational suffixes causing interference effects on pseudoword lexical decision). 1.3. Suffix frequency, suffix numerosity, and productivity In considering the frequency of suffixes, two main quantitative measures can be adopted. On the one hand, frequency in the proper sense is calculated on word tokens, by summing up the cumulative frequency in a given corpus of all the word tokens in which a given suffix occurs. On the other hand, suffix frequency can be measured by calculating the number of word types in which a given suffix occurs in a given language. This second measure could be named numerosity of the suffix (as proposed by Burani et al. 1995). There could be reasons for considering numerosity (i.e., suffix typefrequency) as a better quantitative characterization for suffixes and a stronger predictor of performance in access tasks. Suffix numerosity is closely related to suffix productivity thus allowing the suffix to “emerge” as a separate processing unit (see, e.g., Baayen 1989; 1992; Bybee 1995a). However, there is a strong link and a complex interplay among suffix type The interplay of root, suffix and whole-word frequency 161 and token frequency, productivity and probability of morphemic parsing (Hay and Baayen 2002). In the study by Burani et al. (1997), suffix numerosity and suffix frequency were not disentangled because, after inspection of frequency distributions, it was found that suffix token-frequency and suffix numerosity tended to be highly correlated. Suffix frequency was used in a broad sense to subsume the two quantitative measures that could affect processing. Consequently, suffixes were either high or low on both dimensions, frequency and numerosity, calculated on a corpus of Italian written language (Istituto di Linguistica Computazionale CNR 1989). 1.4. Other properties of suffixes relevant for word processing Some recent research has investigated the role of properties of derivational suffixes in lexical access to words (see Bertram, Laine and Karvinen 1999, for Finnish; Bertram, Schreuder and Baayen 2000, for Dutch). For both Finnish and Dutch, properties like suffix productivity and suffix homonymy (i.e., suffix ambiguity in serving more than one semantic function) were found to affect processing, with words including productive and nonhomonymous suffixes being more likely to induce morpheme-based processing (see also, for Japanese, Hagiwara et al. 1999). In the studies by Bertram, Laine and Karvinen (1999) and Bertram, Schreuder and Baayen (2000), no information was given on the frequency values of the productive vs. unproductive suffixes, and the issue of suffix frequency/numerosity was not assessed directly. A variation in productivity usually corresponds to a variation in frequency/numerosity. However, although very related to suffix productivity, suffix frequency and numerosity do not necessarily correspond to productivity. There may be differences in suffix numerosity that do not correspond to differences in suffix productivity. At the same time, it is not always the case that differences in productivity correspond to differences in suffix frequency or numerosity. 2 Thus there are reasons for investigating suffix frequency/numerosity in derived words, without identifying these quantitative measures with productivity. 162 Burani and Thornton 2. The present study While there is evidence that root frequency affects access to printed suffixed derived words, evidence for a role of quantitative properties of suffixes in visual processing comes almost exclusively from pseudowords. The present study aimed at assessing simultaneously the roles of both root and suffix frequency in Italian derived words, by testing different combinations of roots and suffixes with differing frequency. If the role of quantitative properties of morphemes have to be assessed per se, derived words with morphemic constituents of different frequencies should be matched for a number of factors, including orthographic/phonological transparency, semantic transparency, and whole-word frequency. Italian derivation occurs mostly through agglutination of suffixes to roots which are not occurring words themselves (see Peperkamp 1995). Orthographic/phonological transparency of derived forms with respect to their roots is quite common, wide-spreading across different frequency ranges of both words and morphemes, and can be easily controlled for. Semantic transparency can also be kept under control, while varying suffix frequency/numerosity. Suffix numerosity, i.e., the number of word types in which a given affix occurs, is one determinant of semantic transparency, but it does not identify with it (see Bybee 1995a). Moreover, in intramodal tasks there might be reasons for expecting effects of morphological constituency also in derived words that are less transparent for meaning or in semantically opaque words (see, e.g., Bentin and Feldman 1990; Feldman and Soltano 1999; Plaut and Gonnerman 2000; Schreuder, Burani and Baayen 2002; Stolz and Feldman 1995; Vannest and Boland 1999; but see also, for contrasting evidence in cross-modal tasks, Marslen-Wilson et al. 1994). Given the basic prediction that low-frequency words with two highfrequency constituents should be the best candidates for access through morphemes, which predictions could be made for low-frequency words that include only one high-frequency constituent (either the root or the affix)? Would lexical access be equally sensitive to the higher frequency constituent? Would it be differentially sensitive to the frequency of the root and the affix, respectively? In some studies the assumption has been made that root frequency effects should manifest themselves in low-frequency derived words with frequent and productive suffixes. To our knowledge, there were no investigations of whether root frequency effects would show up in the context of low-frequency suffixes. Similarly, no study has inves- The interplay of root, suffix and whole-word frequency 163 tigated whether high-frequency suffixes may affect the probability of morpheme-based access in the context of low-frequency roots. In synthesis, no study has addressed the issue of whether low-frequency derived words that include either one or both low-frequency constituents were likely to activate morphemic units at all. Our predictions were developed in the framework of the model proposed first by Schreuder and Baayen (1995) (see, for recent updates, Baayen and Schreuder 1999; 2000; Baayen, Schreuder and Sproat 2000). This is a race model for the recognition of morphologically complex words in which there are two parallel access routes, one based on whole-form information, and the other based on morphemic decomposition. One assumption of the model is that, for the visual modality, the complete input is available from the start. Thus in principle, for low-frequency derived words, both root and suffix frequency should affect processing at the stages in which morphemic access representations are activated over time by the sensory input. In the framework of this race model, it is crucial to assess the complex balance between access through storage (whole-word activation) and access through computation (morphemic activation). An open issue is how processing proceeds for low-frequency words which include low-frequency constituent morphemes. This implies assessing the relation existing, in terms of processing costs and benefits, between components in which morphemic units are segmented and activated, and subsequent components in which they are re-combined in order to derive meaning. So far, the probability of faster access through whole-word activation has been suggested for high-frequency derived words that tend to be highly lexicalized (Baayen and Neijt 1997; Burani and Laudanna 1992; Bybee 1995b; Chialant and Caramazza 1995; Frauenfelder and Schreuder 1992; 3 Schreuder and Baayen 1995). Additionally, whole-word storage has been proposed for English derived words which include non-neutral affixes and whose stems tend to cluster around recurring patterns thus constituting “gangs” (Alegre and Gordon 1999b), or for derived words which include unproductive suffixes (Bertram, Laine and Karvinen 1999; Bertram, Schreuder and Baayen 2000; Hagiwara et al. 1999). However, the possibility should be conceived that also low-frequency derived words which include low-frequency morphemic constituents – even if phonologically transparent – are more likely to be accessed as whole forms through direct whole-word access. For these words, the reduced probability of access through morphemic decomposition would de- 164 Burani and Thornton rive from the fact that the slight difference between the frequency of morphemes and whole-word frequency is not large enough for morphological processing to result in benefits relative to whole-word based lexical access. The following visual lexical decision experiments addressed the latter issues by combining evidence from pseudoword and word processing. Experiment 1 was conducted on pseudowords, whereas both Experiments 2 and 3 involved words. Experiment 1 on pseudowords aimed at replicating and extending results on the role of suffix quantitative properties in nonlexical contexts. It addressed issues that should help in interpreting results from the two following experiments on words. By including suffixes in pseudoword contexts in which the initial orthographic sequence did not correspond to an existing root, the role of suffix frequency/numerosity could be differentiated from its consequences on the semantic transparency or interpretability of a newly derived form with respect to its base. At the same time, by investigating stimulus contexts in which the lexical morphemic unit (the suffix) occurred in the rightmost part of the stimulus in the absence of a morphemic unit on its left side, we aimed at providing evidence for a role of morphemic units which is independent of sequential left-to-right processing. Experiments 2 and 3 addressed the issue of the interplay of root, suffix and whole-word frequency in access to derived words, by orthogonally varying high- and low-frequency roots and suffixes in low-frequency transparent derived Italian words. In order to specify the balance between the processing routes based on whole-word and morphemic units, respectively, the derived words were contrasted with nonderived words of analogously low frequency (Experiment 3). 3. Experiment 1 In Experiment 1, we aimed at replicating, with three sets of suffixes, the effect of suffix frequency in lexical decision to pseudowords found by Burani et al. (1997). In that study, suffixes were combined with real roots to form pseudowords. In the present experiment, the pseudowords were obtained by combining suffixes of varying frequencies with orthographic sequences that did not correspond to real roots. If suffix frequency effects were to occur in lexical decision to pseudowords of this sort, strong evidence for the role of suffixes in visual processing would be provided. If activation of the morphemic units comprising a stimulus occurs irrespective of their sequential positions within the stimulus, provided they are The interplay of root, suffix and whole-word frequency 165 frequent enough, the prediction could be made that high-frequency suffixes are activated and play some role also when affixed after nonroots. The expected result has twofold implications. On the one hand, if highfrequency suffixes delay lexical decisions to pseudowords even when they occur in stimuli that do not contain real roots, it could be concluded that the effects of frequency/numerosity of suffixes occur at a processing stage in which affix morphemes are available independently of their semantic content. When suffixes are combined with nonroots, no interpretability of the combination should be expected, because of the absence of a meaningful component in first position (for the effects of interpretability of new root-suffix combinations in lexical access, see Burani et al. 1999; see also, for the effects of interpretability on novel Dutch compounds, Coolen, van Jaarsveldt and Schreuder 1991; van Jaarsveldt, Coolen and Schreuder 1994). On the other hand, if we were to show a frequency effect induced by a morphemic unit located in the rightmost position of the stimulus, within an orthographic context in which no lexical or morphemic unit occurs in left position, we would challenge a sequential search model, which predicts that the frequency of the second constituent should not affect lexical processing (Taft and Forster 1976). Evidence against this sort of model has been provided by studies which used both compound nonwords (Lima and Pollatsek 1983), and real compound words (Andrews 1986; Andrews and Davies 1999; Pollatsek, Hyönä and Bertram 2000). The main finding of these studies, which mainly employed lexical decision, but also the recording of eye movements in sentence reading (Pollatsek, Hyönä and Bertram 2000), was an effect of the lexical status or of the frequency of the second constituent. Evidence for a frequency effect of the second constituent when this is a suffix is still lacking. However, even in a theoretical framework which incorporates principles of interactive activation (Taft 1994), it is still assumed that, while inflectional endings would be stripped off in word processing, derivational suffixes would not, because of their different role in processing. Within the latter framework, all the pseudowords that are tested in our experiment, provided they are equated in their leftmost nonlexical part on purely orthographic grounds, should be rejected equally fast, irrespective of the presence of a suffix on their rightmost side. In contrast with these predictions, if interference effects on nonword lexical decision do arise when the stimulus includes a high-frequency suffix in combination with a nonroot orthographic sequence, a model in which the 166 Burani and Thornton processing system activates frequent morphemic units, irrespective of their relative locations within the word, would be supported In Experiment 1, three sets of Italian derivational suffixes were selected. The three sets, matched for length in letters and phonemes, and for orthographic/phonological structure, differed only for frequency, calculated both on word tokens and on word types. Suffixes in the three sets could be considered of high, medium and low frequency, respectively, by considering the overall distribution of frequency values of Italian suffixes of the same length. The main prediction was that high-frequency suffixes should cause more interference on nonword decision when included in pseudoword contexts, relative to low-frequency suffixes. Suffixes of medium frequency might either not constitute sufficiently activated processing units for interference to occur, or they might show interference effects of a smaller size than high-frequency suffixes. 3.1. Method 3.1.1. Materials and design Nine suffixes were selected, equally subdivided in three experimental sets, of high, medium and low frequency, respectively. Frequencies, in this experiment and in all the following experiments, were derived from a corpus of Italian written language of 1.5 million tokens (Istituto di Linguistica Computazionale CNR 1989). The mean suffix frequencies in the three sets, calculated on word tokens, were 1,060 per 1.5 million (range: 639-1,557); 68.3 (range: 55-90), and 12.3 (range: 7-18), for the three sets, respectively. Differences in mean suffix numerosity between the three sets, calculated on word types in the corpus, paralleled differences in frequency. The mean number of word types in which suffixes occurred were 165 (range: 145187), 20.6 (range: 11-39), and 6.3 (range: 2-10) for the three sets, respectively. There were both nominal and adjectival suffixes. No suffix was homonymous with another Italian suffix. All suffixes were four-letter long and were matched across sets for length in phonemes and for syllabic structure. For each suffix, a control sequence with similar orthographic and syllabic structure was selected. The sequences corresponding to a suffix and the control sequences were matched for orthographic frequency in word final position in each set. The mean frequencies of control sequences in The interplay of root, suffix and whole-word frequency 167 word final position were: 1,538 per 1.5 million for the first set; 472 for the second set; 64 for the third set. These values were matched to the mean frequencies of the orthographic strings corresponding to the selected suffixes, calculated in word final position and including both real suffixes and pseudosuffixes: 1,335 per 1.5 million for the high-frequency set; 411 for the medium-frequency set, and 62 for the low-frequency set, respectively. The suffixes were combined with orthographically legal letter sequences that did not correspond to any existing root. Each suffix was combined with four different pseudoroots, for a total of twelve pseudowords in each set. The length of pseudowords fell within the length range of Italian words including the same suffix, and respected as much as possible the distribution of word length for each suffix in the Italian language (calculations were based on Ratti et al. 1988). Mean lengths in letters of the pseudowords were 9.1, 8.6, and 8.7 for the three sets, respectively. Each suffixed pseudoword was matched with a control pseudoword that included the same pseudoroot in combination with the orthographic sequence that constituted the control sequence for the suffix. Thus pseudowords in each suffixed-control pair had the same length, the same syllabic structure, similar orthographic/phonological structure, and similar orthographic frequency of the final part, either corresponding to a suffix or to a nonsuffix. Pseudowords including suffixes and control sequences were also matched for bigram frequency. Mean bigram frequencies, calculated on the base of the natural logarithm, were: 10.49, 10.57, and 10.60 for pseudowords in the three suffixed sets; they were 10.80, 10.55, and 10.44 for pseudowords in control sets. In combining initial letter strings with suffixes and control letter sequences, we avoided the presence in the pseudowords of embedded real words. Pseudowords in the six sets were also matched for their overall degree of orthographic similarity to a real word, i.e., for the number of orthographic neighbors. Adopting the N-count measure (Coltheart et al. 1977), i.e., the total number of words that can be obtained from each pseudoword by replacing one letter at a time with another letter, while preserving the other letters’ positions, we determined that the great majority of pseudowords had a null N-count (with a few exceptions of N-count = 1, balanced across sets), i.e., we obtained pseudowords that were equally dissimilar from existing words, according to the N-count metric. In synthesis, there were six sets of pseudowords, arranged in a 2x3 design, in which the main factors were the presence vs. absence of a suffix, and the high vs. medium vs. low frequency of the orthographic sequence 168 Burani and Thornton corresponding either to a suffix or to a nonsuffix. In each of the six sets, there were 12 pseudowords (4 for each suffix or control sequence), for a total of 72 experimental stimuli, 36 suffixed and 36 controls. The experimental items, with the mean RT and percent error for each item, are reported in Appendix A. In order to avoid presenting the same pseudoroot to the same participant both in the suffixed and in the nonsuffixed control condition, each experimental set was split in two subsets of 6 items each. Each participant was presented with 36 experimental pseudowords, 18 suffixed and 18 pseudosuffixed, in which no pseudoroot was repeated. In each subset there were two instances of the same suffix or final control sequence. For each set of suffixed and control pseudowords, the entire set of single scores was provided by two participants presented with two complementary sublists. In each sublist, the 36 experimental pseudowords were presented together with 66 filler pseudowords and 102 filler words. Each participant was presented with a total of 204 stimuli. Filler stimuli were the same in each of the two sublists: Words included medium/low frequency singular nouns and adjectives, either derivationally suffixed or nonsuffixed, in a proportion that reflected the composition of the Italian basic dictionary in the medium/low frequency range (see Thornton, Iacobini and Burani 1994; 1997). Each suffix and each control final sequence that occurred in experimental pseudowords was also included in the same number of filler words. Filler pseudowords were drawn from words analogous to the filler words by changing one or two letters in different positions. Mean length was the same for words and pseudowords (range: 6-11 letters). The list was presented to participants in a single experimental session, arranged in three randomized blocks of 68 items each. For each block, participants were assigned to one of two different randomizations of items. Each experimental list was preceded by a practice list of 50 items, 25 words and 25 pseudowords, assigned in the same proportion to two randomized blocks. 3.1.2. Procedure Participants were tested individually in a soundproof experimental booth. They received standard lexical decision printed instructions in which they were asked to decide as quickly and as accurately as possible whether a presented letter string was an Italian word or not. If it was a word (YES The interplay of root, suffix and whole-word frequency 169 response), they had to press the right one of two response keys, otherwise (NO response) the left one. For left-handed participants, the order of the response buttons was reversed. Each trial started with the presentation of a fixation mark (a cross) in the center of the screen for 400 ms, followed after 300 ms by the stimulus centered at the same position. Stimuli were presented on a monitor in white uppercase letters on a dark background and remained on the screen until the participant pressed one of the two response buttons. They disappeared after a time period of 1,500 milliseconds if no response was given. A new trial began 1,200 ms after responding or time-out. If a participant responded more slowly than the preset limit of 1.5 sec, the words FUORI TEMPO (‘out of time’) appeared on the screen. If the participant gave the wrong response, the word ERRORE (‘error’) appeared on the screen. This signal was displayed for 500 ms. The interval between the disappearance of the feedback and the next warning signal was 1,200 ms. There was a pause after each block of stimuli. The total duration of the experimental session was approximately 20 minutes. 3.1.3. Participants Forty-eight participants, mostly University students, were paid to participate in the experiment. All were native speakers of Italian. 3.2. Results and discussion The data of four participants, whose mean reaction times for correct responses or whose error rates were more extreme than 2 s.d from the mean of all participants, were excluded from further analysis. Using the remaining forty-four participants, the mean reaction times and error rates for all items were obtained and one pair of items in the medium-frequency set was removed because the number of errors for one of the two members of the pair (crofusso) was more than 2.5 s.d. above the mean. When means for length, bigram frequency and N-count were recalculated after removing the two paired items, the sets were still balanced. The remaining observations were used to calculate participants’ and items’ mean reaction times and error scores. Mean reaction times by items and percentages of errors for 170 Burani and Thornton the three experimental categories and their respective controls are shown in Table 1. Table 1. Experiment 1. Mean reaction times by items in ms. and % error. Suffixed and control (nonsuffixed) pseudowords, with high-frequency (HF), medium-frequency (MF), and low-frequency (LF) final sequences Suffixed Control Difference HF Mean RT % Error 739 13.6 700 6.1 +39 + 7.5 MF Mean RT %Error 701 4.1 701 7.4 0 - 3.3 LF Mean RT %Error 680 4.6 679 4.2 +1 + 0.4 Results were submitted to a mixed three-way analysis of variance with two within-participants factors: Suffixedness (suffixed vs. nonsuffixed pseudowords) and frequency of final sequence, both suffix and control (high vs. medium vs. low). The third between-participants factor was list (first vs. second sublist, each administered to one half of participants). The ANOVAs were performed both by participants and by items and showed interaction between suffixedness and frequency on both reaction times (F1(2,84) = 7.59, p<.001, MSE= 1,412.1; F2(2,58) = 3.34, p=.04, MSE= 977.3) and errors (F1(2,84) = 5.92, p=.004, MSE= 117.2; F2(2,58) = 5.97, p=.004, MSE= 1.48). Results differed across the three experimental sets when suffixed pseudowords were compared to their respective controls. Comparisons between suffixed-control pairs based on the Duncan test on means by items revealed that suffixed pseudowords in the highfrequency set were significantly (39 ms) slower (p=.03) and gave rise to significantly (7.5%) more errors (p=.003) with respect to controls. By contrast, suffixed pseudowords were equally fast relative to their controls in both the medium-frequency and the low-frequency sets (p>.1 in both cases). Percent errors on suffixed pseudowords were 3.3 less and 0.4 more in the medium-frequency and in the low-frequency sets, respectively. These differences were not significant (p>.1 in both cases). An effect of frequency was found on both reaction times (F1(2,84) = 19.78, p<.001, MSE= 1,505.6; F2(2,58) = 10.12, p<.001, MSE= 977.3), The interplay of root, suffix and whole-word frequency 171 and errors (F1(2,84) = 5.76, p=.004, MSE= 122.5; F2(2,58) = 6.28, p=.003, MSE= 1.48). The main effect of suffixedness (suffixed vs. nonsuffixed pseudowords) was found on reaction times by participants only (F1(1,42) = 6.57, p=.013, MSE= 900.46; F2(1,58) = 2.56, p>.1, MSE= 977.3). No main effect of suffixedness was found on errors (F1(1,42) = 2.03, p>.1, MSE= 72.23; F2(1,58) = 1.27, p>.1, MSE= 1.48). As revealed by the strong interaction between suffixedness and frequency of final sequence, and by post-hoc comparisons, response latencies and percentages of errors to suffixed pseudowords were higher, relative to their controls, only when the pseudowords included a high-frequency suffix. By contrast, pseudowords that included either medium-frequency or low-frequency suffixes did not reveal longer reaction times nor lower accuracy with respect to matched orthographic controls. These results confirm those obtained by Burani et al. (1997): High-frequency suffixes activate corresponding morphemic access units in pseudoword contexts. By contrast, no access unit seems to be available for suffixes that are either medium- or low-frequency, at least not in pseudoword contexts and within the time required to perform lexical decision. The present results allow us to build on the findings by Burani et al. (1997). In the present experiment, the interference effect caused by highfrequency suffixes occurred with suffixes that were combined with nonexisting roots. Hence, activation of morphemic lexical units corresponding to suffixes occurred in the absence of a real root on their left side. This finding hardly seems compatible with sequential search accounts (Taft and Forster 1976), and with recent reformulations (Taft 1994), which predict that the frequency of the second constituent, the derivational suffix, should not affect lexical processing in the absence of a lexical unit as first constituent. 4. Experiment 2 Experiment 1 provided evidence for a role in processing of suffix frequency, with high-frequency suffixes significantly affecting rejection latencies in visual lexical decisions to pseudowords. In Experiment 1 there was no evidence that suffixes of medium/low frequency which extended up to a frequency of 90 per 1.5 million constituted effective processing units: No interference arose in lexical decision, when a suffix was either medium- or low-frequency. 172 Burani and Thornton The role of suffix frequency in lexical decision to real words was assessed in Experiment 2, by varying both root and suffix frequency in transparent derived words of low surface frequency. Derived words included suffixes belonging to two sets of differing frequencies. Suffixes of high frequency were contrasted with suffixes that were of medium/low frequency. In Experiment 1 there was no evidence for differences between medium- and low-frequency suffixes. Hence, suffixes from both the latter frequency ranges were pooled together in a single set. For simplicity, hereafter we will refer to medium/low- frequency suffixes as lowfrequency suffixes. All low-frequency derived words should in principle be accessed through constituent morphemes – even when both the root and the suffix are low-frequency, the derived word is nevertheless lower in frequency than its constituent morphemes. Hence, for low-frequency derived words that are equated for all the relevant properties except for frequency of the two constituent morphemes, either high or low, predictions were that both reaction times and error rates should not be function of whole-word frequency, but should rather reflect differences in the frequency of morphemic constituents. Words including higher-frequency morphemes were expected to be accessed more quickly and more accurately than words including lowerfrequency morphemes, with words including both root and suffix of high frequency being the fastest and the most accurate, and words with lowfrequency root and suffix being the slowest and the least accurate. Derived words in which only one morpheme, either the root or the suffix, is of high frequency, were expected to show intermediate reaction times and error rates. If for printed stimuli simultaneous parallel activation of both root and affix is assumed, irrespectively of their relative positions within the word, words in which the high-frequency constituent is either the root or the suffix were not expected to differ in activation times. 4.1. Method 4.1.1. Materials and design Four sets of equally low-frequency suffixed derived words were selected. In the four sets, root and suffix frequency varied orthogonally: The first set included high-frequency roots and high-frequency suffixes (HH); the sec- The interplay of root, suffix and whole-word frequency 173 ond set included low-frequency roots and high-frequency suffixes (LH); the third set included high-frequency roots and low-frequency suffixes (HL); the fourth set included low-frequency roots and low-frequency suffixes (LL). Suffixes were either high- or low-frequency on both tokens and types, i.e., on both frequency tout court and numerosity. The root frequency measure included the cumulative frequency of both the inflected and the derived forms of the base. Thirteen words (nouns and adjectives) were included in each set, for a total of nine different suffixes in each set. No suffix was homonymous with a different Italian suffix. The same suffixes were included in the two highfrequency suffix sets and in the two low-frequency suffix sets, respectively. Suffixes were three to five letters long. High-frequency suffixes and low-frequency suffixes were matched for length and syllabic structure. Roots were different in the four sets. Root length was balanced across sets. The roots belonged to different grammatical categories (i.e., nouns, adjectives and verbs) that were balanced across sets. All the derived words were presented in singular citation form. They were orthographically and phonologically transparent with respect to their bases, i.e., there was no orthographic/phonological assimilation at the boundary between root and suffix. Across the four sets, words were matched for surface frequency, length, syllable structure and bigram frequency. The 52 experimental words were presented together with 108 filler words and 160 filler pseudowords, for a total of 320 stimuli. Any suffix that occurred in experimental words occurred also in the same number of filler pseudowords. Filler pseudowords were drawn from words analogous to the filler words by changing one or two letters in different positions in the word. Filler words included medium/low-frequency singular nouns and adjectives, either morphologically complex or simple, in a proportion that reflected the composition of the Italian basic dictionary in the medium/low frequency range (Thornton, Iacobini and Burani 1994; 1997). Mean length was the same for words and pseudowords (range: 6-11 letters). The list was presented to participants in a single experimental session, arranged in four randomized blocks of 80 items each. Each participant was presented with a different block randomization and with a different randomization of items within each block. Each experimental list was preceded by a practice list of 40 items, 20 words and 20 pseudowords, assigned in the same proportion to two randomized blocks. 174 Burani and Thornton 4.1.2. Procedure The procedure was the same as in Experiment 1. The experimental session lasted about 30 minutes. 4.1.3. Participants Forty-five participants, mostly University students, were paid to participate in the experiment. All were native speakers of Italian. 4.2. Results and discussion The data of ten participants, who made more than 15 percent errors on the experimental words, were excluded from further analysis. Using the remaining thirty-five participants, the mean reaction times and error rates for all items were obtained. We removed four experimental words that showed error rates exceeding 40% from the data set. One word (tenerume) was removed in set HL, two words (aratore and larvale) in set LH, and one word (ameboide) in set LL. One item (rimanenza) was removed in set HH because it was the only word which included a prefixed bound root of an irregular verb. Removal of these items did not affect the matching of the four sets for the relevant variables. In Table 2 the mean values with standard deviations for the variables in each experimental set are reported. The list of the experimental items, with root frequency, suffix frequency, word frequency, mean RT and percent error for each item, are reported in Appendix B. The remaining observations were used to calculate participant and item mean reaction times and error scores. Mean reaction times by items and percentages of errors for the four experimental sets are shown in Table 3. The interplay of root, suffix and whole-word frequency 175 Table 2. Experiment 2. Mean values and standard deviations (s.d.) for the relevant variables. HH = Derived words with high-frequency root and high-frequency suffix HL = Derived words with high-frequency root and low-frequency suffix LH = Derived words with low-frequency root and high-frequency suffix LL = Derived words with low-frequency root and low-frequency suffix HH Root frequency Family size Suffix frequency Suffix numerosity Semantic relatedness Familiarity Bigram frequency Word length in letters Root length in letters Suffix length in letters Word frequency HL LH LL Mean s.d. Mean s.d. Mean s.d. Mean s.d. 501 412.1 507 409.8 33.5 19.1 33.3 21.9 15.7 1,859 246 3.77 6.57 10.79 8.2 4.4 3.8 3.1 8.05 1,515 123.6 0.43 0.78 0.4 1.5 1.4 0.6 2.8 10.20 57 17.3 3.47 6.05 10.69 8.2 4.3 3.9 3.5 3.82 33.7 10.8 0.89 1.03 0.3 1.1 1.1 0.5 3.2 4.4 1,636 217 3.66 6.15 10.56 8.4 4.5 3.9 2.2 2.5 1,260 101.39 0.68 0.9 0.3 1.0 1.0 0.5 2.3 4.2 58 17.7 3.45 5.75 10.60 8.2 4.4 3.8 1.7 1.7 32.5 10.6 0.95 1.01 0.3 0.9 0.8 0.6 1.2 Table 3. Experiment 2. Mean reaction times by items in ms and % error. Suffixed derived words with high-frequency root and high-frequency suffix (HH); high-frequency root and low-frequency suffix (HL); lowfrequency root and high-frequency suffix (LH); low-frequency root and low-frequency suffix (LL). HH HL Mean Reaction Time % Error 597 2.5 LH 624 5.9 LL Mean Reaction Time % Error 634 6.7 670 12.2 Results were submitted to two-way analyses of variance, with root frequency (high vs. low) and suffix frequency (high vs. low) as the two factors. There were main effects of both root frequency and suffix frequency on both reaction times and error rates. For root frequency, F1(1,34)=77.83, p<.001, MSE= 771.3; F2(1,43)= 7.96, p<.01, MSE= 2,551.55 on reaction times; F1(1,34)= 13.96, p<.001, MSE= 68.9; F2(1,43)= 6.08, p<.025, MSE= 6.59 on error rates. For suffix frequency, F1(1,34)= 28.92, p<.001, 176 Burani and Thornton MSE= 1,088; F2(1,43)= 4.77, p<.05, MSE= 2,551.55 on reaction times; F1(1,34)= 11.00, p=.002, MSE= 63.59; F2(1,43)= 4.38, p<.05, MSE= 6.59 on error rates. There was no interaction between the two factors (p>.1 in all the analyses). Results on both reaction times and error rates strictly paralleled differences in frequency of constituent morphemes, with words including highfrequency constituents determining quicker and more accurate performance. No differential role of root frequency with respect to suffix frequency was apparent in the data. Hence, results seemed to confirm the hypothesis of access through activation of morphemic constituents for lowfrequency derived words. We controlled post-hoc for possible residual asymmetries in the properties of the experimental words that could have contributed to the effect. Three properties of the derived words were considered: the semantic relatedness to the base, the word’s morphological family size, and the word familiarity. 4.2.1. Ratings of semantic relatedness with the base According to some authors, effects of morphological structure should be found preferentially in derived words that are semantically transparent (or related) with respect to the base (Marslen-Wilson et al. 1994; but see also, for contrasting data and accounts, Bentin and Feldman 1990; Feldman and Soltano 1999; Plaut and Gonnerman 2000; Schreuder, Burani and Baayen 2002; Stolz and Feldman 1995; Vannest and Boland 1999). In selecting stimuli, we aimed at balancing words in the four sets for the degree of semantic transparency. We controlled for semantic transparency of the derived words with respect to their bases by excluding semantically opaque words, and by including in each set approximately the same number of suffixes that could be considered either productive or unproductive on the basis of different measures of productivity. In each frequency set there were suffixes that could be considered productive because they had been used to coin a substantial number of neologisms in the last fifty years, or could be rated as productive on the basis of the quantitative measure of productivity proposed by Baayen (1989; 1992). Analogously, in each set there was a similar number of suffixes that could be considered scarcely productive or unproductive on either one or both the latter measures. The interplay of root, suffix and whole-word frequency 177 However, it could not be excluded that, independently of productivity rated in the latter ways, derived words including high-frequency suffixes might result in greater semantic transparency with respect to their bases by virtue of suffix numerosity itself. High suffix numerosity is related to a greater number of derived words which tend to share a similar part of meaning, namely the meaning carried by the suffix. Analogously, it could not be excluded that words might have different semantic transparency values due to specific idiosyncrasies. Derived words were submitted to empirical ratings for semantic relatedness with their base. Each derived word was paired with its base word. The printed list of word-pairs was presented in different random orders to thirty-eight University students who had not participated in the lexical decision experiment. Participants had to rate, for each pair, on a five-point scale ranging from “Very unrelated” to “Very related”, how “related in meaning” they thought the first word (the derived word) was to the second word (the base word). Mean ratings of semantic relatedness with the base were 3.77 (s.d. 0.43) for HH words; 3.47 (s.d. 0.89) for HL words; 3.66 (s.d. 0.68) for LH words; 3.45 (0.95) for LL words, respectively. A two-way ANOVA with root frequency (high vs. low) and suffix frequency (high vs. low) as factors was performed on semantic relatedness rating means both by participants and by items. A suffix frequency effect was found, by participants only (F1 (1,37) = 15.65, p<.001, MSE= 195.1; F2 (1,43) = 1.35, p=.25, MSE=.55), with words including high-frequency suffixes being rated as significantly more related for meaning to their base words (mean semantic relatedness: 3.71) than words including low-frequency suffixes (mean semantic relatedness: 3.46). Neither root frequency nor the interaction were significant (F<1 in both cases). In order to assure that the suffix frequency effect was not confounded with the fact that words with high-frequency suffixes were more transparent for meaning than words with low-frequency suffixes, two further analyses were carried out. First, the results of lexical decision were reanalyzed by excluding from the two sets with low-frequency suffixes the least transparent items (four items in all), thus obtaining new sets that were perfectly matched for semantic transparency. After matching sets for semantic transparency, the results of ANOVAs did not change, but showed even stronger effects of both root and suffix frequency (F2 (1,39) = 7.3, p<.025, MSE= 2,314.56; F2 (1,39) = 9.46, p<.005, MSE= 2,314.56 on reaction times for root and suffix, respectively; F2 (1,39) = 6.08, p<.025, MSE= 6.36; F2 178 Burani and Thornton (1,39) = 7.88, p<.01, MSE= 6.36, on error rates for root and suffix, respectively), and no interaction (p>.1). Furthermore, post-hoc correlation analysis did not reveal significant correlation (one-tailed test) of reaction time with semantic relatedness (r = -.14, t(45)=0.92, p>.1). Hence we could exclude that semantic transparency was responsible for the effects found (see also, for evidence that semantic transparency itself cannot explain why some suffixes induce decomposition while others do not, Vannest and Boland 1999). 4.2.2. Morphological family size Recently, Bertram, Baayen and Schreuder (2000) reported evidence for the role, in the lexical processing of Dutch complex words, of morphological family size, i.e., the type count of derived words and compounds with a given base word as a constituent. This type count of the number of morphological family members, that has been found to be a strong independent co-determinant of response latencies for Dutch monomorphemic and inflected words (de Jong, Schreuder and Baayen 2000; Schreuder and Baayen 1997), also affected latencies to derived words. Bertram, Baayen and Schreuder (2000) suggested that a large family size of the base word facilitates lexical processing for most suffixed derived words. According to the authors, the facilitatory effect of a large family size is due to semantic activation spreading from a complex word to its family members. The family size of the base root – i.e., the root numerosity – could in principle affect processing of Italian derived words. In our study, a larger morphological family size should be expected in both sets with high root frequency, relative to the sets with low root frequency. For each target word, the number of word types that share the same root in the corpus was counted. The obtained mean number of morphological family members was 15.7 (s.d. 8.05) for HH words, 10.2 (s.d. 3.82) for HL words, 4.4 (s.d. 2.5) for LH words, and 4.2 (s.d. 1.7) for LL words, respectively. A twoway ANOVA with root frequency (high vs. low) and suffix frequency (high vs. low) as the two factors was performed on family size values in the four sets. As expected, a difference in the numerosity of the morphological family between words with high and low frequency roots was found (F(1,43)= 39.01, p<.0001, MSE= 22.5). A difference in morphological family size between words with high and low frequency suffixes was also found (F(1,43)= 4.24, p<.05, MSE= 22.5), and a marginally significant The interplay of root, suffix and whole-word frequency 179 interaction (F(1,43)= 3.43, p=.07, MSE=22.5). A two-tailed t-test between HH and HL sets revealed a significant difference in family size between the two sets with high-frequency root (t(22)= 2.11, p<.05). The differences in family size among the experimental sets were in the same direction as the differences in response times, with HH words having a mean larger number of family members (15.7) than HL words (10.2), and words with high-frequency suffixes a mean larger number of family members (10.1) than words with low-frequency suffixes (7.2). Hence we assessed whether these differences could be responsible for part of the effect that was found in lexical decision. Two further analyses were made. First, we reanalyzed the results of lexical decision by excluding two items in each of the two sets with highfrequency roots, to obtain new sets that were matched for mean family size. After matching sets for family size, the results of ANOVAs did not change, but still showed effects of both root and suffix frequency (F2(1,39)= 7.82, p=.008, MSE= 2,602.1; F2 (1,39) = 4.31, p<.05, MSE= 2,602.1, on reaction times for root and suffix, respectively; F2 (1,39) = 6.7, p=.01, MSE= 6.75; F2 (1,39) = 4.54, p= .04, MSE= 6.75, on error rates for root and suffix, respectively), and no interaction (p>.1). Furthermore, post-hoc correlation analysis did not reveal any correlation of reaction time with family size (r=.04, t(45)=0.27, p>.1). Thus the hypothesis that differences in family size were responsible for part of the effects found in lexical decision could be rejected. 4.2.3. Familiarity ratings Words from the low-frequency range of a corpus may differ in familiarity, and familiarity is usually a good predictor of lexical decision performance (Connine et al. 1990; Gernsbacher 1984). Although our derived words were matched for whole-word frequency, we made a post-hoc check for familiarity. The derived words were submitted to twenty-seven University students for familiarity ratings. Participants had to rate the printed words on a seven-point scale ranging from “Unknown” (1) to “Very well known” (7). All the derived words received high familiarity ratings. However, there were differences between the four groups. Mean familiarity ratings were: 6.57 (s.d. 0.78) for HH words; 6.05 (s.d. 1.03) for HL words; 6.15 (s.d. 0.9) for LH words; 5.75 (s.d. 1.01) for LL words. 180 Burani and Thornton A two-way ANOVA with root frequency (high vs. low) and suffix frequency (high vs. low) as the two factors performed on familiarity rating means both by participants and by items showed significant effects of both factors, by participants only (F1(1,26) = 15.03, p<.001, MSE= .51; F2(1,43) = 2.56, p>.1, MSE= .88 for root frequency; F1(1,26) = 44.11, p<.001, MSE= .46; F2(1,43) = 1.74, p>.1, MSE= .88 for suffix frequency), and no interaction (F<1). Results on familiarity ratings paralleled results on reaction times and accuracy, with words including high-frequency roots and high-frequency suffixes being rated as more familiar than words with low-frequency roots and suffixes. Differences in rated familiarity were so clean that we could not select post-hoc a subset matched for familiarity. Moreover, post-hoc correlation analysis revealed a strong correlation of reaction time with familiarity (r = -.66, t(45) = 5.83, p<.0001). 4.2.4. Ad interim considerations In synthesis, the results of post-hoc controls on three possible factors contributing to the effects found at lexical decision (i.e., semantic relatedness with the base, morphological family size, and word familiarity) evidentiated word familiarity as a possible determinant of lexical decision performance. There could be reasons for adopting differences in rated familiarity of morphologically complex words as evidence per se for access to morphemic constituency (see Bertram, Baayen and Schreuder 2000; Schreuder and Baayen 1997). However, it could also be the case that word familiarity provides a different source of explanation for the effect we found. In Experiment 3, we tried to disentangle the role of morphemic frequency from that of word familiarity, while addressing further processing issues. 5. Experiment 3 The aim of Experiment 3 was twofold. First, we aimed at detailing the effects found in Experiment 2 with different and larger sets of derived words, better balanced for properties like semantic relatedness with the base, morphological family size and rated familiarity. Second, we assessed whether slower reaction times and higher error rates to words including both a root and a suffix of low frequency (LL words) were a function of The interplay of root, suffix and whole-word frequency 181 the low frequency of constituent morphemes, or whether performance was merely a function of low whole-word surface frequency. The latter possibility would imply that, for low-frequency derived words with both constituents of low-frequency, the output of lexical decision does not result from morphological processing, but from whole-word processing. For lowfrequency derived words whose constituents are both low-frequency, the moderate difference between the frequency of morphemes and whole-word frequency (with root and suffix only slightly higher in frequency than the whole-word) might not be large enough for morphological processing to result in benefits relative to access based on the whole-word. To address the latter issue, a set of nonderived words (ND) was matched for frequency to four new sets of low-frequency derived words that included morphemes of differing frequencies. Analogously to Experiment 2, the first set of derived words included high-frequency roots and high-frequency suffixes (HH); the second set included low-frequency roots and high-frequency suffixes (LH); the third set high-frequency roots and low-frequency suffixes (HL); the fourth set low-frequency roots and lowfrequency suffixes (LL). Words in the five sets (the four sets of derived words and the set of underived words) had the same mean low surface frequency and were matched for all the relevant variables, including familiarity. The only difference was that words in the fifth (nonderived) set did not 4 include any derivational suffix. Predictions were the following. If LL derived words with both lowfrequency constituents are accessed preferentially as whole-words and no morpheme-based access succeeds because of including exceedingly lowfrequency roots and suffixes, LL derived words should show similar results to nonderived (ND) words: For both LL and ND words, reaction times and error rates should be function of surface frequency only. If, by contrast, activation of morphemes is involved in access to LL derived words, and if morphemic activation implies processing advantages because of accessing a root and a suffix which are, although slightly, higher in frequency than the whole-word, LL derived words should be quicker than nonderived words. The latter do not benefit in fact from any constituent morpheme of higher frequency.5 If the closer matching for familiarity, semantic relatedness and morphological family size obtained for words in the experimental sets of Experiment 3 does not make any contribution to results, HL and LH derived words which include one high-frequency constituent (either the root or the suffix), should show intermediate reaction times and error rates relative to LL words on the one hand, and HH derived words on the other. 182 Burani and Thornton Accordingly, HH derived words with both constituents of high-frequency should be the most quickly and most accurately recognized. 5.1. Method 5.1.1. Materials and design The five experimental sets included seventeen words each, nouns and adjectives in analogous proportions in each set. In the four derived sets, there were nine different high-frequency suffixes, and ten different lowfrequency suffixes, with analogous distributions in the two high-frequency suffix sets, and in the two low-frequency suffix sets, respectively. No suffix was homonymous to a different Italian suffix. Suffixes were three to five letters long. High-frequency suffixes and low-frequency suffixes were matched for length and syllabic structure. Roots were different in the four sets, and belonged to different grammatical categories (i.e., nouns, adjectives and verbs) that were balanced across sets. Root length was balanced across sets. Analogously to Experiment 2, suffixes were either high- or low-frequency on both word tokens (suffix frequency) and word types (suffix numerosity), and the root frequency included the cumulative frequency of both the inflected and the derived forms of the base. The highfrequency root words had also a larger mean family size than lowfrequency root words. Words were matched for mean morphological family size across sets with the same root frequency. All the derived words were orthographically and phonologically transparent with respect to their bases. All words in the five sets were presented in the citation form. Words were matched, across the five sets, for surface frequency, length, syllabic structure and bigram frequency. The five sets were also matched for rated familiarity (familiarity ratings were obtained on a seven-point scale from twenty-four participants, see Experiment 2 for details about the method), and the four sets of derived words were matched for semantic relatedness with the base (semantic relatedness ratings were obtained on a seven-point scale from twenty-four different participants; see Experiment 2 for details concerning the method). The mean values with standard deviations for the relevant variables in each experimental set are reported in Table 4. The list of stimuli, with root frequency, suffix frequency, word frequency, mean 6 RT and percent error for each item are reported in Appendix C. The interplay of root, suffix and whole-word frequency 183 The 85 experimental words were presented together with 115 filler words and 200 filler pseudowords, for a total of 400 stimuli. Any suffix that occurred in the experimental words occurred also in the same number of filler pseudowords. The filler pseudowords were drawn from words analogous to the filler words by changing one or two letters in different positions in the word. The filler words included medium/low-frequency singular nouns and adjectives, either morphologically complex or simple, in a proportion that reflected the composition of the Italian basic dictionary in the medium/low frequency range (Thornton, Iacobini and Burani 1994; 1997). The mean length was the same for words and pseudowords (range: 6-11 letters). The list was presented to participants in a single experimental session, arranged in five randomized blocks of eighty items each. Each participant was presented with a different block randomization and with a different randomization of items within each block. Each experimental list was preceded by a practice list of 40 items of 20 words and 20 pseudowords, assigned in the same proportion to two randomized blocks. Table 4. Experiment 3. Mean values and standard deviation (s.d.) for the relevant variables. HH = Derived words with high-frequency root and high-frequency suffix HL = Derived words with high-frequency root and low-frequency suffix LH = Derived words with low-frequency root and high-frequency suffix LL = Derived words with low-frequency root and low-frequency suffix ND = Nonderived words, Freq: Frequency; Num: Numerosity; Rel: Relatedness HH Root Freq. Family Size Suffix Freq. Suffix Num. Semantic Rel. Familiarity Bigram Freq. Word Length Root Length Suffix Length Word Freq. Mean 547 12.3 2,119 247 5.41 6.42 10.72 8.2 4.4 3.8 5.3 HL s.d. 536.5 8.81 1,653 141.2 0.56 0.34 0.44 1.29 1.06 0.66 4.04 Mean 554 11.1 75 21 5.01 6.24 10.74 8.6 4.5 4.2 4.6 LH s.d. 526.2 4.05 37.26 12.6 0.77 0.6 0.25 1.22 1.23 0.64 4.94 Mean 38 4.6 1,892 227 5.34 6.22 10.58 8.1 4.3 3.8 3.1 LL s.d. 16.72 1.94 1,479 127.33 0.65 0.46 0.52 1.20 1.22 0.66 2.68 Mean 31 4.1 68 21 5.24 6.15 10.47 8.8 5.0 3.8 3.1 ND s.d. 22.9 2.11 43.9 12.5 0.82 0.48 0.27 0.88 0.94 0.66 3.53 Mean 9.5 1.8 — — — 6.21 10.75 7.9 — — 0.4 s.d. 7.98 0.97 — — — 0.68 0.29 0.83 — — 3.47 5.1.2. Procedure The procedure was the same as in Experiment 2. The experimental session lasted about 30 minutes. 184 Burani and Thornton 5.1.3. Participants Fifty participants, mostly University students, were paid to participate in the experiment. All were native speakers of Italian. 5.1.4. Results and discussion The data of three participants, whose mean reaction times for correct responses or whose error rates were more extreme than 2 s.d. from the mean of all participants, were excluded from further analysis. Using the remaining forty-seven participants, the mean reaction times and error rates for all items were obtained. Mean reaction times by items and percentages of errors for the five experimental sets are shown in Table 5. Table 5. Experiment 3. Mean reaction times by items in ms and % error. Suffixed derived words with high-frequency root and high-frequency suffix (HH); high-frequency root and low-frequency suffix (HL); low-frequency root and high-frequency suffix (LH); low-frequency root and low-frequency suffix (LL); nonderived words (ND). HH HL LH LL ND Mean Reaction Time 603 605 641 645 640 % Error 5.4 8.6 14.1 17.1 13.6 Results on the five sets were submitted to one-way ANOVAs. Additionally, two-way analyses of variance, with root frequency (high vs. low) and suffix frequency (high vs. low) as the two factors were performed on the four derived sets. Results of one-way ANOVAs showed a significant difference among experimental categories, on both reaction times (F1(4,184) = 35.77, p <.0001, MSE= 483.08; F2(4,80) = 4.05, p<.005, MSE= 1,816.13) and errors (F1(4,184) = 21.09, p<.0001, MSE= 1.43; F2(4,80) = 2.84, p<.03, MSE= 29.35). Post-hoc comparisons based on the Duncan’s test on the The interplay of root, suffix and whole-word frequency 185 means by items showed that both HH and HL derived words gave rise to significantly faster reaction times than words in the other three sets (for all comparisons involving HH or HL words, p<.025). Additionally, HH and HL derived words did not differ from one another (p>.1). Analogously, no differences were found among LH, LL and ND words (always p>.1). A similar pattern was found on errors, with significant differences between HH words on the one hand, and LH, LL, and ND words, on the other (always p<.05), and between HL and LL words (p=.05). The two-way ANOVAs on the four derived sets, with root frequency (high vs. low) and suffix frequency (high vs. low) as the two factors, confirmed a root effect only, by both participants and items, on both reaction times and errors (F1 (1,46) = 129.3, p<.0001, MSE= 438.24; F2 (1,64) = 14.59, p<.0001, MSE= 1,740.71 for reaction times; F1 (1,46) = 66.38, p<.0001, MSE= 1.53; F2 (1,64) = 9.14, p<.004, MSE= 30.66 for errors). On reaction times, no suffix effect was found (F<1), and no interaction (F<1). A suffix effect was found on errors, in the analysis by participants only (F1 (1,46) = 9.83, p<.003, MSE= 1.35; F2 (1,64) = 1.20, p>.1, MSE= 30.7), with words with low-frequency suffixes giving rise to more errors than words with high-frequency suffixes. No interaction was found on errors (F<1). Results of Experiment 3 confirmed morpheme-based processing for HH words. As expected, these derived words showed faster reaction times and higher accuracy because of including high-frequency morphological constituents. The outcomes of Experiment 3 also suggested whole-word processing for LL derived words – the latter words, whose constituent morphemes were low-frequency, did not show any advantage with respect to nonderived words of the same surface frequency. The results of Experiment 3 were not in accordance with the predictions made for HL and LH derived words. Differently from Experiment 2, in which the two sets of derived words which include one high-frequency constituent did not differ from each other, and showed intermediate reaction times and accuracy with respect to words including two highfrequency constituents on the one hand, and words including two lowfrequency constituents on the other, in Experiment 3 HL and LH words gave rise to contrasting results. Apparently, the imperfect balance in rated familiarity among word sets was responsible for part of the effects found in Experiment 2. A better matching among experimental sets led to a different pattern of results in Experiment 3. While words with high-frequency root 186 Burani and Thornton and low-frequency suffix (HL words) were as fast as words with both root and suffix of high frequency (HH words), words with a high-frequency suffix but a low-frequency root (LH words) did not differ either from words in which both constituents were low-frequency (LL words), nor from words with no morphological constituency, i.e., nonderived (ND) words. From these results it could be argued that the major determinant of lexical decision performance to suffixed derived words is the root frequency, with no role for the frequency of the suffix. In the General discussion a processing account will be discussed, that reconciles these results on words with the apparently contrasting results on suffixed pseudowords, including results of Experiment 1, in which a strong role for suffix frequency was found. 6. General discussion Three lexical decision experiments investigated how the frequency of morphemic constituents, namely roots and suffixes, affects the visual processing of low-frequency derived stimuli. In Experiment 1, pseudowords made up of Italian derivational suffixes of various frequencies and meaningless pseudoroots were contrasted to pseudowords in which the same pseudoroots were combined with control orthographically legal final sequences. These final sequences were matched to the suffixes for frequency and for other relevant variables, but were not suffixes themselves. There were three sets of suffixed/control pseudowords, differing in the frequency of the final sequences, either high, medium or low. Only pseudowords that included high-frequency suffixes showed interference, namely longer decision times and higher error rates, with respect to their matched non suffixed controls. Neither pseudowords including medium-frequency suffixes nor pseudowords with low-frequency suffixes differed from their respective controls. These results are in accordance with previous results by Burani et al. (1997), and extend them to pseudoword contexts in which no root is present. The results provide further evidence that the activation of morphemic access units corresponding to suffixes is constrained, in visual tasks, by the quantifiable characteristics of the suffixes themselves (see also Laudanna and Burani 1995; Laudanna, Burani and Cermele 1994). Experiment 2 and 3 explored whether the frequency of the root or the suffix affected lexical decision to low-frequency suffixed derived Italian The interplay of root, suffix and whole-word frequency 187 words. Four sets of derived nouns and adjectives were contrasted in Experiment 2. All of the words in the four sets had a low frequency, but differed with respect to the frequency of their morphemic constituents, either high or low with orthogonal variation. The results showed that reaction times and accuracy to derived words were affected by the frequency of both roots and suffixes. Lexical decisions were faster and more accurate when the derived words included two high-frequency constituents, they were the slowest and the least accurate when both constituents had low frequency, and had intermediate times and error rates when the derived words included only one high-frequency constituent, either the root or the suffix. No differential effects of root and suffix frequency were found. However, post-hoc controls showed that the effects of morphemic frequency on lexical decision performance were possibly confounded with effects of wordfamiliarity, which differed among the four sets in a way that paralleled differences in the frequency of morphological constituents. Four new sets of low-frequency derived words were tested in Experiment 3. The derived words differed in the frequency of the constituent roots and suffixes, which were orthogonally varied as in Experiment 2. However, the derived words were also matched for ratings of familiarity. In this experiment, the sets of derived words were contrasted with a set of low-frequency nonderived words, matched to the derived words for all the relevant variables, including word familiarity. When word familiarity was controlled, lexical decisions to derived words were found to be a function of the frequency of the root only, irrespective of suffix frequency. Decision latencies to the two sets of derived words with high-frequency roots, irrespective of suffix frequency, were faster than to the two sets of derived words with low-frequency roots. Moreover, with low root frequency items, there was no effect of suffix frequency, either high or low. Finally, performance to words with low-frequency roots did not differ from performance to nonderived words, thus suggesting analogous processing for derived words with low-frequency constituents and nonderived words. Collectively, these findings reveal effects of suffix as well as root units in the processing of derived stimuli. They also indicate that results may be affected by word familiarity. We will discuss first the results on real words, then we will show how they could be reconciled with results on pseudoword processing, in which an effect of suffix frequency was found. Experiment 3 showed that, when low-frequency derived words were equated for ratings of familiarity, only those that included a high-frequency root resulted in faster access relative to nonderived words of similar fre- 188 Burani and Thornton quency/familiarity. Thus access through activation of morphemes is beneficial only for derived words with high-frequency roots. By contrast, suffixed derived words that did not include any high-frequency constituent, or only included a high-frequency suffix, did not show any processing advantage with respect to derived words of similar low-frequency. Hence, lexical decision latencies to words with low-frequency roots, irrespective of suffix frequency, seem to be a function of surface (whole-word) frequency, and are analogous to words with no morphemic constituency. Thus the main result of Experiment 3 is that access to low-frequency derived words is not always obtained via morphological parsing. The full-form access route is also involved, and in some cases it determines response latency. How could this pattern of results be interpreted? In the framework of a parallel dual-route model, whole-word activation would start simultaneously and proceed with analogous time courses for all the five categories of words considered in Experiment 3 because of their similarly low surface frequency. However, different outcomes are expected for the different words, due to the different probability of morphemic access. That words with high-frequency roots and high-frequency suffixes (HH words) should result in faster and more accurate performance with respect to the other words is an expected finding, because the higher frequency of morphemes with respect to the frequency of the whole-word combination should affect positively both the speed and accuracy of access through morphemic activation. The result for derived words in which both the root and the suffix are low-frequency (LL words) is also expected, on the assumption that the slightly higher frequency of the constituents might not be large enough to result in advantageous morphemic processing with respect to whole-word processing. However, the asymmetrical results between words with high-frequency root and low-frequency suffix (HL words), and words with low-frequency root and high-frequency suffix (LH words) call for some refinement of a model in which whole-word activation and morphemic activation are assumed to occur in parallel. Some suggestion comes from studies that have investigated how, in silent sentence reading, eye fixations on compounds are affected by component morphemes. In these studies, it has been shown that words composed of eight letters or more, like our derived words, typically require more than one eye-fixation. When (at least) two eye-fixations are involved, the frequency of the first morphemic constituent strongly influences the duration of the first fixation on the target word (Hyönä and The interplay of root, suffix and whole-word frequency 189 Pollatsek 1998). The frequency of the second morpheme influences gaze duration, but its influence is not immediate, and only affects relatively later processing (Pollatsek, Hyönä and Bertram 2000). Furthermore, second constituent effects may overlap in time with whole-word effects: The frequency of the whole word influences eye movements at least as early as the frequency of the second constituent, and can have an effect even before access of the second constituent (Pollatsek, Hyönä and Bertram 2000). In the framework suggested by these authors, the identification of morphologically complex words involves parallel processing of both morphological constituents and whole-word representations. The two morphological constituents each have an effect but differ in the time course. While the probability of whole-word processing would be the same for all the derived words with similar frequency/familiarity, a head start to access through morphological segmentation might be available only for words with a highfrequency first constituent (in our case, the root). A high-frequency second constituent (here, the suffix) would not result in a significant advantage, with respect to whole-word access. In a framework in which no different head start is assumed for morphemes occurring in different word positions, not even when they are of relevant length (Baayen and Schreuder 2000; Baayen, Schreuder and Sproat 2000), the present results could be interpreted as arising at stages following segmentation, in which the morphemes are combined and the result of composition is checked for licensing. The model proposed by Baayen, Schreuder and coworkers distinguishes, in the route for morphological processing, a number of successive processing stages. According to Baayen and Schreuder (1999) (see also Baayen and Schreuder 2000; Baayen, Schreuder and Sproat 2000), access representations are activated over time by the sensory input through the stages of perceptual identification and segmentation. Access representations are assigned resting activation levels that are proportional to their frequency of occurrence, with high-frequency morphemes reaching a pre-set activation threshold more 8 quickly than low-frequency morphemes. Once an access representation for a root or an affix reaches the threshold activation level, it is copied to a short-term memory buffer. Once the representations provide full, nonoverlapping spannings of the input, they are passed on to the following processing stages of licensing (the checking for subcategorisation compatibility), composition (the compositional computation of the meaning of the whole from its parts) and semantic activation of semantically related representations in long-term memory. 190 Burani and Thornton In this model, derived words with different morphological constituents should result in different processing times. The access representations of words whose constituents are both high-frequency (HH words) would be passed on to the processing stages of licensing, composition and semantic activation more quickly than the other words. For words in which only one constituent is high-frequency (HL and LH words), the access representation corresponding to the high-frequency constituent is quickly copied to the short-term memory buffer. However, the full segmentation of the input would be delayed by the slow activation of the access representation corresponding to the low-frequency morpheme. At the segmentation stage, at least one frequent constituent should be easily identifiable for effective segmentation to occur, in that identification of one highly activated morpheme should leave the remainder as a prime candidate for a second constituent. When no morphemic access representation can be easily segmented, like in LL words in which both constituents are low-frequency, additional time consuming procedures have to be called upon. Thus, there might be some extra segmentation cost involved for morphemic access to LL words, which would give an advantage to wholeword access. At the segmentation stage, HH words would be favoured by morphological processing with respect to both HL words and LH words. However, at the composition and licensing stages, a main role for the root morpheme could be assumed. At these stages, for both HH and HL suffixed words, a highly activated root is available. In both cases, the root representation activates the set of derivational affixes that are compatible with it. The amplitude of this set is similar for both HH and HL words, which have the same mean derivational family size (see Table 4). Thus little evidence from the orthographic input is needed in both cases, in order to activate the correct suffix among the set of pre-activated ones: Independently of its frequency, the presented suffix should be activated, combined, and the combination checked for licensing, among the same (small) number of possible suffixes. In the case of LH words, no highly activated root is available from the start. The representation that is highly activated at the composition and licensing stages is the one corresponding to the suffix. At these stages, the representation corresponding to a high-numerosity suffix is compatible with a large number of representations corresponding to roots (as many as 240 root types on average, if calculated in the corpus; about 650 root types if calculated in the dictionary). Hence, the orthographic evidence required from the input should be large, in order to be correctly The interplay of root, suffix and whole-word frequency 191 activated, composed and finally licensed. But this is not the case when the stimulus includes a scarcely activated low-frequency root, as in the case of LH derived words. The process of composition and licensing would be long for LH words, thus allowing for processing through whole-word to win the race. In summary, for both LH and LL words, for which activation via morphemes is so drastically slowed down in different processing components, whole-word processing would be faster in providing access to the lexicon, not differently from nonderived (ND) words, for which wholeword processing is the only possible route. The results on suffixed pseudowords that were obtained in Experiment 1 can now be reconciled with results on suffixed words. In Experiment 1, pseudowords made up of a pseudoroot and a high-frequency/numerosity suffix resulted in longer reaction times and lower accuracy with respect to matched pseudowords in which the same pseudoroots were combined with pseudosuffixes. Pseudowords made up of a pseudoroot and a highfrequency suffix are in a way not that different from LH words, which include a low-frequency root and a high-frequency suffix. Therefore, analogously to suffixed LH words, pseudowords of this sort are subject to morphemic segmentation because of the very high frequency/numerosity of one constituent, namely the suffix. After reaching the threshold activation level and being copied to the short-term memory buffer, the access representation corresponding to the suffix cannot be passed on to the subsequent stages of composition and licensing because no full spanning of the input is provided. However, the very same attempt at morphemic segmentation causes delay or interference in the process of nonword decision, thus resulting in slower decision times and higher error rates. By contrast, neither delay nor interference would occur in the case of pseudowords made up of a pseudoroot and a medium/low-frequency suffix, because here no morphemic constituent would be frequent enough to trigger morphemic segmentation (at least not within the deadline for lexical decision). The results obtained by Burani et al. (1997) can find a similar account. The pseudowords investigated by Burani et al. (1997) were made up of a real root of medium/low frequency and a suffix that could be either highor low-frequency. Pseudowords with medium-frequency root and highfrequency suffixes activate two access representations that are both likely to be passed on to the composition and licensing stages. Thus they were subject to (morpho-)lexical interference in nonword decision. However, interference was not found in lexical decision to either pseudowords made up of a (medium-frequency) root and a low-frequency suffix, or to 192 Burani and Thornton pseudowords made up of a (medium-frequency) root and a pseudosuffix. In the latter cases no morphemic constituent was frequent enough to trigger morphemic segmentation that would leave the remainder as a prime candidate for a second constituent. In summary, the results reported in the present study on both suffixed derived words and suffixed pseudowords, together with previous results on morphological pseudowords, point to the conclusion that the assumption of a higher probability of morphemic parsing for low-frequency derived words (Burani and Laudanna 1992; Frauenfelder and Schreuder 1992) needs to be further specified. Not all low-frequency derived words might be similarly subject to be accessed via morphological parsing. In formulating predictions for access through morphemic decomposition, the complex balancing between root and affix properties, including quantitative properties like frequency and numerosity, are to be taken into account. The complex balancing of root and suffix quantitative properties should be relevant for expecting costs of morphological parsing, as well as benefits. In the studies by Bertram, Laine and Karvinen (1999) and by Bertram, Schreuder and Baayen (2000), conducted on Finnish morphologically complex words, it has been proposed that some derived words (those with unproductive or homonymous suffixes) are accessed on the basis of storage, thus are as quick as monomorphemic Finnish words. This prediction finds confirmation in the lexical decision to our derived words with lowfrequency root and low-frequency suffix (LL words), which did not differ from nonderived (ND) words. However, this same prediction would be too simplistic in the case of derived words with a low-frequency/numerosity suffix and a high-frequency root (HL words) on the one hand, and for derived words with a high-frequency/numerosity suffix but a low-frequency root (LH words) on the other hand. Apparently, neither Bertram, Laine and Karvinen (1999), nor Bertram, Schreuder and Baayen (2000) specifically investigated the differences between these cases. The present results on Italian suffixed derived words provide some evidence for the processing of derived words of this sort. The interplay of root, suffix and whole-word frequency Appendices Appendix A Experiment 1 Suffixed pseudowords and their controls with mean RT and % Error. HF = Pseudowords with high-frequency final sequence HF Suffixed Control ITEM RT Prucezza 723 matirezza 757 accogezza %E ITEM RT %E 13.6 prucondo 638 0 9.1 matirondo 699 13.6 748 9.1 accogondo 759 18.2 sillerezza 734 13.6 sillerondo 709 4.5 feldismo 768 22.7 feldanca 624 0 rovollismo 714 4.5 rovollanca 683 0 rachenismo 718 13.6 rachenanca 704 13.6 cabilismo 771 22.7 cabilanca 806 9.1 cempenista 788 22.7 cempenosto 693 0 livonista 754 18.2 livonosto 662 4.5 ascobista 744 9.1 ascobosto 711 0 pirgista 655 4.5 pirgosto 718 9.1 MEAN 739 13.6 700 6.1 193 194 Burani and Thornton Experiment 1 Suffixed pseudowords and their controls with mean RT and % Error. MF = Pseudowords with medium-frequency final sequence MF Suffixed Control ITEM RT lengardo 710 elbirardo 725 fozzardo mevinardo %E ITEM RT %E 9.1 lengerta 660 0 0 elbirerta 721 4.5 681 0 fozzerta 747 9.1 674 9.1 mevinerta 737 22.7 varbesco 757 0 varbanna 649 13.6 orcittesco 742 0 orcittanna 683 4.5 sicoresco 728 9.1 sicoranna 748 4.5 dolmibesco 664 0 dolmibanna 707 9.1 stemigno 719 13.6 stemusso 702 0 trudigno 686 0 trudusso 676 9.1 seltigno 622 4.5 seltusso 684 4.5 701 4.1 MEAN 701 7.4 The interplay of root, suffix and whole-word frequency Experiment 1 Suffixed pseudowords and their controls with mean RT and % Error. LF = Pseudowords with low-frequency final sequence LF Suffixed Control ITEM RT gurnense 713 adricense 685 tirfense %E ITEM RT %E 4.5 gurnombe 653 4.5 0 adricombe 634 4.5 633 0 tirfombe 686 0 enovense 614 0 enovombe 660 9.1 siramigia 735 13.6 siramegio 687 0 amittigia 718 13.6 amittegio 678 4.5 furnigia 662 0 furnegio 684 9.1 davelligia 691 0 davellegio 765 4.5 parcinoide 739 4.5 parcinaudo 647 0 balmoide 688 4.5 balmaudo 701 4.5 taripoide 642 9.1 taripaudo 672 4.5 cettoide 643 4.5 cettaudo 676 4.5 MEAN 680 4.6 MEAN 679 4.2 195 196 Burani and Thornton Appendix B Experiment 2 Experimental items with mean RT and % Error HH = Words with high-frequency root and high-frequency suffix HL = Words with high-frequency root and low-frequency suffix HH WORD HL Root Suf- Word Freq. fixFreq Freq. RT %E WORD Root Suffix Word Freq. Freq. Freq. RT %E . bassezza 414 1,557 1 665 0 umanoide 324 12 1 683 giornalismo 307 639 9 588 0 pazzoide 175 12 1 631 2.9 centrismo 501 639 2 652 5.7 ferrigno 369 55 2 739 14.3 acquario 17.2 1,120 1,177 3 540 0 testardo 698 60 4 548 0 nudista 253 984 1 613 0 donnesco 1,556 90 2 658 11.4 macchinista 305 984 8 600 0 guerresco 630 90 1 623 8.6 amatore 603 2,074 3 563 8.6 levatoio 927 102 5 606 0 tiratore 524 2,074 1 601 2.9 spogliatoio 108 102 1 590 0 goloso 117 1,335 2 539 2.9 violaceo 126 13 5 677 14.3 dentale 250 888 1 622 5.7 pacifico 475 53 10 547 2.9 ottimale 125 888 1 573 0 frutteto 335 46 9 622 0 credibile 1,485 262 5 603 2.9 roseto 363 46 1 567 0 501 1,859 3.1 597 2.5 MEAN 507 57 3.5 624 5.9 MEAN The interplay of root, suffix and whole-word frequency Appendix C Experiment 3 Experimental items with mean Rt and % Error. HH = Words with high-frequency root and high-frequency suffix HL = Words with high-frequency root and low-frequency suffix HH WORD HL Root Suffix Word Freq. Freq. Freq. RT %E WORD Root Suffix Word Freq. Freq. RT %E Freq. liberismo 877 639 1 661 14.9 donnesco 1,556 90 2 651 27.7 carnoso 329 1,335 4 619 0 campestre 646 59 5 604 4.3 godibile 187 956 3 620 19.1 guerresco 630 90 1 603 2.1 scenario 244 1,177 13 559 4.3 muraglia 510 184 17 580 6.4 numerale 475 4,942 1 642 6.4 sanguigno 540 55 10 575 0 consumismo 160 639 2 628 0 pacifico 475 53 10 549 0 temibile 223 956 6 600 6.4 spogliatoio 108 102 1 585 0 pensatore 2,204 2,074 1 613 0 parlatoio 2,075 102 2 687 12.8 ordinanza 773 1,485 8 568 0 bambinesco 693 90 1 610 6.4 erboso 236 1,335 6 605 4.3 onorifico 215 53 1 664 17.0 piccolezza 937 1,557 5 600 0 pazzoide 173 12 1 620 21.3 2.1 serale 1,266 4,942 11 604 12.8 romanzesco 109 90 1 606 velocista 150 984 3 575 0 testardo 698 60 4 571 0 bruttezza 228 1,557 3 605 4.3 alpestre 187 59 5 651 34.0 bestiale 233 4,942 8 573 0 canneto grossezza 391 1,557 2 610 navale 394 4,942 13 573 MEAN 547 2,119 5.29 603 204 46 13 597 8.5 17 roseto 363 46 1 576 4.3 2.1 poliziesco 238 90 3 549 0 5.4 MEAN 554 75.3 4.6 605 8.6 197 198 Burani and Thornton Experiment 3 Experimental items with mean Rt and % Error. LH = Words with low-frequency root and high-frequency suffix LL = Words with low-frequency root and low-frequency suffix LH WORD LL Root Suffix Word Freq. Freq. RT %E WORD Freq. Root Suffix Word Freq. Freq. RT %E Freq. limatura 22 1,482 2 696 31.9 luridume 10 23 2 679 42.5 astrale 68 4,942 3 616 10.6 zingaresco 33 90 2 636 2.1 flautista 26 984 3 677 23.4 bugiardo 77 60 13 535 2.1 maestoso 25 1,335 10 611 66 90 1 730 14.9 igienista 30 984 1 635 14.9 beffardo 49 60 5 608 12.8 gaiezza 33 1,557 2 660 14.9 viscidume 8 23 2 743 40.4 rozzezza 33 1,557 2 653 14.9 orinatoio 10 102 1 702 31.9 rugoso 21 1,335 3 610 2.1 agrumeto 22 46 1 660 23.4 intuibile 32 956 3 692 40.4 cupidigia 20 7 6 645 14.9 rudezza 33 1,557 2 607 2.1 brodaglia 44 184 1 700 46.8 doganale 22 4,942 1 660 4.3 gigantesco 72 90 10 576 0 schedario 31 1,177 8 620 6.4 lerciume 11 23 2 690 36.2 punibile 69 956 1 600 14.9 fiabesco 10 90 1 564 2.1 lagnanza 45 1,485 1 641 27.7 serbatoio 29 102 1 576 2.1 lanoso 69 1,335 2 659 19.1 burlesco 12 90 1 608 6.4 fenomenale 54 4,942 1 651 8.5 sudiciume 22 23 2 629 0 pessimismo 35 639 7 602 0 prolifico 28 53 1 679 12.8 38.1 1,892 3.1 641 31 68 3.1 645 17.1 MEAN 4.3 serpentesco 14.1 MEAN The interplay of root, suffix and whole-word frequency 199 Experiment 3 Experimental items with mean Rt and % Error. ND = Nonderived words ND WORD avezzo Root Word Freq. Freq. RT %E 18 6 670 12.8 caparbio 9 2 684 14.9 damigiana 6 2 692 31.9 sbilenco 8 4 702 31.9 cospicuo 12 4 651 19.1 giaguaro 2 1 661 12.8 aragosta 8 2 602 8.5 scirocco 12 8 561 2.1 farabutto 8 4 631 14.9 inerme 9 7 682 25.5 ascesso 1 1 649 6.4 collasso 3 3 559 0 scarlatto 35 15 668 17.0 laringe 3 2 668 25.5 calunnia 14 7 605 2.1 rimorchio 9 4 630 4.3 trapezio 4 3 570 2.1 MEAN 9.5 4.4 640 13.6 Notes * We are indebted to Emanuela Rellini for running Experiment 2, and to Alberto Spuntarelli for his precious contribution to the various phases of Experiment 3. We also thank Harald Baayen, Rob Schreuder, Alessandro Laudanna, Daniela Traficante, Lisa S. Arduino, Francesca M. Dovetto and Sergio Carlomagno for valuable discussions. Finally, we thank the referees, Laurie Feldman, Jen Hay and Harald Baayen, whose revisions and comments helped to improve the paper. 200 1. 2. 3. 4. 5. 6. 7. Burani and Thornton An exception is Bradley’s (1979) study, in which words involving different suffixes with different effects on the orthographic/phonological characteristics of the stem were contrasted (see also Tsapkini, Kehayia and Jarema 1998; 1999; Vannest and Boland 1999). For instance, the three Italian suffixes -ista, -ezza and -oide could be compared. While the first two have high frequency and high numerosity in a corpus (frequency: 984 and 1,557/1,500,000, respectively; numerosity: 145 and 187, respectively), they differ in productivity, if we take as indicator of productivity the number of words containing these suffixes found in five Italian dictionaries of neologisms. While -ista appears in as many as 417 neologisms, -ezza appears in only 3 neologisms. These data can be further compared with those concerning the suffix -oide, which has a very low frequency and low numerosity in the corpus (frequency: 12/1,500,000; numerosity: 10), but appears in 11 neologisms, i.e., in four times as many as the neologisms in which the very frequent suffix -ezza appears. If the higher probability of storage (or whole-word access) vs. computation (or morphemic access) is determined by high whole-word frequency, also inflected high-frequency words should be likely to be accessed as whole-forms. Recent evidence for storage of high-frequency regularly inflected English words comes from Alegre and Gordon (1999a). Related evidence can be found in Baayen, Dijkstra and Schreuder (1997), and in Baayen, Burani and Schreuder (1997), for Dutch and Italian regularly inflected words, respectively. Although nonderived words did not include any derivational affix, they included, like the derived words and like almost any Italian word, an inflectional suffix for number and gender. For this reason we name them "nonderived", not "monomorphemic". We selected nonderived words with very low cumulative root frequency, in a way that the cumulative root frequency was as close as possible to surface frequency. Any contribution of the frequency of the inflection to morphemic access would be the same for all the five word sets. The total number of selected items was not as large as we had aimed at. It turned out that in trying to match items for all the variables, we had exploited all the possible words in our corpus. Specifically, derived words in the sets with low-frequency suffixes (HL and LL), that were already very few in the corpus, had to be further reduced in number in order to be matched with the other words. Many LL words were excluded because they had lower familiarity with respect to words in the other sets. Additionally, the inclusion of nonderived words made even more difficult to match words across sets, because of the tendency of nonderived words to be shorter than derived words (see Campos 1993). Interestingly, matching derived words for rated familiarity left the robust root effect unchanged, while suffix frequency effects were completely washed out. The interplay of root, suffix and whole-word frequency 8. 201 This suggests that familiarity rating is a task that is much more sensitive to properties of the suffix than to properties of the root. Recent evidence from our laboratory (Burani, Bimonte and Barca, in preparation) has shown that, on a larger sample of low-frequency suffixed derived words (N=122), familiarity ratings had a significant correlation with (log) suffix frequency (r = .43, p<.0001), while they had no correlation with (log) root frequency (r = -.06). Further research is required in order to investigate why should this be case. This "segmentation-through-recognition" approach should avoid the objections raised by Andrews and Davis (1999) to the interactive activation accounts of morphological decomposition, by assuming that "The activation weights of access representations are increased only for constituents that are aligned with the left or right edge of the word, or that are aligned with access representations that have reached threshold and that themselves are edgealigned, either with the word edge itself or with another edge-aligned constituent in the short-term-memory buffer." (Baayen and Schreuder 2000: 5). References Alegre, Maria, and Peter Gordon 1999a Frequency effects and the representational status of regular inflections. Journal of Memory and Language 40: 41–61. Alegre, Maria, and Peter Gordon 1999b Rule-based versus associative processes in derivational morphology. Brain and Language, 68: 347–354. Andrews, Sally 1986 Morphological influences on lexical access: Lexical or nonlexical effects? Journal of Memory and Language 25: 726–740. Andrews, Sally, and Colin Davis 1999 Interactive activation accounts of morphological decomposition: Finding the trap in the Mousetrap? Brain and Language 68: 355– 361. Baayen, R. Harald 1989 A corpus-based approach to morphological productivity. Statistical analysis and psycholinguistic interpretation. Ph.D dissertation, Department of Linguistics, Vrije Universiteit, Amsterdam. Baayen, R. Harald 1992 Quantitative aspects of morphological productivity. In Yearbook of morphology 1991, Geert E. Booij and Jaap van Marle (eds.), 109–149. Dordrecht: Kluwer. 202 Burani and Thornton Baayen, R. Harald, Cristina Burani, and Robert Schreuder 1997 Effects of semantic markedness in the processing of regular nominal singulars and plurals in Italian. In Yearbook of morphology 1996, Geert E. Booij and Jaap van Marle (eds.), 13–33. Dordrecht: Kluwer. Baayen, R. Harald, Ton Dijkstra, and Robert Schreuder 1997 Singulars and plurals in Dutch: Evidence for a parallel dual-route model. Journal of Memory and Language 37: 94–117. Baayen, R. Harald, and Anneke Neijt 1997 Productivity in context: a case study of a Dutch suffix. Linguistics 35: 565–587. Baayen, R. Harald, and Robert Schreuder 1999 War and peace: Morphemes and full forms in a noninteractive activation parallel dual-route model. Brain and Language 68: 27–32. Baayen, R. Harald, and Robert Schreuder 2000 Towards a psycholinguistic computational model for morphological parsing. Philosophical Transactions of The Royal Society (Series A: Mathematical, Physical and Engineering Sciences) 358: 1–13. Baayen, R. Harald, Robert Schreuder, and Richard Sproat 2000 Morphology in the mental lexicon: A computational model for visual word recognition. In Lexicon development for speech and language processing, Frank van Eynde and Dafydd Gibbon (eds.), 267–291. Dordrecht: Kluwer. Beauvillain, Cécile 1996 The integration of morphological and whole-word form information during eye-fixations on prefixed and suffixed words. Journal of Memory and Language 35: 801–820. Bentin, Slomo, and Laurie B. Feldman 1990 The contribution of morphological and semantic relatedness to the repetition effect at long and short lags: Evidence from Hebrew. Quarterly Journal of Experimental Psychology 42(A): 693–711. Bertram, Raymond, R. Harald Baayen, and Robert Schreuder 2000 Effects of family size for derived and inflected words. Journal of Memory and Language 42: 390–405. Bertram, Raymond, Matti Laine, and Katja Karvinen 1999 The interplay of word formation type, affixal homonymy, and productivity in lexical processing: Evidence from a morphologically rich language. Journal of Psycholinguistic Research 28: 213–226. The interplay of root, suffix and whole-word frequency 203 Bertram, Raymond, Robert Schreuder, and R. Harald Baayen 2000 The balance of storage and computation in morphological processing: The role of word formation type, affixal homonymy, and productivity. Journal of Experimental Psychology: Learning, Memory and Cognition 26: 489–511. Bradley, Dianne C. 1979 Lexical representation of derivational relation. In Juncture, Mark Aronoff and Marie Louise Kean (eds.), 37–55. Cambridge, MA: MIT Press. Burani, Cristina, Daniela Bimonte, and Laura Barca in prep. Knowledge of morphology as an aid to word comprehension and vocabulary learning. Burani, Cristina, and Alfonso Caramazza 1987 Representation and processing of derived words. Language and Cognitive Processes 2: 217–227. Burani, Cristina, Francesca M. Dovetto, Alberto Spuntarelli, and Anna M. Thornton 1999 Morpho-lexical naming of new root-suffix combinations: The role of semantic interpretability. Brain and Language 68: 333–339. Burani, Cristina, Francesca M. Dovetto, Anna M. Thornton, and Alessandro Laudanna 1997 Accessing and naming suffixed pseudo-words. In Yearbook of morphology 1996, Geert E. Booij and Jaap van Marle (eds.), 55– 72. Dordrecht: Kluwer. Burani, Cristina, and Alessandro Laudanna 1992 Units of representation of derived words in the lexicon. In Orthography, phonology, morphology, and meaning, Ram Frost and Leonard Katz (eds.), 361–376. Amsterdam: North-Holland. Burani, Cristina, Anna M. Thornton, Claudio Iacobini, and Alessandro Laudanna 1995 Investigating morphological non-words. In Crossdisciplinary approaches to morphology, Wolfgang U. Dressler and Cristina Burani (eds.), 37–53. Wien: Verlag der Österreichischen Akademie der Wissenschaften. Bybee, Joan 1995a Regular morphology and the lexicon. Language and Cognitive Processes 10: 425–455. Bybee, Joan 1995b Diachronic and typological properties of morphology and their implications for representation. In Morphological aspects of language processing, Laurie B. Feldman (ed.), 225–246. Hove: Erlbaum. 204 Burani and Thornton Campos, Alfredo 1993 Simple and derived words: Influence on other values of words. Perceptual and Motor Skills 77: 1193–1194. Caramazza, Alfonso, Alessandro Laudanna, and Cristina Romani 1988 Lexical access and inflectional morphology. Cognition 28: 297– 332. Chialant, Doriana, and Alfonso Caramazza 1995 Where is morphology and how is it processed? The case of written word recognition. In Morphological aspects of language processing, Laurie B. Feldman (ed.), 55–76. Hove: Erlbaum. Colé, Pascale, Cécile Beauvillain, and Juan Segui 1989 On the representation and processing of prefixed and suffixed derived words: A differential frequency effect. Journal of Memory and Language 28: 1–13. Coltheart, Max, Eileen Davelaar, Jon T. Jonasson, and Derek Besner 1977 Access to the internal lexicon. In Attention and performance II, Stanislav Dornič (ed.), 335–355. New York: Academic Press. Connine, Cynthia M., John Mullennix, Eve Shernoff, and Jennifer Yelen 1990 Word familiarity and frequency in visual and auditory word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition 16: 1084–1096. Coolen, Riet, Henk J. van Jaarsveld, and Robert Schreuder 1991 The interpretation of isolated novel nominal compounds. Memory and Cognition 19: 341–352. de Jong, Nivja H., Robert Schreuder, and R. Harald Baayen 2000 The morphological family size effect and morphology. Language and Cognitive Processes 15: 329–365. Feldman, Laurie B., and Emily G. Soltano 1999 Morphological priming: The role of prime duration, semantic transparency, and affix position. Brain and Language 68: 33–39. Frauenfelder, Uli H., and Robert Schreuder 1992 Constraining psycholinguistic models of morphological processing and representation: the role of productivity. In Yearbook of morphology 1991, Geert E. Booij and Jaap van Marle (eds.), 165–183. Dordrecht: Foris. Gernsbacher, Morton Ann 1984 Resolving 20 years of inconsistent interactions between lexical familiarity and orthography, concreteness, and polysemy. Journal of Experimental Psychology: General 113: 256–281. The interplay of root, suffix and whole-word frequency 205 Hagiwara, Hiroko, Yoko Sugioka, Takane Ito, Mitsuru Kawamura, and Junichi Shiota 1999 Neurolinguistic evidence for rule-based nominal suffixation. Language 75: 739–763. Hay, Jennifer 2000 Causes and consequences of word structure. Ph.D diss., Field of Linguistics, Northwestern University. Hay, Jennifer 2001 Lexical frequency in morphology: is everything relative? Linguistics 39: 1041–1070. Hay, Jennifer, and R. Harald Baayen 2002 Parsing and productivity. In Yearbook of morphology 2001, Geert E. Booij and Jaap van Marle (eds.). Dordrecht: Kluwer. Holmes, Virginia M. and J. Kevin O’Regan 1992 Reading derivationally affixed French words. Language and Cognitive Processes 7: 163–192. Hyönä, Jukka, and Alexander Pollatsek 1998 Reading Finnish compound words: Eye fixations are affected by component morphemes. Journal of Experimental Psychology: Human Perception and Performance 24: 1612–1627. Istituto di Linguistica Computazionale CNR 1989 Corpus di italiano contemporaneo. Unpublished manuscript. Pisa. Jarvella, Robert J., and Ola Wennstedt 1993 Recognition of partial regularity in words and sentences. Scandinavian Journal of Psychology 34: 76–85. Laine, Matti 1996 Lexical status of inflectional and derivational suffixes: Evidence from Finnish. Scandinavian Journal of Psychology 37: 238–248. Laudanna, Alessandro, and Cristina Burani 1995 Distributional properties of derivational affixes: implications for processing. In Morphological aspects of language processing, Laurie B. Feldman (ed.), 345–364. Hove: Erlbaum. Laudanna, Alessandro, Cristina Burani, and Antonella Cermele 1994 Prefixes as processing units. Language and Cognitive Processes 9: 295–316. Lima, Susan D., and Alexander Pollatsek 1983 Lexical access via an orthographic code? The basic orthographic syllabic structure (BOSS) reconsidered. Journal of Verbal Learning and Verbal Behavior 22: 310–332. 206 Burani and Thornton Marslen-Wilson, William, Lorraine K. Tyler, Rachelle Waksler, and Lianne Older 1994 Morphology and meaning in the mental lexicon. Psychological Review 101: 3–33. Meunier, Fanny, and Juan Segui 1999 Morphological priming effect: The role of surface frequency. Brain and Language 68: 54–60. Peperkamp, Sharon 1995 Prosodic constraints in the derivational morphology of Italian. In Yearbook of morphology 1994, Geert E. Booij and Jaap van Marle (eds.), 207–244. Dordrecht: Foris. Plaut, David C., and Laura M. Gonnerman 2000 Are non-semantic morphological effects incompatible with a distributed connectionist approach to lexical processing? Language and Cognitive Processes 15: 445–485. Pollatsek, Alexander, Jukka Hyönä, and Raymond Bertram 2000 The role of morphological constituents in reading Finnish compound words. Journal of Experimental Psychology: Human Perception and Performance 26: 820–833. Ratti, Daniela, Lucia Marconi, Giovanna Morgavi, and Claudia Rolando 1988 Flessioni, rime e anagrammi. Bologna: Zanichelli. Schreuder, Robert, and R. Harald Baayen 1995 Modeling morphological processing. In Morphological aspects of language processing, Laurie B. Feldman (ed.), 131–154. Hove: Erlbaum. Schreuder, Robert, and R.Harald Baayen 1997 How complex simple words can be. Journal of Memory and Language 36: 118–139. Schreuder, Robert, Cristina Burani, and R.Harald Baayen 2002 Parsing and semantic opacity. In Reading complex words, Egbert Assink and Dominiek Sandra (eds.), 159–189. Dordrecht: Kluwer. Stolz, Jennifer A., and Laurie B. Feldman 1995 The role of orthographic and semantic transparency of the base morpheme in morphological processing. In Morphological aspects of language processing, Laurie B. Feldman (ed.), 109–129. Hove: Erlbaum. Taft, Marcus 1994 Interactive-activation as a framework for understanding morphological processing. Language and Cognitive Processes 9: 271– 294. The interplay of root, suffix and whole-word frequency 207 Taft, Marcus, and Ken Forster 1975 Lexical storage and retrieval of prefixed words. Journal of Verbal Learning and Verbal Behavior 14: 637–647. Taft, Marcus, and Ken Forster 1976 Lexical storage and retrieval of polymorphemic and polysyllabic words. Journal of Verbal Learning and Verbal Behavior 15: 607–620. Thornton, Anna M., Claudio Iacobini, and Cristina Burani 1994 BDVDB. Una base di dati sul Vocabolario di Base della lingua italiana. Roma: Istituto di Psicologia del CNR. Thornton, Anna M., Claudio Iacobini, and Cristina Burani 1997 BDVDB. Una base di dati sul Vocabolario di Base della lingua italiana. Con un intervento di Tullio De Mauro. 2nd edition. Roma: Bulzoni. Tsapkini, Kyrana, Eva Kehayia, and Gonia Jarema 1998 The psycholinguistic reality of morphophonological changes during derivation. Brain and Cognition 37: 166–168. Tsapkini, Kyrana, Eva Kehayia, and Gonia Jarema 1999 Phonological change in derivation: A psycholinguistic study. Brain and Language 68: 318–323. van Jaarsveld, Henk J., Riet Coolen, and Robert Schreuder 1994 The role of analogy in the interpretation of novel compounds. Journal of Psycholinguistic Research 23: 111–137. Vannest, Jennifer, and Julie E. Boland 1999 Lexical morphology and lexical access. Brain and Language 68: 324–332.
 0
0
advertisement
Related documents





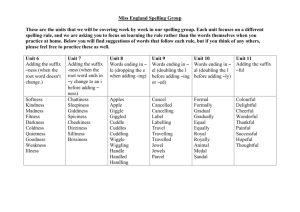

Download
advertisement
Add this document to collection(s)
You can add this document to your study collection(s)
Sign in Available only to authorized usersAdd this document to saved
You can add this document to your saved list
Sign in Available only to authorized users