Assignments for lecture „Bioinformatics III“ WS 03/04
advertisement

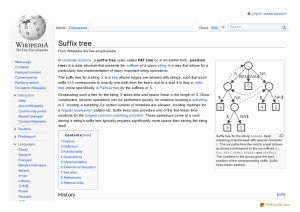
Assignments for lecture „Bioinformatics III“ WS 03/04 Assignment 2, return in room 1.05 Building 17.1 until Nov 18, 2003, 11 am Your name: Matrikelnummer: Fachrichtung: General remark: These exercises often require to “show” something. This does not require a formal proof. Just describe the solution idea. Please direct questions to: Jörg Niggemann, tel. 302-64176, email: joergn@thoughtblade.com (1) Draw a suffix tree for the string “mississippi”. Optional: use a shorter string of your choice, and use one of the algorithms of McGraigh, Ukkonen or Weiner. Use a different color for each phase. (20 points) (2) How can you improve the suffix tree, such that it takes less space in memory? Hint: You don't have to maintain it as a tree. Look at repetitive branches and think of a DAG (directed acyclic graph) as a result. (10 points) (3) Construct an infinite family of strings over a fixed alphabet, where the total length of the edge-labels on their suffix trees grows faster than (m) (m is the length of the string). That is, show that linear-time suffix tree algorithms would be impossible if edge-labels were written explicitly on the edges. (15 points) (4) Consider a generalized suffix tree built for a set of k strings. Additional strings may be added to the set, or entire strings may be deleted from the set. This is the common case for maintaining a generalized suffix tree for biological sequence data. Discuss the problem of maintaining the generalized suffix tree in this dynamic setting. Explain why this problem has a much easier solution than when arbitrary substrings represented in the suffix tree are deleted. (15 points) (5) a) Show how to count the number of distinct substrings of a string T in O(m) time, where the length of T is m. b) Show how to enumerate one copy of each distinct substring, all together in time proportional to the total length of all strings. c) Given a substring P of length n, compute the frequency of P in T in O(n) time. That is the time needed to walk along P to its end, so the information should be accessible from the end of P in constant time. Hint for this and the next exercise: O(m) is again the time to construct the suffix tree. Think how you can accumulate information on the nodes either while constructing the tree or during one tree traversal after the tree is finished. Recall that tree traversals are linear, so they don't spoil the O(m) time bound. (20 points) (6) One way to hunt for “interesting“ sequences in a DNA sequence database is to look for substrings in the database that appear much more often than they would be predicted to appear by chance alone. This is done today and will become even more attractive when huge amounts of anonymous DNA sequences are available. Assuming one has a statistical model to determine how likely any particular substring would occur by chance, and a threshold above which a substring is “interesting”, show how to efficiently find all interesting substrings in the database. If the database has a total length m, then the method should take time O(m) (= construction of the suffix tree plus traversal) plus time proportional to the number of interesting substrings (= output each one's origin and length). (10 points) (7) Given a set S of k strings, we want to find every string in S that is a substring of some other string in S. Assuming that the total length of all the strings is n, give an O(n) time algorithm to solve this problem. (10 points)

















![Algorithms on Strings, Trees, and Sequences [Gusfield 1997-05-28]](http://s3.studylib.net/store/data/025479450_1-d17df8d956097aef6f5c5055ee175e02-300x300.png)